阿里云服务器迁移实战(一)——Mysql平滑迁移
一、背景
- 由于业务原因,需要把服务器从外部阿里云账号迁移到阿里云账号
- 其中最重要的就是数据库迁移,要保证数据不能丢失,设计完善的迁移和回滚方案
二、方案设计
1.迁移要求
- 数据一致:项目业务数据允许短时间(5分钟内)不一致,但要保证数据的最终一致性
- 同步方式:迁移中要包含某个时间点的全量同步,以及后续持续的增量同步让新库的数据追平旧库
- 一致性保证:迁移后要做一致性校验,确保新库和老库数据一致
- 回滚方案:如果新库出现问题,需要无缝切换回旧库
2.方案选型
| 方案类型 |
具体实现 |
|
| 停机全量迁移 |
先暂停数据写入,全量迁移数据,恢复服务写入新库 |
不适用当前场景,无法长时间停机,且难以回滚 |
| 数据库双写 |
数据同时写入新库和老库,新库稳定后再完全迁移 |
流程复杂,改造成本高 |
| 增量迁移(采用) |
指定时间点全量迁移,再增量同步追平数据 |
对业务改动少,且有清晰可控的回滚方案 |
3.迁移工具
- 因为是迁移源数据库和目标数据库都是阿里云,选择阿里云DTS(数据传输服务)来做迁移
三、迁移方案
1.迁移时序图
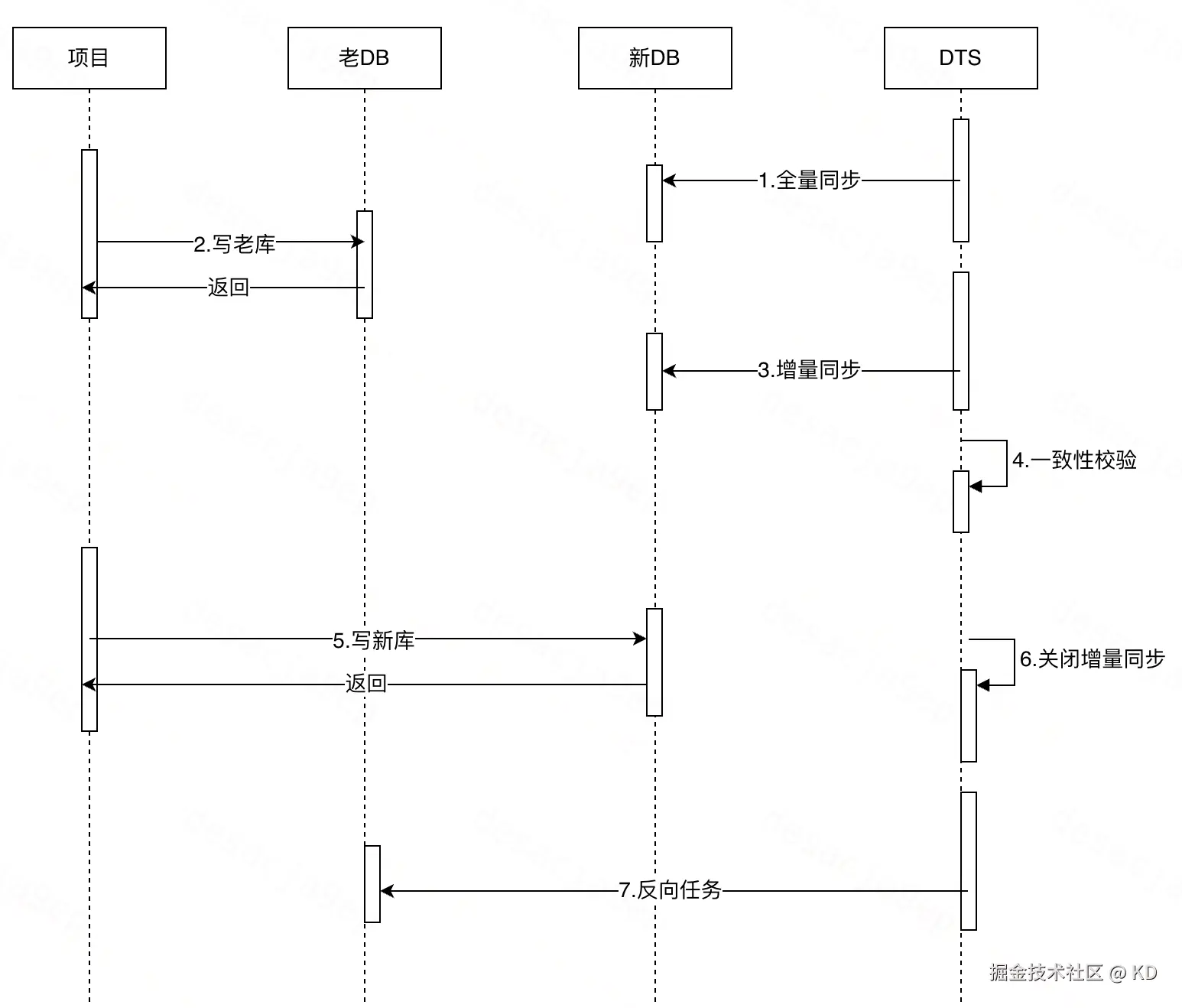
2.具体迁移步骤
- 全量同步:DTS指定当前时间点,开始做全量数据同步,同时开始增量数据采集,记录当前时间点开始后写入老库的所有数据
- 数据写老库:此时数据还在写入老库,原有项目未做任何改动
- 增量同步:DTS全量同步完成,开始增量同步,新库数据逐渐追平老库
- 一致性校验:DTS可以对全量同步和增量同步的数据分别做校验,可以对数量和数据内容做比对
- 切换写新库:数据校验无异常,切换项目中数据库地址到新库,数据开始写入新库
- 关闭增量同步:DTS暂停增量同步,这时老库已经不写入数据了
- 反向任务:DTS开启反向任务,新库数据增量同步给老库,用于回滚
四、回滚方案:
1.思路
- 核心是反向任务,让新库的数据一直增量同步回老库
- 因此我们相当于用DTS的正向和反向传输任务,建立起了数据同步的双向通道
2.具体回滚操作
- 回滚数据源:切换项目中数据库地址回老库,数据开始写入老库
- 关闭反向任务:DTS暂停反向任务,数据都写到老库,新库没有数据要同步到老库了
- 开启DTS正向同步:DTS开启刚才暂停的正向同步,为后面的切换做准备
五、遇到的问题与解决
