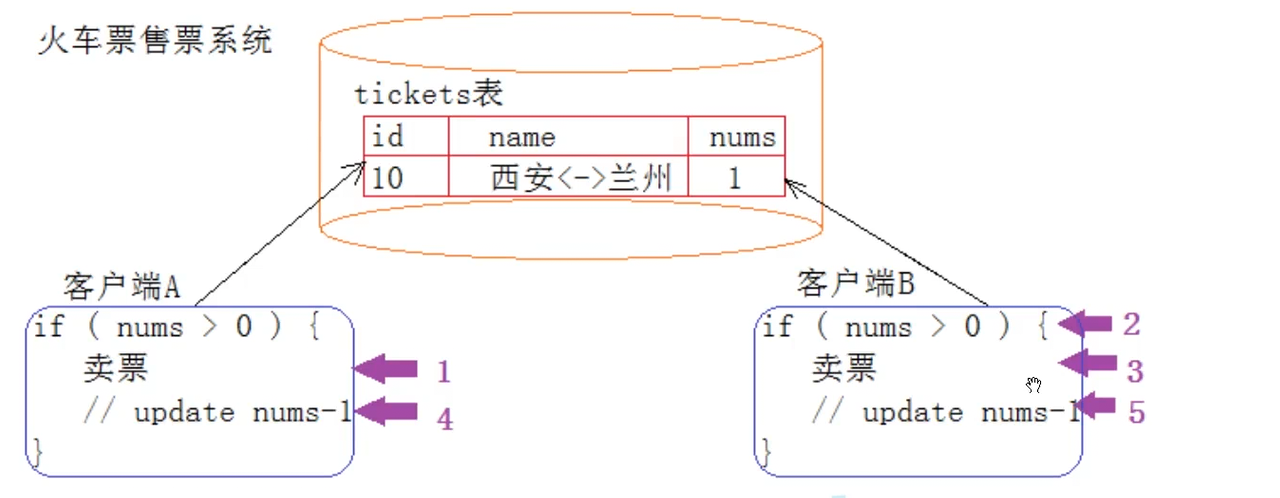
转账、买票,有一个中间过程,就比如说转账的时候转了100但是因为数据库有异常,最后没有转成功,但是用户的钱却被扣了,这时候我们的数据库就必须的回滚;一个数据库必定会被多种客户端去访问的;mysql是一个网络服务;mysql内部是以多线程来实现我们数据的存储的;所以会有对数据并发访问的场景,所以我们这种关系性数据库就为我们提供了事务这种概念;
不同的客户端访问
1.什么是事务
事务必须的站在mysql上层,所以事务是由一条或者多条mysql语句;事务就是一组DML语句组成,这些语句在逻辑上存在相关性 ,这一组DML语句要么全部成功,要么全部失败,是一个整体。MySQL提供一种机制,保证我们达到这样的效果。事务还规定不同的客户端看到的数据是不相同的。事务就是要做的或所做的事情,主要用于处理操作量大,复杂度高的数据。
假设一种场景:你毕业了,学校的教务系统后台 MySQL 中,不在需要你的数据,要删除你的所有信息(一般不会:) ), 那么要删除你的基本信息(姓名,电话,籍贯等)的同时,也删除和你有关的其他信息,比如:你的各科成绩,你在校表现,甚至你在论坛发过的文章等。这样,就需要多条 MySQL 语句构成,那么所有这些操作合起来,就构成了一个事务。
正如我们上面所说,一个 MySQL 数据库,可不止你一个事务在运行,同一时刻,甚至有大量的请求被包装成事务,在向 MySQL 服务器发起事务处理请求。而每条事务至少一条 SQL ,最多很多 SQL ,这样如果大家都访问同样的表数据,在不加保护的情况,就绝对会出现问题。甚至,因为事务由多条 SQL 构成,那么,也会存在执行到一半出错或者不想再执行的情况,那么已经执行的怎么办呢?
这就涉及到了我们刚才说的数据回滚了;
值得注意得是事务不止是一条条sql语句的集合,它还有自己的属性,分别是原子性、隔离性、持久性、一致性,而一致性是在上面三种特性存在的基础上天然就拥有的;
2.为什么要存在事务
事务被 MySQL 编写者设计出来,本质是为了当应用程序访问数据库的时候,事务能够简化我们的编程模型,不需要我们去考虑各种各样的潜在错误和并发问题.可以想一下当我们使用事务时,要么提交,要么回滚,我们不会去考虑网络异常了,服务器宕机了,同时更改一个数据怎么办对吧?因此事务本质上是为了应用层服务的。而不是伴随着数据库系统天生就有的.
