文章目录
前言
在语言、机器翻译等核心序列任务中,RNN及其门控变体(LSTM, GRU)大家应该很熟悉了,也见的比较多了。传统循环神经在实际工程实现中,处理变长序列所需的繁琐对齐与填充操作,使其在计算资源利用率上大打折扣。随着深度学习迈向大规模预训练时代,Transformer 模型,完全抛弃了传统的循环结构,引入了自注意力机制(Self-Attention),这个就是它的核心。那么下文带你深入了解 Transformer 模型。
Transformer 论文地址: Attention Is All You Need
Transformer 结构
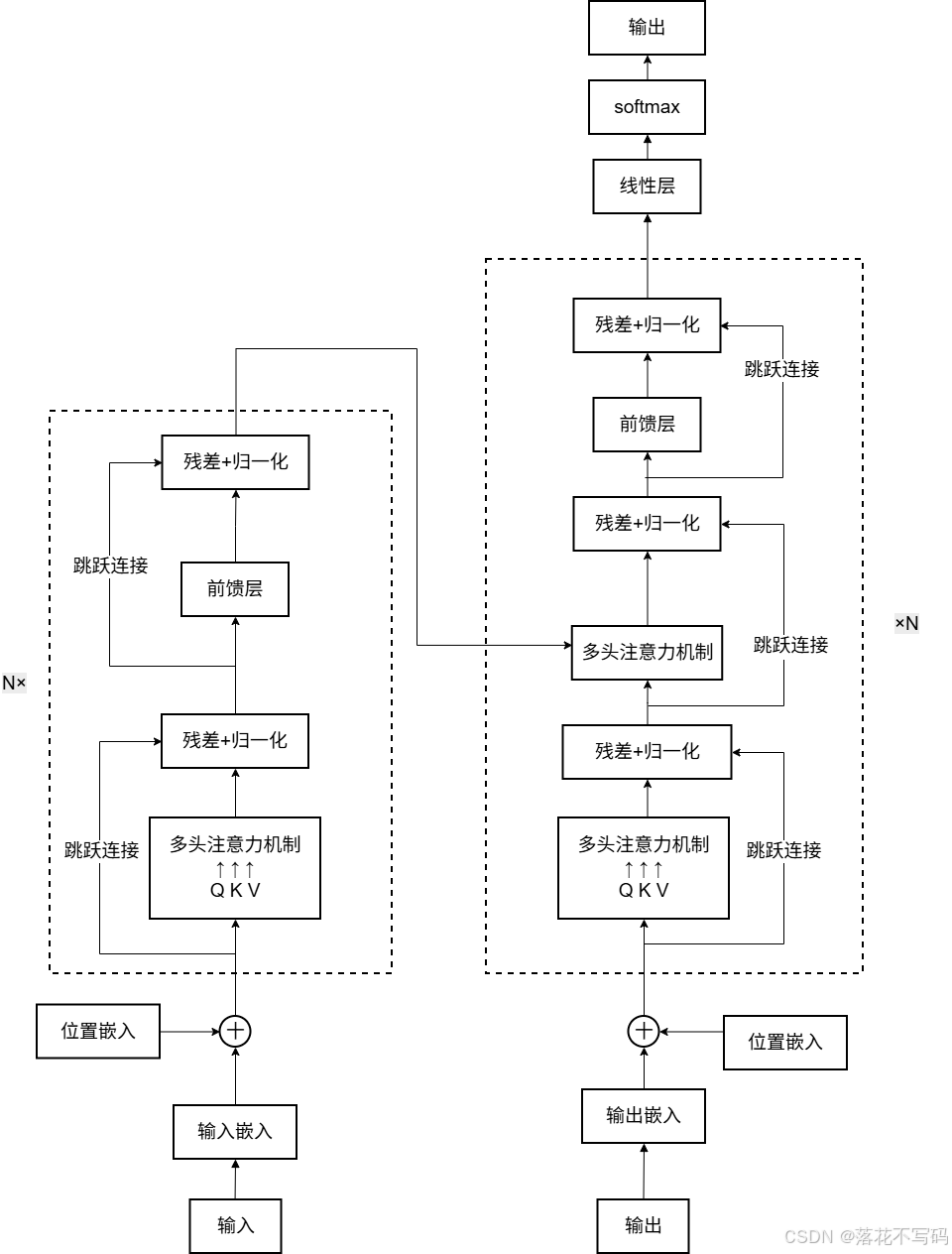
Transformer 模型结构如图下图所示(摘自论文),整体结构可以分为编码和解码两部分,输入编码器的数据是输入向量序列,输出也是大小相同的向量序列。
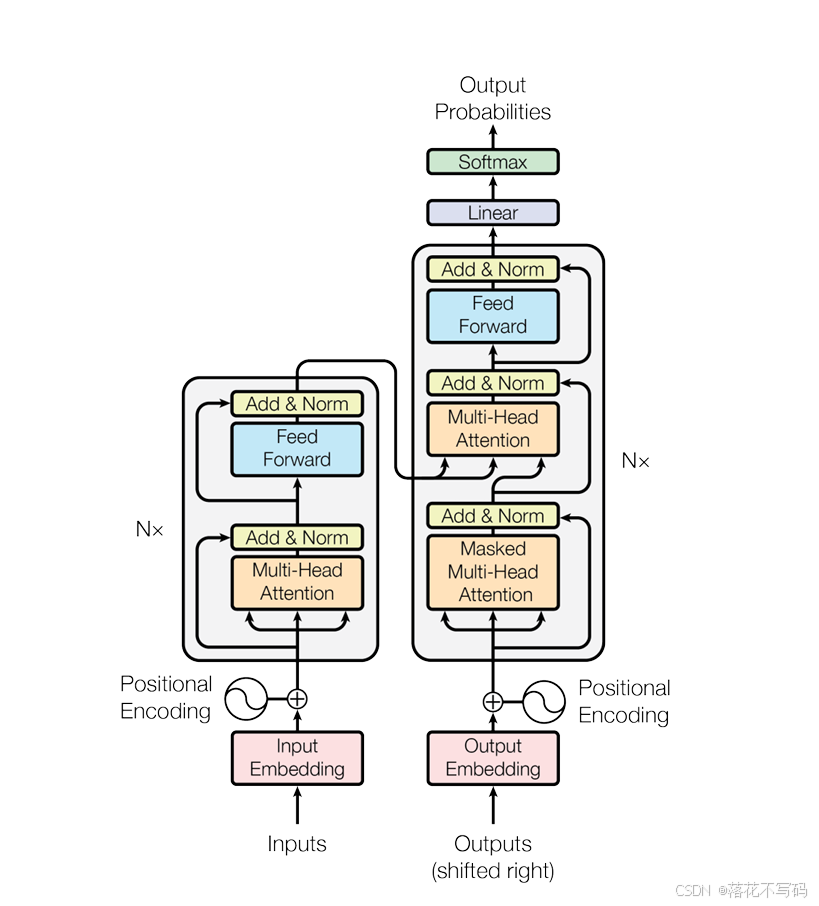
中文图如下:
⚡⚡编码器(Encoder)
