目录
[一、 物联网时代的时序数据挑战](#一、 物联网时代的时序数据挑战)
[二、 构建理想时序数据底座的核心维度](#二、 构建理想时序数据底座的核心维度)
[三、 Apache IoTDB:高性能的物联网原生时序数据库](#三、 Apache IoTDB:高性能的物联网原生时序数据库)
[3.1 核心产品体系拆解](#3.1 核心产品体系拆解)
[3.2 产品核心特性解析](#3.2 产品核心特性解析)
[四、 赋能多行业场景,释放时序数据潜能](#四、 赋能多行业场景,释放时序数据潜能)
[五、 商业支持与资源获取](#五、 商业支持与资源获取)
前言
在当前的数字化浪潮中,无论是智能工厂里的机床、穿梭于城市的轨道交通,还是风力发电站的涡轮机,无以计数的物理设备正持续被接入网络。这些设备以毫秒级甚至微秒级的频率,不断生成温度、压力、速度、振动等运行数据。这些带有时间戳的数据被称为时序数据。对于企业而言,时序数据不仅是记录设备状态的流水日志,更是进行故障预警、能耗优化和智能决策的重要资产。
然而,当设备数量达到百万级、每日新增数据量达到千亿条时,传统的基础架构往往显得力不从心,不仅写入和查询延迟高,存储成本更是难以承受。面对这种困境,寻找一款真正契合物联网特性的时序数据库,成为了众多企业数字化转型中必须解决的问题。
一、 物联网时代的时序数据挑战
物联网场景下的数据有着极其鲜明的特征,这使得传统数据库甚至部分早期的大数据组件在处理时面临巨大压力。具体而言,企业在构建物联网大数据平台时,通常会遇到以下几大痛点:
(1)数据体量庞大且采样频率极高
