
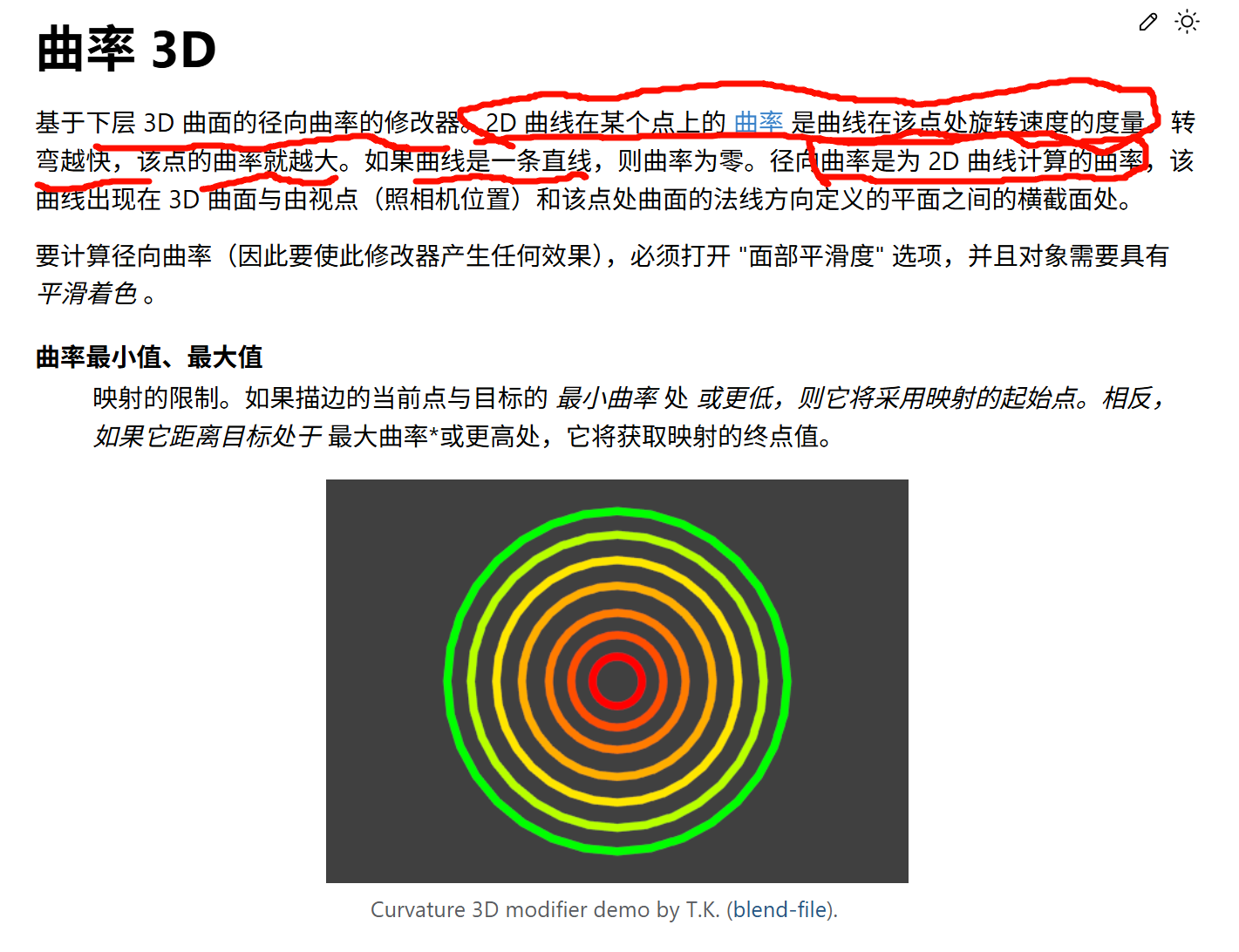
**Curvature Shading(曲率着色/曲率渲染)**在很大程度上依赖于检查和分析顶点法线(Vertex Normals)以及由它们插值得到的表面法线 。计算邻近顶点法线之间的变化速率来衡量表面曲率。
overflow-visible!
per-pixel curvature shading
Material Graph 没有 curvature。
但如果改引擎:
可以在 GBuffer 加一个 channel:
overflow-visible!
