从 Spring Boot 项目理解 RAG:ingest、query、rerank、trace 到 eval
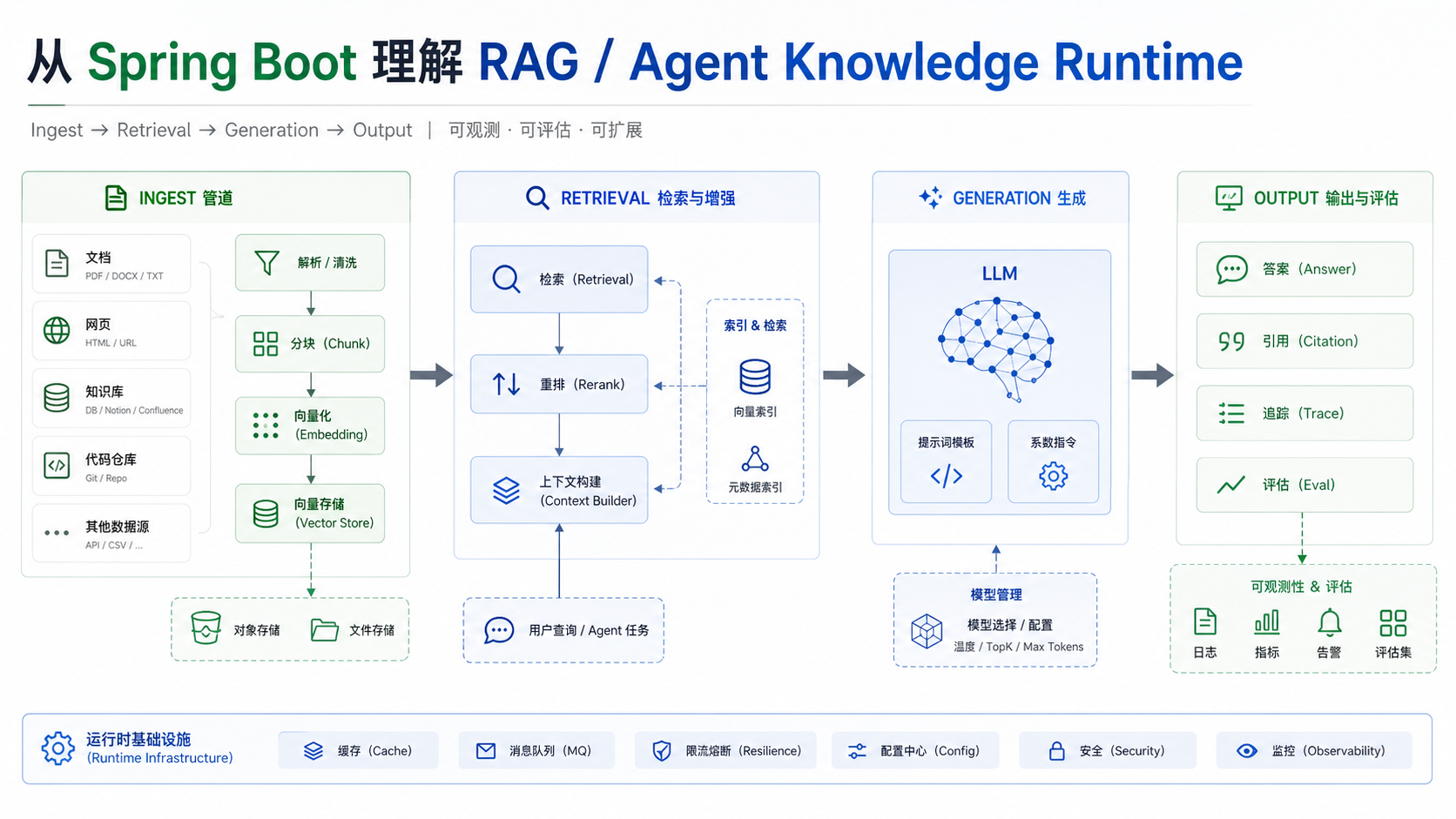
很多后端开发者第一次接触 RAG 时,容易把注意力放在大模型本身:
"是不是换一个更强的模型,效果就会更好?"
但真正开始设计 RAG 系统后会发现,LLM 只是链路中的一环。一个可用的 RAG 系统,核心不只是"生成答案",而是围绕知识资料建立一套完整的工程闭环:
- 资料如何进入系统?
- 资料如何被切分和存储?
- 用户问题如何检索到相关内容?
- 检索结果如何筛选?
- 答案如何带上引用来源?
- 一次回答过程如何复盘?
- 系统效果如何评估和持续改进?
本文从一个 Spring Boot 后端项目的角度,梳理一个最小 RAG 系统应该具备的几个关键模块:ingest、query、rerank、trace 和 eval。
对应项目:
- GitHub:https://github.com/huajiexiewenfeng/agent-knowledge-runtime
- 当前版本:v0.1
- 技术栈:Spring Boot、Spring Data JPA、H2、Maven
这篇文章不是完整源码讲解,而是专栏的第一篇:先建立全局工程地图。后续文章会分别展开项目骨架、文档导入链路、查询链路、trace 设计和 eval 体系。
也需要先说明这个项目的定位:
它首先是一个 Spring Boot 版 RAG 学习骨架,用来理解 RAG 如何从概念落到工程结构,而不是为了替代 WeKnora、Dify、NotebookLM 这类成熟知识库产品。
这类成熟产品已经覆盖了大量生产能力,比如多源导入、权限、UI、知识库管理、复杂解析、向量检索和运维能力。这个项目更适合用来学习和拆解:
- RAG 的每个环节为什么存在
- 每个能力在 Spring Boot 项目中可以如何抽象
- 哪些地方可以接入 embedding model、rerank model、chat model 和 eval model
- 后续如何把成熟知识库产品作为外部能力集成进来
1. RAG 的核心:不是让 LLM 记住更多,而是让它有证据回答
RAG 的全称是 Retrieval-Augmented Generation,中文通常叫"检索增强生成"。
可以拆成三部分:
- Retrieval:从知识库中检索相关资料
- Augmented:把检索结果作为上下文提供给大模型
- Generation:大模型基于上下文生成答案
也就是说,RAG 的重点不是让 LLM 直接凭记忆回答,而是先从你的资料库里找到证据,再让模型基于证据回答。
一条典型链路可以分成三层:
RAG Request
Retrieval Layer
Generation Layer
Quality Layer
retriever / chunks / context
LLM / answer
citation / trace / eval
从工程视角看,RAG 系统不是一个简单的"调用大模型接口",而是一个围绕知识、检索、上下文、引用和评估构建的后端系统。
2. ingest:资料如何进入系统
ingest 可以理解为知识进入系统的入口。
在一个 Spring Boot 项目中,ingest 模块通常负责:
- 接收原始文档
- 解析文档格式,比如 Markdown、PDF、HTML、Word
- 清洗无用内容
- 按规则切分成 chunk
- 为 chunk 生成 metadata
- 存储到数据库或向量库
为什么不能直接把整篇 Markdown 塞给 LLM?
因为整篇文档往往包含大量无关内容,会带来几个问题:
- token 成本过高
- 上下文污染
- 关键信息被噪声稀释
- LLM 更容易被不相关信息带偏
- 无法精确标注 citation
ingest 的主流程可以这样理解:
Raw Document
Parse / Clean
Chunking
Metadata
Embedding
Vector Store
这里的 chunk 可以理解为 RAG 系统中的"最小知识单元"。
每个 chunk 通常会包含:
| 字段 | 作用 |
|---|---|
chunkId |
唯一标识 |
content |
片段正文 |
sourcePath |
来源文件 |
heading |
所属标题 |
chunkIndex |
在文档中的顺序 |
metadata |
标签、项目、权限等信息 |
embedding |
语义向量 |
一句话概括:
ingest负责把原始资料加工成系统可以检索和引用的知识单元。
3. query:问题如何变成一次 RAG 请求
query 是用户提问之后的主链路。
它通常包含几个步骤:
- 接收用户问题
- 将问题转换为检索条件
- 从知识库中检索相关 chunk
- 构建上下文
- 调用 LLM 生成答案
- 返回答案和 citation
- 记录 trace
如果节点太多,强行画成一条长流程图,阅读体验会很差。更适合按职责分层:
Question
Retrieve Stage
Context Stage
Generation Stage
Response Stage
embedding / topK / rerank
selected chunks / prompt context
LLM answer
answer / citations / traceId
在 Spring Boot 项目里,代码结构可以按职责拆分:
Controller:接收 HTTP 请求Service:编排一次 query 流程Retriever:负责检索 chunkContextBuilder:负责构建 LLM 上下文AnswerComposer:负责组织答案CitationBuilder:负责生成引用TraceService:负责记录过程
这样设计的好处是,每个环节都可以独立演进。
比如早期可以先用关键词检索,后续再替换成向量检索;早期可以直接拼接上下文,后续再加入 rerank 和 prompt 模板。
4. TopK 与 rerank:低成本召回与高成本精选
很多人会问:
既然最后只给 LLM 3 到 5 个 chunk,为什么不一开始就直接取 TopK=3 或 TopK=5?
