当人们还在吐槽Mac 只能办公不能玩大型3A游戏的时候,国外开发者 ScottJG 干了一件事:把一块 600W 功耗的桌面级 RTX 5090 显卡,接到了只有 22W 功耗、连风扇都没有的 M4 MacBook Air 上。
更离谱的是,他不仅让显卡成功工作,还在这台轻薄本上跑通了《赛博朋克 2077》《孤岛危机重制版》等 3A 大作,甚至让本地大语言模型的推理速度暴涨了 6.5 倍。
ChatGPT 一开始就给他泼了冷水:"这在今天没有任何实际可行性,最多只能作为边缘研究项目。" 但 ScottJG 的人生信条恰好是:"边缘可行性,就是我的舒适区。"
为什么 Mac 外接 eGPU 是个难题?
先给大家科普一个冷知识:Thunderbolt 接口本质上是把 PCIe 信号封装在 USB-C 线缆里传输。理论上,只要你的电脑有 Thunderbolt 口,就能外接任何 PCIe 设备,包括显卡。

在 Windows 和 Linux 上,eGPU 几乎是插上去就能用。但在苹果芯片的 Mac 上,这件事从根上就被堵死了:
-
macOS 根本没有 NVIDIA/AMD 显卡的驱动
苹果铁了心要推自己的 Metal 生态,完全放弃了对第三方桌面显卡的支持
-
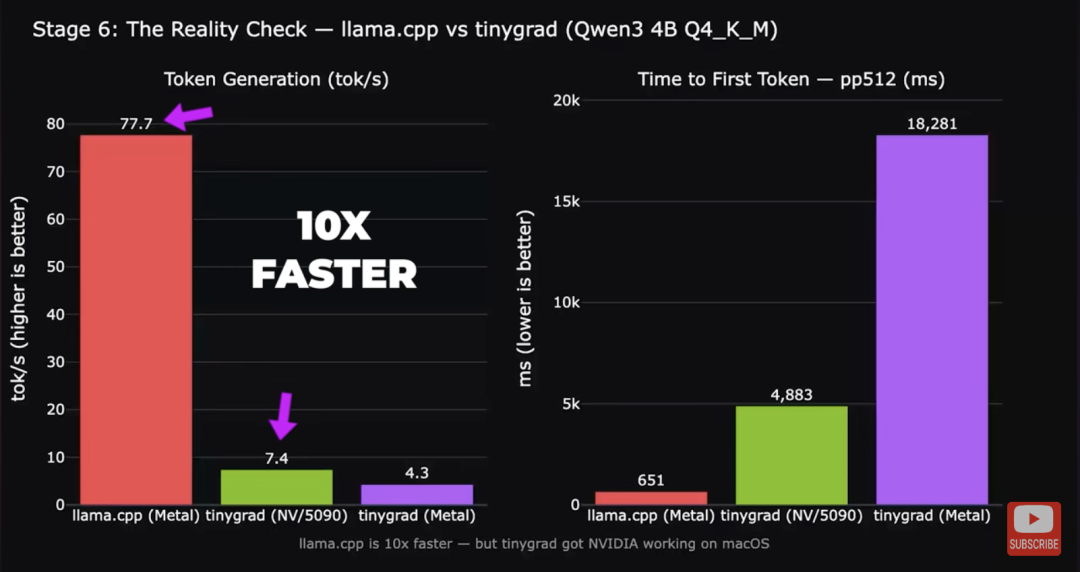
市面上唯一的第三方方案 tinygrad,性能比 M4 自带的集成 GPU 还慢 10 倍,而且只能跑 tinygrad 自己的 AI 框架
-
苹果芯片的 Linux 原生系统至今不支持 Thunderbolt,只能用 USB3
ScottJG 想到了一个曲线救国的方案:在 macOS 上跑一个 ARM 架构的 Linux 虚拟机,然后把 RTX 5090 通过 PCIe 直通技术,直接 "塞" 进这个虚拟机里。