GBufferD = curvature
shader 质量会立刻提升。
纯数学上讲,Disney BRDF、GGX 变体、Charlie、Burley diffuse、multi-scatter compensation,这些全都只是函数:
-
输入:N、V、L、roughness、metallic、anisotropy、clearcoat...
-
输出:f(l, v)
在这个意义上,你说得对,它们都不要求改源码。只要给你一个足够自由的 shader 环境,你就能实现。
"能不能被当前引擎路径正确使用"。
在 UE 里,如果你只是在 Material Graph 或 Custom 节点里写一个 BRDF 公式,你通常只是做了下面几种事之一:
-
伪装成 BaseColor / Emissive / Specular 的某种近似输出
-
在默认 lighting model 上叠加一个 correction term
-
在 Forward/Unlit 里自己做一部分假光照
源码的情况:
-
想让新 BRDF 进入 deferred lighting 主循环
-
想让它参与所有灯光类型的一致受光
-
想匹配 skylight / reflection capture / SSR / Lumen 反射
-
想新增 shading model
-
想扩展 GBuffer 通道承载新参数
-
想做正确的预积分 LUT、重要性采样和 IBL 配套
"Disney BRDF 变体作为数学函数本身,不需要改源码;但要把它作为 UE 中完整、正确、一致、可维护的渲染模型使用,通常需要改源码。"
-
我不要只在某个材质球上 fake 一下
-
我要它进主光照路径
-
我要它和全局反射、阴影、GBuffer、灯光循环协同工作
-
我要它能规模化给整个项目用
这就从"数学实现"变成"渲染架构实现"了。
效果怎么规模化给几十个场景、几百个材质用规模化给几十个场景、几百个材质用混合多种追踪技术(屏幕追踪、网格体距离场追踪),在即时生成光线反弹的同时,结合 Nanite 几何体进行表面缓存缓存到物体的表面(表面缓存)(Surface Cache)
-
Ray Tracing (光线追踪): 这是一个总称。它是一套完整的渲染技术体系,包含了很多子项目。
-
Ray Traced Reflections (光追反射): 它是光线追踪技术里的一个具体应用方向。
-
如果说 Ray Tracing 是"运动",那么 Ray Traced Reflections 就是其中的"跑步"。除了反射,光线追踪还包括:
- Ray Traced Shadows (光追阴影): 让阴影边缘更自然,远近虚实更真实。
- Ray Traced Global Illumination (光追全局光照/RTGI): 模拟光线在物体表面多次弹射后的颜色干扰,让室内光线更柔和。
- Ray Traced Ambient Occlusion (光追环境光遮蔽/RTAO): 强化物体缝隙处的阴影,让物体更有立体感。

Ray Tracing (名词词组):- 这是一个动名词 结构,代表的是**"这项技术本身"**。
Ray Traced (过去分词作形容词):
- 这是一个被动语态 的用法,意思是**"经过光追处理的"**。
- Ray Traced Reflections 翻译为"经过光追渲染的反射"。这里的
Ray Traced用来修饰后面的Reflections(反射)。
虽然它们的核心都是"光线追踪",但在逻辑表达上,它们侧重点不同:
- Ray Tracing 是主语/技术名。
- Ray Traced 某物 是渲染结果。
虚幻引擎(Unreal Engine, 简称UE)中,
CSM 是 Cascaded Shadow Maps 的缩写,中文翻译为级联阴影贴图 或层级阴影贴图 。用于处理平行光(Directional Light,通常是太阳光)动态阴影CSM 是实时开放世界或室外大场景中,单纯使用单一的阴影贴图,要么近处阴影有锯齿,要么远处阴影模糊。阴影分为几层,能兼顾近处细腻和远处阴影覆盖层级越多、距离越远,对 GPU 和 CPU 的负荷就越大。Distribution Exponent (分布指数): 决定近处和远处层级之间的划分权重。Transition Fraction (过渡比例): 用于平滑相邻阴影层级之间的过渡,防止锯齿突变在 UE5 中,虽然传统的 CSM 仍在广泛使用,但更高级的 VSM(Virtual Shadow Maps,虚拟阴影贴图) 被引入,能提供更细腻且基于像素的阴影,成为大场景的主流方案。 阴影贴图分割成虚拟小块并在需要时动态加载,能实现高清、稳定且无虚化效果(高细节)的动态阴影,并完美配合Nanite和Lumen系统使用。划分为小的"页"(Pages),仅在需要时分配和计算屏幕可见区域内的阴影,总结来说,VSM 是 UE5 渲染引擎的核心功能,让开发者可以在实时渲染中获得堪比离线渲染的电影级阴影效果。王鑫 (库洛游戏《鸣潮》图形渲染组长)
目前的实现中,它们的虚拟分辨率为16k x 16k像素。
https://www.bilibili.com/video/BV1hSW4zTEgQ/?vd_source=8edbc527019213f5a0f28f3a4b395636
https://zhuanlan.zhihu.com/p/1967117197915693977
魔改UE5的Lumen方案并移植到UE4.26,结合硬件光追与自研模块,在开放世界卡通渲染中达成了4060显卡2K分辨率60帧的性能目标。光追反射、全局光照和阴影三大效果ReSTIR
(时空重要性重采样)是一种用于实时路径追踪的尖端算法,旨在通过在空间和时间上重采样光线样本,从而高效处理大量动态光源并显著降低间接光照的噪声。它利用前一帧和相邻像素的样本来优化当前样本质量,非常适合实现高质量的动态全局光照(GI),例如 UE5 的 Lumen技术 。ReSTIR 路径追踪的关键要素:
- 核心原理: ReSTIR(Spatiotemporal Reservoir Resampling )通过构建"采样水库"(Reservoir)来存储和重用有效的光线样本,以提高对复杂光照的贡献度。
- 空间重采样: 在当前帧中,将像素与其相邻像素的样本进行重采样,利用空间上的信息来传播高质量样本。
- 时间重采样: 将当前帧的样本与上一帧对应的像素样本进行重采样,从而在时间上重用旧的样本,减少画面闪烁。
- 应用场景: 主要用于实时渲染(RTGI),在处理数百万个动态光源时,能够以较少的采样数实现高画质。
- 主要优势: 相比传统的路径追踪,ReSTIR 极大地降低了蒙特卡洛积分的噪声,在保证实时性的同时获得高质量的全局光照效果。
https://zhuanlan.zhihu.com/p/407945117#CTZ_DEFAULT
这是 Spatial(空间) 和 Temporal(时间) 的合成词。
- Temporal (时间): 指算法会"记住"上一帧渲染出的优秀光照样本。既然画面每秒更新 60 次,前后两帧的变化通常很小,直接复用上一帧的数据能极大减少重复计算。
- Spatial (空间): 指屏幕上相邻的像素通常受相似光源的影响。算法会让像素之间互相"交流"光照信息,如果邻居找到了一个很亮的光源,它会把这个信息分享给你。
-
在统计学中,蓄水池采样(Reservoir Sampling) 是一种从海量流式数据中等概率选取样本的方法。
-
在渲染中,每个像素都有一个"蓄水池",它并不存储成千上万个光源,而是只存储**极少数(通常只有 1 个)**最有代表性的光源样本,以及一个代表该样本权重的值。这让内存消耗极低。
-
算法并不是随机选一个灯光就结束了,而是通过不断地将"旧样本"(来自上一帧或邻居)与"新生成的随机样本"进行对比。
-
通过重要性重采样(Importance Resampling),算法能自动剔除那些对画面亮度贡献微弱的光源,最终在蓄水池里留下那个最能照亮该像素的"核心光源"。
每一个像素都准备一个小本本(Reservoir ),通过不断地翻看自己上一秒记录的、以及周围邻居记录的优秀灯泡信息(Spatiotemporal ),来反复筛选(Resampling )出那一束最能照亮自己的光。这种"抄作业"会导致的**画面残留(Ghosting)**怎么解决?
