1. TCN 的三大核心支柱
TCN 之所以能替代 LSTM,主要依靠以下三个技术点:
A. 因果卷积 (Causal Convolutions)
工业预测的核心原则是"不能利用未来信息"------预测 t 时刻的设备状态、传感器数值,只能依赖 t 时刻及之前的历史数据,任何未来信息的泄露都会导致预测结果失去实际工程价值。
实现方式: 在 CausalConv1d 中,通过在左侧填充 (kernel_size - 1) * dilation 个零,确保卷积核的覆盖范围仅包含当前及过去的输入;随后在输出时切掉末尾的填充部分,从根本上杜绝未来信息泄露,严格遵循时序因果性。
B. 空洞卷积 (Dilated Convolutions)
工业时序数据往往包含数百甚至数千个时间步(如高频传感器每秒采集1次数据,1小时就是3600个时间步),若仅用普通卷积,需要堆叠极多层数才能覆盖足够的历史信息,这会导致模型参数量暴增、训练不稳定。
TCN 使用空洞卷积(又称膨胀卷积)解决这一问题:
| 特性 | 说明 |
|---|---|
| 感受野 (Receptive Field) | 感受野随层数 i 以 2ⁱ 指数级增长,无需堆叠过多层数,就能快速覆盖超长历史序列 |
| 公式 | 代码中的 self._rf 计算了完整的感受野范围,这对于确定输入序列长度(Look-back Window)至关重要------工业场景中,必须确保输入序列长度不小于模型感受野,否则模型无法捕捉足够的历史特征 |
C. 残差连接 (Residual Connections)
为了覆盖更长的历史序列,TCN 通常需要堆叠多个卷积层,而深层卷积网络容易出现梯度退化、训练困难的问题,这在工业场景中会导致模型无法收敛,或收敛后泛化能力极差。
实现: TemporalBlock 中引入了 self.skip(残差连接)。如果输入输出通道数不一致,使用 1×1 卷积进行维度对齐,确保恒等映射的顺畅,让梯度能够直接从输出层传递到输入层,有效缓解梯度退化问题,保证深层网络的训练稳定性。
2. 代码实现深度分析
核心模块:CausalConv1d
因果卷积是 TCN 保证时序因果性的核心,其 forward 方法的关键设计是"填充-切除"逻辑:
python
def forward(self, x):
out = self.conv(x)
# 关键:切除多余的 padding 保证因果性
return out[:, :, :-self.pad] if self.pad > 0 else out重要设计细节: 使用 weight_norm(权重归一化),而非工业场景中常见的 BatchNorm。
在处理工业长序列数据时,BatchNorm 会依赖批次数据的均值和方差,而工业数据的批次波动较大(如不同设备、不同工况的数据差异),容易导致归一化偏差;而 weight_norm 直接对卷积核权重进行归一化,不依赖批次数据,能有效加速模型收敛,同时起到一定的正则化作用,避免神经元坏死,比 BatchNorm 更稳定、更适配工业长时序场景。
工业回归头设计
对于工业回归任务(如 RUL 预测、传感器数值预测),代码采用了一套非常简洁且贴合工业场景的回归头设计,核心优势是**"适配工业物理量的大范围波动"**:
| 设计特点 | 工程意义 |
|---|---|
| 纯线性输出 | self.head = nn.Linear(...),未添加任何复杂的非线性激活层 |
| 无激活约束 | 最后一层不加 ReLU 或 Sigmoid,避免输出被限制在固定范围------工业物理量(如温度、压力、设备寿命)的波动范围极大,激活层会导致梯度在边界饱和,影响预测精度 |
| Scaler 控制 | 目标值的范围完全交给数据预处理阶段的 Scaler(如 StandardScaler 或 MinMaxScaler)。这种设计将"数值缩放"与"模型预测"解耦,既简化了模型结构,又能灵活适配不同工业场景的数值范围,同时避免梯度饱和问题 |
3. 进阶:TCN + Attention 混合架构
虽然 TCN 通过空洞卷积获得了巨大的感受野,能捕捉长程依赖,但它对所有历史信息的权重分配相对固定------工业场景中,不同历史时刻的特征重要性不同(如设备大修周期的特征比日常运行特征更重要),固定权重无法精准捕捉这种动态关联。
TCNAttn 类引入了 多头自注意力 (Multi-head Self-Attention),实现"局部特征+全局关联"的双路特征捕捉:
python
class TCNAttn(TCN):
def forward(self, x):
