Redis 主从复制(Replication)是构建高可用 Redis 系统的基石,其核心作用是实现数据冗余备份 、读写分离以及为哨兵(Sentinel)和集群(Cluster)提供高可用基础。本文将从核心概念、完整流程、关键机制、演进优化等维度,深入、严谨地剖析其实现原理。
一、核心概念与关键数据结构
在讲解流程前,必须先明确支撑主从复制的核心概念和数据结构,这是理解后续原理的基础。
1. 运行 ID(Run ID)
- 定义:每个 Redis 节点启动时自动生成的唯一 40 位十六进制字符串,用于唯一标识节点身份。
- 作用 :
- 从节点通过对比主节点的 Run ID,判断当前连接的主节点是否为 "之前同步过的那个主节点"。
- 若 Run ID 不匹配,说明主节点发生了切换(或从节点连接了新主节点),必须进行全量复制。
2. 复制偏移量(Replication Offset)
主从节点各自维护一个偏移量,用于精确衡量数据同步状态:
- 主节点偏移量(
master_repl_offset) :主节点每执行一个写命令,就将该命令的字节长度累加到偏移量上。 - 从节点偏移量(
slave_repl_offset):从节点每收到并执行一个主节点的写命令,也将字节长度累加到自己的偏移量上。 - 核心作用 :
- 通过对比主从偏移量,可快速判断数据是否一致(偏移量相等则一致)。
- 部分复制时,主节点根据从节点的偏移量,确定需要补发的命令范围。
3. 复制积压缓冲区(Replication Backlog Buffer)
- 定义 :主节点维护的一个固定大小的环形缓冲区 (默认 1MB,通过
repl-backlog-size配置)。 - 存储内容:主节点最近执行的写命令,以及每个命令对应的偏移量范围。
- 核心作用 :
- 用于部分复制:当从节点短暂断线重连时,若其偏移量仍在积压缓冲区范围内,主节点只需补发缓冲区中缺失的命令,无需全量复制。
- 相关配置:
repl-backlog-ttl(缓冲区闲置多久后释放,默认 3600 秒)。
4. 复制缓冲区(Replication Buffer)
- 注意与积压缓冲区区分 :复制缓冲区是主节点为每个从节点独立维护的缓冲区,而积压缓冲区是主节点全局的。
- 作用:在全量复制期间,暂存主节点在生成 RDB 文件过程中收到的新写命令,等从节点加载完 RDB 后,再将这些命令发送给从节点执行,保证数据不丢失。
二、主从复制的完整流程(分阶段深度解析)
主从复制的完整流程分为四个核心阶段:1. 建立连接与握手阶段 ;2. 数据同步阶段(全量 / 部分) ;3. 命令传播阶段 ;4. 心跳与状态维护阶段。
具体的流程图:
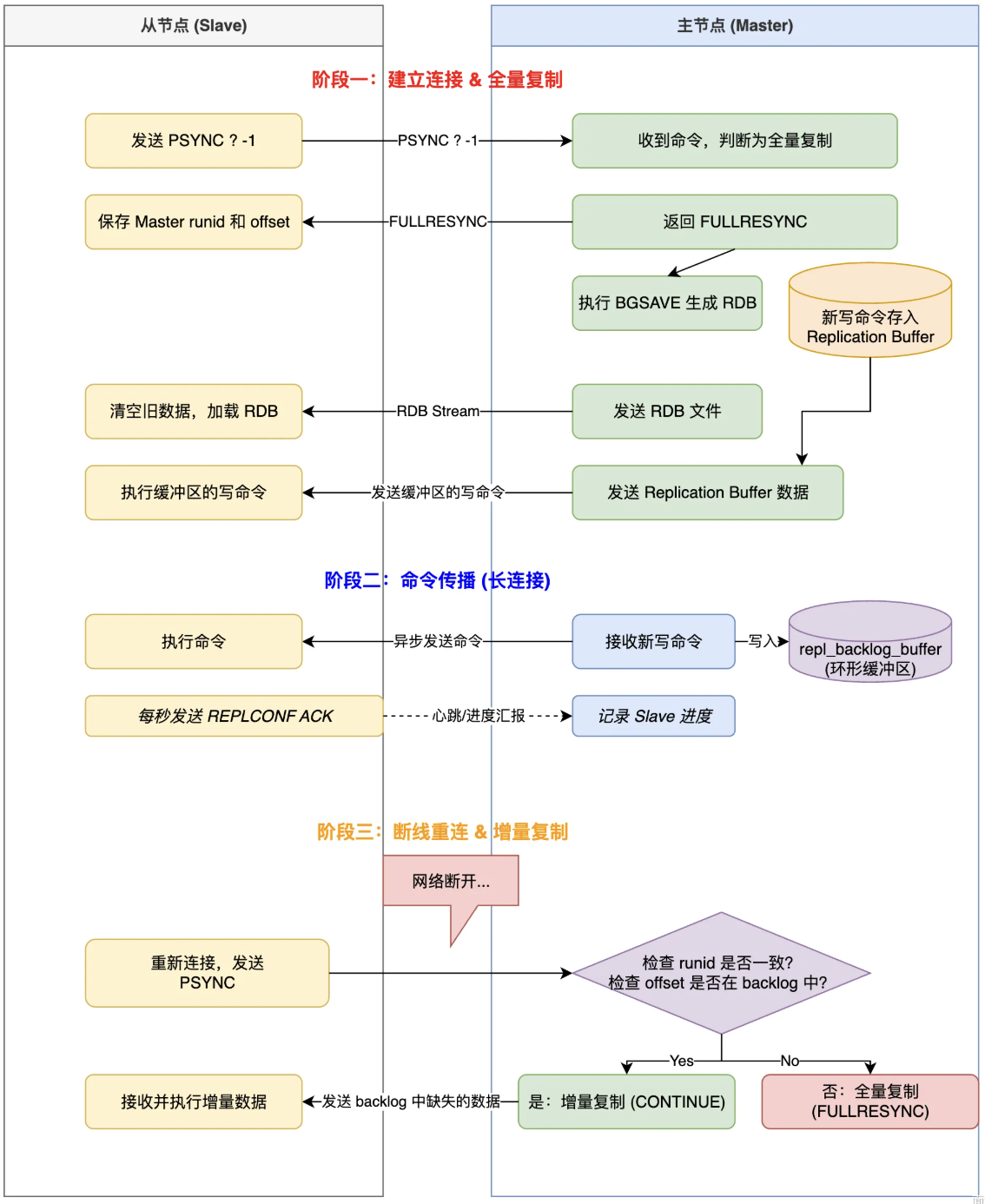
阶段 1:建立连接与握手阶段
从节点通过配置或命令指定主节点后,首先与主节点建立 TCP 连接并完成握手,确认双方的复制能力。
从节点配置主节点的方式
- 配置文件 :
replicaof <master-ip> <master-port>(Redis 5.0 之前用slaveof,现仍兼容)。 - 命令行 :从节点启动后,执行
replicaof <master-ip> <master-port>命令。
