目录
目录
前言
一、问题背景及现象
[1.1 故障场景与表现](#1.1 故障场景与表现)
[1.2 报错信息与定位](#1.2 报错信息与定位)
二、技术分析与原理
[2.1 内存结构](#2.1 内存结构)
[2.2 溢出成因](#2.2 溢出成因)
[2.3 核心对比](#2.3 核心对比)
三、解决方案与实践
四、进阶优化与指南
五、本文总结
六、更多操作

前言
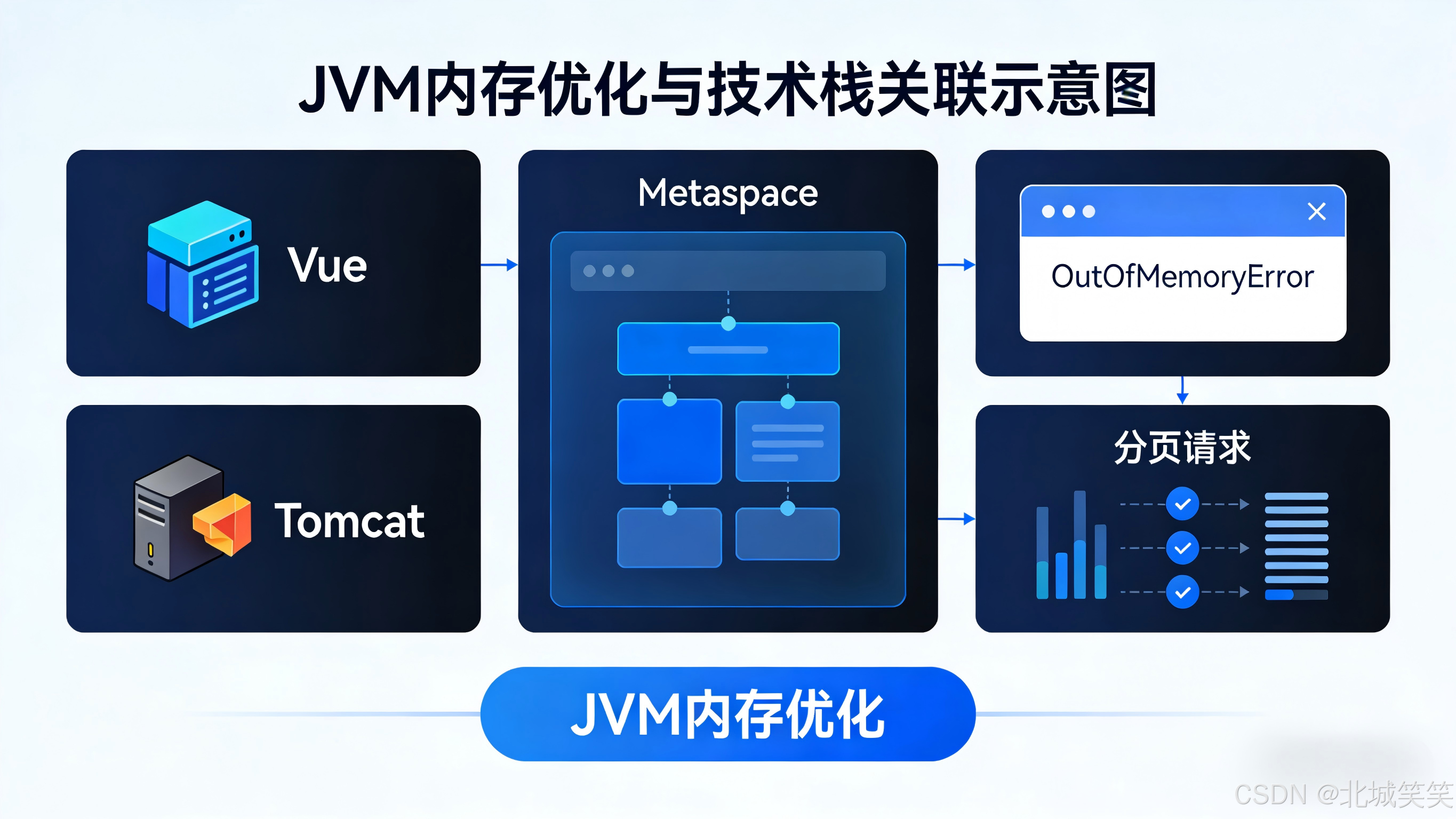
前后端交互 中,数据量控制 是性能优化 的核心。前端获取大量数据时,一次性请求全部数据 (如1000条)与分页请求 (如每次100条),看似数据总量相同,实则对系统内存 、稳定性影响巨大。
近期我们的「Vue 3 + Spring Boot + Tomcat 」项目,就因前端一次性请求1000条数据 ,导致Tomcat频繁报 Metaspace memory lack / OutOfMemoryError: Metaspace ,服务多次崩溃。
本文结合该真实故障案例 ,解析问题本质 、Metaspace机制 及分页实践 ,帮大家避坑。

一、问题背景及现象
1.1 故障场景与表现
在前端项目中页面需要展示大量数据(比如设备列表、历史记录、监控日志等),每次进入页面默认请求全部数据,数据量大约 1000 条。
原始实现中采用的是一次性请求所有数据的方式,代码如下(伪代码)(举例):
await axios.get('/api/data?limit=1000');
上线后故障频发:前端接口超时、页面卡顿;Tomcat日志报Metaspace溢出,服务每2~3小时崩溃一次。系统环境:JDK 8、Tomcat 9.0、Vue 3.2,未显式配置Metaspace阈值。
1.2 报错信息与定位
前端报错:
tomcat Metaspace memory lack Error {}
Tomcat 元空间内存不足错误 {} 。
Tomcat核心报错堆栈(关键截取):
java.lang.OutOfMemoryError: Metaspace at java.lang.ClassLoader.defineClass1(Native Method) at com.fasterxml.jackson.databind.ser.BeanSerializerFactory.createSerializer(BeanSerializerFactory.java:210) at com.fasterxml.jackson.databind.ObjectMapper.writeValue(ObjectMapper.java:3772) ...
通过JVisualVM监控发现:一次性请求1000条数据,Metaspace从200MB飙升至500MB+触发OOM;分页请求(每次100条)时,Metaspace稳定在250MB左右,故障消失。
二、技术分析与原理
2.1 内存结构
JVM内存结构(JDK8+)
Tomcat 的内存结构简述:Tomcat 是运行在 JVM 之上的 Servlet 容器。JVM 内存区域主要包括:
Heap(堆):用于存放 Java 对象。
Stack(栈):用于线程执行相关数据。
Metaspace(元空间) :JDK8 开始替代永久代(PermGen),专门用来存储类的元信息,如方法结构、常量池、类加载器等。
