
TL;DR
- 场景:离线数仓建设中,需要处理商品分类、商家组织、商品信息等维表建模与每日装载。
- 结论:小维表适合每日快照,大维表适合拉链表;反范式宽表能显著降低查询复杂度,但要明确更新策略与口径边界。
- 产出:本文覆盖 Hive DIM 建表、ODS 到 DIM 加载脚本、快照表与 SCD 拉链表实现思路及错误排查入口。
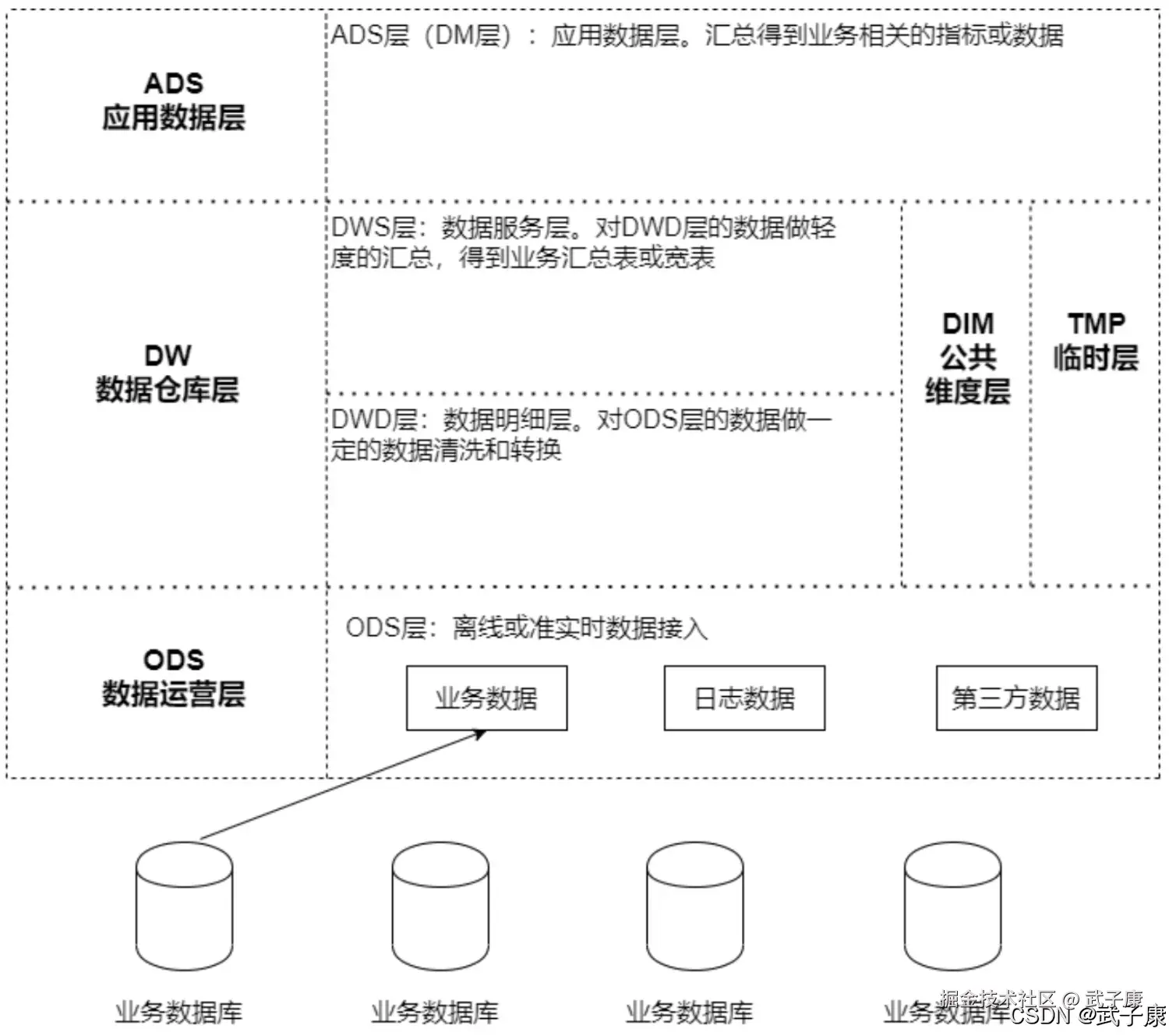
基本介绍
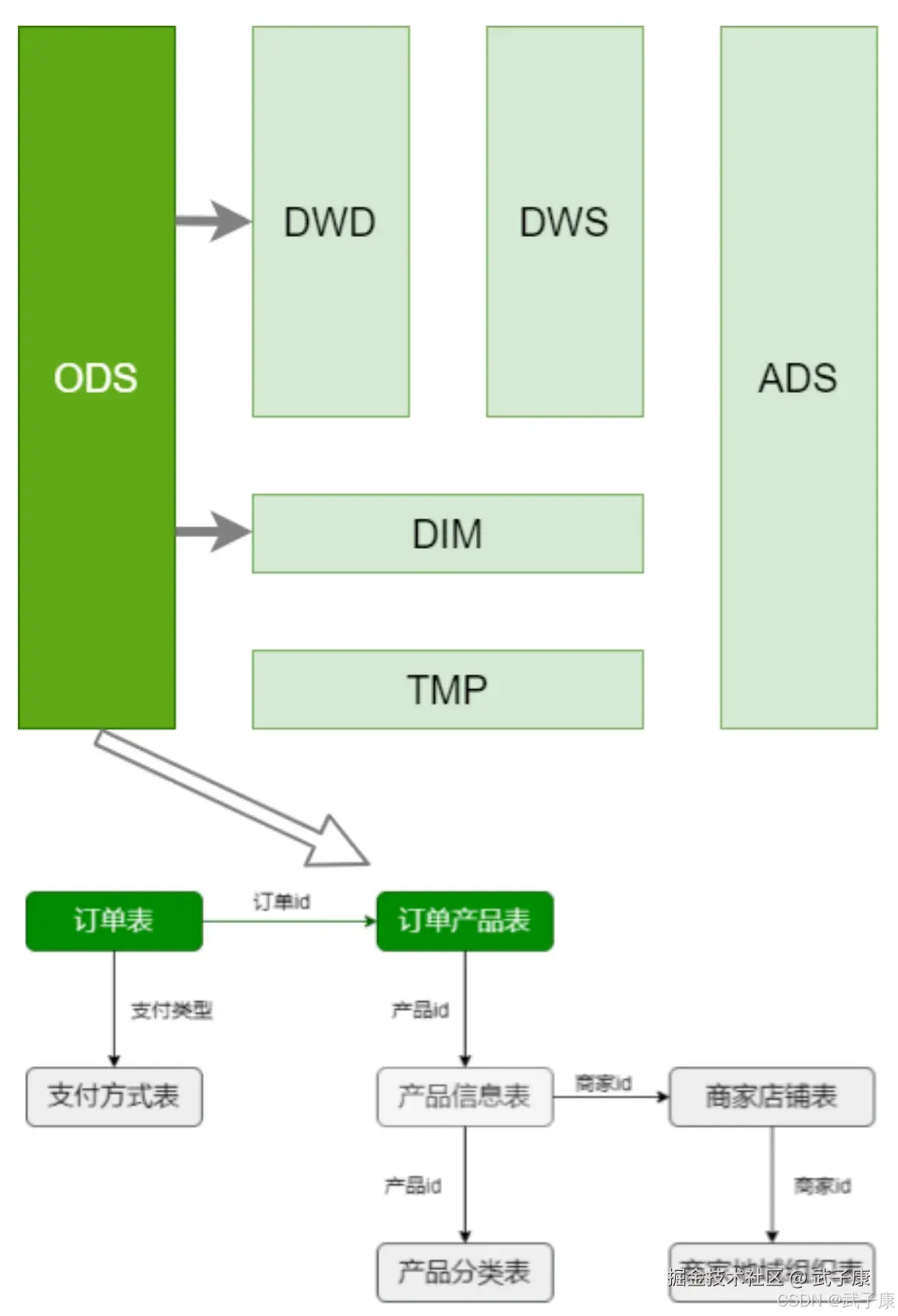 首先要确定哪些是事实表、维表。
首先要确定哪些是事实表、维表。
- 绿色为事实表
- 灰色为维表
用什么方式处理维表,每日快照、拉链表?
