本篇目标:解释实现大型需求自动化开发、验证的方法,展示效果,形成可复用(易复用)的方法论。
本篇由 AI 协助完成,10x "开发"文档
0 术语
| 术语 | 含义 |
|---|---|
| CC | Claude Code,Anthropic 的 AI 编程助手 |
| SDD | Spec-Driven Development,规格驱动开发 |
| Spec | 规格文档------SDD 各阶段的核心产出物 |
| Context | 输入给模型的上下文信息(含系统提示、对话历史、文件内容等) |
| Session | 一次完整的人-模型交互会话 |
| Fresh Session | 全新的、无历史累积的干净会话 |
| Subagent | 主 Agent 派生的子 Agent,在独立 Session 中执行特定任务 |
| MCP | Model Context Protocol,模型上下文协议(外部工具集成标准) |
| Skill | 可复用的 Agent 行为模板(prompt + 约束 + 工具配置) |
| Plan Spec | 任务计划文档,含原子任务列表及执行所需的 Context |
| Design Spec | 系统设计文档,含架构、接口定义、数据模型 |
1 定义"长任务 Vibe"
先明确概念------长任务 vibe 和传统逐任务交互有什么本质区别。
核心差异:人从"每一步的执行者"变成"流程的监督者"和"Context 决策者"。
传统模式下,人需要在每个任务上花费大量时间进行上下文切换、手动喊给 AI、再检查输出。Long-task vibe 模式下,人只在关键节点进行审核------需求是否对齐、设计是否合理、任务拆分是否完备------执行工作交由 Agent 在隔离的 Fresh Session 中自动完成。
要保证长任务的稳定性,关键在于两点:原子任务拆分 的质量和任务 Context 隔离执行的能力。
2 模型决定下限和上限
模型能力决定了天花板和地板,但在这个范围内你实际落在哪里,取决于 context 质量。
差模型的信息密度低,且由于 context window 的强限制,其大量的无效输出会很快污染 context,导致输出质量逐渐降低。可以用一个二维坐标来理解不同模型的表现差异:
- X 轴:Token 消耗量------完成同样任务,模型需要消耗多少 token(包括输入和输出)
- Y 轴:智能程度------模型理解意图、做出正确决策的能力(体现为代码正确率、架构合理性、边界处理等)
理想模型位于左上角(低消耗、高质量)。闭源前沿模型(如 Claude Sonne/Gemini)倾向于更精简的输出,在相同 context 预算下能保持更高的信息密度;而部分开源或较弱的模型则倾向于生成大量解释性文字,快速消耗 context window。
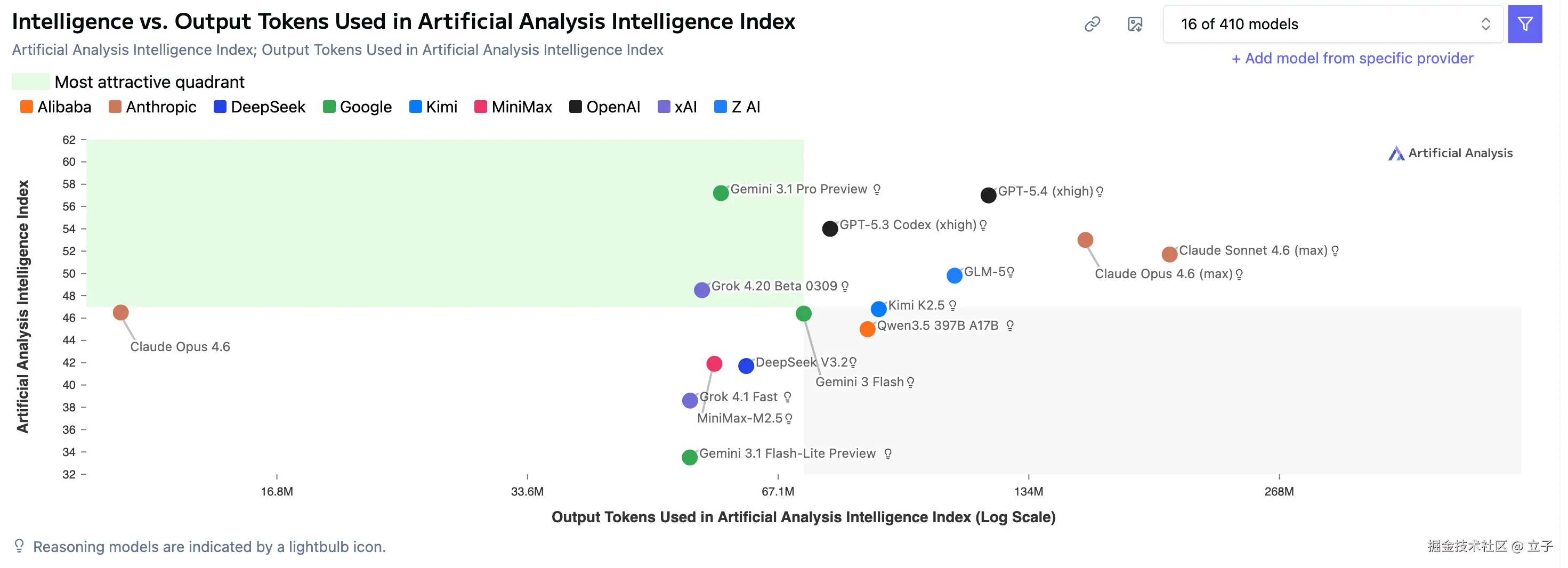
Takeaways:
- 模型的"废话"会污染 context,压缩有效信息密度
- 不同模型输出的精简程度不一,闭源模型通常更简洁
- 重点:选对模型是前提,但不是全部------能管好 context 才是胜负手
3 SDD 开发与长任务
3.1 SDD 与传统需求的开发流程
根据 Wikipedia 的定义:
Spec-driven development (SDD) is a software engineering methodology where a formal, machine-readable specification serves as the authoritative source of truth and the primary artifact from which implementation, testing, and documentation are derived
规格驱动开发(SDD)是一种软件工程方法论,以一份正式的、机器可读的规格说明作为唯一权威的事实来源,实现、测试和文档均从该规格派生而来。