Material Graph 属于 shading expression layer ,而不是 rendering architecture layer多画面结果其实决定于"这个像素是怎么被看见、怎么被照亮、怎么被积累、怎么被缓存"的整套流程。GBuffer layout:为什么材质图改不了"材质语义"UE 的 deferred path 里,Material Graph 最终输出的并不是"最终画面"
关于 Spatiotemporal Reservoir Resampling (ReSTIR),目前最值得看的演示主要集中在 NVIDIA 的官方技术 Demo、学术成果展示以及集成该技术的顶级 3A 游戏。
以下是几个最具有代表性的 Demo 和视频:
1. NVIDIA 官方技术演示 (RTXDI 系列)
NVIDIA 将 ReSTIR 商业化后命名为 RTXDI (RTX Direct Illumination)。
- Bonsai Diorama (盆栽场景) Demo: 这是 2025 年最新的演示,基于 Unreal Engine 5.6。它不仅展示了 ReSTIR 对海量动态光源的处理,还结合了 RTX Mega Geometry(处理数亿个三角形的微几何技术),是目前画质最顶尖的演示之一。
- Amusement Park (游乐园) Demo: NVIDIA 在 GDC 2025 推出的互动示例,展示了 DLSS 4 和 ReSTIR 在极其复杂的光源环境(旋转木马、霓虹灯阵列)中的表现,采样质量比传统方法提升了近 100 倍。
-
SIGGRAPH 2020 原始演示视频\]: 即使是几年前的视频,它依然最直观。视频中展示了"百万光源"场景(如一个装满发光球体的房间),你可以清楚地看到即使没有去噪器(Denoiser),ReSTIR 也能迅速收敛到纯净的画面。 \[1, 2, 3, 4, 5, 6
2. 游戏中的实战演示
如果你想看这项技术在实际游戏里的表现,以下两个案例是"教科书级"的:
- 《赛博朋克 2077》光线追踪:超速模式 (Overdrive Mode):
- 该模式是 ReSTIR GI(全局光照)的大规模应用场景。它处理了夜之城数以万计的霓虹灯、车灯和广告牌。开启后,你会发现所有动态物体(如行驶的车辆)都能实时投射出准确的彩色阴影和反光。
- 《Portal with RTX》(传送门 RTX 版):
- 这个 Demo 证明了 ReSTIR 如何通过"时空复用"让老游戏焕发新生。它将原本简单的光源替换为物理正确的光源,利用 ReSTIR 实现实时路径追踪。 7
3. 开源实现与交互式工具
如果你想亲自"上手"调参数,可以看这些开源项目:
- NVIDIA RTXDI SDK (GitHub): NVIDIA 官方在 GitHub 上开源了 RTXDI 的示例项目,包含 MinimalSample(最小化实现)和 FullSample(完整渲染管线),适合开发者研究。
-
Falcor 渲染框架下的 ReSTIR 实现\]: 许多研究者在 NVIDIA 的 [Falcor 框架](https://github.com/Trylz/Restir_CPP "Falcor 框架")上实现了 ReSTIR。你可以下载这些 Demo,并在运行时开关"空间复用"或"时间复用",肉眼观察噪点的变化过程。 \[8, 9, 10
观看建议
在观看这些 Demo 时,你可以重点留意以下"马赛克"相关的现象:
- 收敛速度:看摄像机快速转动时,画面是否会瞬间变模糊(重采样过程),然后又迅速变得极其清晰。
- 动态光源:看那些高速运动的灯泡,阴影是否能实时跟上且不产生"拖影"。
- 邻居交流:如果关闭"空间复用",你会看到画面变回满是细碎噪点的状态;开启后,噪点会立刻聚拢成平滑的光影。
1 https://developer.nvidia.com
虚幻引擎 (Unreal Engine) 默认采用的是 延迟渲染路径 (Deferred Rendering Path) 。虽然它也支持 前向渲染 (Forward Rendering)(主要用于移动端、VR 或需要高性能抗锯齿的场景),但其核心桌面和主机端的功能(如 Nanite 和 Lumen)都是围绕延迟渲染架构构建的。
-
光源处理能力强 :延迟渲染最显著的优势是能够处理成百上千个光源,而不会导致性能呈几何倍数下降。这是因为它将几何计算与光照计算分离,光照只在屏幕空间可见的像素上执行。
-
解耦几何与光照 :通过 G-Buffer(几何缓冲区)存储深度、法线和材质属性,复杂的材质计算只需进行一次,后续光照阶段直接读取这些信息。
-
复杂特效支持 :许多现代视觉特性(如屏幕空间反射 SSR、环境光遮蔽 SSAO 以及 UE5 的 Lumen 动态全局光照)在延迟管线下实现起来更为高效。
-
内存带宽压力 :由于需要维护庞大的 G-Buffer,延迟渲染对显存带宽的要求较高。半透明渲染痛点 :由于 G-Buffer 只存储每个像素最前面的一层信息,半透明物体 通常需要切换回前向渲染模式来单独处理。抗锯齿限制 :延迟管线天然不支持传统的 MSAA (多重采样抗锯齿),因此 UE 默认强力推行 TAA 或 TSR (时域超分辨率)等方案。渲染管线是一个大框架(通常分为应用阶段、几何阶段、光栅化阶段),而几何阶段是其中的第二个主要阶段 。
从
宏观结果 来看,渲染管线的终点确实就是输出一帧(Frame) 图像。 微观运行上,为了追求极致的性能,管线并不是"走完一个零件再生产下一个",而是像真正的工业流水线一样: -
当 GPU 正在处理第 N 帧的光栅化时;
-
几何阶段可能已经在处理第 N+1 帧的顶点了;
-
而 CPU 可能正在准备第 N+2 帧的数据。
-
这种设计确保了 GPU 的各个硬件单元始终保持忙碌,从而提高 帧率(FPS) 。
时间单位的衡量
- 吞吐量(Throughput):也就是你说的,单位时间内吐出多少帧(比如 60 FPS,意味着每 16.6ms 吐出一帧)。
- 延迟(Latency):指单个顶点或像素从进入管线到显示在屏幕上经历的总时长。
延迟的具体定义
在渲染管线中,延迟是指:从 CPU 开始处理某一帧的数据,到这一帧最终显示在显示器上所经历的总时间。
我们可以把这一帧的"旅程"拆解为几个关键耗时点:
- 输入延迟 (Input Latency):你按下鼠标或键盘,信号传给 CPU 的时间。
- 处理延迟 (CPU/App Latency):CPU 计算游戏逻辑、物理碰撞、准备提交给 GPU 的渲染命令(Draw Calls)的时间。
- 几何延迟 (Geometry Latency):GPU 接收到顶点数据,进行坐标变换、裁剪、投影的时间。
- 光栅化/着色延迟 (Rasterization/Shading Latency):GPU 把几何图形变成像素并涂上颜色的时间。
- 显示延迟 (Display Latency):显卡把渲染好的帧传给显示器,显示器刷新出画面的时间。
为什么"帧率高"不代表"延迟低"?