握手的详细步骤
- 建立 TCP 连接:从节点向主节点的默认端口(6379)发起 TCP 连接。
- 从节点发送 PING 命令 :
- 目的:检测主节点是否可达、TCP 连接是否正常。
- 响应:主节点正常则返回 PONG;若主节点设置了
requirepass,则返回NOAUTH错误。
- 身份验证(若需) :
- 若主节点设置了密码,从节点需发送
AUTH <password>命令(可通过masterauth配置自动发送)。
- 若主节点设置了密码,从节点需发送
- 从节点发送 REPLCONF listening-port <port> :
- 目的:告知主节点自己的监听端口,主节点会记录该信息用于后续心跳检测。
- 从节点发送 REPLCONF capa eof capa psync2 :
- 目的:告知主节点自己支持的复制能力(如 PSYNC2.0、无盘复制的 EOF 标识)。
- 主节点会根据从节点的能力选择最优复制方式。
- 握手完成:双方确认复制能力,进入数据同步阶段。
阶段 2:数据同步阶段(核心中的核心)
从节点发送 PSYNC 命令(Redis 2.8 之前用 SYNC)请求同步数据。PSYNC 命令的格式随版本演进:
- PSYNC1.0(Redis 2.8-3.2) :
PSYNC <master-runid> <offset> - PSYNC2.0(Redis 4.0+) :
PSYNC <master-runid> <offset> [replid2 <replid2> <offset2>]replid2:从节点记录的上一个主节点的复制 ID(用于主节点切换后的部分复制)。offset2:对应replid2的偏移量。
主节点收到 PSYNC 后,会先判断是执行全量复制 还是部分复制。
2.1 全量复制(Full Resync)
适用场景:
- 从节点第一次连接主节点(
master-runid为?)。 - 从节点断线重连,但
master-runid与当前主节点不匹配。 - 从节点的偏移量不在复制积压缓冲区范围内。
全量复制的详细流程:
- 主节点执行 BGSAVE 生成 RDB 文件 :
- 主节点
fork出一个子进程,子进程负责生成 RDB 快照文件。 - 关键细节 :
fork操作会短暂阻塞主节点(取决于内存大小,因为需复制页表),Redis 采用写时复制(Copy-On-Write) 机制减少内存占用 ------ 子进程共享主进程的内存页,仅当主进程修改某页时,才会复制该页的副本。
- 主节点
- 主节点发送 FULLRESYNC 响应 :
- 格式:
FULLRESYNC <master-runid> <offset>。 - 从节点记录下主节点的 Run ID 和初始偏移量,作为后续部分复制的依据。
- 格式:
- 主节点向从节点发送 RDB 文件 :
- 子进程完成 RDB 生成后,主节点通过 TCP 连接将 RDB 文件发送给从节点。
- 无盘复制优化(Diskless Replication) :
- 配置:
repl-diskless-sync yes(默认no)。 - 流程:主节点不将 RDB 写入磁盘,而是直接通过网络发送给从节点,避免磁盘 IO 瓶颈(适合主节点磁盘慢但网络快的场景)。
