1、RAG
概述:
RAG被称为检索增强生成,其目的是为了加强大模型针对特定垂直领域的推理回答能力,大概的实现思路就是会给大模型准备一个特定领域的知识库,大模型会参考知识库做出对应的推理回答。优势:
- 训练成本低,可扩展性强,更改需求只需要更新知识库
- 减少了模型的幻觉,提高生成结果的准确性
- 可控性
- 可解释性
一般的Agent开发框架RAG都是重要的一部分,例如
LangChain,SpringAI等
但是RAG也存在一些缺点这些缺点需要根据实际业务需求进行适当的调整:
- 知识库中没有相关知识
- 知识库选取TopN的知识不含有对应问题知识
- 模型输出格式不对
- 模型输出不完整...
相关测试代码参考Gitee仓库内容:分支RAG_And_BPE
RAG相关延伸知识:
-
MemWalker:主要是为了解决长文本无法和用户问题一起送入模型的问题,主要方式是拆分长文本构建向量树,选取长文本向量树中与用户问相似的拆分片段再连同用户问送入模型。
-
ReadAgent:也是用于处理长文本,先让大模型阅读长文本,分成多个gist memory,形成知识库;模型在处理用户问题时,如果遇见不会的还是会lookup原passage。
-
Corrective RAG:该操作方式是会引入网络查询,首先会有一个模型判断输入问题是否需要使用到网络知识,以及用一部分网络知识和一部分知识库知识,最后再将结果以及用户问题送入问答模型中。
-
self-RAG:根据模型判断知识库中的知识哪些可以被用于用户问题的辅助回答
-
power of Noise:知识库中召回中存在一些与问题不相关的知识,反而可以提高RAG的效果
2、bpe压缩算法
概述:bpe算法是一种文本压缩算法出现时间比较早,目前大模型解码编码操作基本都用到了bpe算法的相关思想。
基本实现思路: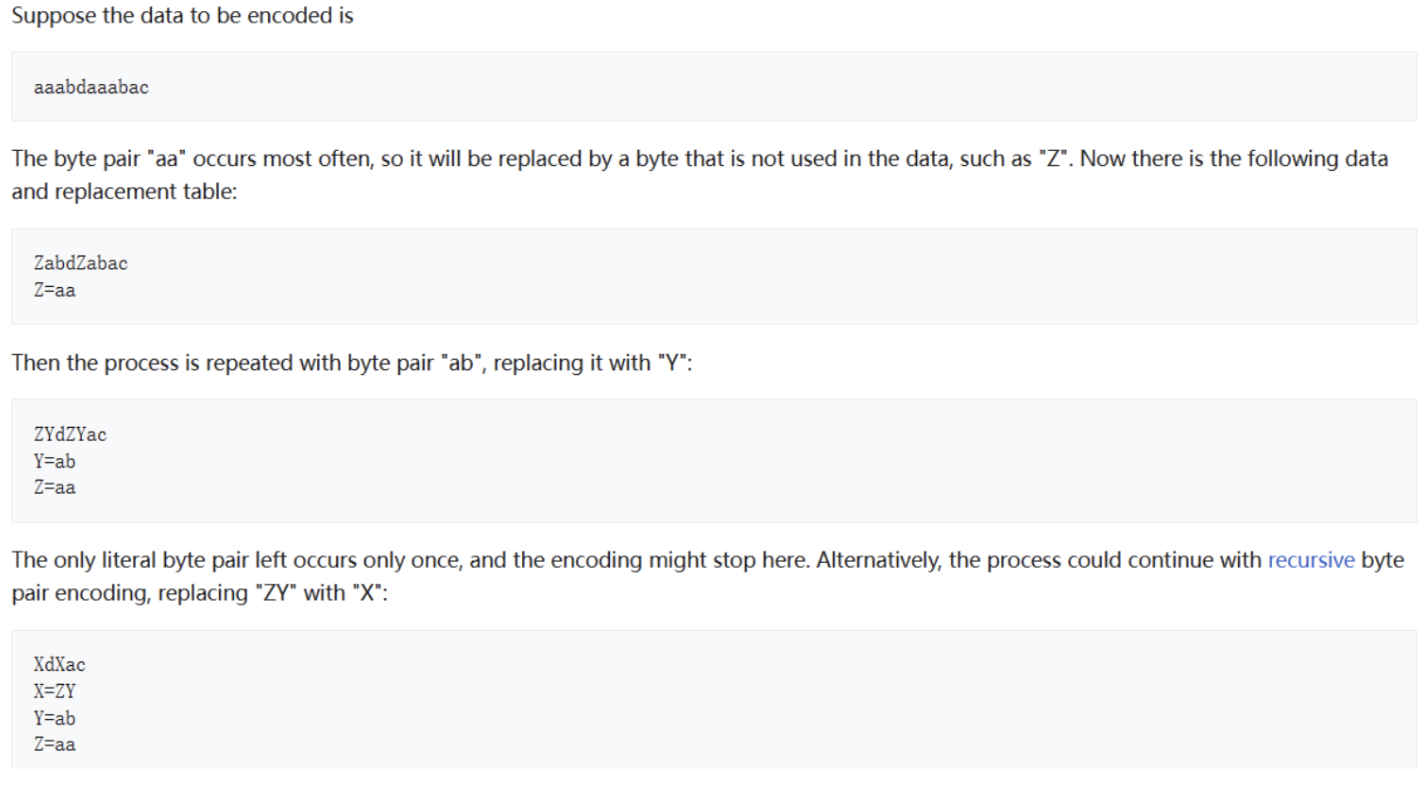
相关测试代码参考:分支RAG_And_BPE
相关总结:
- 通过对bpe算法的了解,对于大模型内部的解码、编码原理也会清晰的了解,尤其是对于token的认识,它并不一定是一个字符对应一个token,也可能会出现一个token代表对个字符的情况