3.事务的支持版本
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务, MyISAM 不支持。
如何产看数据库引擎

3.事务的常见操作
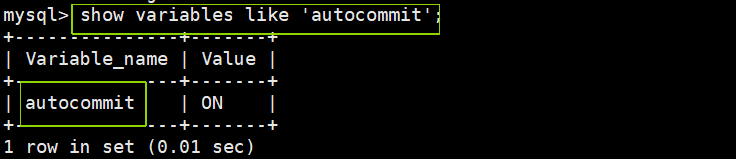
3.1查看事务是否自动提交
事务的提交方式分为两种:手动提交、自动提交
未commit,客户端崩溃,MySQL自动会回滚;
commit了,客户端崩溃,MySQL数据不会在受影响,已经持久化
begin操作会自动更改提交方式,不会受MySQL是否自动提交影响
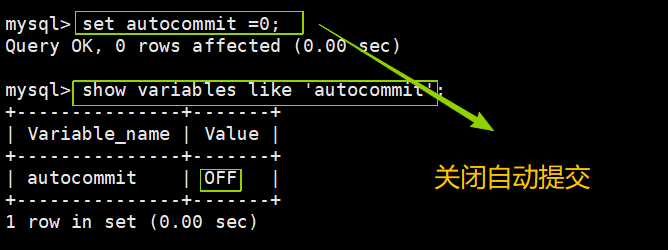
. 如果我们自己begin了,就必须自己commit,如果我们没有begin会进行系统的自动提交方式;当条sql和事务的关系autocmmit会影响我们之前写的事务,每一条sql其实就是一个事务,如果我们把autocommit关闭掉,当服务器挂掉之后,我们写的sql语句会回滚,但是如果我们将autocommit开启,当我们的把服务器挂掉之后,我们的sql语句会自动提交;
3.1.1关闭自动提交
3.2事务的开始
sql
start transcation;或者
sql
begin;一旦输入事务的开始,下面的sql语句都属于这个事务,直到事务结束
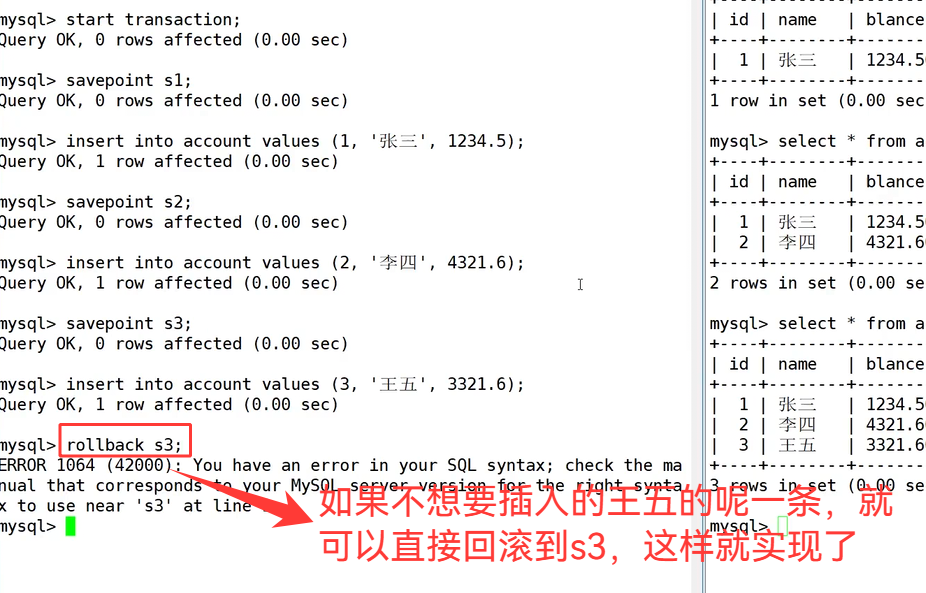
3.3 创建保存点/回滚保存点
sql
savepoint save 1;
sql
rollback to save1;如果没有设置保存点,也可以回滚,只能回滚到事务的开始。直接使用 rollback(前提是事务
还没有提交)如果一个事务被提交了(commit),则不可以回退(rollback);
3.4 总结
只要输入begin或者start transaction,事务便必须要通过commit提交,才会持久化,与是
