在 MySQL 日常开发与使用中,单表查询只能满足基础的数据检索需求,实际业务场景里,数据往往分散在多张表中 ,还会涉及到复杂的条件筛选、数据聚合与嵌套查询 。复合查询 作为 MySQL 查询的核心进阶技能,涵盖多表连接、自连接、子查询、合并查询等多种操作,是处理复杂数据检索的必备能力。
一、基本查询回顾
复合查询是在单表查询的基础上延伸而来,先快速回顾单表查询的高频实操场景,涵盖条件筛选、排序、聚合函数、分组过滤等核心操作,所用示例均基于经典的 EMP 员工表。
1. 多条件组合筛选
结合逻辑运算符(and/or)与模糊查询(like)实现精准筛选,例如查询工资高于 500 或岗位为 MANAGER、且姓名首字母为大写 J 的雇员:
select * from EMP where (sal>500 or job='MANAGER') and ename like 'J%';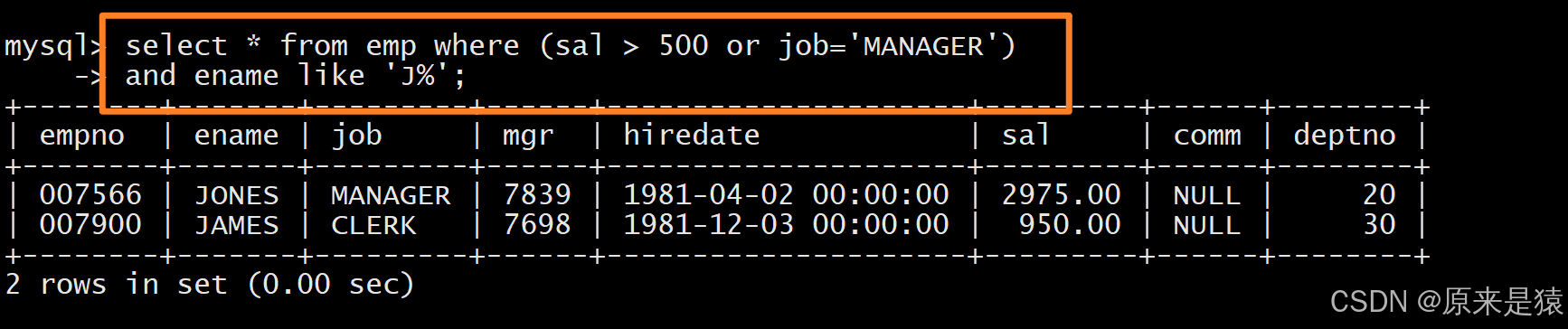
2. 多字段排序
支持按多个字段排序,指定升序(asc,默认)/ 降序(desc),例如按部门号升序、雇员工资降序排序:
select * from EMP order by deptno, sal desc;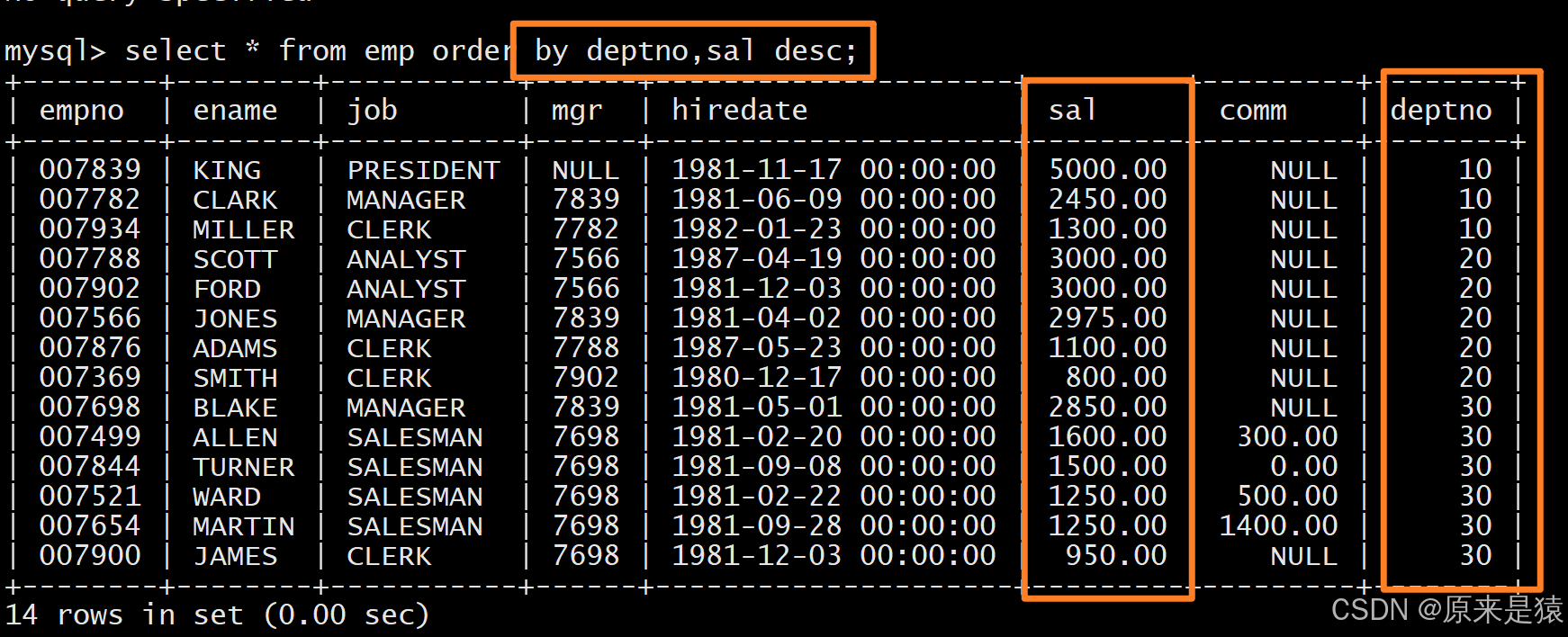
3. 计算字段与别名
