目录
[1. 阻塞 I/O](#1. 阻塞 I/O)
[2. 非阻塞 I/O](#2. 非阻塞 I/O)
[3. 信号驱动 I/O](#3. 信号驱动 I/O)
[4. I/O 多路转接/复用](#4. I/O 多路转接/复用)
[5. 异步 I/O](#5. 异步 I/O)
[6. 同步通信 vs 异步通信(⭐⭐⭐)](#6. 同步通信 vs 异步通信(⭐⭐⭐))
[6.1 同步通信](#6.1 同步通信)
[6.2 异步通信](#6.2 异步通信)
[1. select函数参数](#1. select函数参数)
[1.1 FD 集合参数 (readfds, writefds, exceptfds)](#1.1 FD 集合参数 (readfds, writefds, exceptfds))
[1.2 超时参数 (timeout)](#1.2 超时参数 (timeout))
[1.3 fd_set 结构体](#1.3 fd_set 结构体)
[1.4 timeval 结构体](#1.4 timeval 结构体)
[2. select的就绪条件](#2. select的就绪条件)
[2.1 读就绪](#2.1 读就绪)
[2.2 写就绪](#2.2 写就绪)
[2.3 异常就绪](#2.3 异常就绪)
[3. select服务器的简单建立(⭐⭐⭐)](#3. select服务器的简单建立(⭐⭐⭐))
[3.1 引入 fd_array的必要性](#3.1 引入 fd_array的必要性)
[3.2 SelectServer 核心运作流程](#3.2 SelectServer 核心运作流程)
[3.2.1 初始化花名册与监听套接字](#3.2.1 初始化花名册与监听套接字)
[3.2.2 重置位图与寻找最大 FD(第一次遍历)](#3.2.2 重置位图与寻找最大 FD(第一次遍历))
[3.2.3 陷入阻塞,等待内核通知](#3.2.3 陷入阻塞,等待内核通知)
[3.2.4 事件分发与处理(第二次遍历)](#3.2.4 事件分发与处理(第二次遍历))
[4.1 优点](#4.1 优点)
[4.2 缺点](#4.2 缺点)
[4.2.1 连接数存在硬性上限](#4.2.1 连接数存在硬性上限)
[4.2.2 繁琐的"参数重置"开销](#4.2.2 繁琐的“参数重置”开销)
[4.2.3 高昂的"用户态 ⇌ 内核态"内存拷贝成本](#4.2.3 高昂的“用户态 ⇌ 内核态”内存拷贝成本)
[4.2.4 盲目的 O(N) 线性遍历(最大的性能瓶颈)](#4.2.4 盲目的 O(N) 线性遍历(最大的性能瓶颈))
[1. poll函数参数](#1. poll函数参数)
[2. struct pollfd](#2. struct pollfd)
[3. 核心事件宏 (Events)](#3. 核心事件宏 (Events))
[4. poll 的运转逻辑(对比 select)](#4. poll 的运转逻辑(对比 select))
[4.1 初始化阶段:结构体数组](#4.1 初始化阶段:结构体数组)
[4.2 等待阶段:告别重置](#4.2 等待阶段:告别重置)
[4.3 事件分发阶段:位运算](#4.3 事件分发阶段:位运算)
[4.4 连接的动态增删](#4.4 连接的动态增删)
[5. poll 的优缺点](#5. poll 的优缺点)
[5.1 优点](#5.1 优点)
[5.2 缺点](#5.2 缺点)
[1. epoll 的三大核心接口](#1. epoll 的三大核心接口)
[1.1 epoll_create](#1.1 epoll_create)
[1.2 epoll_ctl](#1.2 epoll_ctl)
[1.3 epoll_wait](#1.3 epoll_wait)
[2. 数据结构](#2. 数据结构)
[2.1 struct epitem 结构体](#2.1 struct epitem 结构体)
[2.1.1 rbn 的作用:O(log N) 的增删改查](#2.1.1 rbn 的作用:O(log N) 的增删改查)
[2.1.2 rdllink 的作用:O(1) 的就绪转移](#2.1.2 rdllink 的作用:O(1) 的就绪转移)
[2.1.3 event 的作用:原封不动的物归原主](#2.1.3 event 的作用:原封不动的物归原主)
[2.2 epoll_event 结构体](#2.2 epoll_event 结构体)
[2.2.1 events:事件掩码(情报类型)](#2.2.1 events:事件掩码(情报类型))
[2.2.2 data:联合体](#2.2.2 data:联合体)
[3. 工作原理(⭐⭐⭐)](#3. 工作原理(⭐⭐⭐))
[3.1 epoll_create 的内核布局](#3.1 epoll_create 的内核布局)
[3.2 epoll_ctl 的暗箱操作](#3.2 epoll_ctl 的暗箱操作)
[3.3 epoll_wait 的守株待兔](#3.3 epoll_wait 的守株待兔)
[3.4 网卡发力与回调爆发](#3.4 网卡发力与回调爆发)
[3.5 唤醒收割](#3.5 唤醒收割)
[4. epoll简单使用](#4. epoll简单使用)
[1. 核心触发机制](#1. 核心触发机制)
[2. 对Socket 属性的硬性要求](#2. 对Socket 属性的硬性要求)
[3. 代码编写范式的区别](#3. 代码编写范式的区别)
[4. 性能与系统调用的较量](#4. 性能与系统调用的较量)
一、五个模型
我们必须先牢记一个核心前提。一次完整的网络 I/O 读取操作(如 recv 或 read),在底层其实分为两个完全不同的阶段:
阶段一:等待数据准备就绪(等网卡收到报文,并由内核放入接收缓冲区)。
阶段二:将数据从内核拷贝到用户态 (把内核缓冲区的数据,强行搬运到你代码里的
char buffer[]中)。
1. 阻塞 I/O
这是最原始、最简单的模型,也是所有套接字的默认状态。
运转逻辑: 进程调用
recv,如果缓冲区没数据,进程就一直死等(休眠)。等数据来了(阶段一完成),进程醒来,内核开始把数据拷贝到用户态(阶段二),拷贝完后recv才返回。特点: 两个阶段全程阻塞。对 CPU 非常不友好,只能处理单并发。
2. 非阻塞 I/O
运转逻辑: 你把套接字设置为非阻塞(
O_NONBLOCK)。调用recv时,如果没数据,内核不让你休眠,而是立刻返回一个错误码(EAGAIN/EWOULDBLOCK)。你只能写个while循环不断去问。当终于问到数据准备好了,在执行阶段二(拷贝数据)时,进程依然是阻塞的。特点: 阶段一不阻塞,阶段二阻塞。不停地轮询会导致 CPU 占用率极高(Busy Wait),极少单独使用。
3. 信号驱动 I/O
运转逻辑: 给套接字注册一个信号处理函数(比如
SIGIO)。然后进程去干别的事,完全不阻塞。当内核发现数据准备好了,会发送一个信号给你。你收到信号后,再调用recv把数据拷贝出来。特点: 阶段一完全不阻塞,靠异步信号通知;阶段二依然是阻塞的。在实际的 TCP 网络编程中极少使用,因为 TCP 产生信号的条件太复杂了,很难区分到底是因为读就绪还是写就绪。