这是一个常见的误区。想象一条超长的流水线:
-
高吞吐量(高 FPS):流水线终点每秒钟能吐出 144 个零件(144 FPS)。
-
高延迟(Latency):但每个零件由于流水线太长,从头走到尾需要 500 毫秒。
-
结果 :你在屏幕上看到的画面确实很丝滑,但你动一下鼠标,画面要在半秒钟后才会有反应。这就是典型的输入延迟。
-
闭"三重缓冲(Triple Buffering)",虽然可能导致画面撕裂,但能减少一帧在显存里的排队时间。
逻辑与指令准备 (App Stage)
管线的起点提交指令 (Draw Call Submission) :CPU 需要告诉 GPU"画这个、画那个"。如果 Draw Call 数量爆炸(比如一万个独立的小石头),CPU 在组织这些命令时会消耗大量时间,把 3D 模型的顶点从模型坐标转到屏幕坐标。如果模型面数(Triangle Count)极高,或者骨骼动画极其复杂,GPU 的几何单元就会超负荷。带宽压力 (Memory Bandwidth) :频繁读写显存里的贴图数据,如果显存频率不够,数据传输也会产生等待耗时。显示输出 (Display/V-Sync)
*如果开启,显卡必须等显示器刷新卡 10ms 画完,但显示器 16.6ms 才刷新一次,显卡就得干等 6.6ms。面板延迟 :显示器接收到信号到像素点亮,物理上也需要几毫秒。Profiler(性能分析工具) 确实无法在一个界面里直接给你一个从"手点下去"到"屏幕发光"的总延迟(End-to-End Latency) 。
rofiler 看不到的(隐形成本)
- 驱动开销(Driver Overhead):指令在进入 GPU 硬件之前的排队时间,Profiler 有时难以精准捕捉。
如何测量 Profiler 看不到的部分?
为了测量真实的全链路延迟,业内通常使用以下方法:
- 硬件方案 (LDAT):NVIDIA 有专门的硬件工具(Latency Display Analysis Tool),一头连着鼠标,一头贴在屏幕上,直接测量点击到光变的物理时间。
- NVIDIA Reflex SDK:通过在代码中植入标记,让 CPU、GPU 和驱动程序"互相通气",从而在软件里模拟出全链路延迟的各个组成部分。
- 高速摄像机:最原始但也最准的方法。用 1000fps 的相机拍手部动作和屏幕变化,数中间差了多少帧。
UE 是如何处理的?
- 默认方案 :UE 的桌面端延迟渲染通常使用 TAA (Temporal Anti-Aliasing) 或 TSR (Temporal Super Resolution) 。这些方案利用时域信息(上一帧的数据)来平滑边缘,成本极低且能处理着色器高频噪点(Specular Aliasing)。
- MSAA 的保留地 :在 UE 中,MSAA 仅在 前向渲染 (Forward Shading) 模式下可用。这也就是为什么在开发注重画面清晰度的 VR 项目 或 移动端项目 时,官方文档通常会指导开发者切换到前向渲染器
MSAA 的核心在于几何阶段对每个像素进行多次采样,并在这些子采样点之间进行深度测试。然而,延迟渲染将几何与光照解耦。在光照阶段,显卡只看到 G-Buffer (纹理数据),不再拥有物体的几何边缘信息,因此无法直接利用硬件 MSAA 进行边缘平滑。如果强行在延迟管线中开启 MSAA,为了让光照计算在子采样级别上保持正确,每一个采样点都需要存储一套完整的 G-Buffer 数据(法线、粗糙度、颜色等)。
- 显存需求:如果开启 4x MSAA,G-Buffer 的体积会翻 4 倍,极易撑爆显存。
- 计算压力:光照阶段的计算量也会成倍增加,因为原本按像素进行的着色可能需要按采样点进行,这会让延迟渲染"处理成百上千光源"的优势荡然无存
MSAA 的采样发生在"光栅化(Rasterization)"阶段 ,也就是几何数据(三角形)转化为像素碎片的转折点。之前的表述是为了简化理解,将"光栅化"这个衔接步骤笼统地归在了广义的几何处理流程中。更精确的解释如下:需要显存支持: 开启 MSAA 时,渲染目标(Render Target)需要多倍的深度和模板缓存(Render Target 大小可能翻倍或更多),这对显卡内存的带宽和容量有很高的要求
MSAA 如何在显卡上运行?