- 细节 :无盘复制时,主节点会等待
repl-diskless-sync-delay(默认 5 秒),以便让更多从节点连接上来,一起接收 RDB(因为无盘复制只能同时发送给一批从节点)。
- 配置:
- 从节点接收并加载 RDB 文件 :
- 从节点先清空自己的旧数据 (执行
FLUSHALL)。- 注意:若
replica-serve-stale-data yes(默认),在清空旧数据到加载完新 RDB 期间,从节点仍会响应读请求,但返回旧数据。
- 注意:若
- 从节点将 RDB 保存到磁盘(无盘复制则直接加载到内存),然后加载 RDB 到内存(加载期间从节点阻塞,无法处理命令)。
- 从节点先清空自己的旧数据 (执行
- 主节点发送复制缓冲区中的写命令 :
- 在 BGSAVE 生成 RDB 期间,主节点仍会接收新写命令,这些命令被暂存到为该从节点维护的复制缓冲区中。
- 从节点加载完 RDB 后,主节点将复制缓冲区中的命令发送给从节点,从节点执行这些命令,保证数据与主节点一致。
- 全量复制完成:从节点进入命令传播阶段。
2.2 部分复制(Partial Resync)
适用场景:从节点短暂断线重连,且满足:
- 主节点 Run ID 匹配(或 PSYNC2.0 下
replid2匹配)。 - 从节点的偏移量在复制积压缓冲区范围内。
部分复制的详细流程:
- 主节点发送 CONTINUE 响应:表示可以进行部分复制。
- 主节点定位缺失命令:根据从节点的偏移量,在复制积压缓冲区(环形结构)中找到该偏移量之后的所有写命令。
- 主节点补发缺失命令:将找到的命令发送给从节点。
- 从节点执行命令并更新偏移量:执行完命令后,从节点的偏移量与主节点一致,部分复制完成,进入命令传播阶段。
阶段 3:命令传播阶段(持续同步)
全量 / 部分复制完成后,主从进入命令传播阶段:主节点将写命令异步发送给从节点,从节点执行命令以保持数据一致。
详细流程:
- 主节点执行写命令 :如
SET key value、DEL key等。 - 主节点更新偏移量 :将命令的字节长度累加到
master_repl_offset。 - 主节点异步发送命令给从节点 :
- 关键细节:异步发送 ------ 主节点执行完命令就返回客户端,不等待从节点确认,因此主从复制是最终一致性,而非强一致性。
- 主节点为每个从节点维护输出缓冲区,暂存待发送的命令,避免网络阻塞导致主节点卡住。
- 从节点接收并执行命令 :
- 从节点将命令存入输入缓冲区,在事件循环中取出执行。
- 从节点更新自己的
slave_repl_offset。
一致性补充:
- Redis 本身不支持纯同步复制,但可通过
WAIT <numreplicas> <timeout>命令实现有限同步:阻塞主节点,直到至少numreplicas个从节点确认收到最近的写命令,或超时。
阶段 4:心跳与状态维护阶段
主从通过心跳机制检测对方存活状态,并维护复制健康度。
4.1 从节点的心跳:REPLCONF ACK
从节点每秒 向主节点发送一次 REPLCONF ACK <offset> 命令(offset 是从节点当前的偏移量)。
