前言
本篇文章是本人学习完MySQL所有八股知识的总结,不适合从0-1学习MySQL的小伙伴进行学习。
在准备 MySQL 面试的过程中,我刷了大量八股文,也零散地写过不少相关博客。
但一个很明显的问题是:
知识点都懂一点,却始终是碎片化的,缺乏一条清晰的主线。
比如:
- 知道索引能加速查询,但不清楚它在整个执行流程中的位置
- 知道 MVCC,但和事务、锁之间的关系说不清
- 知道有 Redo Log /Binlog,但不明白它们是怎么配合工作的
这些问题的本质,其实不是"不会",而是:没有把知识点串成体系
这篇文章不会从 0 到 1 讲解 MySQL,而是尝试做一件更实用的事情:把常见 MySQL 八股知识点,按照执行链路串成一张完整的认知网
我将以"一条 SQL 的执行"为起点,把各个知识模块串联起来:
SQL执行
↓
索引(加速查询)
↓
事务 & MVCC(保证正确)
↓
锁(解决冲突)
↓
日志(保证不丢数据)
↓
SQL优化(提升性能)
↓
主从复制(扩展系统)
一、从一条 SQL 开始(全局入口)
第一章我们从SQL语句在MySQL中的执行流程开始引入(了解执行器与优化器的区分),然后了解MySQL事务机制是如何实现的(ACID),B+树查询数据的全过程(为什么选择B+树),三层B+树能存储多少数据,最后承上启下了解判断索引是否生效。
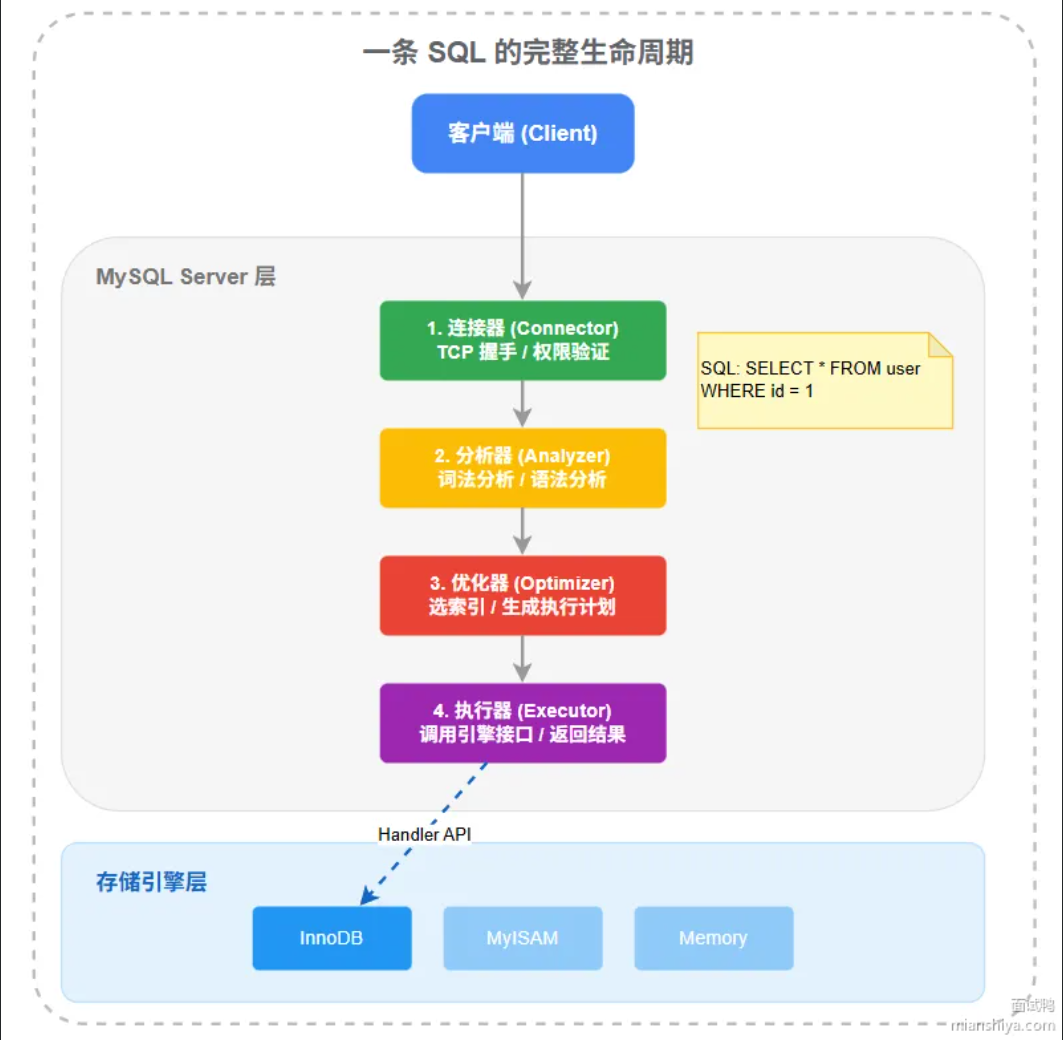
描述一下一条SQL语句在MySQL中的执行过程
MySQL的架构分为两层:Service层负责连接管理,SQL解析,查询优化这些逻辑处理。存储引擎负责数据的实际存取。
集体流程分为5步:
- 客户端先于MySQL建立连接,连接器负责验证账号密码和权限,确认你能对哪些库表做什么操作。
- 老版本会先查询缓存,在8.0版本之后删除了,因为每当表一更新,缓存就会不失效,缓存命中率太低
- 分析器对SQL语句做词法和语法分析。先将字符串拆成一个个Token,识别SELECT,表明,列名,WHERE这些元素;再按语法规则判断SQL语句写的对不对,最终生成一颗语法树。
- 优化器拿到语法树后,决定用哪个索引,多表JOIN时先查哪张表,子查询要不要改成JOIN,最终生成一个执行计划。
- 执行计 划按照执行计划,调用存储引擎的接口一行行读数据,做条件过滤,最终将结果表返回给客户端。
分析器和优化器有什么区别
分析器直观SQL写的对不对,不管这么执行。他把字符串拆成Token,检查语法,生成一颗描述SQL结构的语法树。优化器拿到这颗树后,要决定怎么执行:用哪个索引,表连接顺序,子查询要不要改写。同一条SQL语法树是固定的,但执行计划可能有很多种,优化器负责选成本最低的
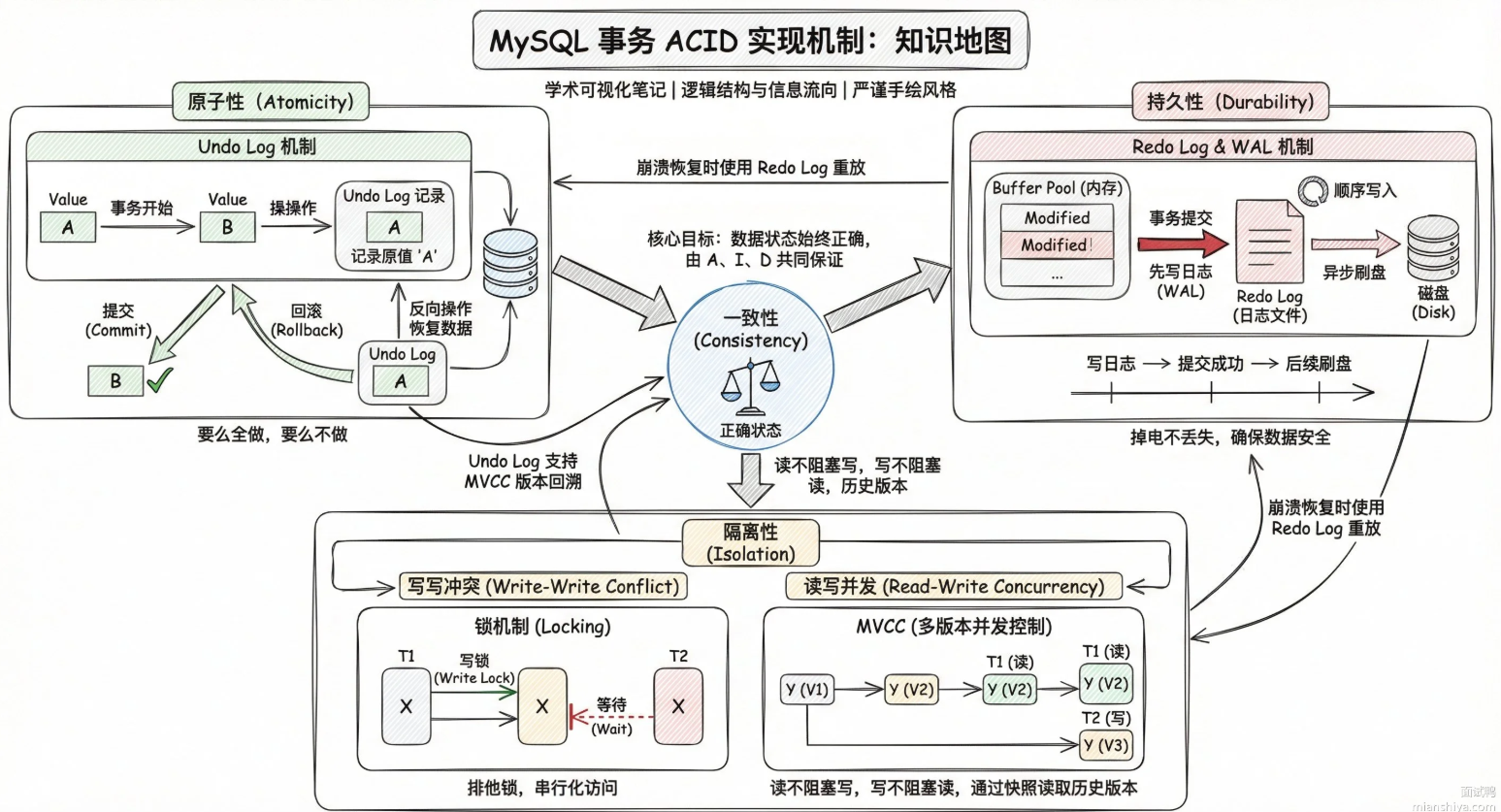
MySQL是如何实现事务的
实现事务主要靠四个核心组件:redo log undo log MVCC 锁 分别对应了事务ACID特性的不同方面。
Redo Log 保证持久性:事务提交时,修改先写到redo log再写磁盘数据页。就算写数据页时宕机了,重启后通过redo log就能恢复数据。这就是WAL机制。
Undo Log 保证原子性:每次修改数据前,先把原值存到undo log里。事务回滚时,按undo log反向操作把数据恢复回去。要么全做完,要么全撤销,不会出现改了一半的中间状态。
锁机制 (行锁,间隙锁)保证隔离性:两个事务同时改同一行,必须一个等另一个释放锁。InnoDB的锁粒度精确到行级,还有间隙锁防止幻读。
MVCC保证隔离性的读写并发:读操作不加锁,用过undo log里的版本连找到自己应该看到的数据版本。写的时候别人照样能读,读的时候别人也能写。大大提升并发性能。
一致性不是单独实现的,它是由:原子性,隔离性,持久性共同作用的结果。数据从一个正确状态转移到另一个正确状态,中间不会出现不一致。
衍生
redo log的工作原理
innodb修改数据时不会直接写磁盘上的数据页,因为随机IO太多,性能扛不住。用的是WAL策略:先修改操作顺序到redo log,再找机会把数据页刷到磁盘。顺序写比随机写快几个数量级。
redo log采用循环写的方式,有两个指针:write pos表示当前写到哪了,checkpoint表设计已经刷盘的位置。两个指针之间就是待刷盘的脏数据。
sql
+---+---+---+---+
| 0 | 1 | 2 | 3 | redo log 文件组
+---+---+---+---+
^ ^
| |
checkpoint write_pos事务提交时,redo log必须落盘,这个行为由innodb_flush_log_at_trx_commit控制:
- 设成1:每次提交都刷盘,最安全但性能差
- 设成0:每秒刷一次,宕机可能丢失一秒数据
- 设成2:写到操作系统缓存,MySQL挂了数据还在,机器挂了才丢
undo log与版本链
每条数据都有两条隐藏字段:trx_id记录最后修改这条数据的事务ID,roll_pointer指向undo log里的上一个版本。多次修改就会形成一条版本链。
假设原始数据name='张三,事务100改成李四',事务200又改成'王五':
sql
