关注我的公众号:【编程朝花夕拾】,可获取首发内容。
01 引言
这段时间一直在做紧急项目,有一个类似朋友圈的功能,需要查询发布的内容。第一印象跟肯定是全文检索了,全文检索最常用的就是Elasticsearch 或者Solr。
之前分享过一篇关于Manticore Search的文章,但是一直没有使用。这次就深度使用一下。它比 Elasticsearch 轻量得多,性能却不虚,而且 SQL 支持做得比 ES 好太多。
02 Manticore Search 简介

Manticore Search 是一个高性能、多功能的搜索引擎数据库,专门为搜索和数据分析场景打造。它的前身是 Sphinx Search,2017 年正式独立出来并进行了完全重写。它兼具以下特性:
- 高性能全文搜索:全文检索性能优异,支持超过 20 种全文运算符和 20+ 排名因子
- 实时索引:新增或更新的文档可以立即被读取,无需等待定时任务
- 向量搜索:支持嵌入向量最近邻搜索,可构建语义搜索、相似推荐等能力
- 列式存储:可选的列式存储,大幅降低大数据集的内存占用
- 双协议支持:原生支持
SQL(MySQL 协议/HTTP SQL)和 HTTP JSON 协议 - 水平扩展:支持
Galera多主复制,可横向扩展
Manticore Search 开源免费,核心由 C++ 编写,启动极快,内存占用极低(空实例仅约 40MB RSS)。这玩意儿在国内真的被 Elasticsearch 压得太惨了,没什么人知道。
03 核心功能
3.1 全文检索
全文搜索的关键词是match,输入查询字符串使用与索引文本时相同的设置进行分词。除了输入文本的分词外,查询字符串还支持一系列的 全文操作符,这些操作符会强制执行各种规则,以确保关键词能够提供有效的匹配。
全文匹配子句可以与属性 过滤器 结合使用,作为 AND 布尔运算。全文匹配和属性过滤器之间的 OR 关系不被支持。
SELECT 子句中最多只能有一个 MATCH()。还可以支持JOIN查询。
主要的功能如下:
- 模糊搜索(Fuzzy Search):自动纠正用户拼写错误
- 自动补全(Autocomplete):支持前缀和短语补全
- 同义词(Synonyms) 和 词形还原(Stemming/Lemmatization)
- 中文分词:支持准确的中文分割
- 高亮(Highlighting):搜索结果关键词高亮
- 自定义排名:支持自定义排序规则
3.2 向量搜索
可以将机器学习模型生成的向量嵌入添加到文档中,执行最近邻(KNN)搜索,适用于:
- 语义搜索
- 相似内容推荐
- 图片、视频、音频的相似性搜索
3.3 结构化查询
除了全文搜索,Manticore Search 还支持:
- 范围过滤(Range) :如
id < 100 - 布尔过滤(BoolFilter):组合多个条件(must/must_not/should)
- JOIN 查询:跨表关联查询
- 聚合统计:faceted search 等
3.4 存储模式
Manticore 提供行存储和列存储选项,以适应不同规模的数据集。行存储是大家最常用的存储模式,如Mysql等,而列式存储被称之为newSQL,如Starrocks、ClickHourse、TiDB等分布式数据库。
04 基于Match的实践
Manticore的部署非常简单,直接使用Docker部署即可。
shell
docker pull manticoresearch/manticore
docker run --name manticore -p9306:9306 -p9308:9308 -p9312:9312 -d manticoresearch/manticore
4.1 准备工作
我们以Java客户端为例,因为对应的依赖:
xml
<dependency>
<groupId>com.manticoresearch</groupId>
<artifactId>manticoresearch</artifactId>
<version>8.1.0</version>
<scope>compile</scope>
</dependency>客户端:
java
ApiClient apiClient = Configuration.getDefaultApiClient();
apiClient.setBasePath("http://ip:9308");所有 API 操作都通过 ApiClient 发起,9308 是 Manticore Search 的默认 HTTP 端口(SQL 和 JSON 协议共用)。
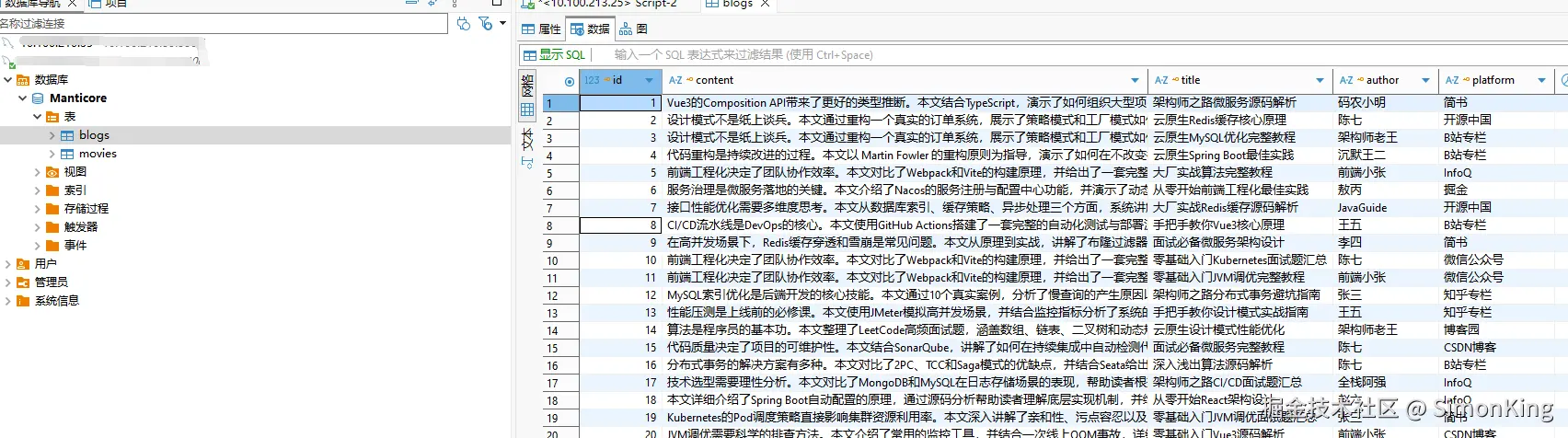
造数据。使用AI造了10W条数据:
4.2 SQL 查询
直接使用SQL查询。
java
ApiClient apiClient = Configuration.getDefaultApiClient();
apiClient.setBasePath("http://127.0.0.1:9308");
UtilsApi utilsApi = new UtilsApi(apiClient);
String sql = """
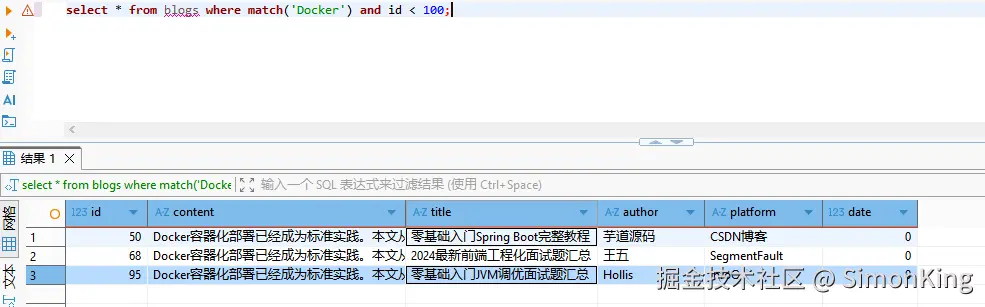
select * from blogs where match('Docker') and id < 100
""";
SqlResponse response = utilsApi.sql(sql, true);
Object actualInstance = response.getActualInstance();
// 解析json数据
String json = JSON.toJSONString(actualInstance);
List<JSONObject> jsonObjects = JSON.parseArray(json, JSONObject.class);
String data = jsonObjects.get(0).getString("data");
List<JSONObject> dataList = JSON.parseArray(data, JSONObject.class);
for (JSONObject jsonObject : dataList) {
System.out.println(jsonObject);
}解析:
- 使用
UtilsApi.sql()执行原始 SQL 语句 match('Docker')是 Manticore Search 的全文搜索语法,表示在全文索引字段中搜索包含 "Docker" 的文档且ID小于100的记录- 使用
JSON解析最终的记录
结果:

图像化界面结果:
4.3 SearchApi
除了使用SQL,还可以使用API的方式直接调用,有点类似ES的API。
java
ApiClient apiClient = Configuration.getDefaultApiClient();
apiClient.setBasePath("http://127.0.0.1:9308");
SearchApi searchApi = new SearchApi(apiClient);
SearchQuery searchQuery = new SearchQuery();
Map<String, Object> match = new HashMap<>();
