🎙️ Day 1:语音信号处理基础(上)
今天的目标:从声音的本质 出发,一步步理解到Mel频谱图。
第一步:声音到底是什么?
1.1 物理本质
声音 = 空气压力的变化(振动)
想象你对着水面丢石头,产生波纹。声音就是空气中的"波纹"------声波。
声波的关键属性:
- 频率 (Frequency): 每秒振动次数,单位 Hz。频率越高,声音越尖
- 振幅 (Amplitude): 振动幅度,振幅越大,声音越响
- 相位 (Phase): 振动的起始位置举个直觉例子:
-
成年男性说话:基频约 85-180 Hz(低沉)
-
成年女性说话:基频约 165-255 Hz(较高)
-
钢琴中央C:261.6 Hz
1.2 最简单的声音:正弦波
世界上最"纯净"的声音就是一个正弦波:

但是! 现实中的声音(人说话、音乐)不是简单正弦波,而是很多不同频率的正弦波叠加在一起的。
🎯 关键认知 :任何复杂声音 = 多个不同频率、不同振幅的正弦波叠加(这就是傅里叶变换的核心思想)
第二步:声音如何存进计算机?------ 采样与量化
2.1 模拟信号 → 数字信号
声波在现实中是连续 的(模拟信号),但计算机只能处理离散的数字。
所以我们需要两步:
连续声波 ──采样(Sampling)──→ 离散时间信号 ──量化(Quantization)──→ 数字信号2.2 采样 (Sampling)
采样 = 每隔固定时间间隔,记录一次声波的振幅值
-
采样率 (Sample Rate):每秒采样多少次,单位 Hz
-
电话语音:8000 Hz(8kHz)
-
语音识别常用:16000 Hz(16kHz) ⭐
-
CD音质:44100 Hz(44.1kHz)
-
高清音频:48000 Hz(48kHz)
-
🔥 面试必知 --- 奈奎斯特采样定理:
采样率必须 ≥ 2 × 最高频率,才能无失真地还原原始信号。
人耳能听到 20Hz ~ 20000Hz,所以 CD 用 44100Hz > 2 × 20000Hz ✅
语音的有效频率主要在 8000Hz 以下,所以 16kHz 采样就够了 ✅
2.3 量化 (Quantization)
采样后每个值还是连续的浮点数,量化就是把它映射到有限的离散值:
-
16-bit 量化:每个采样点用 16 位表示,范围 (-32768, 32767)
-
这就是
.wav文件的标准格式
2.4 动手看一下
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# ========== 第一步:加载一段音频 ==========
# 你可以用任意 wav 文件,这里用 librosa 自带示例
# 如果你有自己的文件: y, sr = librosa.load("your_file.wav", sr=16000)
y, sr = librosa.load(librosa.ex('trumpet'), sr=16000)
print(f"采样率: {sr} Hz")
print(f"音频长度: {len(y)} 个采样点")
print(f"音频时长: {len(y)/sr:.2f} 秒")
print(f"每个采样点的值(前10个): {y[:10]}")
print(f"值的范围: [{y.min():.4f}, {y.max():.4f}]")
# ========== 第二步:画出波形 ==========
plt.figure(figsize=(14, 4))
librosa.display.waveshow(y, sr=sr)
plt.title('Waveform (时域波形)')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')
plt.show()
# ========== 放大看局部,感受"采样" ==========
# 取 0.5s ~ 0.52s 的一小段
start = int(0.5 * sr)
end = int(0.52 * sr)
segment = y[start:end]
time_axis = np.arange(start, end) / sr
plt.figure(figsize=(14, 4))
plt.plot(time_axis, segment, 'b-o', markersize=2)
plt.title('放大波形 — 每个点就是一个采样点')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')
plt.show()运行后你会看到:
-
第一张图:完整的波形,横轴是时间,纵轴是振幅
-
第二张图:放大后能看到一个一个的离散点------这就是"采样"
第三步:从时域到频域 ------ 傅里叶变换 (FFT)
3.1 为什么要做频率分析?