当前数据页:name='王五', trx_id=200, roll_pointer →
undo log:name='李四', trx_id=100, roll_pointer →
undo log:name='张三', trx_id=0, roll_pointer=nullMVCC读数据时,根据事务的Read View沿着版本链往回找,找到第一个自己能看见的版本。可重复读隔离级别下,Read View在事务开始时生成一次,后面一直用这个。读已提交隔离级别下,每次查询都生成新的Read VIew。
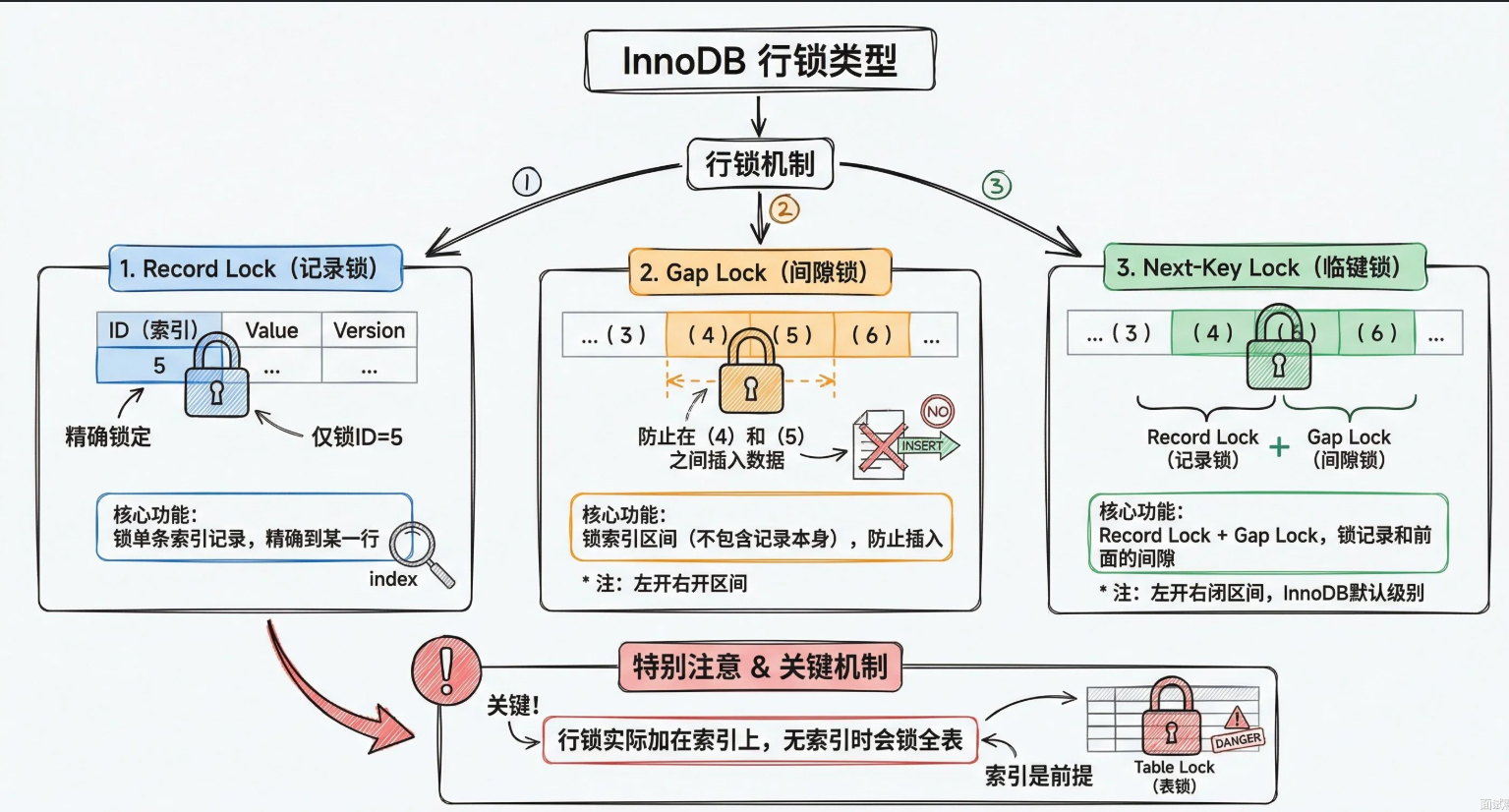
锁的实现细节
innodb的行锁是加在索引上的。如果MySQL没走索引,就会锁全表
InnoDB有三种行锁:
Record Lock:锁单条记录
GapLock:锁一个区间,不包含记录本身
Next-Key Lock:Record Lock +Gap Lock,锁记录和它前面的间隙
事务提交的两阶段提交
InnoDB和Service层有各自自己的日志,redo log和binlog。为保证这两个日志的一致性,用了两阶段提交:
- prepare阶段:redo log写盘,状态标记为prepare
- commit阶段:binlog写盘,然后redo log状态改为commit
如果prepare后binlog写入前宕机,重启恢复时发现redo log是prepare状态但没对应的binlog,事务回滚。
如果 binlog 写完但 commit 前宕机,重启恢复时发现 redo log 是 prepare 状态且有对应的 binlog,事务提交。
这套机制保证了主从复制的数据一致性,从库靠 binlog 同步数据,主库靠 redo log 恢复数据,两边必须对得上。
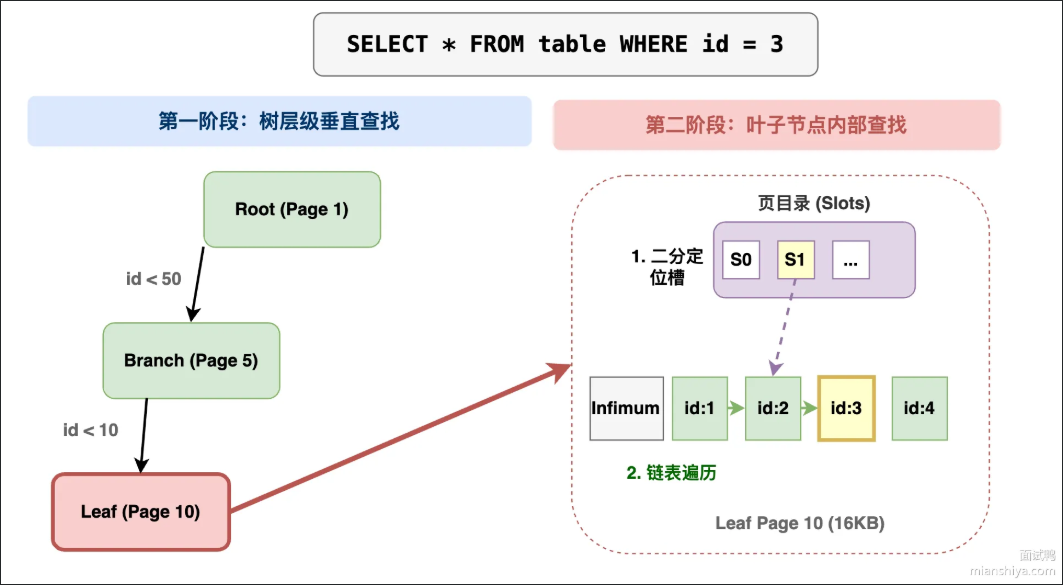
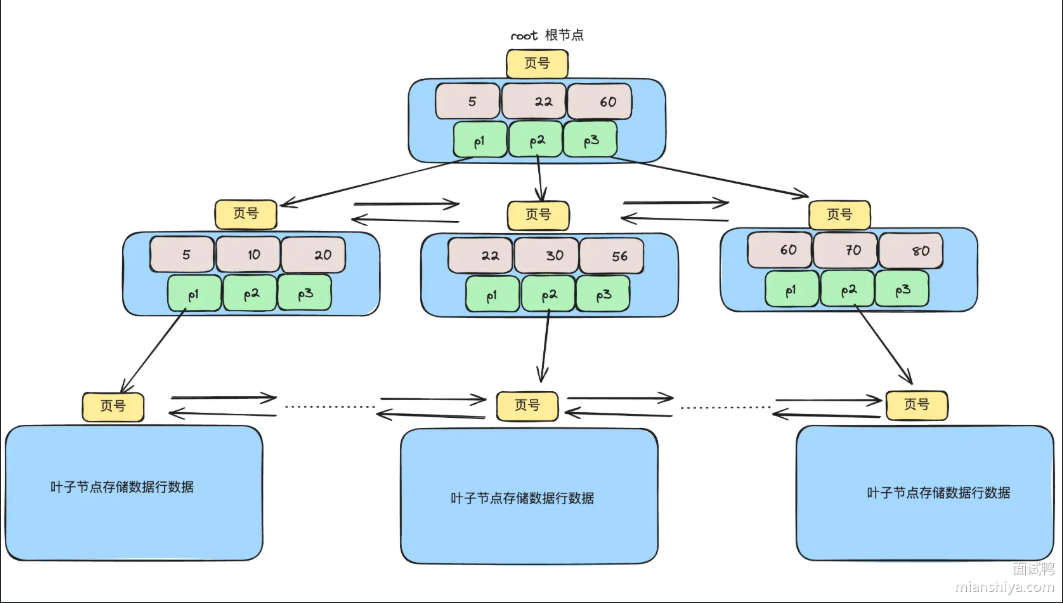
MySQL中B+树查询数据的全过程
B+树查询数据可以分为两个阶段:1.树的垂直查找2.页内查找
第一阶段(树的垂直查找):从根节点开始,把查询的键值与节点中存储的键值进行比较,用二分法来确定具体位置,顺着指针来达到子节点,一直重复直到到达叶子节点。一颗三层B+树查询一次数据最多需要三次I/O
第二阶段(页内查询):叶子节点是一个16KB的数据页,InnoDB用页目录 来加速查找,页目录将数据分成若干组。先用二分法在页目录中定位到记录所在的组,再沿着组内的单向链表遍历,找到目标记录。
过程浏览:根节点->中间节点->叶子节点->页目录二分->组内链表遍历
为什么MySQL用B+树来作为索引结构
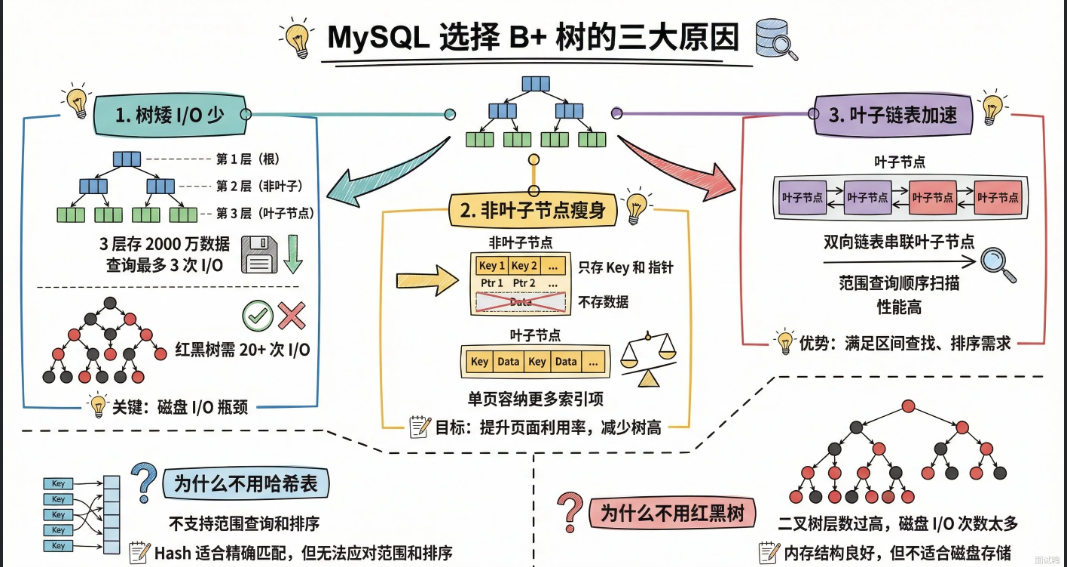
本质原因:磁盘I/O次数少
分三点来答:
- 树矮:B+树是多叉树,一个节点能存几百上千个key。三层B+树就可以存储两千多万条数据,查询一次最多3次磁盘I/O。作为二叉树的红黑树,存储同样多的数据需要20多层。
- 非叶子节点值存key和键值,不存出数据。一个16KB的数据页能塞下更多索引,内存能存储更多索引,命中率高,磁盘访问少。
- 叶子节点用双向链表串起来,范围查询时,顺序I/O比随机I/O快很多。
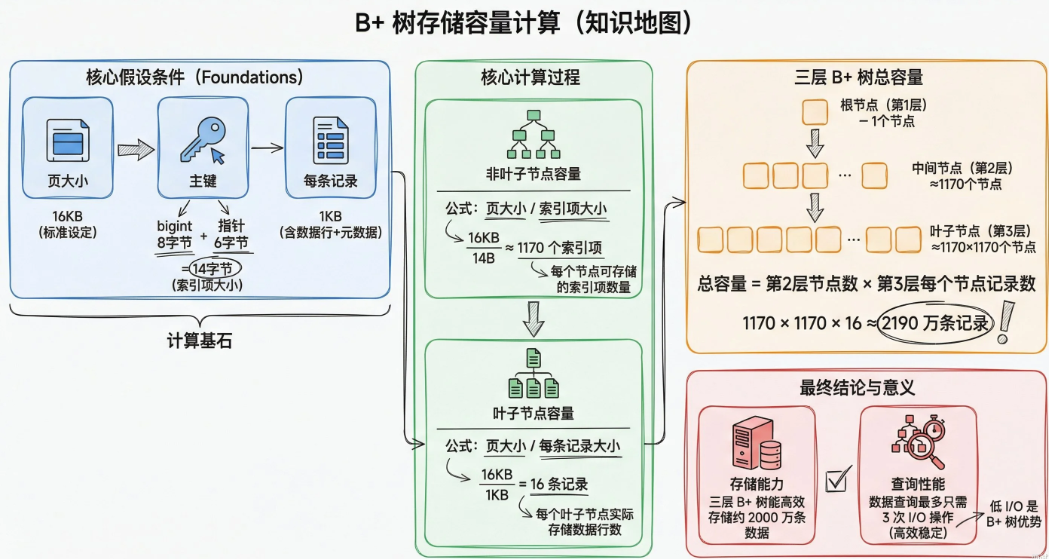
三层B+树能存多少数据具体时这么计算的
InnoDB默认页大小是16KB,非叶子节点存储的是主键和指针,叶子节点存的是完整数据行。
假设主键是bigint占8个字节,指针占6个字节,那么一个非叶子节点能存储的索引数量为:161024/14=1170个
假设每条记录占1KB,那么一个叶子节点能存的记录数为16/1=16条
总记录数:1170 1170*16=2190万条
如何判断索引是否生效
排查索引效果最直接的办法就是用 EXPLAIN 命令。在 SQL 前面加上 EXPLAIN,就能看到 MySQL 选择的执行计划。重点看这几个字段:
1)type:访问类型,ALL 是全表扫描,range 是范围扫描,ref 是等值匹配,index 是全索引扫描。ALL 基本就是没走索引,ref 和 range 才是真正利用了索引的快速查找能力。
2)key:实际用的索引名称,NULL就是没用上索引。
3)rows:预估扫描的行数,这个数字越大说明查询代价越高。
二、索引体系(查询性能核心)
第二章主要讲解的是索引机制,先从索引的类型开始讲解(为什么选择了B+树),然后了解联合索引的最左前缀匹配原则,进一步探讨索引下推与覆盖索引的区分,最后了解实际工程中索引造多还是造少进行取舍。
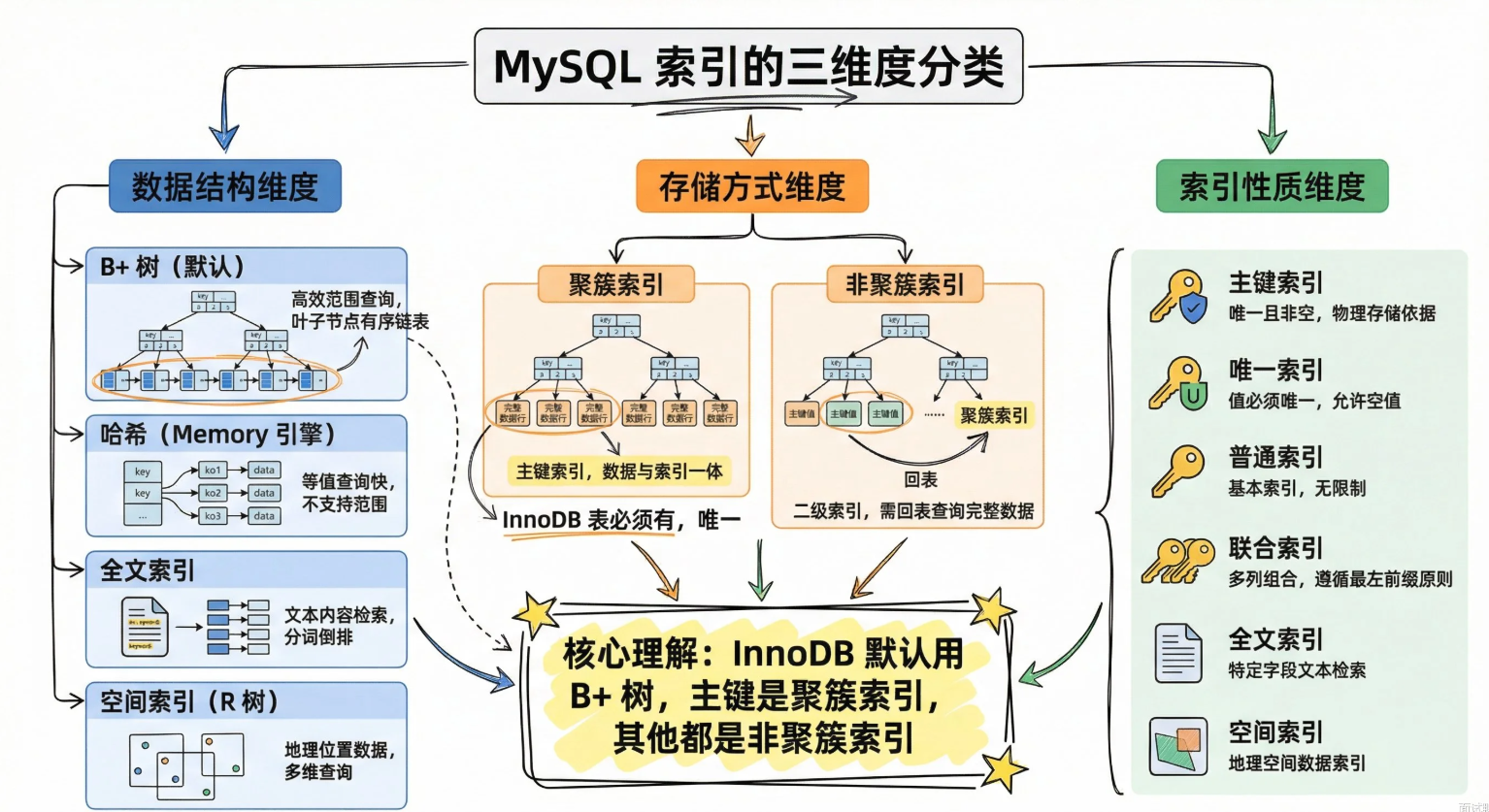
索引类型有哪些
MySQL索引可以从三个维度来分类:数据结构,存储方式,索引性质。我们先从数据结构来切入,重点讲解B+树,然后展开讲解聚簇索引和非聚簇索引的区别。
数据结构:
- B+树索引:叶子节点存储数据,叶子节点通过链表串起来:保证了快速定位单条记录和高效做出范围扫描。
- 哈希索引:通过哈希函数直接算出数据位置,等值查询O(1),不支持范围查询和排序。
- 全文索引
- 空间索引