- 作用 :
- 检测主节点存活:若主节点超过
repl-timeout(默认 60 秒)未收到 ACK,认为从节点断线。 - 上报偏移量:主节点记录每个从节点的偏移量,用于:
- 判断从节点是否落后太多。
- 执行
WAIT命令时判断同步的从节点数量。
- 检测网络延迟。
- 检测主节点存活:若主节点超过
4.2 主节点的心跳:PING
主节点默认每 10 秒 向从节点发送一次 PING 命令(可通过 repl-ping-slave-period 配置)。
- 作用 :检测从节点存活,若超过
repl-timeout未响应,关闭连接。
三、PSYNC 的演进与核心优化
1. SYNC(Redis 2.8 之前)
- 仅支持全量复制,断线重连成本极高(即使只丢少量数据,也要重传整个 RDB)。
2. PSYNC1.0(Redis 2.8-3.2)
- 引入复制偏移量、复制积压缓冲区、Run ID,支持部分复制,大幅降低断线重连成本。
3. PSYNC2.0(Redis 4.0+)
核心优化:
- 主节点切换后的部分复制 :
- 引入
replid2(第二个复制 ID):当主节点故障转移(如哨兵模式下从节点升级为主节点),新主节点会保留旧主节点的复制 ID 作为replid2。 - 旧从节点重连时,可通过
replid2和对应偏移量进行部分复制,无需全量复制。
- 引入
- 完善无盘复制 :
- 支持 EOF 标识,主节点发送完 RDB 后发送 EOF,从节点明确知道传输完成。
- 优化多从节点同时接收的逻辑。
四、关键配置参数总结
表格
| 参数 | 作用 | 默认值 |
|---|---|---|
replicaof <ip> <port> |
配置从节点的主节点 | - |
masterauth <password> |
从节点连接主节点的密码 | - |
repl-backlog-size <size> |
复制积压缓冲区大小 | 1MB |
repl-backlog-ttl <sec> |
积压缓冲区闲置释放时间 | 3600s |
repl-diskless-sync yes/no |
开启无盘复制 | no |
repl-timeout <sec> |
复制超时时间 | 60s |
slave-read-only yes/no |
从节点是否只读 | yes |
五、一致性保证与局限性
1. 一致性保证
- 最终一致性:主从数据最终一致,但命令传播期间可能存在短暂不一致。
- 有限同步一致性 :通过
WAIT命令可在一定程度上保证数据不丢失,但会降低性能。
2. 局限性
- 非强一致性:主节点宕机可能导致未同步到从节点的数据丢失。
- 从节点延迟:从节点可能因网络、处理慢等原因落后于主节点,导致读旧数据。
- 全量复制开销:第一次同步或部分复制不可用时,全量复制需传输大 RDB 文件。
总结
Redis 主从复制通过 "连接握手 → 数据同步(全量 / 部分)→ 命令传播 → 心跳维护" 的完整流程,实现了高效的数据冗余和读写分离。其核心机制(复制偏移量、积压缓冲区、PSYNC 演进)大幅提升了复制的可靠性和效率,但需注意其最终一致性的局限性,并合理配置参数以保障复制健康运行。