
OpenClaw 的长程记忆困局
近期 OpenClaw 在开发者社区中备受瞩目。它赋予了 Agent "看见"和"操作"的能力,开启了自动化复杂任务的想象空间。
但随着交互加深,一个普遍的"上下文管理困境"也随之浮现:Agent 常常遗忘之前交代过的信息,正如一些开发者在深入体验后指出的,尽管 OpenClaw 备受赞誉,但在长期使用中,"它完全忘记了我给它的API密钥"。这种不稳定的"记忆"不仅影响了 Agent 的自主性,也暴露了当前 AI Agent 在长周期任务中管理海量、动态上下文的普遍难题。
根据社区的真实反馈和我们的深入测试,OpenClaw 原生的 memory-core 模块在处理长程任务时,存在几个核心痛点:
- 任务完成率偏低: 单次对话随着对话轮次增加,原生记忆机制难以有效支撑复杂的上下文依赖,导致记忆出错,回复结果不尽如人意。
- 记忆碎片化,检索低效: 随着使用时间增加,记忆信息记录杂乱,且是平铺式检索,在需要时难以高效、精准地检索到关键上下文。
- Token 成本激增: 为了维持记忆,原生模式需要将大量历史信息塞入上下文窗口,这直接导致输入 Token 数量爆炸式增长,使用成本居高不下。
- 跨场景协作困难: 在多会话、跨场景的协作任务中,Agent 间的记忆孤岛问题尤为突出,关键信息无法流转,导致协作失败。
这些问题共同构成了长程 Agent 落地的一道高墙。
OpenViking 的文件系统式方案
作为发布仅一个月就斩获 4.5k Github Star 的开源项目OpenViking ,已然成为社区热议的全新品类------面向AI Agent的上下文数据库,其核心价值正是为解决上下文工程中长期记忆的核心痛点而生,它并非要取代OpenClaw,而是作为其强大的"外挂记忆体",提供跨应用、跨平台、跨智能体的通用记忆和上下文能力。
OpenViking 的核心价值在于:
- "虚拟文件系统"范式: 创新地以文件系统的方式来组织和管理 Agent 的上下文,无论是记忆、资源还是技能,皆可结构化存储,告别碎片化,让用户可视化管理 Agent 记忆。
- 轻量高效,成本极低: 通过分层上下文供给和高效的检索机制,仅在必要时加载信息,从根本上解决了输入 Token 消耗巨大的问题。
- 插件化无缝集成: 作为 OpenViking Plugin,它可以轻松接入 OpenClaw,开发者无需对框架核心代码进行任何改造,即可享受强大的长程记忆能力。
简而言之,OpenViking 为 OpenClaw 提供了一个轻量、高效且低成本的"长程记忆解决方案"。
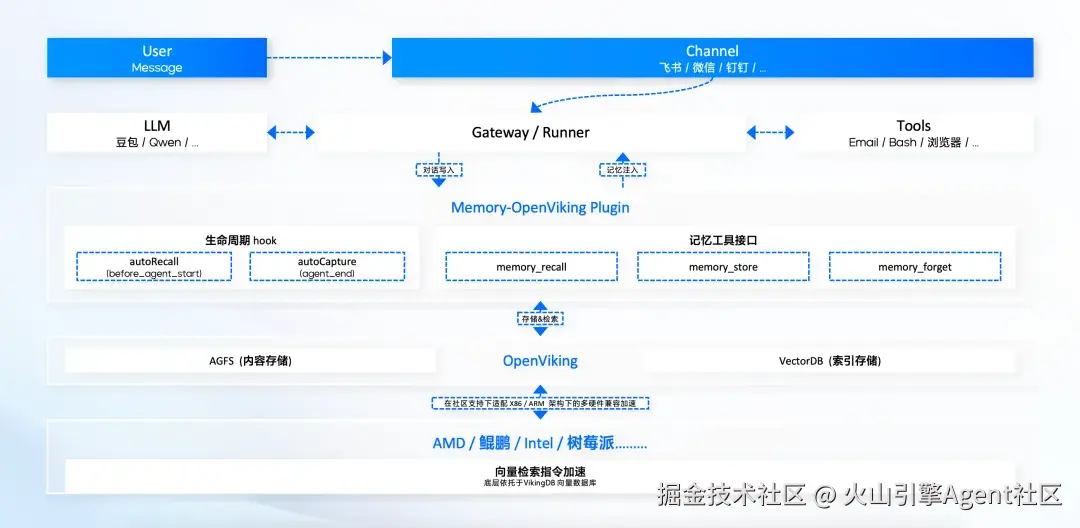