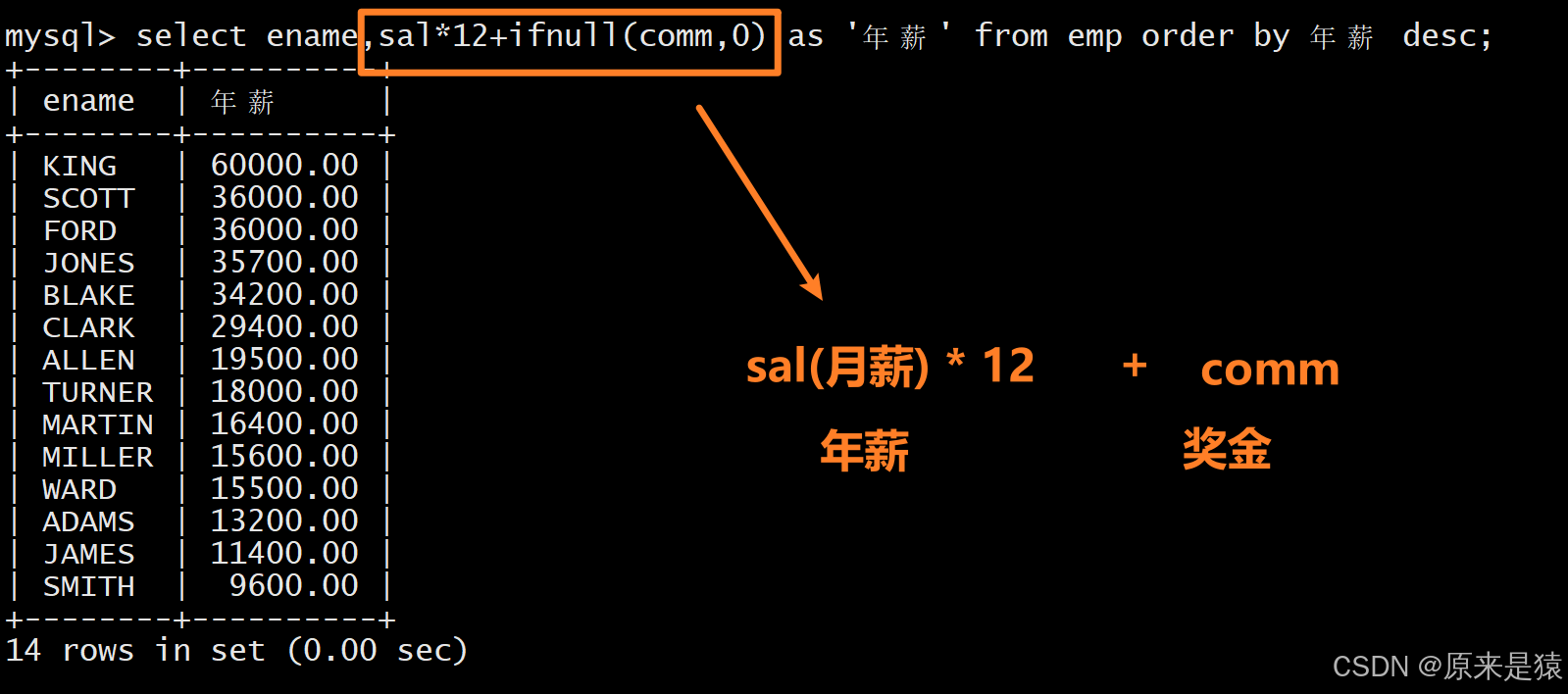
通过算术运算生成计算字段,用as指定别名,结合ifnull处理 NULL 值,例如按年薪降序排序(年薪 = 月薪 * 12 + 奖金,奖金为 NULL 时按 0 计算)
select ename, sal*12+ifnull(comm,0) as '年薪' from EMP order by 年薪 desc;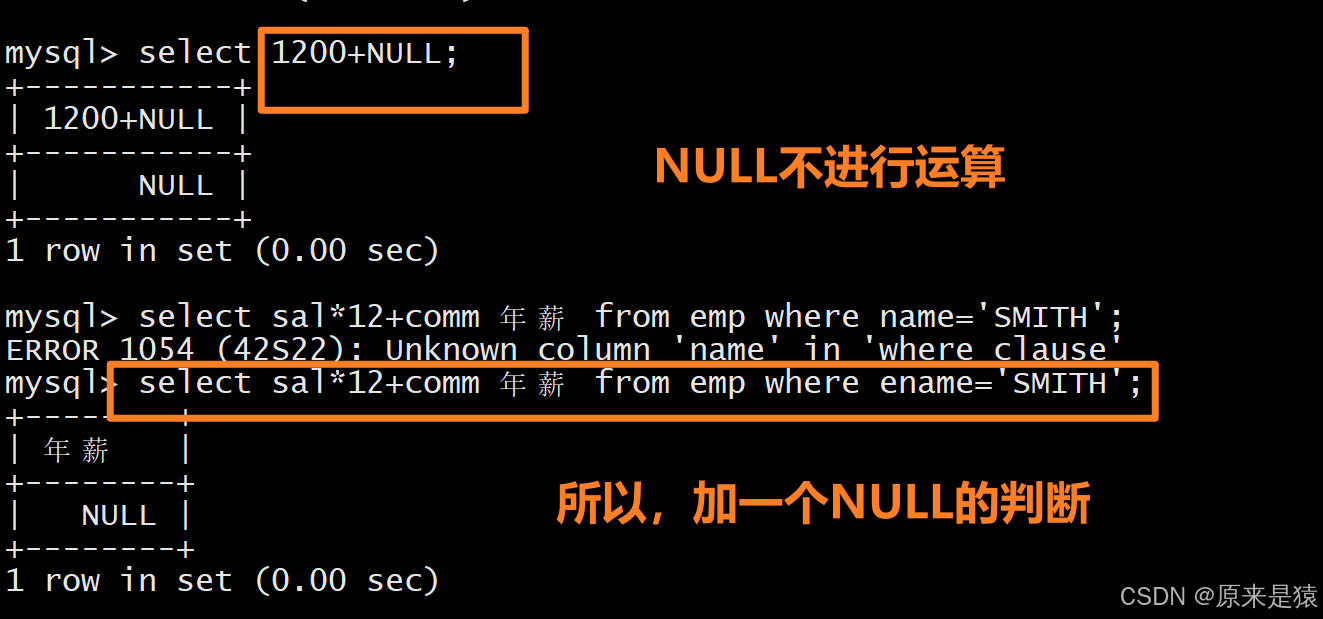
4. 聚合函数的单表应用
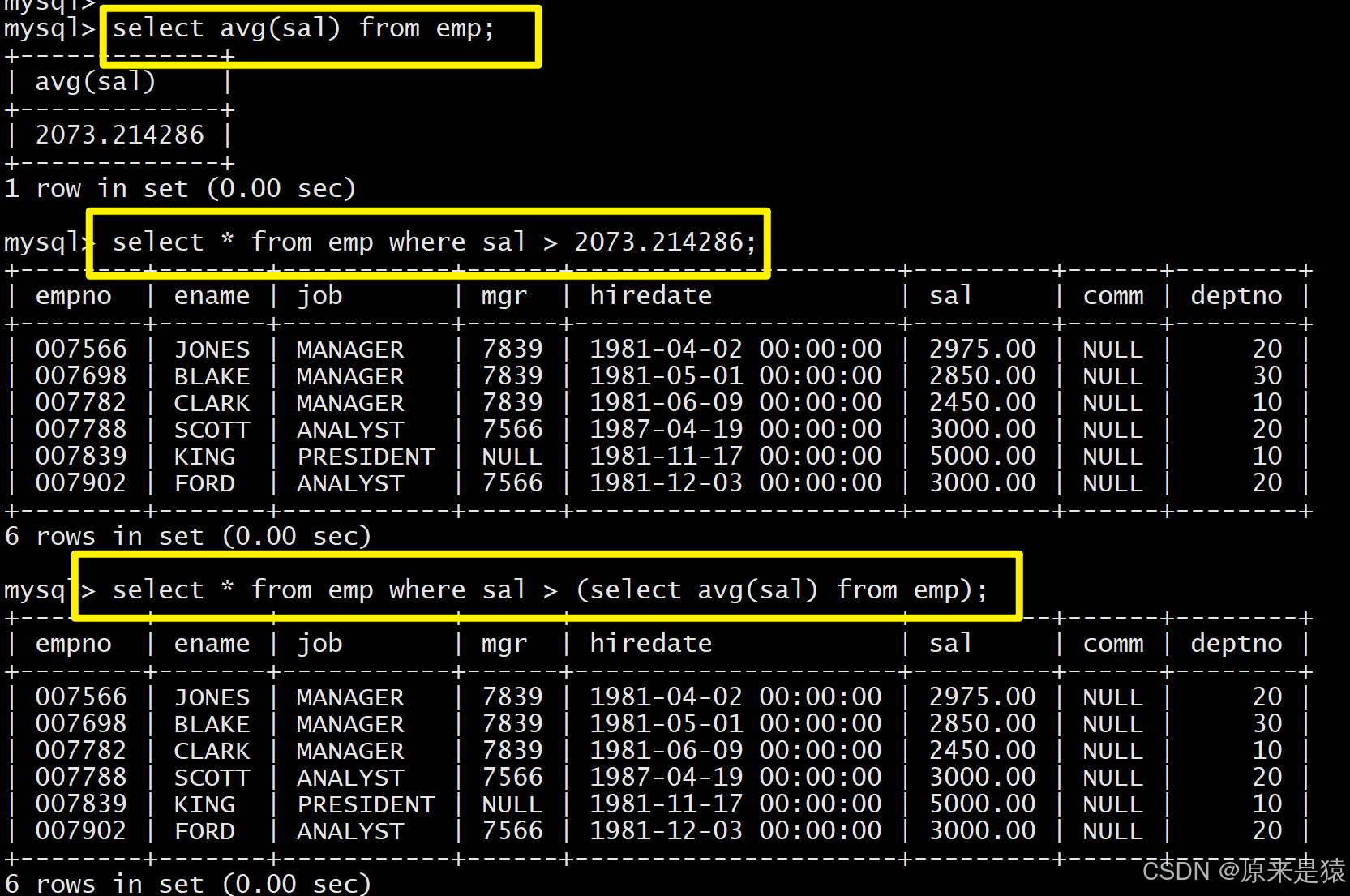
聚合函数(max/avg/count等)是数据统计的核心,常与子查询、分组结合,例如:
-
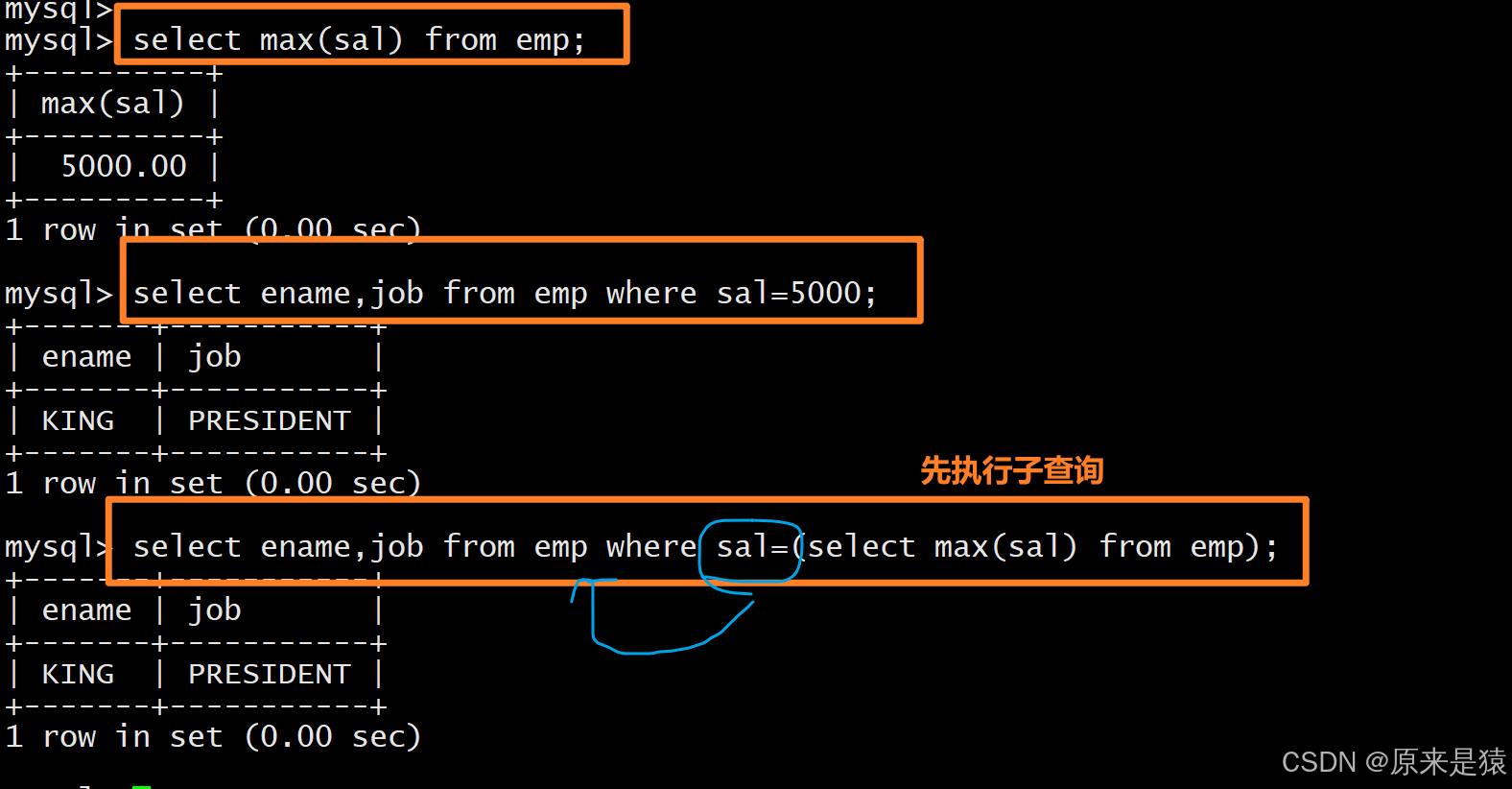
显示工资最高的员工姓名和工作岗位
select ename, job from EMP where sal = (select max(sal) from EMP);
-
显示工资高于平均工资的员工信息
select ename, sal from EMP where sal>(select avg(sal) from EMP);
5. 分组查询与分组过滤
用group by按指定字段分组,结合聚合函数做分组统计;having对分组结果过滤(区别于where:where过滤原始数据,having过滤分组后数据),例如:
-
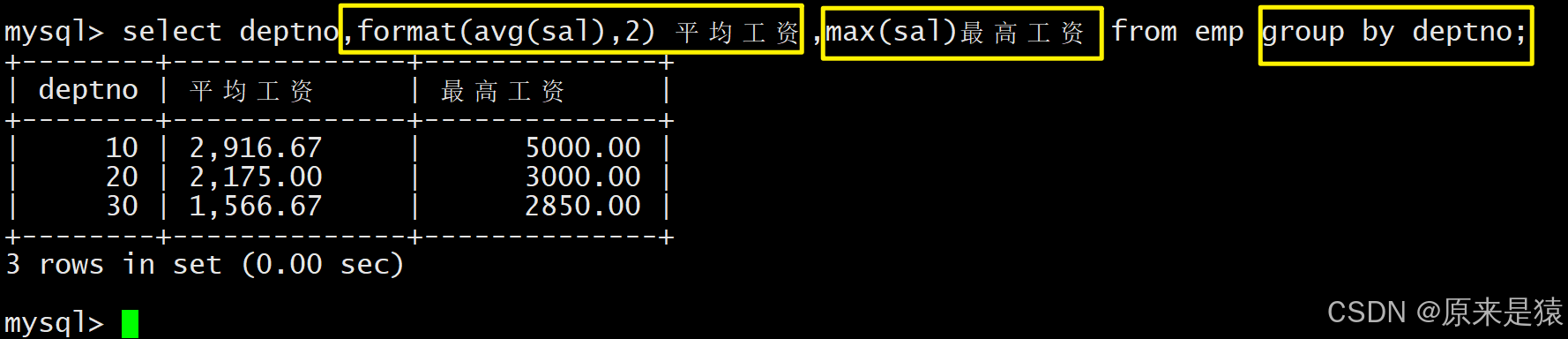
显示每个部门的平均工资(保留 2 位小数)和最高工资
select deptno, format(avg(sal), 2) , max(sal) from EMP group by deptno;
-
显示平均工资低于 2000 的部门号和平均工资
select deptno, avg(sal) as avg_sal from EMP group by deptno having avg_sal<2000;

-
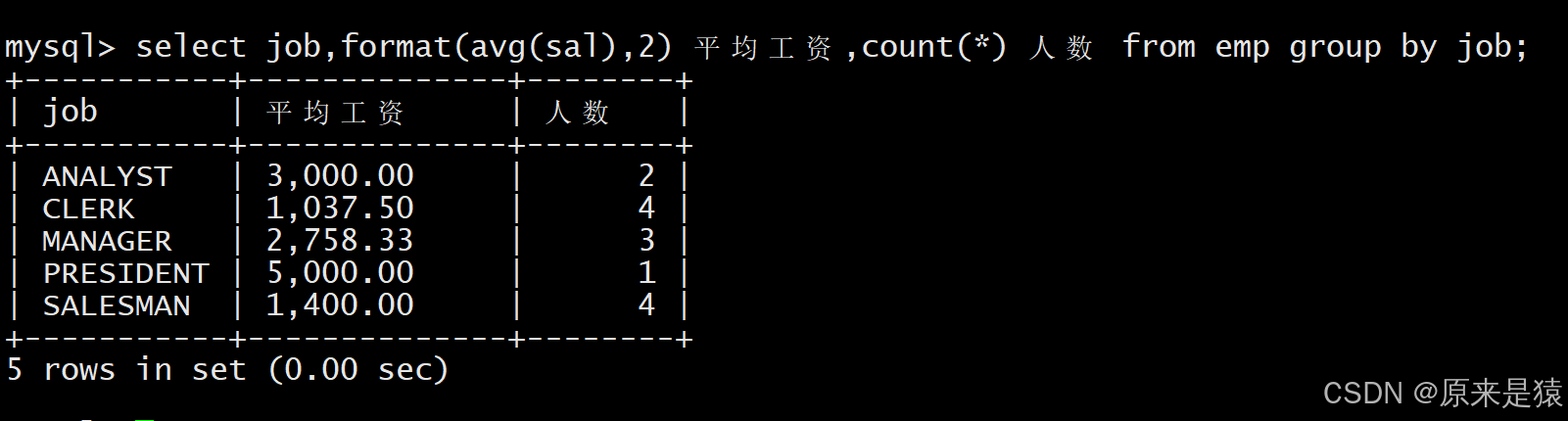
显示每种岗位的雇员总数和平均工资
select job,count(*), format(avg(sal),2) from EMP group by job;
二、多表查询
实际业务中,数据通常分散在多张关联表中(例如 EMP 员工表、DEPT 部门表、SALGRADE 工资等级表),多表查询的核心是通过关联字段消除笛卡尔积,找到表之间的连接关系。
直接查询多张表而不加过滤条件,会得到笛卡尔积结果(表 1 记录数 * 表 2 记录数),这是无意义的,例如:
-- 无意义的笛卡尔积,避免直接使用
select * from EMP, DEPT;多表查询的核心:关联字段过滤 , 多表查询的关键是找到表之间的关联主键 / 外键 ,通过where子句指定关联条件,筛选出有效数据
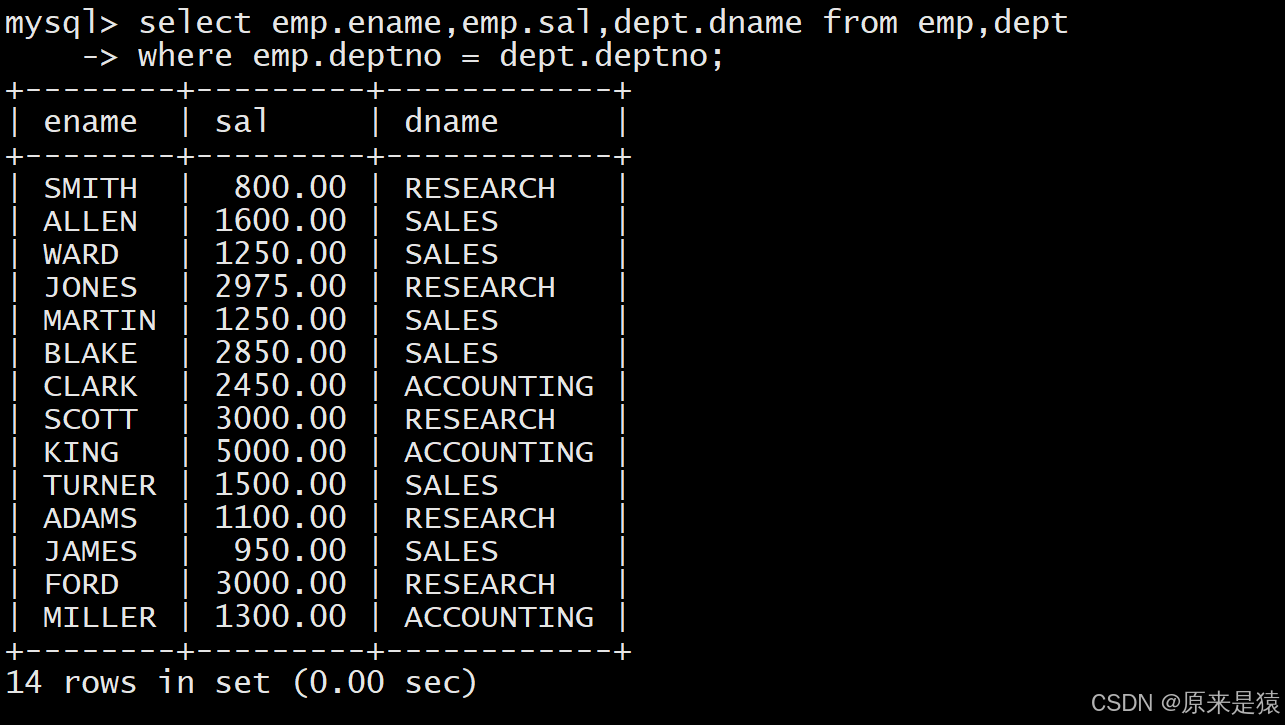
- 显示雇员名、雇员工资以及所在部门的名字因为上面的数据来自EMP和DEPT表,因此要联合查询

其实我们只要emp表中的deptno = dept表中的deptno字段的记录
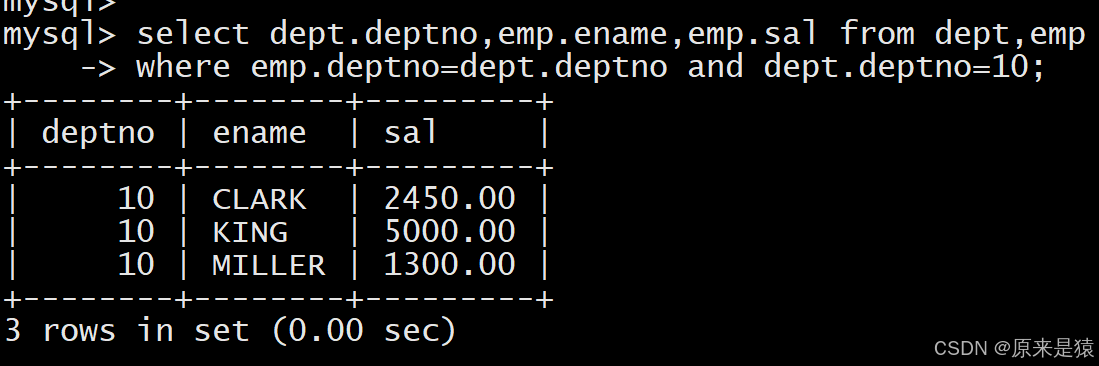
- 显示部门号为10的部门名,员工名和工资
在关联条件基础上,增加业务条件过滤:
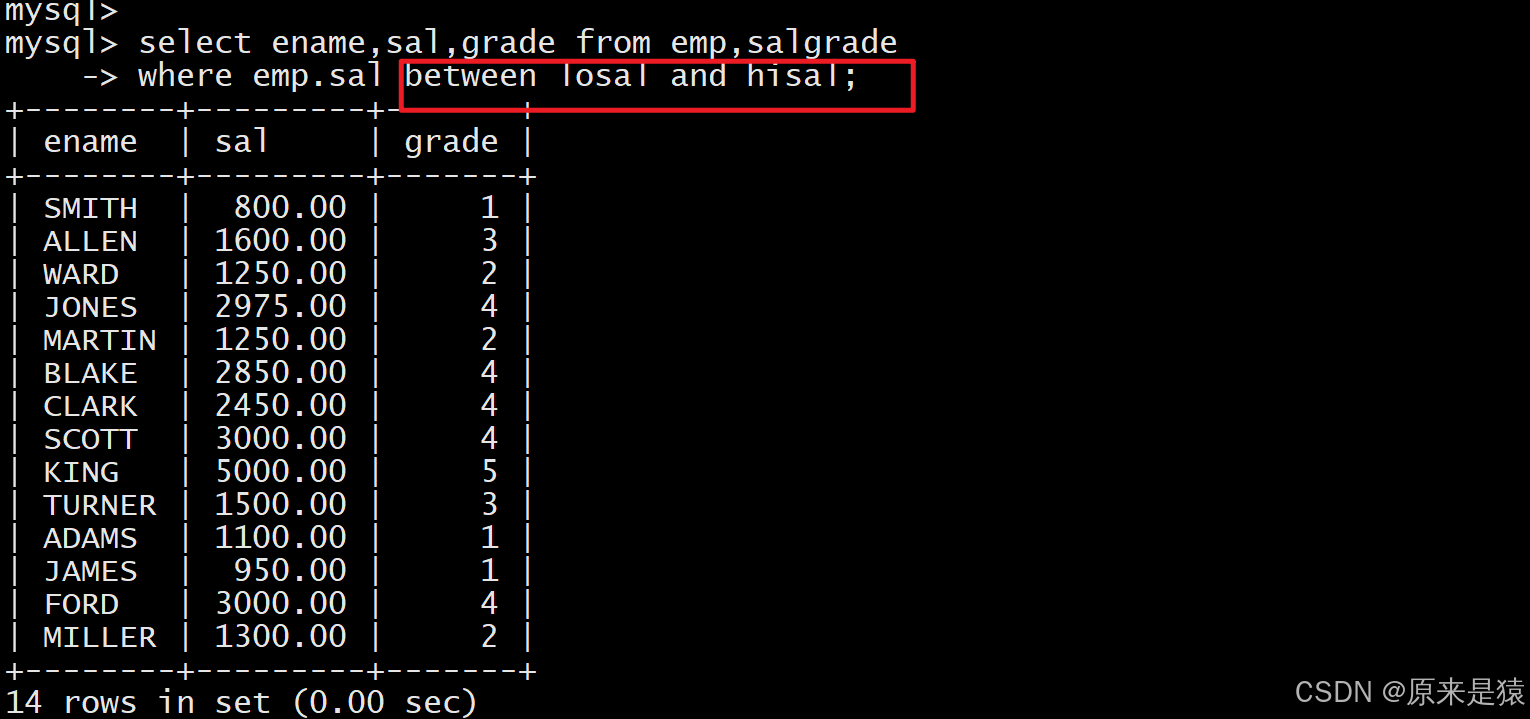
- 显示各个员工的姓名,工资,及工资级别
EMP 表与 SALGRADE 表通过工资范围关联(SALGRADE 的losal为最低工资,hisal为最高工资),用between ... and ...匹配:
三、自连接
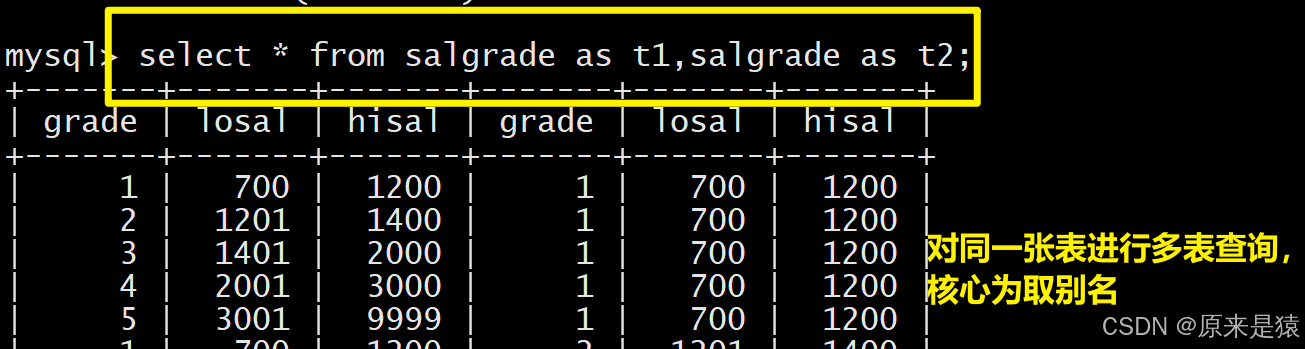
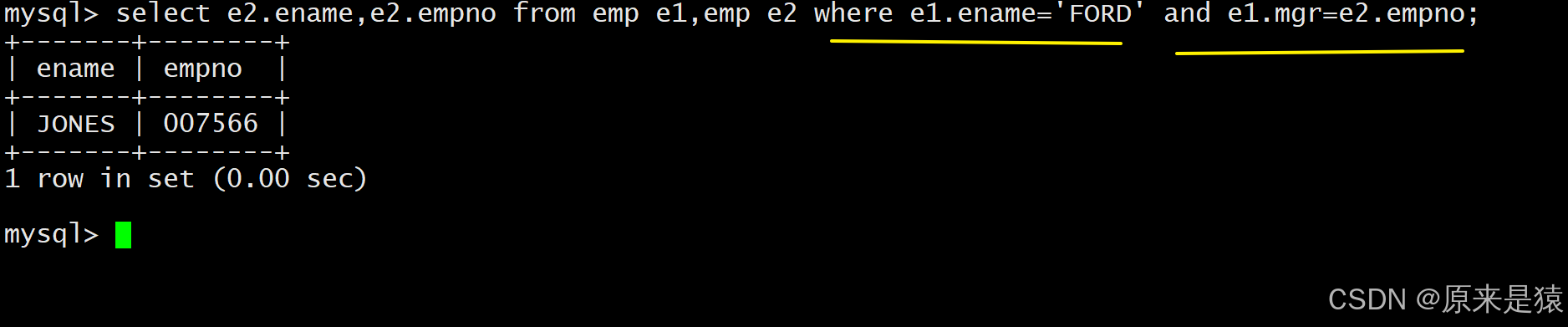
自连接是多表查询的特殊形式,将同一张表当作多张表来使用 ,核心是为表起不同的别名,通过关联字段实现表内的关联检索。
什么场景下,我们需要自连接?
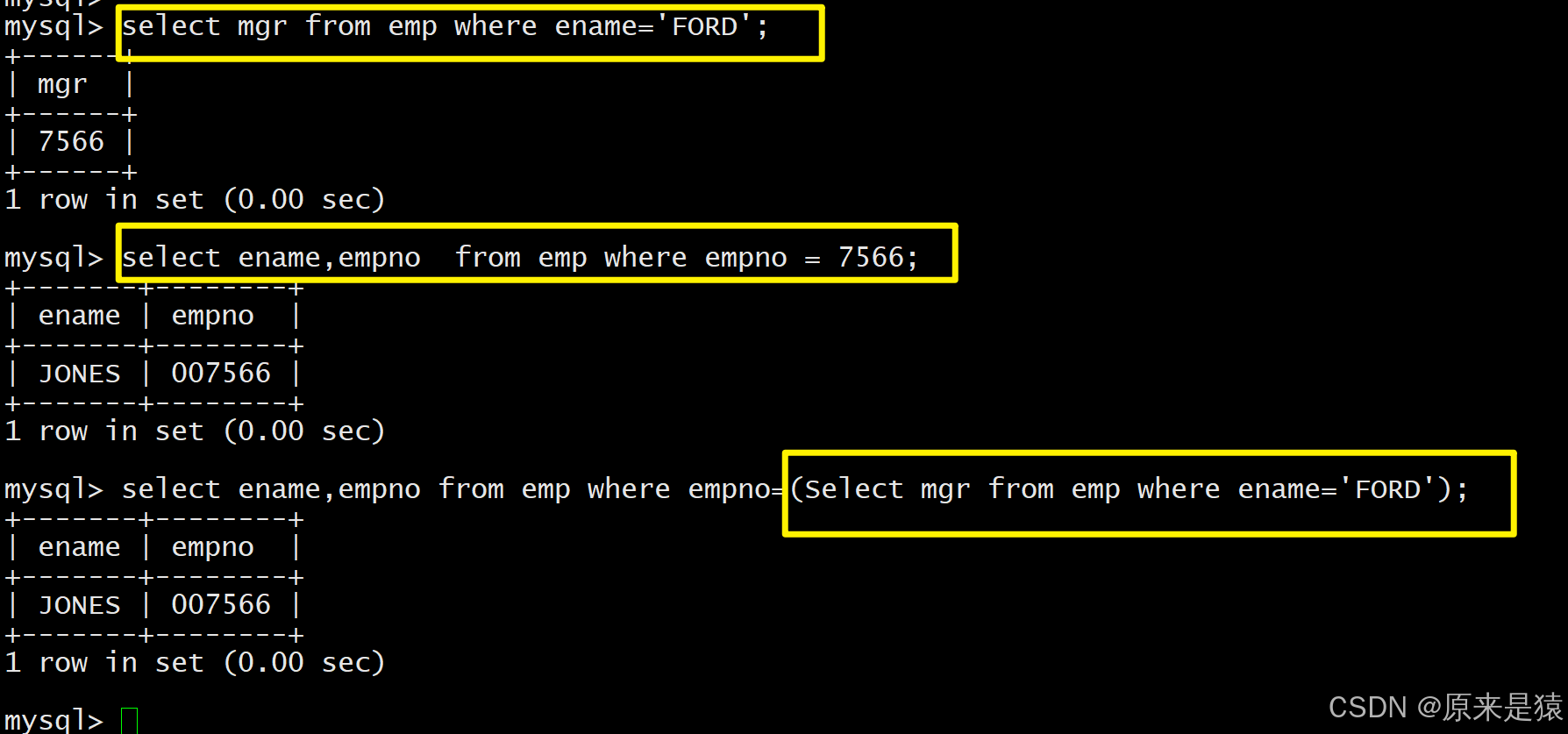
例如 EMP 表中,mgr字段是员工领导的编号(对应另一员工的empno),**需查询员工 FORD 的上级领导的编号和姓名,**有两种实现方式,自连接是更优解。
- 子查询
先找到FORD领导的编号 - EMP
根据领导编号,找领导信息
-
多表查询
select leader.empno,leader.ename from emp leader, emp worker where leader.empno = worker.mgr and worker.ename='FORD';
四、子查询
子查询(嵌套查询)是指将一个
select语句嵌入到另一个select/insert/update/delete语句中,被嵌入的查询称为子查询,外层查询称为主查询 。子查询可根据返回结果分为单行子查询 、多行子查询 、多列子查询 ,还可在from子句中当作临时表使用。
4.1 单行子查询
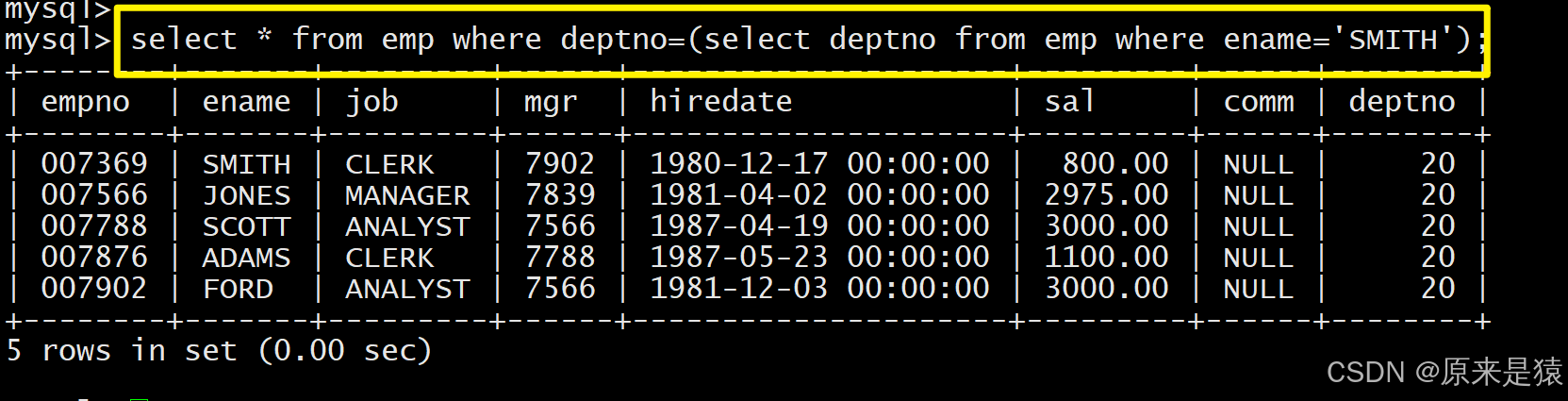
子查询返回 单行单列的结果,通常与 = > < 等单值比较运算符结合使用
- 显示 SMITH 同一部门的所有员工
4.2 多行子查询
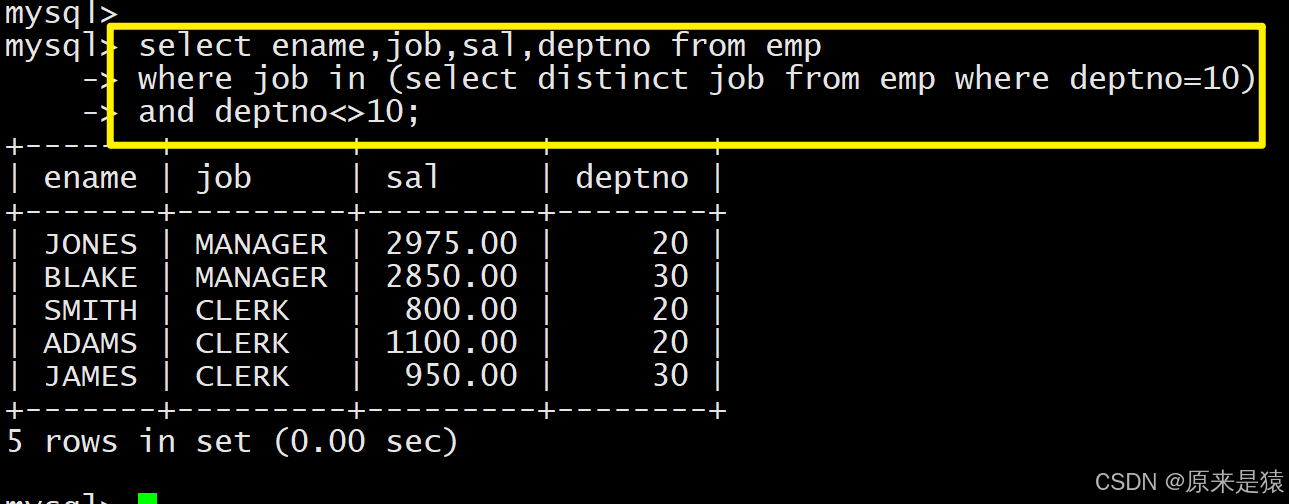
子查询返回多行单列的结果,需与
in/all/any等多行运算符结合使用,不可直接用单值比较运算符。
- in关键字;查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的
- all关键字;显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
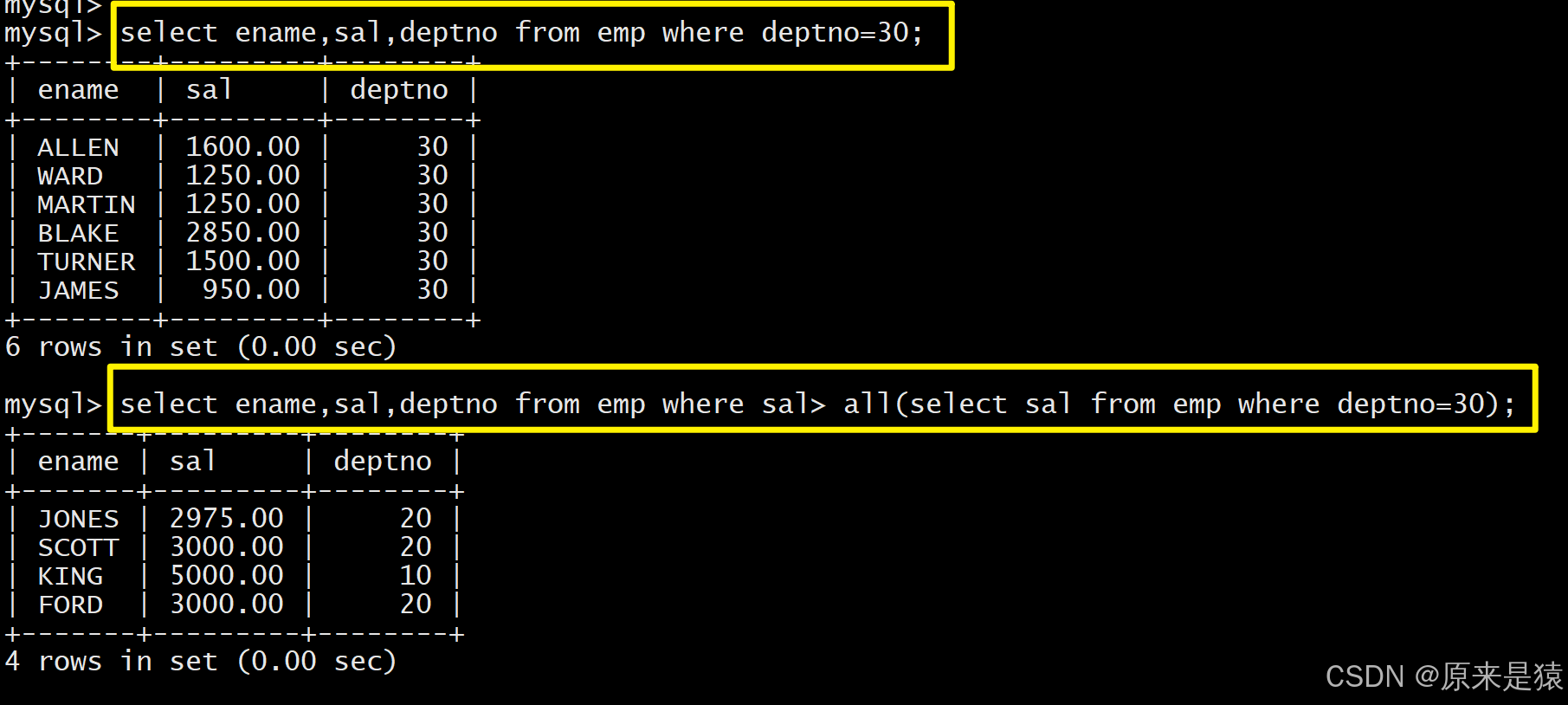
- any关键字;显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门 的员工)
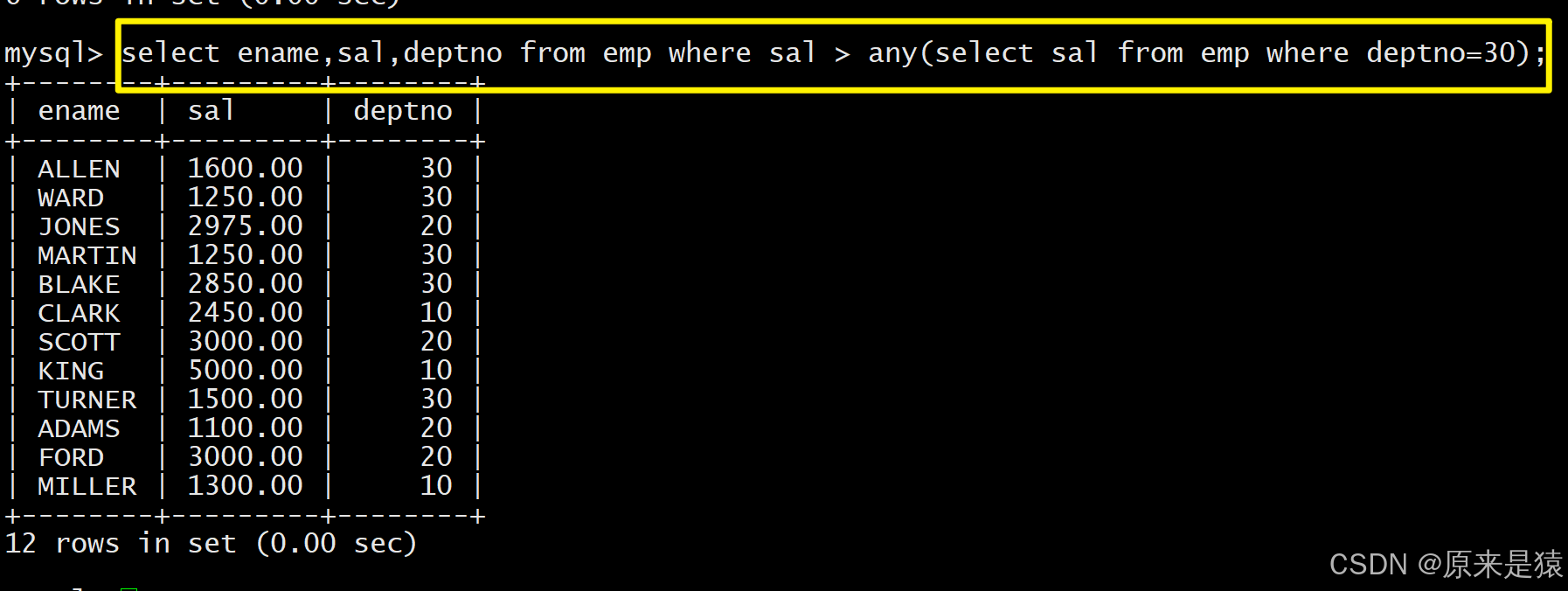
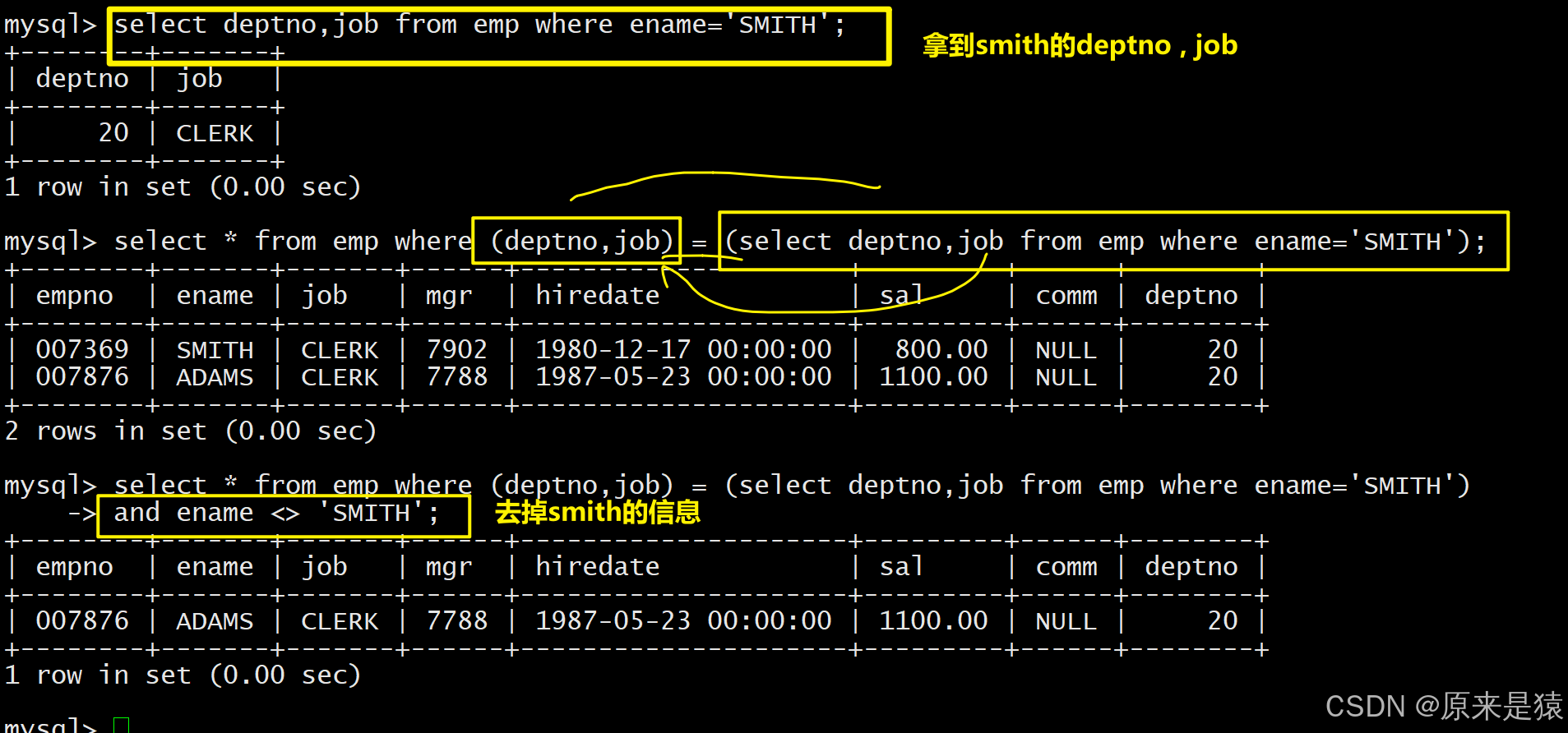
4.3 多列子查询
子查询返回多列(单行 / 多行)的结果,需用括号将多列字段包裹,与主查询的多列进行匹配,适用于多条件完全匹配的场景。
案例:查询和 SMITH 的部门、岗位完全相同的所有雇员(排除 SMITH 本人)
- 目前全部的子查询,全部都在where 子句中 , 充当判断条件
- 任何时候,查出来的临时结构,本 质上在逻辑上也是表结构
4.4 在from 子句中使用子查询
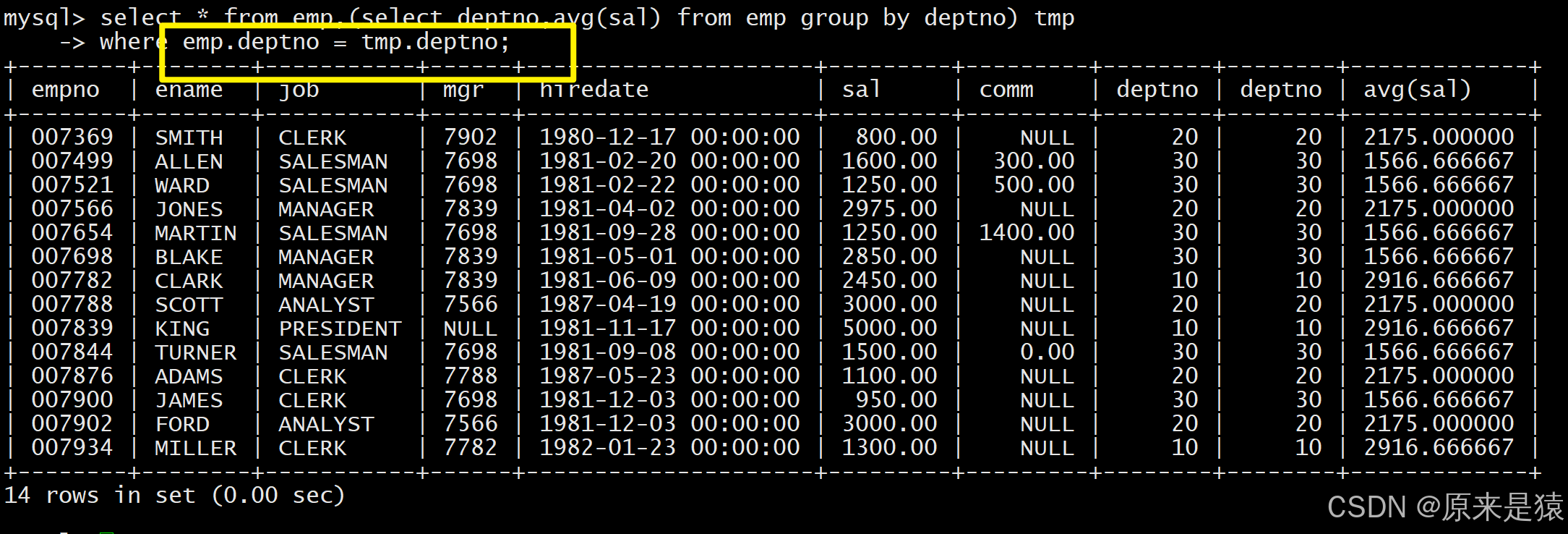
将子查询的结果当作临时表使用,这是复合查询的高频技巧,需为临时表指定别名(否则 MySQL 会报错),适用于需要先统计再关联查询的场景。
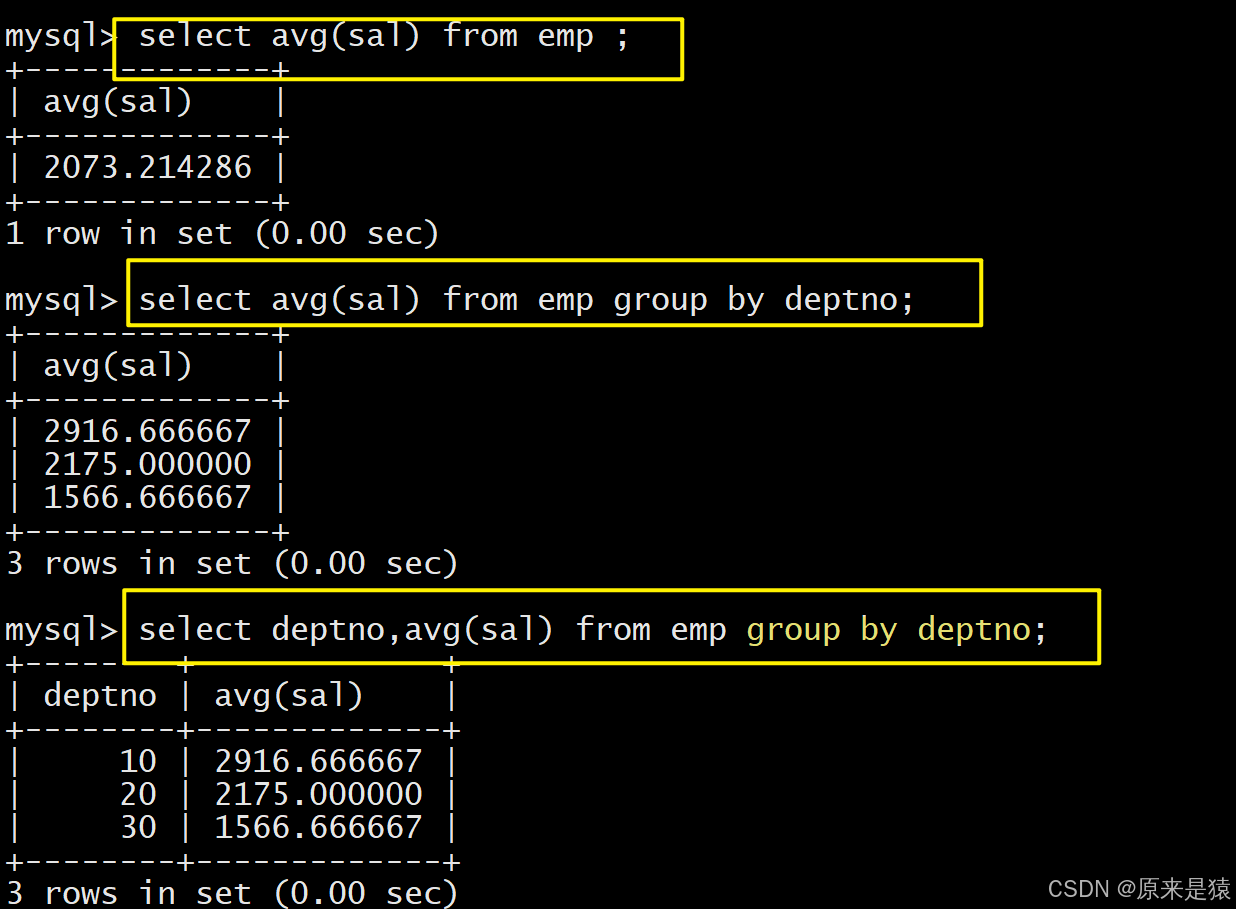
-
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
select ename, deptno, sal, format(asal,2) from EMP,
(select avg(sal) asal, deptno dt from EMP group by deptno) tmp
where EMP.sal > tmp.asal and EMP.deptno=tmp.dt;


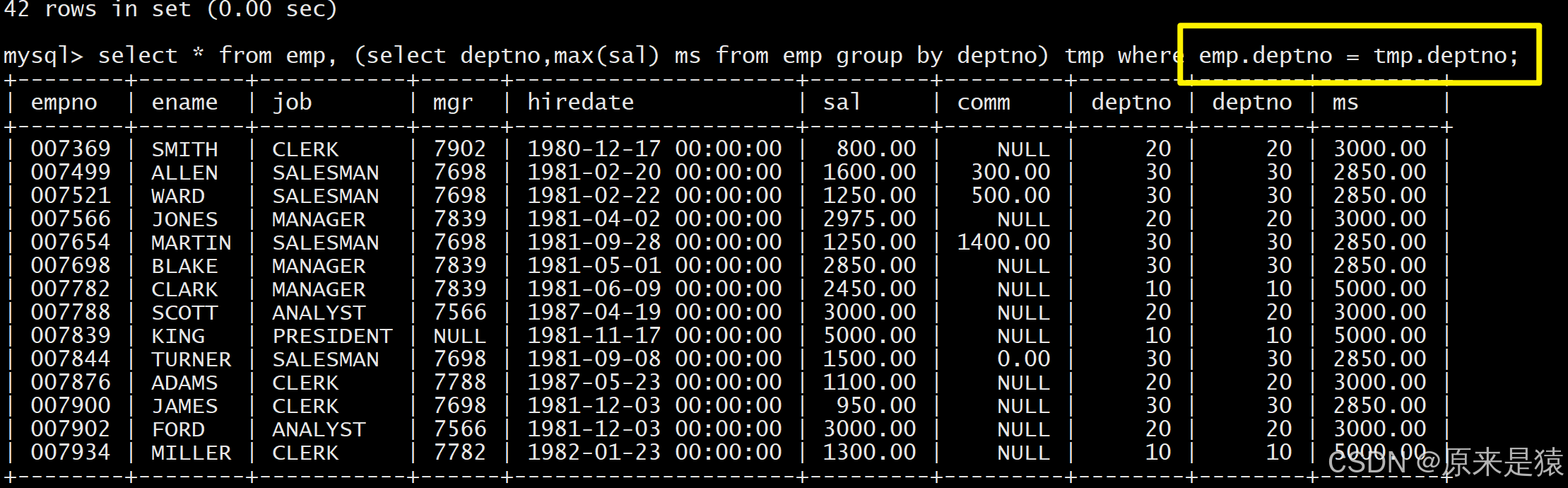
- 查找每个部门工资最高的人的姓名、工资、部门、最高工资
先统计各部门的最高工资(生成临时表),再关联 EMP 表匹配对应员工:
select EMP.ename, EMP.sal, EMP.deptno, ms from EMP,
(select max(sal) ms, deptno from EMP group by deptno) tmp
where EMP.deptno=tmp.deptno and EMP.sal=tmp.ms;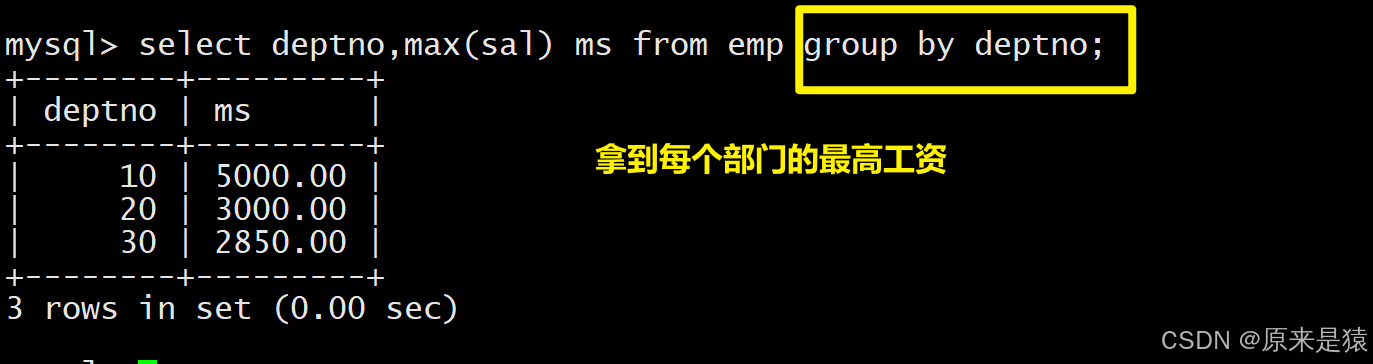


- 显示每个部门的信息(部门名,编号,地址)和人员数量
方法 1:多表直接分组统计
select DEPT.dname, DEPT.deptno, DEPT.loc,count(*) '部门人数' from EMP, DEPT
where EMP.deptno=DEPT.deptno
group by DEPT.deptno,DEPT.dname,DEPT.loc;
方法2:使用子查询
elect t1.dname,t1.loc,t2.dept_num,t1.deptno from dept t1 ,(select deptno,count(*)dept_num from emp group by deptno) t2 where t1.deptno = t2.deptno;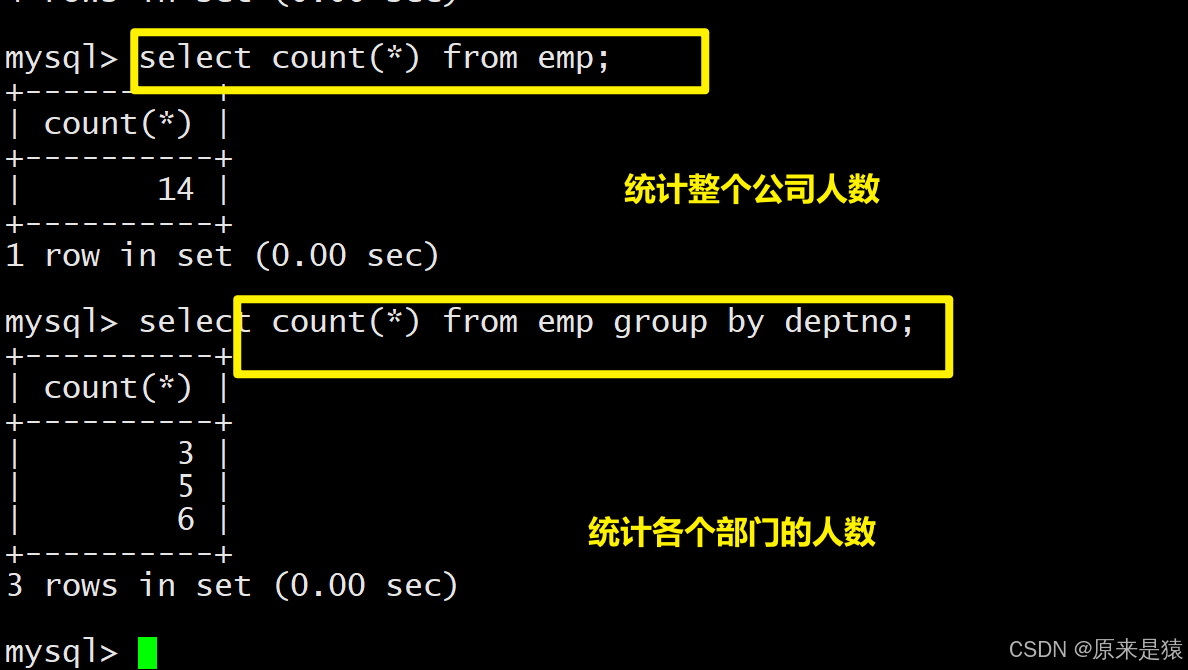

解决多表问题的本质 :想办法将多表转化为单表, 所以在mysql中 ,所有问题全部都可以转化成单表问题!!!
4.5 合并查询
在实际应用中,需要将多个独立的
select查询结果合并为一个结果集,MySQL 提供 union和
union all 两个集合操作符,核心区别是是否去重。
union:合并结果集并自动去重
union会将多个查询结果合并,同时去掉重复的记录 ,要求多个select语句的字段数、字段类型一致。
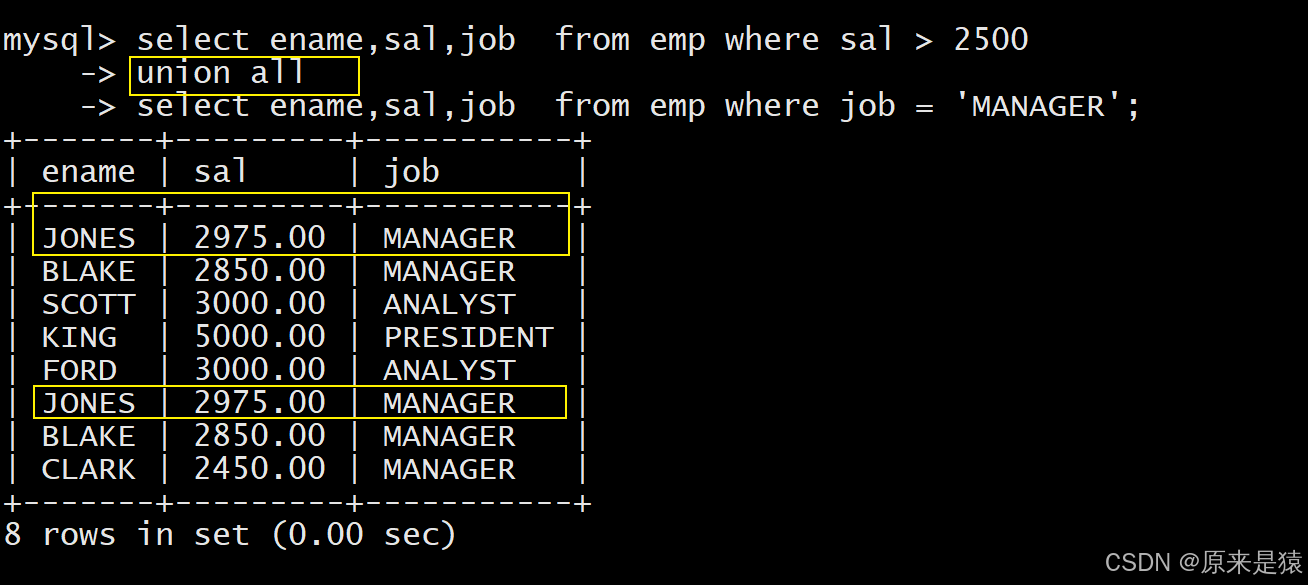
案例:将工资大于2500或职位是MANAGER的人找出来
select ename, sal, job from EMP where sal>2500
union
select ename, sal, job from EMP where job='MANAGER';
union all:合并结果集不进行去重
union all仅简单合并多个查询结果,不会去重 ,执行效率比union更高(无需做去重处理),适用于确定无重复数据或需要保留重复数据的场景。
案例:将工资大于25000或职位是MANAGER的人找出来