原因在于:第一阶段检索的 score 和 rerank 的 score 不是同一种东西。
第一阶段 TopK 通常使用低成本方式快速召回,比如:
- 向量相似度
- BM25
- 关键词匹配
- 混合检索
它的目标是:
快速从大量 chunk 中找出可能相关的一批候选。
而 rerank 通常使用更昂贵但更精细的模型或规则,对候选 chunk 重新排序。
它的目标是:
从候选中挑出最能支撑当前问题答案的少数 chunk。
可以这样理解:
| 阶段 | 目标 | 特点 |
|---|---|---|
| Retriever / TopK | 召回候选 | 快、便宜、偏 recall |
| Reranker | 精选证据 | 慢、贵、偏 precision |
一个成熟一点的链路通常是:
All Chunks
Cheap Retrieval
TopK = 20
Expensive Rerank
TopN = 3~5
Context Builder
所以,retrieve 和 rerank 的关系可以总结为一句话:
Retrieve 是低成本召回,rerank 是高成本精选。
第一阶段尽量别漏掉可能有用的候选;第二阶段再把真正有用的 chunk 挑出来,避免把噪声塞给 LLM。
5. citation:答案可以由 LLM 生成,但证据链最好由系统控制
RAG 系统里,citation 非常重要。
它解决的是:
- 答案来自哪里?
- 用户能不能追溯来源?
- 系统有没有基于证据回答?
- 后续 eval 能不能判断答案是否可信?
这里有一个重要原则:
LLM 可以生成答案,但 citation 最好由系统生成。
原因很简单:如果让 LLM 自己编 citation,它可能会引用不存在的文件、错误的标题,甚至生成看起来合理但实际不存在的来源。
更稳妥的做法是:
- Retriever 找到 chunk
- 每个 chunk 本身带有 metadata
- LLM 基于 chunk 内容生成答案
- 系统根据 retrieved/selected chunks 组装 citation
例如:
json
{
"answer": "项目后端使用 Spring Boot 构建。",
"citations": [
{
"sourcePath": "docs/design.md",
"heading": "技术选型",
"chunkId": "chunk_001"
}
]
}需要注意的是:
retrieved chunks 不一定等于 answer actually used chunks。
检索阶段可以多召回一些,但 citation 阶段应该更克制。
如果一个答案实际只依赖 1 个 chunk,就不应该把所有相似 chunk 都作为 citation 返回。否则 citation 会变宽,降低证据精度。
更理想的设计是区分:
retrievedCitations:检索候选来源answerCitations:真正支撑答案的来源
6. trace:不是普通日志,而是一次 RAG 请求的执行轨迹
在传统后端系统里,我们很熟悉 log。
但 RAG 系统里的 trace 和普通日志不完全一样。
普通日志偏向记录运行状态:
log
INFO Query request received
INFO Retrieved 5 chunks
INFO Answer generated而 trace 更像一次请求的结构化过程记录:
json
{
"traceId": "trace_123",
"events": [
{
"type": "QUERY_RECEIVED",
"detail": "用户提出的问题"
},
{
"type": "CHUNKS_RETRIEVED",
"detail": "检索到了哪些 chunk"
},
{
"type": "CONTEXT_BUILT",
"detail": "最终给 LLM 的上下文"
},
{
"type": "ANSWER_GENERATED",
"detail": "生成的答案"
}
]
}trace 解决的问题是:
- 这次回答为什么会这样?
- 检索到了哪些 chunk?
- 哪些 chunk 被放进了 context?
- LLM 是否基于证据回答?
- citation 是否和证据一致?
- 如果回答失败,问题出在哪一环?
没有 trace,就很难复盘一次 RAG 请求。
可以说:
trace 是 AI 系统的可复盘能力。
7. eval:没有评估,就没有持续改进
RAG 系统上线后,真正困难的不是"能回答",而是"回答得是否稳定可靠"。
这就需要 eval。
eval 不是简单看接口是否返回 200,而是要判断:
- 答案是否正确
- 是否基于检索证据
- citation 是否准确
- 是否遗漏关键内容
- 是否引入了无关信息
- 是否出现幻觉
- retriever 是否召回了正确 chunk
- reranker 是否排序合理
一个完整的改进闭环如果全部展开会比较长,文章里可以先画成三个阶段:
Runtime Evidence
Quality Judgment
System Improvement
query / answer / citation / trace
eval / review / failure case / success case
chunking / retrieval / prompt / rerank
失败样本非常重要。
当一个回答出错时,我们不能只说"模型不行",而要继续追问:
- 是 chunk 切得不好吗?
- 是 embedding 没召回吗?
- 是 topK 太小了吗?
- 是 rerank 排错了吗?
- 是 context builder 塞了太多噪声吗?
- 是 prompt 没约束好 citation 吗?
- 是 LLM 忽略了证据吗?
这就是 trace、eval、review 的价值。
它们让系统从"凭感觉调参",变成"基于样本和证据持续改进"。
8. 对应到当前 Spring Boot 项目
当前项目的核心代码在 knowledge-agent-api 模块中,包结构大致如下:
text
agent-knowledge-runtime
└── knowledge-agent-api
└── src/main/java/io/github/xiewenfeng/agentknowledge
├── common
├── ingest
├── query
├── memory
└── eval这些目录并不是随便命名的,而是把 RAG 里的概念转换成了 Spring Boot 项目中的对象、服务和模块。
可以做一个简单对应:
| RAG 概念 | 当前项目中的工程表达 |
|---|---|
| 文档 | KnowledgeDocument |
| chunk | DocumentChunk |
| 文档导入 | ImportDocumentService |
| chunk 切分 | SimpleChunkingService |
| 检索 | KeywordChunkRetriever |
| 查询编排 | QueryKnowledgeService |
| 引用来源 | CitationBuilder |
| 答案生成 | AnswerComposer |
| 执行轨迹 | TraceService |
以查询链路为例,当前 v0.1 的调用关系可以这样看:
KnowledgeQueryController
QueryKnowledgeService
KeywordChunkRetriever
AnswerComposer
CitationBuilder
TraceService
这里有一个很重要的工程理解:
当前 v0.1 不是为了证明"关键词检索就足够好",而是先把 RAG 的工程骨架搭出来。
现在的实现比较朴素:
SimpleChunkingService:规则切 chunkKeywordChunkRetriever:关键词检索AnswerComposer:模板式生成答案CitationBuilder:从 chunk metadata 中组装 citationTraceService:记录一次 query 的关键事件
后续真正接入 AI 能力时,不需要推翻这套结构,而是把每一层替换成更智能的模型实现。
9. 一个最小 RAG 后端的模块划分
如果用 Spring Boot 实现一个最小 RAG 后端,可以先这样划分模块:
| 模块 | 职责 |
|---|---|
ingest |
文档导入、解析、切 chunk、存储 |
query |
接收问题、检索、构建上下文、生成答案 |
memory |
长期记忆、用户偏好、跨会话上下文 |
eval |
评估回答质量、沉淀样本 |
common |
错误处理、通用模型、trace 等公共能力 |
其中,早期版本不一定要一次性实现所有能力。
一个 v0.1 版本可以先做到:
- 支持 Markdown 导入
- 支持 chunk 存储
- 支持关键词检索
- 支持返回 answer 和 citation
- 支持记录 trace
- 支持基础测试
后续再逐步升级:
- 关键词检索升级为向量检索
- 加入 embedding 模型
- 接入向量数据库
- 加入 reranker
- 接入真实 LLM
- 加入 eval model
- 建立 eval 数据集
- 沉淀 failure case 和 success case
这比一开始就追求"完整智能体"更现实。
从工程抽象上看,后续可以逐步沉淀出几类模型接口:
java
public interface EmbeddingModel {
EmbeddingResponse embed(String text);
}
public interface RerankModel {
List<RetrievedChunk> rerank(String query, List<RetrievedChunk> candidates);
}
public interface ChatModel {
ChatResponse generate(ChatRequest request);
}
public interface EvalModel {
EvalResult evaluate(EvalRequest request);
}这几个接口分别对应不同的能力层:
| 模型接口 | 作用 |
|---|---|
EmbeddingModel |
把 query/chunk 转成向量 |
RerankModel |
对候选 chunk 重新排序 |
ChatModel |
基于 context 生成答案 |
EvalModel |
评估回答质量、证据一致性和 citation 准确性 |
也就是说,RAG 不只是需要生成模型,也需要 embedding model、rerank model 和 eval model。生成答案只是链路的一环,检索、精排和评估同样需要模型能力支撑。
总结
从后端工程角度看,RAG 不是简单调用大模型,而是一条完整的知识使用链路。
如果节点超过 6 个,建议不要把所有细节都塞进一张流程图,而是先表达整体分层:
Knowledge Preparation
Query Answering
Quality Loop
ingest / chunk / embedding
retrieve / rerank / context / LLM
citation / trace / eval
可以用几句话总结:
ingest负责把资料变成可检索的知识单元query负责把用户问题转成一次 RAG 请求retriever负责低成本召回候选 chunkreranker负责高成本精选最相关证据citation负责让答案可追溯trace负责让过程可复盘eval负责让系统可以持续改进
RAG 的核心不是让 LLM 记住更多知识,而是让 LLM 在回答时有证据、有来源、有过程、有评估。
这也是为什么一个真正可用的 RAG 系统,最终一定会从"模型调用"走向"工程闭环"。