目录
[C++ 线程库的基本使用](#C++ 线程库的基本使用)
[main.cpp(thread 对象的基本使用)](#main.cpp(thread 对象的基本使用))
[一、C++11 线程库的基本使用(结合代码拆解)](#一、C++11 线程库的基本使用(结合代码拆解))
[二、thread构造函数的核心:万能引用 + 参数包(泛型模板)](#二、thread构造函数的核心:万能引用 + 参数包(泛型模板))
[三、thread封装pthread_create的细节(Linux 下)](#三、thread封装pthread_create的细节(Linux 下))
[一、核心问题:thread构造函数的参数传递机制(值拷贝 vs 引用)](#一、核心问题:thread构造函数的参数传递机制(值拷贝 vs 引用))
[二、更简洁的替代方案:Lambda 表达式的引用捕获](#二、更简洁的替代方案:Lambda 表达式的引用捕获)
[main.cpp(封装锁 ------ 类似智能指针)](#main.cpp(封装锁 —— 类似智能指针))
[二、LockGuard 的核心实现:RAII 封装锁(类比智能指针)](#二、LockGuard 的核心实现:RAII 封装锁(类比智能指针))
[三、LockGuard 如何解决 "死锁 / 异常导致的锁未释放" 问题](#三、LockGuard 如何解决 “死锁 / 异常导致的锁未释放” 问题)
[四、代码执行流程(验证 LockGuard 的作用)](#四、代码执行流程(验证 LockGuard 的作用))
总结(关键点回顾)
多线程done(两个线程,奇偶数交替输出)[一、condition_variable(条件变量):线程间的 "等待 / 唤醒" 同步工具](#一、condition_variable(条件变量):线程间的 “等待 / 唤醒” 同步工具)
[二、unique_lock vs lock_guard:锁的灵活性对比](#二、unique_lock vs lock_guard:锁的灵活性对比)
[三、cv.wait () 和 cv.notify_one () 的核心行为](#三、cv.wait () 和 cv.notify_one () 的核心行为)
[main.cpp(单例模式 - 饿汉模式)](#main.cpp(单例模式 - 饿汉模式))
四、总结(关键点回顾)
[单例模式之懒汉模式 - 缺少线程板块代码](#单例模式之懒汉模式 - 缺少线程板块代码)[main.cpp(单例模式 - 懒汉模式)](#main.cpp(单例模式 - 懒汉模式))
[一、GetInstance 函数的线程安全:双重检查锁(Double-Checked Locking)的设计逻辑](#一、GetInstance 函数的线程安全:双重检查锁(Double-Checked Locking)的设计逻辑)
[二、DelInstance 函数设为 static 的原因](#二、DelInstance 函数设为 static 的原因)
[三、Gc 私有内部类的作用(单例的 "守护类")](#三、Gc 私有内部类的作用(单例的 “守护类”))
[四、static Gc _gc 能自动调用析构的原因](#四、static Gc _gc 能自动调用析构的原因)
[六、为什么 A::DelInstance () 能调用私有析构函数](#六、为什么 A::DelInstance () 能调用私有析构函数)
C++ 线程库的基本使用
main.cpp(thread 对象的基本使用)
#include <iostream> // 用于cout控制台输出
#include <thread> // C++11线程库核心头文件(thread类、this_thread命名空间)
#include <string> // string字符串类头文件
using namespace std; // 简化std::前缀,新手更易阅读
// 线程执行函数:循环输出线程ID、自定义字符串和循环变量
// begin:循环起始值,end:循环结束值,s:线程标识字符串
void Func(int begin, int end, const string& s)
{
// 循环遍历[begin, end)区间的整数
for (int i = begin; i < end; i++)
{
// this_thread::get_id():获取当前执行线程的唯一ID(类型为thread::id)
// 输出格式:线程ID + 自定义字符串 + 循环变量i
cout << this_thread::get_id() << s << " : " << i << endl;
}
}
int main()
{
// 1. 创建线程对象t1,绑定执行函数Func,并传递参数:10(begin)、100(end)、"线程1"(s)
// thread类构造时,会立即启动新线程执行Func函数
thread t1(Func, 10, 100, "线程1");
// 创建线程对象t2,执行Func函数,参数:50(begin)、100(end)、"线程2"(s)
thread t2(Func, 50, 100, "线程2");
// 2. thread类禁用拷贝构造:以下代码编译报错
// 原因:thread对象管理的是系统内核线程资源,拷贝会导致资源归属混乱,因此C++11显式禁用拷贝
// thread t3(t1); error
// 3. thread类支持移动构造/移动赋值:通过std::move转移线程资源所有权
// std::move(t1):将t1的线程资源所有权转移给t3,转移后t1变为"空线程"(joinable()返回false)
// thread t3(move(t1));
// 4. 使用lambda表达式创建线程(C++11+特性,更灵活的线程执行逻辑)
int n2 = 100; // 循环次数变量
string s = "线程3"; // 线程标识字符串
// 创建线程t4,执行lambda表达式(捕获n2和s的值,无参数)
thread t4([n2, s]() // [n2, s]:值捕获,lambda内使用n2和s的副本(避免线程间数据竞争)
{
// lambda内的循环逻辑:输出线程ID、标识字符串和循环变量
for (int i = 0; i < n2; i++)
{
cout << this_thread::get_id() << s << " : " << i << endl;
}
}
);
// 5. 等待线程执行完毕(join()):主线程阻塞,直到对应子线程执行完成
// 必须调用join()或detach(),否则线程对象析构时会调用std::terminate()终止程序
t1.join(); // 等待t1线程执行完毕
t2.join(); // 等待t2线程执行完毕
t4.join(); // 等待t4线程执行完毕
return 0;
}一、C++11 线程库的基本使用(结合代码拆解)
C++11 引入的<thread>库是对操作系统底层线程 API(如 Linux 的 pthread、Windows 的 CreateThread)的跨平台封装,核心目标是让开发者无需关注不同系统的线程 API 差异,用统一的语法创建和管理线程。代码中体现了线程库的核心使用场景:
1. 线程创建:thread对象构造即启动线程
// 普通函数作为线程执行体,传递3个参数
thread t1(Func, 10, 100, "线程1");
// Lambda表达式作为线程执行体(更灵活)
thread t4([n2, s](){ ... });thread是管理线程资源的 "智能对象":构造时会立即调用底层 API(如 pthread_create)创建系统内核线程,并让新线程执行指定的可调用对象(普通函数、Lambda、仿函数等);- 可调用对象的参数直接跟在函数名后(如
10, 100, "线程1"),无需手动封装,由thread库自动处理。
2. 线程的拷贝与移动:禁用拷贝,支持移动
// 编译报错:thread禁用拷贝构造(避免线程资源归属混乱)
// thread t3(t1);
// 合法:移动构造,将t1的线程资源所有权转移给t3,t1变为"空线程"
thread t3(move(t1));- 线程是 "唯一资源"(一个内核线程对应一个