match.put("content", "Docker");
Map<String, Object> rangeItem = new HashMap<>();
rangeItem.put("lt", 100);
Map<String, Object> range = new HashMap<>();
range.put("id", rangeItem);
BoolFilter boolFilter = new BoolFilter();
QueryFilter queryFilter = new QueryFilter();
queryFilter.setMatch(match);
boolFilter.addMustItem(queryFilter);
QueryFilter queryFilter2 = new QueryFilter();
queryFilter2.setRange(range);
boolFilter.addMustItem(queryFilter2);
searchQuery.setBool(boolFilter);
SearchRequest searchRequest = new SearchRequest();
searchRequest.setTable("blogs");
searchRequest.setQuery(searchQuery);
SearchResponse response = searchApi.search(searchRequest);
System.out.println("总命中: " + response.getHits().getTotal());
System.out.println("list: " + JSON.toJSONString(response.getHits().getHits()));解析:
- 这该示例展示了如何组合多个过滤条件
BoolFilter支持四种逻辑组合:must:所有条件都必须满足(AND)must_not:所有条件都不能满足(NOT)should:满足任一条件即可(OR)filter:同 must,但不参与评分
- 本例中
addMustItem()添加了两个必须同时满足的条件:content字段匹配 "Docker"id字段小于 100
结果:

其中结果集里面包含了_score,表示命中的椎确分数。
类似ES的API:
bash
curl -sX POST http://localhost:9308/search -d '
{
"table":"blogs",
"query": {
"bool": {
"must": [
{ "match": {"content":"Docker"} },
{ "range": { "id": { "lt": 100 } } }
]
}
}
}4.4 Mysql和Manticore的速度
我们可以看一下普通的like查询和Manticore的match的速度对比,同样10W条数据。
Mysql的查询结果:
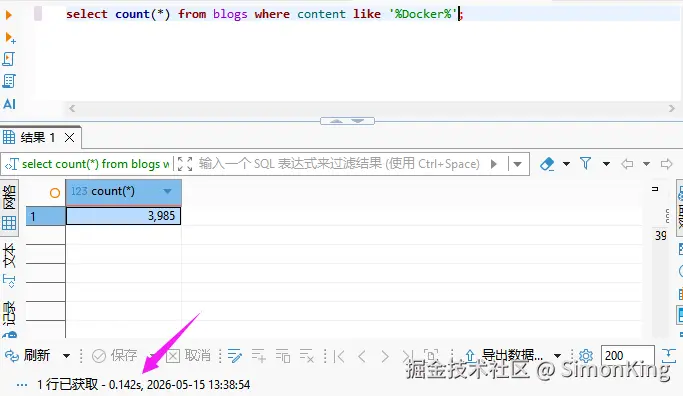
差不多耗时:142ms
Manticore结果:
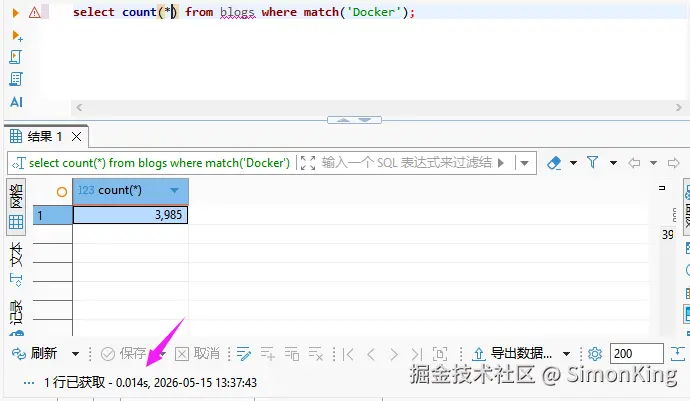
差不多耗时:14ms
两者相差有10倍。
05 小结
Manticore Search的客户端可以使用DBeaver,之前的版本是不能使用的,打开直接报错,主要因为别名的问题。后面已经修复。相关的issues:
Manticore Search 是一个被严重低估的搜索引擎,国内用户依然还是首选ES,如果你也在寻找替代方案,不妨了解一下这个产品。