4. I/O 多路转接/复用
运转逻辑: 进程阻塞在
select或epoll_wait上,而不是阻塞在真实的 I/O 系统调用(如recv)上。虽然也是阻塞,但它的好处在于它能同时监视成千上万个套接字 。只要有一个数据好了,它就返回,你再针对那个就绪的套接字调用recv取数据。特点: 两个阶段依然全是阻塞的。但它通过一次阻塞管理了海量连接,是当前高并发服务器(Nginx, Redis)的绝对中流砥柱。
5. 异步 I/O
运转逻辑: 进程调用异步读取接口(如
aio_read),告诉内核:"这里有 1024 字节的空间,如果有数据,你帮我读出来,并且帮我填到这个空间里,全搞定后直接发个通知或执行个回调告诉我。" 进程调用完立刻返回,继续干别的事。内核全自动完成阶段一(等数据)和阶段二(拷贝数据),完事后才通知用户。特点: 阶段一和阶段二全部非阻塞。这是最完美的模型。
6. 同步通信 vs 异步通信(⭐⭐⭐)
6.1 同步通信
转逻辑: 发送方发出请求后,必须停下来原地等待,直到接收方处理完毕并返回结果,发送方才能继续执行下一步。
技术场景:
传统的 HTTP 请求(浏览器转圈圈等服务器返回)。
绝大多数的 RPC(远程过程调用)调用,如 Dubbo、gRPC 的默认模式。
数据库的增删改查(执行 SQL 后等结果返回)。
优点: 逻辑简单直观: 代码是从上往下写的,符合人类的线性思维。
强一致性: 这一步做完才做下一步,绝对不会乱。
致命缺点: 阻塞等待,浪费资源: 如果接收方处理很慢(或者网络卡顿),发送方的线程就会一直被挂起,白白消耗系统资源。
- 级联雪崩: A 调 B,B 调 C。如果 C 挂了,B 会卡死,接着 A 也会卡死,最后整个系统崩溃。
6.2 异步通信
运转逻辑: 发送方发出请求后,立刻返回,继续去干别的事 。接收方收到请求后慢慢处理,处理完之后,再通过状态、通知或回调机制来告诉发送方结果。
技术场景:
各种消息队列 (Message Queue) 架构,如 Kafka、RabbitMQ、RocketMQ。
前端 AJAX 的异步回调、Node.js 的事件驱动机制。
发送短信验证码、后台音视频转码、生成大量报表等极其耗时的任务。
优点
极高的吞吐量: 发送方无需等待,可以疯狂发送请求,极大提升了并发能力。
解耦与削峰: 通过引入消息队列,前端的洪峰流量可以被缓存下来,后端的服务按照自己的节奏慢慢消费,系统极其稳定。
致命缺点:
编程复杂度飙升: 逻辑被割裂了。发送请求的代码和处理结果的代码不在同一个地方(回调地狱)。
最终一致性: 无法立刻知道结果,不适合需要严格实时强一致性的金融级核心交易场景。
二、fcntl实现SetNoBlock
cpp
#include <iostream>
#include <fcntl.h> // fcntl 所在的头文件
#include <unistd.h>
// 将指定的文件描述符设置为非阻塞模式
// 成功返回 true,失败返回 false
bool SetNoBlock(int fd) {
// 第一步:获取该文件描述符当前的所有的状态标志(File Status Flags)
int fl = fcntl(fd, F_GETFL);
if (fl < 0) {
std::cerr << "fcntl F_GETFL failed for fd: " << fd << std::endl;
return false;
}
// 第二步:在原有标志的基础上,按位或(|)加上非阻塞标志 O_NONBLOCK
// 然后将新的标志集合设置回该文件描述符
if (fcntl(fd, F_SETFL, fl | O_NONBLOCK) < 0) {
std::cerr << "fcntl F_SETFL failed for fd: " << fd << std::endl;
return false;
}
return true;
}
先用
F_GETFL拿到当前的属性清单存入变量fl中。利用位运算
fl | O_NONBLOCK,意思是:"保留之前的全部属性,只是在这个基础上追加一个非阻塞的标签",然后再用F_SETFL塞回给内核。
三、多路转接select
1. select函数参数
它的核心作用是让进程监视多个文件描述符(FD),直到其中一个或多个变为"就绪"状态。
cpp
函数原型:int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
- nfds(输入):监视的文件描述符范围。通常设置为所有集合中最大 FD 值加 1。
- readfds(输入/输出 ):监视可读事件的集合(如:缓冲区有数据、连接关闭)。
- writefds(输入/输出 ):监视可写事件的集合(如:发送缓冲区有空间)。
- exceptfds(输入/输出 ):监视异常条件的集合(如:带外数据 OOB)。
- timeout(输入/输出):输入输出型参数,调用时由用户设置select的等待时间,返回时表示timeout的剩余时间。
1.1 FD 集合参数 (readfds, writefds, exceptfds)
-
作为输入: 你通过这些集合告诉内核:"请帮我关注这些文件描述符"。
-
作为输出: 当函数返回时,内核会修改这些集合,只保留那些真正发生了事件的描述符。
注意: 正因为集合会被修改,所以每次在循环中调用
select之前,你必须重新初始化(重新设置)这些集合。
1.2 超时参数 (timeout)
-
作为输入: 告诉内核最长等多久。
-
作为输出: 在某些 Linux 系统上,函数返回时会修改此结构体,反映剩余的等待时间。为了跨平台兼容,建议每次循环都重新给它赋值。
1.3 fd_set 结构体
fd_set 本质上是一个位图(Bitmap),每一位(bit)对应一个文件描述符(FD)。
cpp
typedef struct {
long fds_bits[FD_SETSIZE / (8 * sizeof(long))];
} fd_set;
FD_SETSIZE :这是一个系统定义的宏,通常是 1024 。这意味着
select默认最多只能监视 1024 个文件描述符。位操作 :如果你把文件描述符
5加入集合,fd_set内部数组的第 5 个 bit 就会被置为1。
FD_ZERO(&set):清空所有位(全部设为 0)。
FD_SET(fd, &set):把特定位设为 1(添加监视)。
FD_CLR(fd, &set):把特定位设为 0(取消监视)。
FD_ISSET(fd, &set):检查特定位是否为 1(判断是否就绪)。
1.4 timeval 结构体
struct timeval 用于指定 select 等待的截止时间。
cpp
struct timeval {
long tv_sec; // 秒 (seconds)
long tv_usec; // 微秒 (microseconds)
};通过设置
timeout参数的不同取值,select会表现出截然不同的行为:
永久阻塞 (