OpenViking 记忆架构
效果与成本的双重飞跃
为了量化 OpenViking 带来的提升,我们在严格控制的实验环境下,用 公开评测集进行了一场全面的对比测试。
实验环境设置:
- 测试集:LoCoMo10 (github.com/snap-resear... 1540 条有效测试用例。
- 实验组: 为帮助用户找到最佳记忆方案,我们设立了四组对照实验,涵盖了不同的记忆方案组合,包括是否启用 OpenClaw 原生的 memory-core。
- 版本信息: OpenViking 0.1.18 ,测试模型为 seed-2.0-code。
- 评测脚本: 采用开源评测脚本 ZaynJarvis/openclaw-eval (github.com/ZaynJarvis/...
实验数据对比:
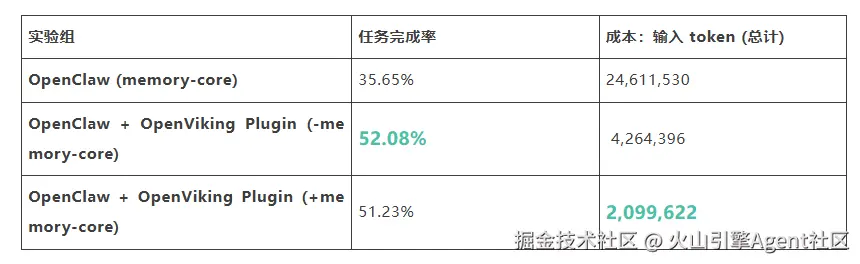
实验结论:
数据结果清晰地展示了 OpenViking 在效果 和成本上的双重、压倒性优势。
- 当开启原生记忆时(与 +memory-core 组合):
- 相较于原生 OpenClaw,任务完成率提升 43% ,而输入 token 成本剧降 91% 。
- 当关闭原生记忆时(与 -memory-core 组合):
- 相较于原生 OpenClaw,任务完成率大幅提升 49% ,输入 token 成本则降低了 83% 。
无论是否保留原生记忆,集成 OpenViking 都能为 OpenClaw 带来巨大的性能飞跃和成本节约。推荐大家保持原生开启使用,此时实际只会使用OpenViking,memory-core 是关闭的,但OpenClaw原生的一些优化策略会让成本更低,效果几乎无影响。
从"健忘"到"过目不忘"
我们模拟真实用户在使用 OpenClaw的过程中,集成 OpenViking 前后的效果对比,帮助大家感知 OpenViking 的优势和价值。
优势一:日常 Skill 使用经验沉淀为记忆,提升任务效率
场景: 销售小王日常会用通过 OpenClaw 调用销售数据库的检索 Skill 查询全国销售结果,用来分析产品数据。
- 原生 OpenClaw 反复犯错: OpenClaw 在调用"查询公司内部销售数据库"的 Skill 时,每次都会犯同样的错误(如参数格式不对、缺少鉴权信息等),需要经过多次报错、试错才能勉强完成任务。而每次开启新对话,它都会把以前犯过的错再犯一遍。
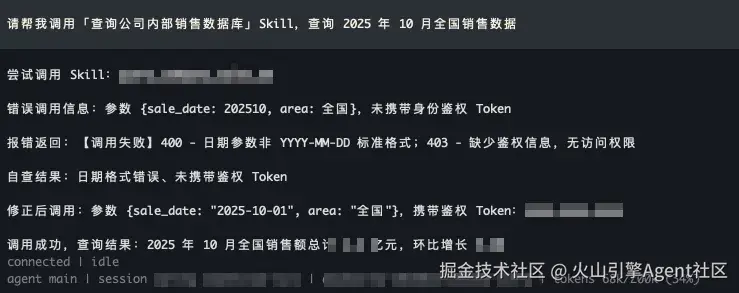
原生 OpenClaw:第一次调用 Skill
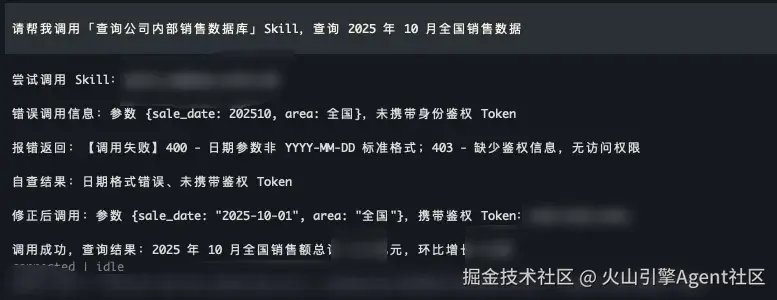
