摘要:本文是大模型推理优化框架vLLM深度解析系列的第一章,全面介绍vLLM的诞生背景、核心优势、生态地位,并提供Docker与pip两种部署方式的详细教程,附带最小可运行示例。通过本文,读者将掌握vLLM服务化部署的基本技能,为后续深入PagedAttention原理与性能调优打下坚实基础。
目录
- 为什么需要vLLM?
- vLLM项目全景
- [2.1 诞生背景:从UC Berkeley到行业标准](#2.1 诞生背景:从UC Berkeley到行业标准)
- [2.2 核心优势:PagedAttention与连续批处理](#2.2 核心优势:PagedAttention与连续批处理)
- [2.3 生态地位:Star数超7万,事实标准](#2.3 生态地位:Star数超7万,事实标准)
- 快速开始:两种部署方式
- [3.1 方式一:pip安装与离线推理](#3.1 方式一:pip安装与离线推理)
- [3.2 方式二:Docker部署与在线服务](#3.2 方式二:Docker部署与在线服务)
- [3.3 最小可运行示例](#3.3 最小可运行示例)
- 收获清单:你将掌握什么?
- 深入解析:PagedAttention的基本思想
- [5.1 KV Cache的显存浪费问题](#5.1 KV Cache的显存浪费问题)
- [5.2 虚拟内存分页的启发](#5.2 虚拟内存分页的启发)
- [5.3 PagedAttention的数学表达](#5.3 PagedAttention的数学表达)
- [性能对比:vLLM vs TGI vs TensorRT-LLM](#性能对比:vLLM vs TGI vs TensorRT-LLM)
- 应用场景:谁适合使用vLLM?
- 总结与展望
- 参考文献
1 为什么需要vLLM?
在大语言模型(LLM)落地的过程中,推理效率已成为制约应用规模的核心瓶颈。传统推理框架(如Hugging Face Transformers、FasterTransformer)面临两大难题:
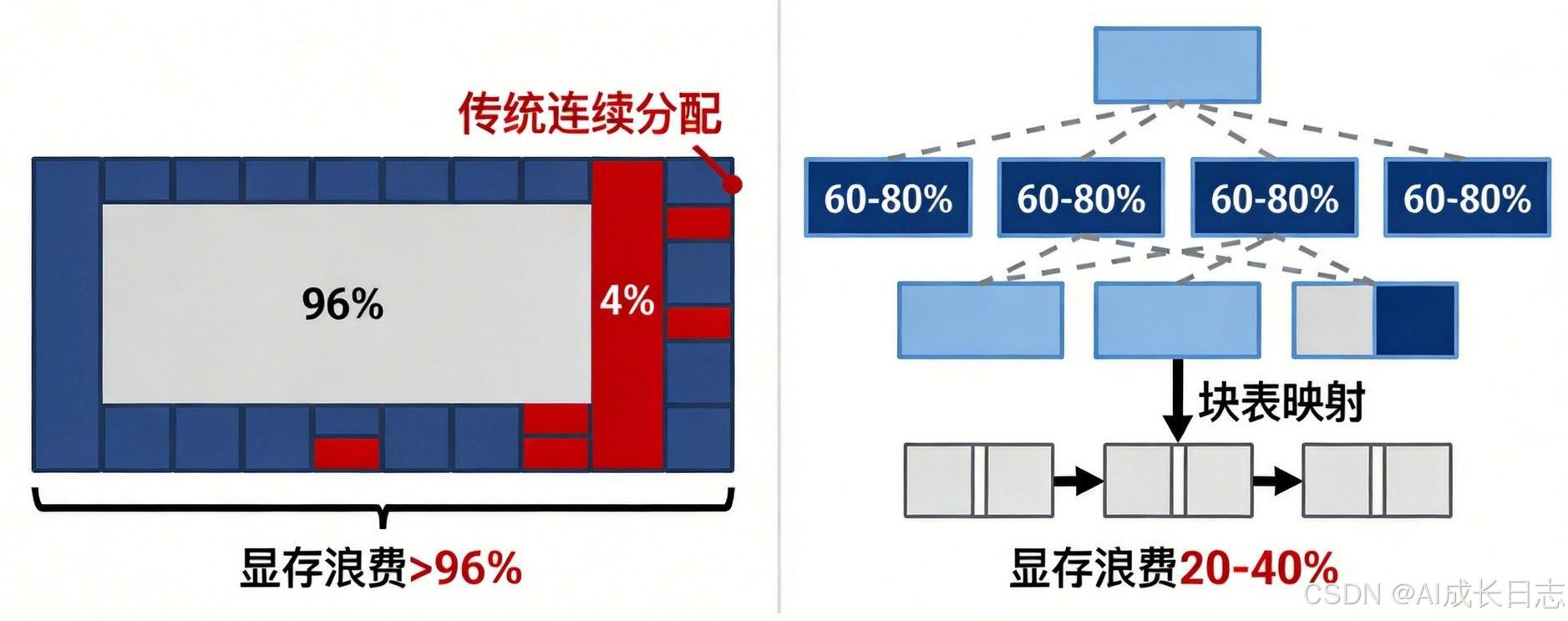
- 显存利用率低:每个请求需要预分配连续的KV Cache(键值缓存)空间,导致60%--80%的显存因碎片化和过度保留而被浪费。
- 批处理效率低:静态批处理需等待整批请求完成才能处理新请求,GPU利用率仅60%左右,无法支撑高并发场景。
以LLaMA-13B模型为例,单个序列的KV Cache可能占用1.7GB显存。若采用传统方法,一张80GB的A100显卡实际只能同时服务约15个请求------这与生产环境要求相去甚远。
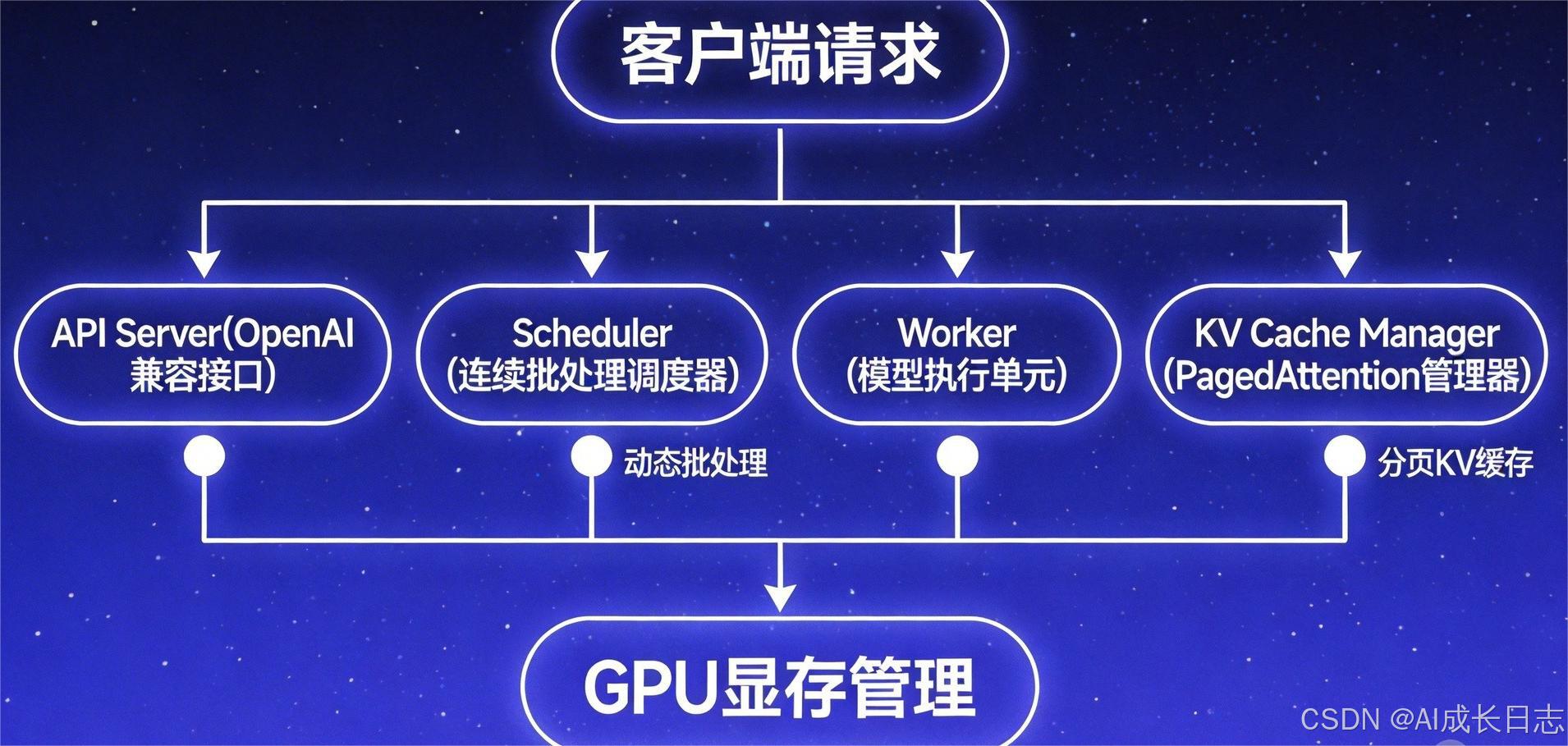
vLLM(Virtual Large Language Model)正是为解决这些问题而生。它由加州大学伯克利分校Sky Computing Lab于2023年推出,已成为高性能LLM推理的事实标准 。其核心创新是PagedAttention (分页注意力)与连续批处理 (Continuous Batching),分别从内存管理和调度策略两个维度,实现了2--4倍的吞吐量提升 与接近100%的显存利用率。
2 vLLM项目全景
2.1 诞生背景:从UC Berkeley到行业标准
vLLM起源于UC Berkeley Sky Computing Lab的研究项目,旨在解决大模型推理中的内存瓶颈问题。2023年,团队发表论文《Efficient Memory Management for Large Language Model Serving with PagedAttention》,首次提出PagedAttention算法,将操作系统中的虚拟内存分页思想迁移至KV Cache管理。