thread对象),拷贝会导致 "多个对象管理同一个内核线程",因此 C++11 显式禁用thread的拷贝构造 / 赋值; - 移动语义(
std::move)可转移线程资源所有权,保证资源唯一归属。
3. 等待线程完成:join()的核心作用
t1.join(); // 主线程阻塞,直到t1线程执行完毕
t2.join();
t4.join();join():主线程暂停执行,等待子线程执行完成后再继续;- 必须调用
join()或detach()(分离线程):若thread对象析构时仍未调用,会触发std::terminate()终止程序(避免线程资源泄漏)。
4. 线程 ID 获取:this_thread::get_id()
cout << this_thread::get_id() << s << " : " << i << endl;this_thread是<thread>库的命名空间,get_id()返回当前执行线程的唯一标识(thread::id类型),用于区分不同线程。
二、thread构造函数的核心:万能引用 + 参数包(泛型模板)
thread能支持 "任意可调用对象 + 任意参数",核心依赖 C++11 的万能引用(Universal Reference) 和参数包(Variadic Templates) 特性,先明确两个核心概念:
1. 万能引用(Universal Reference)
-
定义 :仅当模板参数为
T且发生类型推导 时,T&&才是万能引用(否则是右值引用)。它的核心能力是:既能接收左值,也能接收右值,并通过std::forward实现完美转发(保持参数的左 / 右值属性)。 -
thread 构造中的应用 :
thread的构造函数是模板函数,简化原型如下:template <class F, class... Args> explicit thread(F&& f, Args&&... args);F&& f:万能引用,接收任意可调用对象(左值如普通函数名、右值如临时 Lambda);Args&&... args:参数包的万能引用,接收任意个数、任意类型的参数(如10, 100, "线程1")。
2. 参数包(Variadic Templates)
- 定义 :
class... Args(模板参数包)和Args&&... args(函数参数包)是 C++11 的 "可变参数模板",能承接任意个数、任意类型的参数(0 个或多个),解决了 "线程函数参数个数不确定" 的问题。 - 核心价值:无需为不同参数个数的线程函数写不同的封装逻辑,一套模板适配所有场景。
3. 万能引用 + 参数包的协作逻辑
代码中thread t1(Func, 10, 100, "线程1")的构造过程:
- 模板推导:
F推导为void(*)(int, int, const string&)(Func 的类型),Args推导为int, int, const string&; - 完美转发:
F&& f转发 Func,Args&&... args转发10, 100, "线程1",保证参数的左 / 右值属性不丢失; - 绑定执行:
thread库将可调用对象和参数包绑定,生成一个 "适配函数",供底层线程 API 调用。
三、thread封装pthread_create的细节(Linux 下)
Linux 系统中,thread的底层实现依赖 POSIX 线程库(pthread),核心是封装了pthread_create函数。先看pthread_create的原型和痛点:
// pthread_create原型(Linux)
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);1. pthread_create的核心痛点
- 线程函数必须是
void* (*)(void*)类型:只能接收一个void*参数,返回void*,限制极大; - 多参数需手动封装:若线程函数需要多个参数,需将参数封装成结构体,再强转为
void*传递; - 类型转换繁琐:参数和返回值都需强制类型转换,易出错且代码冗余。
2. thread的封装逻辑(屏蔽底层痛点)
thread通过 "泛型 + 万能引用 + 参数包" 封装了pthread_create的痛点,核心步骤:
- 参数封装 :将用户传入的可调用对象(如 Func)和参数包(10,100,"线程 1")绑定成一个 "无参数的可调用对象"(通过
std::bind或 lambda); - 类型适配 :将绑定后的可调用对象转换成
void* (*)(void*)类型的函数(符合pthread_create的要求); - 参数传递 :将封装后的可调用对象指针强转为
void*,作为pthread_create的第四个参数; - 执行与清理:新线程启动后,调用适配函数,解包参数并执行原可调用对象,执行完成后清理资源。
3. 封装后的价值:简化使用
对比pthread_create的繁琐写法(以调用 Func 为例):
// pthread_create调用Func的繁琐写法(仅示例)
struct Args { int begin; int end; string s; };
void* Func_wrap(void* arg) {
Args* p = (Args*)arg;
Func(p->begin, p->end, p->s);
delete p;
return nullptr;
}
int main() {
pthread_t tid;
Args* arg = new Args{10, 100, "线程1"};
pthread_create(&tid, nullptr, Func_wrap, (void*)arg);
pthread_join(tid, nullptr);
return 0;
}而 C++ thread仅需一行:thread t1(Func, 10, 100, "线程1");------ 万能引用 + 参数包隐藏了所有封装、类型转换的细节,让线程创建和调用普通函数一样简单。
四、为什么thread的泛型设计能简化使用?
- 支持任意可调用对象 :普通函数、Lambda(含捕获变量)、仿函数、成员函数都能作为线程执行体,而
pthread_create仅支持无捕获的 Lambda(或普通函数); - 支持任意参数个数 / 类型 :无需手动封装结构体,直接传递参数即可,
thread库自动处理参数的转发和封装; - 无强制类型转换 :模板推导自动匹配类型,避免
void*强转带来的错误; - 跨平台兼容 :Windows 下封装
CreateThread,Linux 下封装pthread_create,用户无需关注系统差异。
五、总结(关键点回顾)
- C++11
<thread>库是底层线程 API 的跨平台封装,核心用法:构造thread对象创建线程,调用join()等待线程完成; thread构造函数的核心是万能引用 + 参数包:万能引用实现可调用对象 / 参数的完美转发,参数包承接任意个数 / 类型的参数;- 封装
pthread_create的价值:屏蔽void* (*)(void*)函数类型限制、单参数限制、类型转换繁琐等痛点; - 简化使用的体现:无需手动封装参数、转换类型,直接传递任意可调用对象和参数,代码简洁且不易出错。
线程与互斥锁的基本使用
main.cpp(互斥锁)
#include <iostream> // 用于cout控制台输出
#include <thread> // C++11线程库头文件(thread类)
#include <mutex> // C++11互斥锁头文件(mutex类)
#include <functional> // 用于std::ref(包装引用)
using namespace std; // 简化std::前缀
// 线程函数:循环n次对共享变量rx进行自增操作,rm为保护共享变量的互斥锁
// n:循环次数,rx:共享变量的引用(需保护),rm:互斥锁的引用(用于加锁)
void AddX(int n, size_t& rx, mutex& rm)
{
// 循环n次执行自增操作
for (int i = 0; i < n; i++)
{
// 1. 加锁:获取互斥锁rm,若锁已被其他线程持有,则当前线程阻塞等待
// 加锁后进入临界区,确保同一时间只有一个线程操作共享变量rx
rm.lock();