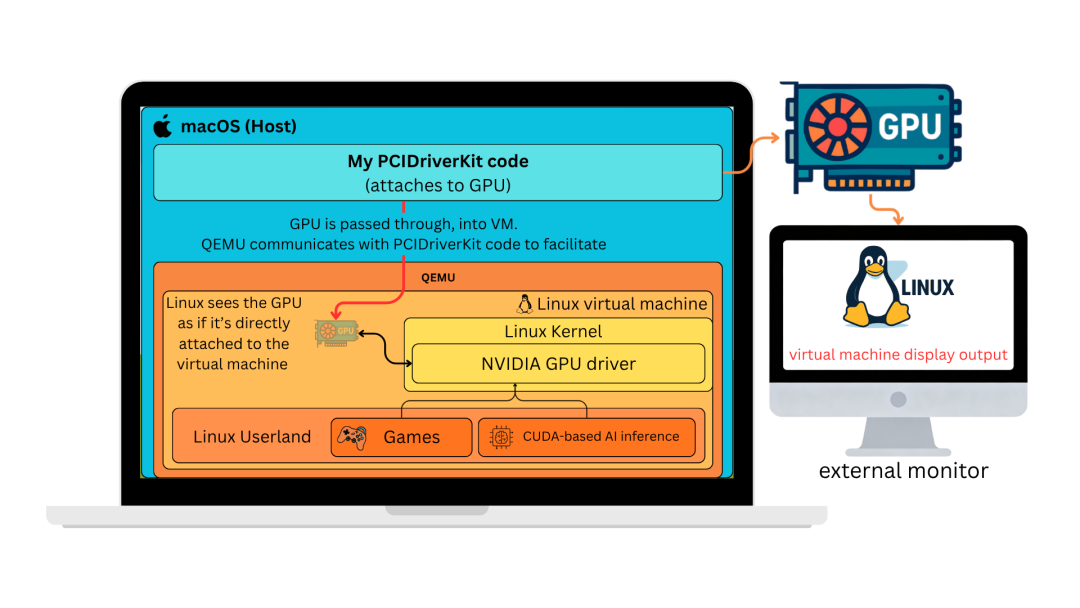
听起来简单,但为了让这个方案跑通,他几乎重构了整个虚拟化栈。
为了让显卡工作,他改了半个系统
整个项目的核心难点,在于解决苹果芯片和标准 PCIe 设备之间的兼容性问题。ScottJG 踩过的坑,足以写一本《macOS 内核崩溃大全》。
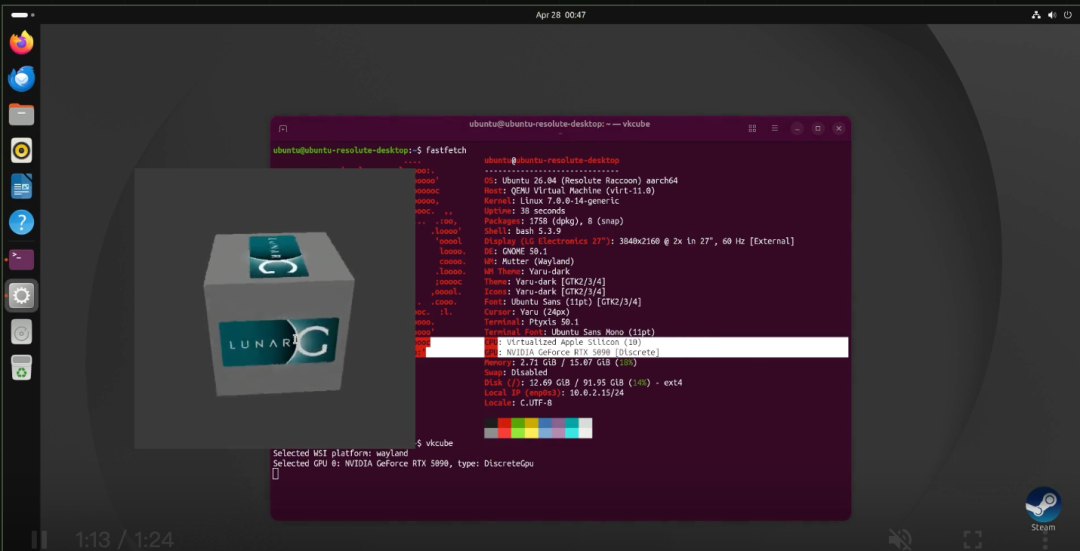
第一个坑:一碰显卡内存,系统就死机
显卡和电脑通信,靠的是一块叫 "PCI BAR" 的专用内存区域。理论上,只要把这块内存映射到虚拟机里,虚拟机就能直接控制显卡。

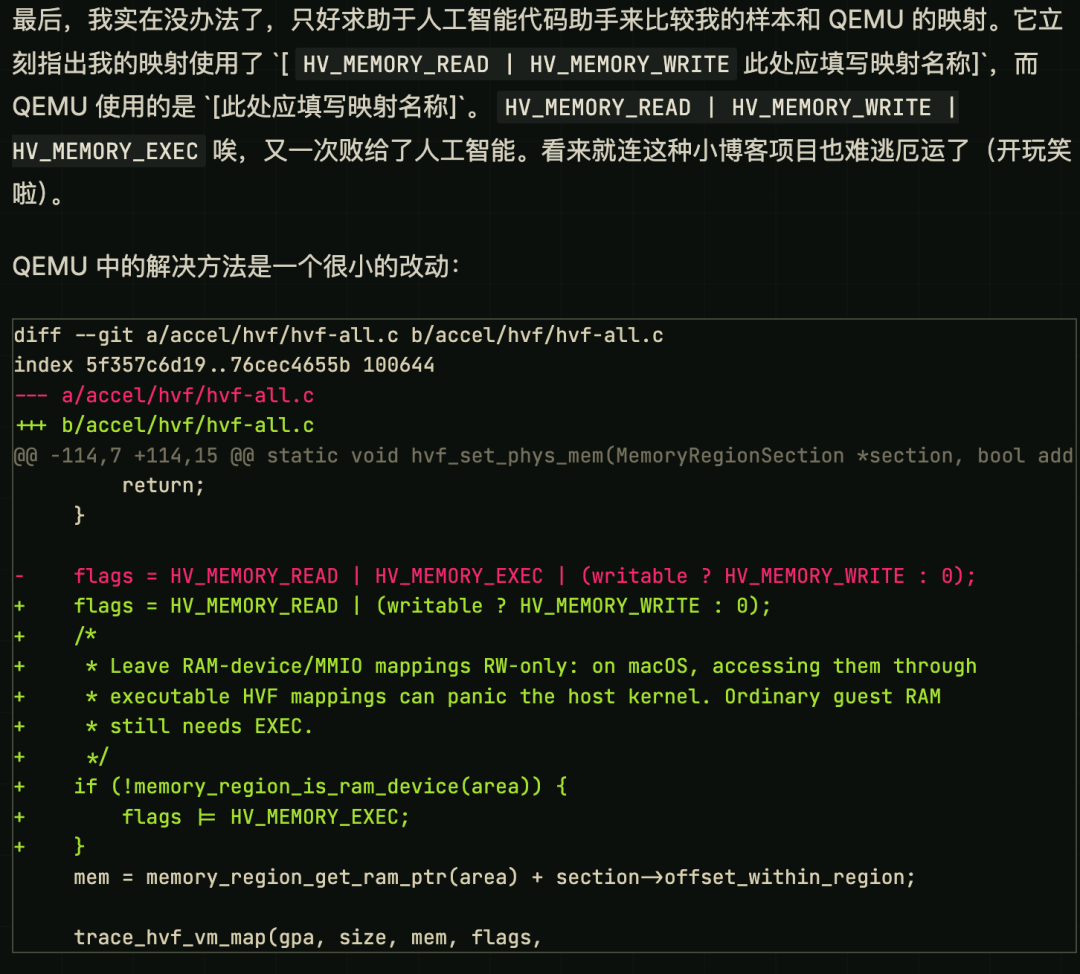
但 ScottJG 发现,只要虚拟机一碰这块内存,整个 macOS 主机就会立刻内核崩溃。经过无数次调试和 AI 辅助对比,他终于找到了问题:QEMU 默认给所有内存都加了可执行权限,而 macOS 的 Hypervisor 框架不允许设备内存被执行。