项目于2023年中开源,迅速获得社区关注。截至2026年3月,vLLM在GitHub上的Star数已突破7.2万 ,成为最活跃的LLM推理项目之一。其已被AWS、阿里云、Databricks 等云厂商集成,并作为核心组件服务于LMSYS Chatbot Arena、Perplexity等高流量应用。
2.2 核心优势:PagedAttention与连续批处理
vLLM的核心优势源于两项关键技术:
PagedAttention:显存碎片消除的工程魔法
传统方法为每个请求分配一块连续显存,如同为每个人分配一整间房,即使只住一人也要占用全部空间。PagedAttention将KV Cache切分为固定大小的"页"(默认16个Token/页),按需分配,不同请求可共享相同的前缀页(如系统提示词)。
- 显存浪费从60--80%降至<4%
- 支持动态增长:对话越长,自动加页
- 内存共享:并行采样、束搜索场景下内存节省最高达66.3%
连续批处理:高并发下的吞吐优化策略
传统静态批处理需等待一批请求全部完成,如同公交车必须坐满20人才发车。vLLM的连续批处理实现动态调度:请求完成后立即腾出位置给新请求,GPU始终满负荷运转。
- 吞吐量提升10--30倍
- P99延迟显著降低
- 支持优先级队列:区分实时交互与后台任务
2.3 生态地位:Star数超7万,事实标准
与同类框架相比,vLLM在性能、易用性、生态兼容性三个维度取得了最佳平衡:
| 特性 | vLLM | TGI(Text Generation Inference) | TensorRT-LLM | Ollama |
|---|---|---|---|---|
| 吞吐量(tok/s) | 1000--2000(A100) | 800--1500 | 2500--4000+ | 低--中 |
| 硬件兼容性 | NVIDIA、AMD、Intel、TPU | NVIDIA优先 | 仅限NVIDIA | 跨平台 |
| OpenAI兼容API | ✅ 原生支持 | ✅ 支持 | ✅ 需额外封装 | ✅ 支持 |
| 部署复杂度 | 低 | 中 | 高 | 极低 |
| 生产级特性 | 高 | 高(内置监控) | 极高(极致性能) | 低 |
| 社区活跃度 | ⭐ 7.2万+ | ⭐ 2.8万+ | ⭐ 6.6万+ | ⭐ 160万+ |
关键结论:
- vLLM:通用生产环境首选,平衡性能与易用性
- TensorRT-LLM:极致性能追求,适合NVIDIA专有环境
- TGI:HuggingFace生态深度集成,长提示处理优势明显
- Ollama:本地快速原型,部署门槛最低
3 快速开始:两种部署方式
本节提供pip安装 与Docker部署两种方式,适配不同场景。无论你是开发者初次体验,还是运维人员准备生产部署,都能找到合适路径。
3.1 方式一:pip安装与离线推理
环境准备
- 操作系统:Linux(Ubuntu 20.04+)
- Python:3.10--3.12(推荐3.10)
- CUDA:11.8+(推荐12.1)
- GPU:NVIDIA GPU,显存≥16GB(如RTX 4090、A100)
安装步骤
bash
# 创建虚拟环境(推荐使用conda)
conda create -n vllm python=3.10 -y
conda activate vllm
# 安装vLLM(自动适配CUDA版本)
pip install vllm
# 验证安装
python -c "import vllm; print(vllm.__version__)"如果输出版本号(如0.7.3),则安装成功。
离线推理示例
创建Python脚本offline_inference.py:
python