timeout = NULL):select会一直等下去,直到至少有一个 FD 就绪或被信号中断。完全非阻塞 (
tv_sec = 0, tv_usec = 0):select立即检查所有 FD 状态并返回,不管有没有就绪的,都不会等待。限时等待 (
tv_sec > 0或tv_usec > 0): 在指定时间内等待。如果在 5 秒内有数据,立即返回;如果 5 秒到了还没数据,返回0。
2. select的就绪条件
"读就绪就是有数据,写就绪就是能发数据",但实际上,"就绪"的真正含义是:此时对该文件描述符(FD)调用对应的 I/O 函数(如 read、write、accept),一定不会被阻塞。 select 告诉你"就绪",只是承诺你去操作不会卡住(阻塞),但不承诺操作一定成功,所以配套的返回值检查是必不可少的。
2.1 读就绪
当一个Socket被标记为"读就绪"并从 select 返回时,意味着它满足以下 四个条件之一:
接收缓冲区有数据: 套接字接收缓冲区中的数据字节数,大于等于接收缓冲区的低水位标记 (SO_RCVLOWAT)。对于 TCP 和 UDP 套接字,默认的读低水位标记通常是 1 字节 。此时调用
read/recv会返回大于 0 的值。对端关闭连接(收到 FIN): 如果客户端正常断开连接(或者调用了
close/shutdown),内核会收到一个 FIN 包。此时套接字处于读就绪状态,调用read/recv不会阻塞,而是立即返回 0。监听套接字有新连接: 对于作为服务器的监听套接字(Listening Socket),如果底层已经完成了 TCP 三次握手,有一个新的连接待处理,它就会被标记为读就绪。此时调用
accept不会阻塞。套接字发生错误: 如果套接字上发生了一个挂起的错误(例如收到了 RST 报文),它也会被标记为读就绪。此时调用
read/recv会立即返回 -1 ,并且系统会设置errno(例如ECONNRESET)。
2.2 写就绪
写就绪通常是最容易忽视的,因为大多数时候 TCP 发送缓冲区都是有空间的。写就绪意味着满足以下 四个条件之一:
发送缓冲区有空间: 套接字发送缓冲区的可用空间字节数,大于等于发送缓冲区的低水位标记 (SO_SNDLOWAT)。对于 TCP 套接字,这个默认值通常是 2048 字节 。这意味着只要你的缓冲区没被塞满,
select就会一直告诉你"可以写"。连接的写半部被关闭: 如果你主动调用
shutdown(fd, SHUT_WR)关闭了写的方向,或者收到了某些致命错误。此时套接字也是"写就绪"的,但如果你真的去调用write,非但写不进去,还会触发SIGPIPE信号(这会导致进程崩溃,除非你忽略了该信号)。非阻塞 connect 完成: 在进行异步网络编程时,如果你对一个设置为非阻塞 的套接字调用
connect,它会立即返回EINPROGRESS。当底层的三次握手成功,或者因为超时/被拒绝而失败时,该套接字会变为写就绪。套接字发生错误: 与读就绪类似,发生挂起错误时,套接字也会变为写就绪。此时调用
write/send会立即返回 -1 ,并设置errno。
避坑指南: 绝不要像监视读事件那样,一开始就把所有 FD 都加入
writefds中。因为绝大多数情况下发送缓冲区都是不满的,这会导致select每次都立即返回(形成 CPU 空转/Busy Loop)。正确做法是:只有当你想发数据,但调用write返回EAGAIN(表示缓冲区满了)时,才将该 FD 加入writefds,等select通知你有空间了,再去继续发。
2.3 异常就绪
在 Linux/Unix 的网络编程中,exceptfds 中的异常绝大多数情况下指的并不是普通的 TCP 错误(如断网、超时)。普通的网络错误都是通过"读/写就绪 + read/write 返回 -1"来体现的。满足异常就绪通常只有以下几种极其罕见的情况:
收到带外数据 (Out-of-Band Data, OOB): 这是 TCP 协议中的一个特殊标志位(URG)。发送方可以发送带有紧急指针的数据。当网络层收到这种"带外数据"时,对应的套接字会在
select中被标记为异常就绪。伪终端控制状态改变: 在某些特定的伪终端(pty)主设备状态发生改变时。这与常规的 Socket 网络编程无关。
对于绝大多数的 Web 服务器和网络应用开发,几乎永远不需要把套接字加入到 exceptfds 参数中,直接传 NULL 或 nullptr 即可。
3. select服务器的简单建立(⭐⭐⭐)
3.1 引入 fd_array的必要性
fd_set 每次循环都会被内核"破坏",就必须在循环之外找一个安全的地方 ,把我们到底想监视哪些 FD 给永久记录下来。这就是引入第三方数组的根本原因。我们可以把 fd_array 形象地比喻为服务器的"客户花名册"。
入会(新连接到来): 调用
accept获取新 FD,找个空位塞进fd_array。退会(客户端断开): 调用
close关闭 FD,并把fd_array对应位置设为无效值(通常是-1)。点名(select 轮询): 每次调用
select前,照着fd_array这个花名册,重新画一遍fd_set签到表。
没有这个花名册,服务器在一轮循环后就会彻底"失忆"。
3.2 SelectServer 核心运作流程
3.2.1 初始化花名册与监听套接字
在服务器启动前,我们需要将 fd_array 全部初始化为无效值 -1。随后,创建服务器的核心------监听套接字 (listensock) ,并将其作为我们的一号 VIP 客户,放入 fd_array[0] 中。
cpp
// 初始化阶段
for (int i = 0; i < fd_num_max; i++) {
fd_array[i] = defaultfd; // 全部设为 -1
}
fd_array[0] = listensock_.Fd(); // 将监听套接字加入花名册3.2.2 重置位图与寻找最大 FD(第一次遍历)
进入死循环。在调用 select 之前,我们必须根据花名册重新生成位图。 同时,select 函数的第一个参数要求传入最大文件描述符的值加 1 (为了内核底层遍历位图时的边界判断)。因此,我们顺便在这次遍历中求出 maxfd。
cpp
fd_set rfds;
FD_ZERO(&rfds); // 绝对不能忘:清空被内核污染的位图
int maxfd = fd_array[0];
for (int i = 0; i < fd_num_max; i++) {
if (fd_array[i] == defaultfd) continue;
FD_SET(fd_array[i], &rfds); // 照着花名册,重新设置位图
if (maxfd < fd_array[i]) {
maxfd = fd_array[i]; // 动态更新 maxfd
}
}3.2.3 陷入阻塞,等待内核通知
万事俱备,调用 select。此时当前线程交出 CPU 执行权,进入休眠,直到我们监视的 FD 中有事件发生(或者超时)。
cpp
// 这里的 timeout 也是输入输出型参数,为了跨平台稳定,每次循环也要重新赋值!