修改一行代码,问题解决。
但这只是开胃菜。
第二个坑:苹果DART限制死了性能
显卡最依赖的功能叫 DMA(直接内存访问),可以让显卡不经过 CPU,直接读写电脑的内存。这就像给显卡开了一条直达内存的快递通道。
但苹果在芯片里加了一个叫 DART 的硬件单元

而且限制极其苛刻:
-
单次最多只能映射 1.5GB 内存(现代游戏随便就要 8-16GB)
-
最多只能同时存在 64000 个映射条目
-
完全不能控制内存地址和对齐方式
为了绕过这个限制,ScottJG 发明了一个叫apple-dma-pci的虚拟 PCI 设备。

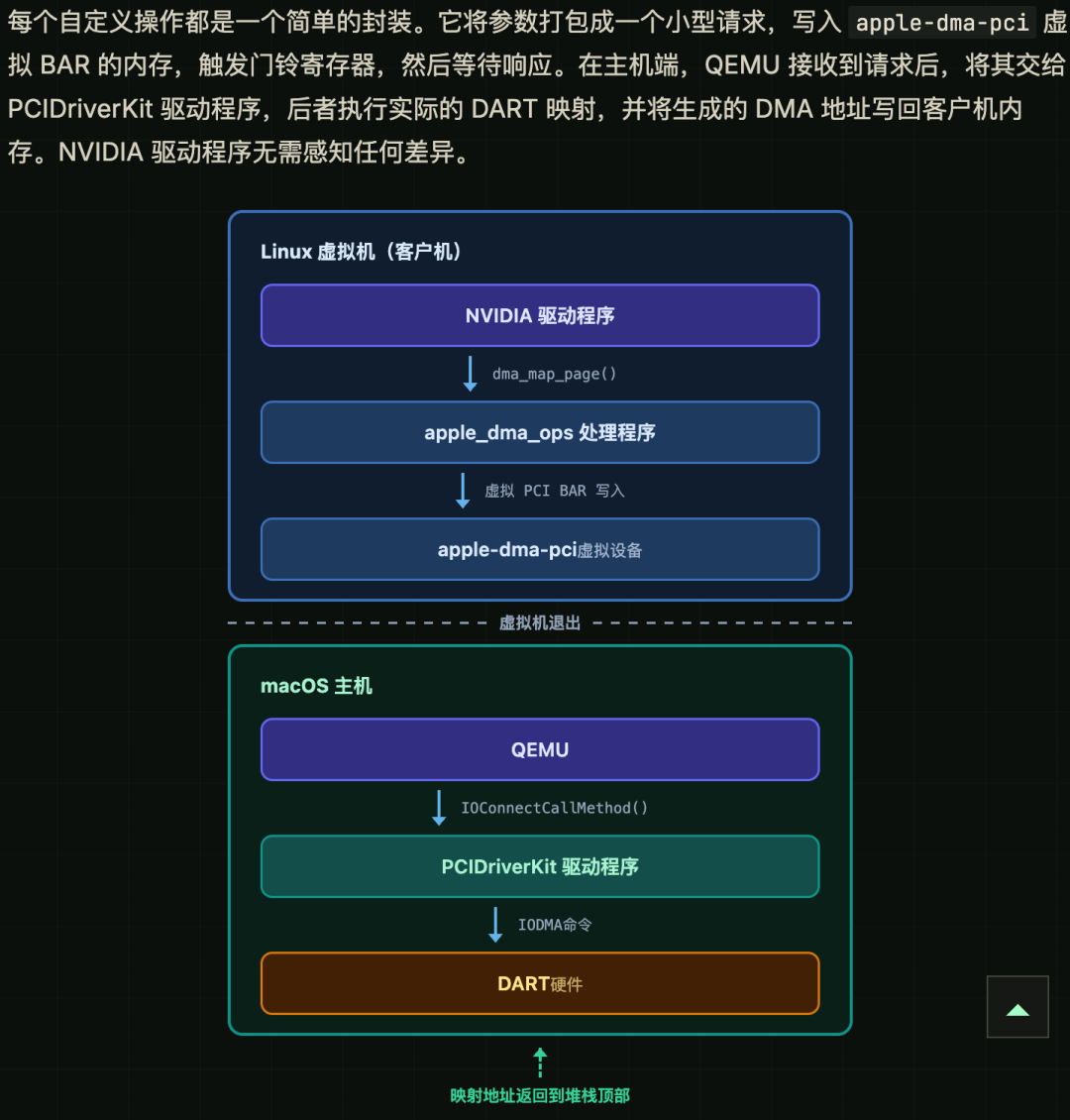
它是个中转站:
-
不一次性映射所有虚拟机内存,只映射显卡当前正在用的缓冲区
-