原生 OpenClaw:再次调用 Skill 出同样错误
- 结合 OpenViking 越用越熟练: OpenViking 为 OpenClaw 引入了针对特定资源的经验记忆机制 。当 OpenClaw 第一次成功使用某个 Skill 或克服某个工具的"坑"之后,OpenViking 会自动总结出"避坑指南"(如:该 API 时间参数必须是 ISO 格式),并将其作为该 Skill 的专属上下文记忆存储起来。 下次调用时,OpenClaw 会自动检索并加载这份"经验记忆",指导自己避开雷区,实现一次性精准调用,大幅降低了推理成本和工具报错率。
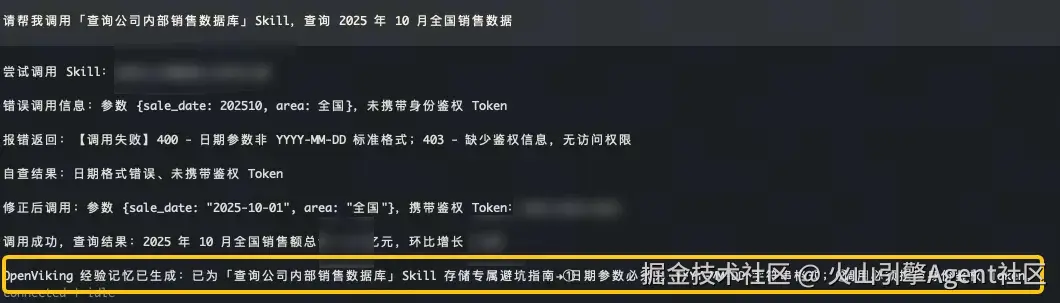
结合 OpenViking:第一次调用 Skill,经验记忆生成
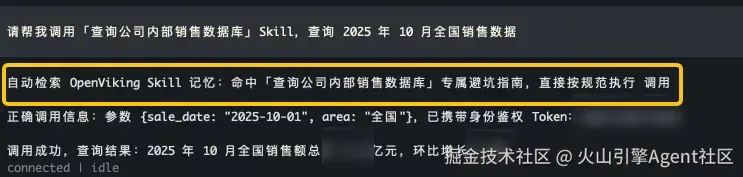
结合 OpenViking:再次调用能正确引用skill记忆,直接完成任务
优势二:长程对话下的核心信息不丢失,保持记忆稳定
场景: 小杨会为 OpenClaw 定义工作目标,和 OpenClaw 进行各类主题的长周期对话后,让其围绕目标进行总结。
- 原生 OpenClaw 金鱼记忆: 小杨在进行各种主题超过一百轮对话后,OpenClaw 开始遗忘最初设置的工作目标,导致回答不够聚焦,无法产生价值。

原生 OpenClaw:第一次对话同步目标
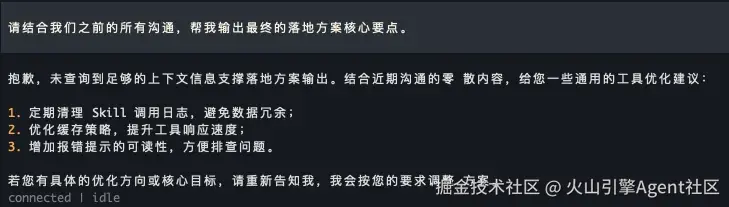
原生 OpenClaw:100轮对话后,无法围绕工作目标输出核心要点,记忆遗忘
- 结合 OpenViking 越用越懂你: OpenClaw 能够始终记住对话的核心上下文。即使在百轮对话后,依然能准确调用最初设定的目标,并结合过程中的新信息进行推理,准确写出了我们在开头希望它明确的核心指标,表现出优异的"记忆一致性"。

结合 OpenViking:第一次对话同步目标

结合 OpenViking:100轮对话后,仍能记住长期目标并给出要点,记忆稳定
优势三:多 OpenClaw 共享统一用户记忆,实现高效协同
场景: 研究生小李在本地部署了多个 OpenClaw 实例,由主 OpenClaw 负责调度决策,设实验助手、代码助手、训练助手三个子 OpenClaw,仅主 OpenClaw 有 gateway 权限。小李希望所有助手都能 "读懂" 他完整的研究过程,本地各 OpenClaw 记忆安全互通,无需手动同步,实现一站式科研。
- 原生 OpenClaw 表现: 本地部署的多 OpenClaw 记忆独立存储,无法自动感知彼此的对话与成果。主 OpenClaw 调度训练助手执行任务时,仍需小李手动复制和实验助手理清的实验思路、和代码助手迭代的脚本文件,交给训练助手重新理解,产生重复性工作,还可能因手动操作失误,导致实验参数出错、进度延误。