from vllm import LLM, SamplingParams
# 定义采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.95,
max_tokens=512
)
# 初始化LLM引擎(加载Qwen2.5-7B-Instruct)
llm = LLM(model="Qwen/Qwen2.5-7B-Instruct")
# 输入提示列表
prompts = [
"请用一句话解释什么是人工智能:",
"写一首关于春天的五言绝句:",
"解释深度学习与机器学习的区别:"
]
# 批量推理
outputs = llm.generate(prompts, sampling_params)
# 输出结果
for i, output in enumerate(outputs):
print(f"提示 {i+1}: {prompts[i]}")
print(f"生成文本: {output.outputs[0].text}")
print("-" * 50)运行脚本:
bash
python offline_inference.py你将看到模型生成的文本输出。
3.2 方式二:Docker部署与在线服务
Docker安装
确保系统已安装Docker和NVIDIA Container Toolkit:
bash
# 安装Docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
# 安装NVIDIA Container Toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker启动vLLM服务
使用官方Docker镜像启动OpenAI兼容API服务器:
bash
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 \
--port 8000参数说明:
--gpus all:使用所有可用GPU-v ~/.cache/huggingface:/root/.cache/huggingface:挂载模型缓存目录--ipc=host:共享内存,支持张量并行--model:指定模型名称(支持HuggingFace Hub或本地路径)
验证服务
bash
# 查看可用模型
curl http://localhost:8000/v1/models
# 测试Chat Completion
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct",
"messages": [
{"role": "user", "content": "你好,请介绍一下自己。"}
],
"max_tokens": 100,
"temperature": 0.7
}'如果返回JSON格式的生成结果,则服务运行正常。
3.3 最小可运行示例
如果你希望用最少的步骤验证vLLM功能,以下是最精简的示例:
步骤1:安装vLLM
bash
pip install vllm步骤2:运行交互式推理
python
from vllm import LLM
llm = LLM(model="Qwen/Qwen2.5-1.5B-Instruct") # 使用更小的模型快速启动
output = llm.generate(["人工智能是什么?"])
print(output[0].outputs[0].text)步骤3:启动最小API服务
bash
vllm serve Qwen/Qwen2.5-1.5B-Instruct --port 8000然后用浏览器访问http://localhost:8000/v1/models,确认服务已启动。
4 收获清单:你将掌握什么?
通过本章学习,你将具备以下能力:
-
vLLM全景认知:
