深度解析 LLM Agent 进化史:从 ReAct 到 Self-Discover 框架的底层逻辑与工程实现
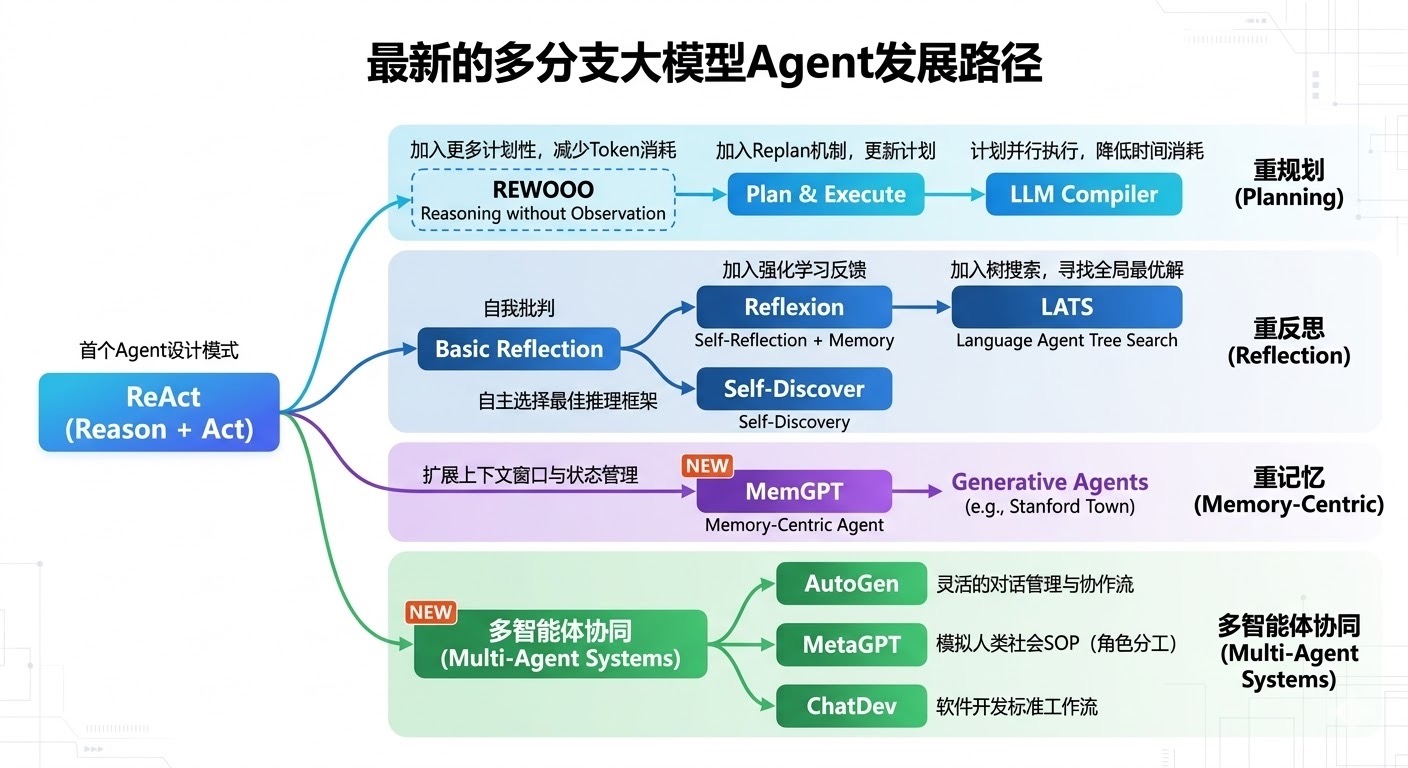
在目前的大模型 Agent 赛道,架构的演进日新月异。如果我们回顾 Agent 的发展路径(正如上方的发展路线图所示),可以清晰地看到一条主线:从"通用但粗糙的试错"向"定制化、结构化、具备自我反思能力的高效推理"演进。
从首个确立 Agent 范式的 ReAct (Reason + Act) 开始,大模型具备了与外部环境交互的基础能力。然而,ReAct 的问题在于其推理链路是固定的、线性的,且极其依赖模型本身的 Zero-shot/Few-shot 涌现能力。为了突破这个瓶颈,学术界和工业界在"重反思 (Reflection)"这一分支上进行了深度探索,并衍生出两条截然不同的路线:
- 后置纠错路线 :例如 Reflexion (加入强化学习反馈,事后反思更新 Memory)和 LATS(引入蒙特卡洛树搜索 MCTS,在生成过程中寻找全局最优解)。
- 前置架构生成路线 :即图中标注的"自主选择最佳推理框架"的 Self-Discover。
一、 来龙去脉:为什么我们需要 Self-Discover?