// 临界区:操作共享变量rx(自增),必须加锁保护,否则会出现竞态条件(数据错乱)
rx++;
// 2. 解锁:释放互斥锁rm,让其他等待的线程可以获取锁
// 解锁必须与加锁一一对应,否则会导致死锁
rm.unlock();
}
}
int main()
{
// 共享变量x:多个线程会同时修改,需用互斥锁保护
size_t x = 0;
// 互斥锁m:用于保护共享变量x的原子操作
mutex m;
// 创建线程t1,执行AddX函数,传递参数:100(n)、ref(x)(x的引用)、ref(m)(m的引用)
// 关键:thread构造函数默认对参数做值拷贝,若要传递引用,必须用std::ref()包装
// 若直接传x/m(而非ref(x)/ref(m)),编译会报错:无法将拷贝的临时对象绑定到非const引用
thread t1(AddX, 100, ref(x), ref(m));
// 互斥锁mutex禁用拷贝构造:以下代码编译报错
// 原因:mutex管理的是系统内核锁资源,拷贝会导致资源归属混乱,因此C++11显式禁用拷贝
// mutex m2(m);
// 使用lambda表达式创建线程t2,避开ref传递的问题
int n2 = 200; // lambda的循环次数
// 创建线程t2,lambda表达式通过引用捕获x和m,值捕获n2
// 优势:lambda的引用捕获(&x、&m)可直接访问主线程的变量,无需std::ref包装
thread t2([&x, &m, n2]()
{
// 循环n2次执行自增操作
for (int i = 0; i < n2; i++)
{
// 加锁保护共享变量x
m.lock();
x++;
// 解锁释放锁资源
m.unlock();
}
}
);
// 等待线程t1执行完毕,主线程阻塞至t1结束
t1.join();
// 等待线程t2执行完毕,主线程阻塞至t2结束
t2.join();
// 输出最终的x值(正确结果应为100+200=300,加锁保证结果正确)
cout << x << endl;
return 0;
}一、核心问题:thread构造函数的参数传递机制(值拷贝 vs 引用)
thread类的构造函数有一个关键设计规则:默认对所有传入的参数进行 "值拷贝" ,而非直接传递引用。这个规则的初衷是避免 "悬垂引用"(比如主线程变量提前销毁,子线程引用失效),但在 "多线程修改主线程共享变量" 的场景下,会引发致命问题 ------ 这也是必须用std::ref的核心原因。
1. 不使用ref的错误逻辑(以传递x为例)
如果直接写:
// 错误写法:未用ref包装x和m
thread t1(AddX, 100, x, m);实际执行过程:① thread构造函数接收到主线程的x后,会拷贝一份临时的size_t变量 (记为temp_x),存储在thread对象内部;② thread构造函数将temp_x的地址传递给AddX的参数size_t& rx;③ 此时rx引用的是 **thread内部的temp_x**,而非主线程的x------ 引发两个问题:
- 编译错误 :C++ 规定 "非 const 的左值引用(
size_t&)不能绑定到临时对象(temp_x)",直接报编译错; - 逻辑错误 :即使强行绕过编译(比如用
const引用),AddX中修改的是temp_x,主线程的x完全不受影响,最终x的结果还是 0,失去多线程修改共享变量的意义。
同理,mutex m的传递:mutex类禁用了拷贝构造函数 (代码注释中也提到),直接传m会触发 "无法拷贝 mutex" 的编译错误 ------ 必须传递m的引用,而传递引用就需要解决thread构造函数 "值拷贝" 的问题。
2. std::ref的核心作用:包装引用,传递 "真实引用"
std::ref是 C++ 的引用包装器 ,它的核心价值是:将普通变量包装成 "可拷贝的引用类型",让thread构造函数传递的不是变量的拷贝,而是变量的真实引用。
当写:
thread t1(AddX, 100, ref(x), ref(m));执行过程:① std::ref(x)生成一个reference_wrapper<size_t>类型的对象(可拷贝),这个对象内部保存的是主线程x的地址 ;② thread构造函数拷贝这个reference_wrapper对象(而非拷贝x),然后将其解包,传递给AddX的size_t& rx;③ 此时rx引用的是主线程的x ,rm引用的是主线程的m ------ 既解决了编译错误,又能让AddX真正修改主线程的共享变量x。
二、更简洁的替代方案:Lambda 表达式的引用捕获
Lambda 表达式可以直接通过 "引用捕获" 获取主线程变量的引用,完全避开std::ref的使用,核心逻辑:
thread t2([&x, &m, n2]() {
for (int i = 0; i < n2; i++) {
m.lock();
x++;
m.unlock();
}
});关键解析:
① Lambda 的捕获列表[&x, &m, n2]:
&x:引用捕获 主线程的x,Lambda 内部的x直接指向主线程的x;&m:引用捕获 主线程的m,Lambda 内部的m直接指向主线程的m;n2:值捕获 ,拷贝一份n2到 Lambda 内部(无需修改,值拷贝更安全);②thread构造函数只需要拷贝 Lambda 对象(Lambda 对象本身很小,且可拷贝),而 Lambda 内部的&x、&m已经绑定了主线程的变量 ------ 相当于 "绕开了thread构造函数的参数值拷贝规则",直接通过 Lambda 的捕获机制拿到了共享变量的引用;③ 优势:代码更简洁,无需记忆std::ref的使用场景,是多线程传递共享变量的推荐写法。
三、补充:mutex禁用拷贝的原因
代码中mutex m2(m);编译报错,核心原因是:mutex类管理的是操作系统内核级的锁资源 (比如 Linux 的pthread_mutex_t),每个mutex对象对应一个唯一的内核锁。如果允许拷贝,会导致多个mutex对象对应同一个内核锁,解锁 / 加锁操作会混乱(比如一个线程解锁另一个线程加的锁),引发死锁或竞态条件。因此 C++11 显式禁用了mutex的拷贝构造和赋值重载,必须通过引用传递。
总结(关键点回顾)
thread构造函数默认值拷贝 参数:不使用ref时,AddX的引用参数绑定的是thread内部的临时拷贝,而非主线程变量,导致编译错误 / 修改无效;std::ref的作用:包装变量为 "可拷贝的引用类型",让thread传递真实引用,绑定到主线程的x和m;- Lambda 的优势:通过引用捕获(
&x、&m)直接绑定主线程变量,无需std::ref,代码更简洁; mutex必须传引用:因为mutex禁用拷贝,只能通过ref或 Lambda 引用捕获传递。
封装互斥锁避免死锁(RAII)
main.cpp(封装锁 ------ 类似智能指针)
#include <iostream> // 控制台输出头文件
#include <thread> // C++11线程库头文件
#include <mutex> // 互斥锁头文件
using namespace std; // 简化std::前缀
// 通用模板类LockGuard:基于RAII机制封装任意锁类型(如mutex、spinlock等),自动管理锁的加解锁
// 模板参数Lock:锁类型(需支持lock()和unlock()成员函数,如std::mutex)
template<class Lock>
class LockGuard
{
public:
// 构造函数:资源获取即初始化(RAII核心)
// 参数lock:传入锁的引用(避免拷贝,mutex禁用拷贝),构造时自动加锁
LockGuard(Lock& lock)
: _lock(lock) // 保存锁的引用,关联到外部的锁对象
{
_lock.lock(); // 构造对象时自动调用lock()加锁,进入临界区前必加锁
}
// 析构函数:资源自动释放(RAII核心)
// 栈对象生命周期结束时(如出作用域),自动调用unlock()解锁,无需手动调用
~LockGuard()
{
_lock.unlock(); // 析构时自动解锁,确保锁一定会被释放
}
private:
// 私有成员:锁的引用(必须用引用,避免拷贝锁对象,且保证操作的是外部的同一个锁)
Lock& _lock;
// 禁用拷贝构造和赋值:避免LockGuard对象拷贝导致锁被重复管理(可选,增强安全性)
LockGuard(const LockGuard&) = delete;
LockGuard& operator=(const LockGuard&) = delete;
};
int main()
{
int x = 0; // 多线程共享变量,需锁保护
int n = 100; // 每个线程的循环次数
mutex m; // 保护共享变量x的互斥锁
// 创建线程t1:循环n次对x自增,使用LockGuard管理锁
thread t1([&x, &m, n]()
{
for (int i = 0; i < n; i++)
{
// 创建LockGuard栈对象lg:构造时自动调用m.lock()加锁
// lg是栈对象,作用域为当前for循环体,出循环体时自动析构
LockGuard<mutex> lg(m);
// 临界区:操作共享变量x,无需手动加解锁
// 即使此处抛出异常(如x++改为复杂逻辑触发异常),lg也会析构解锁
x++;
// 出for循环体时,lg的生命周期结束,析构函数自动调用m.unlock()解锁
}
}
);
// 创建线程t2:逻辑同t1,共享同一个锁m,保证临界区互斥
thread t2([&x, &m, n]()
{
for (int i = 0; i < n; i++)
{
// 自动加锁,无需手动调用m.lock()
LockGuard<mutex> lg(m);
x++;
// 自动解锁,无需手动调用m.unlock()
}
}
);
// 等待两个线程执行完毕
t1.join();
t2.join();
// 输出最终x值(加锁保护下必为200,无竞态条件)
cout << x << endl;
return 0;
}一、先明确核心痛点:手动管理锁的致命问题
在没有封装锁之前,手动调用lock()/unlock()管理互斥锁存在两个核心风险,也是LockGuard要解决的核心问题:
- 漏解锁 / 解锁不及时 :比如代码中途
return、抛出异常,导致unlock()无法执行 ------ 锁永远被持有,其他线程阻塞等待,最终引发死锁; - 人为操作失误 :加锁和解锁必须一一对应,手动写
lock()/unlock()时,容易多解锁、少解锁,或解锁位置写错,破坏锁的互斥性。
而LockGuard的设计思路和智能指针(如 shared_ptr)完全一致:基于 RAII(资源获取即初始化)思想,将 "锁的获取(加锁)" 绑定到对象构造,"锁的释放(解锁)" 绑定到对象析构,让编译器自动管理锁的生命周期,彻底规避手动操作的风险。
二、LockGuard 的核心实现:RAII 封装锁(类比智能指针)
智能指针的核心是 "构造获取内存,析构释放内存";LockGuard的核心是 "构造获取锁(加锁),析构释放锁(解锁)",二者都是 RAII 思想的典型应用。以下结合代码拆解:
1. 模板设计:适配任意锁类型(通用化)
template<class Lock>
class LockGuard- 模板参数
Lock:支持任意符合 "有lock()和unlock()成员函数" 的锁类型(如std::mutex、自旋锁spinlock等),和shared_ptr的模板参数T(支持任意内存类型)思路一致,实现通用化封装。
2. 构造函数:自动加锁(RAII - 获取资源)
LockGuard(Lock& lock)
: _lock(lock) // 保存锁的引用(关键:操作外部的同一个锁)
{
_lock.lock(); // 构造时自动加锁,进入临界区前必加锁
}- 为什么用引用 保存锁:
std::mutex禁用拷贝构造(和智能指针禁用拷贝同理),必须通过引用关联到外部的锁对象,保证操作的是 "同一个锁"; - 自动加锁:创建
LockGuard对象的瞬间,就完成加锁,无需手动调用lock(),避免 "忘加锁" 的问题。
3. 析构函数:自动解锁(RAII - 释放资源)
~LockGuard()
{
_lock.unlock(); // 析构时自动解锁,锁一定会被释放
}- 核心保障:
LockGuard是栈对象 (如代码中LockGuard<mutex> lg(m);),栈对象的生命周期由作用域决定 ------ 只要出作用域(比如 for 循环结束、函数返回、抛出异常),析构函数一定会执行,解锁操作一定会触发。- 对比智能指针:
shared_ptr是栈对象,析构时自动释放内存;LockGuard是栈对象,析构时自动释放锁,逻辑完全一致。
- 对比智能指针:
4. 禁用拷贝:避免锁被重复管理(增强安全性)
LockGuard(const LockGuard&) = delete;
LockGuard& operator=(const LockGuard&) = delete;- 和
shared_ptr/thread/mutex禁用拷贝同理:如果允许拷贝,会导致多个LockGuard对象管理同一个锁,可能出现 "重复解锁"(一个LockGuard析构解锁后,另一个析构时再次解锁),引发未定义行为;禁用拷贝后,一个锁只能被一个LockGuard管理,保证加解锁的唯一性。
三、LockGuard 如何解决 "死锁 / 异常导致的锁未释放" 问题
1. 解决 "异常导致的锁未释放"(核心优势)
假设手动加解锁时,临界区抛出异常:
// 手动加解锁的错误示例(异常导致死锁)
void AddX(int n, int& x, mutex& m) {
for (int i = 0; i < n; i++) {
m.lock();
x++;
throw runtime_error("异常"); // 抛出异常,unlock()无法执行
m.unlock(); // 永远执行不到,锁被永久持有→死锁
}
}而用LockGuard时:
void AddX(int n, int& x, mutex& m) {
for (int i = 0; i < n; i++) {
LockGuard<mutex> lg(m); // 构造加锁
x++;
throw runtime_error("异常"); // 抛出异常
// 无需unlock(),异常触发栈展开,lg析构→自动解锁
}
}- 栈展开(Stack Unwinding):C++ 异常抛出时,会销毁当前作用域的所有栈对象 ------
lg作为栈对象,析构函数会被调用,unlock()执行,锁被释放,不会死锁。
2. 解决 "漏解锁 / 解锁位置错误" 问题
手动加解锁时,容易因代码逻辑(如return)导致漏解锁:
// 手动加解锁:return导致漏解锁
void AddX(int n, int& x, mutex& m) {
for (int i = 0; i < n; i++) {
m.lock();
if (x > 50) return; // 提前return,unlock()执行不到→死锁
x++;
m.unlock();
}
}用LockGuard时,即使return,lg的析构函数仍会执行,自动解锁,彻底避免漏解锁。
3. 简化代码:专注业务逻辑
手动加解锁需要写m.lock()/m.unlock(),且要保证一一对应;用LockGuard后,只需创建栈对象,临界区无需关注锁的管理,代码更简洁,也减少了人为失误的可能。
四、代码执行流程(验证 LockGuard 的作用)
thread t1([&x, &m, n]() {
for (int i = 0; i < n; i++) {
LockGuard<mutex> lg(m); // 构造→m.lock()
x++; // 临界区(互斥访问x)
} // 出for循环→lg析构→m.unlock()
});- 每次循环创建
lg:构造时调用m.lock()加锁,确保同一时间只有一个线程进入临界区; - 循环结束:
lg出作用域,析构时调用m.unlock()解锁,其他线程可获取锁; - 即使
x++抛出异常:lg析构仍会解锁,不会死锁; - 最终
x的结果必为 200(100+100),无竞态条件,也无死锁风险。
总结(关键点回顾)
- 核心思想 :
LockGuard和智能指针同源(RAII)------ 构造获取资源(锁 / 内存),析构释放资源(解锁 / 内存),让编译器自动管理生命周期; - 解决的核心问题 :
