快速了解部分
基础信息(英文):
- 题目: Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
- 时间: 2024.12
- 机构: MIT CSAIL, Technical University of Munich
- 3个英文关键词: Diffusion Models, Sequence Modeling, Causal Architecture
1句话通俗总结本文干了什么事情
本文提出了一种叫"扩散强制(Diffusion Forcing)"的新方法,让模型既能像GPT一样自由地生成长短不一的序列(如视频、动作),又能像全序列扩散模型一样进行全局规划和纠错,解决了长序列生成容易"崩"掉的问题。
研究痛点:现有研究不足 / 要解决的具体问题
- Teacher Forcing (自回归模型):只能一个接一个地预测,没法回头改,稍微预测错一点,后面的误差就会累积爆炸(比如生成视频到后面画面乱飞),而且没法进行全局优化(比如没法指导模型"为了达到最终目标,你现在该怎么做")。
- Full-Sequence Diffusion (全序列扩散):虽然能全局规划,但它必须一次性生成固定长度的序列,没法灵活地处理变长任务,而且因为是非因果的,很难直接用作策略(Policy)进行实时决策。
核心方法:关键技术、模型或设计(简要)
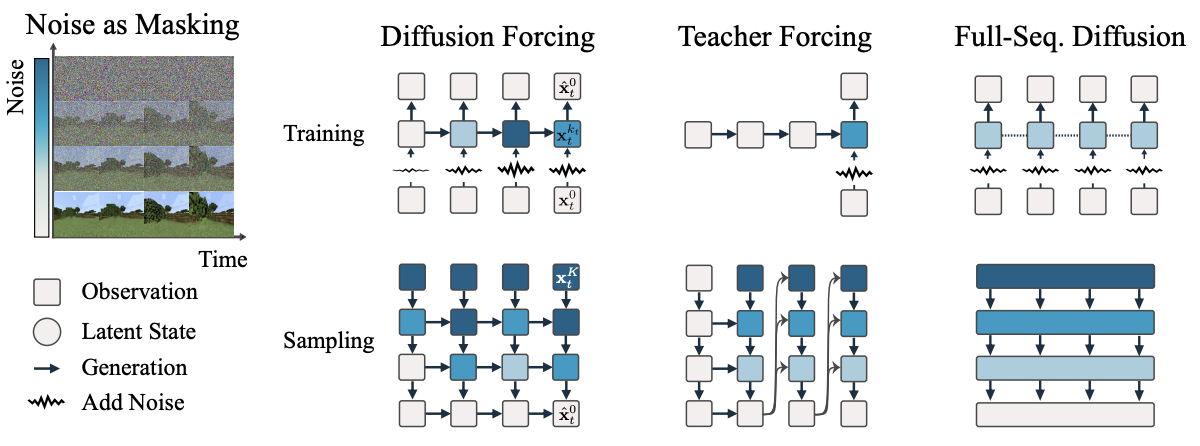
核心技巧 :给序列里的每一个 Token(比如每一帧画面)分配一个独立的、随机的噪声等级 ,而不是像传统扩散那样给整段序列加同样的噪声。
通俗理解:这就像是在考试时,允许学生对不同的题目有不同的确定度。模型要学会在只知道部分历史(低噪声)和面对充满噪声的未来时,依然能推理出当前该做什么。
深入了解部分
作者想要表达什么
作者想证明,"去噪"本质上是一种广义的"填补缺失"。通过将"时间轴上的预测"和"噪声轴上的扩散"统一起来,可以打破自回归和全序列生成的界限。他们想告诉我们:最好的序列模型应该既能向前走(自回归),又能回头看并修正(扩散),同时还能接受最终目标的指引。
相比前人创新在哪里
- 独立噪声调度 (Independent Noise Levels):前人(如 AR-Diffusion)通常是按顺序给越后面的 Token 加越多的噪声。本文让每个 Token 的噪声等级是独立随机的,这迫使模型必须学会处理任意形式的"部分观测"。
- 因果扩散 (Causal Diffusion):在训练时引入了因果结构(RNN),使得模型在推理时既能像扩散模型一样进行多步迭代优化(Guidance),又能保持自回归模型的灵活性(变长输出)。
解决方法/算法的通俗解释
想象你在玩"你画我猜",但规则很怪:
- 训练时:你的队友每次给你看的图片都是不同程度的"马赛克"(噪声)。有时候第一张图很清晰,有时候最后一张图全是雪花点,而且每张图的清晰度是随机打乱的。你的任务是,不管中间有多模糊,都要猜出原本的清晰图像是什么。
- 推理时(生成):你从一张全是雪花点的电视画面开始,一边看着刚才画的模糊画面(历史记忆),一边慢慢把当前这一帧擦清晰,同时还能根据"最终大奖"(Guidance)的提示来调整你的画法。
解决方法的具体做法
- 训练(Diffusion Forcing) :
- 拿一段数据(比如视频),给每一帧都随机加不同量的噪声。
- 用一个 RNN 模型来读取"带噪的历史画面",然后让它去预测"当前这一帧原本清晰的样子"。
- 关键是:历史画面可以是清晰的,也可以是全噪的,随机组合。
- 推理(Sampling) :
- Zig-Zag 采样:不是一下子把所有帧都变清晰。而是从全噪声开始,按照一个"金字塔"式的噪声表(先近后远,近处清晰,远处模糊),一行一行地把画面变清晰。
- 蒙特卡洛引导 (MCG):在生成过程中,可以计算"这样做未来得分高不高",并利用梯度把生成的轨迹往高分方向拉。
基于前人的哪些方法
- 扩散模型 (Diffusion Models):基于 DDPM 的去噪原理。
- Teacher Forcing:传统的序列训练方法,本文将其泛化了。
- Bayesian Filtering (贝叶斯滤波) :本文的模型结构借鉴了卡尔曼滤波的思想,用隐变量 zzz 来总结历史状态。
实验设置、数据、评估方式、结论
- 视频生成 (Minecraft/DMLab) :任务是根据第一帧预测后面的视频。
- 结果:相比基线(Teacher Forcing 和 Full-Sequence Diffusion),本文方法生成的视频更稳定,能跑出比训练长度长得多的视频(Infinite Rollout),且画面连贯。
- 强化学习规划 (Maze2D) :在迷宫里找路。
- 结果 :使用 MCG (Monte Carlo Guidance) 后,成功率远超 SOTA 的 Diffuser 模型,且不需要额外的控制器。
- 机器人控制 (Real Robot) :机械臂要把苹果和橘子换位置。
- 结果:即使蒙住摄像头或有干扰,模型也能靠记忆完成任务,成功率 80%,而普通扩散策略(Diffusion Policy)因为没有记忆会失败。
提到的同类工作
- Diffuser 37:用全序列扩散来做规划,但无法处理变长任务,且生成的动作往往不符合因果律。
- AR-Diffusion 66:也是想结合自回归和扩散,但它的噪声是按位置线性增加的,不够灵活,无法实现本文的"因果不确定性"建模。
- TimeGrad 50:经典的单步时间序列扩散模型,属于 Teacher Forcing 范畴。
和本文相关性最高的3个文献
- Planning with diffusion for flexible behavior synthesis (Diffuser) 37 <2022_ICML>:这是本文在决策规划领域最主要的对比基准和前人工作。
- Denoising diffusion probabilistic models (DDPM) 29 <2020_NeurIPS>:扩散模型的基础理论,本文的数学根基。
- AR-Diffusion: Auto-regressive diffusion model for text generation 66 <2023_NeurIPS>:这是本文在序列生成领域最直接的前人工作,本文正是为了克服它的局限性(线性噪声)而提出的。