否设置set autocommit无关。事务可以手动回滚,同时,当操作异常,MySQL会自动回滚
对于 InnoDB 每一条 SQL 语言都默认封装成事务,自动提交。(select有特殊情况,因为
MySQL 有 MVCC )
4.事务的隔离(隔离是指"运行中的事务"的术语)
4.1如何理解事务的隔离性
MySQL服务可能会同时被多个客户端进程(线程)访问,访问的方式以事务方式进行,一个事务可能由多条SQL构成,也就意味着,任何一个事务,都有执行前,执行中,执行后的阶段。而所谓的原子性,其实就是让用户层,要么看到执行前,要么看到执行后。执行中出现问题,可以随时回滚。所以单个事务,对用户表现出来的特性,就是原子性。但是毕竟所有事务都要有个执行过程,那么在多个事务各自执行多个SQL的时候,就还是有可能会出现互相影响的情况。
比如:多个事务同时访问同一张表,甚至同一行数据。就如同你妈妈给你说:你要么别学,要学就学到最好。至于你怎么学,中间有什么困难,你妈妈不关心。那么你的学习,对你妈妈来讲,就是原子的。那么你学习过程中,很容易受别人干扰,此时,就需要将你的学习隔离开,保证你的学习环境是健康的。
数据库中,为了保证事务执行过程中尽量不受干扰,就有了一个重要特征:隔离性数据库中,允许事务受不同程度的干扰,就有了一种重要特征:隔离级别
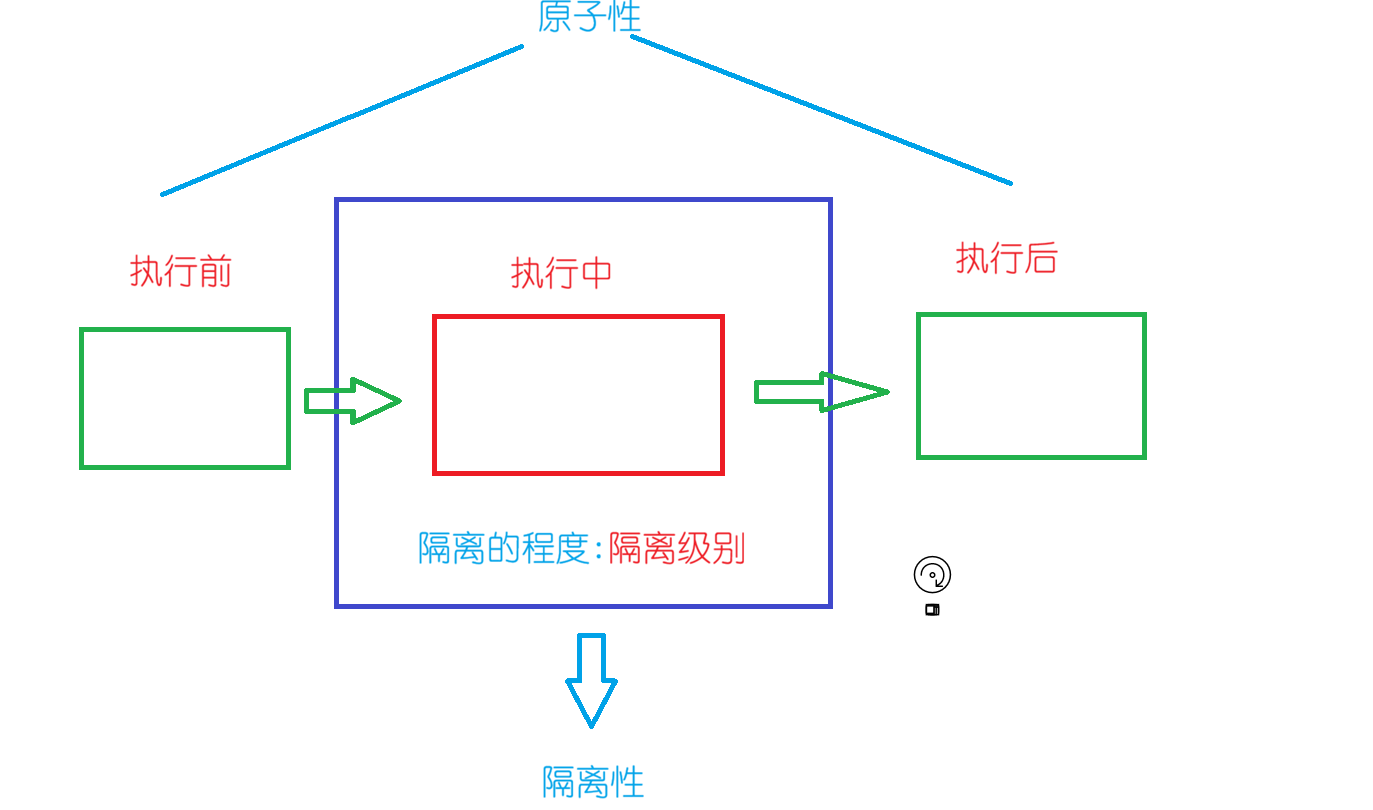
4.2 事务的隔离级别
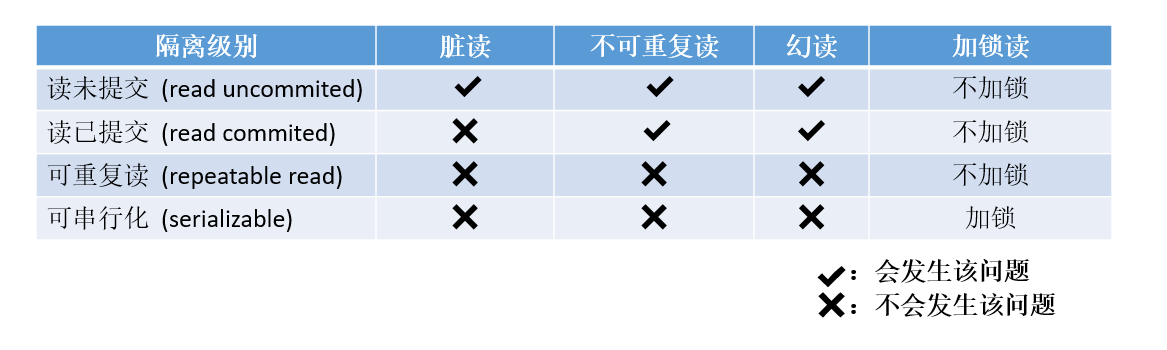
4.2.1读未提交【Read Uncommitted】
如果想理解可以认为未提交读 ,就是一个事务在另外一个事务执行的时候就能读到他的变化,这种现象叫做脏读 ,在该隔离级别,所有的事务都可以看到其他事务没有提交的行结果。(实际生产中不可能使用这种隔离级别的),相当于没有任何隔离性,也会有很多并发问题,如脏读,幻读,不可重复读等;