看波形图,你能分辨出一个人说了什么吗?很难。
但是如果我们知道这段声音里有哪些频率成分,就有用多了------不同的音素(元音、辅音)对应不同的频率模式。
3.2 傅里叶变换的直觉
傅里叶变换 = 把一个复杂信号拆解成各个频率的正弦波成分
就像把白光通过棱镜拆分成彩虹光谱一样 🌈
时域 (Time Domain): 信号随时间变化 → 横轴是时间
频域 (Frequency Domain): 信号的频率组成 → 横轴是频率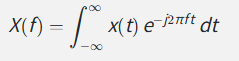
离散版本(DFT),计算机用的:
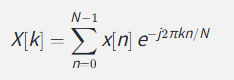
你不需要记公式,理解含义就行:把信号分解成不同频率的成分,每个频率有多大的强度
3.3 动手:对一段音频做 FFT
# ========== 对整段信号做 FFT ==========
N = len(y)
Y = np.fft.fft(y) #对 y 做 FFT,得到长度为 N 的复数数组(包含幅度和相位信息)
freqs = np.fft.fftfreq(N, 1/sr) #生成每个 FFT 分量对应的频率值(单位 Hz)
# 只看正频率部分(对称的)
magnitude = np.abs(Y[:N//2]) #取 FFT 结果前一半的幅度(模)
freqs_positive = freqs[:N//2] #取前一半对应的正频率
plt.figure(figsize=(14, 4))
plt.plot(freqs_positive, magnitude)
plt.title('频谱 (Frequency Spectrum)')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Magnitude')
plt.xlim(0, 8000) # 语音主要在 8kHz 以下
plt.show()你会看到: 某些频率处有明显的峰值------这些就是信号的主要频率成分。
3.4 问题:FFT 丢失了时间信息!
做一次 FFT,你知道"整段信号有哪些频率",但不知道什么时间出现了什么频率。
而语音是时变的------人在说话时,频率特征一直在变化(不同的音素有不同频谱)。
这就引出了下一个核心概念 👇
第四步:短时傅里叶变换 (STFT)
4.1 核心思想
既然整段做FFT丢失时间信息,那就把信号切成很多小段(帧),每一帧分别做FFT!
加窗分帧
长信号 ──────────────────────────→ [帧1] [帧2] [帧3] [帧4] ...
↓ ↓ ↓ ↓
FFT FFT FFT FFT
↓ ↓ ↓ ↓
频谱1 频谱2 频谱3 频谱4 ...
↓
拼起来 → 语谱图 (Spectrogram)
横轴=时间, 纵轴=频率, 颜色=能量4.2 关键参数(面试必知⭐)
| 参数 | 含义 | 语音识别常用值 |
|---|---|---|
| 帧长 (frame_length / n_fft) | 每一帧的长度 | 25ms → 400点(16kHz) 或 512点 |
| 帧移 (hop_length) | 相邻帧的间隔 | 10ms → 160点(16kHz) |
| 窗函数 (window) | 乘在每帧上,减少频谱泄漏 | Hamming窗 / Hann窗 |
🔥 面试常问:为什么帧长选 25ms?
因为语音信号在 20-30ms 内可以近似看作平稳信号(短时平稳假设)。太短频率分辨率差,太长则跨越不同音素。
🔥 面试常问:为什么要加窗函数?直接截断信号相当于乘了一个矩形窗,会导致频谱泄漏(不该有的频率出现了)。Hamming/Hann窗把边缘平滑过渡到0,大大减少泄漏。
4.3 帧移 vs 帧长的关系
信号: |================================================|
帧1: |████████████|
帧2: |████████████| ← 帧移(hop) < 帧长(frame)
帧3: |████████████| 所以帧之间有重叠!
帧4: |████████████|
...
重叠部分保证了时间上的平滑过渡,不会丢失信息。
常见重叠率: 帧长25ms, 帧移10ms → 重叠 15ms (60%)4.4 动手:计算STFT并画语谱图
# ========== STFT ==========
n_fft = 512 # FFT点数(帧长512点,对应32ms@16kHz)
hop_length = 160 # 帧移160点,对应10ms@16kHz
# librosa.stft 返回复数矩阵,取模得到幅度
D = librosa.stft(y, n_fft=n_fft, hop_length=hop_length, win_length=400, window='hamming')
magnitude = np.abs(D) # 幅度谱
power = magnitude ** 2 # 功率谱
print(f"STFT 输出形状: {D.shape}")
print(f" → 频率bins: {D.shape[0]} (= n_fft/2 + 1 = {n_fft//2+1})")
print(f" → 时间帧数: {D.shape[1]}")
# 转换为 dB 刻度(人耳感知是对数的)
magnitude_db = librosa.amplitude_to_db(magnitude, ref=np.max)
plt.figure(figsize=(14, 5))
librosa.display.specshow(magnitude_db, sr=sr, hop_length=hop_length,
x_axis='time', y_axis='hz')
plt.colorbar(format='%+2.0f dB')
plt.title('Spectrogram (语谱图)')
plt.ylim(0, 8000)
plt.show()你会看到: 一张热力图,横轴时间,纵轴频率,颜色深浅表示该时刻该频率的能量强度。这就是语谱图 (Spectrogram)。
第五步:Mel 频谱图 ------ 模拟人耳感知
5.1 为什么不直接用频谱图?