struct timeval timeout = {3, 0};
int n = select(maxfd + 1, &rfds, nullptr, nullptr, &timeout);3.2.4 事件分发与处理(第二次遍历)
当 select 返回大于 0 的值时,说明有事件发生了。此时的 rfds 已经被内核修改,里面位值为 1 的就是"就绪"的套接字。 再次遍历花名册,拿着每个 FD 去测试 rfds!
cpp
for (int i = 0; i < fd_num_max; i++) {
int fd = fd_array[i];
if (fd == defaultfd) continue;
// 使用 FD_ISSET 检查内核是否保留了该 FD 的标记
if (FD_ISSET(fd, &rfds)) {
if (fd == listensock_.Fd()) {
// 情况 A:监听套接字就绪,说明有新客户端连接!
Accepter();
} else {
// 情况 B:普通套接字就绪,说明客户端发数据来了,或者退出了!
Recver(fd, i);
}
}
}
Accepter(增加监视): 当获取到新的sock时,遍历fd_array找到一个值为-1的位置填进去。这就意味着,在下一次大循环开始时,这个新的套接字就会被FD_SET自动加进位图中!
Recver(取消监视): 当read返回 0(对端关闭)或发生错误时,调用close(fd),同时执行fd_array[i] = -1。这就意味着,该客户端从花名册中被除名,下一次循环不再被监视。
4.select的优缺点
4.1 优点
极致的跨平台通用性
select几乎被所有的主流操作系统所支持,包括所有的 Unix/Linux 分支、macOS,甚至 Windows(Winsock 提供了高度兼容的select实现)。如果你需要写一个在任何平台上都能直接编译运行的网络模块,select通常是唯一的保底选择。微秒级的超时精度
select的timeout参数使用的是struct timeval,理论上可以支持微秒(us)级别的精细控制(尽管实际精度受限于系统时钟)。相比之下,后来的poll函数只支持毫秒(ms)级。概念相对简单明了 对于处理少量固定连接(比如十几个、几十个以内的终端或本地进程间通信),
select的位图机制和逻辑非常直接,不需要像epoll那样维护复杂的红黑树和事件队列。
4.2 缺点
在面对现代互联网动辄"C10K"(单机万级并发)的挑战时,select 暴露出以下四个致命缺陷:
4.2.1 连接数存在硬性上限
原理 :
select使用fd_set位图来保存文件描述符。在大多数 Linux 系统中,FD_SETSIZE宏被硬编码为 1024。痛点:这意味着一个进程默认最多只能监视 1024 个文件描述符(还要扣除标准输入、输出、错误等)。要想突破这个限制,必须修改内核头文件并重新编译系统内核,这在生产环境中是极其不现实的。
4.2.2 繁琐的"参数重置"开销
原理 :正如在博客中反复强调的,
fd_set是输入输出型参数。痛点 :每次调用
select之前,开发者都必须手动清空位图,并遍历自己的fd_array把感兴趣的 FD 重新"画"回位图中。这不仅让代码变得繁琐,也增加了 CPU 的无谓开销。
4.2.3 高昂的"用户态 ⇌ 内核态"内存拷贝成本
原理 :每次调用
select,都需要将完整的fd_set集合从用户态拷贝到内核态;当select返回时,内核又需要将修改后的fd_set集合从内核态拷贝回用户态。痛点:即使这 1024 个连接中只有一个连接发来了数据,这来回两次的完整位图拷贝也是不可避免的。并发量越大,拷贝开销越恐怖。
4.2.4 盲目的 O(N) 线性遍历(最大的性能瓶颈)
内核底层的遍历 :内核在拿到位图后,不知道到底哪个 FD 有事件,只能从 0 一直遍历到
maxfd去挨个检查底层硬件状态。用户代码的遍历 :
select返回后,只告诉你"有 n 个事件就绪了",但不告诉你是哪几个。开发者必须再次写一个for循环,遍历整个fd_array,用FD_ISSET挨个去试探。痛点 :假设你有 1000 个活跃连接,但某一个瞬间只有 1 个客户端发了消息。为了找出这 1 个连接,内核和你的代码都要各自空转循环 1000 次。这种 O(N) 的复杂度导致
select的性能随着连接数的增加呈断崖式下跌。
四、多路转接poll
1. poll函数参数
它的核心作用是让进程监视多个文件描述符(FD),直到其中一个或多个变为"就绪"状态。
cpp
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
- fds:这是一个数组的首地址 。你可以根据需要
new或malloc任意大小的数组。- nfds:告诉内核,这个数组里当前有效 的元素有多少个(不需要像
select那样算maxfd + 1了)。- timeout:超时时间,单位是毫秒 (ms)。
-1:永久阻塞等待;0:非阻塞,查完立刻返回;>0:限时等待。
2. struct pollfd
cpp
struct pollfd {
int fd; // 你要监视的文件描述符
short events; // 你希望内核监视的事件(输入型参数)
short revents; // 内核实际返回的就绪事件(输出型参数)
};在 select 中,我们提过最大的痛点是 fd_set 作为输入输出型参数,每次调用都会被内核"破坏",导致必须引入第三方数组 fd_array 并每次重新循环赋值。 而 pollfd 巧妙地将"提问(events)"和"回答(revents)"分开了!
每次调用
poll时,内核只读取events,不管revents。当
poll返回时,内核把结果写在revents里,绝对不会去动你的events。结论:你再也不需要在
while循环里每次重新设置关心的事件了!
3. 核心事件宏 (Events)
events 和 revents 的值是通过位掩码(按位或 |)来组合的。最常用的事件有:
POLLIN:读就绪(有数据可读、或者有新连接请求accept)。相当于select的readfds。
POLLOUT:写就绪(发送缓冲区有空间)。相当于select的writefds。
POLLERR:发生错误(仅用于revents输出)。
POLLHUP:对端挂断(如对端关闭连接,仅用于revents输出)。
cpp
if (fds[i].revents & POLLIN) {
// 读事件发生了!