- 异常安全:即使临界区抛异常,栈对象析构仍会解锁,避免死锁;
- 避免漏解锁:无需手动写
unlock(),彻底规避人为操作失误;
- 设计关键 :
- 用引用保存锁(避免拷贝,操作外部同一个锁);
- 禁用拷贝(避免重复管理锁);
- 模板化设计(适配任意锁类型,通用化)。
多线程done(两个线程,奇偶数交替输出)
main.cpp(交替打印奇偶数)
#include <iostream> // 控制台输出头文件
#include <thread> // C++11线程库头文件
#include <mutex> // 互斥锁头文件
#include <condition_variable> // 条件变量头文件
using namespace std; // 简化std::前缀
// 定义宏NUM:每个线程需要打印的次数(总共打印20个数:1-20)
#define NUM 10
int main()
{
mutex m; // 互斥锁:保护共享变量(x、flag)的原子操作
int x = 1; // 共享变量:要打印的数字,初始为1(第一个奇数)
bool flag = false; // 同步标志位:控制线程交替执行
// false:线程1(奇数)执行;true:线程2(偶数)执行
condition_variable cv; // 条件变量:实现线程间的等待/唤醒,配合互斥锁使用
// 创建线程t1:负责打印奇数(1、3、5...19)
thread t1([&]() // 捕获所有外部变量的引用(x、m、flag、cv)
{
// 循环NUM次,打印NUM个奇数
for (int i = 0; i < NUM; i++)
{
// 创建unique_lock对象:相比lock_guard,支持wait()时自动释放锁,是条件变量的必需搭配
// 构造时自动加锁,保护临界区(flag判断、x操作)
unique_lock<mutex> lock(m);
// 若flag为true(此时该线程1不该执行,该线程2执行),则等待
while (flag)
{
// cv.wait(lock):核心操作,分两步:
// 1. 自动释放锁m,让线程2能获取锁执行;
// 2. 阻塞当前线程t1,直到被notify_one()唤醒,唤醒后重新获取锁m并继续执行
cv.wait(lock);
}
// 临界区:打印当前线程ID和奇数,x自增(准备下一个数)
cout << this_thread::get_id() << ":" << x++ << endl;
// 切换标志位:设为true,让线程2执行(打印偶数)
flag = !flag;
// 唤醒等待在cv上的一个线程(此处唤醒线程2)
// 通知线程2:可以执行打印偶数的操作了
cv.notify_one();
}
}
);
// 创建线程t2:负责打印偶数(2、4、6...20)
thread t2([&]() // 捕获所有外部变量的引用
{
// 循环NUM次,打印NUM个偶数
for (int i = 0; i < NUM; i++)
{
// 创建unique_lock对象,自动加锁
unique_lock<mutex> lock(m);
// 若flag为false(此时该线程2不该执行,该线程1执行),则等待
while (!flag)
{
// wait前自动释放锁m,让线程1能执行;被唤醒后重新获取锁
cv.wait(lock);
}
// 临界区:打印当前线程ID和偶数,x自增
cout << this_thread::get_id() << ":" << x++ << endl;
// 切换标志位:设为false,让线程1执行(打印下一个奇数)
flag = !flag;
// 唤醒等待在cv上的一个线程(此处唤醒线程1)
cv.notify_one();
}
}
);
// 等待线程t1执行完毕
t1.join();
// 等待线程t2执行完毕
t2.join();
return 0;
}一、condition_variable(条件变量):线程间的 "等待 / 唤醒" 同步工具
1. 核心定义
condition_variable是 C++11 封装的线程同步原语,核心作用是:让一个 / 多个线程等待某个 "条件满足",直到其他线程通知(唤醒)它 ------ 解决了 "线程轮询检查条件(浪费 CPU)" 的问题,实现高效的线程间同步。
2. 底层实现(Linux 下)
condition_variable底层封装了 POSIX 线程库的pthread_cond_t(条件变量)和pthread_cond_wait/pthread_cond_signal等函数:
cv.wait(lock)→ 封装pthread_cond_wait(&cond, &mutex);cv.notify_one()→ 封装pthread_cond_signal(&cond);cv.notify_all()→ 封装pthread_cond_broadcast(&cond);C++ 封装的价值:跨平台(Windows 下封装CONDITION_VARIABLE),无需关注系统底层 API 差异,且结合 C++ 的锁机制(如unique_lock)更安全。
3. 核心依赖:必须配合互斥锁使用
条件变量本身不保证 "条件判断的原子性",必须和互斥锁(mutex)搭配:
- 条件(如
flag)是共享变量,需锁保护; wait()/notify_one()的执行依赖锁的释放 / 重新获取,保证同步逻辑的正确性。
二、unique_lock vs lock_guard:锁的灵活性对比
两者都是基于 RAII 的锁封装,但核心差异是灵活性,以下是关键对比:
| 特性 | lock_guard | unique_lock |
|---|---|---|
| 核心定位 | 简单 RAII 锁,自动加解锁 | 灵活 RAII 锁,支持手动加解锁 |
| 手动解锁 | 不支持(仅析构解锁) | 支持unlock()/lock()手动控制 |
| 配合条件变量 wait | 不支持(无法手动释放锁) | 支持(wait () 时自动释放锁,唤醒后重新加锁) |
| 性能 / 开销 | 轻量(无额外状态) | 稍重(维护锁的状态,如是否持有锁) |
| 适用场景 | 简单临界区(无需手动控锁) | 复杂同步(如条件变量、手动控锁) |
为什么这里必须用 unique_lock?
cv.wait(lock)的核心操作需要 "先释放锁→阻塞→唤醒后重新获取锁",而lock_guard仅支持 "构造加锁、析构解锁",无法手动释放锁 ------ 如果用lock_guard,wait()时无法释放锁,会导致:
- 线程阻塞时仍持有锁,其他线程永远拿不到锁,最终死锁;
unique_lock的灵活性刚好满足wait()的需求:wait()调用时会自动释放锁,唤醒后又自动重新加锁,保证同步逻辑的正确性。
三、cv.wait () 和 cv.notify_one () 的核心行为
1. cv.wait (unique_lock& lock)(核心操作,分三步)
while (flag) {
cv.wait(lock);
}- 第一步 :自动释放
lock关联的互斥锁(m),让其他线程能获取锁执行; - 第二步 :阻塞当前线程(如 t1),直到被
notify_one()/notify_all()唤醒; - 第三步 :被唤醒后,重新获取互斥锁
m(若锁被其他线程持有则阻塞等待),然后重新检查while条件(而非if)------ 这是为了处理 "虚假唤醒"(系统层面的误唤醒,需重新验证条件)。
⚠️ 关键:必须用while判断条件,而非if!如果用if,虚假唤醒会导致线程跳过条件检查直接执行临界区,破坏交替逻辑。
2. cv.notify_one ()(唤醒操作)
cv.notify_one();- 唤醒一个 等待在当前条件变量(
cv)上的线程(如 t1 唤醒 t2,t2 唤醒 t1); - 注意:
notify_one()仅 "通知",不会释放锁 ------ 被唤醒的线程需要等当前线程释放锁后,才能重新获取锁继续执行。
四、交替打印的核心逻辑(两种场景验证)
先明确初始状态:x=1(第一个奇数)、flag=false(奇数线程 t1 执行)、m未加锁、cv无等待线程。