在工业现场,测点数量庞大。一个中型制造企业可能拥有数十万个传感器,持续以高频采集数据。每天产生的数据量轻松突破 TB 甚至 PB 级。如果底层架构缺乏针对性的高吞吐设计,系统将极易在数据洪峰中出现性能瓶颈。
(2)复杂的应用场景与数据乱序问题
网络波动、设备离线重启、边缘网关缓存重发等情况在物联网环境中十分常见。这导致大量数据到达数据中心时,时间戳并不是严格按照先后顺序排列的,产生了大量的"乱序数据"。系统必须具备强大的乱序数据处理能力,且不能因此大幅拖慢整体写入和查询性能。
(3)多元化的分析需求与处理耗时
单纯的数据存储只是第一步,业务端更看重的是数据背后的价值。无论是简单的降采样聚合(如求每小时的平均温度)、复杂的时间序列对齐,还是面向未来的深度特征提取,都需要数据库层提供底层的算力支持。如果计算链路过长、处理耗时过多,就无法满足工业现场对实时预警和敏捷调度的需求。
(4)居高不下的存储与运维成本
海量数据如果得不到高比例的压缩,企业将面临高昂的磁盘和服务器采购成本。同时,如果系统部署复杂、节点扩容困难、缺乏易用的监控和管理工具,企业的 IT 运维团队将被繁重的日常维护工作拖垮。
二、 构建理想时序数据底座的核心维度
基于上述痛点,如果企业准备重新规划或升级其时序数据架构,在考察各类基础软件时,应当重点关注以下几个核心维度:
(1)原生的物联网数据模型适配
优秀的底层架构需要能自然地反映物理世界的真实结构。工业现场往往呈现"厂区-车间-产线-设备-测点"的树状层级关系。基础软件应当能够支持层级化的测点组织与管理,让开发和业务人员可以直接通过符合人类直觉的逻辑进行数据检索和建模。