- 小表使用每日快照表:产品分类表、商家店铺表、商家地域组织表、支付方式表
- 大表使用拉链表:产品信息表
商品分类表
范式与反范式
数据库范式是设计关系型数据库结构时的一套指导原则,目的是为了减少数据冗余、确保数据依赖性合理,并提高数据一致性。然而,遵循范式也有一些潜在的缺点:
- 性能问题:高度规范化的数据库可能会导致查询和连接操作变慢,因为需要在多个表之间进行复杂的连接来获取完整的信息。
- 复杂性增加:随着范式的深入应用,数据库模式变得更加复杂,维护起来更加困难。对于开发人员来说,理解和编写针对规范化数据库的查询也变得更具有挑战性。
- 过度设计:有时过于追求范式会导致对简单场景的过度工程化,增加了不必要的复杂性和工作量。
- 读取效率低下:在某些情况下,为了保证写入时的数据完整性,范式可能导致频繁的读取操作变得低效,特别是在高并发读取环境中。
为了避免这些缺点,可以采取以下策略: -选择适当的范式级别:并不是所有应用程序都需要达到第三范式或更高的标准。根据具体需求,选择适合的范式级别,例如第二范式可能就足够了。
- 反范式化(Denormalization):在一些特定场景下,如报表生成、分析处理或者为了优化读取性能,可以适当放宽范式要求,通过引入冗余数据来简化查询逻辑并提升性能。
- 使用缓存机制:对于频繁访问但不经常变化的数据,可以考虑使用缓存技术来减轻数据库的压力,从而改善性能。
- 分区与分片:对于大型数据集,可以通过水平分割(分片)或垂直分割(分区)的方式来分散数据存储,以减少单个查询所需扫描的数据量。
- 索引优化:创建合理的索引可以帮助加速查询过程,但是过多的索引同样会影响插入和更新操作的速度,因此需要权衡利弊。
- 评估业务需求:始终基于实际业务需求来进行数据库设计,不要盲目追求理论上的完美范式。了解哪些数据更关键,哪些操作更频繁,据此调整设计方案。
总之,在实践中应该灵活运用范式原则,既要保持良好的数据结构,也要考虑到性能和易用性等因素。
创建表
数据库中的数据是规范的(满足三范式),但是规范化的数据给查询带来不便。 备注:这里对商品分类维度表做了逆规范化,省略了无关的信息,做成了宽表:
sql
DROP TABLE IF EXISTS dim.dim_trade_product_cat;
create table if not exists dim.dim_trade_product_cat(
firstId int, -- 一级商品分类id
firstName string, -- 一级商品分类名称
secondId int, -- 二级商品分类Id
secondName string, -- 二级商品分类名称
thirdId int, -- 三级商品分类id
thirdName string -- 三级商品分类名称
)
partitioned by (dt string)
STORED AS PARQUET;实现的具体是:
sql
select T1.catid, T1.catname, T2.catid, T2.catname, T3.catid,
T3.catname
from (select catid, catname, parentid
from ods.ods_trade_product_category
where level=3 and dt='2020-07-01') T3
left join
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=2 and dt='2020-07-01') T2
on T3.parentid=T2.catid
left join
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=1 and dt='2020-07-01') T1
on T2.parentid=T1.catid;数据加载
编写脚本
shell
vim dim_load_product_cat.sh写入的内容如下所示:
shell
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dim.dim_trade_product_cat
partition(dt='$do_date')
select
t1.catid, -- 一级分类id
t1.catname, -- 一级分类名称
t2.catid, -- 二级分类id
t2.catname, -- 二级分类名称
t3.catid, -- 三级分类id
t3.catname -- 三级分类名称
from
-- 商品三级分类数据
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=3 and dt='$do_date') t3
left join
-- 商品二级分类数据
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=2 and dt='$do_date') t2
on t3.parentid = t2.catid
left join
-- 商品一级分类数据
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=1 and dt='$do_date') t1
on t2.parentid = t1.catid;
"
hive -e "$sql"商品地域组织表
创建表
商家店铺表、商家地域组织表 => 一张维表 这里也是逆规范化的设计、将商家店铺表、商家地域组织表组织成一张表,并拉宽。 在一行数据中体现:
- 商家信息
- 城市信息
- 地域信息
信息中包括ID和Name:
sql
drop table if exists dim.dim_trade_shops_org;
create table dim.dim_trade_shops_org(
shopid int,
shopName string,
cityId int,
cityName string ,
regionId int ,
regionName string
)
partitioned by (dt string)
STORED AS PARQUET;实现方式:
sql
select T1.shopid, T1.shopname, T2.id cityid, T2.orgname
cityname, T3.id regionid, T3.orgname regionname
from
(select shopid, shopname, areaid
from ods.ods_trade_shops
where dt='2020-07-01') T1
left join
(select id, parentid, orgname, orglevel
from ods.ods_trade_shop_admin_org
where orglevel=2 and dt='2020-07-01') T2
on T1.areaid=T2.id
left join
(select id, orgname, orglevel
from ods.ods_trade_shop_admin_org
where orglevel=1 and dt='2020-07-01') T3
on T2.parentid=T3.id
limit 10;数据加载
编写脚本对数据进行加载:
shell
vim dim_load_shop_org.sh写入的内容如下所示:
shell
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dim.dim_trade_shops_org
partition(dt='$do_date')
select t1.shopid,
t1.shopname,
t2.id as cityid,
t2.orgname as cityName,
t3.id as region_id,
t3.orgname as region_name
from (select shopId, shopName, areaId