- 结合 OpenViking 优化效果: 所有本地 OpenClaw 共享 OpenViking 的用户记忆目录。主 OpenClaw 可直接读取小李和其他两位助手讨论的实验思路和代码迭代记忆,将最新实验流程和脚本文件直接同步给训练助手,输入指令后,训练助手无需重复理解即可按计划开展实验,高效推进科研。
三条路径,开箱即用
心动不如行动。我们提供了三种灵活的路径,帮助不同类型的开发者将 OpenViking 的强大记忆能力集成到 OpenClaw 中,为了让各类硬件运行环境都能快速体验,OpenViking 支持了 Linux/OSX/Windows 等多种操作系统,并在社区支持下适配了 X86/ARM 架构下的 AMD/鲲鹏/英特尔/树莓派 等不同芯片的向量计算指令。
- 本地 OpenClaw 接入插件
- 适用场景: 若你是本地使用的 OpenClaw,希望快速升级 OpenViking 能力。
- 核心优势: 执行如下命令快速安装 OpenViking 插件,无需改造 OpenClaw 核心代码,即刻获得更优的长程记忆体验。
前置条件: Python >= 3.10、Node.js >= 22。脚本会自动校验这些依赖,若有缺失会给出安装指引。
ruby
curl -fsSL https://raw.githubusercontent.com/volcengine/OpenViking/main/examples/openclaw-memory-plugin/install.sh | bash- 使用特点: 安装简单,学习曲线低,是体验 OpenViking 价值的最快方式。
- 参考链接: github.com/LinQiang391...
- 火山云上版本 OpenClaw
- 适用场景: 需要稳定、可扩展环境的个人开发者或中小型团队;或者想一键直接使用的普通用户。
- 核心优势:
-对于开发者:我们直接与火山 ECS 合作,直接参考集成文档配置便可在云上使用,免去本地部署和维护的烦恼。后续也会提供预装 OpenViking 的 OpenClaw 环境,开箱即用,并使用字节自研向量库 VikingDB 让数据上云,天然支持大规模长会话和高并发场景。
-对于普通用户:我们后续将内置在 ArkClaw,可通过 ArkClaw 直接使用 OpenViking 记忆能力,更多 Claw 产品合作敬请期待。
- 使用特点: 稳定、可扩展、易于维护。
- 参考链接: www.volcengine.com/docs/6396/2...