场景 1:假设 t1 先运行(打印奇数的线程先执行)
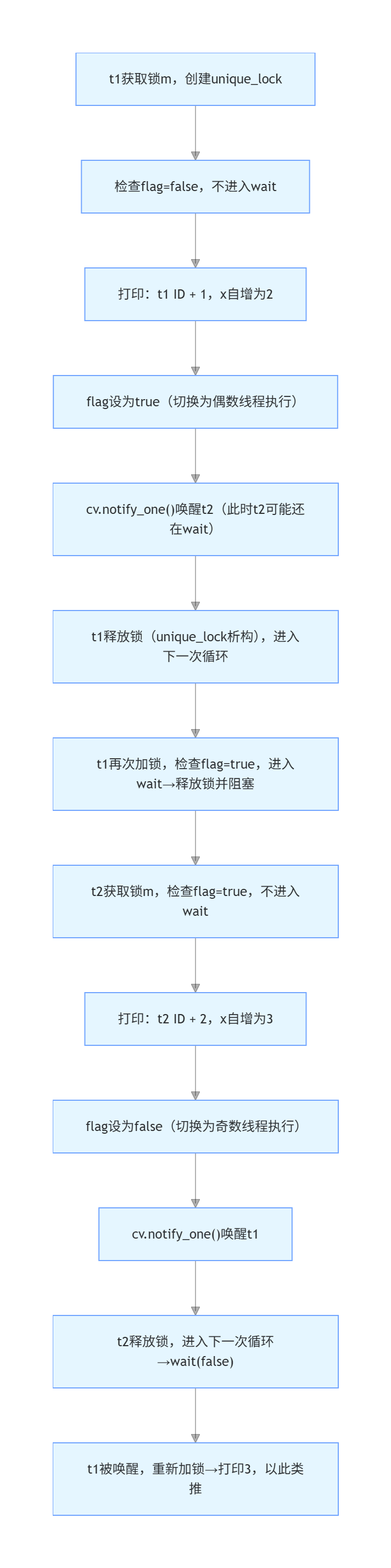
- 核心:t1 执行完奇数后,切换 flag 并唤醒 t2,自己进入 wait;t2 执行完偶数后,切换 flag 并唤醒 t1,自己进入 wait,形成交替。
场景 2:假设 t2 先运行(打印偶数的线程先执行)
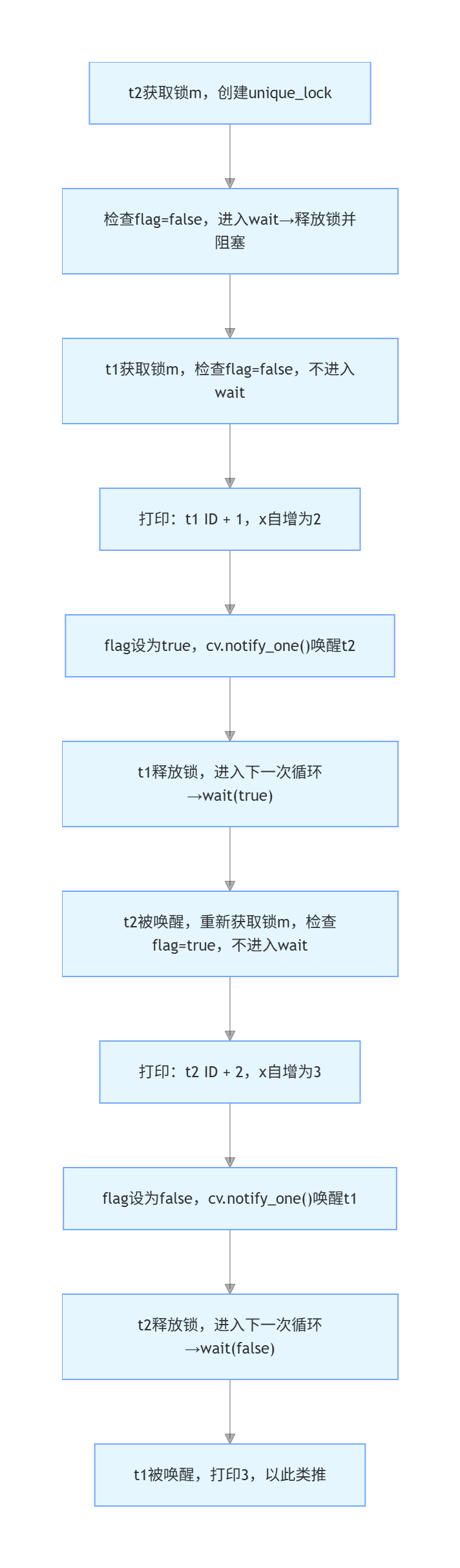
- 核心:t2 先运行时,因 flag=false 直接进入 wait 并释放锁,t1 顺利获取锁执行奇数打印;t1 执行完后唤醒 t2,t2 此时 flag=true,执行偶数打印,后续逻辑和场景 1 一致,仍能保证交替。
关键结论:无论 t1/t2 谁先运行,最终都能交替
- t1 先运行:主动切换 flag 并唤醒 t2,自己等待;
- t2 先运行:因条件不满足直接等待,释放锁让 t1 执行,t1 执行后唤醒 t2;
- 条件变量 + flag 的组合,保证了 "谁先运行都不影响交替逻辑"------ 本质是通过 "等待 - 唤醒" 让线程按条件执行,而非依赖执行顺序。
五、总结(关键点回顾)
condition_variable:封装pthread_cond_t,实现线程间 "等待 - 唤醒" 同步,必须配合互斥锁使用;unique_lockvslock_guard:lock_guard:简单 RAII,自动加解锁,无灵活性;unique_lock:灵活 RAII,支持手动控锁,是cv.wait()的必需搭配;
cv.wait():释放锁→阻塞→唤醒后重新加锁 + 条件检查(必须用 while);cv.notify_one():唤醒一个等待线程,仅通知不释放锁;- 交替逻辑:无论 t1/t2 先运行,
flag+wait+notify的组合都会让线程按 "奇数→偶数→奇数" 的顺序执行,保证交替打印。
单例模式之饿汉模式
main.cpp(单例模式 - 饿汉模式)
// 补充编译所需的头文件(必须)
#include <iostream> // cout 控制台输出
#include <string> // string 字符串类型
#include <map> // map 键值对容器
using namespace std; // 简化std::前缀,新手更易阅读
// 饿汉模式单例类A:程序启动时就创建唯一实例,线程安全(静态成员初始化天然线程安全)
class A
{
public:
// 核心:获取单例实例的静态方法(全局唯一入口)
// 返回值:A& 实例的引用(避免拷贝,保证全局唯一)
static A& GetInstance()
{
// 返回类内静态成员_inst(程序启动时已初始化,全局唯一)
return _inst;
}
// 业务方法:向单例的map中添加键值对
// k:键(const& 避免拷贝,提高效率),v:值(const& 同理)
void Add(const string& k, const string& v)
{
_dict[k] = v; // 向map容器中插入/更新键值对
}
// 业务方法:打印map中的所有键值对
void Print()
{
// 遍历map容器(范围for循环)
for (auto& kv : _dict)
{
// kv.first:键,kv.second:值
cout << kv.first << ":" << kv.second << endl;
}
}
private:
// 1. 私有化默认构造函数:禁止外部通过 A a; 创建实例
// 饿汉模式的核心:外部无法手动构造对象,只能通过GetInstance获取唯一实例
A()
{}
// 2. 私有化并删除拷贝构造函数:禁止外部拷贝实例(A a = A::GetInstance(); 编译报错)
// = delete:C++11特性,显式禁用该函数
A(const A& aa) = delete;
// 3. 私有化并删除赋值重载函数:禁止外部赋值实例(A a; a = A::GetInstance(); 编译报错)
A& operator=(const A& aa) = delete;
// 成员变量:存储键值对的map(单例的业务数据,全局唯一)
map<string, string> _dict;
// 核心:静态成员变量(类内声明),存储唯一的单例实例
// 静态成员属于类,而非对象,程序启动时(main函数执行前)就初始化,全局唯一
static A _inst;
};
// 静态成员变量(类外定义):饿汉模式的关键
// 程序启动时,全局区初始化该静态对象,此时还未进入main函数,且初始化过程天然线程安全
A A::_inst;
// 主函数:测试饿汉模式单例的使用
int main()
{
// 通过GetInstance()获取唯一实例,调用Add方法添加键值对
// 多次调用GetInstance(),返回的都是同一个_inst实例
A::GetInstance().Add("sort", "排序");
A::GetInstance().Add("left", "左边");
A::GetInstance().Add("right", "右边");
// 调用Print方法,打印单例中存储的所有键值对
A::GetInstance().Print();
return 0;
}一、单例模式的核心定义
单例模式是创建型设计模式 的一种,核心目标是:保证一个类在整个程序生命周期中只能创建一个对象(实例),并提供一个全局唯一的访问入口,让所有程序模块共享这个唯一实例。
这种模式适用于 "全局唯一资源管理" 场景(如配置文件管理器、日志管理器、连接池)------ 避免多次创建对象导致资源冲突(如重复打开配置文件)、内存浪费,同时保证所有模块访问的是同一套数据。
二、饿汉模式的核心实现逻辑(结合代码拆解)
饿汉模式的核心特点是:程序启动时(main 函数执行前)就创建好唯一实例,而非 "用到时才创建"(懒汉模式)。代码中通过 "私有化构造 + 静态成员 + 静态访问函数" 实现,以下逐点解释:
1. 为什么要私有化构造、拷贝构造、赋值重载?(单例的核心保障)
单例的核心是 "只能创建一个对象",必须禁止外部通过常规方式创建 / 拷贝对象,因此需要私有化并禁用这些函数:
// 1. 私有化默认构造函数:禁止外部通过 A a; 创建实例
A() {}
// 2. 私有化并删除拷贝构造:禁止外部拷贝实例(A a = A::GetInstance(); 编译报错)
A(const A& aa) = delete;
// 3. 私有化并删除赋值重载:禁止外部赋值实例(A a; a = A::GetInstance(); 编译报错)
A& operator=(const A& aa) = delete;- 默认构造私有化 :如果构造函数是 public,外部可以直接
A a;创建任意多个对象,违背 "单例" 核心;私有化后,只有类内部能调用构造函数创建对象,外部无法手动构造。 - 拷贝构造 / 赋值重载删除 :即使外部拿到了单例实例的引用(如
A& ref = A::GetInstance();),也无法通过A a = ref;或a = ref;拷贝 / 赋值出新对象,彻底杜绝 "多实例" 可能。
2. static A _inst;:类内静态成员的本质与声明 / 定义规则
// 类内声明:静态成员变量(属于类,而非对象)
static A _inst;
// 类外定义:程序启动时初始化该静态对象
A A::_inst;- 本质 :
_inst是一个全局静态变量 ,只是 "放在类的作用域内"(通过A::_inst访问)。全局静态变量的特性是:程序启动时(main 函数执行前)在全局区初始化,生命周期贯穿整个程序,且只有一份(全局唯一)。 - 为什么要 "类内声明 + 类外定义" :
- C++ 语法规定:类内的静态成员变量只是 "声明"(告诉编译器有这个变量),必须在类外 "定义"(分配内存并初始化),否则会报 "未定义的引用" 错误;
- 类外定义
A A::_inst;时,会调用 A 的私有化构造函数(只有类内部能调用),创建唯一的实例 ------ 这也是为什么要把构造函数私有化:只有类内的静态成员初始化时能调用,外部无法调用。
3. 为什么static A& GetInstance()必须是静态成员函数?