(2)极高的写入吞吐与低硬件成本存储
必须能够支撑百万级设备的并发接入与高速读写,同时兼顾复杂工业读写场景(如多频采集、乱序写入)。在存储方面,需要具备极高的数据压缩比,能够在不影响查询性能的前提下,大幅缩减历史数据的物理存储空间。理想的架构应能实现历史数据与实时数据的统一管理,无需人为区分冷热库,从而降低系统复杂性。
(3)丰富高效的时序查询与计算支撑
时序数据最典型的应用是基于时间窗口的聚合分析。理想的基础平台应当内置丰富的时序处理函数,支持查询时的时间戳自动对齐。更进一步,系统若能整合一定的智能分析计算能力,在库内完成时序特征分析或模型推断,将极大缩短数据从存储到产生决策价值的路径。
(4)高可用性、灵活部署与极低使用门槛
物联网场景往往跨越边缘端与云端。因此,系统需支持终端解压即用、云端一键部署,以及端云之间的无缝协同同步。在集群层面,应当具备分布式高可用架构,能够容忍节点故障,实现稳定不间断服务,并能根据负载自动均衡资源。而在使用层面,如果能支持类 SQL 的查询语言,并提供多语言接口和完善的可视化控制台,将极大降低开发与运维门槛。
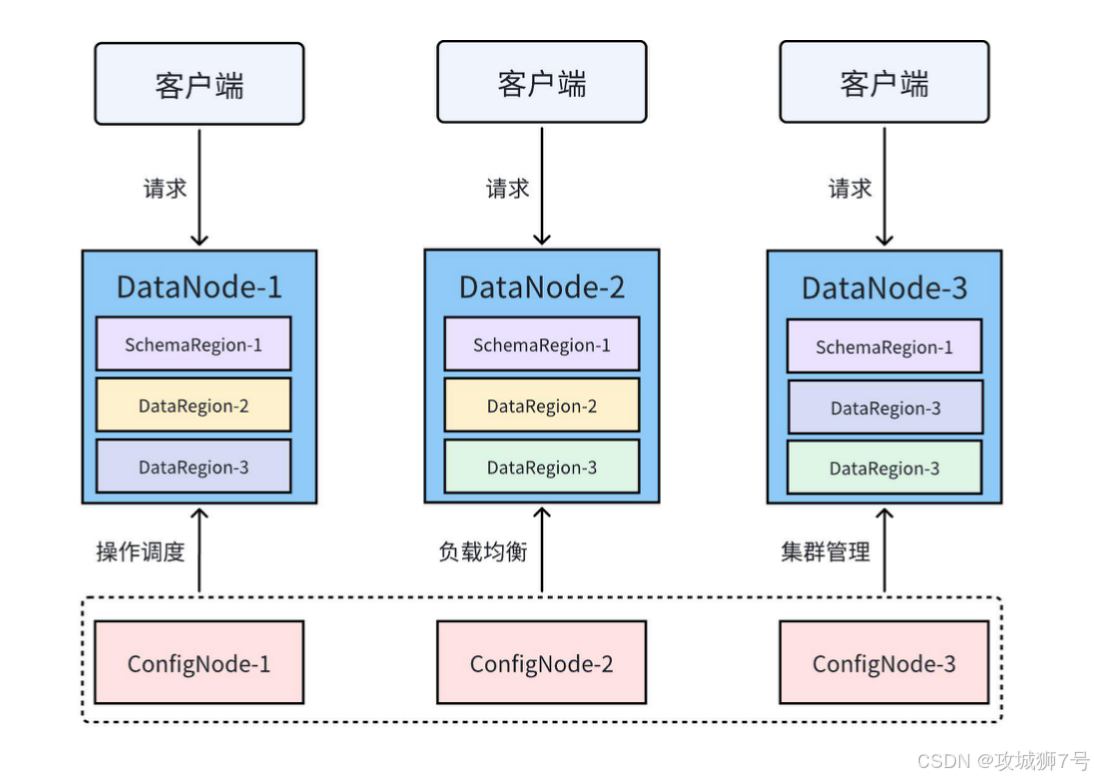
三、 Apache IoTDB:高性能的物联网原生时序数据库
为了解决企业在管理时序数据时遇到的高昂成本和复杂技术挑战,Apache IoTDB 应运而生。作为一款低成本、高性能的物联网原生时序数据库,IoTDB 的设计初衷就是直面物联网领域的种种难题。它的产品体系由多个深度打磨的组件构成,全方位覆盖了时序数据的采集、存储、管理与分析。
3.1 核心产品体系拆解
