RAFT: Recurrent All-Pairs Field Transforms 完整技术总结
这篇文章我看了很久,并且借助AI对细节更深入了进行了解,这篇论文是raft stereo的前提,raft stereo是目前主流迭代式密集匹配的开端,所以了解raft的原理和思路还是很有必要的。
目录
1. 概述与核心贡献
1.1 光流估计背景
光流估计是计算机视觉中的核心任务,传统上被建模为手工设计的能量最小化问题:
min f E d a t a ( I 1 , I 2 , f ) ⏟ 数据项:视觉相似性 + E s m o o t h ( f ) ⏟ 正则化项:运动合理性 \min_{f} \underbrace{E_{data}(I_1, I_2, f)}{\text{数据项:视觉相似性}} + \underbrace{E{smooth}(f)}_{\text{正则化项:运动合理性}} fmin数据项:视觉相似性 Edata(I1,I2,f)+正则化项:运动合理性 Esmooth(f)
传统方法(如Horn-Schunk、TV-L1)面临的主要挑战:
- 需要手工设计优化目标
- 难以处理各种边界情况(corner cases)
- 粗到细(coarse-to-fine)策略容易丢失小物体和快速运动
1.2 RAFT的三大核心优势
| 指标 | RAFT表现 | 对比基准 | 提升幅度 |
|---|---|---|---|
| KITTI F1-all | 5.10% | 6.10% (此前最佳) | 16%误差降低 |
| Sintel EPE | 2.855像素 | 4.098像素 (此前最佳) | 30%误差降低 |
| 跨域泛化(KITTI) | 5.04像素 | 8.36像素 (此前最佳深度网络) | 40%误差降低 |
| 推理速度 | 10 FPS (1088×436) | - | 高效 |
| 训练迭代次数 | 100K+60K | >1M (其他架构) | 10倍减少 |
2. 理论架构
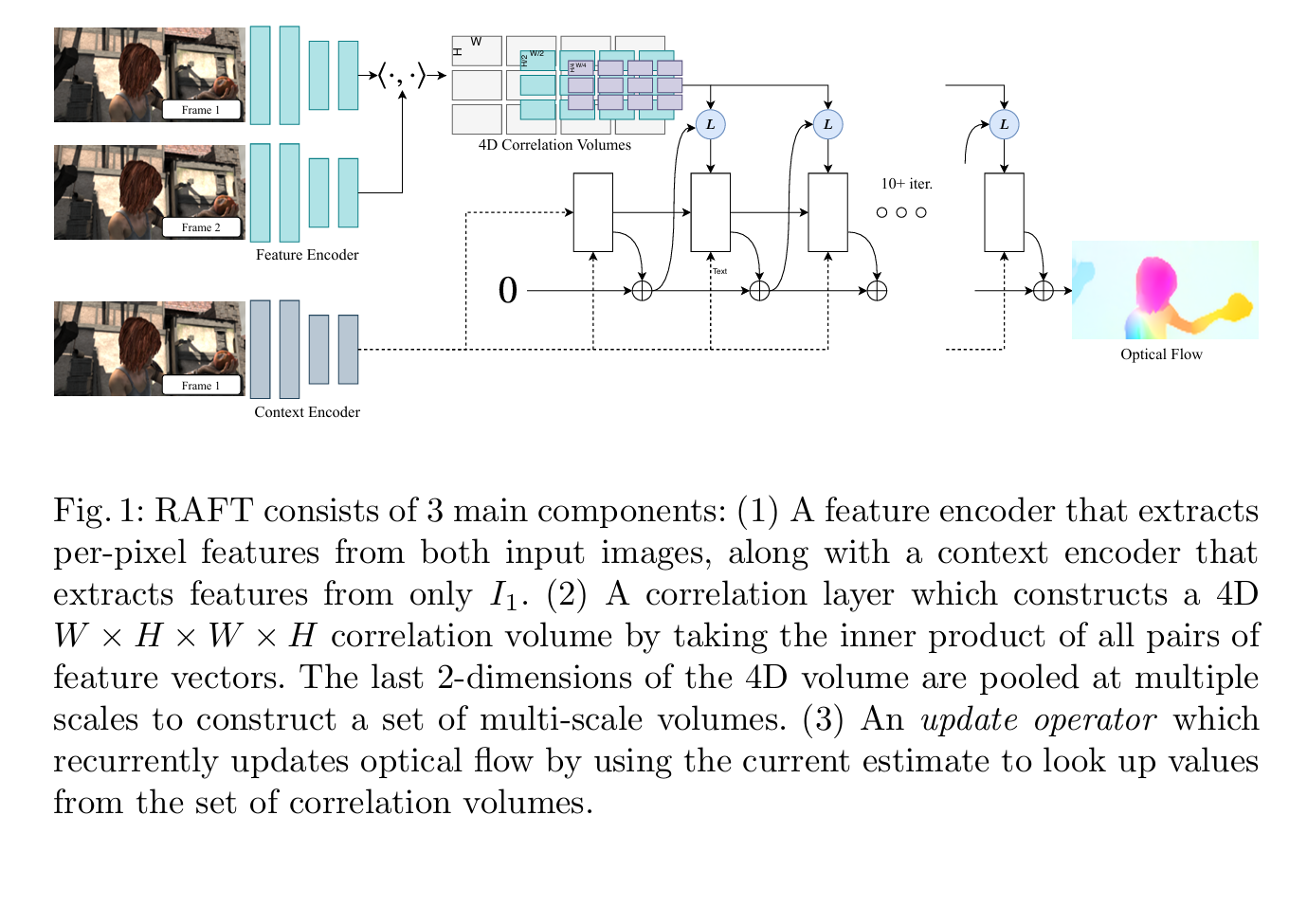
2.1 整体架构设计哲学
RAFT的设计深受传统优化方法启发,但完全采用可学习的组件替代手工设计:
传统方法 RAFT
─────────────────────────────────────────────────
特征提取(手工设计) → 特征编码器 g_θ (CNN学习)
相似性度量(固定函数) → 4D相关体积 (内积计算)
迭代优化(固定规则) → ConvGRU更新算子 (学习)关键创新:RAFT在单一高分辨率上维护和更新光流场,而非传统的粗到细金字塔结构。
2.2 三阶段流程
┌─────────────────────────────────────────────────────────────┐
│ Stage 1: 特征提取 (Feature Extraction) - 仅需执行一次 │
│ │
│ Frame 1 ──→ Feature Encoder g_θ ──┐ │
│ ├──→ (·,·) → 4D Corr │