static A& GetInstance()
{
return _inst; // 返回唯一实例的引用
}- 核心原因:静态成员函数属于 "类本身",无需创建对象即可调用(通过
类名::函数名);而非静态成员函数属于 "对象",必须先创建对象才能调用 ------ 但单例模式禁止外部创建对象,因此必须用静态函数作为 "全局访问入口"。 - 补充:返回值用
A&(引用)而非A(值),是为了避免返回时拷贝出新对象(进一步保证单例);用引用也能直接修改实例的成员(如调用Add方法)。
4. 为什么必须通过A::GetInstance().Add(...)访问成员方法?
A::GetInstance().Add("sort", "排序");拆解这个调用的逻辑:
A::GetInstance():通过类名调用静态函数,获取唯一实例的引用(A&);.Add(...):通过实例引用调用非静态成员方法(Add/Print是操作实例数据的业务方法,必须通过实例调用)。
如果直接写A::Add(...)会报错 ------ 因为Add是非静态成员方法 ,必须绑定到具体实例才能调用;而单例模式下唯一的实例只能通过GetInstance()获取,因此必须通过这种 "静态函数获取实例 + 实例调用方法" 的方式访问。
三、饿汉模式的优缺点(用户指定要点)
1. 优点:实现简单,天然线程安全
- 实现简单 :无需考虑 "懒汉模式" 的线程安全问题(如多线程同时调用
GetInstance导致创建多个实例),仅需私有化构造 + 静态成员 + 静态访问函数,代码量少,新手易理解; - 天然线程安全 :静态成员
_inst在程序启动时(main 前)由编译器初始化,这个过程是单线程的,不会出现多线程竞争创建实例的问题。
2. 缺点:启动慢 + 无法控制实例初始化顺序
- 缺点 1:进程启动变慢 饿汉模式的实例在
main函数执行前就创建完成,如果程序中有多个饿汉单例类(如配置管理器、日志管理器、连接池),这些实例会在程序启动时逐个初始化 ------ 初始化逻辑复杂(如加载配置文件、建立数据库连接)时,会导致程序启动时间变长,甚至出现 "一直卡在启动阶段,进不到 main 函数" 的情况。 - 缺点 2:无法控制实例初始化顺序C++ 没有规定 "多个全局静态变量(饿汉单例的_inst)" 的初始化顺序 ------ 如果单例 A 的初始化依赖单例 B,但编译器先初始化 A、后初始化 B,会导致 A 初始化时 B 还未创建,出现 "空指针 / 未初始化" 的错误,而饿汉模式无法手动控制这个顺序。
四、总结(关键点回顾)
- 单例模式核心:保证类只有一个实例,提供全局访问入口;
- 饿汉模式核心:main 前创建唯一实例,通过 "私有化构造 + 静态成员 + 静态访问函数" 实现;
- 关键语法:
- 构造 / 拷贝 / 赋值私有化:禁止外部创建 / 拷贝实例;
- 静态成员
_inst:类内声明 + 类外定义,本质是全局静态变量,唯一实例; - 静态
GetInstance:无需对象即可调用,作为全局访问入口;
- 饿汉模式特点:实现简单、线程安全,但启动慢、无法控制初始化顺序。
单例模式之懒汉模式 - 缺少线程板块代码
main.cpp(单例模式 - 懒汉模式)
#include <iostream> // 控制台输出头文件
#include <mutex> // 互斥锁头文件
#include <map> // map容器头文件
#include <string> // string字符串头文件
#include <memory> // unique_lock所需头文件
using namespace std; // 简化std::前缀
// 线程安全的懒汉式单例类A:全局唯一实例,存储键值对字典并支持自动/手动释放
class A
{
public:
// 静态成员函数:获取类A的唯一实例(核心:双检查锁保证线程安全+懒加载)
static A* GetInstance()
{
// 第一层检查:双检查锁(DCL)的外层判断
// 作用:避免实例创建后,每次调用GetInstance都加解锁(减少无意义的锁开销)
if (_inst == nullptr)
{
// 加锁保护:实例创建阶段(new A())的线程安全,防止多个线程同时new
// unique_lock支持自动加解锁,比lock_guard灵活(此处仅需基础加解锁,也可用lock_guard)
unique_lock<mutex> lock(_mtx);
// 第二层检查:双检查锁的内层判断
// 作用:即使多个线程突破外层检查,也只有一个线程能创建实例(避免重复new)
if (_inst == nullptr)
{
_inst = new A(); // 懒加载:第一次调用时才创建实例(懒汉式核心)
}
}
return _inst; // 返回唯一实例的指针
}
// 成员函数:向单例的字典中添加键值对
void Add(const string& k, const string& v)
{
_dict[k] = v; // _dict是单例的成员,全局唯一,所有调用都操作同一个字典
}
// 成员函数:打印字典中所有键值对
void Print()
{
// 遍历map容器,输出每个键值对
for (auto& kv : _dict)
{
cout << kv.first << ":" << kv.second << endl;
}
}
// 静态成员函数:手动释放单例实例(支持提前释放资源)
static void DelInstance()
{
// 判空:避免重复释放导致野指针/崩溃
if (_inst != nullptr)
{
delete _inst; // 释放实例内存,触发A的析构函数(执行资源清理)
_inst = nullptr; // 置空指针,避免悬空指针
}
}
private:
// 私有化构造函数:禁止外部通过A()创建对象(单例的核心约束)
// 确保只能通过GetInstance()获取唯一实例
A()
{
}
// 私有化析构函数:禁止外部通过delete直接释放实例(必须通过DelInstance()释放)
// 析构时可执行资源清理(如文件写入、数据库连接关闭等)
~A()
{
cout << "数据写入文件等操作" << endl; // 模拟析构时的资源清理逻辑
}
// 私有化拷贝构造函数并删除:禁止外部拷贝单例实例(=delete表示禁用该函数)
A(const A& aa) = delete;
// 私有化赋值运算符并删除:禁止外部赋值单例实例
A& operator=(const A& aa) = delete;
// 成员变量:存储键值对的字典(全局唯一,所有单例调用共享)
map<string, string> _dict;
// 静态成员变量:指向类A唯一实例的指针(懒汉式初始化为nullptr)
static A* _inst;
// 嵌套GC类(垃圾回收类):充当单例的"最后一道闸口",确保实例最终被释放
// 原理:static成员_gc在main函数结束后自动析构,触发~Gc()调用DelInstance()
class Gc
{
public:
// GC类的析构函数:调用DelInstance()释放单例
~Gc()
{
DelInstance();
}
};
// 静态GC对象:全局生命周期,main结束后析构
static Gc _gc;
// 静态互斥锁:保护GetInstance()中new A()的线程安全
static mutex _mtx;
};
// 静态成员初始化:单例实例指针初始化为nullptr(懒汉式,初始不创建实例)
A* A::_inst = nullptr;
// 静态GC对象初始化:触发GC类的构造(无实际逻辑,仅占内存,等待析构)
A::Gc A::_gc;
// 静态互斥锁初始化:默认构造,用于GetInstance()的加锁保护
mutex A::_mtx;
int main()
{
// 通过单例的GetInstance()获取实例,调用Add添加键值对
A::GetInstance()->Add("sort", "排序");
A::GetInstance()->Add("left", "左边");
A::GetInstance()->Add("right", "右边");
// 打印单例字典中的所有键值对
A::GetInstance()->Print();
// 手动释放单例实例:触发A的析构函数(打印"数据写入文件等操作")
A::DelInstance();
cout << "提前手动释放" << endl;
// 说明:若未手动调用DelInstance(),main结束后GC类的_gc析构,会自动调用DelInstance();