from ods.ods_trade_shops
where dt='$do_date') t1
left join
(select id, parentId, orgname, orglevel
from ods.ods_trade_shop_admin_org
where orglevel=2 and dt='$do_date') t2
on t1.areaid = t2.id
left join
(select id, parentId, orgname, orglevel
from ods.ods_trade_shop_admin_org
where orglevel=1 and dt='$do_date') t3
on t2.parentid = t3.id;
"
hive -e "$sql"商品信息表
数据处理
使用拉链表对商品信息进行处理
历史数据
历史数据 => 初始化拉链表(开始日期:当日,结束日期:9999-12-31)只执行一次
每日数据
- 新增数据:每日新增数据(ODS) => 开始日期:当日,结束日期:9999-12-31
- 历史数据:拉链表(DIM)与每日新增数据(ODS)做左连接(连接上有数据,数据有变化,结束日期变为当日。为连接上数据,数据无变化,结束日期保持不变)
创建维表
拉链表要增加两列,分别记录生效日期和失效日期
sql
drop table if exists dim.dim_trade_product_info;
create table dim.dim_trade_product_info(
`productId` bigint,
`productName` string,
`shopId` string,
`price` decimal,
`isSale` tinyint,
`status` tinyint,
`categoryId` string,
`createTime` string,
`modifyTime` string,
`start_dt` string,
`end_dt` string
) COMMENT '产品表'
STORED AS PARQUET;初始数据加载
历史数据加载,只需要执行一次
sql
insert overwrite table dim.dim_trade_product_info
select productId,
productName,
shopId,
price,
isSale,
status,
categoryId,
createTime,
modifyTime,
-- modifyTime非空取modifyTime,否则取createTime;substr取
日期
case when modifyTime is not null
then substr(modifyTime, 0, 10)
else substr(createTime, 0, 10)
end as start_dt,
'9999-12-31' as end_dt
from ods.ods_trade_product_info
where dt = '2020-07-12';增量数据导入
重复执行,每次加载数据执行,编写脚本:
shell
vim dim_load_product_info.sh写入的内容如下所示:
shell
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dim.dim_trade_product_info
select productId,
productName,
shopId,
price,
isSale,
status,
categoryId,
createTime,
modifyTime,
case when modifyTime is not null
then substr(modifyTime,0,10)
else substr(createTime,0,10)
end as start_dt,
'9999-12-31' as end_dt
from ods.ods_trade_product_info
where dt='$do_date'
union all
select dim.productId,
dim.productName,
dim.shopId,
dim.price,
dim.isSale,
dim.status,
dim.categoryId,
dim.createTime,
dim.modifyTime,
dim.start_dt,
case when dim.end_dt >= '9999-12-31' and ods.productId
is not null
then '$do_date'
else dim.end_dt
end as end_dt
from dim.dim_trade_product_info dim left join
(select *
from ods.ods_trade_product_info
where dt='$do_date' ) ods
on dim.productId = ods.productId
"
hive -e "$sql"错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| Shell 脚本执行报错,无法启动 | #!/bin/bash 写成全角 #!/bin/bash |
head -1 xxx.sh 检查首行改为半角标准 shebang |
| Hive 建表时报 decimal 语法或精度问题 | price decimal 未定义精度 |
查看建表 DDL改为 decimal(10,2) 或业务需要的精度 |
| 拉链表每天跑完后数据量异常膨胀 | 每日 union all 直接并入 ODS 全量分区数据,且旧数据未严格去重 |
对比前后分区行数、按 productId 统计版本数增加"变更判断 + 仅关闭变更旧链 + 保留未变历史"逻辑 |
| 历史链路结束日期不准确 | 当前逻辑只要连接到当天 ODS 数据就把旧链结束为当日,未判断字段是否真的变化 | 抽查同一 productId 的多版本记录先比较关键字段,再决定是否闭链 |
| 商品分类维表关联后上级分类为空 | 层级数据缺失或 parentid 对不上 |
分别单查 level=1/2/3 数据校验 ODS 分类层级完整性与父子关系 |
| 商家地域组织表字段名混乱 | SQL 中 shopid/shopId、parentid/parentId、regionId/region_id 命名不统一 |
对照 DDL 与 SELECT 字段别名统一命名风格,避免大小写与下划线混用 |
| 脚本默认日期不符合预期 | 使用 date -d "-1 day" 依赖运行环境时区与 GNU date |
手动输出 do_date 检查固定调度环境时区,脚本打印执行日期 |
| 分区表查不到数据 | insert overwrite table ... partition(dt='xxx') 写入成功但查询未带分区条件 |
show partitions 与 select * where dt=...查询时显式带 dt,并确认分区已生成 |
| 商品信息拉链初始化起始日期不稳定 | modifyTime、createTime 字段格式依赖源表字符串格式 |
抽样检查时间字段原值统一时间格式,必要时先 regexp_extract 或 to_date |
| Hive SQL 可读性差,后期维护困难 | 业务注释、字段口径、变更规则未贴近 SQL 展开 | 查看脚本与文档是否一一对应补充字段口径、变更字段清单、初始化与日常加载边界 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地 🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础! 🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解 🔗 大数据模块直达链接