幻读
虽然大部分内容是可重复读的,但是insert的数据在可重复读情况被读取出来,导致多次查找时,会多查找出来新的记录,就如同产生了幻觉。这种现象,叫做幻读
不可重复读
即一个事务执行时,如果多次 select, 可能得到不同的结果。
4.2.2读提交【Read Committed】
该隔离级别是大多数数据库的默认的隔离级别(不是 MySQL 默认的)。它满足了隔离的简单定义:一个事务只能看到其他的已经提交的事务所做的改变。这种隔离级别会引起不可重复读;
4.2.3 可重复读【Repeatable Read】
这是 MySQL 默认的隔离级别,它确保同一个事务,在执行中,多次读取操作数据时,会看到同样的数据行。但是会有幻读问题。
4.2.4串行化【Serializable】
这是事务的最高隔离级别,就是一个一个的事务根据来的时间一个一个进行,一个结束再执行另一个;它通过强制事务排序,使之不可能相互冲突,从而解决了幻读的问题。它在每个读的数据行上面加上共享锁,。但是可能会导致超时和锁竞争(这种隔离级别太极端,实际生产基本不使用)对所有操作全部加锁,进行串行化,不会有问题,但是只要串行化,效率很低,几乎完全不会被采用
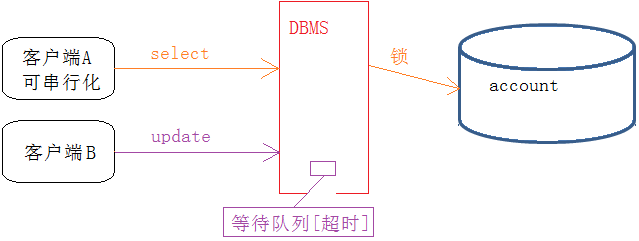
4.3总结
其中隔离级别越严格,安全性越高,但数据库的并发性能也就越低,往往需要在两者之间找一个平
衡点。不可重复读的重点是修改和删除:同样的条件, 你读取过的数据,再次读取出来发现值不一样了幻读的重点在于新增:同样的条件, 第1次和第2次读出来的记录数不一样说明: mysql 默认的隔离级别是可重复读,一般情况下不要修改上面的例子可以看出,事务也有长短事务这样的概念。事务间互相影响,指的是事务在并行执行的时候,即都没有commit的时候,影响会比较大。
4.4设置隔离级别