- 理解vLLM的诞生背景与设计哲学
- 掌握PagedAttention与连续批处理的核心思想
- 了解vLLM在LLM推理生态中的定位
-
部署实战技能:
- 掌握pip安装与虚拟环境配置
- 掌握Docker部署与容器化服务启动
- 能够启动OpenAI兼容API服务并验证
-
基础应用能力:
- 编写离线批量推理脚本
- 调用Chat Completion接口
- 根据需求选择合适部署方式
-
性能对比分析:
- 理解vLLM与TGI、TensorRT-LLM的优劣势
- 根据业务场景选择推理框架
这些能力是后续深入PagedAttention原理、性能调优、生产部署的基础。
5 深入解析:PagedAttention的基本思想
作为第二章的铺垫,本节简要介绍PagedAttention的核心原理。详细数学推导与工程实现将在下一章展开。
5.1 KV Cache的显存浪费问题
在自回归生成中,每个Token都需要计算其与之前所有Token的注意力得分。为了避免重复计算,Transformer模型会缓存每个Token的Key向量和Value向量(KV Cache)。
传统KV Cache管理面临两大问题:
- 外部碎片:每个请求分配连续显存,请求长度不一导致显存块之间留下无法利用的空隙
- 内部碎片:按最大序列长度预分配,实际使用不足造成浪费
数学上,传统方法需要为每个序列 s i s_i si预分配长度为 L m a x L_{max} Lmax的KV缓存矩阵 K i ∈ R L m a x × d k , V i ∈ R L m a x × d v K_i \in \mathbb{R}^{L_{max} \times d_k}, V_i \in \mathbb{R}^{L_{max} \times d_v} Ki∈RLmax×dk,Vi∈RLmax×dv,实际使用仅为 l i ≤ L m a x l_i \leq L_{max} li≤Lmax个Token,浪费比例为:
Waste = 1 − ∑ i = 1 N l i N ⋅ L m a x \text{Waste} = 1 - \frac{\sum_{i=1}^{N} l_i}{N \cdot L_{max}} Waste=1−N⋅Lmax∑i=1Nli
当 L m a x = 4096 L_{max}=4096 Lmax=4096、平均序列长度 l a v g = 512 l_{avg}=512 lavg=512时,浪费高达87.5%。
5.2 虚拟内存分页的启发
操作系统通过虚拟内存分页解决物理内存碎片问题:将逻辑地址空间划分为固定大小的页,物理内存中建立页表映射,允许非连续存储。
PagedAttention借鉴这一思想:
- KV块:固定大小的KV缓存单元(如16个Token)
- 块表:序列逻辑块到物理块的映射表
- 按需分配:仅当序列需要新Token时才分配物理块
5.3 PagedAttention的数学表达
传统注意力计算中,第 i i i个Token的输出向量 o i o_i oi为:
o i = ∑ j = 1 i exp ( q i ⊤ k j / d ) ∑ t = 1 i exp ( q i ⊤ k t / d ) v j o_i = \sum_{j=1}^{i} \frac{\exp(q_i^\top k_j / \sqrt{d})}{\sum_{t=1}^{i} \exp(q_i^\top k_t / \sqrt{d})} v_j oi=j=1∑i∑t=1iexp(qi⊤kt/d )exp(qi⊤kj/d )vj
其中 q i q_i qi为查询向量, k j , v j k_j, v_j kj,vj为Key-Value向量。
PagedAttention将KV缓存按块分组,设块大小为 B B B,则第 j j j个键值块为:
K j = k ( j − 1 ) B + 1 , ... , k j B ∈ R B × d k , V j = v ( j − 1 ) B + 1 , ... , v j B ∈ R B × d v K_j = k_{(j-1)B+1}, \\ldots, k_{jB} \in \mathbb{R}^{B \times d_k}, \quad V_j = v_{(j-1)B+1}, \\ldots, v_{jB} \in \mathbb{R}^{B \times d_v} Kj=k(j−1)B+1,...,kjB∈RB×dk,Vj=v(j−1)B+1,...,vjB∈RB×dv
注意力计算转化为块级并行:
o i = ∑ j = 1 ⌈ i / B ⌉ V j ⋅ exp ( q i ⊤ K j / d ) ∑ t = 1 ⌈ i / B ⌉ exp ( q i ⊤ K t / d ) ⊤ o_i = \sum_{j=1}^{\lceil i/B \rceil} V_j \cdot \frac{\exp(q_i^\top K_j / \sqrt{d})}{\sum_{t=1}^{\lceil i/B \rceil} \exp(q_i^\top K_t / \sqrt{d})}^\top oi=j=1∑⌈i/B⌉Vj⋅∑t=1⌈i/B⌉exp(qi⊤Kt/d )exp(qi⊤Kj/d )⊤
通过块表索引非连续物理块,计算时无需拼接完整KV Cache,兼顾效率与灵活性。
6 性能对比:vLLM vs TGI vs TensorRT-LLM
基于2025--2026年的公开基准测试,三大推理框架的性能对比如下:
吞吐量(Tokens/Second)
| 模型 | vLLM | TGI | TensorRT-LLM |
|---|---|---|---|
| LLaMA-7B | 15,243 | 4,156 | 18,500 |
| LLaMA-13B | 8,934 | 3,187 | 10,200 |
| LLaMA-70B(4×GPU) | 3,245 | 1,544 | 4,100 |
关键发现:
- vLLM在7B模型上比TGI快3.67倍,优势随模型减小、并发增加而扩大
- TensorRT-LLM在极致优化下比vLLM快20--30%,但部署复杂度高
- TGI在长提示(>200k tokens)场景下通过前缀缓存实现13倍加速,针对聊天优化
延迟(Time to First Token)
| 并发数 | vLLM(ms) | TGI(ms) | TensorRT-LLM(ms) |
|---|---|---|---|
| 1 | 50--100 | 30--60 | 10--30 |
| 25 | 80--150 | 60--120 | 30--80 |
| 100 | 150--300 | 200--400 | 100--250 |
延迟特征:
- TensorRT-LLM:极致低延迟,适合交互式应用
- TGI:平衡延迟与吞吐,生产环境稳定
- vLLM:高并发下延迟可控,适合批量处理
显存利用率
| 框架 | 显存浪费率 | 并发提升倍数 |
|---|---|---|
| vLLM(PagedAttention) | <4% | 2--4× |
| TGI(传统分配) | 20--40% | 基准 |
| TensorRT-LLM(量化+分页) | 5--15% | 1.5--3× |
选择建议:
- 追求极致性能:TensorRT-LLM(NVIDIA专属环境)
- 生产部署平衡:vLLM(通用场景,高吞吐)
- 长对话优化:TGI(聊天应用,前缀缓存)
- 快速原型:Ollama(本地体验)
7 应用场景:谁适合使用vLLM?