**时序数据库(Apache IoTDB):**作为整个产品体系的核心,IoTDB 提供了强悍的底层支撑。它不仅具备高压缩存储能力和丰富的时序查询能力,还能处理实时流数据。其分布式架构保证了数据的高可用与集群的高扩展性,并在全方位提供安全保障。此外,IoTDB 内置了完善的控制台应用工具以及多语言 API,非常便于外部系统集成与业务应用开发。
**时序数据标准文件格式(Apache TsFile):**这是 IoTDB 生态的一大亮点。TsFile 是一种专为时序数据设计的底层存储文件格式。通过精心设计的数据块和列式存储结构,TsFile 能够极其高效地存储和查询海量数据。在 IoTDB 的生态中,TsFile 是通用的底层语言。用户可以在边缘采集端直接生成 TsFile,然后将其无缝同步传输到云端的数据中心或分析引擎中。这种"一份文件贯穿全流程"的设计,极大简化了数据流转链路,提高了整体管理效率。
**时序模型训推一体化引擎(IoTDB AINode):**面向更高阶的智能分析场景,IoTDB 在架构中引入了 AINode 组件。它底层包含模型训练引擎,支持训练任务的管理与数据调度,并兼容主流的机器学习和深度学习算法。这意味着企业无需将海量时序数据费力导出到第三方算法平台,而是可以直接利用系统内置的一体化引擎,就近对数据进行深度挖掘与价值提炼。
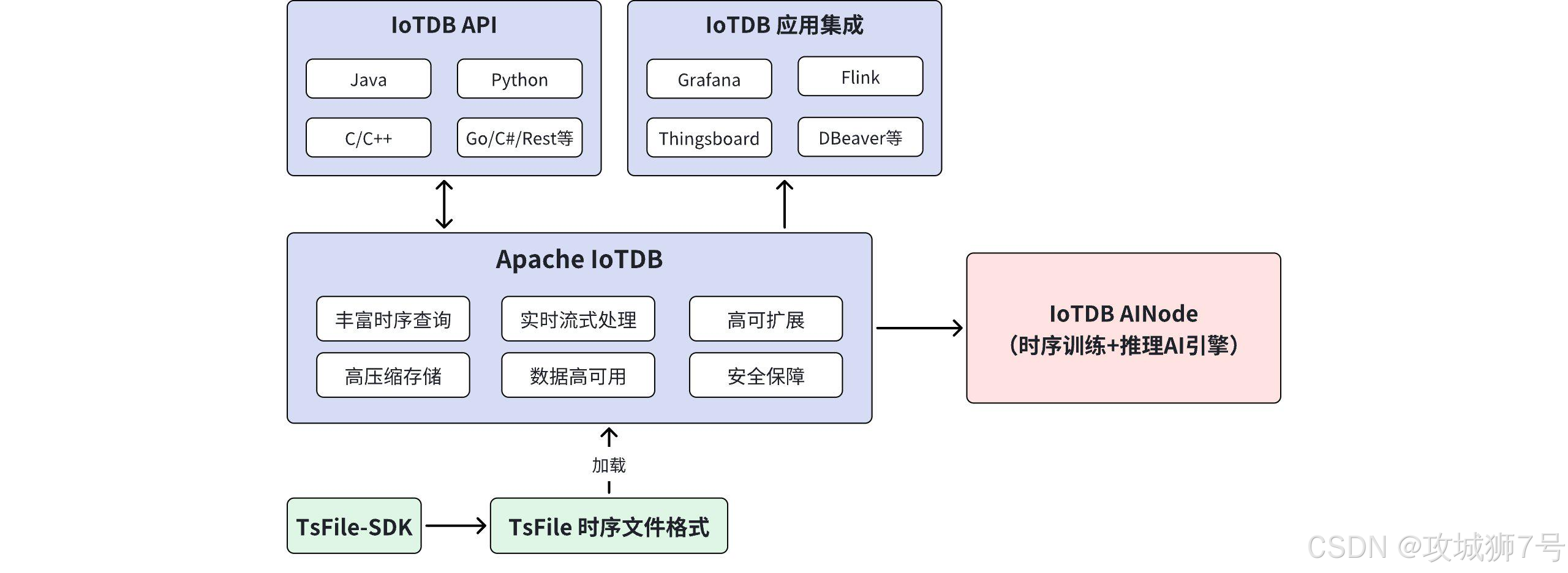
3.2 产品核心特性解析
**灵活敏捷的部署方式:**IoTDB 不仅支持大型云端数据中心的一键部署,还可以轻量级地部署在资源受限的边缘终端设备上。配合其内置的数据云端同步工具,企业可以轻松构建"终端-云端"无缝连接的时序数据网络。
**低硬件成本的高效存储:**依靠底层 TsFile 的深度优化,IoTDB 实现了极高压缩比的磁盘存储。它突破了传统架构中需要设立独立的"实时内存库"与"历史磁盘库"的桎梏,实现对所有数据的统一集中管理,大幅削减了硬件采购与存储成本。
**层级化的测点组织管理:**IoTDB 创新性地支持在系统中根据物理设备的实际层级关系进行树状建模。这种结构能够完美对齐工业测点的管理规范,支持针对层级目录的快速查看与高效检索,极大降低了业务逻辑映射的难度。
**高通量的极速数据读写:**无论是百万级设备并发接入,还是高频率的采样写入,亦或是处理延迟到达的乱序数据,IoTDB 均能保持稳定的高速读写能力,从容应对各类严苛的工业级场景。
**丰富的原生时序查询语义:**基于时序数据原生计算引擎,IoTDB 能够自动在查询时对齐时间戳。它提供近百种内置的聚合与时序计算函数,免去了用户自行编写大量处理逻辑的麻烦,并支持面向时序特征的深度分析及计算。
**高可用与自动负载均衡:**基于先进的 HA(高可用)分布式架构设计,IoTDB 集群能够提供 7×24 小时不间断的服务。在集群中,即使个别物理节点发生网络故障或意外宕机,也不会影响整个系统的正常运作。系统支持动态增加、删除节点,并自动完成存储与计算资源的负载均衡。同时支持异构环境,不同配置的服务器均可纳入同一集群协同工作。
**平易近人的使用与运维体验:**提供了贴近主流体系的类 SQL 查询语言,技术人员几乎不需要重新学习即可上手。原生的多语言二次开发接口及完善的控制台体系,拉低了日常开发与运维的门槛。
**高度开放的生态环境对接:**在大数据生态方面,它可以对接 Hadoop、Spark 等主流分析组件;在前端展示与设备管理上,原生支持与 Grafana、Thingsboard、DataEase 等热门可视化工具的平滑集成。
四、 赋能多行业场景,释放时序数据潜能
Apache IoTDB 以其卓越的性能和稳定性,已在诸多重要行业中得到了广泛深度应用。
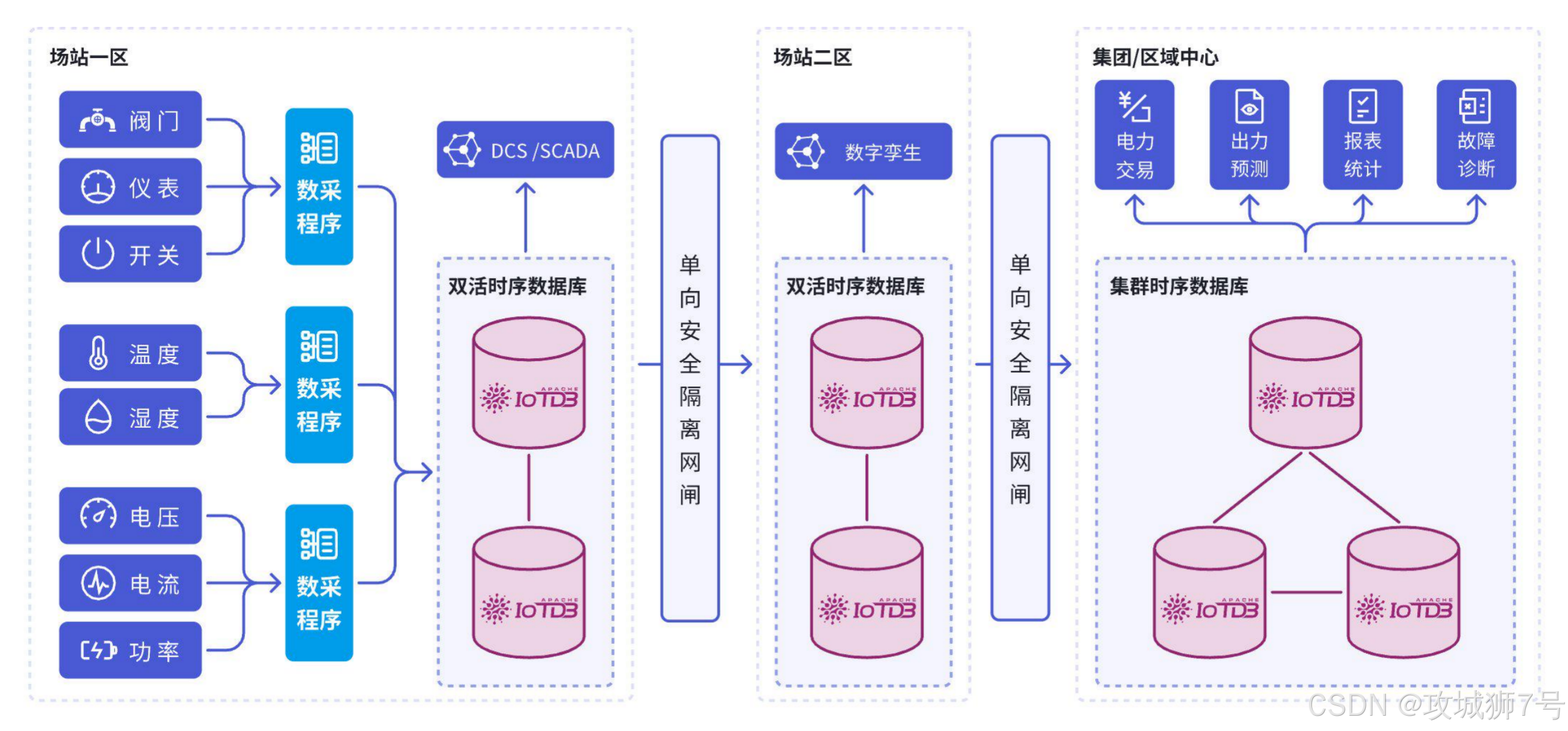
(1)能源电力:保障电网安全与高效调度
在能源的生产、传输、存储与消费各个环节,时序数据无处不在。对这些数据进行实时监控、精准预测与智能调度,直接关系到电网的稳定。IoTDB 凭借其集群高可用性、低流量的数据同步机制以及对跨网闸等复杂网络环境的支持,为能源企业提供了自主可控的底层解决方案,帮助企业从容应对大规模管理挑战,推动传统能源与可再生能源的整合调度。
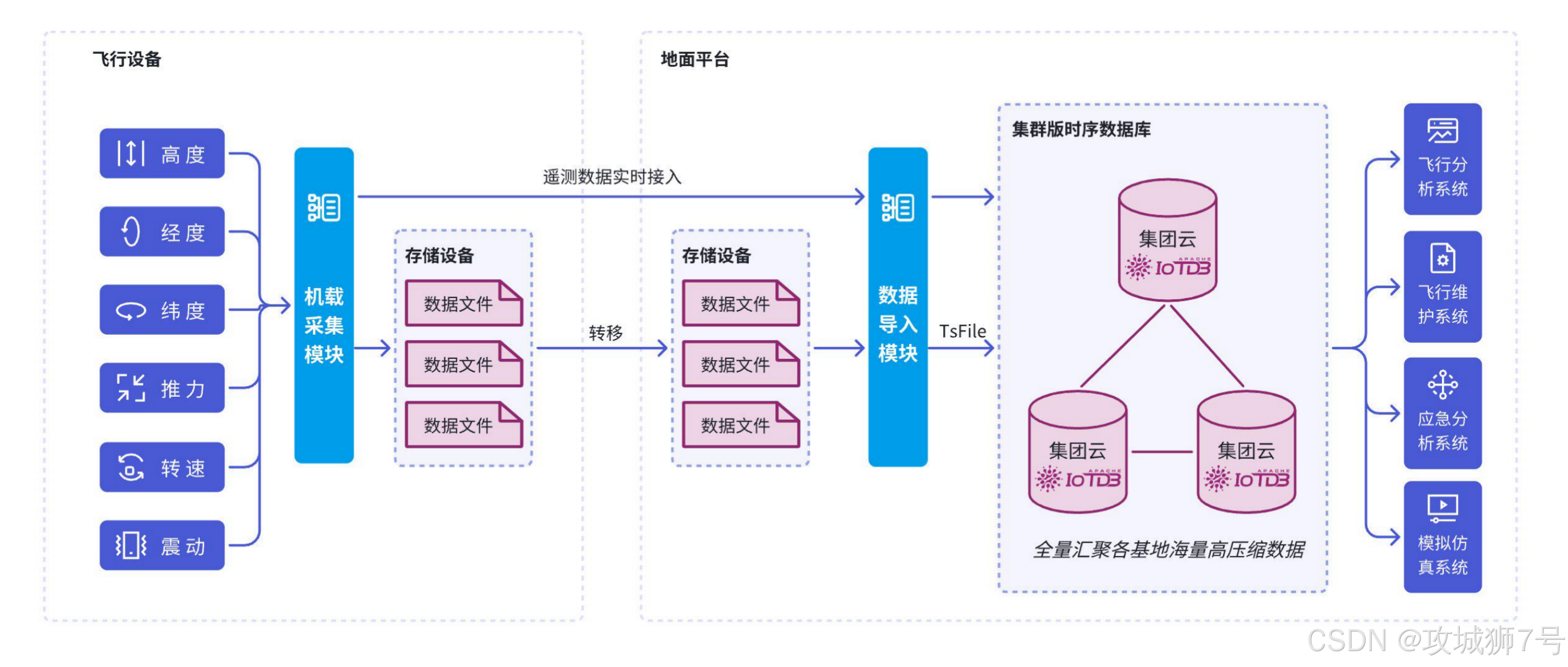
(2)航空航天:精密监测与全生命周期管理
伴随着航空航天工业的数字化步伐,先进的数据采集与处理已成为保障飞行安全的核心。从飞机、火箭到卫星,设计、制造、试飞到运行的全流程会产生庞大复杂的数据。IoTDB 凭借低资源占用、离线数据高速迁移以及极具特色的低流量同步技术,使得遥测数据能够实时回传,试飞数据快速导入分析,确保飞行任务中关键系统的精准监测。
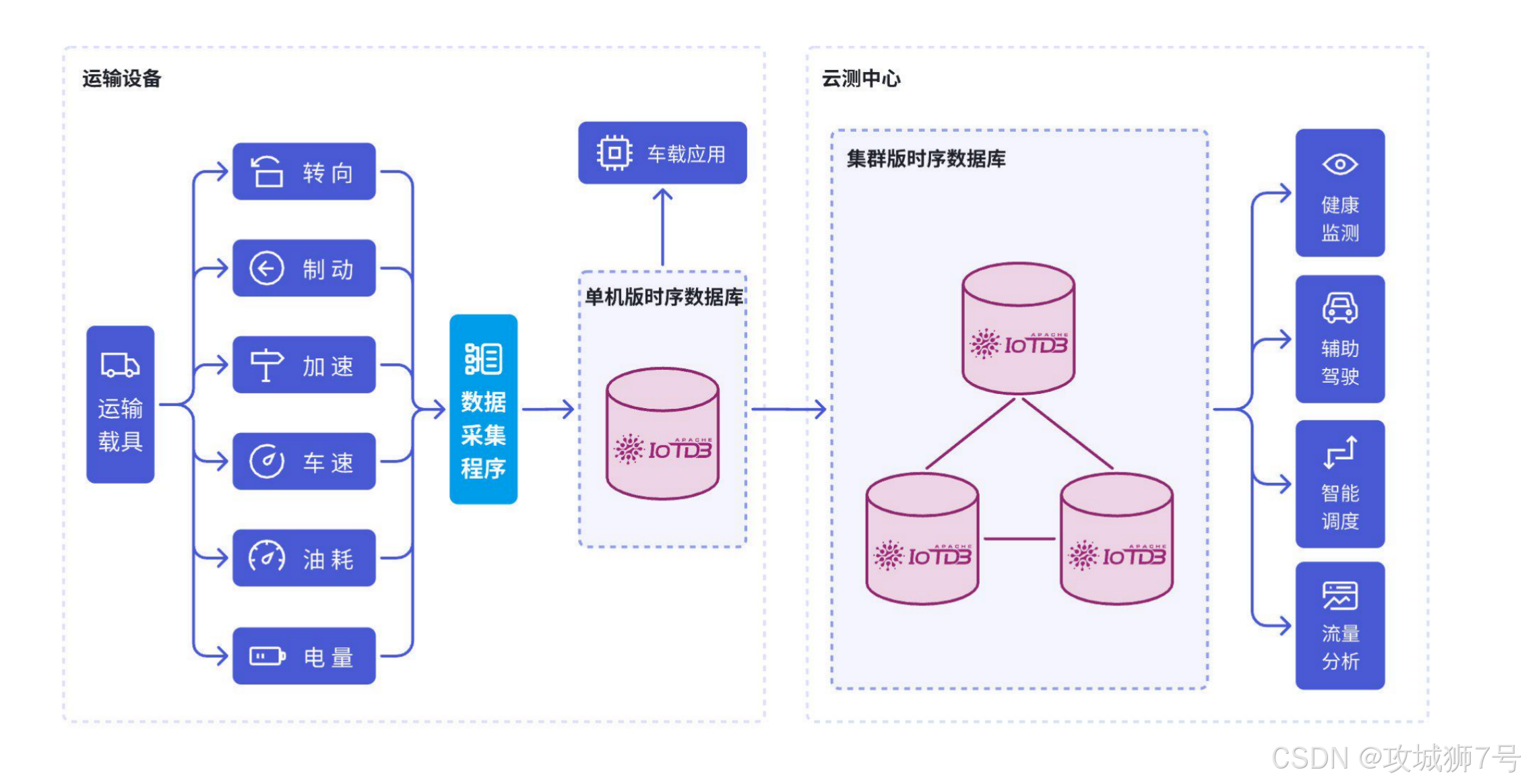
(3)交通运输:支撑智能交通网络的高效运转