当 Metaspace 空间不足时,就会报出 java.lang.OutOfMemoryError: Metaspace,Tomcat 便无法再加载类或完成对象创建。
核心内存区域重点关注Metaspace:
| 内存区域 | 核心作用 | 溢出类型 |
|---|---|---|
| Heap(堆) | 存储Java对象实例 | OutOfMemoryError: Heap |
| Metaspace(元空间) | 存储类元信息(类结构、方法、类加载器等),替代永久代 | OutOfMemoryError: Metaspace |
关键:Metaspace使用本地内存,无默认上限,Tomcat类加载器回收滞后易放大内存压力。建议显式配置JVM参数(8G服务器示例):
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m -XX:+PrintMetaspaceStatistics
2.2 溢出成因
Metaspace溢出成因(结合业务)
Metaspace 溢出的成因:一般情况下,Metaspace 溢出常见原因有:
动态类加载器频繁创建新的类(如反射、大量动态代理)
接口调用过于频繁,堆积过多 class metadata 信息
数据处理过程消耗了大量的临时类结构或缓存类信息
短时间内处理过多数据,类加载器回收滞后
而在我们的场景中,由于一次性请求大量数据,后端需要:
查询并封装大量对象
执行 JSON 序列化,创建临时字段和结构类
快速、重复创建类元信息,导致 Metaspace 急剧上涨
一次性请求1000条数据,后端3个操作直接触发溢出:
数据库查询后创建1000个POJO,同时生成临时SQL执行类,元信息存入Metaspace;
Jackson序列化时,为每个复杂POJO动态生成
BeanSerializer,临时类元信息快速堆积;Tomcat类加载器回收滞后,无用类元信息无法被GC清理,Metaspace持续上涨突破阈值。
从而直接诱发了 Metaspace 报错。
分页请求的优势:分散临时类创建压力,给GC足够时间回收,使Metaspace保持稳定。
2.3 核心对比
两种请求方式核心对比:一次请求 vs 分页请求,本质对比
| 对比维度 | 一次请求1000条 | 每页请求100条,分10次 |
|---|---|---|
| 请求次数 | 1 次 | 10 次 |
| 单次数据量 | 高 | 小 |
| 后端瞬时内存压力 | 高 | 低 |
| JSON 解析和序列化负担 | 高 | 低 |
| 响应大小 | 大(MB级) | 小(KB级) |
| 前端解析耗时 | 高 | 低 |
| 易触发 GC 或类加载异常 | 是 | 否 |
| 可恢复性(如失败) | 差,需重试全部 | 好,可断点续传 |
| 用户体验 | 慢,可能崩溃 | 平稳流畅 |
具体原因:
| 对比维度 | 一次请求1000条 | 分页请求100条×10次 |
|---|---|---|
| Metaspace峰值 | 500MB+(OOM) | 250MB左右(稳定) |
| 前端响应时间 | 3~5s(卡顿) | 0.5~1s(流畅) |
| 失败恢复成本 | 重试全部数据 | 重试失败页码 |
| 服务器CPU占用 | 瞬时80%+ | 稳定30%左右 |
分页请求能够在客户端与服务端之间起到"负载均衡"的作用。一次处理 100 条数据,无论在 CPU、内存、IO 资源上都更为可控。
尤其在高并发系统中,分页还能有效防止:
单点高峰请求压垮服务
请求体过大导致 socket 拒绝连接
内存快速飙升带来崩溃风险
三、解决方案与实践
**分页请求的实现方式,**前端分页请求示例:
javascript
async loadCameraList() {
try {
// 根据当前模式选择API:搜索模式或常规分页获取
const api = this.isSearchMode ? SearchCameraContent : getCameraResourcePage;
// 每页请求的数据量
const pageSize = 200;
// 当前页码
let pageNo = 1;
// 存储所有页的相机列表数据
let allList = [];
// 循环获取所有页的数据,直到满足退出条件
while (true) {
// 设置分页参数
this.queryParams.pageNo = pageNo;
this.queryParams.pageSize = pageSize;
// 调用API获取数据
const response = await api(this.queryParams);
// 检查响应是否成功且包含有效数据
if (response.code === 200 && Array.isArray(response.data?.list)) {
const list = response.data.list;
const total = response.data.total || 0;
// 将当前页的数据添加到总列表中
allList.push(...list);
console.log(`第 ${pageNo} 页返回 ${list.length} 条数据,累计 ${allList.length}`);
// 判断是否已经拉取完所有数据:
// 1. 已获取的数据总数达到或超过总记录数
// 2. 当前页返回的数据为空
if (allList.length >= total || list.length === 0) {
break;
}
// 准备获取下一页
pageNo++;
} else {
// 处理请求失败或数据格式异常的情况
console.warn(`第 ${pageNo} 页请求失败或格式异常`);
break;
}
}
// 更新组件状态中的相机列表和总数
this.cameraPointList = allList;
this.total = allList.length;
} catch (error) {
// 统一错误处理
console.error('加载监控列表错误:', error);
}
}注意这里后端需支持分页接口。
⚠️ 注意:该方法不能根治问题,只能延缓溢出 ,根源仍在于数据量控制。分页虽能降低压力,但并非万能。若数据总量过大(如 10 万级),需结合滚动加载 、按需加载 等策略,避免前端累积过多数据导致浏览器崩溃。
四、进阶优化与指南