把大量 4KB 的小映射合并成 256KB 的大映射,直接把映射数量减少了 4 倍
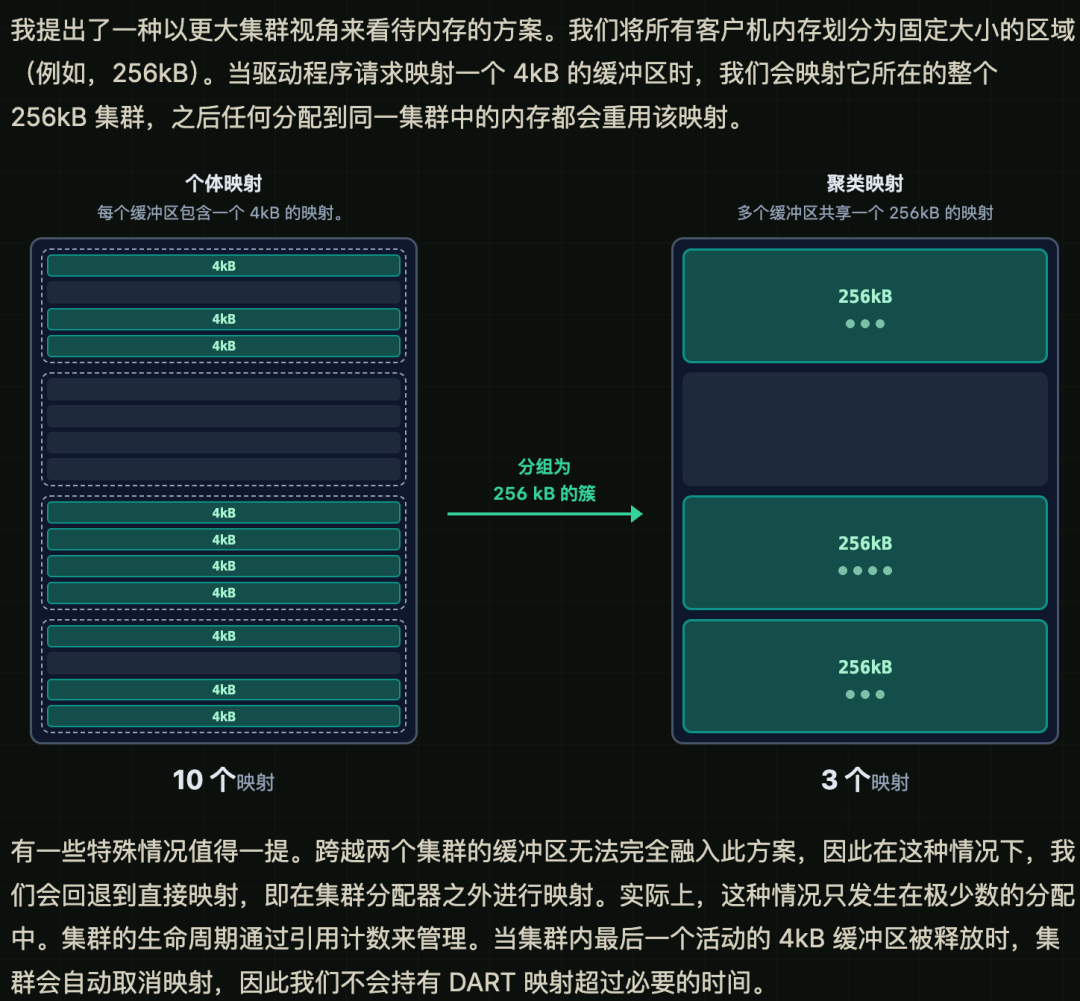
-
用 Linux 内核的 kprobes 功能,给 NVIDIA 驱动打了个热补丁,解决了内存对齐问题
第三个坑:x86 游戏模拟的致命缺陷
解决了显卡问题,还有最后一座大山:几乎所有 PC 游戏都是 x86 架构的,而 Mac 是 ARM 架构。要运行这些游戏,需要用 FEX-Emu 把 x86 指令翻译成 ARM 指令。
但 x86 和 ARM 的内存排序规则完全不同。如果直接翻译,游戏会随机崩溃。好在苹果在 macOS 15 中加入了硬件级的 TSO(全存储排序)模式,可以让 ARM 芯片模拟 x86 的内存行为。
ScottJG 把这个功能集成到了 QEMU 里,终于让游戏稳定运行了起来。
实测结果:22W 轻薄本真的能玩 3A?
