Grafana 配置实战
1.1 数据源配置
登录 Grafana (http://your-grafana:3000)
点击 Configuration → Data Sources → Add data source
选择 Prometheus
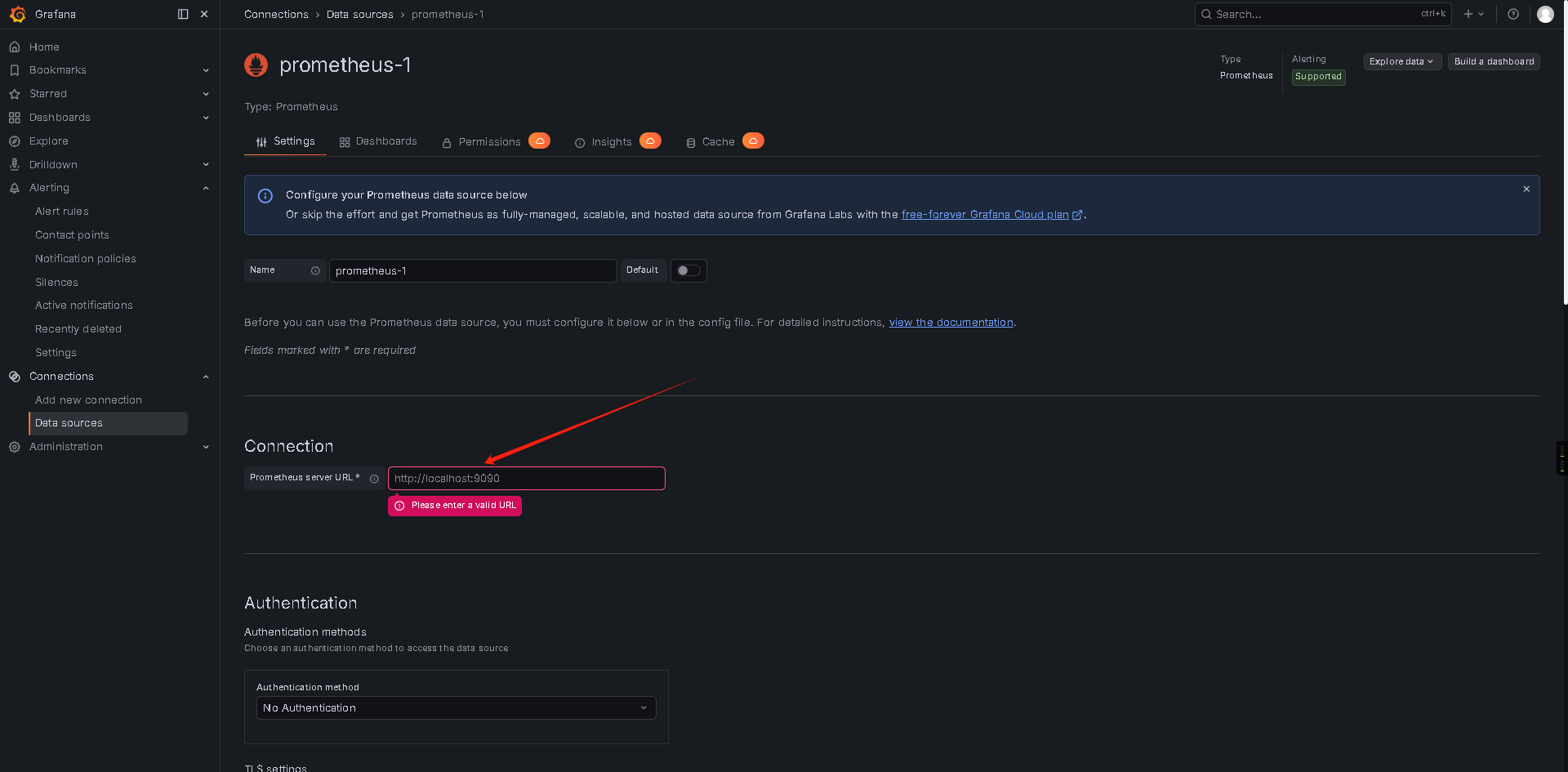
配置 URL: http://your-prometheus:9090
点击 Save & Test
1.2 仪表盘创建
 选择Add visualization
选择Add visualization
1.2.1 端口状态概览面板查询语句:
# 端口连通状态
probe_success{job="port_monitoring"}
# 响应时间
probe_duration_seconds{job="port_monitoring"}可视化配置:
类型: Stat
阈值: 绿色(0.9-1), 红色(0-0.89)
值映射: 1=UP, 0=DOWN
4.2.2 响应时间趋势面板
查询语句:
# 按实例分组的响应时间
sum by(instance) (rate(probe_duration_seconds{job="port_monitoring"}[5m]))可视化配置:
类型: Time series
单位: seconds
显示: Lines
4.3 告警规则配置
4.3.1 创建告警规则
1.进入 Alerting → Alert rules → New alert rule
2.规则配置:
- List item规则名称: Port Monitoring - Service Down
- 评估组: 选择或创建评估组
查询:
sum by(instance) (probe_success{job="port_monitoring"} == 0)条件: IS ABOVE 0
评估间隔: 1m
持续时间: 1m
4.3.2 无数据处理策略
在 Advanced options 中配置:
No Data Handling: Do not fire
执行错误处理: Alerting
Paused: 保持关闭
4.3.3 通知策略
创建 Contact point:
类型: Email
配置 SMTP 服务器
测试邮件发送
创建通知策略:
匹配标签: severity=critical
联系人: 邮件联系人
分组: 按 cluster, alertname
静默期: 5m
配置 Grafana SMTP
-
修改 Grafana 配置文件
编辑 grafana.ini
sudo tee -a /etc/grafana/grafana.ini << 'EOF'
[smtp]
enabled = true
host = smtp.163.com:465
user = xxx@163.com
password = xxxx
from_address =xxxx@163.com
from_name = Grafana Port Monitoring
ehlo_identity = 163.com
startTLS_policy = OpportunisticStartTLS
skip_verify = true
EOF
需要手动去/etc/grafana/grafana.ini
删除smtp
-