vLLM的定位决定了它在不同场景下的适用性:
企业AI服务部署
- 优势:OpenAI兼容API + 高并发 + 分布式支持
- 典型场景:替代商业API服务,构建私有化大模型平台
- 案例:阿里云Aegaeon方案、AWS SageMaker集成
AI研究实验
- 优势:快速评估不同模型,批量推理效率高
- 典型场景:模型对比、消融实验、性能基准测试
- 案例:LMSYS Chatbot Arena每日处理30K+对话
独立开发者项目
- 优势:一行pip安装,几行代码启动服务
- 典型场景:个人博客AI助手、小型商业应用
- 案例:基于vLLM搭建的本地知识问答系统
本地大模型玩家
- 优势:量化支持好,有限显存也能跑大模型
- 典型场景:消费级显卡运行70B模型
- 案例:RTX 4090运行LLaMA-3-70B(INT4量化)
云服务提供商
- 优势:多GPU并行 + Multi-LoRA支持
- 典型场景:一套服务多个租户,高资源利用率
- 案例:Together.AI的共享推理集群
8 总结与展望
本章作为vLLM深度解析系列的开篇,完成了以下任务:
- 全景介绍:从vLLM的诞生背景到生态地位,建立完整认知框架
- 快速入门:提供pip与Docker两种部署方式,附带最小可运行示例
- 技术铺垫:简要解析PagedAttention核心思想,为第二章深入原理做准备
- 决策参考:对比vLLM、TGI、TensorRT-LLM性能特征,指导框架选型
vLLM的核心价值可总结为:
- 技术突破:PagedAttention解决KV Cache显存浪费问题
- 工程实践:连续批处理实现高GPU利用率
- 生态兼容:OpenAI API协议降低迁移成本
- 生产就绪:分布式、量化、监控等企业级特性
未来演进方向:
- 跨节点调度:扩展至多机推理,支持万亿参数模型
- 异构计算:整合CPU/GPU/NPU混合推理管道
- 自适应量化:动态精度切换平衡质量与效率
- 安全与隐私:同态加密、可信执行环境集成
在后续章节中,我们将深入:
- 第二章:PagedAttention原理深度拆解------显存碎片消除的工程魔法
- 第三章:连续批处理与调度器------高并发下的吞吐优化策略
- 第四章:模型量化与适配实战------LLaMA、Qwen、Yi主流模型部署
- 第五章:高级特性剖析------多GPU并行、LoRA加载、流式输出
- 第六章:性能调优指南------从基准测试到生产级部署
- 第七章:真实案例------搭建企业级大模型API服务
9 参考文献
- vLLM官方文档:https://docs.vllm.ai
- GitHub仓库:https://github.com/vllm-project/vllm
- PagedAttention论文:Kwon et al., "Efficient Memory Management for Large Language Model Serving with PagedAttention", 2023
- 连续批处理研究:Yu et al., "Orca: A Distributed Serving System for Transformer-Based Generative Models", 2022
- TensorRT-LLM技术报告:NVIDIA, "TensorRT-LLM: A High-Performance Inference Library for Large Language Models", 2025
- TGI v3长提示优化:HuggingFace, "Text Generation Inference v3: Chunking and Prefix Caching for Long Contexts", 2025
- 性能基准测试:LMSYS, "Chatbot Arena: Benchmarking LLM Serving Systems", 2026
- 量化技术综述:Yao et al., "A Survey of Quantization Methods for Efficient Neural Network Inference", 2024