- 基于 OpenViking 自研 类Claw产品
- 适用场景: 资深开发者、企业级研发团队,想基于 OpenViking 深度定制化自己的 Claw。
- 核心优势: 我们提供了完全基于 OpenViking 实现的类 Claw 产品的最佳实践 VikingBot,带来更全面的任务效果及更低的使用成本,开发者可参考最佳实践,基于 OpenViking 深度定制 Agent 的记忆系统,以适配高度个性化的业务场景。
- 使用特点: 架构完全可控,可扩展性强,拥有最强的可观测与自迭代能力。
- 参考链接: github.com/volcengine/...
OpenViking 的底层引擎------VikingDB 向量数据库
OpenViking 通过云端提供卓越性能服务时,底层依托VikingDB 向量数据库 大规模高性能的上下文检索服务。对于需要处理更大数据规模、寻求企业级解决方案的开发者而言,直接利用 VikingDB 向量数据库的能力是通往未来的最佳路径。 VikingDB 向量数据库具备五大核心优势:
- 内置最先进 Doubao 模型: 默认集成业界领先的 Doubao Embedding 和 Rerank 模型,从源头保证向量化和检索排序的顶尖效果。
- 兼顾语义与关键词的更强检索: 支持向量与关键词的混合检索,完美应对需要精确匹配与语义理解并存的复杂场景。
- 多模态数据嵌入: 原生支持文本、图片等多种数据格式的嵌入和检索,轻松构建多模态 AI 应用。
- 万亿级向量规模与极致成本优势: 专为海量数据设计,可承载万亿级向量,同时通过架构创新,对比传统内存方案成本可降低 75%。
- 百亿数据毫秒级检索延迟: 在提供强大扩展性的同时,依然保持业界绝对领先的性能,实现百亿数据规模下的毫秒级响应。
开源号召:共建 Agent 长程记忆新生态
OpenViking 的征程才刚刚开始,我们深知一个充满活力的社区是项目成功的基石。我们在此真诚地邀请每一位对 AI Agent 技术充满热情的开发者加入我们。
- Star & Fork 我们: 请访问我们的 GitHub 仓库 github.com/volcengine/... Star,这是对我们最大的鼓励。
- 访问我们的网站: openviking.ai,了解我们传递的理念,在您的项目中感受它带来的改变,并向我们反馈最真实的体验。
- 加入社区: 扫描下方二维码,加入我们的官方交流群,与我们和其他开发者共同探讨 Agent 的未来,分享你的洞见。
- 成为贡献者: 无论是提交一个 Issue,还是贡献一段代码 (PR),你的每一次参与都将使 OpenViking 变得更好。
火山引擎将长期投入并维护 OpenViking 项目,持续优化其与 OpenClaw 等主流框架的适配体验。让我们一起,为 Agent 插上记忆的翅膀,共同定义下一代 Agent 上下文管理的未来!


关于我们:字节跳动 Viking 团队
我们用 C 端产品的体验标准打造能够重塑企业生产力的产品和技术。在上下文工程领域具有深厚的技术积累与商业化实践,我们的愿景是提供用户友好的上下文工程产品矩阵。
我们的产品历程
- 2019 年: VikingDB 向量数据库支撑字节内部全业务大规模使用
- 2023 年: VikingDB 在火山引擎公有云售卖
- 2024 年: 推出面向开发者的产品矩阵:VikingDB 向量数据库、Viking 知识库、Viking 记忆库
- 2025 年: 打造 AI 搜索、vaka 知识助手等上层应用产品
- 2025 年 10 月: 开源 MineContext github.com/volcengine/... AI 应用探索
- 2026 年 1 月: 开源 OpenViking,为 AI Agent 提供底层上下文数据库支撑