1.切换后接口报504
- 问题背景:这个接口是提供给管理中台调用的,用来管理平台账号
- 问题分析:504异常比较少见,是Gateway Timeout,即接口响应超时,链路比较长,要逐步排查
- 具体排查 :
- 项目error日志:项目中未见相关error日志
- Controller层日志:未见到Controller层日志,(这里有个坑,实际是应该有的,但是AOP切面只抓public方法,这个方法没有用public修饰)
- nginx日志:项目是通过nginx反向代理的,找access.log,可以看到请求确实到了nginx
- 看nginx超时时间:并未配超时时间,默认的超时时间是60秒。这里接口报504只用了10秒,基本确定了是管理中台的网关报超时了
- 排查接口性能:没有错误日志,那就是单纯的超时了,因为迁移前数据库在同一个阿里云的内网,迁移后需要走公网到另一个阿里云服务器,重点排查多次数据库请求
- 定位原因:在循环中写了SQL查询,115个账号查了300多次SQL,同时走公网导致性能变慢,从1100毫秒到18秒,导致接口超时
- 解决方案:优化SQL,改为批量查询
2.切换后高峰期上游服务线程池积压
- 紧急止损:数据库执行回滚操作
- 初步分析 :
- 可能是数据库本身性能问题
- 也可能是多次公网数据库查询导致接口响应变慢,导致超时
- 排查数据库性能 :在小高峰期切回新库调整参数
- 增大sort_buffer_size:参考旧数据库参数,调大了排序缓存,积压情况并未缓解
- 开启change_buffer:服务写入操作相对较多,开启change_buffer想提升写入性能,但执行命令查看数据库状态,innodb并未使用change_buffer,可能是因为change_buffer使用条件较为苛刻,写入并未用到二级非唯一索引
- 调整innodb_buffer_pool_size:先稍微调小缓冲池,再调大,发现innodb_buffer_use_ratio(缓冲池使用率)仅有75%,但innodb_buffer_read_hit(缓冲池命中率)为99.99%,缓冲池大小已经完全足够了,不是缓冲池的大小问题
- 结论:基本排除数据库性能问题,排查到部分核心接口也有循环内SQL查询,基本确定是多次公网查询导致
- 解决方案:新项目部署到新服务器上,走内网连接新数据库。小流量验证功能后,全量切换,未再出现线程池积压异常