存储方式: - 聚簇索引:又叫主键索引,叶子节点世界存放完整的行数据,数据按主键顺序物理存储,一张表只能由一个主键索引
- 非聚簇索引:也叫二级索引,叶子节点只存储索引字段值和主键值。查完二级索引还得拿着主键取主键索引获取具体数据。
索引性质 :
1)主键索引:唯一且非空,每张表只能有一个。InnoDB里主键索引就是聚簇索引。2)唯一索引:保证列值不重复,但允许有NULL,可以有多个NULL。
3)普通索引:没有唯一约束,纯粹为了加速查询。
4)联合索引:多列组合成一个索引,遵循最左前缀原则,列顺序很重要。5)全文索引:文本搜索用。
6)空间索引:GIS数据用。
衍生
B+树厉害在哪
数据库查询由两大类构成:等职查询和范围查询。哈希索引等值查询速度快,但是无法进行范围查询。B+树两个都行,并且叶子节点用双向链表连接,范围扫描的时候顺着链表走,不用回溯。
另外,B+树特点是树矮,一个三层的B+树就能存储2000万左右的数据。查询一条数据最多3次I/O。
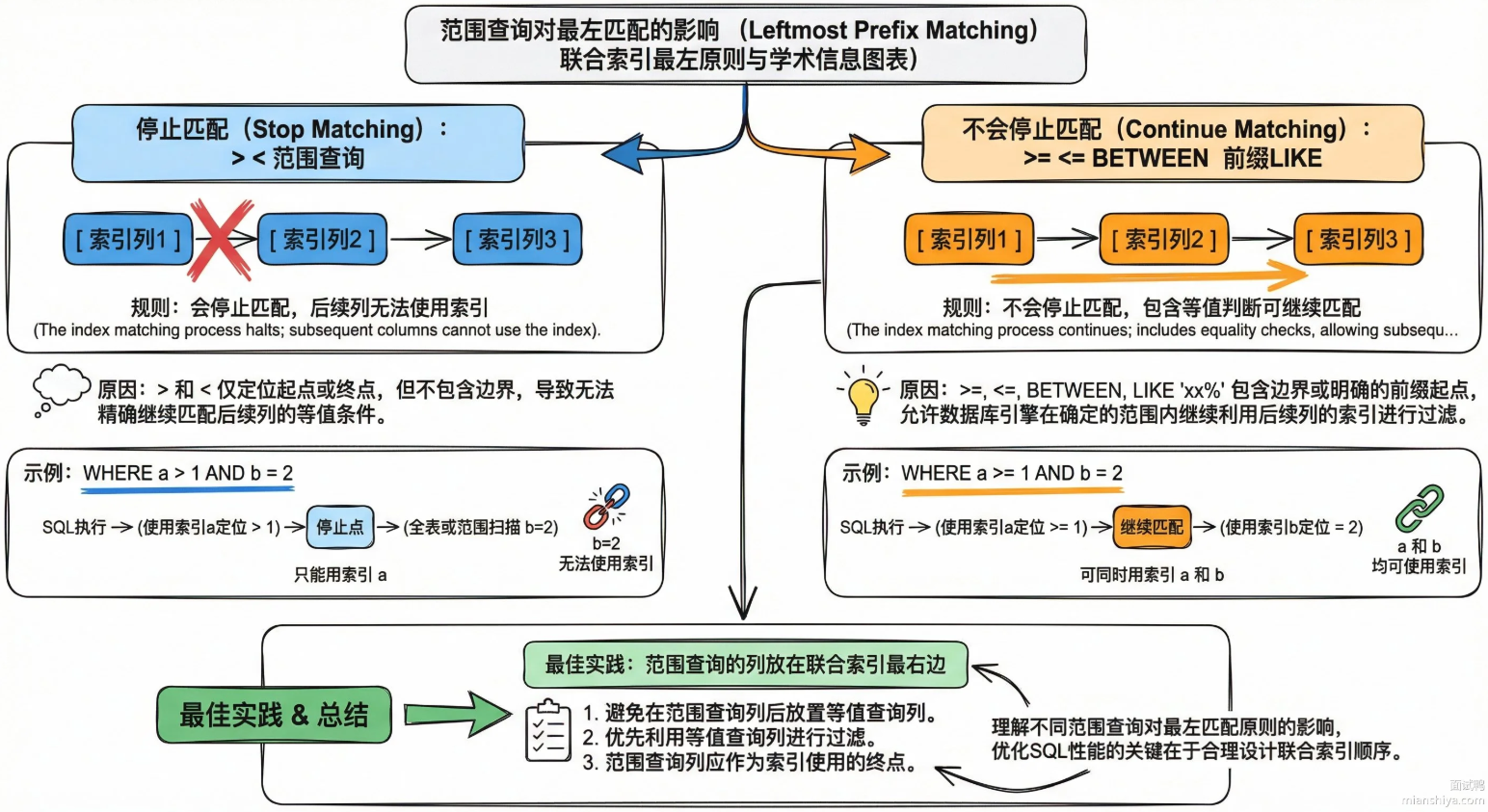
MySQL索引的最左前缀匹配原则是什么?
一句话概括:
当MySQL在使用联合索引时,查询条件必须从索引的最左列开始匹配。
这是因为联合索引在B+树中的排列方式是"从左到右"的顺序。比如联合索引(first_name,last_name,age)会先按 first_name 排序,first_name 相同再按last_name 排序,last_name 相同再按 age 排序。MySQL 查找时会优先用first_name作为匹配依据,然后依次用last_name和 age。跳过最左侧字段,后面的列在B+树中是无序的,压根没法利用索引快速定位。
特例:范围查询
当范围查询是:>,<这种,会停止匹配
sql
where a > 1 and b = 2 and c = 3;只有a能用上联合索引,因为a经过查询筛选后,不同a值之间的b和c是无序的。无法走索引。
相反,当遇到>=,<=,前缀 like xx%时,不会停止匹配。因为他们之中包含等值判断
MySQL的覆盖索引
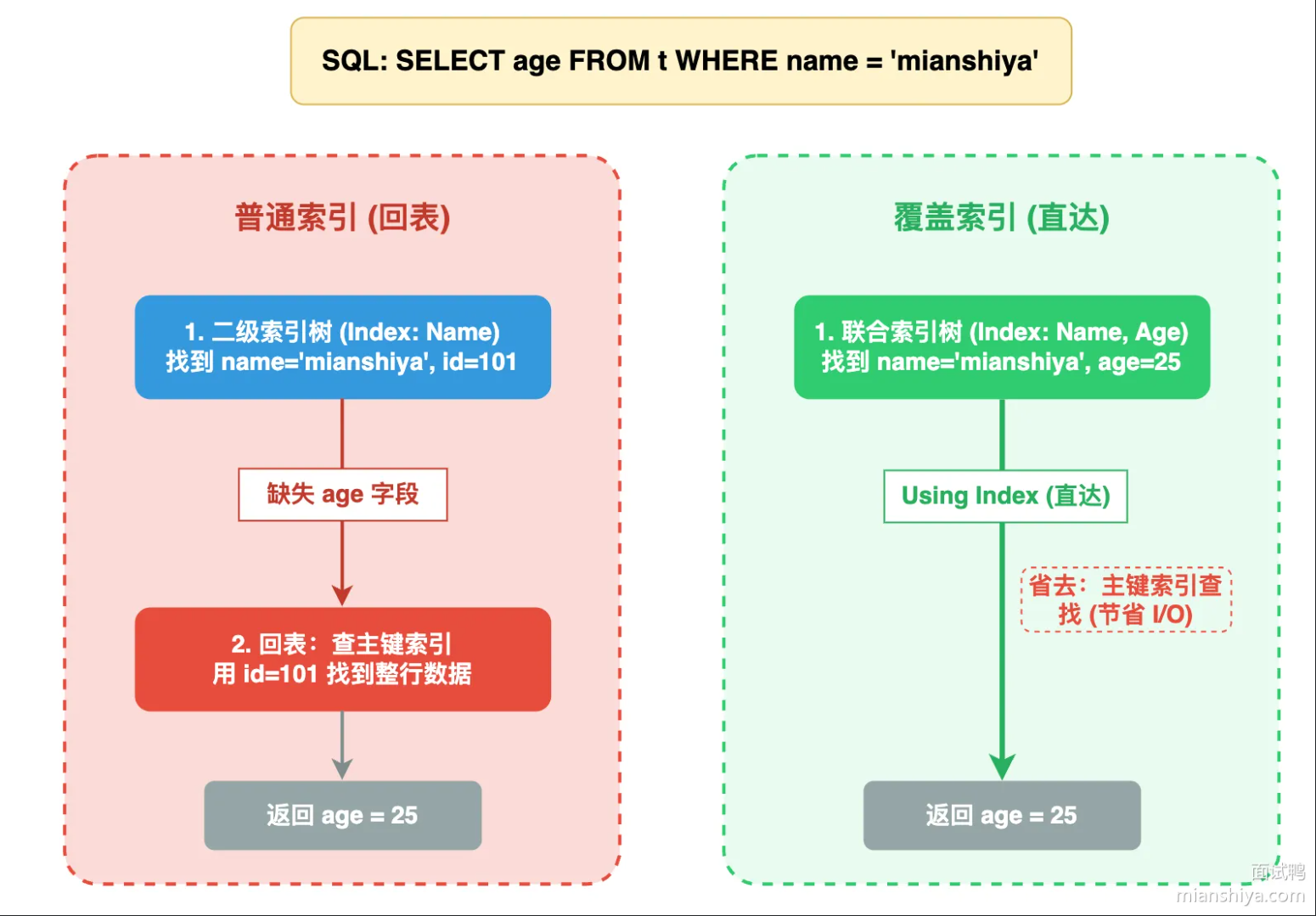
覆盖索引指的是查询内容包含在了二级索引内部,查询时直接从索引里拿数据,无需再次执行回表操作。
本质是:索引中有的数据直接拿,避免回表操作。
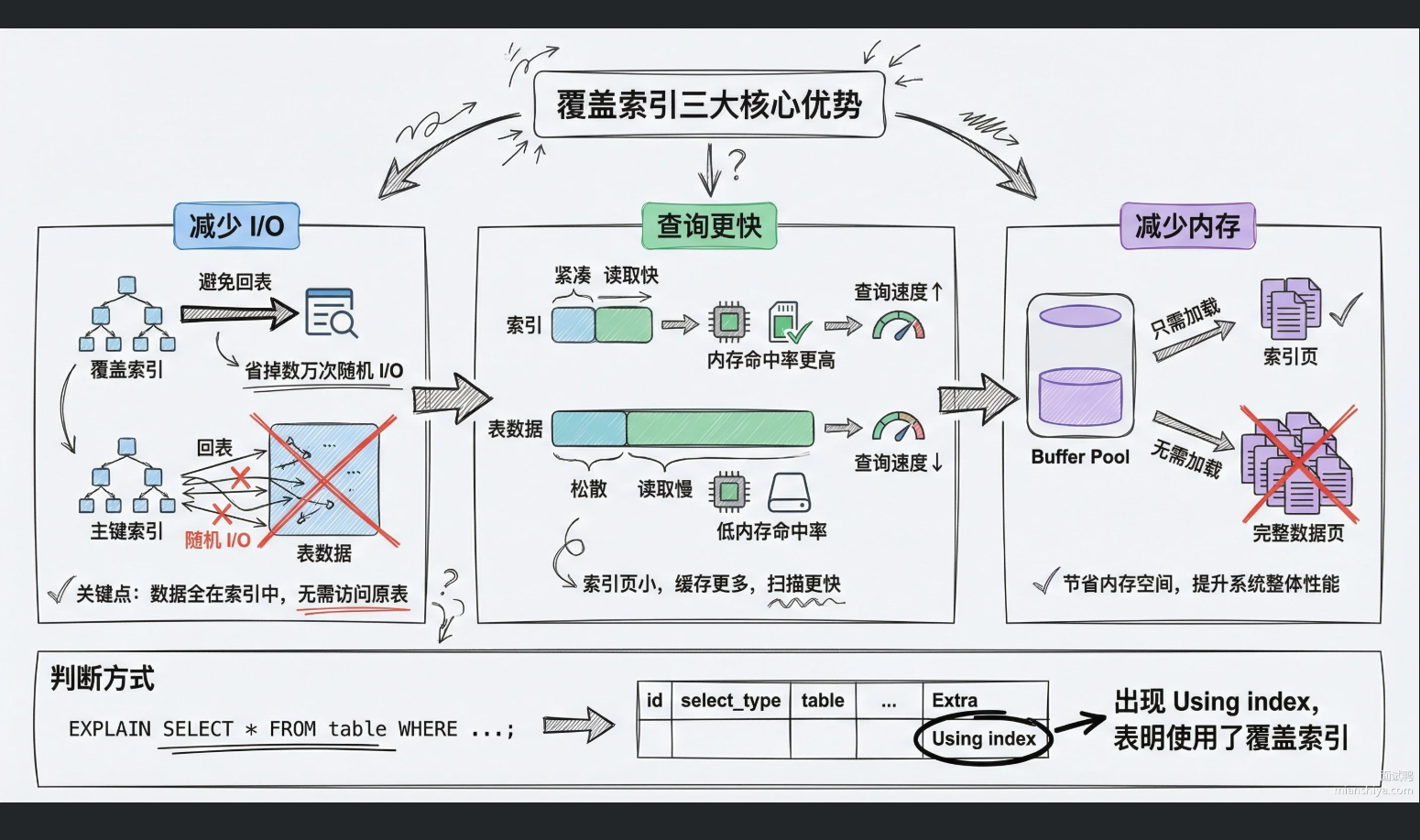
优点:
- 减少I/O操作:查询直接从索引中拿数据,避免访问主键索引的数据页。
- 查询更快:索引页小,结构紧凑,缓存命中率更高
- 减少内存占用:Buffer Poll只需加载索引页,不用加载更大的数据页
设计覆盖索引的哲学
主要分三点来设计:
- 高频查询优先:分析业务哪些查询频率高,针对这些设计覆盖索引
- 权衡读写比列:覆盖索引不是越多越好。索引列越多,索引越大,写入维护成本高。
- 利用联合索引:把where条件的列与select的列创建为一个联合索引。例如:select a,b from t where c=1,可以键(c,a,b)索引
覆盖索引和索引下推的区别
覆盖索引是完全不回表,索引里有查询需要的所有数据。索引下推是减少回表次数,把过滤条件下推到引擎层提前过滤,但最终还是要回表拿完整数据。两种解决的问题不一样
索引下推
索引下推是MySQL 5.6之后引入的技术。核心思路是把部分查询条件从Service层下推到存储引擎层,在引擎层就把不符合查询条件的数据过滤,不用在将这些数据进行回表操作。作用是:减少回表操作,提升查询效率。
没有索引下推的流程是:引擎层用索引定位数据,返回主键给Service层,Service层回表拿到完整数据,再用剩余条件过滤。有了索引下推,引擎层能直接用索引里的列来过滤,不符合条件的不会回表,减少了I/O
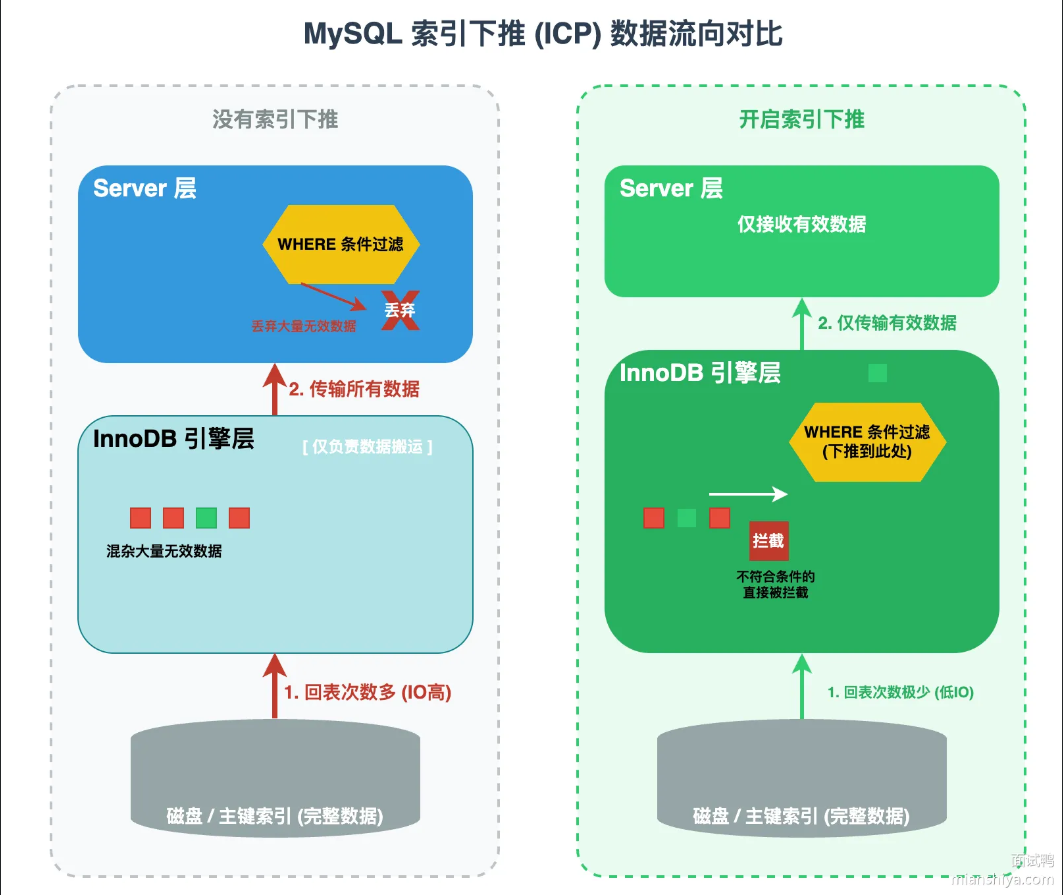
如何判断索引是否生效
在SQL语句的前面加上EXPLAIN,如果显示Usingindexcondition,说明用上了索引下推。
sql
EXPLAIN SELECT * FROM people
WHERE zipcode='95054'
AND lastname LIKE '%etrunia%';Extra 显示Usingindex condition就表示 lastname 条件被下推到引擎层了。`
关于联合索引,覆盖索引,索引下推的区分
联合索引是基础,有了联合索引才有覆盖索引和索引下推。
索引下推和覆盖索引是技术。
这两个优化都能减少I/O,但原理不同:
| 特性 | 索引下推 | 覆盖索引 |
|---|---|---|
| 解决的问题 | 减少回表次数 | 完全避免回表 |
| 是否回表 | 需要回表,但次数少 | 不需要回表 |
| EXPLAIN 标识 | Using index condition | Using index |
| 适用场景 | select * 且有额外过滤条件 | select 的列都在索引里 |
两者可以同时存在吗?不能。如果走了覆盖索引,压根不回表,索引下推就没有用武之地了。
MySQL中的索引是否越多越好
不是,索引是把双刃剑。读的时候能加速查询,写的时候要付出代价。索引太多,时间和空间成本都会上去。