- 光栅化采样: 现代GPU光栅化器通过判断一个三角形是否被像素内的多个样本覆盖来实现。
- 多采样缓冲: GPU利用专用的帧缓冲区存储这些覆盖样本。
- 解析(Resolve): 最终,这些样本被解析并平均成一个最终像素颜色。
MSAA的局限性(非技术限制,而是架构限制)
- 延迟渲染不兼容
延迟渲染在像素着色阶段已经丢失了物体边界的几何信息。正向渲染(Forward Rendering)中表现优异,但不支持大多数现代游戏采用的延迟渲染(Deferred Shading) ,因为延迟渲染在像素着色阶段已经丢失了物体边界的几何信息。
MSAA(多重采样抗锯齿)不算作严格意义上的 Shader(着色器)程序
,它是一种硬件渲染特性 和图形管线技术 。具体来说:它是渲染流程的一环:
MSAA 工作在片段着色器(Fragment Shader)执行之后、光栅化之后,负责对计算出的颜色进行多次采样和平均,以减少边缘锯齿。
强调布
利用高带宽MRT(多目标渲染)需要GPU硬件支持MRT技术同一个Pass中向多个RenderTarget写入数据。显存带宽较窄的设备(如部分移动端GPU)上,延迟渲染可能导致性能下降硬件解决方案 :现代移动端通过分块延迟渲染(Tile-Based Deferred Rendering, TBDR)将场景分块,利用片上内存(On-chip Memory)缓存G-Buffer,避免频繁读写显存,从而在高通骁龙等GPU上实现高效的延迟渲染。必须支持多目标渲染。 需要大容量显存存储G-Buffer。假设你想做一个更完整的各向异性 BRDF,需要额外参数:
-
anisotropy strength
-
anisotropy direction
-
maybe secondary lobe weight
如果默认 GBuffer 没有空间存这些量,你在 Material Graph 里即使能算出来,也很难把它们完整传递给后续 deferred light loop。
能做的通常只有几种折中:
- 挤占已有通道,牺牲别的语义
临时在某个 pass 里 fake改成 forward 或 unlit 近似处理
真正系统化的办法是改:
-
GBuffer packing
-
material template
-
deferred shading decode
-
light integration path
光照积分方式:为什么你能改 BRDF 输入,但不能改整个受光机制Material Graph 里你可以输出:
-
Roughness
-
Normal
-
BaseColor
-
F0 近似
-
ClearCoat input
-
Subsurface input
-
但真正的 direct lighting / indirect lighting 是由引擎固定积分方式算的。 也就是说,Material Graph 只能影响:
BRDF 的参数输入,
但不能直接决定:
-
灯光循环怎么遍历
-
NDF / G / F 的具体组合逻辑
-
-
多光源累加如何处理
-
IBL 用什么 LUT / prefilter
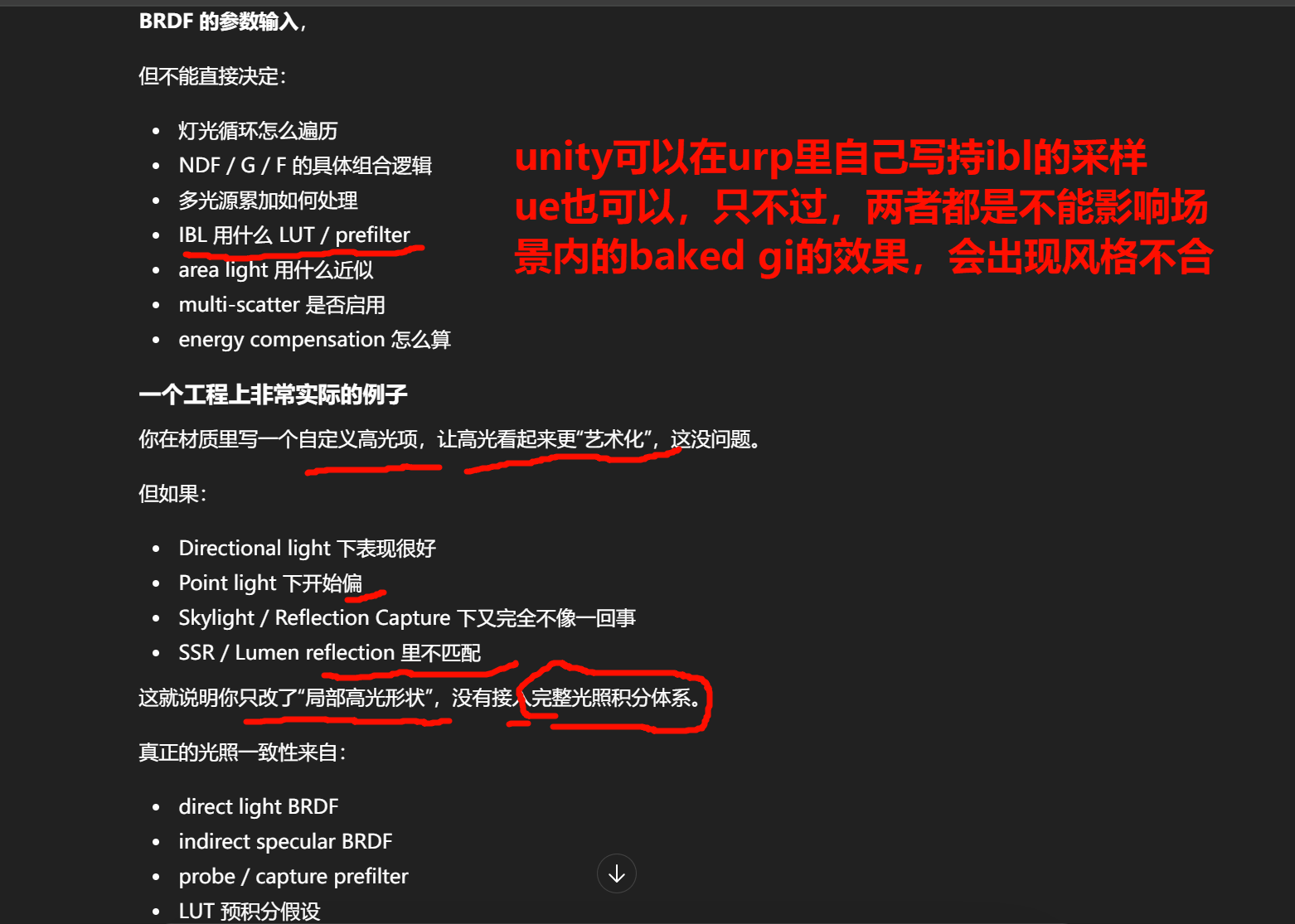
真正的光照一致性来自:
-
direct light BRDF
-
indirect specular BRDF
-
probe / capture prefilter
-
LUT 预积分假设
-
shadow term / visibility term 组合
这些都不在 Material Graph 权限里。
Material Graph 能说:
这个表面比较粗糙,法线朝这边,反照率是这个。
但它不能说:
引擎,从今天开始请按新的光照数学来解释这些属性。
shadowing pipeline:为什么材质能"看起来像在影响阴影",但其实没改阴影系统
-
用 AO、curvature、mask 做局部压暗
-
用 Fresnel / view term 假装接触阴影
-
用 Dither / PDO 做接地过渡
-
用 emissive/opacity 做风格化假受光
这些都能显著改变观感,但它们不是"阴影系统本身"。
真正的 shadowing pipeline 包括:
-
shadow map / VSM / VSM page / CSM / VSM resolve
-
shadow depth pass 怎么生成
-
filtering 策略(PCF、PCSS、EVSM、MSM 等)
-
receiver bias / normal bias
-
contact shadow
-
ray traced shadow / distance field shadow
-
translucency shadow handling
-
virtual shadow map residency 和 page cache
这些是 visibility + light occlusion 的系统,不是材质图层面的局部表达。