- 正是因为bpe算法的缘故我们也可以从侧面联想到大模型不擅长数学推理类的任务(原因之一)
- 同时也不是特别擅长反过来表示默写句子
3、Diffusion model(Sora背后的技术)
概述:目前大模型中一种重要的开发方向就是文本生成图片/视频,
Diffusion Model相关技术就是其中对于文本生成图片/视频实现效果较好且比较成熟的技术。
基本实现思路:Diffusion Model的基本实现思路主要是首先随机生成一张噪声图,然后持续有条件的进行降噪,最终得到一张清晰完整的图片;生成视频也是一样的本质上就是在生成多张图片(图片又被称为单帧视频)
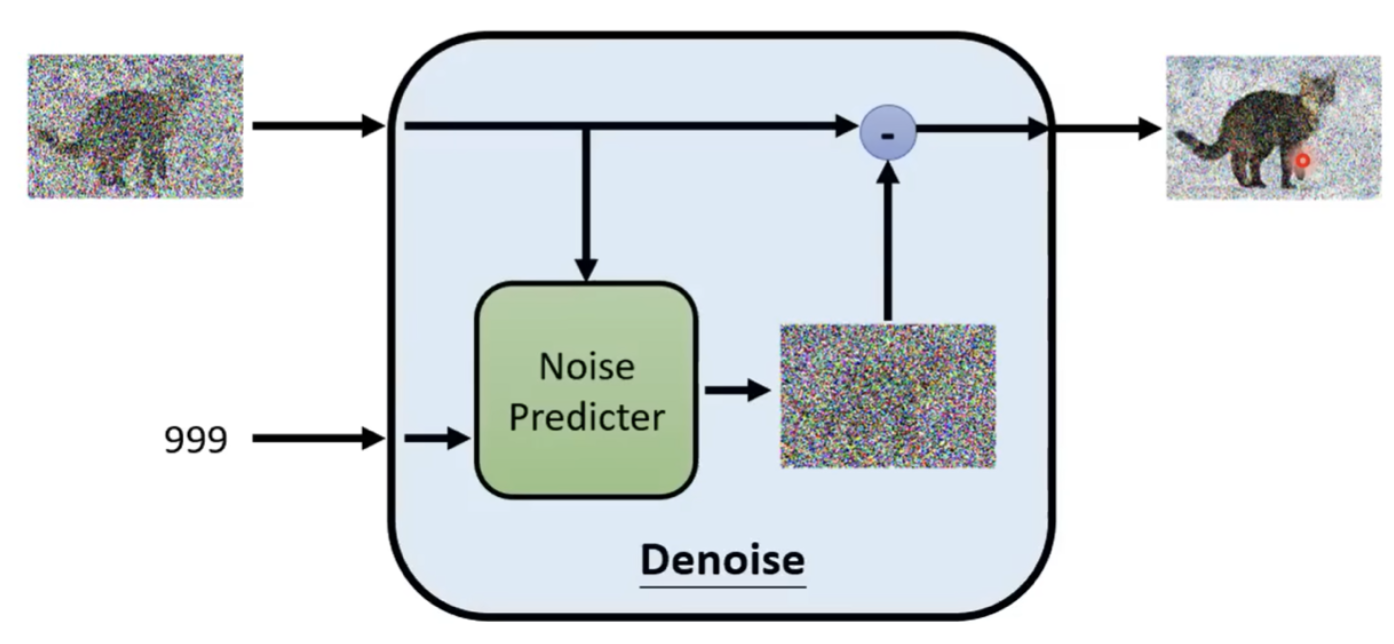
模型的输入:
- 随机噪声图
- 文本描述
- 时间步
实现细节:模型(Noise Predicter)预测噪声,有噪声图像-噪声;在这里模型的作用是在判断图像中哪些部分是噪声。
4、关于大模型可解释性
大模型学习到的是语言信息、世界模型还是单纯的词之间的概率?
通过论文《LANGUAGE MODELS REPRESENT SPACE AND TIME》可以证明模型学习到的是真实世界,主要实现思路就是准备一些真实世界实体词及其属性表述相关的语料(例如国家-经纬度),通过大模型生成这些实体词的特征向量,然后用这些特征向量去训练一个浅层模型;如果最终可以拟合这些数据则说明模型大模型学习到的是真实世界,而不是单纯的概率。
superposition
superposition主要是对大模型中单个神经元的研究,单个神经元是复杂的,具有多个特征处于一种叠加状态,每个神经元负责多项功能。
Dola encoding
Dola编码,主要就是在编码层面提高模型的推理能力,减少幻觉,产生含更多信息量更加正确的结果。
主要实现思路:
- 利用中间层模型输出辅助编码
- 看一个词在大模型的初始层概率值,到最末层概率值的变化程度,如果是逐渐上升或者提升很大,则说明该词是可信的;如果提升变化很小甚至降低,则说明该词不可信。