│ Frame 2 ──→ Feature Encoder g_θ ──┘ │
│ │
│ Frame 1 ──→ Context Encoder h_θ ──→ L (上下文特征) │
│ │
├─────────────────────────────────────────────────────────────┤
│ Stage 2: 计算视觉相似性 (Visual Similarity) │
│ │
│ 构建4D相关体积 C ∈ R^(H×W×H×W) │
│ 通过池化生成多尺度体积 (1/4, 1/8分辨率) │
│ │
├─────────────────────────────────────────────────────────────┤
│ Stage 3: 迭代更新 (Iterative Updates) - 可执行100+次 │
│ │
│ f_0 = 0 │
│ for t = 1 to N: │
│ h_t, Δf_t = UpdateBlock(h_{t-1}, f_{t-1}, C, L) │
│ f_t = f_{t-1} + Δf_t │
│ │
└─────────────────────────────────────────────────────────────┘2.3 与传统粗到细方法的对比
| 特性 | 粗到细方法 (PWC-Net等) | RAFT (单分辨率) |
|---|---|---|
| 流程 | 低分辨率→高分辨率逐级细化 | 单一高分辨率迭代优化 |
| 小物体 | 容易丢失 | 可以捕捉 |
| 快速运动 | 难以恢复 | 通过4D体积处理 |
| 错误恢复 | 早期错误会传播 | 每次迭代都使用完整信息 |
| 训练 | 通常需要>1M次迭代 | 仅需100K+60K次迭代 |
3. 技术细节详解
3.1 特征提取网络 (Feature Extraction)
3.1.1 网络结构
特征编码器 g_θ 和上下文编码器 h_θ 具有相同的架构,仅在归一化方式上有区别:
| 组件 | 特征编码器 g_θ | 上下文编码器 h_θ |
|---|---|---|
| 归一化 | Instance Normalization | Batch Normalization |
| 输入 | Frame 1, Frame 2 | Frame 1 only |
| 输出用途 | 构建4D相关体积 | 提供给Update Block |
| 输出维度 | H/8 × W/8 × 256 | H/8 × W/8 × 256 |
3.1.2 维度变换详解(以480×640输入为例)
输入图像: I ∈ R^(480×640×3)
第0步: Conv7×7, stride=2, 输出通道=64
480×640×3 ──→ 240×320×64
(H/2 × W/2)
第1步: Res.Unit×2 + Conv3×3, stride=2, 输出通道=256
240×320×64 ──→ 120×160×256
(H/4 × W/4)
第2步: Res.Unit×2 + Conv3×3, stride=2, 输出通道=256
120×160×256 ──→ 60×80×256
(H/8 × W/8) ← 最终输出分辨率
关键理解:
- 256通道: 每个像素的特征向量维度
- 1/8分辨率: 空间下采样8倍 (480/8=60, 640/8=80)
- 这实现了计算效率与特征表达力的平衡3.1.3 残差单元 (Residual Unit) 结构
输入 x
│
├──→ Conv1×1 (降维) ──→ Conv3×3 ──→ Conv1×1 (升维) ──┐
│ │
└────────────────→ (捷径连接) ───────────────────────→ ⊕ ──→ 输出
(相加)RAFT-S轻量版修改:使用Bottleneck结构减少参数量
3.2 4D相关体积 (4D Correlation Volume)
3.2.1 数学定义
给定特征图 g θ ( I 1 ) , g θ ( I 2 ) ∈ R H × W × D g_\theta(I_1), g_\theta(I_2) \in \mathbb{R}^{H \times W \times D} gθ(I1),gθ(I2)∈RH×W×D,4D相关体积定义为所有像素对的点积:
C i j k l = ⟨ g θ ( I 1 ) i j , g θ ( I 2 ) k l ⟩ = ∑ d = 1 D g θ ( I 1 ) i j d ⋅ g θ ( I 2 ) k l d C_{ijkl} = \langle g_\theta(I_1){ij}, g\theta(I_2){kl} \rangle = \sum{d=1}^{D} g_\theta(I_1){ijd} \cdot g\theta(I_2)_{kld} Cijkl=⟨gθ(I1)ij,gθ(I2)kl⟩=d=1∑Dgθ(I1)ijd⋅gθ(I2)kld
维度: C ∈ R H × W × H × W C \in \mathbb{R}^{H \times W \times H \times W} C∈RH×W×H×W
3.2.2 多尺度池化金字塔
为处理不同尺度的运动,RAFT构建相关体积金字塔:
层级 池化核 分辨率 用途
─────────────────────────────────────────────────
Level 0 1×1 (原始) H×W×H×W 小位移精细匹配
Level 1 2×2, stride2 H×W×H/2×W/2 中等位移
Level 2 4×4, stride4 H×W×H/4×W/4 大位移关键优势:每个局部更新都能同时访问小位移和大位移信息,无需显式的粗到细处理。
3.2.3 查找操作 (Lookup)
给定当前光流估计 f t f_t ft,在特征图 g θ ( I 2 ) g_\theta(I_2) gθ(I2) 上计算对应位置:
x ′ = x + f t ( x ) x' = x + f_t(x) x′=x+ft(x)
通过双线性插值从相关体积中检索特征:
C o r r ( x ) = ∑ i , j ∈ N ( x ′ ) w i j ⋅ C ( x , i , j ) Corr(x) = \sum_{i,j \in \mathcal{N}(x')} w_{ij} \cdot C(x, i, j) Corr(x)=i,j∈N(x′)∑wij⋅C(x,i,j)