// 若已手动释放,DelInstance()中_inst已置空,GC析构时再次调用也不会重复释放(判空保护)
return 0;
}一、GetInstance 函数的线程安全:双重检查锁(Double-Checked Locking)的设计逻辑
懒汉模式的核心是 "用到时才创建实例 "(区别于饿汉模式的 "启动即创建"),但这种 "延迟创建" 会引入线程安全问题 ------ 多个线程同时调用GetInstance()时,可能重复创建实例。因此需要通过 "加锁 + 双重检查" 解决,且兼顾性能:
1. 仅加锁不做外层检查的问题(性能浪费)
如果只写:
static A* GetInstance()
{
unique_lock<mutex> lock(_mtx); // 每次调用都加锁
if (_inst == nullptr)
{
_inst = new A();
}
return _inst;
}- 问题:
_inst创建完成后(非空),后续所有线程调用GetInstance()仍会执行 "加锁→解锁" 操作 ------ 加锁是有系统开销的(内核态 / 用户态切换),这些操作完全无意义,会降低程序性能。
2. 仅做单层检查不加锁的问题(线程安全问题)
如果只写:
static A* GetInstance()
{
if (_inst == nullptr) // 单层检查,不加锁
{
_inst = new A(); // 多线程同时进入,重复new
}
return _inst;
}- 问题:多个线程可能同时通过
if (_inst == nullptr)的检查,进而执行new A(),导致创建多个A实例,破坏单例的核心规则。
3. 双重检查锁的核心逻辑(兼顾线程安全 + 性能)
static A* GetInstance()
{
// 外层检查(无锁):_inst非空时直接返回,避免无意义的加解锁
if (_inst == nullptr)
{
// 加锁:保护new操作的原子性,避免多线程重复创建
unique_lock<mutex> lock(_mtx);
// 内层检查:防止"多个线程同时过外层检查,等待锁后重复new"
if (_inst == nullptr)
{
_inst = new A();
}
}
return _inst;
}- 外层检查 :无锁,快速判断 ------
_inst已创建时直接返回,跳过加锁逻辑,避免性能损耗; - 加锁 :仅当
_inst为空时,才加锁保护new操作,保证同一时间只有一个线程执行new; - 内层检查 :加锁后再次判断 ------ 假设线程 1 和线程 2 同时过外层检查,线程 1 先获取锁并执行
new,线程 2 等待锁;线程 1 释放锁后,线程 2 获取锁,此时内层检查_inst已非空,不会重复new。
二、DelInstance 函数设为 static 的原因
static void DelInstance()
{
if (_inst != nullptr)
{
delete _inst;
_inst = nullptr;
}
}- 操作静态成员的必需条件 :
DelInstance要修改类的静态成员_inst,C++ 语法规定:非静态成员函数必须绑定到具体对象才能调用,而静态成员函数属于 "类本身",可直接访问静态成员(无需对象); - 符合单例的访问逻辑 :单例的核心是 "全局唯一访问入口,无需创建对象",
DelInstance作为释放单例的函数,需要通过A::DelInstance()调用(而非对象.DelInstance()),因此必须设为 static; - 外部无法创建对象的适配 :A 的构造函数私有化,外部无法创建 A 的对象,若
DelInstance是非静态函数,外部根本无法调用(无对象可绑定)。
三、Gc 私有内部类的作用(单例的 "守护类")
A 的析构函数是私有化 的(~A() {}),且_inst是new出来的堆对象 ------ 如果用户忘记手动调用DelInstance(),_inst指向的内存会泄漏,且析构函数无法执行(析构私有化,外部delete会报错)。
Gc 类的核心作用:作为单例的 "最后一道保障" ,即使用户忘记手动释放_inst,程序退出时也会自动调用DelInstance()释放资源,避免内存泄漏:
// 私有内部类:仅A能访问,外部不可见
class Gc
{
public:
~Gc()
{
DelInstance(); // Gc析构时,自动调用DelInstance释放_inst
}
};
static Gc _gc; // A的静态成员,全局生命周期四、static Gc _gc 能自动调用析构的原因
static Gc _gc;是 A 类的静态成员变量,其生命周期遵循 C++"静态 / 全局对象" 的规则:
- 静态成员的生命周期:从程序启动(main 执行前)初始化,到程序完全退出(main 执行后)销毁,而非局部变量的 "作用域生命周期";
- 析构触发时机:main 函数执行完毕后,程序进入 "退出阶段",系统会自动销毁所有全局 / 静态对象 ------ 此时
_gc(A 的静态成员)会被销毁,进而调用 Gc 的析构函数; - 容错性:即使用户提前手动调用了
DelInstance()(_inst = nullptr),DelInstance()内部会判断_inst != nullptr才执行delete,因此 Gc 析构时重复调用也不会出错(只是空操作)。
五、提前释放的两种调用方式区别
1. A::GetInstance()->DelInstance()
- 执行逻辑:先调用
GetInstance()获取_inst指针(会触发双重检查锁逻辑),再通过指针调用DelInstance(); - 本质问题:
DelInstance()是静态函数,通过对象 / 指针调用静态函数,本质还是调用类的静态函数 ------ 相当于 "多此一举":先获取实例指针,再用指针调静态函数,额外执行了GetInstance()的外层检查逻辑,无意义且稍低效。
2. A::DelInstance()
- 执行逻辑:直接调用 A 类的静态函数
DelInstance(),跳过GetInstance()的检查步骤; - 优势:更高效、更符合静态函数的调用规范(静态函数应通过 "类名::函数名" 调用),且
DelInstance()内部已包含_inst != nullptr的检查,效果和前者完全一致。
核心区别
| 调用方式 | 执行步骤 | 效率 | 合理性 |
|---|---|---|---|
| A::GetInstance()->DelInstance() | GetInstance 检查 → 调 DelInstance | 低 | 冗余(静态函数无需实例) |
| A::DelInstance() | 直接调 DelInstance | 高 | 符合静态函数调用规范 |
六、为什么 A::DelInstance () 能调用私有析构函数
// DelInstance内部执行delete _inst;
if (_inst != nullptr)
{
delete _inst; // 调用A的析构函数 + 释放内存
_inst = nullptr;
}C++ 的访问权限规则是 "类的成员函数(包括静态成员函数)可访问类的所有私有成员":
DelInstance()是 A 的静态成员函数,属于 A 类的内部函数,因此可以访问 A 的私有析构函数;delete _inst的执行过程:先调用_inst指向对象的析构函数(~A()),再释放堆内存 ------ 虽然~A()是私有的,但DelInstance()作为内部函数,调用无权限问题;- 若外部直接写
delete A::GetInstance(),会编译报错(外部无法访问私有析构),但通过DelInstance()间接调用则合法。
总结(关键点回顾)
- 双重检查锁:外层无锁检查避免性能浪费,内层加锁检查保证线程安全,解决懒汉模式的线程安全 + 性能问题;
- DelInstance 设为 static:可直接访问静态成员
_inst,且符合单例 "无需对象即可调用" 的逻辑; - Gc 内部类:作为守护类,利用静态成员的生命周期,在程序退出时自动释放单例,避免内存泄漏;
- 静态 Gc _gc 自动析构:静态成员生命周期贯穿程序全程,main 结束后销毁,触发 Gc 析构→调用 DelInstance;
- 释放方式区别:A::DelInstance () 更高效,GetInstance ()->DelInstance () 冗余;
- 私有析构可调用:DelInstance 是类内部函数,有权访问私有析构,通过 delete _inst 触发析构。