1.raspberrypi Camera驱动框架
树莓派核心仓库:
https://github.com/raspberrypi/linux
源码路径:
linux-rpi-6.12.y\drivers\media\platform\raspberrypi
1.1硬件层
包括摄像头传感器(如 IMX219)、MIPI CSI-2 接口、RP1 芯片的 CFE(Camera Front End)、PISP(图像信号处理器)等。
1.2 驱动层
- rp1_cfe:负责摄像头数据采集、MIPI/DPHY 物理层(csi2.c,dphy.c)、前端预处理(pisp_fe.c)。
- pisp_be:负责图像后端处理(pisp_be/pisp_be.c如格式转换、输出)。
- hevc_dec: 负责H265的解码
- 其他驱动(如 sensor 驱动)负责具体摄像头芯片的初始化和控制。
1.3 V4L2 框架对接
树莓派的 camera 驱动通过实现 V4L2 子设备(subdev)和 video device 接口,将底层硬件功能注册到 V4L2 框架。
- 驱动实现 struct v4l2_subdev_ops、v4l2_ioctl_ops、v4l2_file_operations 等接口。
- 通过 media controller 框架描述各模块的数据流关系(sensor → cfe → pisp → video node)。
- 用户空间应用通过 /dev/video* 设备节点,使用 V4L2 API(如 VIDIOC_STREAMON、VIDIOC_QBUF)访问摄像头。
1.4 数据流
摄像头采集到的原始数据经由 rp1_cfe 采集后预处理,再传递到 pisp_be 进行处理,最终通过 V4L2 video node 输出到用户空间。
简要流程:
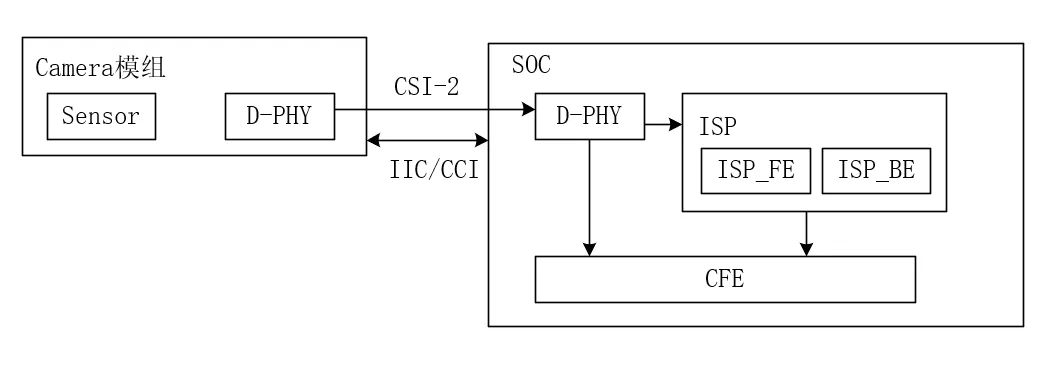
Camera Sensor → CSI2/DPHY (csi2.c/dphy.c) → ISP (pisp_fe.c/pisp_be.c) → V4L2 驱动 (注册 /dev/videoX) → vb2 缓冲区 → 用户空间应用
FE寄存器参考:https://datasheets.raspberrypi.com/camera/raspberry-pi-image-signal-processor-specification.pdf
FE的示例代码:https://github.com/raspberrypi/libpisp.git
参考资料:https://www.kernel.org/doc/html/latest/admin-guide/media/index.html
https://www.kernel.org/doc/html/latest/userspace-api/media/v4l/v4l2.html
树莓派Linux源码仓库:https://github.com/raspberrypi/linux.git
2.rpl-cfe驱动程序
2.1 raspberrypi camera驱动框图
Raspberry PiSP 摄像头前端 (rp1-cfe) 驱动程序位于 drivers/media/platform/raspberrypi/rp1-cfe 的 Drivers/Media/Platform/RaspberryPi/RP1-CFE 中。它使用 V4L2 API 注册 多个视频采集和输出设备,V4L2 subdev API 注册 接收的 CSI-2 的子设备以及连接视频设备的 FE 使用媒体控制器 (MC) API 实现的单个媒体图。
rp1-cfe 驱动程序注册的媒体拓扑,在此特定 连接到 IMX219 传感器的示例如下:
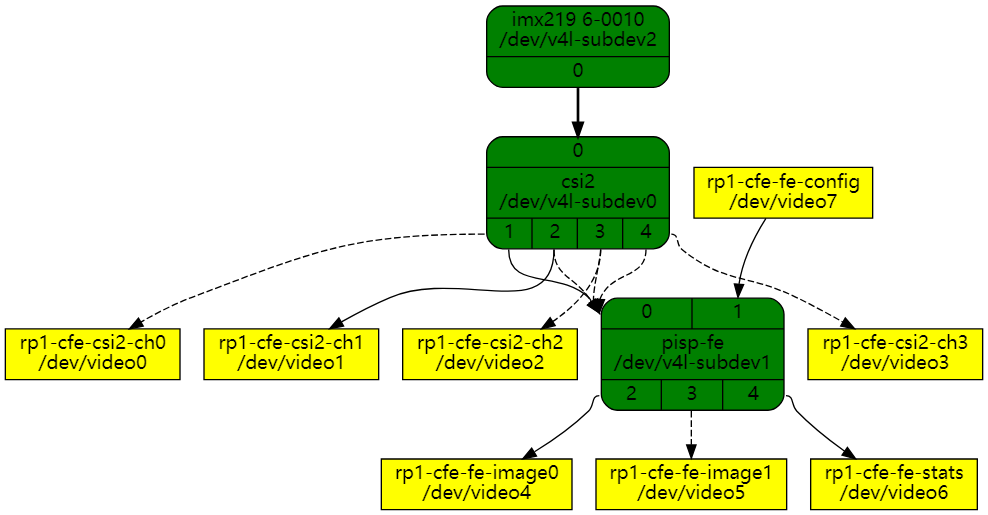
媒体图包含以下视频设备节点(详见node_description node_desc定义):
● rp1-cfe-csi2-ch0:第1个 CSI-2 流的捕获设备
● rp1-cfe-csi2-ch1:第1个 CSI-2 流的的嵌入行数据捕获(embedded data)
● rp1-cfe-csi2-ch2:第2个 CSI-2 流的捕获设备
● rp1-cfe-csi2-ch3:第3个 CSI-2 流的捕获设备
● rp1-cfe-fe-image0:第一个 FE 输出的捕获设备
● rp1-cfe-fe-image1:第二个 FE 输出的捕获设备
● rp1-cfe-fe-stats:用于 FE 统计信息的捕获设备
● rp1-cfe-fe-config:FE 配置的输出设备
rp1-cfe-csi2-chX 捕获设备是普通的 V4L2 捕获设备,它 可用于捕获从 CSI-2 接收的视频帧或元数据。
rp1-cfe-fe-image0 和 rp1-cfe-fe-image1 捕获设备用于写入 将处理的帧保存到内存中。