从定义中可以看出,Spec 是整个需求开发的中心。但在实践中,SDD 更关键的是一套伴随软件开发各个阶段的方法论------它规定了每个阶段应产出什么样的 Spec 文档,以及这些文档如何驱动下一阶段的自动化执行。
要理解它的价值,先看传统开发流程中 SDD 可以介入的环节:
- 需求评审:产品/业务方与研发对齐需求范围
- 系统设计/系分:人工编写系分文档(SDD 可辅助生成)
- 技术方案评审:架构师/TL Review 设计合理性
- 任务拆分/排期:手动拆分子任务并估时(SDD 可自动拆分)
- 编码开发:逐任务手写代码(SDD 可由 Agent 执行)
- 自测/单元测试:开发者手动验证
- Code Review → 联调 → QA → 发布:传统人工驱动链路
传统流程的核心瓶颈在于:每个环节都高度依赖人的执行参与。SDD 的目标不是消除人,而是将人的角色从"执行者"提升为"决策者和审核者"。引入 SDD 后,流程变为:
3.1.1 SDD 增强后的开发流程
对比两张图可以看到关键转变:人工执行的环节变成了人工审核的环节。Agent 承担了系分编写、任务拆分、编码和测试生成的执行工作;人则聚焦在需求评审、设计审核、任务审核和最终的 Code Review------这些是真正需要专业判断的节点。
3.2 SDD 弥补模型 Context 长度限制
要理解 SDD 为何能支撑长任务,需要先理解它解决的核心问题:模型的 Context 限制。
Transformer 的注意力机制天生存在限制。模型推理所需的资源随 Context 窗口增长而急剧增加,因此所有模型的 Context 窗口都有一个硬性天花板。更关键的是,即使在窗口之内,注意力机制也无法保证信息的均匀有效------研究表明,处于 Context 中间位置的信息尤其容易被"遗忘"(Lost in the Middle 现象)。
大多数开发实践中,为了规避这一缺陷,通常由开发者手动拆分较小的任务后交由模型执行。但这又回到了"人是每一步的执行者"的老路。SDD 用一种不同的方式解决了这个问题:
在传统交互模式中,所有任务在同一个 Session 内顺序执行。前序任务的输出(包括大量无关的中间过程)不断累积,挤占后续任务的有效信息空间,导致越往后执行质量越差。
SDD 模式的关键突破在于:将 Spec 文档作为跨 Session 的持久化 Context。每个任务在独立的 Fresh Session 中执行,只加载当前任务所需的 Spec 片段,从而保证每个任务都拥有高质量、高密度的 Context 输入。这也是 SDD 工具箱(特别是集成了 Subagent 机制的实现)能支撑连续数小时长任务执行的根本原因。
3.3 SDD 核心机制:Spec 流水线
SDD 的运作依赖一条文档驱动的流水线。每个阶段产出的 Spec 文档,既是该阶段的交付物,也是下一阶段的输入 Context:
这条流水线的设计遵循三个核心原则:
-
阶段隔离,文档传递:每个阶段结束后,产出的文档进入只读模式。下游阶段仅通过读取文档获取上下文,而非依赖同一个 Session 的记忆。这确保了信息传递的确定性------不会因为 Context 衰减而丢失关键信息。
-
原子任务,独立执行:Plan Spec 将大型需求拆分为若干原子任务,每个任务包含独立执行所需的全部上下文信息(涉及的文件路径、接口定义、依赖关系)。Agent 在 Fresh Session 中逐个执行,互不干扰。
-
Spec 作为外部记忆:模型的 Context Window 是易失的,但文件系统上的 Spec 文档是持久的。SDD 本质上是用文档系统弥补模型的记忆缺陷------将"需要记住的一切"外化为 Spec,让每个 Session 按需加载,而非依赖模型在长对话中"记住"。
3.4 Context 设置基本原则
Context 的质量直接决定 Agent 的输出质量。以下是经过实践验证的关键原则:
最重要的原则:始终关注当前 Context 会话占用情况
不要吝惜新建 session。把每个 session 当作一个独立的 Agent 员工------每个 Agent 只负责完成一个 Skill(一项明确的任务)。session 越长,context 越脏,模型的有效智能越低。当你感觉 Agent 开始"发瘴"的时候,正确的做法不是反复纠正,而是开一个新 session、给它干净的 context、让它重新出发。
Role 设定
为 Agent 设定明确的角色(如"后端架构师"、"QA 专家")会显著影响其行为模式。例如,设定为 QA 角色的 Agent 会专注于发现问题而非擅自修复。Role 影响三个维度:instruction following 的严格程度、输出的语气风格、以及面对歧义时的决策倾向。
工具加载策略
工具不是越多越好------加载过多工具反而降低模型执行质量,因为每个工具的 schema 都会占用 context 空间。推荐策略:
- MCP、Skills 按需加载到当前 session,一个 session 专注一个 skill
- 复杂任务用 specialized sub-agents 拆分执行,每个 subagent 只加载所需工具
- 优先使用本地信息通道(文件读取、grep 搜索),避免低效的远程调用
Workspace 范围
项目的 workspace 要包含全部相关子项目(如本项目同时包含管理态、运行态、接入层),避免 AI 缺少上下文做出错误假设。缺失的依赖信息是 Agent 产生幻觉的常见原因。
Subagent 的 Context 代价
Subagent 会扩展 context(其输出需要回传给主 agent),注意对上下文长度的影响。如果 subagent 输出过长,考虑让其只返回摘要或关键结果。
当前痛点
- 定义自己的 Agent(可复用 context、prompt)是提效的关键
- Qoder 等非 CC 工具有时不严格遵循 SOP,需要在 prompt 中更强调约束
3.5 AGENTS.md
AGENTS.md 是项目根目录下的配置文件,Agent 在启动 session 时会自动读取。它的作用相当于给 Agent 一份"入职须知":
- 编码规范:命名约定、代码风格、注释语言
- 项目架构:模块划分、分层结构、核心依赖关系
- 内部依赖:私有包的引用方式、版本约束
- 禁止操作:如本项目中规定 "Don't perform any git operations"
- 常见陷阱:项目特有的注意事项(如特殊的序列化方式、字段命名例外)
AGENTS.md 应保持精简------它会占用每个 session 的 context 空间。只放全局性的、每次都需要的信息;阶段性的信息放在对应的 Spec 文档中。
3.6 项目开发流程
完成 Context 环境设置后,进入 SDD 的核心开发循环。整个流程由四个阶段组成,严格顺序执行:
每个阶段结束时,产出的文档进入只读模式------这是 SDD 的铁律。下游阶段只能读取上游文档,不能反向修改。如果在执行中发现设计缺陷,应回到对应阶段重新生成 Spec,而非在代码中打补丁。
3.7 基本项目结构
bash
project-root/
├── AGENTS.md # Agent 全局配置(自动加载)
├── 00-prd/ # 阶段 0:产品需求文档
│ └── feature-x-prd.md
├── 01-design/ # 阶段 1:系统设计文档
│ └── feature-x-design.md
├── 02-plan/ # 阶段 2:任务计划文档
│ └── feature-x-plan.md
├── 03-tests/ # 阶段 3:测试用例 + 可执行脚本
│ ├── feature-x-e2e.md
│ └── run-e2e.sh
└── src/ # 实际代码目录这套目录结构的设计意图是:让 Agent 通过文件路径约定自动定位 context 。当 Agent 需要生成设计文档时,它知道去 00-prd/ 读取需求;当它需要执行任务时,它知道去 02-plan/ 读取任务列表。约定优于配置,减少每次手动指定路径的开销。
3.8 PRD
PRD 是整条 Spec 流水线的起点,其质量直接决定下游所有产出物的上限。
核心原则:本地化 。云文档(语雀、Notion 等)性能较差,Agent 无法原生快速搜索(如使用 grep)。应将需求文档导出为 Markdown 存放在 00-prd/ 目录下,确保 Agent 可以直接读取和引用。
PRD 应包含以下关键信息:
- 功能范围:明确哪些功能在本次需求范围内,哪些不在
- 接口契约:涉及的 API 变更、新增字段、数据结构
- 业务规则:状态流转、权限控制、数据校验规则
- 非功能需求:性能要求、兼容性约束、灰度策略
PRD 不需要面面俱到,但需要覆盖 Agent 在后续阶段做决策时所需的全部业务信息------因为 Agent 无法像人一样"去问一下产品经理"。
3.9 Design
Design 阶段是 Agent 第一次介入的产出环节。给 Agent 输入 PRD,让它生成系统设计文档(Design Spec),存放在 01-design/。
生成策略:交叉验证
不要只用一个模型生成设计。推荐流程:
交叉验证的价值在于:不同模型有不同的"盲区"。模型 A 可能遗漏边界条件,模型 B 可能发现接口命名不一致。多视角审查能显著提高设计质量。
Design Spec 应包含:
- 架构变更概览(新增/修改了哪些模块)
- 数据模型变更(新增字段、表结构)
- 接口定义(请求/响应结构、状态码)
- 关键逻辑流程(状态流转、级联操作)
3.10 Tasks
任务拆分是长任务 vibe 的核心环节------拆分质量直接决定 Agent 自动执行的成功率。
拆分原则
- 原子性:每个任务应可独立执行和验证,不依赖其他任务的运行时状态
- 自包含 Context:每个任务必须附带执行所需的全部上下文------涉及的文件路径、接口签名、依赖的数据结构、预期的行为变更。Agent 在 Fresh Session 中不会"记得"之前的任务
- 有序依赖:任务按依赖关系排序(如先建表、再写 DAO、再写 Service、最后写 Controller)
- 可验证:每个任务完成后应有明确的验证标准(编译通过、测试通过、特定输出等)
Plan Spec 的结构
推荐将 Plan 按 Chunk(功能块)组织,每个 Chunk 内包含若干有序 Task。每个 Task 需包含:
- Task 标题:简述要做什么
- Files:涉及的文件(新增或修改)
- Context:执行所需的上下文引用(指向 Design Spec 的具体章节、现有代码的参考文件)
- Steps:用 checkbox 列出具体步骤,便于跟踪进度
Task 的 Context 部分是关键------它就是 Agent 在 Fresh Session 中唯一的"记忆来源"。Context 写得越精确,Agent 执行的成功率越高。
3.11 E2E Tests
E2E 测试是 SDD 流水线的最后一道防线,用于验证从 Plan Spec 派生的代码变更是否符合预期行为。与传统手写测试不同,SDD 中的测试用例可由 Agent 从 Spec 文档自动派生(这是我设想的 E2E,还未标准化)------Spec 既定义了"要实现什么",也定义了"如何验证"。
Backend
分两阶段------先生成测试用例文档,再转化为可执行脚本。
阶段一:生成测试用例(descriptive,不含可执行命令)
markdown
You are a **QA expert**. Given the implementation plans in `02-plan/`, generate a comprehensive E2E test case document and put it under `03-tests/`.
### Rules
1. **Format --- descriptive, not executable.** For each test case, show:
- Test ID and title
- Endpoint (method + path)
- Preconditions / setup
- Request body (JSON)
- Expected response (success/failure + key fields)
- Assertions on specific field values
- Side effects (DB changes, cascade behavior) where relevant
- Do **NOT** generate concrete runnable commands (no curl, no shell scripts).
2. **Coverage requirements:**
- Cover **every API endpoint** introduced or modified by the plans (both new and changed).
- Cover **all VO/config structures** end-to-end (set via update, verify via query).
- Include **negative cases**: missing required fields, invalid state transitions, wrong entity type.
- Include **cascade behavior**: create → copy → delete chains to verify side effects.
- Include **cross-entity interaction** where applicable (e.g., bot → skill relations → agent config).
3. **Regression tests --- protect existing behavior:**
- For every **modified** endpoint, add regression test cases that exercise the **pre-existing** request/response contract **without using any new fields**.
- Verify existing filters, validation rules, and constraints still work unchanged.
- Verify response schema backward-compatibility (no fields removed or renamed).
- Verify business rules that should NOT be relaxed for existing entity types.
4. **Do NOT test:**
- SQL migration scripts (DDL/DML) directly.
- Internal code structure (enums, constants, mapper XML).
- Compilation or unit-level concerns.
5. **Structure:**
- Start with **Section 0: Regression** (existing behavior preservation).
- Then group by feature area (CRUD, config update, bindings, copy, delete cascade, etc.).
- End with an **execution order & variable dependency** graph.
- Use `$VARIABLE_NAME` placeholders for IDs created during the test flow.
6. **Derive everything from the plans.** Read all files in `02-plan/` to understand:
- What endpoints exist (new and modified).
- What request/response fields were added.
- What service-layer behaviors changed (cascade delete, cascade copy, constraint relaxation).
- What data flows end-to-end (create → config → snapshot → publish).阶段二:生成可执行 curl 脚本
csharp
You are a QA expert. Based on the test cases in `03-tests/`,
create executable E2E tests using curl and run them.
The following is a runnable curl demo:
[CURL_DEMO]- CURL_DEMO 是从当前系统导出的可执行的 curl 命令,包含 cookies 以维持登录态。
Frontend
前端 E2E 调试有两种主流方式:
| 维度 | Chrome DevTools | Playwright MCP |
|---|---|---|
| 原理 | Agent 通过 MCP 连接真实浏览器,人工保持 DevTools 打开观察 | Agent 通过 Playwright MCP 用无头浏览器自动操作页面 |
| 调试反馈 | Console 日志实时可见,人工可随时介入 | 截图 + DOM 快照自动回传给 Agent,无需人工监看 |
| 操作方式 | Agent 只负责写代码,人工在浏览器中手动验证 | Agent 直接控制浏览器(点击、填写、导航),全自动执行 |
| 适用场景 | 开发过程中的交互式调试,需要人工判断 UI 表现 | 回归测试、表单流程验证、可重复执行的 E2E 场景 |
| 优势 | 简单直接,不需额外配置;session 自动保持 | 完全自动化,Agent 能自我验证修复结果 |
| 劣势 | 依赖人工观察,无法自动化 | 需配置 Playwright MCP Server,复杂 UI 交互可能不稳定 |
建议:开发过程中用 Chrome DevTools 做交互式调试,回归验证时用 Playwright MCP 做自动化 E2E。
3.12 SDD 选型:speckit vs. superpowers
目前 SDD 工具有两种流行的实现路径:
| 维度 | Speckit 风格 | Superpowers 风格 |
|---|---|---|
| 核心理念 | 轻量级目录约定,以 Spec 文件为中心 | Skill 框架,以可复用的 Agent 行为模板为中心 |
| 任务执行 | 顺序执行,每个任务独立 session | 支持 Subagent 并行派发,主 agent 协调 |
| Context 管理 | 手动指定每个任务的输入文件 | 通过 Skill 定义自动加载所需 context |
| 适用场景 | 项目初期、流程简单、不需要并行 | 大型需求、多文件并行修改、需要角色分工 |
| 学习成本 | 低,只需理解目录约定 | 中,需要编写 Skill 定义和理解 agent 调度 |
| 执行效率 | 线性,受限于单 session 速度 | 更高,Subagent 并行可大幅缩短总时长 |
实践建议:从 Speckit 风格(手动目录结构 + 顺序执行)起步,熟悉 SDD 流程后,再引入 Superpowers 的 Subagent 机制提升执行效率。两者并非互斥------Superpowers 的 executing-plans skill 本质上就是在 Speckit 的 Spec 流水线之上加了自动化调度层。
Superpowers 核心阶段对应 Skill
| 开发阶段 | 推荐 Skill | 说明 |
|---|---|---|
| PRD / 需求探索 | brainstorming |
通过对话澄清意图,输出设计与 Spec,必须在实现前完成 |
| Design / 系统设计 | brainstorming |
同上,设计需经人工 approve 后才进入下一阶段 |
| Plan / 任务拆分 | writing-plans |
long-task 的关键, 将 Spec 转化为可执行的分步计划,包含文件路径、测试策略 |
| Execution / 并行执行 | subagent-driven-development |
每个任务派发独立 Subagent,附带两阶段 Review(Spec 合规 + 代码质量) |
跨阶段通用:
using-superpowers:元 Skill,每个 session 启动时自动检查可用 Skillsusing-git-worktrees:为 feature 创建隔离工作区,避免污染主分支
4 效果展示
把上述方法串起来,在实际项目中落地的效果如何?
以某个实际需求为例------为智能客服平台新增一种完整集成平台模板的 Bot 运行模式 (ReAct Agent 模式)。在管理态,需要从枚举定义、数据库快照、服务层路由到前端 VO 全链路改造,同时必须保证已有模式的行为完全不变(向前兼容)。该需求涉及 2 个子项目,跨 30+ 个文件的新增和修改:
| 指标 | 传统开发 | SDD 长任务 Vibe |
|---|---|---|
| 总工时 | ~16 人天 | ~1.5 人天 |
| 效率倍数 | 基准 | 10x+ |
| 人工参与 | 全程编码 + 调试 | PRD 编写 + 3 次审核 + 最终 CR |
| 代码一致性 | 依赖个人水平 | Agent 严格遵循 Spec,风格统一 |
| 测试覆盖 | 手动编写,覆盖率看心情 | Agent 自动生成,覆盖全部 API 端点 |
省下来的不是编码时间,而是上下文切换时间。传统开发中,工程师需要在 30+ 个文件之间反复切换、记忆接口定义、保持一致性------这些正是模型擅长而人类容易出错的工作。
5 Future
从业务开发到 "Agent 员工开发"
每次清空 session 保证纯净 context,但关键信息如何跨 session 传递?当前依赖手动选择 memory,未来可优化到由 "Agent 员工" 自动管理。终极目标是每位工程师拥有自己的 Agent 员工阵列------Python NO.1 的后端 Agent、 Vue 偏执的前端 Agent、尤其喜欢回归历史 Bug 的测试 Agent,等等 ------ 一切根据个人习惯和项目特点定制。
更轻、更通用的 AI IDE
当前流行的 IDE 工具存在模式冲突(Plan Mode 与 SDD Skills 的交互干扰)。开源社区日新月异,理想的 AI IDE 应该足够轻量------skills 动态加载即可,做好 Skill 与 "子 Agent" 集成(唤醒和通信),无需重量级的模式切换机制。
手动跨会话 Context 传递("Context Engineer")
SDD 用文档解决了跨 session 信息传递的问题,但"哪些信息需要传递"仍然依赖人的判断。未来或许能有可视化的 Context 选择工具------让工程师凭品味和专业知识手动筛选高价值 context,而非完全依赖自动压缩(或至少提供可选的自动化方案)。