从时间来看
每次insert,update,delete都要同步更新索引。例如删除一条name为123的记录。主键索引要改,name字段如果有二级索引也需要改,有几个索引就需要改几棵B+树。B+树还可能出发页分裂,页合并,写放大等问题。一张 高并发 的订单如果创建了10条索引,写入性能直接打骨折。
查询优化器也会增加负担。MySQL执行SQL语句前需要分析走那个索引成本最低,索引越多选择越多,优化器的耗时就更长。
从空间来看
每个二级索引都是一颗B+树,每个数据页16KB。假设一张表1000万行数据,一个二级索引差不多占到了几GB。索引一多,磁盘占用和内存开销都会飙升,Buffer Poll里能缓存的热数据也变少了。
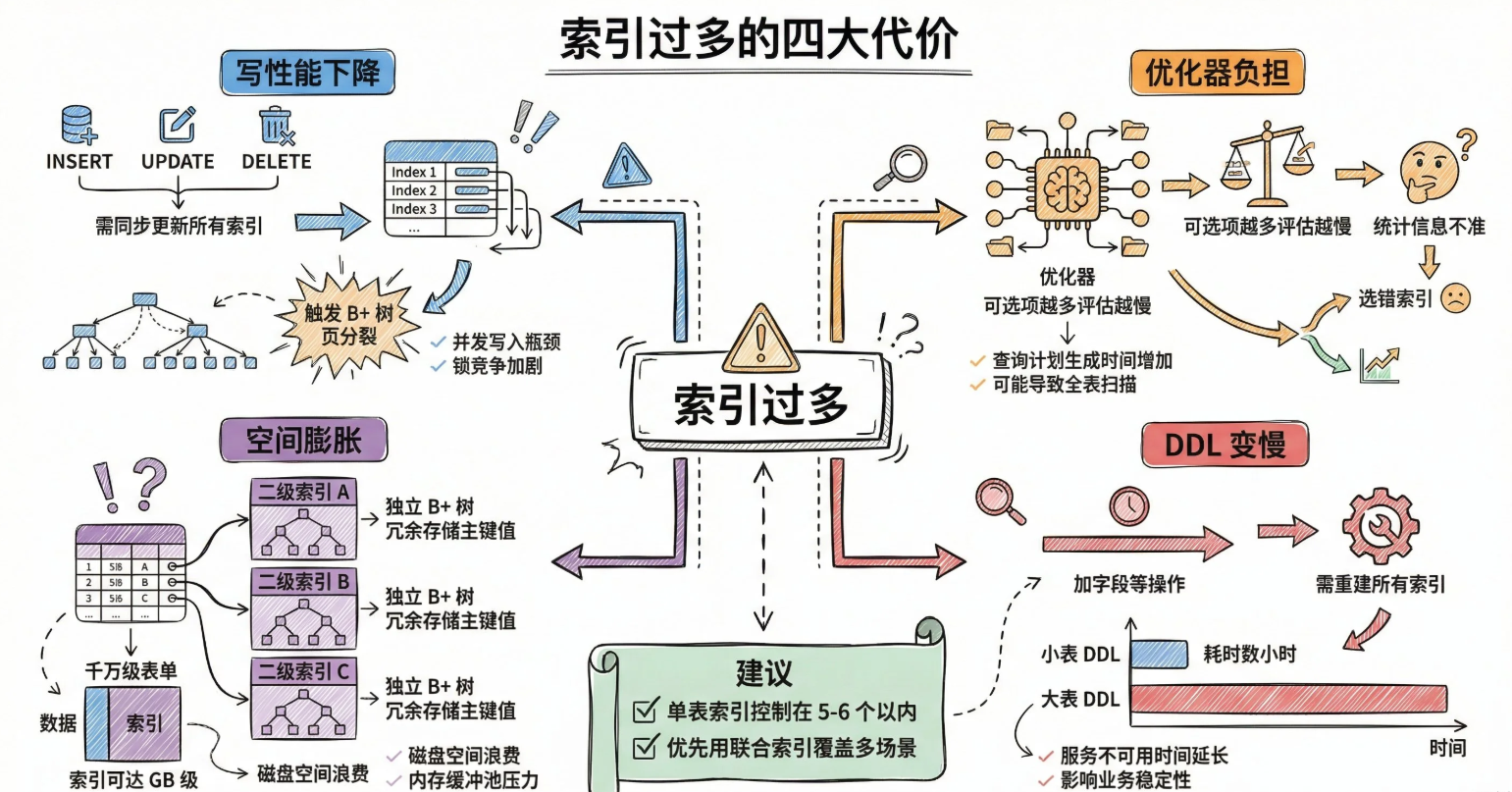
总结
具体由四点原因构成
- 写性能急剧下降
- 优化器选择困难
- 空间占用膨胀
- DDL操作变慢
三、事务与并发控制(核心难点)
MySQL最容易深度考察的内容,先从区分脏读/不可重复读/幻读开始,然后了解MVCC具体机制(实现的事务的隔离性,MVCC实现的具体机制,与锁的区分,优化MVCC的使用),然后了解事务的二阶段提交机制(通过binlog/redolog实现的prepare与commit),最后掌握长事务提交的缺陷(如何避免)
脏读/不可重复读/幻读分别代表什么意思
这三个都是并发事务带来的数据一致性问题,严重程度递减
- 脏读:指数据库中一个事务查询了一个还没提交的数据,万一那个数据回滚了,读到的数据不存在
- 不可重复读:指一个事务查询两次同一行数据,两次获得的数据不一样。因为中间有别是事务修改并提交了这行数据。强调数据的内容改变
- 幻读:指一个事务执行两次同样的范围查询,返回的数据行数不一样。因为中间有别是事务执行了插入或删除操作。强调数据的行数变化。
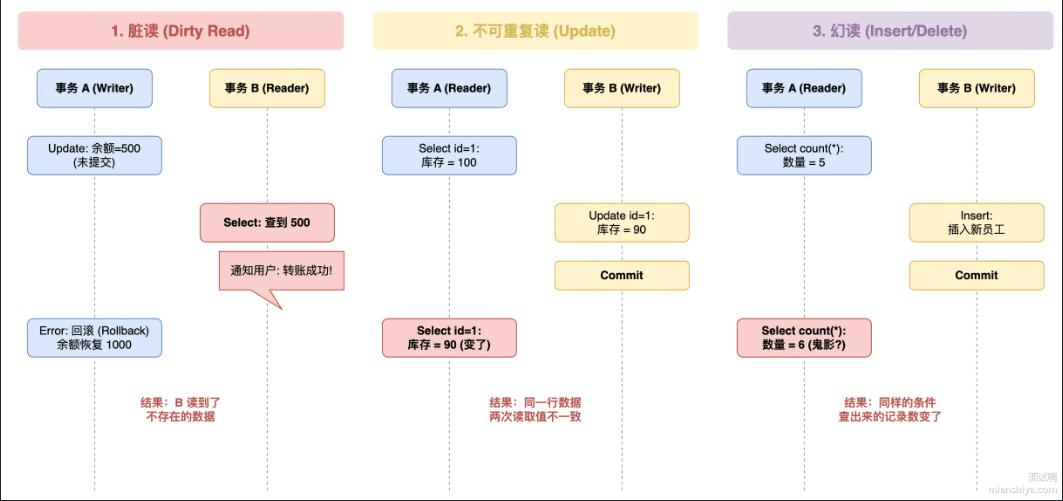
不同隔离级别下会出现的问题
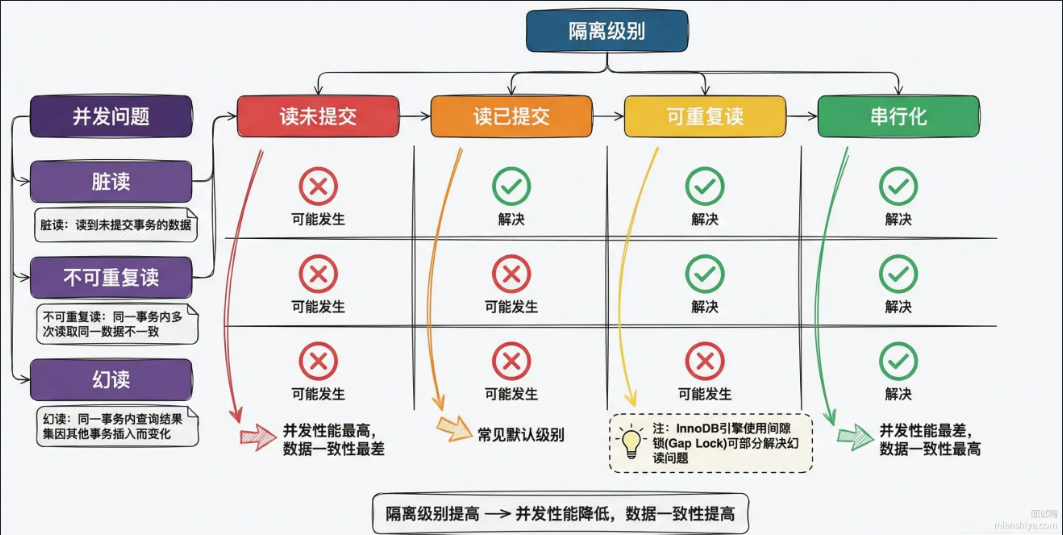
安全程度:读未提交>读已提交>可重复读>串行化
性能依次递减,InnoDB存储引擎默认的就是可重复读。
如何解决的
- 脏读:MVCC天然解决,读的是快照,看不到未提交的数据
- 不可重复读:在可重复读隔离级别下,ReadView在事务一开始就固定了,后续复查读取的是同一个ReadView。
- 幻读:快照读走MVCC,看不到新插入行,当前读用间隙锁所着范围,别的事务插不进来。当快照读和当前都混用时,还会出现幻读。
MVCC
什么是MVCC,它解决了什么问题
MVCC是InnoDB引擎的一种并发控制机制,通过保存数据 的多个版本来管理事务之间的并发访问。它允许事务在读取数据时无需加锁,而是读取数据的历史快照,从而减少锁争用,提高并发性能,同时保证事务的隔离性。
MVCC解决的问题:在高并发下,既要支持多事务并发操作,又尽量避免了因为锁竞争而导致的性能瓶颈。
MVCC的实现机制
主要依赖一下机制:
- 隐藏元信息:每行数据记录包含了两个隐藏字段
创建版本号 :记录事务开始时的唯一事务ID,表示数据是由哪个事务创建的
删除版本号:表示数据被哪个事务删除,未删除是为空 - Undo日志:修改数据时,InnoDB会将旧版本数据保存到Undo日志,用于回溯历史版本。
- 事务版本号:事务启动时会分配一个唯一的递增事务ID,用来判断数据的可见性。
MVCC支持的隔离级别
- 读已提交:每次查询时都会生成一个新的快照,读取最新的已提交数。
- 可重复读:在事务开始时生成一致性视图,整个事务期间看到的数据版本一致
MVCC和锁的区别
MVCC和锁的区别:
- 锁:直接阻止其他事务对数据的访问,适合频繁更新,冲突较多的场景,但易造成性能瓶颈
- MVCC:通过快照读实现数据的版本控制,避免加锁操作,适合高并发读场景,但可能带来存储和垃圾回收的开销。
MVCC实现了读写分离,快照读无需加锁,当前都仍可加锁
MVCC的优缺点
优点
- 减少锁竞争,提高并发性能
- 快照读不会阻塞其他事务,支持高效读操作
- 支持事务的隔离性
缺点 - 需要存储多个版本数据,增加存储开销
- Undo日志产生额外的I/O和管理开销
- 垃圾回收不及时,导致性能下降
MVCC是如何与一致性视图(Read View)结合的
在MySQL中,read view是MVCC实现快照读的核心。事务在第一次执行快照读时,会生成一个一致性视图。记录当前活跃事务的事务ID列表
- 读取数据时,事务会根据read view来判断那些版本的数据时可见的
如何优化MVCC的使用
- 减少长事务:避免undo 日志的堆积
- 调整pruge回收策略
- 选择合适的隔离级别
- 索引优化
MySQL事务的二阶段提交是什么
二阶段提交是MySQL用来保证redo log 和binlog数据一致性的机制。redo log属于innodb存储引擎层,binlog属于service层。如果写入过程中宕机,就可能出两边数据不一致的问题。
事务提交的流程是:
- prepare阶段:事务提交时,InnoDB先把修改的数据写到redo log,但状态标记为prepare。表示我已经准备好了但是还没有真正提交
- commit阶段:redo log写完后,Service层把操作写到binlog。binlog写入成功后,再通知InnoDB将状态修改为commit。到此事务提交完成。
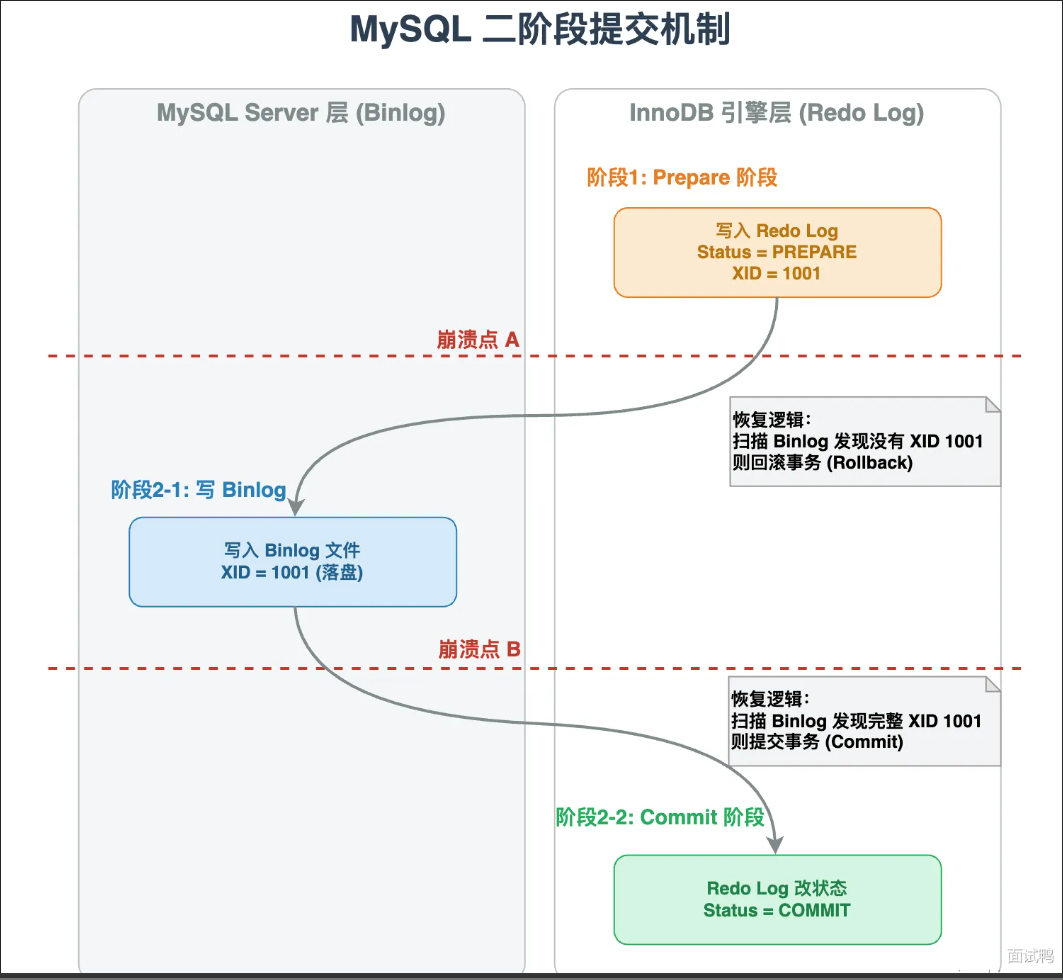
redo log和binlog各自管理的是什么
- redo log是InnoDB自己的日志,记录了数据页的物理修改。主要作用是崩溃恢复,保证已提交的事务数据不丢。
- binlog是service层的日志。记录的是逻辑操作(update/delete)。作用是:用于主从复制,数据恢复和备份归档。
两个日志各司其职,redo log保证单机数据的持久性,binlog保证数据能同步到从库,能做到时间点恢复。
MySQL中长事务可能会导致哪些问题
长事务带来问题的本质是:资占用时间过长,影响整个系统的稳定性和性能。
- 锁竞争严重,容易引发连锁反应。事务持有行锁,间隙锁的时间越长,其他事务等待时间就更久。容易将连接池打爆。
- 死锁风险增加。事务执行时间越长,持有的锁越多,和其他事务产生循环的概率越大。InnoDB索然有死锁检测机制,但检测本身也消耗资源。
- Undo Log膨胀。InnoDB的MVCC机制需要保留事务开始时的数据版本,长事务一直不提交,这个版本链就一直不能被清理。导致磁盘空间暴涨。
- 主从延迟。主库执行一个大事务要10分钟,binlog传到从库后,从库也要重放10分钟。这期间主从数据不一致,从库中读取到的都是脏数据。
- 回滚代价大。长事务一旦报错回滚,之前长时间的成果都白费,并且回滚本身也耗时。
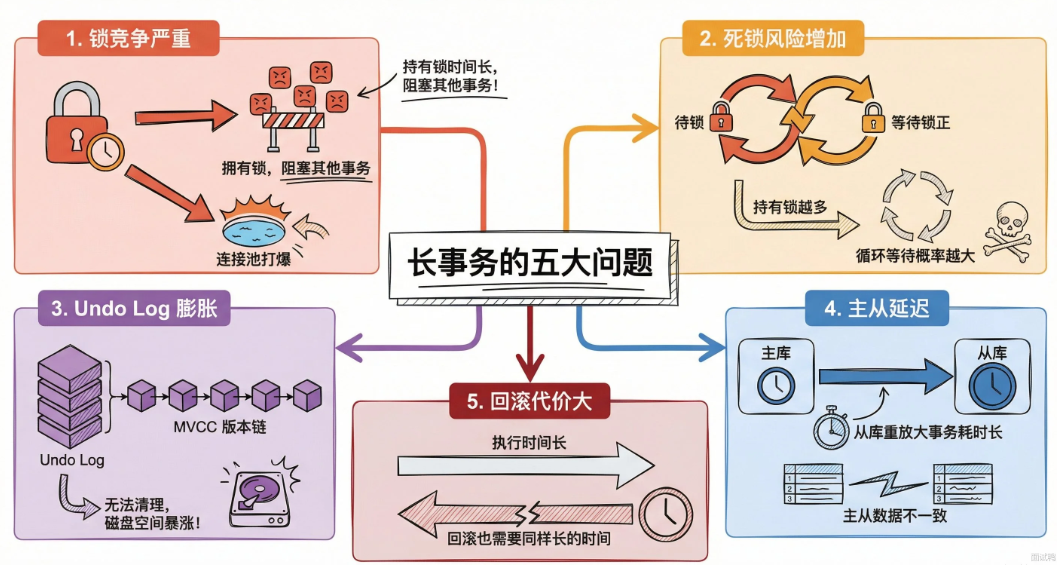
如何避免长事务的产生
- 事务中不要有RPC调用或者外部IO,因为他们的耗时不可控。
- 多可能异步:将发消息,写日志这些可以放到事务外面。
- 大批量数据分批提交
👉 这一章建议你强调:
MVCC + 锁 = 并发控制体系
四、锁机制(并发问题的补充)
掌握MySQL中的锁,先了解MySQL中有哪些锁(粒度/模式),掌握并发控制思想的乐观锁与悲观锁(具体如何实现,工程实际的选择),最后了解死锁的产生原因(如何避免)。
MySQL种有哪些锁
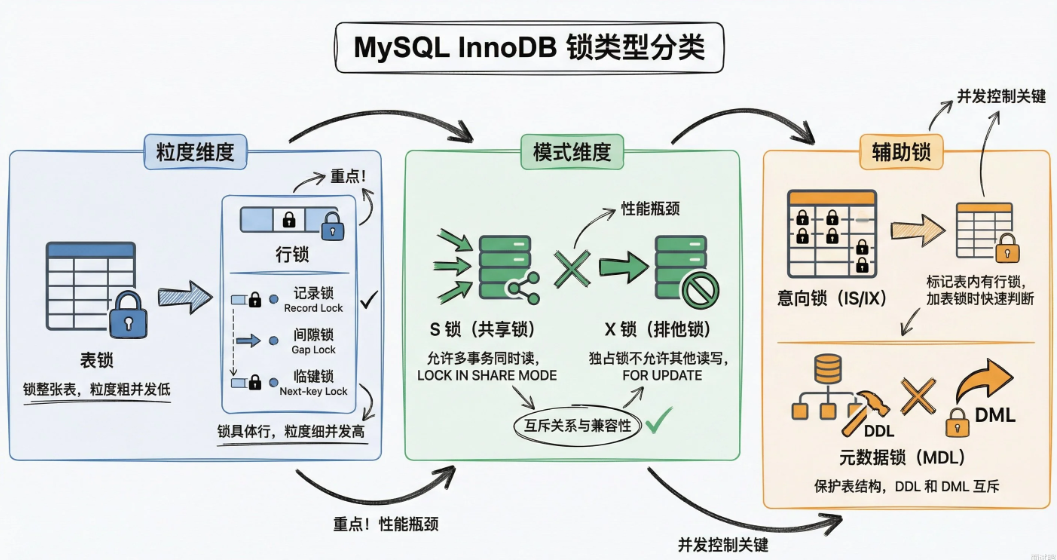
InnoDB中的锁主要可以从两个维度来区分:粒度和模式
粒度上分 :表锁+行锁。表锁锁整张表,行锁只锁具体的行,粒度越细并发越高。
模式上分 :共享锁S锁和排他锁X锁。S锁允许多个事务同时读,X锁独占,读写都不让碰。
行锁又细分为三种:记录行锁锁住具体那一行,间隙锁锁住两条记录之间的空隙防止插入,临键锁是记录锁+间隙锁的组合。
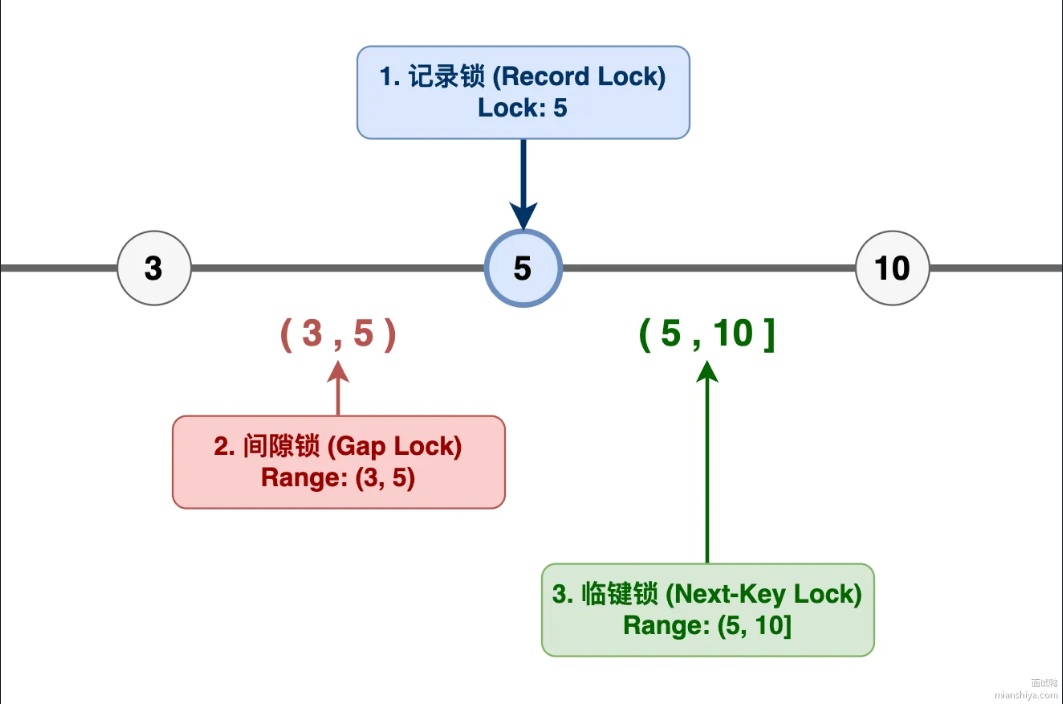
还有几个辅助性质的锁:
意向锁用来表示表里有没有行锁,加表锁的时候不用遍历;元数据锁MDL保护表结构,DDL和DML不能同时跑;插入意向锁表示事务在等着某个间隙插数据。
MySQL乐观锁和悲观锁是什么
乐观锁和悲观锁是一种思想:两种并发控制思想。本质在对于冲突的预期态度不同 。
悲观锁假设所有冲突一定会发生,所有操作数据前先把锁拿到,别的事务就必须等锁释放
MySQL中用SELECT...FOR UPDATE拿排他锁,用SELECT...LOCK IN SHARE MODE拿共享锁。拿到锁之后别的事务都会进行等待。直到事务提交或回滚才释放。
乐观锁假设冲突很少发生,默认不加锁,等到正真更新时再检查数据有没有被别人改过。通常用一个version字段来实现,读的时候把version一起读出来,更新的时候在WHERE条件里带上这个version,如果version改变,更新影响0行,业务层自己决定重试还是报错。
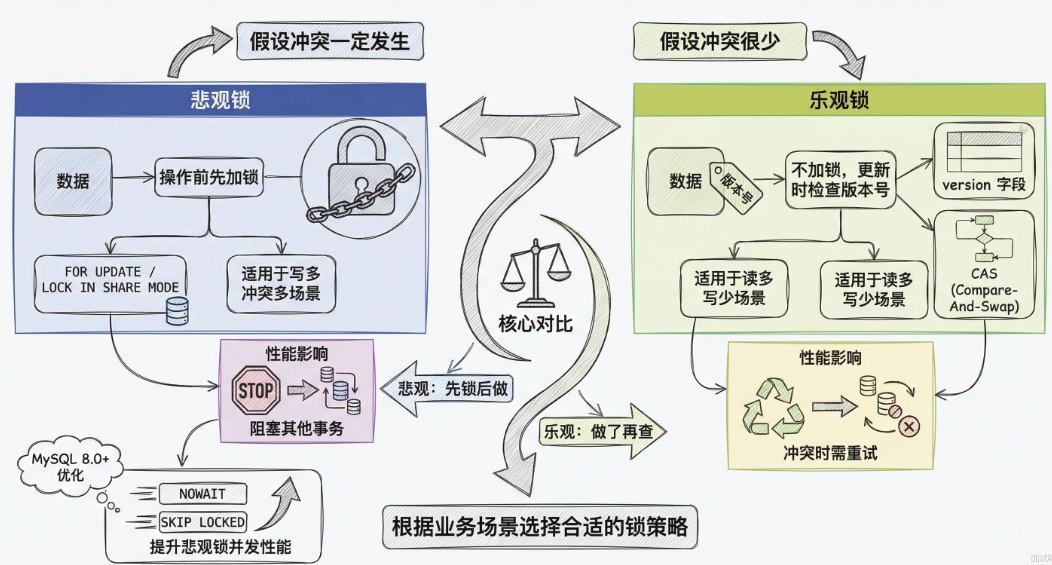
悲观锁的两种模式
- 排他锁X,SELECT...FOR UPDATE 拿到后别的事务读和写操作都会被阻塞
- 共享锁S,SELECT...LOCK IN SHARE MODE 都给事务可以同时持有同一行的S锁,但无法获取到X锁。
乐观锁的两种实现方式
1.版本号
sql
-- 读取数据和版本号
SELECT id, name, stock, version FROM products WHERE id = 1;
-- 假设读出来 version = 5
-- 更新时带上版本号
UPDATE products
SET stock = stock - 1, version = version + 1
WHERE id = 1 AND version = 5;
-- 检查影响行数
-- 如果返回 0 说明被别人改过,需要重试或报错2.CAS比较原值
sql
-- 假设读出来 stock = 100
UPDATE products
SET stock = 99
WHERE id = 1 AND stock = 100;减少了额外字段,但是会产生ABA问题。
关于乐观锁和悲观锁选择
乐观锁:
读多写少,冲突概率低。例如用户修改自己的资料,同一时间同一个用户修改同一条概率很低,用乐观锁省去加锁开销,吞吐量高
悲观锁:
写多冲突多。例如:热门秒杀商品
还有一种思路是先乐观后悲观。平时用乐观锁,如果冲突频发,转变为悲观锁
总结
乐观锁和悲观锁是两种并发控制思想。
面试从三点回答
- 定义的解释
- 两种锁实现的机制是什么
- 根据不同业务怎么去选择锁
乐观锁假设冲突不会发生,不加锁。在提交数据时如果发现数据被修改,则会拒绝当前事务并尝试,直到成功。悲观锁假设冲突一致存在,在操作的时候就加锁,其他事务不可访问
机制:乐观锁:版本号或CAS。版本号需要维护额外字段,但不会产生CAS的ABA问题
选择:读多写少用乐观,冲突多用悲观
MySQL发生死锁如何解决
两种方式:自动处理和手动干预
MySQL InnoBD自带死锁检测机制,默认开启。一旦检测到死锁,存储引擎会自动选自一个代价最小的事务回滚。释放他持有的锁让另一个事务继续执行。
另外还有兜底机制:锁等待机制。默认50秒,超时自动放弃并回滚。
手动干预主要用在自动机制不够快或者需要立刻恢复的场景。先SHOW ENGINE INNODB STATUS或者查INFORMATION_SCHEMA 里的锁相关表找到阻塞的线程ID,然后KILL<thread_id>杀掉它。
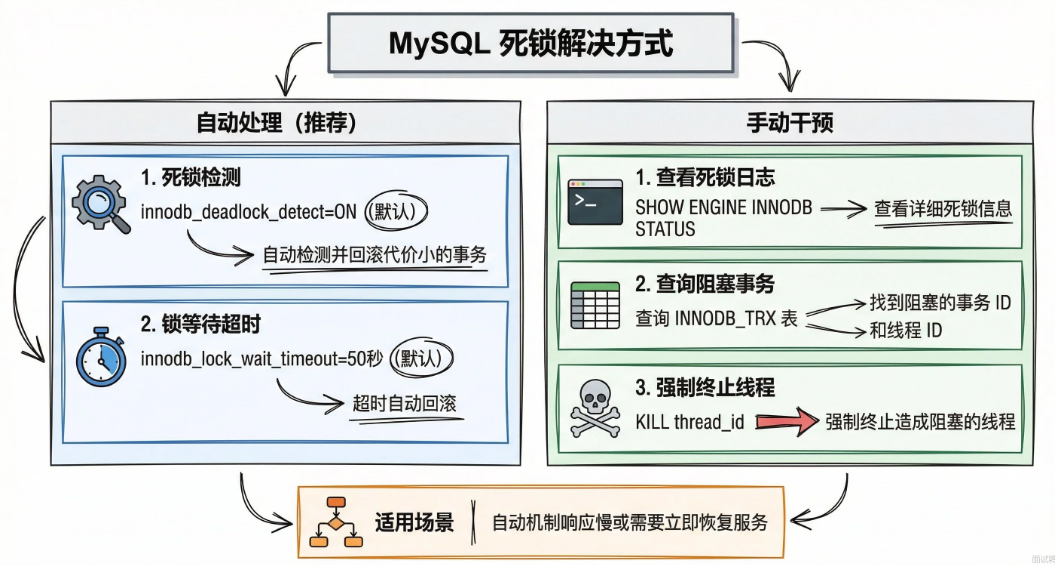
如何避免死锁
- 拆分大小事务。事务持有事件越长,死锁概率越高
- 固定加锁顺序。先锁A再锁B
- 降低隔离级别。可重复读比读已提交多了间隙锁和临键锁,锁的范围更大。如果业务允许,减少锁冲突
- 合理建索引。没命中索引会导致全表扫面。会锁全表
- 调整锁等待时间
总结
讲清楚:
- 说清楚MySQL中怎么处理死锁的(两种方式)
额外可说怎么避免死锁
👉 这一章主线:
锁解决的是"写冲突问题"
五、存储引擎(底层差异)
MySQL的默认引擎InnnoDB,除了这个还有什么呢?了解有哪些存储引擎(各个存储引擎的特点,为什么InnoDB成为主流)
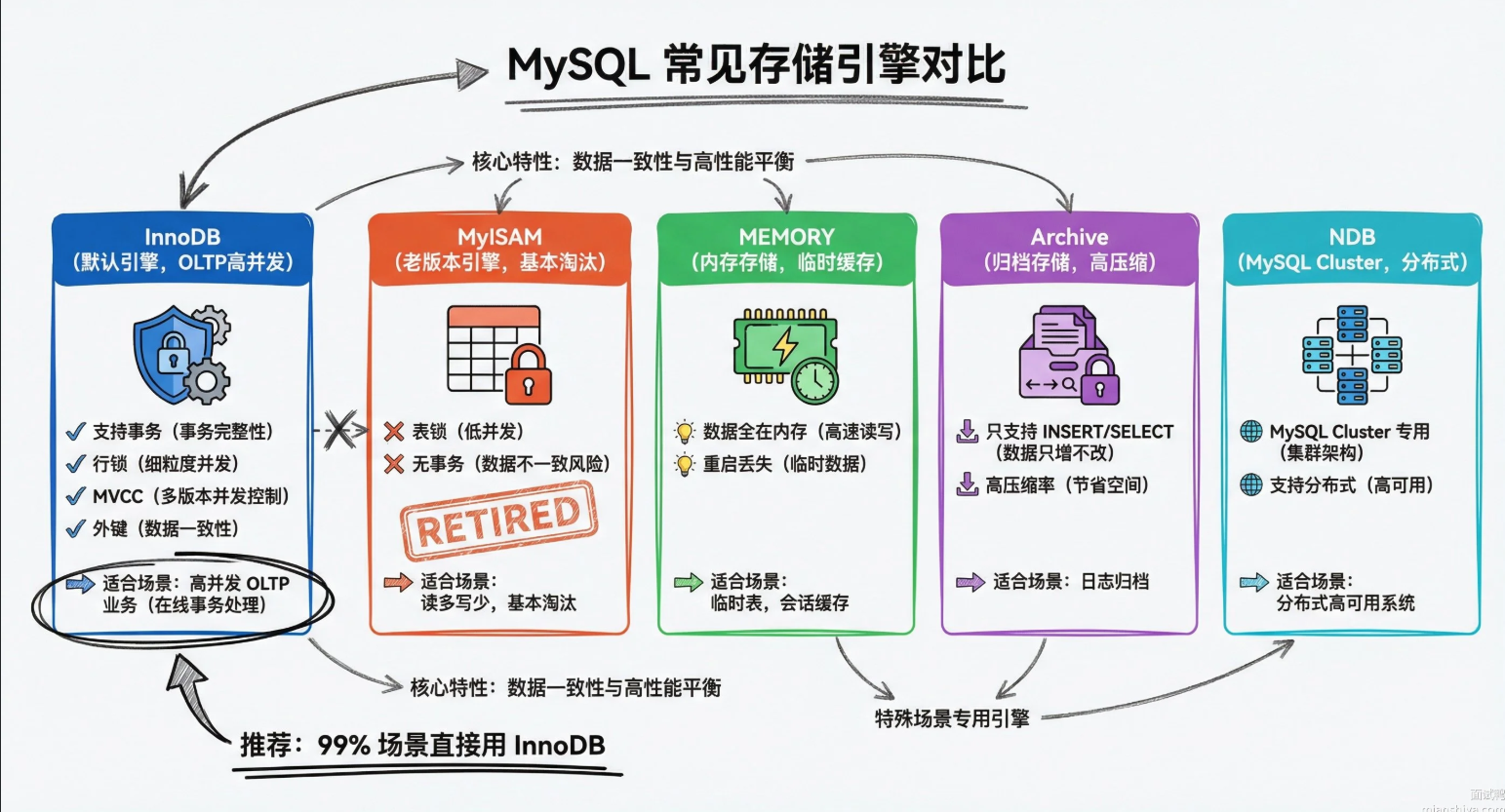
MySQL的存储引擎有哪些,他们之间有什么区别
MySQL的存储引擎是可插拔的,不同引擎辅助数据的存储与读取。实际场景中95%都是使用的InnoDB,面试主要讲InnoDB与MyISAM进行区分就行了
MySQL8.4版本一共提供了10个引擎,常见的有这几个:
1)InnoDB:MySQL5.5 之后的默认引擎,支持事务、行级锁、外键,MVCC也有,适合高并发的OLTP场景。数据按聚簇索引组织,主键查询贼快。
2)MyISAM:老版本的默认引擎,不支持事务,只有表级锁,但读性能不错。适合那种写少读多、对一致性要求不高的场景,比如早年的一些报表系统。
3)MEMORY:数据全放内存里,速度快但MySQL重启数据就没了。一般拿来做时表或者会话级缓存。4)Archive:专门存归档数据的,只支持INSERT 和 SELECT,不支持索引,但压缩率高。日志归档、历史订单这种场景用得上。
5)NDB:MySQLCluster用的引擎,支持分布式和高可用,数据自动分片,适合电信级别的大规模集群。
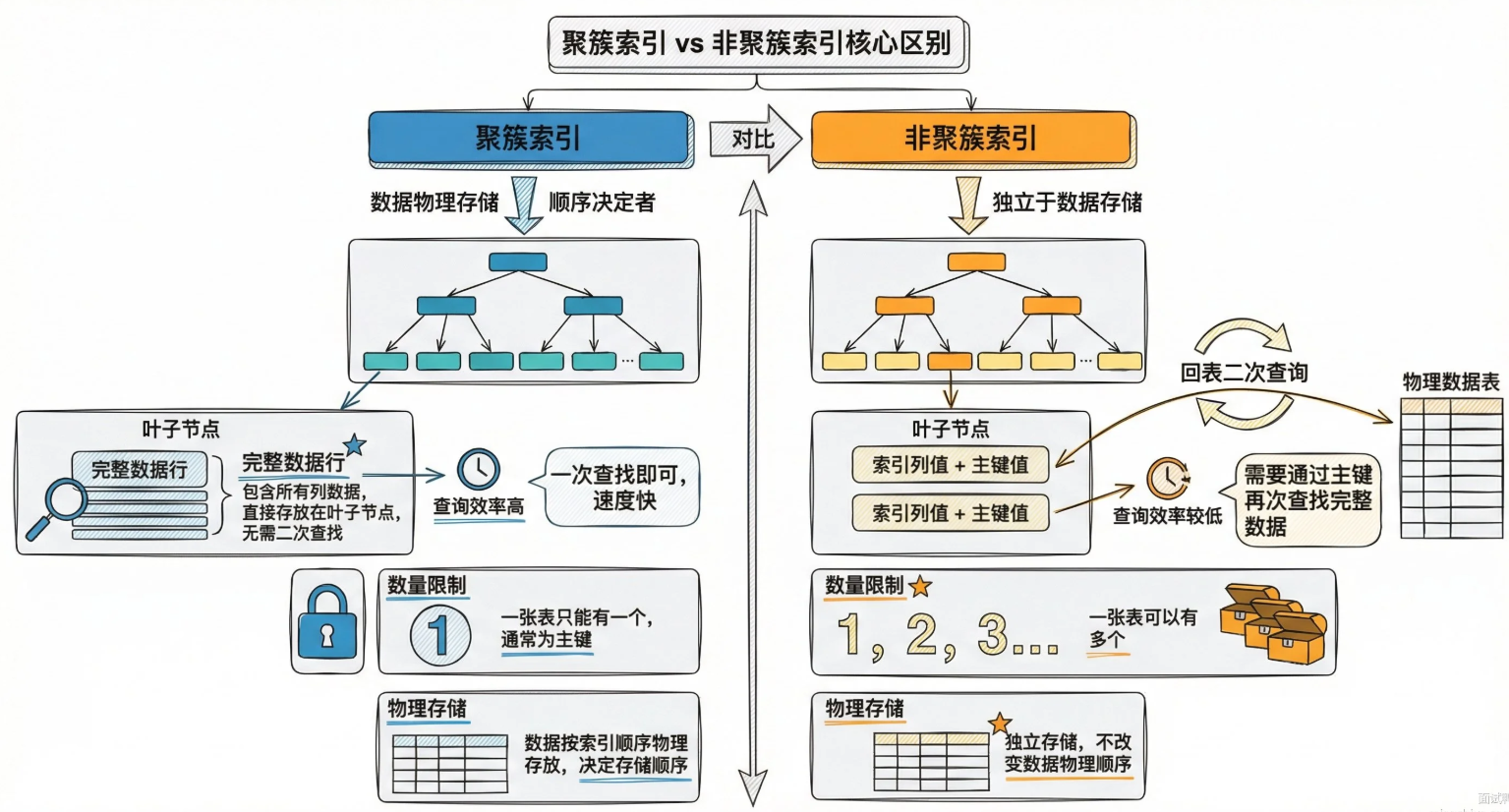
InnoDB存储引擎中聚簇索引和非聚簇索引有什么区别
在 InnoDB 引擎中,聚簇索引的叶子节点直接存储完整的数据行,一张表只能有一个聚簇索引,默认就是主键索引。非聚簇索引的叶子节点只存储索引列的值和主键,要拿到完整数据得先查主键再回表,一张表可以有多个非聚簇索引。
核心区别就是叶子节点存的东西不一样:聚簇索引存完整数据,非聚簇索引存主键值。这导致聚簇索引查询能一步到位拿到数据,非聚簇索引可能要多一次回表操作。
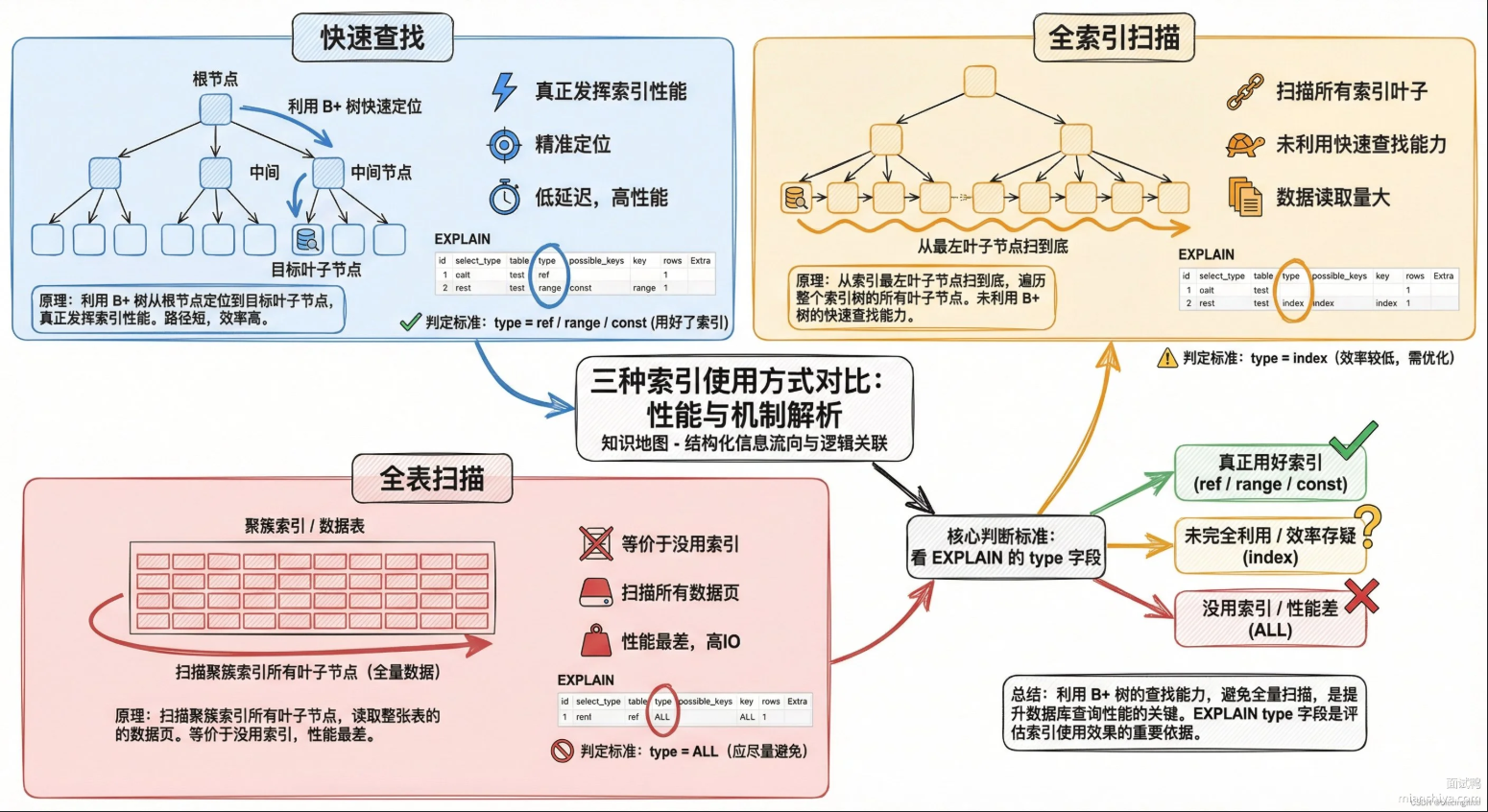
MySQL中使用索引一定有效吗?如何排查索引效果
索引不一定生效 。建了索引不代表查询会用,用了索引不代表查询就快。
MySQL最终是否走索引,靠的是优化器的成本计算。优化器会评估走索引和全表扫描各自的I/O成本和cpu成本。有时全表扫描确实成本低,比如表就几百行数据,走索引不如直接扫;有时统计信息不准,导致优化器算错账。
用EXPLAIN命令来排查索引。在SQL语句前面加上EXPLAIN,就能看到MySQL选择的执行计划,重点看:
- type:访问类型,all是全表扫描,range是范围扫描,ref是等值匹配,index是全索引扫描。
- key:实际用的索引名称,NULL就是没用上索引
- rows:预估扫描行数,这个数字越大说明查询代价越高。
索引失效常见场景
基本原因分为两类:1.查询条件导致索引树的快速查找能力用不上 2.优化器觉得不划算
1)联合索引不符合最左前缀
假设有个联合索引idx_name_age_id,查询写成WHERE age= 10 AND id = 1,跳过了 name字段,最左缀匹配失败,索引树的有序性利用不上,退化成全索引扫描甚至全表扫描。
2)索引列上做了运算
WHEREid+3=8这种写法,MySQL得把每行的id 拿出来算一遍,没法直接在索引|树上定位,只能全录扫描。
3)索引列上用了函数
WHERELOWER(name)='cong',对索引列套了函数,索引树里存的是原始值,函数处理后的值根本不在树里,还是得全表扫。MySQL8.0 可以建函数索引来解决这个问题。
4)LIKE左侧带通配符