FE 统计缓冲区的格式由 C 结构定义,每个参数的含义为 在 PiSP 规范文档中进行了描述。pisp_statistics
FE 配置缓冲区的格式由 C 结构定义,每个参数的含义为 在 PiSP 规范文档中进行了描述。
2.2 rpl-cfe驱动架构
rpl-cfe的目录如下:
c
PS A:\raspberrypi\linux\drivers\media\platform\raspberrypi\rp1_cfe> dir
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 2025/1/7 21:48 65117 cfe.c
-a---- 2025/1/7 21:48 941 cfe.h
-a---- 2025/1/7 21:48 8298 cfe_fmts.h
-a---- 2025/1/7 21:48 17757 csi2.c
-a---- 2025/1/7 21:48 2307 csi2.h
-a---- 2025/1/7 21:48 5041 dphy.c
-a---- 2025/1/7 21:48 452 dphy.h
-a---- 2025/1/7 21:48 409 Kconfig
-a---- 2025/1/7 21:48 175 Makefile
-a---- 2025/1/7 21:48 1548 pisp_common.h
-a---- 2025/1/7 21:48 18627 pisp_fe.c
-a---- 2025/1/7 21:48 1323 pisp_fe.h
-a---- 2025/1/7 21:48 6514 pisp_fe_config.h
-a---- 2025/1/7 21:48 1678 pisp_statistics.h
-a---- 2025/1/7 21:48 6487 pisp_types.h
c
PS A:\raspberrypi\linux\drivers\media\platform\raspberrypi\pisp_be> dir
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 2025/1/7 21:48 407 Kconfig
-a---- 2025/1/7 21:48 172 Makefile
-a---- 2025/1/7 21:48 55988 pisp_be.c
-a---- 2025/1/7 21:48 15149 pisp_be_formats.h从源文件的文件名分析:
| 文件名 | 功能 |
|---|---|
| cfe.c | CSI-2数据流的捕获设备驱动 |
| csi2.c | MIPI-CSI-2的驱动文件 |
| dphy.c | dphy是mipi接口的物理层标准 |
| pisp_fe.c | isp的前端处理(具体可参考背景知识) |
| pisp_be.c | isp的后端处理 |
数据流图:
2.2.1 CFE
在树莓派的驱动中,CFE(Camera Front End,cfe.c)是一个重要的概念,它涉及到摄像头模块与树莓派之间的数据传输和处理。
定义:
• CFE 是树莓派摄像头前端,负责将 CSI-2 接收器与一个简单的 ISP(pisp_fe)连接起来,称为前端(FE)。
• CFE 有四个 DMA 引擎,可以从四个单独的流写入帧从 CSI-2 接收到内存。也可以路由其中一个流直接给 FE 做最少的图片处理,写两个版本(例如,未缩放和缩小版本)将接收到的帧保存到内存中,并且提供接收到的帧的统计信息。
主要功能:
- 数据传输:
• CFE 通过 CSI-2 接收器接收摄像头模块的图像数据。
• 支持多个数据通道(lane),每个通道可以是 D-PHY 或 C-PHY。
- DMA 引擎:
• CFE 有四个 DMA 引擎,可以从四个单独的流写入帧到内存。
• 支持将接收到的帧保存到内存中,并且可以生成多个版本(例如,未缩放和缩小版本)。
- 图像处理:
• CFE 可以将其中一个流直接路由给 FE 进行基本的图像处理。
• 提供接收到的帧的统计信息,用于图像质量控制和调试。
- V4L2 子设备:
• CFE 使用 V4L2 API 注册多个视频采集和输出设备。
• 使用 V4L2 subdev API 注册接收的 CSI-2 的子设备。
• 使用媒体控制器(MC)API 实现单个媒体图,管理视频设备的连接和数据流。
D-PHY
D-PHY驱动中对外提供了3个接口:
c
void dphy_probe(struct dphy_data *dphy);
void dphy_start(struct dphy_data *dphy);
void dphy_stop(struct dphy_data *dphy);
c
static void dw_csi2_host_write(struct dphy_data *dphy, u32 offset, u32 data)
{
writel(data, dphy->base + offset);
}
....