编码器负责将输入序列编码为连续表示,解码器则用于将这些表示转换为输出序列。在编码器中,主要包括多头自注意力层、前馈全连接层以及残差和归一化层。多头自注意力层包含多个自注意力头,它们分别学习不同的注意力表示,用于在输入序列中捕获全局依赖关系,允许模型同时关注序列中的所有位置。前馈全连接层可以对每个位置的表示进行非线性转换。为了防止深层网络训练中的梯度消失或梯度爆炸问题,每个子层都引入了残差连接,将输入与输出相加,从而使信息能够更容易地在网络中流动。在每个编码器层中,对自注意力机制和前馈全连接网络的输出进行层归一化,以加速训练过程并提高模型的稳定性。
☑️多头自注意力层 (Multi-Head Self-Attention)
注意力机制本质上是从大量信息中筛选出少量重要信息并聚焦,忽略不重要的部分。在自注意力机制中,查询(Q)、键(K)和值(V)均来自同一输入矩阵的线性变换 。多头自注意力层包含多个自注意力头,自注意力机制在处理序列数据时,不仅仅依赖相邻位置的元素,而且每个元素都与序列中的其他所有元素建立关联。具体而言,对于序列中的每个元素,自注意力机制计算与其他元素之间的相似度,并将这些相似度归一化为注意力权重。然后,通过将每个元素与对应的注意力权重进行加权求和,得到自注意力机制的输出。模型同时关注序列中的所有位置,获得比传统 CNN 更大的感受野和更丰富的上下文信息。自注意力机制如下图所示:
查询
...