其中 N ( x ′ ) \mathcal{N}(x') N(x′) 是 x ′ x' x′ 的邻域, w i j w_{ij} wij 是双线性插值权重。
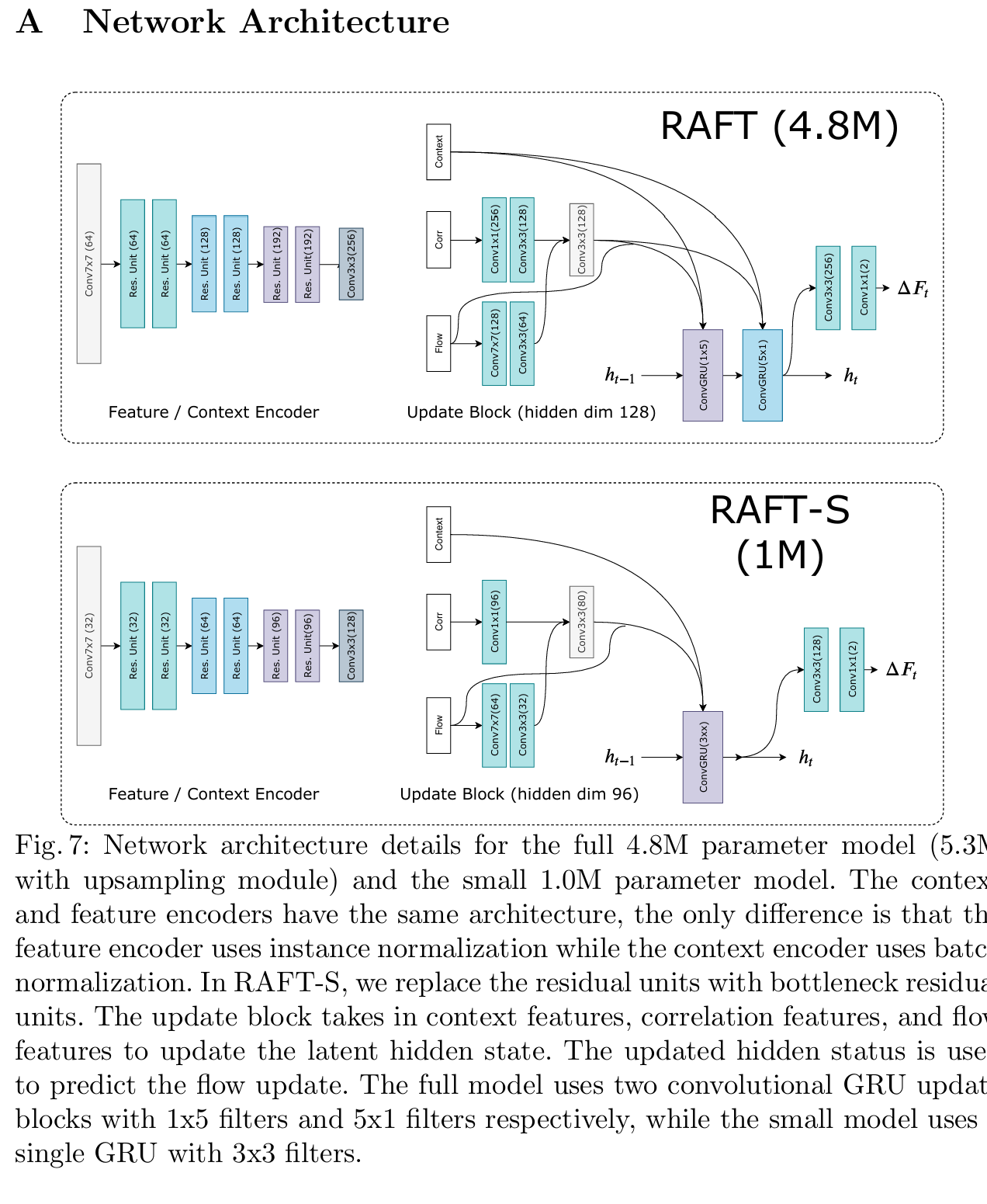
3.3 更新算子 (Update Operator)
3.3.1 整体结构
Update Block是RAFT的核心创新,采用级联ConvGRU结构:
完整版 RAFT (4.8M参数):
┌─────────────────────────────────────────┐
│ 输入特征 x_t (448维) │
│ = [上下文特征; 相关特征; 光流特征] │
│ │
│ x_t ──→ ConvGRU(1×5) ──→ h_t^(1) │
│ ↑ │
│ h_{t-1}^(1) (隐藏状态1) │
│ │
│ h_t^(1) ──→ ConvGRU(5×1) ──→ h_t^(2) │
│ ↑ │
│ h_{t-1}^(2) (隐藏状态2) │
│ │
│ h_t^(2) ──→ Conv1×1(2) ──→ Δf_t │
│ (预测光流更新) │
└─────────────────────────────────────────┘
轻量版 RAFT-S (1M参数):
┌─────────────────────────────────────────┐
│ x_t ──→ ConvGRU(3×3) ──→ h_t │
│ ↑ │
│ h_{t-1} (96维隐藏状态) │
│ │
│ h_t ──→ Conv1×1(2) ──→ Δf_t │
└─────────────────────────────────────────┘Update Block 结构分析
-
输入特征:
- 输入特征 ( x_t ) 包含上下文特征、相关特征和光流特征。这些特征在进入第一个ConvGRU之前经过了一些卷积层处理。
-
第一个ConvGRU:
- 输入:( x_t )(包含上下文、相关和光流特征)。
- 输出:生成隐藏状态 ( h_t\^{(1)} )。
- 隐藏状态:( h_{t-1}\^{(1)} ) 是第一个ConvGRU的前一时刻的隐藏状态。
-
第二个ConvGRU:
- 输入 :第二个ConvGRU的输入是第一个ConvGRU的输出 ( h t ( 1 ) h_t^{(1)} ht(1) ),而不是原始的输入特征 ( x_t )。
- 输出 :生成最终的隐藏状态 ( h t ( 2 ) h_t^{(2)} ht(2) )。
- 隐藏状态:( h_{t-1}\^{(2)} ) 是第二个ConvGRU的前一时刻的隐藏状态。
- 两个隐藏状态的存在:确实存在两个隐藏状态,但它们分别对应于两个不同的ConvGRU层。第一个ConvGRU处理输入特征并生成中间隐藏状态,第二个ConvGRU则进一步处理这个中间隐藏状态。
- 输入关系:第二个ConvGRU的输入是第一个ConvGRU的输出,这样设计的目的是为了在每个时间步中逐步优化光流估计。
3.3.2 ConvGRU详解
GRU (Gated Recurrent Unit) 是一种解决长期记忆问题的循环神经网络,通过门控机制控制信息流动。
标准GRU公式 :
z t = σ ( W z ⋅ h t − 1 , x t ) (更新门) z_t = \sigma(W_z \cdot h_{t-1}, x_t) \quad \text{(更新门)} zt=σ(Wz⋅ht−1,xt)(更新门)
r t = σ ( W r ⋅ h t − 1 , x t ) (重置门) r_t = \sigma(W_r \cdot h_{t-1}, x_t) \quad \text{(重置门)} rt=σ(Wr⋅ht−1,xt)(重置门)
h ~ t = tanh ( W ⋅ r t ⊙ h t − 1 , x t ) (候选状态) \tilde{h}t = \tanh(W \cdot r_t \\odot h_{t-1}, x_t) \quad \text{(候选状态)} h~t=tanh(W⋅rt⊙ht−1,xt)(候选状态)
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t (状态更新) h_t = (1 - z_t) \odot h{t-1} + z_t \odot \tilde{h}_t \quad \text{(状态更新)} ht=(1−zt)⊙ht−1+zt⊙h~t(状态更新)
ConvGRU(本文使用):将矩阵乘法替换为卷积运算
z t = σ ( Conv 3 × 3 ( h t − 1 , x t ) ) z_t = \sigma(\text{Conv}{3\times3}(h_{t-1}, x_t)) zt=σ(Conv3×3(ht−1,xt))
r t = σ ( Conv 3 × 3 ( h t − 1 , x t ) ) r_t = \sigma(\text{Conv}{3\times3}(h_{t-1}, x_t)) rt=σ(Conv3×3(ht−1,xt))
h ~ t = tanh ( Conv 3 × 3 ( r t ⊙ h t − 1 , x t ) ) \tilde{h}t = \tanh(\text{Conv}{3\times3}(r_t \\odot h_{t-1}, x_t)) h~t=tanh(Conv3×3(rt⊙ht−1,xt))
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t ht=(1−zt)⊙ht−1+zt⊙h~t
为什么使用ConvGRU?
- 普通GRU:处理一维序列(如文本)
- ConvGRU:保留空间结构,适合图像/特征图数据
- 门控机制使光流估计序列更容易收敛
3.3.3 输入特征组成 (448维详解)
x_t = [上下文特征; 相关特征; 光流特征]
1. 上下文特征 (Context Features): 128维
- 来源: Context Encoder h_θ 的输出
- 作用: 提供场景语义信息,指导更新方向