}4. poll 的运转逻辑(对比 select)
4.1 初始化阶段:结构体数组
cpp
_event_fds[0].fd = listensock;
_event_fds[0].events = POLLIN; // 告诉内核:盯着它的读事件!
select的痛点 :因为fd_set会被内核破坏,必须额外维护一个int fd_array[]来记住历史连接。
poll的解法 :在PoolServer构造函数和Start中,直接使用了结构体数组struct pollfd _event_fds[fd_num_max]。
这个结构体把"要监视的 FD (
fd)"、"关心的事件 (events)"和"内核返回的事件 (revents)"全部绑定在了一起。初始化时,只需将
_event_fds[0]设为监听套接字,并贴上POLLIN(读就绪)的标签。
4.2 等待阶段:告别重置
select的痛点 :每次while(true)循环开头,都要写一个for循环去FD_ZERO清空位图,然后再用FD_SET重新把数组里的 FD 挂载一遍,最后还要苦哈哈地计算maxfd。
poll的解法 :现在繁琐的准备工作**全部消失了。**直接一行代码调内核。
cpp
for (;;) {
// 不需要清空集合,不需要重新挂载,不需要算 maxfd!
int n = poll(_event_fds, fd_num_max, timeout);
// ... switch 处理返回值
}4.3 事件分发阶段:位运算
select的痛点 :必须遍历fd_array,然后用FD_ISSET(fd, &rfds)去宏里查状态。
poll的解法 :在你的Dispatcher()中,直接遍历_event_fds数组,通过位运算&来检查revents是否被内核打上了特定标记。
cpp
for (int i = 0; i < fd_num_max; i++) {
int fd = _event_fds[i].fd;
if (fd == defaultfd) continue;
// 直接按位与判断,POLLIN 表示读事件就绪
if (_event_fds[i].revents & POLLIN) {
// 处理新连接或新数据...
}
}4.4 连接的动态增删
新增连接 (
Accepter) :当新客户端连入时,你遍历寻找fd == -1的空位。只需把新sock放进去,并必须配上events = POLLIN,下一次poll就会自动监视它。
cpp
_event_fds[pos].fd = sock;
_event_fds[pos].events = POLLIN; // 【修复】一定要告诉内核,我们需要监视它的读事件!
PrintFd();5. poll 的优缺点
5.1 优点
突破 1024 限制:
poll使用的是动态数组,连接数上限取决于系统能打开的文件描述符总数(通常可以配置到 10万 甚至更高),不再有 1024 的硬性编译限制。告别参数重置噩梦: 读写事件分离(
events和revents),代码结构更清晰,不需要每次调用前重置状态。告别
maxfd + 1: 只需要告诉内核当前数组用了多少个位置即可,不用再维护最大的 FD 值。
5.2 缺点
poll 治标不治本,它仅仅优化了开发者的"接口体验",但底层的性能瓶颈一点都没解决。
依然是 O(N) 的线性轮询: 内核拿到你的
pollfd数组后,依然要从头到尾挨个检查底层硬件状态;poll返回后,你依然要写个for循环从头到尾挨个判断revents。并发连接数一多(比如 5 万个连接),即使只有 1 个活跃,依然要空转循环 5 万次。依然有巨大的内存拷贝开销: 每次调用
poll,整个pollfd数组都要在用户态和内核态之间来回拷贝一遍,数组越大,拷贝越慢。
五、多路转接epoll (⭐⭐⭐)
理解 epoll,我们先从一个比喻开始:
select/poll的工作方式(大妈扫楼): 宿管大妈(内核)拿着 10 万个宿舍的名单,为了找出哪个宿舍漏水了,她必须从 1 楼爬到 100 楼,挨个敲门问(O(N) 遍历)。
epoll的工作方式(智能报修): 宿管大妈在一楼大厅喝茶。哪个宿舍漏水了,那个宿舍的智能水表就会自动给大妈发个微信(基于硬件中断的回调机制)。大妈手机上收到几条微信,就直接去处理那几个宿舍,完全不用爬楼(O(1) 获取就绪事件)。
1. epoll 的三大核心接口
1.1 epoll_create
cpp
int epoll_create(int size);
作用: 在内核中创建一个
epoll实例(大本营)。底层原理: 内核会为你创建一颗红黑树(Red-Black Tree) (用来高效存储和查找你要监视的 FD)和一个双向链表组成的就绪队列(Ready List)(用来存放已经发生事件的 FD)。
返回值: 返回一个专门指向这个
epoll实例的文件描述符(epfd)。这意味着,epoll 本身也是一个文件。
1.2 epoll_ctl
cpp
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
作用: 向
epoll的红黑树 中添加、修改或删除你要监视的套接字。参数解析:
epfd:刚才epoll_create返回的句柄。
op:EPOLL_CTL_ADD(新增)、EPOLL_CTL_MOD(修改)、EPOLL_CTL_DEL(删除)。
fd:你要监视的具体网络套接字(比如listensock)。
event:你要监视它的什么事件(如EPOLLIN读、EPOLLOUT写)。核心: 在
select/poll中,我们每次循环都要把整个数组传给内核(巨大的内存拷贝)。而在epoll中,一个套接字只需在刚连接时调用一次EPOLL_CTL_ADD添加进内核即可,之后内核会一直记着它,彻底消灭了毫无意义的重复拷贝!
1.3 epoll_wait
cpp
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);
作用: 阻塞等待事件发生。这是放在
while(true)死循环里的唯一函数。参数解析:
events:这是一个纯输出型参数(用户态分配的一个空数组)。
maxevents:这个数组有多大。核心: 内核如果发现就绪队列里有东西,就会把就绪的事件按顺序 填入你的
events数组中,并返回就绪的总个数n。颠覆性的改变: 此时你的代码只需要遍历
0到n-1即可。**返回的数组里,每一个绝对都是有真实事件发生的,绝没有滥竽充数的空位!,**彻底消灭了 O(N) 的空转遍历。
2. 数据结构
2.1 struct epitem 结构体
如果说 struct eventpoll 是 epoll 的"大本营",那么 struct epitem 就是大本营里为每一个 Socket 建立的"专属档案袋" 。每次调用 epoll_ctl(..., EPOLL_CTL_ADD, ...) 时,内核本质上就是 kmalloc 申请了一块内存,创建了一个 epitem 结构体,并把它挂到了红黑树上。
cpp
struct epitem {
// 1. 红黑树节点:靠它挂在 eventpoll 的红黑树上
struct rb_node rbn;
// 2. 双向链表节点:当事件发生时,靠它链接进 eventpoll 的就绪链表 (rdllist)
struct list_head rdllink;
// 3. 指向所属的 epoll 大本营
struct eventpoll *ep;
// 4. 封装了被监视的 FD 和底层 file 结构体指针
struct epoll_filefd ffd;
// 5. 等待队列里的回调钩子(极其关键)
struct eppoll_entry *pwqlist;
// 6. 保存用户关心什么事件 (EPOLLIN/EPOLLOUT等),以及绑定的用户数据 (data.fd)
struct epoll_event event;
};2.1.1 rbn 的作用:O(log N) 的增删改查
当调用
epoll_ctl(EPOLL_CTL_MOD)想修改某个 FD 的事件,或者EPOLL_CTL_DEL想删除某个 FD 时,内核通过epitem里的rbn快速找到它。内核顺着eventpoll的红黑树根节点向下比较,以 O(log N) 的极快速度就能精准揪出这个epitem。
2.1.2 rdllink 的作用:O(1) 的就绪转移
当网卡数据到来,触发了
ep_poll_callback回调函数时,回调函数手里拿到的就是这个特定 Socket 的epitem指针。回调函数不需要去动红黑树,它只需要极其简单地执行一步链表操作:把当前
epitem里的rdllink这个节点,通过指针操作插入到eventpoll的rdllist(就绪链表)的尾部!
2.1.3 event 的作用:原封不动的物归原主
当
epoll_wait被唤醒,准备向用户态拷贝数据时,它就是遍历rdllist链表上的这些epitem。拷贝就是把epitem->event里的内容(你当初传给内核的关心的事件和data.fd),原封不动地copy_to_user拷贝回你代码里的events数组中。
2.2 epoll_event 结构体
struct epoll_event 是用户态和内核态之间传递情报的"专属信封" 。在 epoll 的编程模型中,这个结构体的出场率是 100%。无论是你告诉内核"我要监视谁"(通过 epoll_ctl),还是内核告诉你"谁就绪了"(通过 epoll_wait),用的都是这个结构体。
cpp
struct epoll_event {
uint32_t events; // 你关心的 epoll 事件(如 EPOLLIN, EPOLLOUT, EPOLLET)
epoll_data_t data; // 用户数据(极其核心!内核不管里面是什么,原样返回)
} __attribute__ ((__packed__)); // 保证在不同平台上的内存对齐
// data 是一个联合体(Union)
typedef union epoll_data {
void *ptr; // 指针(高阶用法,指向你的自定义对象)
int fd; // 文件描述符(最基础、最常用的用法)
uint32_t u32; // 32位整数
uint64_t u64; // 64位整数
} epoll_data_t;2.2.1 events:事件掩码(情报类型)
这是一个 32 位的无符号整数,通过按位或(|)来组合你要监视的事件。最常用的有:
EPOLLIN:表示对应的文件描述符可以读(包括对端 SOCKET 正常关闭)。
EPOLLOUT:表示对应的文件描述符可以写。
EPOLLET:(极其重要) 将 epoll 的工作模式设置为边缘触发(Edge Triggered)。默认是水平触发(LT)。
EPOLLERR/EPOLLHUP:发生错误或挂断(内核会自动为你监视这些,通常不需要你在epoll_ctl时显式添加)。
2.2.2 data:联合体
这是
epoll设计中最灵活的地方!内核对data里面的内容完全不关心,也不做任何解析 。它只负责一件事:你用epoll_ctl传进来什么,它在epoll_wait返回时就原封不动地还给你。
3. 工作原理(⭐⭐⭐)
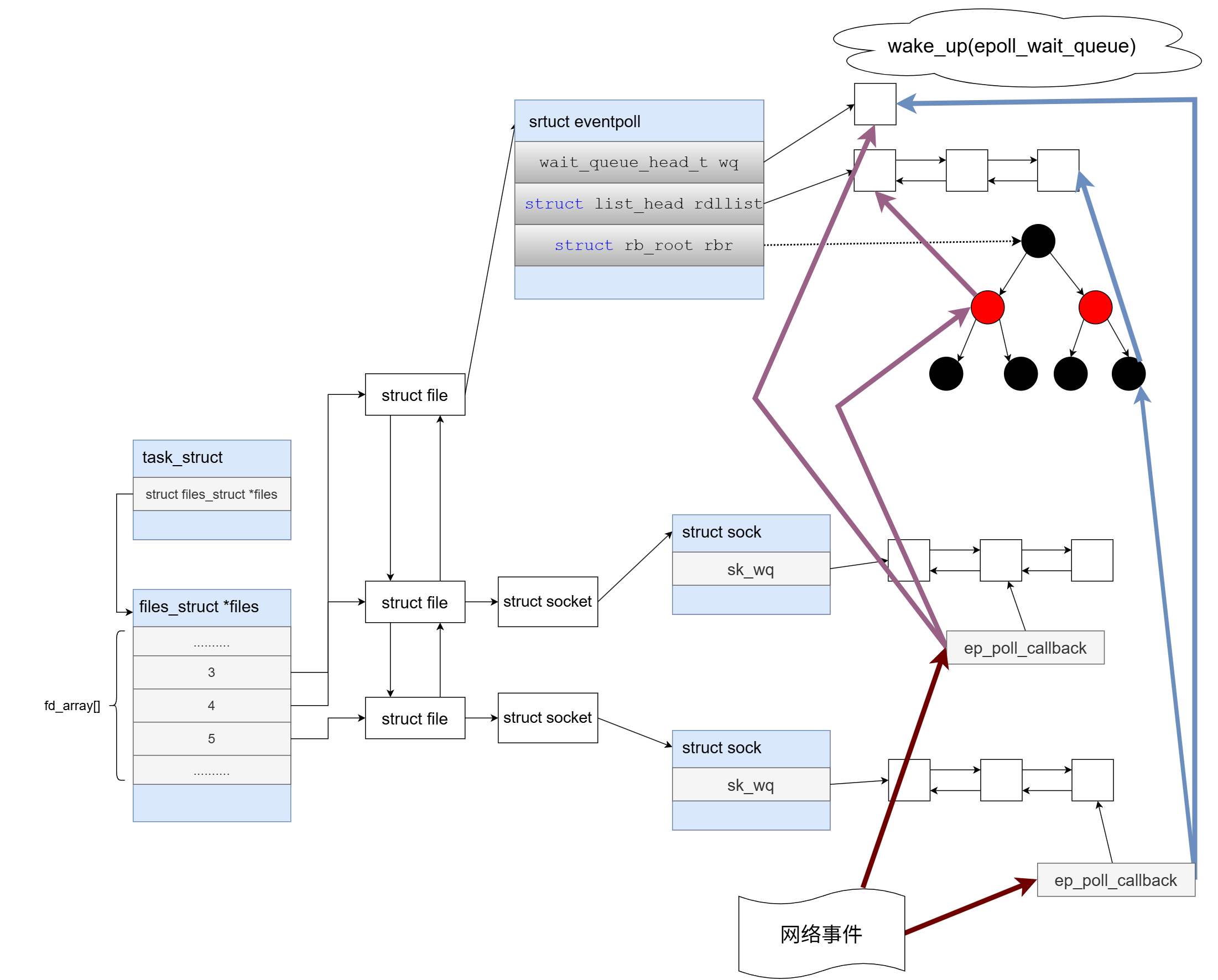
3.1 epoll_create 的内核布局
当我们在用户态调用 epoll_create 时,内核(如图中上方所示)会创建一个核心结构体 struct eventpoll。你可以把它看作是 epoll 的"大本营"。它包含三个至关重要的组件:
rbr(红黑树根节点, rb_root): 用来高效管理所有被监视的 socket 节点。保证增删改查的时间复杂度都是 O(log )。
rdllist(就绪双向链表, list_head): 一个纯粹的就绪队列。这里面只存放真正发生了事件的 socket。
wq(等待队列, wait_queue_head_t): 当没有事件发生时,调用epoll_wait的进程就会在这个队列上挂起休眠。
注意:
epoll实例本身也是一个文件,所以图中左侧的fd_array中,有一个专属的位置(比如 FD 3)是指向这个eventpoll对象的。
3.2 epoll_ctl 的暗箱操作
当我们调用 epoll_ctl(EPOLL_CTL_ADD) 将一个新的 Socket (比如 FD 4) 添加到 epoll 中时,内核会做两件极其关键的事:
上树: 将这个 Socket 包装成一个节点,挂载到大本营的 红黑树 (
rbr) 上。注册回调函数: 这是 epoll 碾压 select 的终极奥义!内核会在这个特定 Socket 的等待队列(图中的
sk_wq)上,悄悄注册一个回调函数 ------ep_poll_callback。这就像是给这个 Socket 绑定了一个触发器,只要网卡一收到属于它的数据,这个触发器就会立刻爆炸!
3.3 epoll_wait 的守株待兔
用户态代码执行到 while(true) 循环里的 epoll_wait 时: 内核会直接去检查大本营里的 就绪链表 (rdllist)。
如果链表里有节点,直接拿走返回。
如果链表是空的(大部分情况),当前进程就会交出 CPU 控制权,挂载到大本营的 等待队列 (
wq) 上陷入休眠,静静等待被唤醒。
3.4 网卡发力与回调爆发
如图中右下角所示,真正的关键在这个瞬间发生:
网络事件到达: 数据包通过网线到达网卡,网卡通过硬件中断通知 CPU。
数据入列: 内核将数据解析后,放入对应 Socket 的接收缓冲区中。
触发回调: Socket 的状态发生变化(变成读就绪),内核顺藤摸瓜找到之前"埋好的雷",直接触发了
ep_poll_callback回调函数!移入就绪队列(核心动作): 这个回调函数非常干脆,它顺着指针找到红黑树上的对应节点,一把将它拽下来,直接插入到就绪链表 (
rdllist) 中!
3.5 唤醒收割
当 ep_poll_callback 把节点塞进就绪链表后,它立刻执行最后一步(图中最上方的蓝线箭头):调用 wake_up() 唤醒等待队列 (wq) 上休眠的进程 。进程醒来后,发现原本空空如也的 rdllist 里已经有东西了。
内核不再需要像
select那样去遍历整棵红黑树,而是直接把rdllist里的节点按顺序拷贝到用户态传入的events数组中。有几个节点,就拷贝几个,最后返回就绪的总数
n。时间复杂度:真正的 O(1) 获取! 没有一次空转,没有一点性能浪费。
4. epoll简单使用
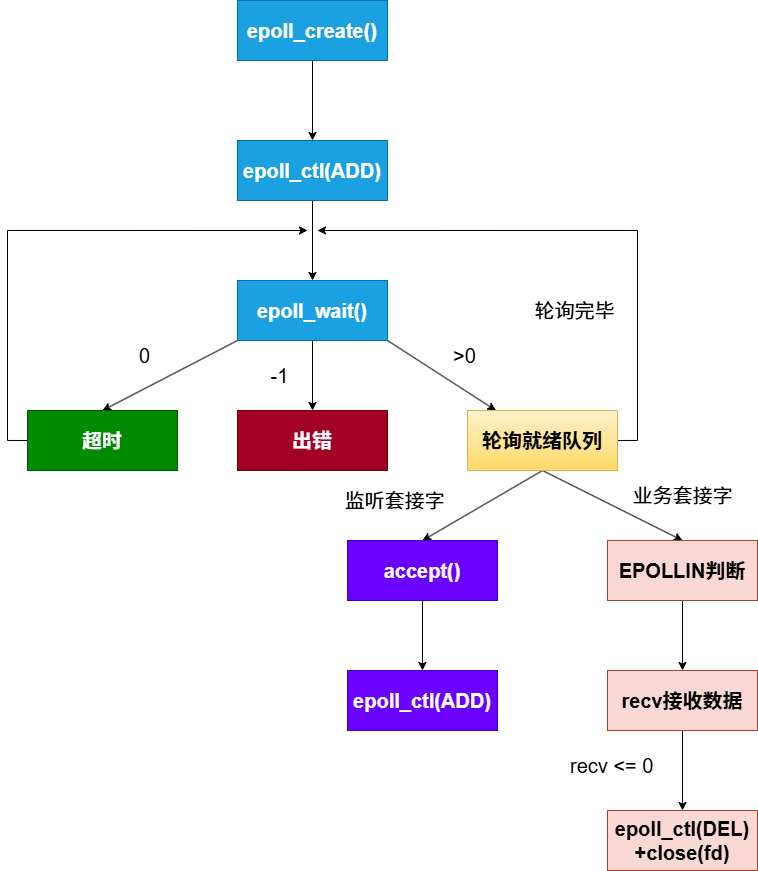
cpp
#pragma once
#include <iostream>
#include <sys/epoll.h> // 引入 epoll 专属头文件
#include <unistd.h>
#include "Socket.hpp"
using namespace std;
static const uint16_t defaultport = 8888;
static const int max_events = 100; // epoll_wait 一次最多拿回多少个就绪事件
class EpollServer
{
public:
EpollServer(uint16_t port = defaultport) : port_(port), epfd_(-1) {}
~EpollServer() {
if (epfd_ >= 0) close(epfd_); // epoll 句柄本身也是个文件,记得关
listensock_.Close();
}
public:
bool Init() {
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
// 1. 建立大本营:创建一个 epoll 实例
// 参数 size 现代 Linux 中已被忽略,但必须大于 0
epfd_ = epoll_create(256);
if (epfd_ < 0) {
cerr << "epoll_create error" << endl;
return false;
}
return true;
}
void Accepter() {
std::string clientip;
uint16_t clientport = 0;
int sock = listensock_.Accept(&clientip, &clientport);
if (sock < 0) return;
cout << "accept success, " << clientip << ":" << clientport << ", sock fd: " << sock << endl;
// 【极其关键】:将新连接直接扔给内核的红黑树!