性能优化往往藏在细节里 。很多团队认为分页 只是用户体验问题,却忽视了它对系统稳定性 的影响。近期我们的Vue 3 + Spring Boot + Tomcat 项目,因前端一次性请求1000条数据 ,导致Tomcat频繁Metaspace溢出 ,服务每2~3小时崩溃一次 。监控显示:一次性请求时Metaspace从200MB飙升至500MB+ ,分页请求则稳定在250MB 。这让我们认识到:分页不是可选项,而是系统稳定的必选项。
✅ 后端开发者需设计良好的分页 API,避免默认全量返回;
✅ 前端请求时应默认分页,并提供加载更多按钮或懒加载机制;
❌ 避免一次性请求上千条数据并渲染,极易造成前端卡顿和后端崩溃;
✅ 添加合理的超时重试与失败提示机制,提高用户体验;
✅ 在高并发环境下可采用并发分页(如 Promise.all)但需限流控制;
⚠️ Tomcat 的 Metaspace 报错不是数据库慢,而是 JVM 内存机制触发;
⚠️ 分页请求不意味着总数据少,而是分段处理,核心是"可控处理压力"。
 分页不是可选项,而是必选项 。无论是后端接口设计 还是前端数据渲染 ,都应将分段处理 作为默认策略。记住:性能优化的本质是控制压力 ,而非单纯追求速度。建议团队将上述规范纳入代码审查清单 ,在需求评审阶段 就明确分页策略,从源头规避风险。只有前后端协同 、开发与运维配合 ,才能打造真正高可用、高性能的企业级应用。
分页不是可选项,而是必选项 。无论是后端接口设计 还是前端数据渲染 ,都应将分段处理 作为默认策略。记住:性能优化的本质是控制压力 ,而非单纯追求速度。建议团队将上述规范纳入代码审查清单 ,在需求评审阶段 就明确分页策略,从源头规避风险。只有前后端协同 、开发与运维配合 ,才能打造真正高可用、高性能的企业级应用。
五、本文总结
本文通过对"一次请求 1000 条"和"分页请求 100 条"的对比,我们深入理解了两种方式对服务端内存的不同影响,尤其是在高负载系统中,分页请求能显著降低 Tomcat 的瞬时压力,避免触发 Metaspace memory lack 错误。
本质上,分页是一种 分批处理、延迟加载、渐进式体验优化策略,在现代 Web 应用架构中属于基本实践标准。
建议:
在设计任何接口时,都应考虑数据量的上限与分页策略;
不仅是防崩溃,更是提升用户体验和系统可维护性的关键所在。
本次故障的核心原因:一次性请求大量数据导致临时类元信息堆积,触发Metaspace溢出。分页请求的本质是"削峰填谷",分散系统瞬时压力,让GC有时间回收无用资源,并非减少数据总量。
六、更多操作
更多 Vue 实战内容,请看,Vue 个人专栏
本文属于 Vue 企业级实战系列,持续更新 Vue2/Vue3、工程化、性能优化、跨域解决方案等干货,欢迎关注我的 CSDN 专栏:
👉 Vue Develop 实战专栏![]() https://blog.csdn.net/weixin_65793170/category_12116741.html
https://blog.csdn.net/weixin_65793170/category_12116741.html
如果本文对你有帮助,欢迎点赞、收藏、评论,你的支持是我持续输出实战干货的动力!
如果你在项目中也遇到类似问题,欢迎留言交流,分享你的场景与解决方案。
原创不易,转载请注明出处 | 关键词:Vue、Tomcat、Metaspace、OutOfMemoryError、分页请求、JVM内存优化