WHEREnameLIKE%cong%'这种写法,索引是按字符顺序排的,左边不确定就没法定位起始位置,只能全扫。LIKE'cong%'是可以走索引的。
5)OR连接了非索引字段
WHEREname='cong'ORage= 18,如果age没索引l,MySQL没法通过索引l快速过滤 age 条件,整个查询可能退化成全表扫描。
6)隐式类型转换
name是Varchar 类型,查询写成 WHERE name = 1,MySQL会做隐式转换,相当于 WHERE CAST(nameAsignedint)=1,索引列上套了函数,索引失效。联表查询时两边字段编码不一致也有同样的问题。7)优化器认为全表扫描更划算
同一个索引,查热点数据可能走全表,查冷门数据走索引。比如订单表按商品ID 查,热门商品占了80%的订单,走索引反而要回表几十万次,不如直接全表扫描。
8)ORDER BY没配合好
ORDER BY 后面的字段不是主键,也不是覆盖索引,MySQL 可能选择全表扫描再排序,而不是走索引。
六、日志与数据安全(事务落地)
强调的不是MySQL实现的底层,而是事务提交的安全与可靠是如何实现的
MySQL事务的二阶段提交是什么
二阶段提交是MySQL用来保证redo log 和binlog数据一致性的机制。redo log属于innodb存储引擎层,binlog属于service层。如果写入过程中宕机,就可能出两边数据不一致的问题。
事务提交的流程是:
- prepare阶段:事务提交时,InnoDB写把修改的数据写到redo log,但状态标记为prepare。表示我已经准备好了但是还没有真正提交
- commit阶段:redo log写完后,Service层把操作写到binlog。binlog写入成功后,再通知InnoDB将状态修改为commit。到此事务提交完成。
redo log和binlog各自管理的是什么
- redo log是InnoDB自己的日志,记录了数据页的物理修改。主要作用是崩溃恢复,保证已提交的事务数据不丢。
- binlog是service层的日志。记录的是逻辑操作(update/delete)。作用是:用于主从复制,数据恢复和备份归档。
两个日志各司其职,redo log保证单机数据的持久性,binlog保证数据能同步到从库,能做到时间点恢复。
MySQL中长事务可能会导致哪些问题
长事务带来问题的本质是:资占用时间过长,影响整个系统的稳定性和性能。
- 锁竞争严重,容易引发连锁反应。事务持有行锁,间隙锁的时间越长,其他事务等待时间就更久。容易将连接池打爆。
- 死锁风险增加。事务执行时间越长,持有的锁越多,和其他事务产生循环的概率越大。InnoDB索然有死锁检测机制,但检测本身也消耗资源。
- Undo Log膨胀。InnoDB的MVCC机制需要保留事务开始时的数据版本,长事务一直不提交,这个版本链就一直不能被清理。导致磁盘空间暴涨。
- 主从延迟。主库执行一个达十五要10分钟,binlog传到从库后,从库也要重放10分钟。这期间主从数据不一致,从库中读取到的都是脏数据。
- 回滚代价大。长事务一旦报错回滚,之前长时间的成果都白费,并且回滚本身也耗时。
如何避免长事务的产生
- 事务中不要有RPC调用或者外部IO,因为他们的耗时不可控。
- 多可能异步:将发消息,写日志这些可以放到事务外面。
- 大批量数据分批提交
事务实现机制(可引用)
七、SQL 调优与执行分析(实战部分)
从如何优化SQL语句出发,进一步掌握如何判断MySQL具体执行走了什么索引(EXPLIAN语句),最后掌握实际工程问题深分页问题。
MySQL怎么进行SQL调优
SQL调优核心思路是减少磁盘I/O和避免无效计算 。分为三步流程:先定位慢SQL,再分析执行计划,最后针对性能优化。
定位慢SQL靠MySQL查询日志,分析执行计划用EXPLAIN,优化手段主要有几类:
- 索引优化
合理设计索引,利用覆盖索引避免回表。
注意最左前缀原则
避免在索引上做函数运算 - SQL写法优化
禁止写select *,只查必要字段,减少网络传输和内存占用
避免%like 前缀模糊查询,like '%关键词'必然全表扫描
连表查询时检查字段字符集是否一致 - 架构优化
热点数据上Redis缓存,访问频率高但变化少的数据没必要每次查询数据库
大表考虑分库分表,单表超过2000万行查询性能明显下降
读写分离,把查询压力分摊到从库
还可以通过业务来优化,少展示不必要的字段,减少多表查询的情况,将列表查询替换成分页分批查询。
总结
优化SQL的本质是为了减少磁盘I/O和避免无效计算
我们分为三步走:先定位慢SQL(MySQL慢查询日志),再分析执行计划(EXPLAIN),最后针对性优化
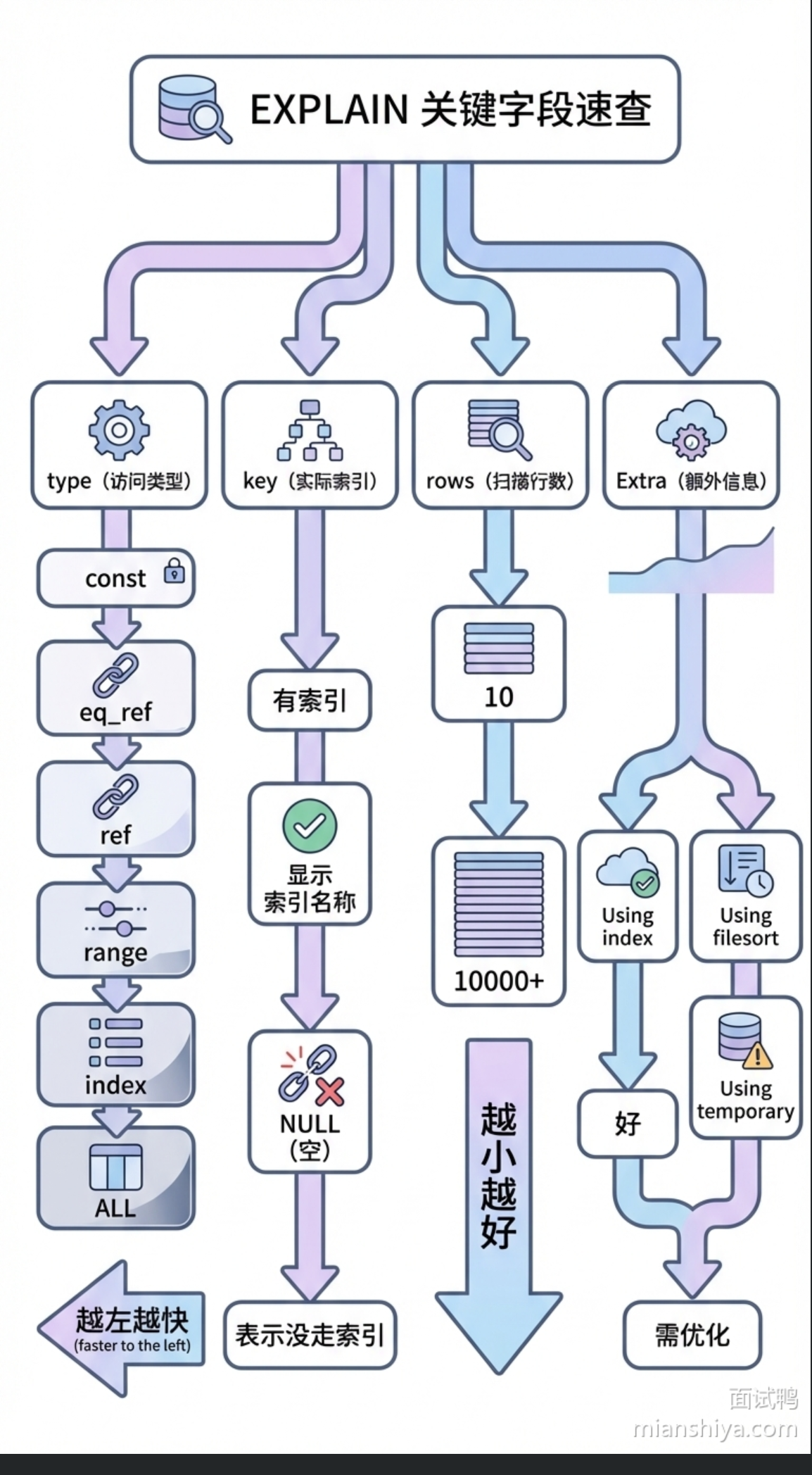
解释一下MySQL的EXPLAIN语句查询
在select语句前加上explain就能看到优化器是如何执行这条语句的。关注有一下几个字段:
- **type访问类型 **,直接决定查询效率。性能从高到底排列:const>eq_ref>ref>range>index>all。
- key实际用到的索引。如果显示NULL表示没走索引
- rows预估要扫描的行数。越小越好
- Extra额外信息藏着很多细节。Usingindex说明走了覆盖索引l,数据直接从索引拿不用回表;Usingfilesort 说明排序没法用索引得额外排序;Using temporary 说明用了临时表,这两个一般都需要优化
type的每个级别具体含义:
const:主键或唯一索引|等值查询,最多一行匹配,最快eq_ref:连接查询里通过主键或唯一索引关联,每次只取一行ref:用非唯一索引查,可能返回多行
range:索引范围扫描,用在 BETWEEN、>、<这类条件上index:扫描整棵索引树,比ALL 好但还是很慢
ALL:全表扫描,遇到大表直接起飞
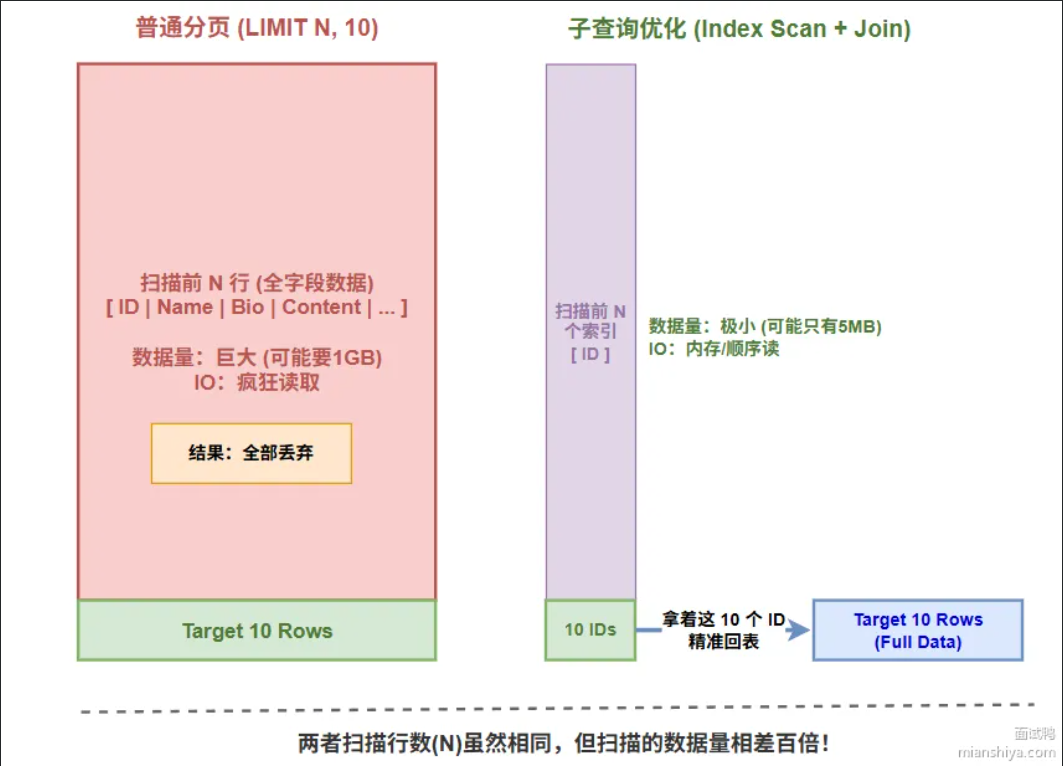
如何解决MySQL中的深分页问题
先分析原因:limit 99999999,10这种写法会让MySQL扫描前99999999条记录并丢弃,浪费了大量IO。解决思路就是减少扫描的数据量,常用的优化方案有三种:
- 子优化查询
把原本的查询拆分成两步:先用子查询在二级索引上快速定位起始id,再用这个id去主键索引取数据
sql
-- 原始写法,慢
SELECT * FROM mianshiya
WHERE name = 'yupi'
ORDER BY id
LIMIT 99999990, 10;
-- 优化写法
SELECT * FROM mianshiya
WHERE name = 'yupi'
AND id >= (
SELECT id FROM mianshiya
WHERE name = 'yupi'
ORDER BY id
LIMIT 99999990, 1
)
ORDER BY id
LIMIT 10;简单理解为,先用子查询查询到第999999的id是多少,拿去到这个id后直接从999999位后面开始查询,避免了扫描前面的数据。
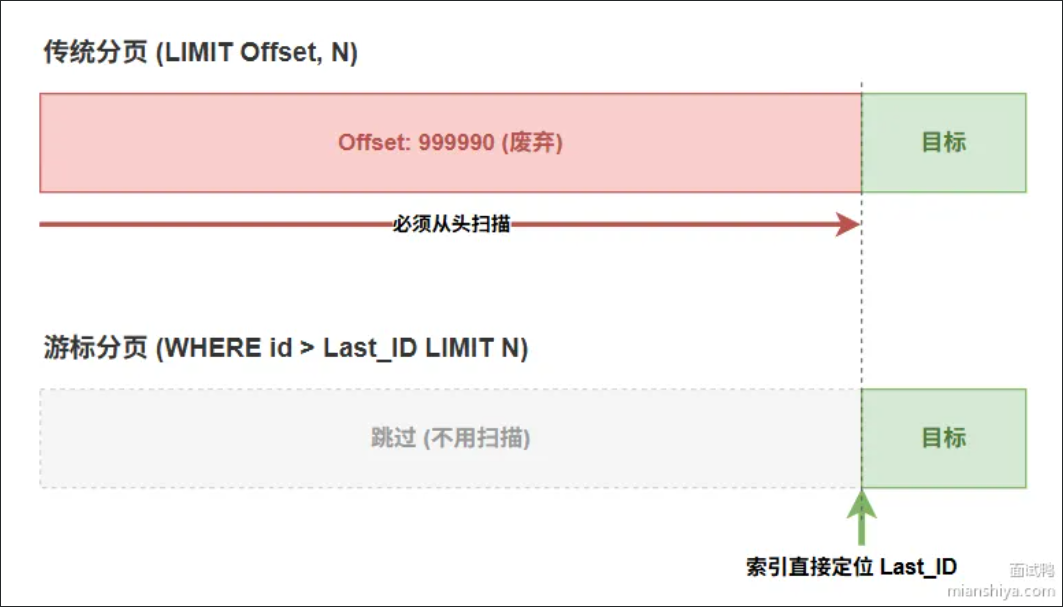
- 游标分页
每次查询都返回当前页最大id,下次查询时带上这个id作为起点
sql
-- 第一页
SELECT * FROM mianshiya WHERE name = 'yupi' ORDER BY id LIMIT 10;
-- 假设最大 id 是 100
-- 第二页
SELECT * FROM mianshiya WHERE name = 'yupi' AND id > 100 ORDER BY id LIMIT 10;利用id>maxId直接过滤,MySQL可以从索引定位到起始位置,不要扫描前面的数据。
缺点是只能连续翻页,无法直接跳到10000页
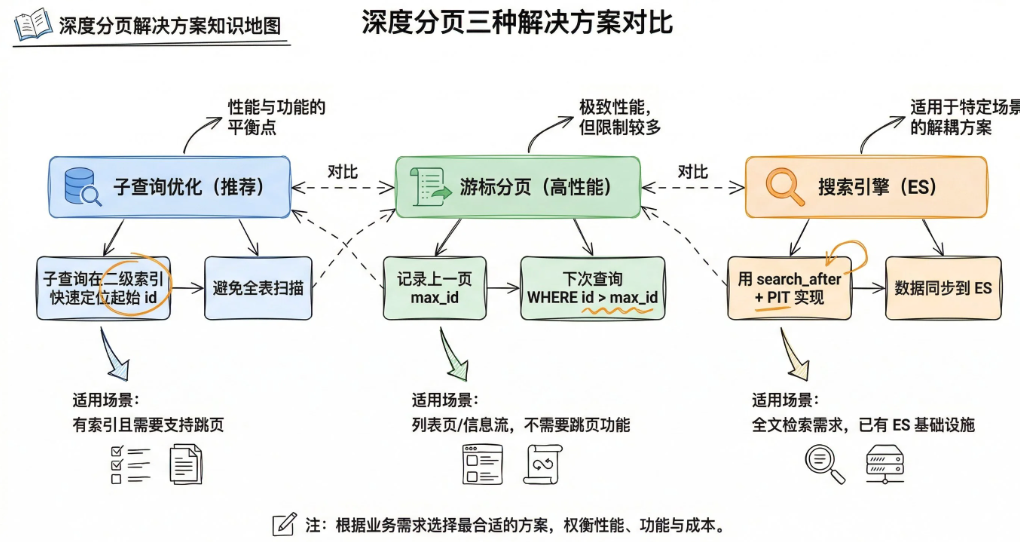
- 搜索引擎
把数据同步到Elasticsearch,用search------after做深度分页。
总结
先说明深分页问题是什么,然后从三个方面来解决
- 子查询优化
- 游标分页
- 搜索引擎
👉 这一章主线:
一切优化,本质都是减少 IO + 减少扫描
八、主从复制与架构(进阶)
从MySQL的主从复制机制开始(掌握怎么实现的,有哪些复制模式),接着进阶如何处理MySQL的主从同步延迟
什么是MySQL的主从同步机制,它是如何实现的
核心原理:
主库把所有"数据变更操作"写进 binlog,从库把这些操作读过来再执行一遍
MySQL的主从同步的核心就是binlog复制:主库把写操作记录到二进制日志中,从库拉过来重放一遍,数据就同步了。
整个流程涉及三个线程配合:
- 主库的dump线程:监听binlog变更,有新内容就推事件给从库
- 从库的I/O线程:拉去主库数据,把收到的binlog写进本地的relay log
- 从库的SQL线程:读取relay log,逐条执行SQL语句
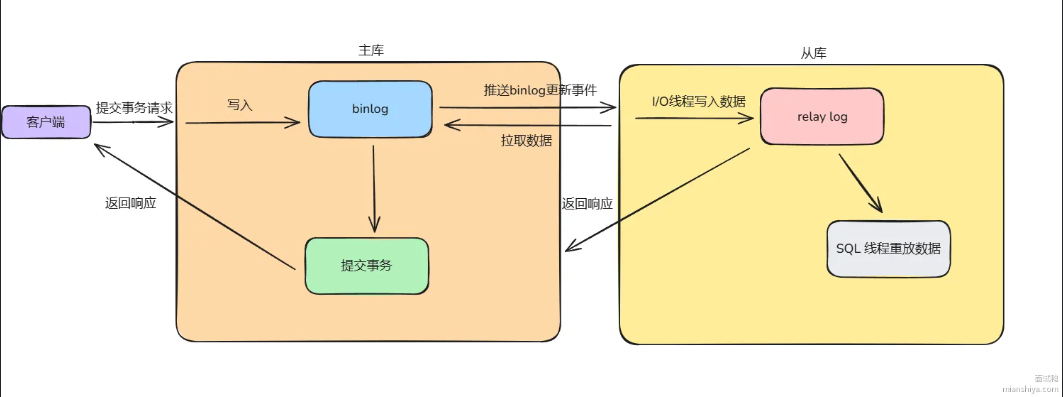
MySQL支持三种复制模式
MySQL支持异步,同步,半同步三种复制模式,区别在于之看什么时候给客户端返回响应:
| 复制模式 | 主库返回时机 | 性能 | 数据可靠性 |
|---|---|---|---|
| 异步复制 | 写完 binlog 立即返回 | 最高 | 最低,主库挂了数据可能丢 |
| 同步复制 | 等所有从库确认 | 最差 | 最高 |
| 半同步复制 | 等至少 N 个从库确认 | 折中 | 较高 |
| MySQL默认是异步复制,主库写完binlog就直接返回,压根不管从库有没有收到。好处是快,坏处是主库突然挂了,哪些还没同步过去的数据就丢了 |
总结
一句话:MySQL 主从同步 =主库写binlog;dump线程推送变更事件;从库拉去数据;从库I/O线程写中继日志;SQL线程重放。
MySQL默认是异步复制,主库binlog就直接返回不管从库有没有收到。
如何处理MySQL的主从同步延迟
主从延迟必然存在 ,不可能完全删除,只能短暂缩短延迟事件或在业务层面来规避。
业务层面常见的处理方式:
- 关键业务强制走主库。比如用户注册完立马登录,写后读的场景直接走主库。
- 延迟感知。写操作后记录事件戳,短时间内的读请求强制走主库,过了延迟窗口再走主库。
- 二次查询兜底。从库查不到就再查一次主库,属于兜底策略。
- 缓存前置。写入主库的同时写入缓存,读请求先查缓存。