// 不需要再去手写 for 循环找 fd_array 的空位了!
struct epoll_event ev;
ev.events = EPOLLIN; // 关心读事件
ev.data.fd = sock; // 绑定用户数据,等它就绪时,内核会把这个 fd 原封不动还给我
epoll_ctl(epfd_, EPOLL_CTL_ADD, sock, &ev);
}
void Recver(int fd) {
char buffer[1024];
ssize_t n = read(fd, buffer, sizeof(buffer) - 1);
if (n > 0) {
buffer[n] = 0;
cout << "get a message on fd " << fd << ": " << buffer << endl;
} else {
if (n == 0) cout << "client quit, close fd: " << fd << endl;
else cerr << "recv error on fd: " << fd << endl;
// 【清理工作】:从内核红黑树中删掉它
epoll_ctl(epfd_, EPOLL_CTL_DEL, fd, nullptr);
close(fd);
}
}
void Start() {
// 先把监听套接字加进大本营
int listensock = listensock_.Fd();
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = listensock;
epoll_ctl(epfd_, EPOLL_CTL_ADD, listensock, &ev);
// 准备一个空数组,专门用来接收内核弹出的"就绪事件"
struct epoll_event revs[max_events];
for (;;) {
// 3. 坐等通知:只取有事件的 FD
int timeout = 1000;
int n = epoll_wait(epfd_, revs, max_events, timeout);
switch (n) {
case 0:
// cout << "time out" << endl;
break;
case -1:
cerr << "epoll_wait error" << endl;
break;
default:
// 有事件就绪了!n 代表有几个就绪
// 这里的循环只遍历 0 到 n-1,绝对没有空转!
for (int i = 0; i < n; i++) {
int ready_fd = revs[i].data.fd; // 拿回刚才绑定的 fd
uint32_t ready_events = revs[i].events; // 拿回具体的事件类型
if (ready_events & EPOLLIN) {
if (ready_fd == listensock_.Fd()) {
Accepter();
} else {
Recver(ready_fd);
}
}
}
break;
}
}
}
private:
Sock listensock_;
uint16_t port_;
int epfd_; // epoll 的专属文件描述符
};六、对比LT和ET(⭐⭐⭐)
1. 核心触发机制
这是两者最本质的区别,也就是我们之前提到的"啰嗦快递员"与"高冷快递员"的区别。
LT (Level Triggered - 水平触发):关注"状态"
原理: 只要底层套接字的读/写缓冲区处于"就绪状态"(例如接收缓冲区里有数据,或者发送缓冲区有空间),
epoll_wait就会一直不断地唤醒并通知你。行为: 假设缓冲区里有 10KB 数据,你只读了 2KB,剩下的 8KB 只要还在里面,你下一次调用
epoll_wait,它还是会立刻返回告诉你"有数据可读"。
ET (Edge Triggered - 边缘触发):关注"变化"
原理:
epoll_wait只有在底层套接字的状态发生"跳变"(Edge)时,才会触发一次通知。行为: 比如接收缓冲区从"空"变成了"有数据",或者对端又发送了"新的数据包"过来。如果缓冲区里有 10KB 数据,你只读了 2KB,只要没有新 的数据到达,你下次再调用
epoll_wait,它绝对不会再通知你,剩下的 8KB 数据就会永远沉睡在内核里。
2. 对Socket 属性的硬性要求
LT 模式:
要求: 非常宽容。你可以使用默认的阻塞套接字(Blocking Socket),也可以使用非阻塞套接字。
原因: 因为就算你这次没读完,下次还能接着读,不要求你一次性榨干缓冲区,所以不用担心被阻塞挂起。
ET 模式:
要求: 必须配合非阻塞套接字(Non-blocking Socket)使用!
原因: 因为 ET 模式"只通知一次",这倒逼你必须写一个死循环不断去
read,直到把缓冲区彻底榨干。如果在这个死循环中使用了阻塞套接字,当读完最后一点数据时,再调用一次read,当前线程就会直接死锁卡住!
3. 代码编写范式的区别
LT 模式的代码范式(简单直白):
cpp// 收到通知后,随缘读一次,读到多少是多少 ssize_t n = read(fd, buffer, sizeof(buffer)); // 完事!没读完的交给下一次 epoll_wait 通知。
ET 模式的代码范式(严谨的榨干循环):
cpp// 收到通知后,必须死循环读,直到内核说"一滴都不剩了" (EAGAIN) while (true) { ssize_t n = read(fd, buffer, sizeof(buffer)); if (n < 0) { if (errno == EAGAIN || errno == EWOULDBLOCK) { break; // 完美榨干,可以安心退出循环 } // 处理其他真错误... } // 处理读到的数据... }
4. 性能与系统调用的较量
LT 模式的性能隐患(惊群与频繁切换):
如果数据包很大,开发者为了不阻塞其他连接,可能会限制每次
read的长度。在 LT 模式下,这会导致epoll_wait被极其频繁地触发。每一次触发都伴随着昂贵的用户态到内核态的上下文切换,极大地浪费 CPU 资源。在写数据时更致命。因为发送缓冲区绝大多数时间都是有空间的,如果你把一个 Socket 的
EPOLLOUT事件注册为 LT 模式,epoll_wait会疯狂触发,形成可怕的 CPU 空转。
ET 模式的高性能奥秘:
最大程度地减少了
epoll_wait的调用次数。将多次系统调用合并为在用户态的一个
while循环,极大地降低了内核态切换的开销。Nginx、Redis、Node.js 等追求极致高并发的中间件,底层清一色采用 ET 模式 + 非阻塞 I/O 的架构。