📈 深度学习中的梯度问题:从消失到爆炸,全面解析与解决方案
更新时间:2026年3月15日
在深度学习的世界里,梯度消失 和梯度爆炸是两个令人头疼的问题。它们不仅影响模型的训练效率,还可能导致模型无法收敛或过早停滞。
今天,我们就来深入探讨这两个问题的本质,并提供一系列经过验证的解决方案------从激活函数的选择,到权重初始化、残差连接、归一化技术,再到梯度裁剪。无论你是初学者还是有经验的研究者,这篇文章都将为你提供清晰的指导。
🛠️ 一、问题回顾:为什么会出现梯度消失/爆炸?
核心原因:链式法则中的连乘
在反向传播过程中,第 l 层的梯度可以表示为:
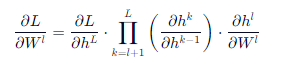
其中:

常见诱因:
- 使用 sigmoid/tanh 激活函数:这些函数的导数最大值较小(如 sigmoid 的导数最大为 0.25),容易导致梯度迅速衰减。
- 权重初始化不当:如果权重过大或过小,会导致信号逐层放大或缩小。
- 网络过深:层数越多,连乘项越多,梯度消失或爆炸的风险越大。
💡 二、主流解决方案详解
✅ 方法 1:使用 ReLU 及其变体(激活函数改进)
原理:
ReLU 函数定义为:
f(x)=max(0,x)
其导数为:
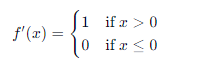
优点:
- 简单高效,计算速度快
- 极大缓解梯度消失(尤其在 CNN 中)
缺点:
- "死神经元"问题:若输入长期 ≤0,梯度=0,永远不更新
- 对梯度爆炸无直接帮助
改进版:
- Leaky ReLU: f(x)=max(0.01x,x) ,负区也有小梯度
- ELU / Swish: 更平滑,兼顾非线性和梯度稳定性
📌 适用场景:CNN、MLP 等前馈网络的默认选择。
✅ 方法 2:合理的权重初始化(Weight Initialization)
原理:
让每层的输出方差 ≈ 输入方差,避免信号逐层放大或缩小。
经典方案:
| 初始化方法 | 适用激活函数 | 公式(权重 ~ Uniform 或 Normal) |
|---|---|---|
| Xavier / Glorot | tanh, sigmoid | 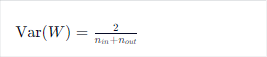 |
| He Initialization | ReLU 及变体 |  |
效果:
- 使前向传播时激活值分布稳定
- 使反向传播时梯度不至于过小或过大
优点:
- 几乎零成本,所有框架默认支持(如 torch.nn.Linear 自动用 He)
- 对浅层到中等深度网络非常有效
局限:
- 无法解决极深网络(>50层)的根本问题
📌 适用场景:所有神经网络的基础必备设置。
✅ 方法 3:残差连接(Residual Connection / Skip Connection)
原理(核心创新):
引入恒等映射(identity mapping),让信息直接跨层传递。
标准残差块:
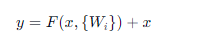
其中 F 是残差函数(如两层卷积)。
为什么能解决梯度消失?
反向传播时:
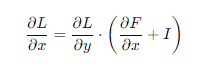
即使 ∂F∂x→0 ,仍有单位矩阵 I 项保证梯度不消失!

优点:
- 彻底解决极深网络(100+层)的训练难题
- 提升模型表达能力(更容易优化)
缺点:
- 增加少量参数和计算(但收益远大于成本)
📌 适用场景:ResNet(图像)、Transformer(NLP)、几乎所有现代深度架构。
✅ 方法 4:归一化技术(Normalization)
常见类型:
| 方法 | 归一化维度 | 主要用途 |
|---|---|---|
| BatchNorm (BN) | Batch 维度(同一通道,不同样本) | CNN、MLP |
| LayerNorm (LN) | Feature 维度(同一样本,所有特征) | Transformer、RNN |
| GroupNorm | 分组归一化 | 小 batch 场景 |
原理:
对某一层的输入 z 做标准化:
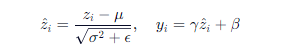
其中 μ,σ 是均值和标准差, γ,β 是可学习的缩放和平移参数。
如何缓解梯度问题?