人耳对频率的感知是非线性的:
-
你能轻松分辨 100Hz 和 200Hz 的差别(低频区域)
-
但很难分辨 8000Hz 和 8100Hz 的差别(高频区域)
人耳对低频分辨率高,高频分辨率低
5.2 Mel 刻度
Mel 刻度就是模拟人耳的这种非线性感知:
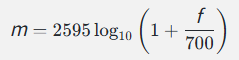
频率 (Hz): 0 500 1000 2000 4000 8000
Mel值: 0 607 999 1521 2146 2840
注意:低频段间距大(分辨率高),高频段被压缩(分辨率低)5.3 Mel 滤波器组 (Mel Filter Bank)
在频谱上放置一组三角形滤波器,按 Mel 刻度均匀分布:
能量
▲
│ /\ /\ /\ /\ /\ /\
│ / \ / \ / \ / \ / \ / \
│ / \ / \ / \ / \ / \ / \
│ / \/ \/ \ / \ / \ / \
└──────────────────────────────────────────────────────→ 频率
低频(滤波器窄且密) 高频(滤波器宽且疏)每个三角形滤波器覆盖一个频率范围,输出该范围内的加权能量和。
5.4 Mel频谱图计算流程
原始波形
↓ 分帧 + 加窗
每帧信号
↓ FFT
功率谱 |X(f)|²
↓ 乘以 Mel 滤波器组
Mel 功率谱 (n_mels 个值, 通常 80)
↓ 取 log
Log-Mel 频谱图 (= FBank 特征!)🔥 FBank (Filter Bank) 特征 = Log-Mel 频谱图,这是现代深度学习语音系统最常用的输入特征!
5.5 动手:计算 Mel 频谱图
# ========== Mel 频谱图 ==========
n_mels = 80 # Mel 滤波器个数(语音识别/TTS标配 80)
# 方法1: 用 librosa 一步到位
mel_spec = librosa.feature.melspectrogram(
y=y, sr=sr,
n_fft=512,
hop_length=160,
win_length=400,
n_mels=n_mels,
window='hamming'
)
print(f"Mel频谱图形状: {mel_spec.shape}")
print(f" → {mel_spec.shape[0]} 个Mel频带 × {mel_spec.shape[1]} 帧")
# 转 dB (取log)
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)
plt.figure(figsize=(14, 5))
librosa.display.specshow(mel_spec_db, sr=sr, hop_length=160,
x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
plt.title(f'Mel Spectrogram ({n_mels} Mel bands)')
plt.show()
# ========== 对比:普通频谱图 vs Mel频谱图 ==========
fig, axes = plt.subplots(2, 1, figsize=(14, 8))
# 普通频谱图
librosa.display.specshow(magnitude_db, sr=sr, hop_length=hop_length,
x_axis='time', y_axis='hz', ax=axes[0])
axes[0].set_title('Linear Spectrogram')
axes[0].set_ylim(0, 8000)
# Mel频谱图
librosa.display.specshow(mel_spec_db, sr=sr, hop_length=160,
x_axis='time', y_axis='mel', ax=axes[1])
axes[1].set_title('Mel Spectrogram')
plt.tight_layout()
plt.show()对比观察: Mel频谱图在低频区域有更高分辨率,高频被压缩了------和人耳感知一致!
5.6 看看 Mel 滤波器长什么样
# ========== 可视化 Mel 滤波器组 ==========
mel_filter = librosa.filters.mel(sr=sr, n_fft=512, n_mels=80)
print(f"Mel滤波器矩阵形状: {mel_filter.shape}") # (80, 257) → 80个滤波器,每个覆盖257个频率bin
plt.figure(figsize=(14, 4))
for i in range(0, 80, 5): # 每隔5个画一个
plt.plot(mel_filter[i])
plt.title('Mel Filter Bank (每隔5个画一个)')
plt.xlabel('Frequency bin')
plt.ylabel('Weight')
plt.show()
# 画全部滤波器
plt.figure(figsize=(14, 4))
librosa.display.specshow(mel_filter, x_axis='linear')
plt.colorbar()
plt.title('Complete Mel Filter Bank')
plt.ylabel('Mel filter index')
plt.xlabel('Frequency (Hz)')
plt.show()📝 Day 1(上半天)知识检查
在继续之前,确认你理解了这些概念:
| # | 问题 | 你应该能回答 |
|---|---|---|
| 1 | 采样率 16kHz 是什么意思? | 每秒采集 16000 个点 |
| 2 | 奈奎斯特定理? | 采样率 ≥ 2 × 最高频率 |
| 3 | 为什么帧长选 25ms? | 语音短时平稳假设 |
| 4 | 为什么加窗? | 减少频谱泄漏 |
| 5 | STFT 做了什么? | 分帧后每帧FFT,得到时频表示 |
| 6 | 为什么用 Mel 刻度? | 模拟人耳非线性频率感知 |
| 7 | FBank 特征是什么? | = Log-Mel 频谱图 |
| 8 | n_fft=512, hop=160, n_mels=80 时输出形状? | (80, 帧数) |
接下来(Day 1 下半部分)预告
-
MFCC ------ FBank 之上再做 DCT(面试最高频考点之一)
-
FBank vs MFCC 的区别和适用场景
-
完整的语音特征提取 pipeline 总结
-
Day 1 综合练习 + 面试模拟题