static void dphy_init(struct dphy_data *dphy)
{
dw_csi2_host_write(dphy, PHY_RSTZ, 0);
dw_csi2_host_write(dphy, PHY_SHUTDOWNZ, 0);
set_tstclk(dphy, 1);
set_testen(dphy, 0);
set_tstclr(dphy, 1);
usleep_range(15, 20);
set_tstclr(dphy, 0);
usleep_range(15, 20);
dphy_set_hsfreqrange(dphy, dphy->dphy_rate);
usleep_range(5, 10);
dw_csi2_host_write(dphy, PHY_SHUTDOWNZ, 1);
usleep_range(5, 10);
dw_csi2_host_write(dphy, PHY_RSTZ, 1);
}
void dphy_start(struct dphy_data *dphy)
{
dw_csi2_host_write(dphy, N_LANES, (dphy->active_lanes - 1));
dphy_init(dphy);
dw_csi2_host_write(dphy, RESETN, 0xffffffff);
usleep_range(10, 50);
}
void dphy_stop(struct dphy_data *dphy)
{
/* Set only one lane (lane 0) as active (ON) */
dw_csi2_host_write(dphy, N_LANES, 0);
dw_csi2_host_write(dphy, RESETN, 0);
}
void dphy_probe(struct dphy_data *dphy)
{
u32 host_ver;
u8 host_ver_major, host_ver_minor;
host_ver = dw_csi2_host_read(dphy, VERSION);
host_ver_major = (u8)((host_ver >> 24) - '0');
host_ver_minor = (u8)((host_ver >> 16) - '0');
host_ver_minor = host_ver_minor * 10;
host_ver_minor += (u8)((host_ver >> 8) - '0');
dphy_info("DW dphy Host HW v%u.%u\n", host_ver_major, host_ver_minor);
}CSI-2
CSI-2是一种应用层协议,通过D-PHY这个物理层传输介质来传输。
CSI-2外露了以下接口:
c
void csi2_isr(struct csi2_device *csi2, bool *sof, bool *eof);
void csi2_set_buffer(struct csi2_device *csi2, unsigned int channel,
dma_addr_t dmaaddr, unsigned int stride,
unsigned int size);
void csi2_set_compression(struct csi2_device *csi2, unsigned int channel,
enum csi2_compression_mode mode, unsigned int shift,
unsigned int offset);
void csi2_start_channel(struct csi2_device *csi2, unsigned int channel,
enum csi2_mode mode, bool auto_arm,
bool pack_bytes, unsigned int width,
unsigned int height);
void csi2_stop_channel(struct csi2_device *csi2, unsigned int channel);
void csi2_open_rx(struct csi2_device *csi2);
void csi2_close_rx(struct csi2_device *csi2);
int csi2_init(struct csi2_device *csi2, struct dentry *debugfs);
void csi2_uninit(struct csi2_device *csi2);以下为csi-2的初始化函数,tx函数和rx函数的实现:
c
int csi2_init(struct csi2_device *csi2, struct dentry *debugfs)
{
unsigned int i, ret;
spin_lock_init(&csi2->errors_lock);
csi2->dphy.dev = csi2->v4l2_dev->dev;
dphy_probe(&csi2->dphy);
debugfs_create_file("csi2_regs", 0444, debugfs, csi2, &csi2_regs_fops);
if (csi2_track_errors)
debugfs_create_file("csi2_errors", 0444, debugfs, csi2,
&csi2_errors_fops);
for (i = 0; i < CSI2_NUM_CHANNELS * 2; i++)
csi2->pad[i].flags = i < CSI2_NUM_CHANNELS ?