- 防止激活值进入饱和区(如 sigmoid 的两端)→ 保持较大导数
- 稳定每层输入分布 → 减少"内部协变量偏移"
- 允许使用更高学习率 → 加速收敛,间接减少不稳定
⚠️ 注意:BN 在小 batch 时效果差;LN 不依赖 batch,更适合 NLP。
📌 适用场景:
- BN:计算机视觉(ResNet 等)
- LN:大语言模型(Transformer 必备)
✅ 方法 5:梯度裁剪(Gradient Clipping)------ 专治爆炸
原理:
如果梯度范数超过阈值 T ,就按比例缩小:
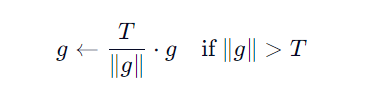
优点:
- 简单粗暴,100% 防止梯度爆炸
- 对 RNN/LSTM 训练至关重要
缺点:
- 只解决爆炸,不解决消失
- 可能丢失部分梯度方向信息
📌 适用场景:RNN、训练初期不稳定、大模型微调。
🧩 三、方法对比总结表
表格
| 方法 | 解决消失? | 解决爆炸? | 是否增加计算? | 适用网络类型 | 备注 |
|---|---|---|---|---|---|
| ReLU 激活 | ✅(强) | ❌ | ❌ | CNN, MLP | 基础首选 |
| 合理初始化 | ✅(中) | ✅(中) | ❌ | 所有 | 必须做 |
| 残差连接 | ✅✅(极强) | ✅(间接) | ✅(少量) | ResNet, Transformer | 深度网络基石 |
| BatchNorm | ✅(中) | ✅(中) | ✅ | CNN, MLP | 依赖 batch size |
| LayerNorm | ✅(中) | ✅(中) | ✅ | Transformer, RNN | LLM 标配 |
| 梯度裁剪 | ❌ | ✅✅(强) | ❌ | RNN, 大模型 | 安全阀 |
🖼️ 四、实际应用中的组合策略(最佳实践)
现代深度学习系统从不依赖单一方法,而是组合使用多种技术来应对复杂的训练挑战。
图像任务(如 ResNet):
- He 初始化 + ReLU + BatchNorm + 残差连接
- 这种组合确保了深层网络的稳定性和高效的梯度传播。
大语言模型(如 Llama, GPT):
- LayerNorm(每层前后) + 残差连接 + GELU/Swish 激活 + 梯度裁剪
- LayerNorm 和残差连接保证了长序列处理的稳定性,GELU/Swish 激活提供了更好的非线性特性,而梯度裁剪防止了潜在的梯度爆炸。
RNN/LSTM:
- tanh/sigmoid(不可避免) + 梯度裁剪 + 精心初始化
- 虽然 RNN/LSTM 使用的激活函数不可避免地会遇到梯度问题,但通过梯度裁剪和合理的初始化可以显著改善训练过程。
🎭 五、一个直观比喻帮你理解
想象你在山谷中找最低点(最优解):
- 没有这些方法:你走着走着,路越来越平(梯度消失)→ 动不了;或者突然掉下悬崖(梯度爆炸)→ 摔死。
- 用了 ReLU:地面不再平坦,总有坡度。
- 用了初始化:起点选在合理位置,不会一开始就悬在崖边。
- 用了残差连接:每隔一段就有电梯直达底层,不怕迷路。
- 用了归一化:地面被整平了,走路不打滑。
- 用了梯度裁剪:给你系了安全绳,掉下去会被拉住。
💬 总结
梯度消失和爆炸的核心问题是连乘导致的数值不稳定。单一方法往往不够,需组合使用多种技术------包括激活函数、权重初始化、结构设计(如残差连接)、归一化以及梯度裁剪。
现代架构(如 Transformer)已经内建了多种防护机制,因此能够轻松训练上百层的网络。你不需要手动实现这些技术------PyTorch/TensorFlow 已内置,但理解原理可以帮助你更高效地调试和优化模型。
🔗 延伸阅读: