深入理解LLM Agent架构:从上下文扩展到MemGPT的底层原理与LangGraph实现
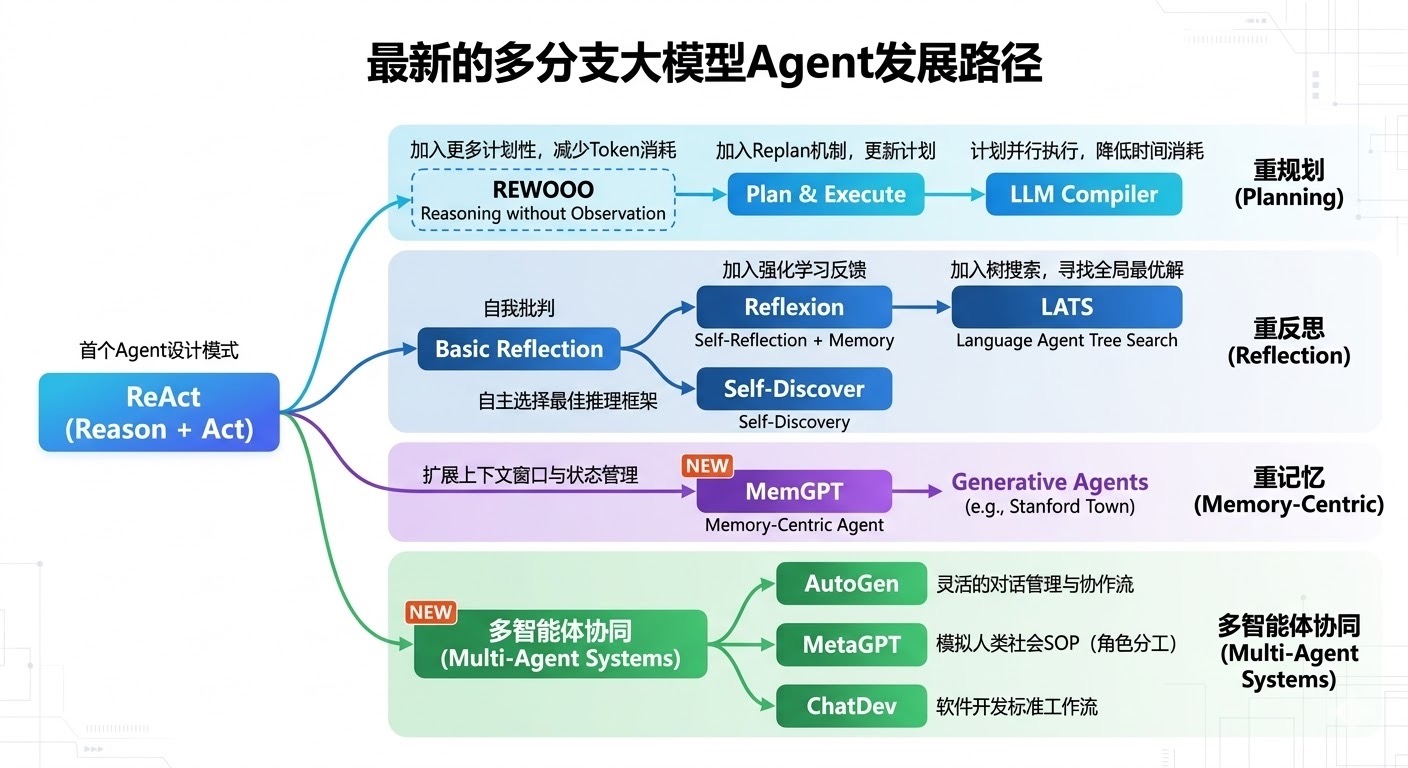
在最新的多分支大模型Agent发展路径中,我们看到Agent的基石是ReAct (Reason + Act) 。ReAct赋予了模型基础的"思考+行动"闭环能力,但在面对超长对话、长期陪伴、复杂多步任务时,ReAct模式很快遇到了物理瓶颈------大模型的上下文窗口(Context Window)限制。
为了解决这个问题,图谱中衍生出了紫色分支:重记忆(Memory-Centric) ,其代表作正是MemGPT(以及后续延伸出的Generative Agents)。今天,我们将深度拆解MemGPT的底层机制,看看它究竟是如何打破大模型记忆极限的。
推荐阅读原论文(2023年): MemGPT: Towards LLMs as Operating Systems。
Git代码仓:MemGPT
一、 技术演进的来龙去脉:为什么需要MemGPT?
在MemGPT出现之前,业界为了解决长上下文问题,主要有两种主流方案,但它们都有致命的弱点:
- 直接扩展模型的物理上下文窗口(如RoPE线性插值、RingAttention) :
- 原理:从模型底层结构入手,支持128K甚至1M的Token输入。
- 痛点 :Transformer的自注意力机制计算复杂度是 O ( N 2 ) O(N^2) O(N2)( N N N为序列长度)。哪怕通过各种工程优化降低了复杂度,长窗口推理带来的高昂算力成本、极高的首Token延迟(TTFT) ,以及 "中间迷失"(Lost in the Middle) 现象,都让它无法在C端长期陪伴型Agent中低成本落地。
- 传统的RAG(检索增强生成) :
- 原理:将历史信息存入向量数据库,用户提问时,基于User Query去被动检索Top-K片段注入上下文。
- 痛点 :RAG是被动 的,它依赖用户的当前Query去触发回忆。如果用户说"今天我很开心",RAG很难主动去联想"上次你开心是因为买到了喜欢的游戏",因为它缺乏一种主动的、有状态的记忆管理机制。
MemGPT的破局点 :
MemGPT的作者灵光一闪,借鉴了传统操作系统(OS)的虚拟内存管理(Virtual Memory Management)与分页(Paging)机制 。既然计算机的RAM(内存)有限,SSD(硬盘)无限,操作系统可以通过缺页中断(Page Fault)在两者之间搬运数据;那么大模型的上下文窗口就是RAM,外部数据库就是SSD,为什么不让大模型自己学会"换页"呢?
二、 MemGPT的底层原理:OS级别的内存架构
MemGPT的核心在于它构建了一个多级记忆架构(Hierarchical Memory),并通过LLM自身的函数调用(Function Calling)能力来主动管理这些记忆。
1. 记忆分层设计
MemGPT将记忆严格划分为两块:
- 主上下文(Main Context,类似于计算机的RAM) :
这是大模型当前能够直接"看"到的部分,即每一次请求发给LLM的实际Token。它包含:- System Instructions:系统设定的不可变指令,告诉LLM它是一个MemGPT,以及它有哪些工具(Tools)可以使用。
- Core Memory :核心记忆。分为两部分:
Persona(AI的人设与当前状态)和Human(对用户的核心认知总结,比如名字、爱好、关键事实)。这部分是可读写的,LLM可以通过工具修改它。 - Working Context:近期的对话历史,当这部分快满时,会被"逐出(Evict)"。
- 外部上下文(External Context,类似于计算机的SSD) :
大模型直接看不见,必须通过工具调用才能拉取到RAM中。- Recall Memory(回忆记忆):完整的历史对话记录(以时间轴排序),可以通过时间范围搜索。
- Archival Memory(归档记忆):类似于向量数据库,存储知识、事实。可以通过文本相似度或关键字搜索。
2. 控制流与主动干预(Interrupts & Yield)
MemGPT通过系统提示词告诉LLM:"你的内存是有限的,如果发现信息不够,你需要调用 search_archival 工具去外部找;如果你觉得用户刚刚说的话很重要,你需要调用 core_memory_append 工具把它写进你的核心记忆中。"
这种设计化被动检索为主动思考与存储。
三、 核心组件的LangGraph实现细节
为了在大厂面试中展现你对工程落地的掌控力,我们需要用最前沿的框架(如LangGraph)来还原MemGPT的核心机制。LangGraph非常适合处理这种带有循环、条件分支和状态流转的Agent。
以下是MemGPT核心思想的LangGraph伪代码实现及解析:
python
from typing import TypedDict, Annotated, List, Sequence
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage, SystemMessage
from langgraph.graph import StateGraph, END
import operator
# ================= 1. 定义全局状态 (相当于操作系统的物理内存状态) =================
class MemGPTState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add] # 存放 Working Context
persona_memory: str # 核心记忆:AI人设
human_memory: str # 核心记忆:用户画像
archival_memory: List[str] # 模拟外部磁盘 (实际生产中这里是VectorDB的连接)
# ================= 2. 定义内存管理工具 (Memory Tools) =================
def core_memory_append(state_ref: dict, section: str, content: str):
"""大模型主动调用的工具:用于向核心记忆中追加关键信息"""
if section == "human":
state_ref["human_memory"] += f"\n- {content}"
elif section == "persona":
state_ref["persona_memory"] += f"\n- {content}"
return "Memory updated successfully."
def core_memory_replace(state_ref: dict, section: str, old_content: str, new_content: str):
"""大模型主动调用的工具:用于修正核心记忆"""
# ... 替换逻辑 ...
return "Memory replaced successfully."
def archival_memory_search(state_ref: dict, query: str):
"""大模型主动调用的工具:从外部磁盘检索历史"""
# 模拟向量检索
results = [doc for doc in state_ref["archival_memory"] if query in doc]
return f"Search results: {results}"
# ================= 3. 核心节点:构建LLM处理器 (带分页调度能力) =================
def llm_processor_node(state: MemGPTState):
# 【核心机制】:每次调用前,动态拼装 Main Context (RAM)
system_prompt = f"""
You are a MemGPT agent with finite context.
--- CORE MEMORY (RAM) ---
Persona: {state['persona_memory']}
Human: {state['human_memory']}
---
You have tools to search the archival memory (Disk) or update your core memory.