MEDIA_PAD_FL_SINK : MEDIA_PAD_FL_SOURCE;
ret = media_entity_pads_init(&csi2->sd.entity, ARRAY_SIZE(csi2->pad),
csi2->pad);
if (ret)
return ret;
/* Initialize subdev */
v4l2_subdev_init(&csi2->sd, &csi2_subdev_ops);
csi2->sd.entity.function = MEDIA_ENT_F_VID_IF_BRIDGE;
csi2->sd.entity.ops = &csi2_entity_ops;
csi2->sd.flags = V4L2_SUBDEV_FL_HAS_DEVNODE;
csi2->sd.owner = THIS_MODULE;
snprintf(csi2->sd.name, sizeof(csi2->sd.name), "csi2");
ret = v4l2_subdev_init_finalize(&csi2->sd);
if (ret)
goto err_entity_cleanup;
ret = v4l2_device_register_subdev(csi2->v4l2_dev, &csi2->sd);
if (ret) {
csi2_err("Failed register csi2 subdev (%d)\n", ret);
goto err_subdev_cleanup;
}
return 0;
err_subdev_cleanup:
v4l2_subdev_cleanup(&csi2->sd);
err_entity_cleanup:
media_entity_cleanup(&csi2->sd.entity);
return ret;
}
void csi2_open_rx(struct csi2_device *csi2)
{
csi2_reg_write(csi2, CSI2_IRQ_MASK,
csi2_track_errors ? CSI2_IRQ_MASK_IRQ_ALL : 0);
dphy_start(&csi2->dphy);
csi2_reg_write(csi2, CSI2_CTRL,
csi2->multipacket_line ? 0 : EOP_IS_EOL);
}
void csi2_close_rx(struct csi2_device *csi2)
{
dphy_stop(&csi2->dphy);
csi2_reg_write(csi2, CSI2_IRQ_MASK, 0);
}
static const struct v4l2_subdev_pad_ops csi2_subdev_pad_ops = {
.init_cfg = csi2_init_cfg,
.get_fmt = v4l2_subdev_get_fmt,
.set_fmt = csi2_pad_set_fmt,
.link_validate = v4l2_subdev_link_validate_default,
};
static const struct media_entity_operations csi2_entity_ops = {
.link_validate = v4l2_subdev_link_validate,
};
static const struct v4l2_subdev_ops csi2_subdev_ops = {
.pad = &csi2_subdev_pad_ops,
};PISP_FE
主要负责与 MIPI/CSI2 接口的数据对接(通常从 csi2.c/dphy.c 获取原始帧),然后对原始图像数据的初步处理(pisp_fe)
pisp_fe是连接 Linux 内核视频子系统和 PiSP 硬件前端的桥梁。它不直接处理图像像素数据,而是负责配置硬件流水线(解压缩、去噪、裁剪、缩放、统计收集等),管理DMA 缓冲区,处理硬件中断,并通过标准的 V4L2 接口 暴露控制能力给用户空间应用程序。
主要的功能函数如下:
c
// PiSP FE 的中断服务程序入口
void pisp_fe_isr(struct pisp_fe_device *fe, bool *sof, bool *eof);
// 验证整个作业配置 (pisp_fe_config) 的全局合法性。
int pisp_fe_validate_config(struct pisp_fe_device *fe,
struct pisp_fe_config *cfg,
struct v4l2_format const *f0,
struct v4l2_format const *f1);
// 将一个图像处理作业提交给硬件执行
void pisp_fe_submit_job(struct pisp_fe_device *fe, struct vb2_buffer **vb2_bufs,
struct pisp_fe_config *cfg);
// 初始化并启动 PiSP FE 硬件模块。
void pisp_fe_start(struct pisp_fe_device *fe);
// 功能: 停止 PiSP FE 硬件模块
void pisp_fe_stop(struct pisp_fe_device *fe);
// 驱动加载时初始化 PiSP FE 设备
int pisp_fe_init(struct pisp_fe_device *fe, struct dentry *debugfs);
// 驱动卸载时清理资源。
void pisp_fe_uninit(struct pisp_fe_device *fe);2.2.2 pisp_be
pisp_be是(后端 Back-End),主要负责后续的图像处理和格式转换,与前端 (FE) 主要负责图像预处理(如去噪、裁剪)不同,后端主要负责图像的最终渲染、格式转换、分块处理 (Tiling)、压缩/解压缩以及多路输出。
pisp_be一个完整的作业(Job)需要多个节点的 Buffer 同时就绪才能触发
工作流
1.应用初始化与格式协商
在传输数据前,应用必须要配置好各个节点
- 打开设备:应用打开对应的
/dev/videoX节点 - 设置格式(VIDIOC_S_FMT):
应用为输入节点设置源图像格式(如 RAW10/RGB888)
应用为输出节点设置目标图像格式(如 YUV420/NV12)
应用为配置节点设置元数据格式(V4L2_META_FMT_PISP_BE_CONFIG)
驱动的行为:调用pispbe_node_s_fmt_*->pispbe_try_format校验参数合法性并保存
- 申请缓冲区:
应用请求分配一定数量的缓冲区(例如 4 个)
驱动的行为:调用 pispbe_node_queue_setup 计算所需内存大小,内核通过 vb2 框架分配 DMA 内存
- 查询缓冲区:
应用获取每个 Buffer 的用户空间指针(mmap)或 fd(dmabuf)
2.入队缓冲区 (应用层到驱动层)
应用将填好数据的 Buffer 和空的接收 Buffer 推送到驱动队列中
- 填充输入数据:应用通过mmap或write将原始图像数据写入输入节点的buffer