2. 相关特征 (Correlation Features): 256维
- 来源: 从4D相关体积中查找得到
- 组成:
* Level 0: 128维 (原始分辨率)
* Level 1: 64维 (1/2池化)
* Level 2: 64维 (1/4池化)
- 作用: 提供视觉相似性信息
3. 光流特征 (Flow Features): 64维
- 来源: 当前光流估计 f_t 经过1×1卷积
- 作用: 编码当前运动估计
总计: 128 + 256 + 64 = 448维3.3.4 可分离卷积 vs 标准卷积
完整版RAFT使用可分离卷积(1×5和5×1):
- 优势:更大感受野(5×5),参数量更少
- 计算:先水平卷积(1×5),再垂直卷积(5×1)
轻量版RAFT-S使用标准卷积(3×3):
- 优势:实现简单,计算更快
- 权衡:感受野较小,精度略低
3.4 上采样模块 (Upsampling Module)
3.4.1 凸组合上采样
RAFT采用学习的凸组合进行8倍上采样:
低分辨率光流 (H/8 × W/8 × 2)
│
▼
为每个高分辨率像素
预测9个权重(对应3×3邻域)
│
▼
凸组合: f_high = Σ w_ij · f_low(i,j)
约束: Σ w_ij = 1, w_ij ≥ 0
│
▼
高分辨率光流 (H × W × 2)优势:
- 比双线性插值更精确
- 能恢复运动边界细节
- 可捕捉小物体(如快速飞鸟)
3.5 训练策略
| 阶段 | 数据集 | 学习率 | 批次大小 | 权重衰减 | 裁剪尺寸 |
|---|---|---|---|---|---|
| Chairs | FlyingChairs© | 4e-4 | 6 | 1e-4 | 368×496 |
| Things | Chairs→FlyingThings(T) | 1.2e-4 | 3 | 1e-4 | 400×720 |
| Sintel微调 | S+T+K+H | 1.2e-4 | 3 | 1e-5 | 368×768 |
| KITTI微调 | KITTI-2015(K) | 1e-4 | 3 | 1e-5 | 288×960 |
数据增强:
- 光度增强:亮度、对比度、饱和度、色调随机扰动
- 几何增强:随机缩放、平移、旋转
损失函数 :
L = ∑ i = 1 N γ N − i ∣ ∣ f g t − f i ∣ ∣ 1 L = \sum_{i=1}^{N} \gamma^{N-i} ||f_{gt} - f_i||_1 L=i=1∑NγN−i∣∣fgt−fi∣∣1
其中 γ = 0.8 \gamma=0.8 γ=0.8, f i f_i fi 是第 i i i 次迭代的光流预测。
4. 实验内容与结论
4.1 主要实验结果
Sintel数据集
| 方法 | Clean Pass EPE | Final Pass EPE |
|---|---|---|
| FlowNet2 | 2.02 | 3.54 |
| PWC-Net | 2.55 | 3.93 |
| LiteFlowNet | 2.23 | 3.78 |
| RAFT | 1.43 | 2.71 |
KITTI数据集
| 方法 | F1-all (%) | EPE (pixels) |
|---|---|---|
| PWC-Net | 9.60 | 10.35 |
| LiteFlowNet | 8.75 | 8.97 |
| RAFT | 5.10 | 5.04 (跨域泛化) |
4.2 消融实验关键结论
| 实验 | 配置 | Sintel Final EPE | 结论 |
|---|---|---|---|
| Update算子架构 | ConvGRU | 2.83 | GRU门控机制有助于收敛 |
| 纯Conv层 | 3.21 | 性能下降 | |
| 权重共享 | 共享权重 | 2.83 | 与固定迭代次数相当 |
| 不共享 | 2.83 | - | |
| 上采样方式 | 凸组合 | 2.71 | 边界更精确 |
| 双线性 | 2.79 | 小物体易丢失 | |
| 迭代次数 | 1次 | 5.45 | 严重欠拟合 |
| 8次 | 2.88 | 基本可用 | |
| 32次 | 2.71 | 最佳平衡点 | |
| 100次 | 2.72 | 边际收益递减 | |
| 200次 | 2.73 | 几乎无提升 |
4.3 效率分析
参数量 vs 精度:
- RAFT (4.8M参数): Sintel Final EPE = 2.71
- RAFT-S (1M参数): Sintel Final EPE = 2.83
- 对比: PWC-Net (约9M参数): EPE = 3.93
推理速度 (1088×436分辨率):
- RAFT: 10 FPS (100次迭代)
- RAFT-S: 20 FPS
训练效率:
- RAFT: 100K (Chairs) + 60K (Things) = 160K次迭代
- 其他架构: 通常需要 >1参数量 vs 精度:
- RAFT (4.8M参数): Sintel Final EPE = 2.71
- RAFT-S (1M参数): Sintel Final EPE = 2.83
- 对比: PWC-Net (约9M参数): EPE = 3.93
推理速度 (1088×436分辨率):
- RAFT: 10 FPS (100次迭代)
- RAFT-S: 20 FPS
训练效率:
- RAFT: 100K (Chairs) + 60K (Things) = 160K次迭代
- 其他架构: 通常需要 >1M次迭代
5. 关键概念速查表
| 概念 | 描述 |
|---|---|
| 光流估计 | 计算图像序列中物体运动的技术。 |
| RAFT | Recurrent All-Pairs Field Transforms,基于递归更新的光流估计方法。 |
| 特征编码器 | 提取图像特征的网络组件。 |
| 相关层 | 计算图像特征之间相似性的层。 |
| 更新算子 | 基于GRU的递归更新机制,用于迭代优化光流估计。 |
| 4D相关体积 | 存储所有像素对之间相似性的四维张量。 |
| ConvGRU | 卷积门控递归单元,适用于图像数据的递归网络。 |
| 上采样模块 | 将低分辨率光流场上采样到原始分辨率的模 |