注意力值
键值1
信息值1
键值2
信息值2
键值n
信息值n
...
...
如何在计算出注意力分数后,正确地叠加 key_padding_mask(处理变长句子的填充)和 attn_mask(处理因果生成的防偷看)。双 Mask 支持的 Multi-Head Attention 核心代码如下:
python
import torch
import torch.nn as nn
import math
class MaskedMultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, dropout: float = 0.1):
super().__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
# 线性投影层
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor,
attn_mask: torch.Tensor = None,
key_padding_mask: torch.Tensor = None):
"""
q: [Batch, T_q, d_model] - Query 序列
k: [Batch, T_k, d_model] - Key 序列
v: [Batch, T_k, d_model] - Value 序列
attn_mask: [T_q, T_k] 或 [Batch, num_heads, T_q, T_k] - 因果/结构掩码。True 表示被遮挡(填入 -inf)
key_padding_mask: [Batch, T_k] - 填充词掩码。True 表示该位置是 Padding(填入 -inf)
"""
B, T_q, _ = q.size()
_, T_k, _ = k.size()
# 形状变化: (B, T, d_model) -> (B, T, num_heads, head_dim) -> (B, num_heads, T, head_dim)
Q = self.q_proj(q).view(B, T_q, self.num_heads, self.head_dim).transpose(1, 2)
K = self.k_proj(k).view(B, T_k, self.num_heads, self.head_dim).transpose(1, 2)
V = self.v_proj(v).view(B, T_k, self.num_heads, self.head_dim).transpose(1, 2)
# 结果形状: (B, num_heads, T_q, T_k)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.head_dim)
if attn_mask is not None:
scores = scores.masked_fill(attn_mask == True, float('-inf'))
if key_padding_mask is not None:
key_padding_mask = key_padding_mask.unsqueeze(1).unsqueeze(2)
scores = scores.masked_fill(key_padding_mask == True, float('-inf'))
attn_weights = torch.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
out = torch.matmul(attn_weights, V)
out = out.transpose(1, 2).contiguous().view(B, T_q, self.d_model)
out = self.out_proj(out)
return out, attn_weights
if __name__ == "__main__":
B, T_q, T_k, d_model = 2, 4, 4, 16
mha = MaskedMultiHeadAttention(d_model=d_model, num_heads=4)
# 模拟输入序列
q = torch.randn(B, T_q, d_model)
k = torch.randn(B, T_k, d_model)
v = torch.randn(B, T_k, d_model)
# 比如在生成第 2 个词时,不能看到第 3、4 个词
causal_mask = torch.triu(torch.ones(T_q, T_k, dtype=torch.bool), diagonal=1)
# 假设 Batch 中第一句话真实长度为 4,第二句话真实长度为 2 (后两个是 PAD)
pad_mask = torch.tensor([
[False, False, False, False], # 第一句没有 PAD
[False, False, True, True] # 第二句后两个词是 PAD,需要屏蔽
])
out, weights = mha(q, k, v, attn_mask=causal_mask, key_padding_mask=pad_mask)
print("注意力权重矩阵形状:", weights.shape) # [2, 4, 4, 4] -> [B, num_heads, T_q, T_k]
print("\nBatch 0, Head 0 的注意力权重 (无 PAD 影响,仅受 Causal Mask 限制,右上角为 0):")
print(torch.round(weights[0, 0] * 100) / 100)
print("\nBatch 1, Head 0 的注意力权重 (受 PAD 影响,最后两列被强制置为 0):")
print(torch.round(weights[1, 0] * 100) / 100)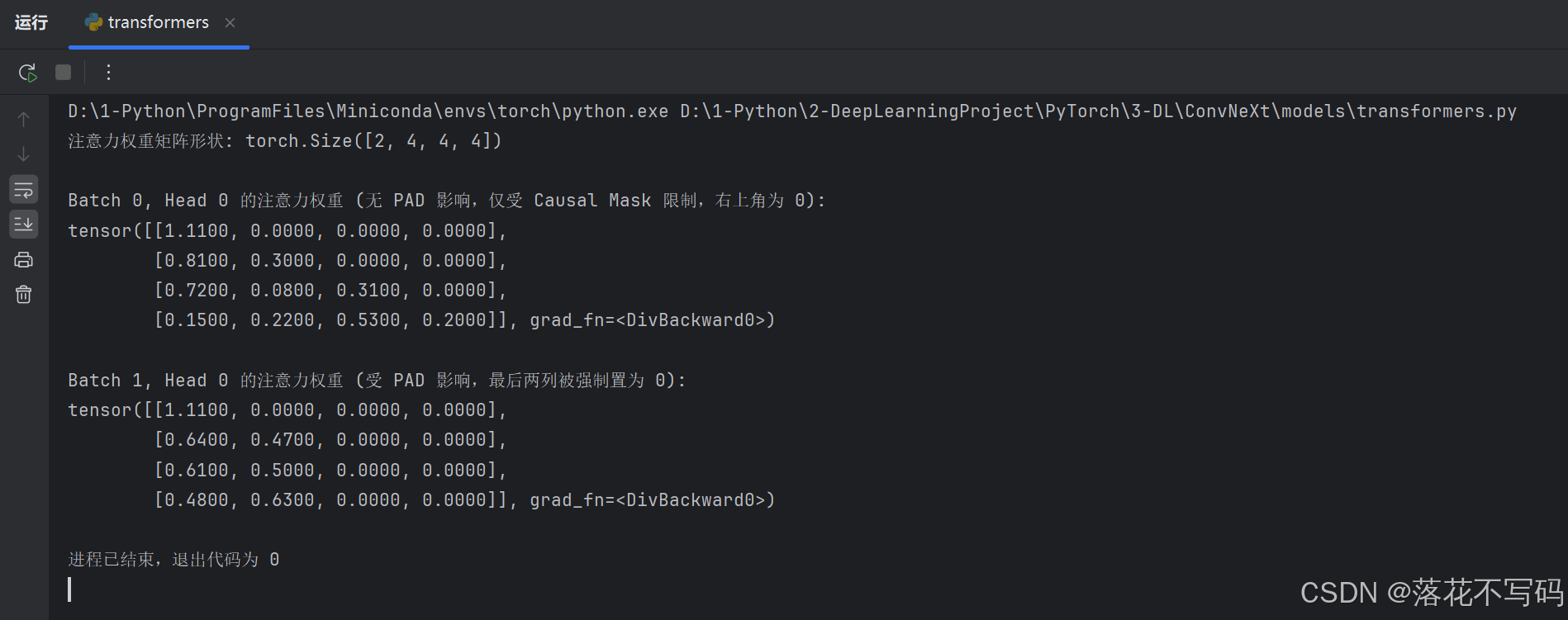
☑️前馈全连接层 (Feed-Forward Network)
在注意力层之后,每个位置的表示都会经过一个前馈全连接层。该层对每个位置进行独立且相同的非线性转换 。它通常包含两次线性变换,并在中间使用 ReLU 激活函数 。
☑️残差连接与层归一化 (Add & Norm)
为了防止深层网络训练中可能出现的梯度消失或梯度爆炸问题,每个子层(包括自注意力层和前馈层)都引入了残差连接,直接将输入与输出相加,使信息更容易在网络中流动 。随后进行层归一化(Layer Normalization),这能有效加速训练过程并提高模型的稳定性 。
⚡⚡解码器 (Decoder)
解码器同样由 N = 6 N=6 N=6 个相同的层堆叠而成,用于将编码器的连续表示转换为最终的输出序列 。除了包含与编码器相同的两个子层外,解码器还引入了一个关键的自注意力变体:
☑️掩码多头自注意力层 (Masked Multi-Head Attention)
在处理当前位置时,必须防止信息"向左流动"以保持自回归特性 。通过掩码操作(将非法连接对应的值设为 − ∞ -\infty −∞),确保位置 i i i 的预测只能依赖于已知的小于 i i i 的输出 。
☑️编码器-解码器多头注意力层 (Encoder-Decoder Attention)
该层的查询(Q)来自前一个解码器层,而键(K)和值(V)则来自编码器的输出 。这种设计使得解码器中的每个位置都能关注到输入序列中的所有相关位置,模仿了传统的编码器-解码器对齐机制 。
⚡⚡计算公式
最常用的注意力计算方法是通过向量点积计算相似性,并使用 Softmax 函数进行归一化。为了防止点积结果过大导致 Softmax 梯度趋近于零,Transformer 引入了缩放因子。
- 注意力值的计算过程如下公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V Attention(Q,K,V)=softmax(dk QKT)V
公式解释:
- Q Q Q (Query / 查询矩阵):代表当前正在处理的词元(Token)特征,用来去和序列中的其他词"寻找关联"。
- K K K (Key / 键矩阵) :代表序列中所有词元的特征,用来与 Q Q Q 进行匹配。
- V V V (Value / 值矩阵) :代表词元的实际内容信息。最终输出就是这些 V V V 的加权和。
- Q K T QK^T QKT : Q Q Q 和 K K K 的点积操作。这计算了当前词与其他所有词的相似度得分(相关性)。得分越高,说明两个词的联系越紧密。
- d k d_k dk :是 K K K 向量的维度大小。
- d k \sqrt{d_k} dk (缩放因子) :当维度 d k d_k dk 很大时,点积结果 Q K T QK^T QKT 的方差会变得极大,导致 Softmax 函数进入梯度极小的饱和区(即"梯度消失")。除以 d k \sqrt{d_k} dk 可以将方差拉回稳定范围,保持训练时的梯度健康。
- s o f t m a x softmax softmax:将点积得分转换为概率分布(即注意力权重),确保所有权重的和为 1。
- 乘以 V V V :根据 Softmax 算出的权重,对所有的 V V V 进行加权求和,提取出当前词最需要关注的上下文信息。
- 多头注意力 (Multi-Head Attention):
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O MultiHead(Q,K,V)=Concat(head_{1},...,head_{h})W^{O} MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_{i}=Attention(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V}) headi=Attention(QWiQ,KWiK,VWiV)
公式解释:
- W i Q , W i K , W i V W_i^Q, W_i^K, W_i^V WiQ,WiK,WiV :分别是第 i i i 个"注意力头"专属的线性映射权重矩阵。模型不直接使用原本的 Q , K , V Q, K, V Q,K,V,而是通过这些矩阵将它们投影到不同的低维子空间中。
- h e a d i head_i headi :在第 i i i 个子空间中独立计算出的注意力结果。多头机制的核心作用是允许模型同时从不同的表征子空间(例如:有的头关注语法结构,有的头关注语义指代)中捕捉多种维度的信息。
- C o n c a t Concat Concat :将所有 h h h 个注意力头(从 h e a d 1 head_1 head1 到 h e a d h head_h headh)的计算结果在特征维度上拼接起来。
- W O W^O WO:最终的线性输出映射矩阵。用于将拼接后的高维向量重新融合,并转换回模型下一层所预期的标准维度。
- 前馈网络 (Feed-Forward Network, FFN):
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=\max(0,xW_{1}+b_{1})W_{2}+b_{2} FFN(x)=max(0,xW1+b1)W2+b2
公式解释:
- x x x:上一层(通常是多头注意力层经过残差连接和层归一化后)的输出向量。
- W 1 , b 1 W_1, b_1 W1,b1:第一层线性变换(全连接层)的权重和偏置。在标准的 Transformer 中,这一步通常会将特征维度显著放大(例如放大 4 倍),以便在更高维的空间中提取更丰富的特征。
- max ( 0 , . . . ) \max(0, ...) max(0,...) :这是 ReLU 激活函数(Rectified Linear Unit)。它为网络引入了非线性,使得模型有能力拟合极其复杂的函数。没有它,整个网络就只是线性的矩阵乘法。
- W 2 , b 2 W_2, b_2 W2,b2:第二层线性变换的权重和偏置。它的作用是将经过非线性激活和高维提取后的特征,重新降维映射回模型原本的维度大小。
总结
后续更多实战项目,持续更新中,相关的 Transformer 模型实战如下:
模型训练篇 | 图像分类识别篇 | Swin Transformer 实战教程:手把手带你训练自己的数据集(附完整源码+数据集)
模型训练篇 | 图像分类识别篇 | Vision Transformer (ViT) 实战教程:手把手带你训练自己的数据集(附完整源码+数据集)