- 填充配置数据:应用构建 struct pisp_be_config 结构体(定义裁剪、缩放、分块 Tile 信息、使能模块等),并将其写入配置节点的 Buffer
- 准备输出空缓冲:应用确保输出节点的 Buffer 是空的,准备好接收硬件处理后的数据
- 入队操作(VIDIOC_QBUF):
- 应用依次对 Input、Output、Config 节点调用 QBUF
- 驱动行为:
- 1.进入 pispbe_node_buffer_queue
- 2.将 Buffer 加入该节点内部的 ready_queue 链表
- 3.如果是配置节点: 驱动会立即将用户空间的配置数据拷贝到内核的相干 DMA 区域 (node_group->config),并调用 pisp_be_validate_config 进行预校验
- 4.调用 pispbe_prepare_job 尝试组装任务
3.任务组装与调度(驱动核心逻辑)
PiSP BE 最关键的一步,只有当所有必需节点都有 Buffer 时,任务才会被提交
- 查就绪状态 (pispbe_prepare_job):
驱动检查当前 Node Group 下的所有相关节点(Main Input, Config, Output0, TDN Input/Output 等)
- 条件判断:
Config 节点必须有 Buffer。
Main Input 节点必须有 Buffer
根据 Config 中的使能位,检查对应的 Output 或其他辅助节点是否有 Buffer
- 地址转换(pispbe_xlate_addrs):
如果条件满足,驱动从各节点的 ready_queue 头部取出 Buffer
调用 pispbe_get_planes_addr 获取每个 Buffer 平面的 DMA 物理地址
将这些地址填入临时的 pispbe_job_descriptor 结构体中
动态掩码: 如果配置开启了某功能但应用没给对应 Buffer,驱动会自动清除该功能的硬件使能位,防止硬件崩溃
- 加入全局队列
组装好的 Job 被放入全局 job_queue
- 触发调度(pispbe_schedule)
检查硬件是否空闲 (hw_busy == false)
如果空闲且 job_queue 非空,取出队首 Job,标记 hw_busy = true,并调用 pispbe_queue_job
4.硬件执行(驱动层->硬件层)
- 寄存器配置 (pispbe_queue_job):
驱动将 Job 描述符中的 DMA 地址 写入 PiSP BE 的地址寄存器 (PISP_BE_IO_ADDR_LOW/HIGH)
驱动将 配置数据 (Tile 信息、模块使能) 写入配置寄存器区域
驱动写入 PISP_BE_CONTROL_QUEUE_JOB 命令寄存器
- 硬件处理:
PiSP BE 硬件通过 DMA 读取输入数据
根据配置执行去噪、色彩转换、缩放、分块渲染等处理
通过 DMA 将结果写入输出 Buffer
处理完成后,硬件触发中断
5.中断处理与完成通知(硬件->驱动层)
- 中断响应(pispbe_isr):
CPU 响应中断,进入 pispbe_isr
读取 BATCH_STATUS 寄存器,确认哪些批次(Batch)已完成
更新驱动内部计数 (running_job, queued_job)
标记 hw_busy = false
- 归还 Buffer (pispbe_isr_jobdone):
遍历已完成 Job 中的所有 Buffer(输入、输出、配置)
设置 Buffer 的时间戳 (timestamp) 和序列号 (sequence)
调用 vb2_buffer_done。这会将 Buffer 状态从 "Processing" 改为 "Done",并唤醒等待在该 Buffer 上的用户空间进程
调度下一个任务:
- 在 ISR 末尾再次调用 pispbe_schedule。如果 job_queue 中还有待处理任务且硬件已空闲,立即启动下一个 Job,实现流水线处理
6.出队与应用获取(驱动层->应用层)
- 出队操作(VIDIOC_DQBUF):
应用在之前 QBUF 的输出节点上调用 DQBUF(通常会阻塞,直到 ISR 唤醒)
驱动行为: vb2_core_dqbuf 从 done_queue 取出 Buffer 返回给用户
- 数据使用:
应用此时可以安全地读取输出 Buffer 中的数据(已经是处理后的图像,如 JPEG 或 YUV)
如果需要继续处理,应用可以修改 Buffer 内容或直接再次 QBUF 将其作为下一帧的输入
7.工作流图
否
是
忙
空闲
复用Buffer
应用: 打开设备并设置格式
应用: 申请 Buffers
应用: 填充 Input与Config数据\n准备空的Output Buffer
QBUF: Input Node
QBUF: Config Node
QBUF: Output Node
驱动: pispbe_prepare_job\n检查所有必需节点是否就绪
驱动: 等待其他节点 QBUF
驱动: 获取 DMA 地址并校验
驱动: 加入 job_queue
驱动: pispbe_schedule\n硬件是否空闲
驱动: 等待硬件完成
驱动: 写寄存器并触发硬件\npispbe_queue_job
硬件: DMA读取 -> 处理 -> DMA写入
硬件: 触发中断 IRQ
驱动: pispbe_isr 中断处理
驱动: 标记 Buffer Done\n调用 vb2_buffer_done
驱动: 尝试调度下一个 Job
应用: DQBUF Output Node\n阻塞直到完成
应用: 获取处理后的图像数据
驱动代码分析
1.基础寄存器操作
c
// 读取 PiSP BE 硬件寄存器的值。
static u32 pispbe_rd(struct pispbe_dev *pispbe, unsigned int offset)
// 向 PiSP BE 硬件寄存器写入值
static void pispbe_wr(struct pispbe_dev *pispbe, unsigned int offset, u32 val)2.作业提交与硬件控制
驱动的核心部分,负责将软件配置发送给硬件执行
c
static void pispbe_queue_job(struct pispbe_dev *pispbe,
struct pispbe_job_descriptor *job)
{
unsigned int begin, end;
// 1.检查硬件是否已处于排队状态(防止冲突)
if (pispbe_rd(pispbe, PISP_BE_STATUS_REG) & PISP_BE_STATUS_QUEUED)
dev_err(pispbe->dev, "ERROR: not safe to queue new job!\n");
/*
* Write configuration to hardware. DMA addresses and enable flags
* are passed separately, because the driver needs to sanitize them,
* and we don't want to modify (or be vulnerable to modifications of)
* the mmap'd buffer.
*/
// 2.将所有输入/输出缓冲区的 DMA 物理地址写入对应的地址寄存器 (PISP_BE_IO_ADDR_LOW/HIGH)。
for (unsigned int u = 0; u < N_HW_ADDRESSES; ++u) {
pispbe_wr(pispbe, PISP_BE_IO_ADDR_LOW(u),
lower_32_bits(job->hw_dma_addrs[u]));
pispbe_wr(pispbe, PISP_BE_IO_ADDR_HIGH(u),
upper_32_bits(job->hw_dma_addrs[u]));
}
// 3.写入 Bayer 和 RGB 处理模块的使能位。
pispbe_wr(pispbe, PISP_BE_GLOBAL_BAYER_ENABLE,
job->hw_enables.bayer_enables);
pispbe_wr(pispbe, PISP_BE_GLOBAL_RGB_ENABLE,
job->hw_enables.rgb_enables);
/* Everything else is as supplied by the user. */
// 4.将用户提供的配置结构体 (pisp_be_config) 复制到硬件配置寄存器区域
begin = offsetof(struct pisp_be_config, global.bayer_order) /
sizeof(u32);
end = sizeof(struct pisp_be_config) / sizeof(u32);
for (unsigned int u = begin; u < end; u++)
pispbe_wr(pispbe, PISP_BE_CONFIG_BASE_REG + sizeof(u32) * u,
((u32 *)job->config)[u]);
/* Read back the addresses -- an error here could be fatal */
//5.校验写入的地址是否正确(防止硬件访问错误内存)
for (unsigned int u = 0; u < N_HW_ADDRESSES; ++u) {
unsigned int offset = PISP_BE_IO_ADDR_LOW(u);
u64 along = pispbe_rd(pispbe, offset);
along += ((u64)pispbe_rd(pispbe, offset + 4)) << 32;
if (along != (u64)(job->hw_dma_addrs[u])) {
dev_dbg(pispbe->dev,
"ISP BE config error: check if ISP RAMs enabled?\n");
return;
}
}
/*
* Write tile pointer to hardware. The IOMMU should prevent
* out-of-bounds offsets reaching non-ISP buffers.
*/
// 6.写入分块 (Tile) 配置的物理地址
pispbe_wr(pispbe, PISP_BE_TILE_ADDR_LO_REG, lower_32_bits(job->tiles));
pispbe_wr(pispbe, PISP_BE_TILE_ADDR_HI_REG, upper_32_bits(job->tiles));
/* 7.Enqueue the job */
// 最后写入 PISP_BE_CONTROL_QUEUE_JOB 命令,触发硬件开始执行。
pispbe_wr(pispbe, PISP_BE_CONTROL_REG,
PISP_BE_CONTROL_COPY_CONFIG | PISP_BE_CONTROL_QUEUE_JOB |
PISP_BE_CONTROL_NUM_TILES(job->config->num_tiles));
}3.地址转换与缓冲区管理
将 V4L2 缓冲区映射为硬件可识别的 DMA 地址
c
// 获取多平面 (Multi-plane) 图像缓冲区的各平面 DMA 地址
// 用于处理 YUV420 等格式,根据步长 (stride) 和高度计算非连续平面的物理地址偏移,填充到地址数组中供硬件使用
static int pispbe_get_planes_addr(dma_addr_t addr[3], struct pispbe_buffer *buf,
struct pispbe_node *node)
// 获取单平面缓冲区的 DMA 地址
// 用于 TDN (Temporal Denoising) 或 Stitching 等单平面输入/输出
static dma_addr_t pispbe_get_addr(struct pispbe_buffer *buf)
// 翻译整个作业的所有缓冲区地址并更新硬件使能位
// 根据配置中的使能位和实际提供的缓冲区指针,动态清除无效的使能位
static void pispbe_xlate_addrs(struct pispbe_job_descriptor *job,
struct pispbe_buffer *buf[PISPBE_NUM_NODES],
struct pispbe_node_group *node_group)4.作业调度与队列管理
管理待执行的任务队列,确保资源就绪后提交给硬件
c
// 检查所有必需的输入/输出缓冲区是否就绪,并准备一个作业描述符
// 1.确认配置节点 (Config) 和主输入节点 (Main Input) 必须有缓冲区
// 2.根据配置中的使能位,检查其他可选节点(如 Output0, TDN Output)是否有缓冲区。如果配置未启用某模块,即使有缓冲区也会忽略或回退。
// 3.从各节点的 ready_queue 中取出缓冲区
// 4.调用 pispbe_xlate_addrs 转换地址
// 5.将作业添加到全局 job_queue 等待调度
static int pispbe_prepare_job(struct pispbe_node_group *node_group)
// 调度器入口,尝试从队列中取出一个作业并提交给硬件。
// 1.检查硬件是否空闲
// 2.如果空闲且队列中有任务,取出队首任务,标记硬件为忙,并调用 pispbe_queue_job 启动硬件
static void pispbe_schedule(struct pispbe_dev *pispbe, bool clear_hw_busy)5.中断处理
处理硬件完成信号,通知上层应用
c
// 辅助函数,标记作业中的所有缓冲区为完成状态:设置时间戳和序列号,调用 vb2_buffer_done 将缓冲区归还给用户空间
static void pispbe_isr_jobdone(struct pispbe_dev *pispbe,
struct pispbe_job *job)
// 主中断服务程序 (ISR)
// 1.读取并清除中断状态寄存器
// 2.读取批次状态寄存器 (BATCH_STATUS),获取已完成 (done) 和已开始 (started) 的任务计数
// 3.对比驱动内部计数与硬件计数,判断哪些任务已完成
// 4. 对已完成的任务调用 pispbe_isr_jobdone
// 5. 更新内部状态机 (running_job, queued_job)
// 6.调用 pispbe_schedule 尝试启动下一个 queued 的任务(实现自动流水线)
static irqreturn_t pispbe_isr(int irq, void *dev)6.配置验证
任务提交前确保参数合法性
c
// 验证用户提交的配置结构体是否合法
// 1.检查是否至少启用了 Bayer 或 RGB 输入之一
// 2.检查分块数量 (num_tiles) 是否在有效范围内
// 3.关键检查: 验证配置中指定的输出图像尺寸、步长 (stride) 是否与 V4L2 节点上设置的缓冲区格式匹配,防止越界写入
static int pisp_be_validate_config(struct pispbe_node_group *node_group,
struct pisp_be_tiles_config *config)7.v4l2队列操作(vb2_ops)
实现Videobuf2 框架回调,管理缓冲区生命周期
c
// 协商缓冲区数量和大小,根据当前设置的格式计算每个平面所需的大小,告知用户空间需要分配多少内存
static int pispbe_node_queue_setup(struct vb2_queue *q, unsigned int *nbuffers,
unsigned int *nplanes, unsigned int sizes[],
struct device *alloc_devs[])
// 在缓冲区入队前进行准备和验证
// 1.检查用户提供的缓冲区大小是否足够
// 2.如果是配置节点,复制配置数据并验证配置是否合法
static int pispbe_node_buffer_prepare(struct vb2_buffer *vb)
// 将缓冲区添加到就绪队列:将缓冲区加入链表的 ready_queue,并尝试触发 pispbe_prepare_job 看是否能组成新任务
static void pispbe_node_buffer_queue(struct vb2_buffer *buf)
// 启动流传输:开启运行时电源管理 (PM Runtime),更新 streaming_map,并尝试调度任务
static int pispbe_node_start_streaming(struct vb2_queue *q, unsigned int count)8.v4l2 ioctl操作
处理用户空间的格式设置、查询等请求,用于获取、设置和尝试设置视频格式
try_fmt用于调用 pispbe_try_format 调整用户请求的分辨率、像素格式到硬件支持的范围内(如对齐 stride,限制最大宽高)。
c
static int pispbe_node_g_fmt_vid_cap(struct file *file, void *priv,
struct v4l2_format *f)
static int pispbe_node_g_fmt_vid_out(struct file *file, void *priv,
struct v4l2_format *f)
static int pispbe_node_s_fmt_vid_cap(struct file *file, void *priv,
struct v4l2_format *f)
static int pispbe_node_s_fmt_vid_out(struct file *file, void *priv,
struct v4l2_format *f)
static int pispbe_node_try_fmt_vid_out(struct file *file, void *priv,
struct v4l2_format *f)
static int pispbe_node_try_fmt_meta_out(struct file *file, void *priv,
struct v4l2_format *f)
...
// 核心格式协商逻辑,用于查找支持的格式表,修正宽高范围,计算正确的颜色空间、编码方式和平面大小
static void pispbe_try_format(struct v4l2_format *f, struct pispbe_node *node)
// 枚举支持的像素格式和帧尺寸,返回驱动支持的格式列表和分辨率范围
static int pispbe_node_enum_fmt(struct file *file, void *priv,
struct v4l2_fmtdesc *f)
static int pispbe_enum_framesizes(struct file *file, void *priv,
struct v4l2_frmsizeenum *fsize)9.初始化与资源销毁
设备探针和移除逻辑
c
// 初始化单个视频节点,:初始化 vb2_queue,注册 video_device,创建 Media Controller Pad 和链接
static int pispbe_init_node(struct pispbe_node_group *node_group,
unsigned int id)
// 初始化 V4L2 Subdevice
// 注册子设备实体,配置 Media Entity 的 Pads(源/宿),建立与视频节点的连接
static int pispbe_init_subdev(struct pispbe_node_group *node_group)
// 初始化一个完整的"节点组" (Node Group)
// 一个组包含所有输入/输出节点和一个子设备。此函数负责创建 V4L2 设备、Media 设备、分配配置缓冲区的 DMA 内存,并循环初始化组内所有节点。
static int pispbe_init_group(struct pispbe_dev *pispbe, unsigned int id)
// 硬件复位和初始化
// 读取版本号校验,清除残留中断,配置 AXI 总线参数(QoS, Cache),使能中断
static int pispbe_hw_init(struct pispbe_dev *pispbe)