最激动人心的时刻来了:这台组合电脑的实际表现到底怎么样?ScottJG 用《赛博朋克 2077》做了最全面的测试,对比了 6 种不同的配置。
| 配置 | 720p 低画质 | 1080p 高画质 | 1080p 光追 Ultra | 4K 光追 Ultra | 4K 光追 Ultra + 帧生成 |
|---|---|---|---|---|---|
| M4 Air 原生 macOS | 61 | 28 | 7 | 3 | 6 |
| M4 Air + RTX 5090 | 49 | 62 | 30 | 27 | 111 |
| M5 Max 原生 macOS | 200 | 131 | 59 | 25 | 42 |
| M5 Max + RTX 5090 | 73 | 68 | 45 | 47 | 145 |
| i5-12600K 原生 PC | 180 | 161 | 105 | 100 | 282 |
对比:
-
原生 M4 Air 在 4K 光追下只有 3 帧,完全是幻灯片;外接 RTX 5090 后直接冲到 27 帧,开 DLSS 帧生成更是达到了 111 帧
-
M5 Max 的集成显卡已经足够强悍,1080p 光追能跑到 59 帧,但 4K 光追还是勉强;外接显卡后直接翻倍
-
原生 PC 的性能依然是天花板,比 M5 Max+eGPU 快了约 2 倍
其他游戏表现
-
《古墓丽影:暗影》:M4 Air 原生 4K 只有 8 帧,外接 eGPU 后达到 40 帧
-
《毁灭战士 2016》:macOS 上完全无法运行,外接 eGPU 后稳定在 49-60 帧
-
《孤岛危机重制版》:是的,它真的能跑 "能跑孤岛危机" 的最高预设
-
❌ 《地平线:零之曙光重制版》:直接突破了 DART 的 1.5GB 映射上限,完全无法启动
AI 推理性能暴涨 120 倍
真正让 ScottJG 意外的是 AI 推理的表现。
由于 CUDA 可以在 ARM Linux 上原生运行,几乎没有额外开销。
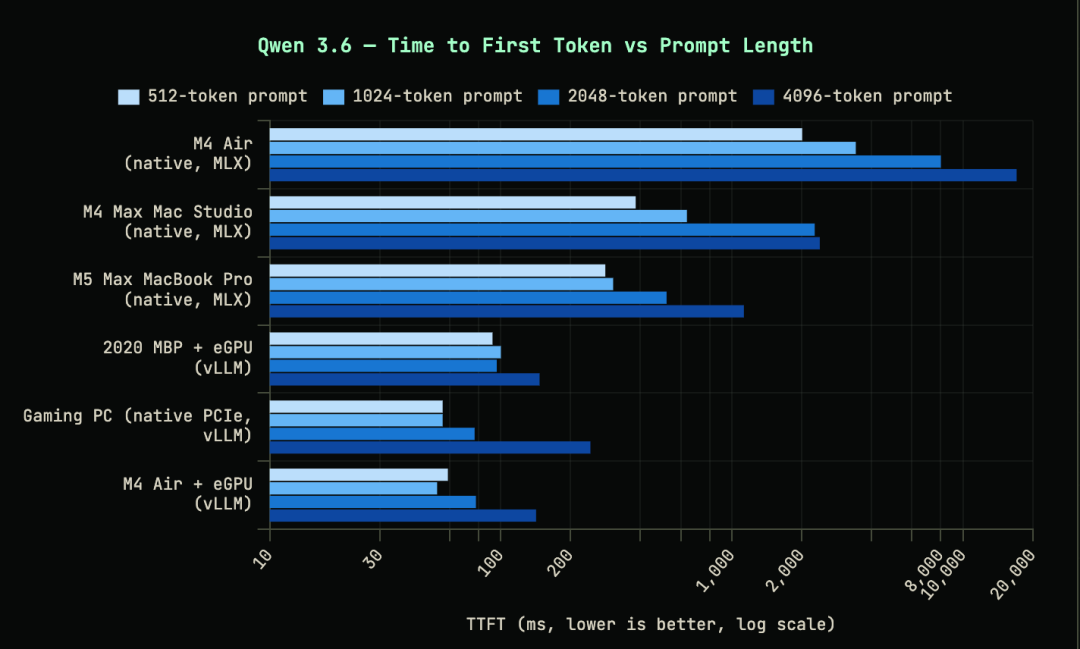
测试用的是通义千问 3.6 35B MoE 模型(4 位量化):