# TCN 提取局部特征,维度转换适配 Attention 输入
h = self.network(x.transpose(1, 2)).transpose(1, 2) # [B, T, C]
# 自注意力计算:动态分配历史特征权重
a, _ = self.attn(h, h, h) # 自注意力计算
# 残差融合 + LayerNorm:稳定训练,强化特征
h = self.norm(h + a) # 残差加 LayerNorm
# 末端决策:取最后一个时间步,聚合全局加权特征
return self.head(h[:, -1, :])为什么这样组合?(工业场景视角)
-
TCN 提取局部特征: 卷积天生擅长提取短程的趋势、周期等局部特征(Local Patterns),比如设备温度的缓慢上升趋势、振动信号的周期性波动,这些都是工业时序数据的核心局部特征
-
Attention 捕捉全局关联: 在 TCN 提取的高维特征基础上,Attention 可以动态地关注到历史中最重要的时刻------例如,设备去年的同一个大修周期、过去出现过的异常前兆特征,这些全局关联信息对工业预测(如 RUL、异常预警)至关重要
-
末端决策高效:
h[:, -1, :]取最后一个时间步,聚合了整个序列经过注意力加权后的信息,进行最终回归,既保证了决策的精准性,又简化了输出逻辑,适配工业实时预测的需求
4. 如何配置与使用
为了适配工业场景的多任务需求(如不同传感器、不同预测目标),代码中设计了 build_tcn 工厂函数,可灵活在基础版 TCN 和 Attention 增强版 TCN 之间切换,无需修改核心代码,工程化适配性极强:
python
cfg = {
"model_type": "tcn_attn", # 或 "tcn",切换基础版/增强版
"input_size": 12, # 特征数 (如压力、温度、转速等工业传感器特征)
"output_size": 1, # 预测目标 (如 RUL、下一秒温度)
"num_channels": [32, 64, 128], # 每一层的通道数,控制模型复杂度
"kernel_size": 3, # 卷积核大小,建议3或5,平衡感受野与参数量
"dropout": 0.2 # 正则化,适配工业数据噪声大的特点
}
model = build_tcn(cfg)
print(f"当前模型感受野: {model.receptive_field}") # 查看感受野,匹配输入序列长度💡 配置小贴士: 工业场景中,建议先根据业务需求确定输入序列长度,再通过调整
num_channels(层数)和kernel_size,确保model.receptive_field略大于输入序列长度,保证模型能利用完整的历史信息。
5. 总结与建议
TCN 凭借因果卷积、空洞卷积和残差连接三大核心支柱,解决了 RNN/LSTM 在工业时序回归中的痛点,而结合 Attention 机制的增强版 TCN,进一步弥补了 TCN 权重分配固定的不足,成为当前处理中长时序预测问题的有力武器。
在实际工业部署中,建议遵循以下原则,确保模型的稳定性和预测精度:
| 原则 | 说明 |
|---|---|
| 感受野匹配 | 确保 receptive_field 略大于你的输入序列长度,否则网络无法利用完整的输入信息,导致预测精度下降 |
| 权重初始化 | 代码中使用了 xavier_uniform_ 和 normal_ 初始化,这对深层 TCN 的起步非常关键------工业场景中模型层数较多,合理的初始化能避免梯度爆炸/消失,加速收敛 |
| 数据归一化 | 既然输出层是线性的,输入和输出的逆归一化逻辑必须严格闭环------工业数据的数值范围差异大,归一化不规范会导致预测结果偏差,甚至失去实际意义 |
TCN 证明了"卷积也能做时序",其高效的并行能力、灵活的感受野控制,完美适配工业场景的高性能、高稳定性需求,而 TCN + Attention 的混合架构,更是进一步拓宽了其在超长时序回归任务中的应用范围。
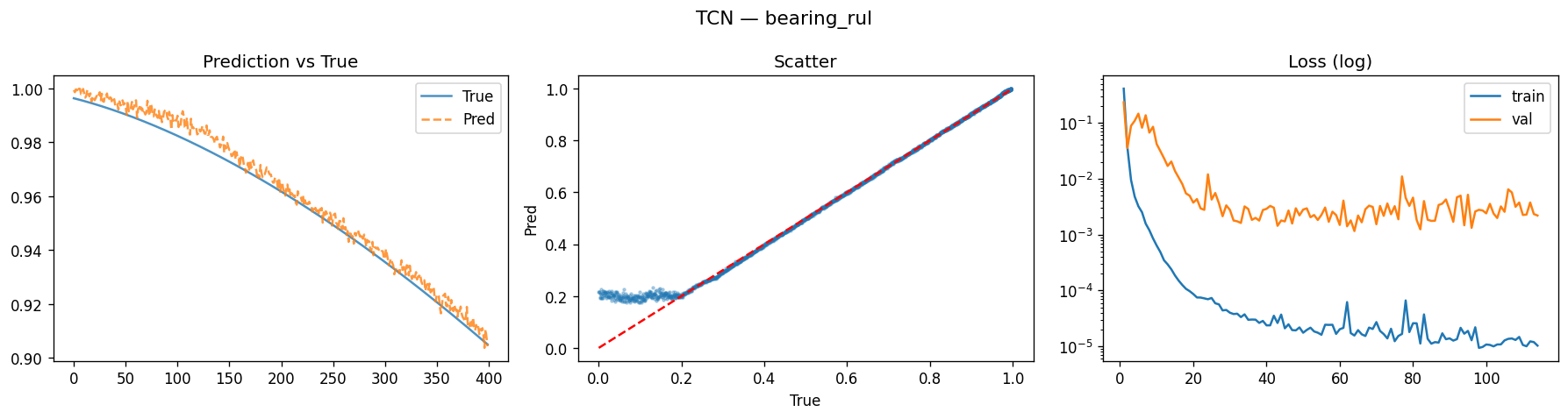
结果
bash
{
"dataset": "bearing_rul",
"loss_fn": "rul_weighted",
"best_epoch": 64,
"test_metrics": {
"MSE": 0.0017837613122537732,
"MAE": 0.0159768033772707,
"RMSE": 0.04223459852128079,
"R2": 0.9798125374643182,
"SMAPE": 10.728160291910172
}
}