// 平台驱动探针入口
// 映射寄存器内存,申请中断,获取时钟,启用电源管理,初始化硬件,并循环创建两个独立的节点组,支持两个并发用户
static int pispbe_probe(struct platform_device *pdev)
// 驱动移除清理
// 反向销毁所有节点组,禁用电源和时钟
static void pispbe_remove(struct platform_device *pdev)10.电源管理
str场景下会使用
c
// 运行时电源管理回调,在空闲时关闭时钟以省电,在有任务时开启时钟
static int pispbe_runtime_suspend(struct device *dev)
static int pispbe_runtime_resume(struct device *dev)11.小结
pisp_be.c 实现了一个复杂的 M2M (Memory-to-Memory) 多节点视频处理设备,其核心特点包括:
多节点架构 : 通过一个子设备关联多个输入/输出视频节点,允许用户灵活构建处理图(例如:输入 -> 降噪 -> 输出A + 输出B)
配置与数据分离 : 使用独立的元数据节点 (CONFIG_NODE) 传递复杂的分块处理配置
严格的同步机制 : 只有当所有必需节点的缓冲区都就绪时,才会组装成一个 Job 提交给硬件
硬件保护 : 在提交前进行大量的地址和尺寸校验,并在地址转换阶段动态禁用未提供缓冲区的硬件模块,防止硬件异常
3.背景知识
3.1 ISP
在图像信号处理(ISP)领域,ISP_FE和 ISP_BE分别代表图像信号处理的前端(Front End)和后端(Back End)。以下是它们的详细解释:
ISP_FE(图像信号处理前端)
定义:
ISP_FE是图像信号处理流水线中前端部分,主要负责从图像传感器接收原始图像数据(通常是 Bayer 格式)并进行初步处理。
主要功能:
• 图像裁剪(Crop):对输入图像进行裁剪,去除不需要的边缘部分。
• 坏点校正(Defect Pixel Correction,DPC):检测和校正图像中的坏点。
• 黑电平校正(Black Level Compensation,BLC):校正图像的黑电平,提高图像质量。
• 镜头阴影校正(Lens Shading Correction,LSC):校正由于镜头光学特性导致的图像阴影。
• 自动曝光控制(Auto Exposure Control,AEC):根据环境光线自动调整曝光参数,以获得最佳图像亮度。
• 自动白平衡(Auto White Balance,AWB):自动调整图像的白平衡,使图像颜色更自然。
ISP_BE(图像信号处理后端)
定义:
ISP_BE是图像信号处理流水线中后端部分,主要负责对前端处理后的图像数据进行进一步的处理,生成最终的输出图像(通常是 YUV 或 RGB 格式)。
主要功能:
• 去噪(Noise Reduction,NR):在 Bayer 域或 RGB 域进行去噪处理,减少图像噪声。
• 色彩校正(Color Correction Matrix,CCM):通过矩阵变换调整图像的色彩平衡。
• 伽马校正(Gamma Correction):调整图像的伽马曲线,改善图像的对比度和亮度。
• 锐化(Sharpening):增强图像的边缘,提高图像的清晰度。
• 动态范围压缩(Dynamic Range Compression,DRC):压缩图像的动态范围,使图像在不同光照条件下都能保持良好的视觉效果。
• 多帧合成宽动态(Multi-Frame Wide Dynamic Range,WDR):通过多帧合成技术,提高图像在高动态范围场景下的表现。
• 色彩空间转换(Color Space Conversion):将图像从 Bayer 格式转换为 YUV 或 RGB 格式,以便后续处理和显示。
示例架构
以下是一个典型的 ISP 处理流图,展示了 ISP_FE和 ISP_BE的位置和功能:
plain
图像传感器 (Sensor) --> D-PHY/C-PHY --> CSI-2 --> ISP_FE --> ISP_BE --> 输出图像 (YUV/RGB)• ISP_FE:
• 接收 Bayer 格式的原始图像数据。
• 进行裁剪、坏点校正、黑电平校正、镜头阴影校正等初步处理。
• 输出处理后的 Bayer 图像数据。
• ISP_BE:
• 接收处理后的 Bayer 图像数据。
• 进行去噪、色彩校正、伽马校正、锐化、动态范围压缩等高级处理。
• 输出最终的 YUV 或 RGB 图像数据。
总结
• ISP_FE:主要负责从图像传感器接收原始图像数据并进行初步处理。
• ISP_BE:主要负责对初步处理后的图像数据进行进一步的处理,生成最终的输出图像。
通过这种分工,ISP 能够高效地处理图像数据,提供高质量的图像输出。
3.2 CSI-2,C-PHY,D-PHY
D-PHY:
- D-PHY 是 MIPI 接口的一种物理层标准,主要用于摄像头(CSI)和显示屏(DSI)的数据传输。
- D 是罗马数字中的 500,表示 D-PHY 最初设计目标是支持 500 Mbits/s 的数据传输速率。
C-PHY:
• C-PHY 是 MIPI 接口的另一种物理层标准,旨在提供更高的数据传输速率,适用于高带宽应用。
• C 代表 Channel-limited,表示 C-PHY 适用于通道受限的应用场景。
CSI-2:
- CSI-2 是 MIPI 接口的一种应用层协议,主要用于摄像头模块与处理器之间的高速数据传输。
- CSI-2 定义了数据传输的格式、协议和控制机制,确保摄像头采集的图像数据能够高效、准确地传输到处理器。
| 特性 | D-PHY | C-PHY | CSI-2 |
|---|---|---|---|
| 类型 | 物理层标准 | 物理层标准 | 应用层协议 |
| 主要功能 | 数据传输的物理介质定义 | 数据传输的物理介质定义 | 数据传输的格式和控制机制 |
| 信号传输 | 差分信号对,每条 lane 两根线 | 三相信号 | 定义数据包格式和传输协议 |
| 时钟支持 | 独立时钟线 | C-PHY 没有单独的时钟线,时钟信号嵌入在数据传输的时序中,减少了引脚数量 | 通过 LLP 和 Lane Management 管理时钟 |
| 传输速率 | 最高 1.5 Gbps/通道 | 高达 2.5 Gbps | 依赖于物理层(D-PHY 或 C-PHY) |
| 数据线配置 | 1/2/4 条数据 lane | 三条信号线 | 多通道数据传输,每个通道可以是 D-PHY 或 C-PHY |
| 应用场景 | 摄像头和显示屏的数据传输 | 高端显示器、相机模块 | 摄像头模块与处理器之间的数据传输 |
| 控制接口 | 无 | 无 | 包含 CCI(基于 I2C) |