重启 Grafana
sudo systemctl restart grafana-server
sudo systemctl status grafana-server -
测试 Grafana 邮件发送
检查配置是否生效
grep -A5 "smtp" /etc/grafana/grafana.ini
5. 故障排查指南
5.1 常见错误及解决方案
错误 1: "frame cannot uniquely be identified by its labels"
原因: 监控目标标签重复
解决方案:
# 错误配置(所有目标相同标签)
- targets: ["server1:80", "server2:80"]
labels:
job: "port_monitoring"
# 正确配置(每个目标唯一标签)
- targets: ["server1:80"]
labels:
job: "port_monitoring"
instance: "server1_80"
- targets: ["server2:80"]
labels:
job: "port_monitoring"
instance: "server2_80"
错误 2: "Loading OnCall integration failed"
原因: Grafana OnCall 插件配置问题
解决方案:
检查插件配置: Configuration → Plugins → OnCall
验证网络连通性
检查服务状态: curl http://oncall:8080/health5.2 监控数据验证步骤
1. 验证 blackbox_exporter
curl http://localhost:9115/probe?target=google.com:443&module=http_2xx
# 2. 验证 Prometheus 目标
curl http://localhost:9090/api/v1/targets
# 3. 验证指标
curl "http://localhost:9090/api/v1/query?query=probe_success{job='port_monitoring'}"6. 最佳实践建议
6.1 标签设计规范
必须包含唯一标识: instance 标签必须唯一
业务维度分组: 使用 service, team, environment 标签
技术维度标注: 使用 protocol, port, region 标签
6.2 告警分级策略

6.3 性能优化
](https://i-blog.csdnimg.cn/direct/4d2d55cfd7ee4accad28f0bd8d526fee.png)
抓取间隔: 根据业务重要性设置 (15s-5m)
数据保留: Prometheus 数据保留 15-30天
告警分组: 避免告警风暴,合理设置分组策略
7. 总结
Grafana 结合 Prometheus 和 Blackbox Exporter 能够构建强大的端口监控体系。关键成功因素包括:
正确的标签设计:避免重复,确保唯一性
合理的告警策略:分级响应,避免误报
完善的故障排查:建立标准化排查流程
持续的优化迭代:根据业务发展调整监控策略
通过本文的实践指南,您可以快速搭建从端口探测到告警通知的完整监控链路,提升系统的可靠性和可观测性。