在深入 Self-Discover 之前,我们需要理解它"革了谁的命"。
以往我们在提升 LLM 推理能力时,通常会使用如 Chain-of-Thought (CoT)、Tree-of-Thoughts (ToT) 或 Graph-of-Thoughts (GoT) 等提示工程技术。
- CoT 过于简单,只是一条单向链,无法处理复杂的分支逻辑。
- ToT / GoT 虽然引入了树/图搜索(类似 LATS 的思想),但推理成本极高。对于每一个 Query,都需要展开搜索树并进行多次评估,Token 消耗呈指数级上升。
Self-Discover 的核心破局点在于:Meta-Reasoning(元推理)。
它不再为每个独立的问题(Instance)去死磕搜索树,而是针对某一类任务(Task Type) ,让 LLM 自主组合出一套最适合该任务的"定制化推理结构"(通常表示为 JSON 格式的流程图)。在推理阶段,只需要按照这个固定下来的结构执行即可。
这本质上是一种 O ( 1 ) O(1) O(1) 的推理成本,却能逼近甚至达到 O ( b d ) O(b^d) O(bd) (如 ToT) 的推理效果。
二、 Self-Discover 的底层原理解析
2024年谷歌提出了一篇 SELF-DISCOVER: Large Language Models Self-Compose Reasoning Structures, 提升模型的推理与数学能力。
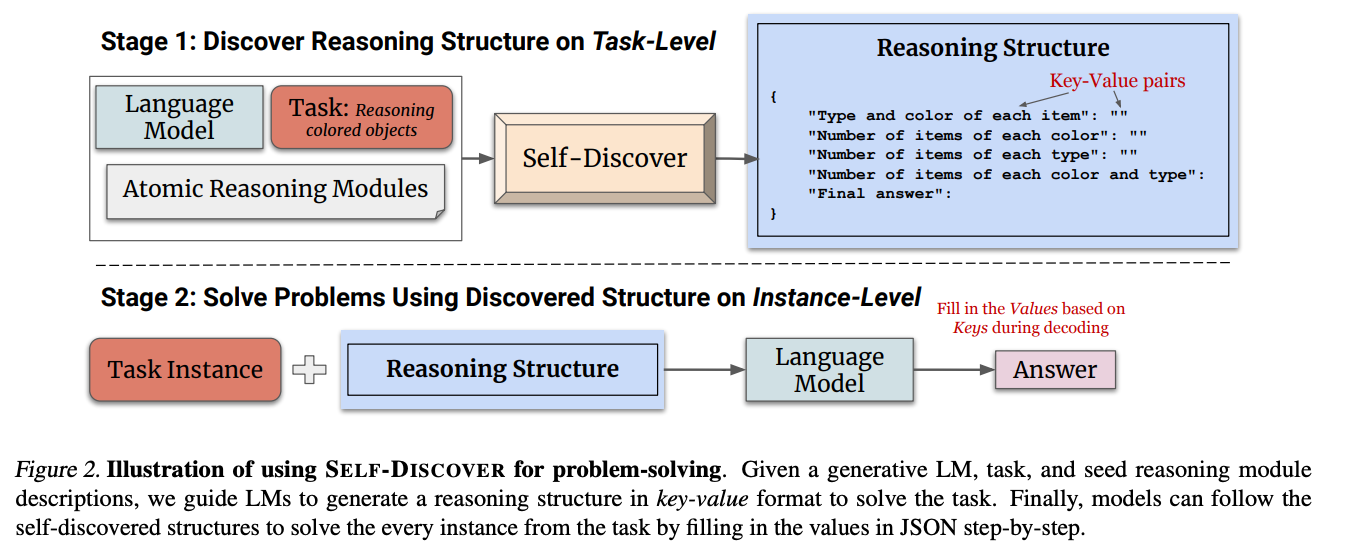
Self-Discover 的核心流程分为两个阶段:发现阶段(Stage 1: Discover) 和 应用阶段(Stage 2: Application)。
Stage 1: Discover(任务级别的架构生成)
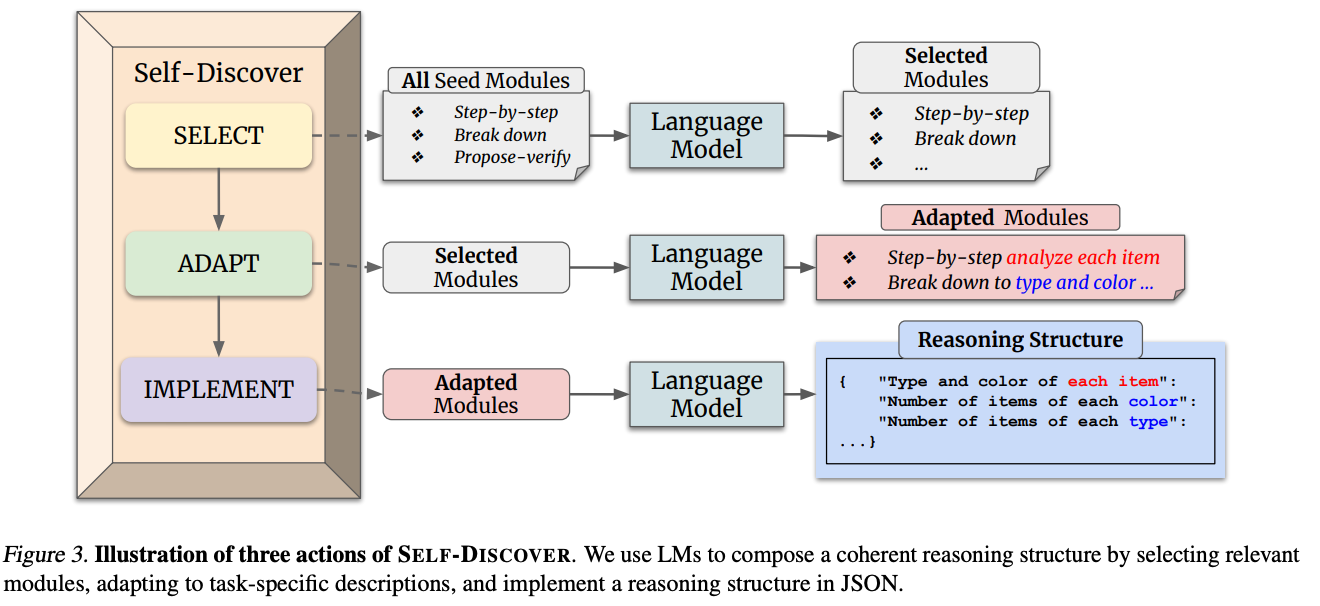
这一阶段的目标是:给定一个任务描述 T T T 和一个人类预定义的通用推理模块种子库 M = { m 1 , m 2 , . . . , m n } M = \{m_1, m_2, ..., m_n\} M={m1,m2,...,mn}(包含如"分解问题"、"批判性思考"、"逆向推导"等 39 个常见的认知模块),生成一个结构化的推理计划 P P P。
该过程包含三个核心动作:
-
Select(选择) :
LLM 根据任务描述 T T T,从种子库 M M M 中挑选出相关的推理模块集合 M s e l M_{sel} Msel。
M s e l = f s e l e c t ( M , T ) M_{sel} = f_{select}(M, T) Msel=fselect(M,T) -
Adapt(适配) :
挑选出来的模块通常是抽象的(如"分解问题")。LLM 需要将这些模块实例化 到具体的任务场景中(如变成"将复杂的物理公式分解为已知的常数和变量")。
M a d a p t = f a d a p t ( M s e l , T ) M_{adapt} = f_{adapt}(M_{sel}, T) Madapt=fadapt(Msel,T) -
Implement(实现/结构化) :
LLM 将适配后的模块组合成一个有向无环图(DAG),通常以 JSON 格式输出,定义了解决该任务的标准操作流程(SOP)。
P = f i m p l e m e n t ( M a d a p t , T ) P = f_{implement}(M_{adapt}, T) P=fimplement(Madapt,T)
Stage 2: Application(实例级别的应用执行)
一旦针对特定任务 T T T 的推理结构 P P P 生成完毕,当新的具体问题(Instance) x x x 到来时,LLM 只需要严格遵循这个结构 P P P 一步一步解答即可,得到最终答案 y y y。
y = f e x e c u t e ( P , x ) y = f_{execute}(P, x) y=fexecute(P,x)
三、 基于 LangGraph 的核心组件实现
我们定义图的状态(State),并将 Select, Adapt, Implement, Execute 封装为图的 Node。
python
from typing import TypedDict, List, Dict, Any
from langgraph.graph import StateGraph, END
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# 1. 定义 Agent 的全局状态
class SelfDiscoverState(TypedDict):
task_description: str # 任务类型描述(如:"解答高中物理逻辑题")
query: str # 具体的问题实例
seed_modules: List[str] # 预设的 39 种通用推理模块
selected_modules: List[str] # Select 阶段选出的模块
adapted_modules: List[str] # Adapt 阶段改写后的模块
reasoning_structure: str # Implement 阶段生成的 JSON 结构
final_answer: str # 最终生成的答案
llm = ChatOpenAI(temperature=0)
# 2. 定义核心 Node 函数
def select_node(state: SelfDiscoverState):
"""从种子库中选择相关模块"""
prompt = PromptTemplate.from_template(
"任务描述: {task_description}\n"
"以下是可用的推理模块列表: {seed_modules}\n"
"请从中挑选出最有助于解决该任务的模块名称。"
)
chain = prompt | llm
res = chain.invoke(state)
# 假设解析后得到了 list of strings
return {"selected_modules": parse_list(res.content)}
def adapt_node(state: SelfDiscoverState):
"""将选出的模块适配到当前任务场景"""
prompt = PromptTemplate.from_template(