If you learn something new and important about the user, USE THE TOOL to update human memory.
"""
# 截断策略:如果 messages 过长,只保留最近的 N 条,其余存入 archival (模拟换页)
working_context = state['messages'][-10:] # 简化的截断逻辑
messages_to_send = [SystemMessage(content=system_prompt)] + list(working_context)
# 调用大模型 (绑定上述 tools)
response = llm_with_tools.invoke(messages_to_send)
return {"messages": [response]}
# ================= 4. 工具执行节点 =================
def tool_executor_node(state: MemGPTState):
last_message = state['messages'][-1]
# 解析 last_message 中的 tool_calls,执行真正的工具函数
# ... 执行逻辑 ...
# 将工具执行结果作为 ToolMessage 返回
return {"messages": [tool_message]}
# ================= 5. 路由逻辑 (控制流) =================
def should_continue(state: MemGPTState):
last_message = state['messages'][-1]
# 如果LLM调用了内存工具(如搜索、更新),则去执行工具
if last_message.tool_calls:
return "tools"
# 如果没有调用工具,说明它已经回答完毕,返回给用户
return END
# ================= 6. 构建图谱 =================
workflow = StateGraph(MemGPTState)
workflow.add_node("agent", llm_processor_node)
workflow.add_node("tools", tool_executor_node)
workflow.set_entry_point("agent")
workflow.add_conditional_edges("agent", should_continue, {"tools": "tools", END: END})
workflow.add_edge("tools", "agent") # 工具执行完后,必须再次回到agent判断下一步
app = workflow.compile()LangGraph设计解析 :
在这个设计中,MemGPTState 充当了内存管理器。每次循环回到 agent 节点时,llm_processor_node 都会重新读取 被工具修改过的 persona_memory 和 human_memory,这就实现了大模型**"写自己记忆 -> 改变自身系统Prompt -> 进而改变未来行为"**的神奇闭环。
四、 常见疑难杂症 QA
🚨 灵魂拷问 1:MemGPT和带有长上下文(Long-Context)的大模型冲突吗?未来有了无限上下文,MemGPT还有用吗?
深度剖析:不冲突,且MemGPT依然不可替代。
- 算力成本维度:哪怕模型支持1M Token,每次都输入1M的Token去进行推导,计算成本是极其巨大的(Attention机制的特性决定)。MemGPT将数据放在外部,按需加载,是成本最优解。
- 逻辑信噪比维度 :上下文越长,"大海捞针"能力虽然在提升,但多重矛盾信息叠加时(比如用户一个月前说喜欢红色,昨天说喜欢蓝色),模型容易出现逻辑混淆。MemGPT的核心在于状态更新(Update) ,它会去修改Core Memory中的状态,明确覆盖旧信息,让主上下文永远保持高信噪比。
🚨 灵魂拷问 2:Agent在循环调用记忆工具时,陷入"死循环"(Infinite Loop)怎么办?
场景重现 :LLM不停地调用 search_archival_memory,但始终找不到它想要的东西,导致无法给用户最终回复(卡死)。
应对策略:
- 强制的 Heartbeat / Yield 机制 :在MemGPT的设计中,可以引入一个特殊的工具叫
send_message_to_user。在系统Prompt中强制规定:在连续调用 K K K 次内部工具后,必须调用这个工具向用户汇报当前进展或求助。 - LangGraph层面的递归限制 :在LangGraph的执行引擎中,设置
recursion_limit。一旦触发异常,捕获该异常并向LLM注入一条强制性的System Message:"检索次数已达上限,请根据现有信息直接回答用户。"
🚨 灵魂拷问 3:大模型怎么知道"什么时候该去更新核心记忆"?如果它忘记更新了怎么办?
底层难点 :LLM本质是Next-Token Prediction,存在惰性,尤其是在处理复杂的推理时,容易忘记调用记忆API。
解决套路:
- Few-Shot Prompting 强化 :在System Prompt中提供标准SOP的示例(例如:
User: "我最近刚搬到北京" -> Agent Action: call core_memory_append("human", "住在北京"))。 - 独立的"反思器"(Reflexion 机制的引入) :回顾我们的Agent发展路线图片,中间有一条分支是 Reflexion (自我批判)。为了提高记忆更新的准确率,可以外挂一个小的、廉价的模型(如GPT-4o-mini或GLM-4-flash)专门作为"Memory Watcher"。这个小模型后台异步监听对话流,只负责判断"当前对话是否包含需要更新的记忆",如果包含,则主动触发写入动作。这种多智能体协同(结合了图片下方的 Multi-Agent 分支思想)能极大提高系统的鲁棒性。
总结
MemGPT的思路挺好的,相信目前大部分业界的Agent应用多少都有参考(比如长期记忆等)。但是原生的代码仓代码写的不咋地,推荐自己手搓一个,更能直观体会里面的设计细节。