在铁路、地铁、船舶和汽车等交通运输网络中,对运行状态和位置等数据的实时性、可靠性有着极致要求。企业需要通过这些数据实现智能调度、线路优化、故障预警和车辆运维。面对交通行业爆发式增长的数据流,IoTDB 的低延迟查询和多源异构数据管理能力大放异彩,为整个交通系统构建起稳定可靠的基础,降低了运营成本。
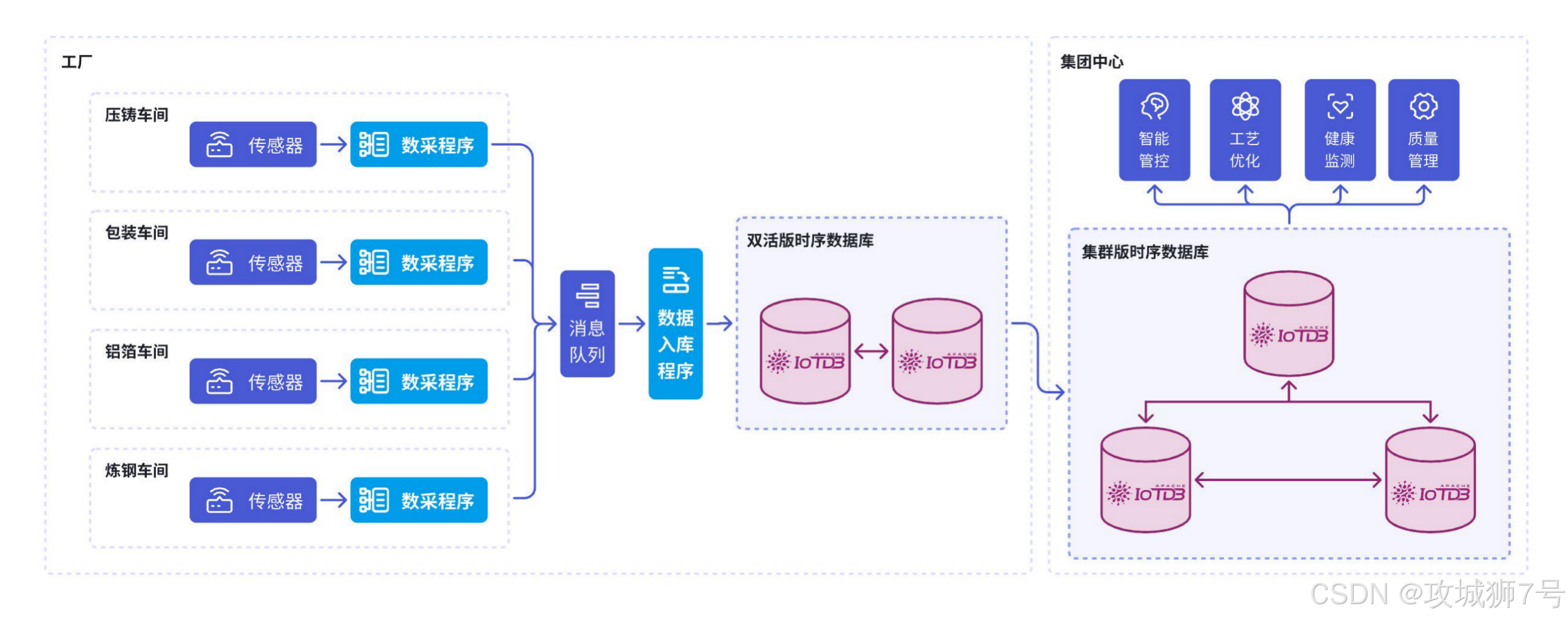
(4)钢铁冶炼:助力传统制造的智慧蜕变
钢铁冶炼作为制造业的代表,正处于智能化改造的关键期。通过工业物联网平台对生产线进行智能监测与控制,是提升产能、降低能耗的必由之路。IoTDB 强大的数据存储与计算能力,为钢铁场景提供了灵活且低资源占用的部署方案。其丰富的外部接口使得与其他生产系统的集成变得非常便捷,成为钢铁企业构建智慧工厂的得力助手。
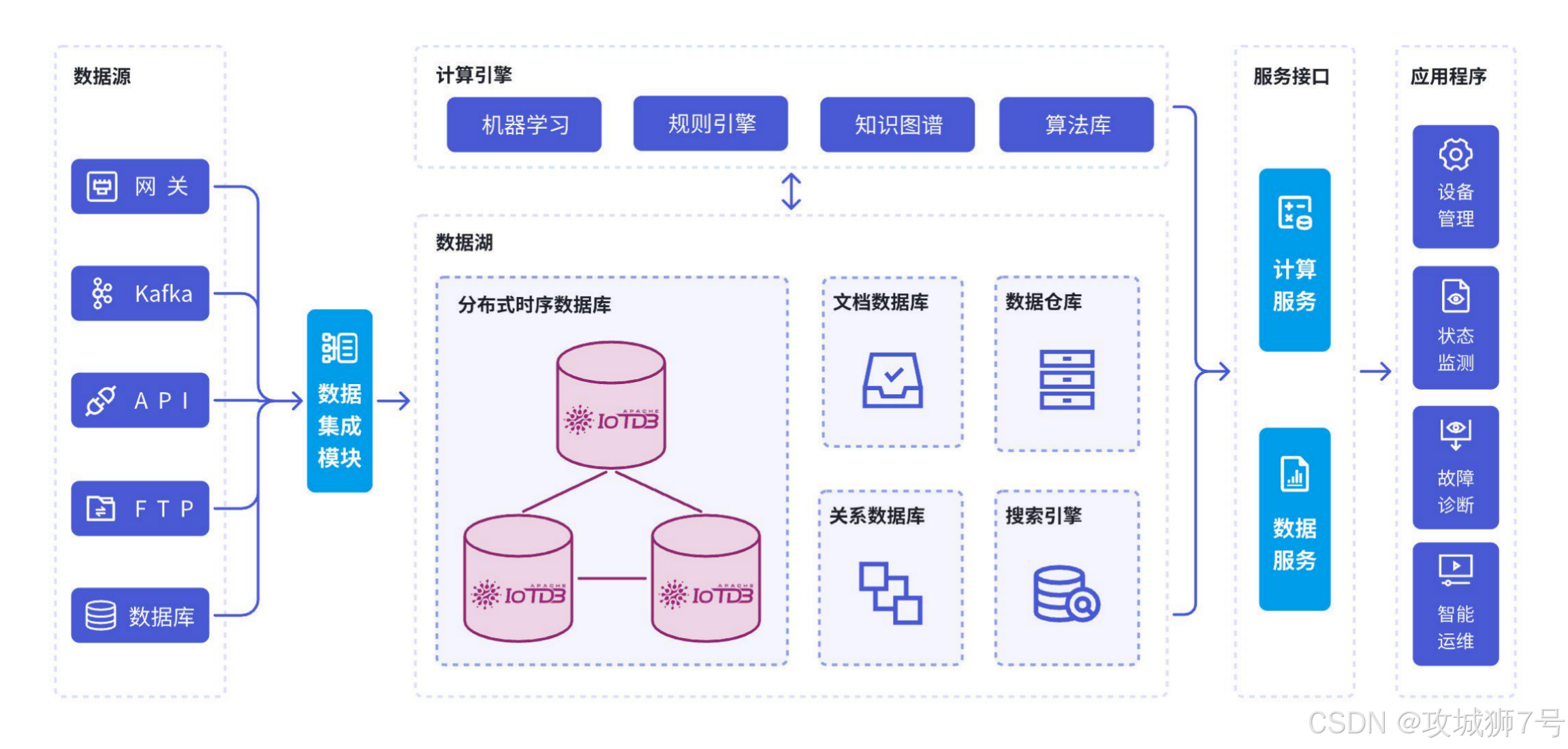
(5)智能物联网:边缘到云端的全链路管理
随着物联网应用拓展,企业迫切需要能够统筹边缘网关到云端数据中心的全链路解决方案。作为纯正的物联网原生数据库,IoTDB 拥有强悍的高并发处理能力,能够轻松满足大规模海量设备的接入需求。它全链路的数据同步和分析机制,不仅保证了系统的实时性,更有效支持了设备状态监测、故障诊断及预测性维护等核心业务,助力企业释放设备数据的商业价值。
五、 商业支持与资源获取
对于许多在业务上有着更为苛刻的稳定性要求、追求更高级别服务保障的企业客户而言,一套完善的商业化产品和原厂级技术支持是不可或缺的。
在开源 Apache IoTDB 的基础之上,天谋科技(Timecho)倾力打造了原厂商业化产品 TimechoDB。这款企业级产品专为解决复杂的物联网大数据管理难题而生。无论是应对极端的数据体量与极高频采样,还是处理大量的乱序数据,亦或是满足繁杂的分析需求并严格控制存储成本,TimechoDB 都能提供稳定高效的解决之道。
天谋科技基于 TimechoDB,不仅为用户提供了更多样化的专属功能、更强悍的性能表现与稳定性,还配备了极其丰富的效能提升工具。专业的技术团队提供全方位的闭环服务,确保商业客户在系统的开发、部署调优及日常运维的每一个环节,都能获得优质体验与可靠保障。
获取资源与了解更多:
* Apache IoTDB 开源安装包下载链接:https://iotdb.apache.org/zh/Download/
* 天谋科技(Timecho)企业版官网:https://www.timecho.com/
结语
在工业物联网的发展进程中,时序数据的存储与分析能力直接决定了底层数据架构的健壮性,也深刻影响着上层业务创新的速度与边界。Apache IoTDB 通过深度贴合物联网场景的产品设计,从海量数据的极速写入、高压缩率的低成本存储,到树状层级的精细管理与一体化的智能分析,将复杂的技术挑战化繁为简。
它打破了传统数据架构在处理时序数据时的种种瓶颈,为千行百业的数字化转型注入了坚实的数据动力。无论企业是正在着手构建崭新的物联网大数据平台,还是寻求对现有数据系统的重构与升级,Apache IoTDB 无疑都是一个极具战略价值的数据底座选择。通过拥抱先进的物联网原生时序数据库,企业必将在未来的智能化竞争中,更加敏捷、高效地释放出海量数据的全部潜能。