"任务描述: {task_description}\n"
"选定的模块: {selected_modules}\n"
"请将这些模块改写为针对上述任务的具体指导原则。"
)
chain = prompt | llm
res = chain.invoke(state)
return {"adapted_modules": parse_list(res.content)}
def implement_node(state: SelfDiscoverState):
"""构建结构化的 JSON 推理流程"""
prompt = PromptTemplate.from_template(
"任务描述: {task_description}\n"
"适配后的模块: {adapted_modules}\n"
"请将这些模块组织成一个 JSON 格式的推理流程结构(包含 key-value 对,value可以是下一步的依赖)。"
)
chain = prompt | llm
res = chain.invoke(state)
return {"reasoning_structure": res.content}
def execute_node(state: SelfDiscoverState):
"""依据生成的 JSON 结构解答具体问题"""
prompt = PromptTemplate.from_template(
"推理结构: {reasoning_structure}\n"
"请严格遵循上述结构的步骤,解答以下问题:\n"
"问题: {query}\n"
)
chain = prompt | llm
res = chain.invoke(state)
return {"final_answer": res.content}
# 3. 构建 LangGraph 状态图
workflow = StateGraph(SelfDiscoverState)
workflow.add_node("select", select_node)
workflow.add_node("adapt", adapt_node)
workflow.add_node("implement", implement_node)
workflow.add_node("execute", execute_node)
# 4. 定义连线 (Edges)
workflow.add_edge("select", "adapt")
workflow.add_edge("adapt", "implement")
workflow.add_edge("implement", "execute")
workflow.add_edge("execute", END)
workflow.set_entry_point("select")
app = workflow.compile()四、 常见疑难杂症 QA
🚨 考点 1:Self-Discover 的 Discover 阶段(前三个 Node)是每个 Query 都要跑一遍吗?
【深度解析】 :这是一个极其关键的工程陷阱。
在上面的 LangGraph 示例中,我将其串联在了一起,是为了展现数据流。但在真实的生产环境中,绝对不能每个 Query 都跑全流程!
- Discover 阶段是 Task-level(任务级)的 。针对某种特定的业务线(比如"客服客诉分类"),前三个节点只需要在离线阶段跑一次,生成那个固定的 JSON 结构。
- Execute 阶段是 Instance-level(实例级)的 。线上的高并发流量只需要拿着缓存好的 JSON 结构去跑
execute_node即可。 - 进阶回答 :"为了兼顾灵活性和推理延迟,一般会采用两层架构设计。离线使用 Meta-Prompting 生成并缓存基于特定任务的 SOP(JSON 结构),线上直接将该 SOP 注入 Context 执行。这样将 O ( N × D i s c o v e r c o s t ) O(N \times \text Discover_{cost}) O(N×Discovercost) 降级为了 O ( 1 × D i s c o v e r c o s t ) + O ( N × E x e c c o s t ) O(1 \times \text Discover_{cost}) + O(N \times \text Exec_{cost}) O(1×Discovercost)+O(N×Execcost)。"
🚨 考点 2:Implement 阶段要求输出复杂的 JSON 图结构,如果模型输出不合法(幻觉、格式错误)导致后续链路崩溃怎么办?
【深度解析】:这也是使用 LLM 做结构化生成的痛点。大模型很容易漏掉括号或者 key 写错。
- 解决方案 1 (Prompt 层) :使用 Few-shot 提供标准 JSON 范例;开启 OpenAI 的
response_format={"type": "json_object"}强制模式。 - 解决方案 2 (工程架构层) :引入 Retry 机制与 Parser 纠错 。在 LangGraph 中,可以在
implement和execute之间加入一个条件边 (Conditional Edge)check_json。结合 Pydantic 进行强类型校验,如果不通过,则将 Error Message 作为 Feedback 重新扔回给implement_node进行重试(类似于图中的 Basic Reflection 思想)。 - 解决方案3(约束解码): openai原生支持,开启strict模式即可。在推理框架的解码层,解码时按照预设的结构体强制提高输出json结构体的概率。比如第一个输出的token只能从 "{", "\[" 中选择,依靠解析函数识别固定位置的token的可选值
- 解决方案4(借助LLM的工具调用): 现在的LLM基本在训练时就会训练function call数据,因此想要稳定按照指定的json结构体输出,可以将目标结构体包装为工具调用形式,这样LLM输出更加稳定!
- 解决方案5(Logits Masking) : 同借助工具调用形式,但是如果工具数量过多,无法让模型正确选择想要的工具(一般是自己伪装的那个工具)。此时可以在推理框架层级,模型在输出工具调用时,通常会有特定的格式或特殊 Token(例如 OpenAI 的 <|tool_call|> ),一旦发现模型输出了该token后就触发干预,在下一个token的transformer输出logits后,mask掉其他工具信息(将目标工具名对应的 Token 的 Logits 保持不变或稍微调高,然后将所有其他工具名对应的 Token 的 Logits 强制修改为 − ∞ -\infty −∞,这样经过softmax后其他工具的概率为0,永远不会被选中),让模型不会错误选择到其他工具。
🚨 考点 3:Self-Discover 相比于图中的 LATS (Language Agent Tree Search) 的优劣势在哪里?应该如何选型?
【深度解析】:考察技术视野与业务选型能力。
- LATS (重搜索) :结合了 MCTS(蒙特卡洛树搜索),在推理过程中 不断进行探索、评估、反思。
- 优势:能找到当前问题状态下的全局最优解,极其适合复杂的、逻辑极度深度的数学证明或代码生成任务。
- 劣势:极度昂贵,无法应对 C 端高并发低延迟场景。
- Self-Discover (重规划) :在执行前 确定推理框架。
- 优势:推理效率极高,Token 消耗少,适合有固定模式、能够抽象出 SOP 步骤的任务(如数据清洗分析、标准化的多步问答)。
- 劣势:面对完全 Out-of-Distribution (OOD) 的罕见问题时,由于框架已被提前固定,可能缺乏 LATS 那种即时的灵活性。
🚨 考点 4:如何设计种子模块 (Seed Modules) 的库?
【深度解析】 :种子库 M M M 决定了 Agent 思维方式的上限。不要以为只是随便写几个词。
工业界的优秀实践是参考人类的认知科学与启发式策略。比如:
"1. How could I devise an experiment to help solve that problem?",
"2. Make a list of ideas for solving this problem, and apply them one by one to the problem to see if any progress can be made.",
"3. How could I measure progress on this problem?",
"4. How can I simplify the problem so that it is easier to solve?",
"5. What are the key assumptions underlying this problem?",
"6. What are the potential risks and drawbacks of each solution?",
"7. What are the alternative perspectives or viewpoints on this problem?",
"8. What are the long-term implications of this problem and its solutions?",
"9. How can I break down this problem into smaller, more manageable parts?",
"10. Critical Thinking: This style involves analyzing the problem from different perspectives, questioning assumptions, and evaluating the evidence or information available. It focuses on logical reasoning, evidence-based decision-making, and identifying potential biases or flaws in thinking.",
"11. Try creative thinking, generate innovative and out-of-the-box ideas to solve the problem. Explore unconventional solutions, thinking beyond traditional boundaries, and encouraging imagination and originality.",
"12. Seek input and collaboration from others to solve the problem. Emphasize teamwork, open communication, and leveraging the diverse perspectives and expertise of a group to come up with effective solutions.",
"13. Use systems thinking: Consider the problem as part of a larger system and understanding the interconnectedness of various elements. Focuses on identifying the underlying causes, feedback loops, and interdependencies that influence the problem, and developing holistic solutions that address the system as a whole.",
"14. Use Risk Analysis: Evaluate potential risks, uncertainties, and tradeoffs associated with different solutions or approaches to a problem. Emphasize assessing the potential consequences and likelihood of success or failure, and making informed decisions based on a balanced analysis of risks and benefits.",
"15. Use Reflective Thinking: Step back from the problem, take the time for introspection and self-reflection. Examine personal biases, assumptions, and mental models that may influence problem-solving, and being open to learning from past experiences to improve future approaches.",
"16. What is the core issue or problem that needs to be addressed?",
"17. What are the underlying causes or factors contributing to the problem?",
"18. Are there any potential solutions or strategies that have been tried before? If yes, what were the outcomes and lessons learned?",
"19. What are the potential obstacles or challenges that might arise in solving this problem?",
"20. Are there any relevant data or information that can provide insights into the problem? If yes, what data sources are available, and how can they be analyzed?",
"21. Are there any stakeholders or individuals who are directly affected by the problem? What are their perspectives and needs?",
"22. What resources (financial, human, technological, etc.) are needed to tackle the problem effectively?",
"23. How can progress or success in solving the problem be measured or evaluated?",
"24. What indicators or metrics can be used?",
"25. Is the problem a technical or practical one that requires a specific expertise or skill set? Or is it more of a conceptual or theoretical problem?",
"26. Does the problem involve a physical constraint, such as limited resources, infrastructure, or space?",
"27. Is the problem related to human behavior, such as a social, cultural, or psychological issue?",
"28. Does the problem involve decision-making or planning, where choices need to be made under uncertainty or with competing objectives?",
"29. Is the problem an analytical one that requires data analysis, modeling, or optimization techniques?",
"30. Is the problem a design challenge that requires creative solutions and innovation?",
"31. Does the problem require addressing systemic or structural issues rather than just individual instances?",
"32. Is the problem time-sensitive or urgent, requiring immediate attention and action?",
"33. What kinds of solution typically are produced for this kind of problem specification?",
"34. Given the problem specification and the current best solution, have a guess about other possible solutions.",
"35. Let's imagine the current best solution is totally wrong, what other ways are there to think about the problem specification?",
"36. What is the best way to modify this current best solution, given what you know about these kinds of problem specification?",
"37. Ignoring the current best solution, create an entirely new solution to the problem.",
"38. Let's think step by step.",
"39. Let's make a step by step plan and implement it with good notation and explanation."
五、 总结
回顾开篇的 Agent 发展图谱,Self-Discover 代表了 Agent 从"蛮力搜索"向"元认知与自规划"进化的重要里程碑。它不仅仅是一个 Prompt 技巧,更是一种工程降本增效的架构级思想:通过将高昂的"探索成本"前置到任务级别的规划层,极大地优化了线上的实时推理性能。