-
令牌生成速度
M4 Air 原生 22 tok/s → 外接 RTX 5090 后 155 tok/s,提升 6.5 倍
-
4K 令牌预填充时间
M4 Air 原生 17 秒 → 外接 RTX 5090 后 150 毫秒,提升120 倍
-
并发性能
RTX 5090 在 4 并发请求下吞吐量提升 3 倍,而 M4 Air 几乎没有提升
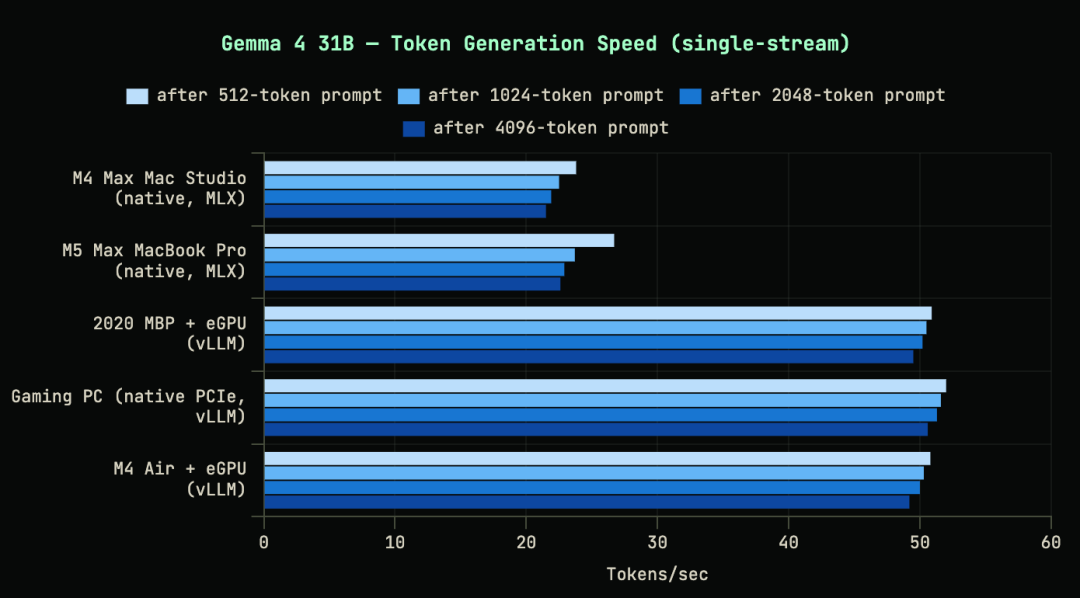
在更重的 Gemma 4 31B 模型测试中,差距进一步拉大。M4 Air 的集成 GPU 只能跑到 2-3 tok/s,而 RTX 5090 依然能稳定在 50 tok/s。
虽然结果不错,但 ScottJG 也坦诚:这目前还是一个 "展示可能性" 的项目,远达不到日常使用的程度。
最大的障碍是需要苹果的特殊开发者权限。
ScottJG 已经向苹果申请了,但被告知等待时间可能长达数月。
在那之前,你只能自己编译驱动并签名,而且不需要关闭 SIP。
其他问题也不少:
-
稳定性很差,Steam 经常陷入崩溃循环
-
游戏启动极慢,有些游戏需要几分钟才能加载
-
DMA 映射会逐渐碎片化,玩几个游戏后就需要重启虚拟机和拔插显卡
-
整体性能还是比原生 PC 差 2-4 倍
意义大于实用的疯狂实验
这个项目的意义,远不止于 "在 Mac 上玩游戏"。
它证明了苹果芯片的 Mac 并非完全封闭,只要有足够的技术能力,依然可以挖掘出巨大的潜力。尤其是在 AI 推理方面,外接 eGPU 的表现远超预期,甚至能打败 M4 Max Mac Studio。
ScottJG 说,如果未来 Linux 能原生支持苹果芯片的 Thunderbolt,那么所有这些虚拟化和 DMA 的问题都会消失。到那时,Mac 外接 eGPU 可能真的会成为一个实用的选择。
而对于我们这些普通用户来说,至少我们知道了:当有人说 "Mac 不能做什么" 的时候,总有人会用代码证明,没有什么是不可能的。
参考来源:
https://scottjg.com/posts/2026-05-05-egpu-mac-gaming/
往期: