思考,输出,沉淀。用通俗的语言陈述技术,让自己和他人都有所收获。
作者:毅航😜
LLM、Token、Context、Prompt、Tool、MCP、Agent、Agent Skill 这些新名词,你或许都听过,但真的能准确说出每个概念的核心含义吗?
本文我们将抛开虚浮的商业概念,从符合普通大众的视角出发,逐一拆解并讲透这些核心概念,相信会让你对 AI 的认知迈上全新台阶。
前言
在拆解相关概念之前,我们不妨通过一个简单的例子,来快速建立起对这些 AI 名词的认知。
事实上,我们可以将整个 AI 交互过程比作去餐厅用餐的场景。
在这个场景中,你的身份是顾客,而AI则是那位全能服务员,它的正常运转,离不开LLM、Token、Context、Prompt、Tool、MCP、Agent、Agent Skill的协同配合。其中:
LLM是服务员的大脑,代表其核心的理解与思考能力;Token是你和服务员沟通的字数单位;Context/Context Window是服务员的记忆容量,决定它能够记住多少你的需求;Prompt是你向服务员下达的指令,包含规则与具体需求;Tool/MCP是服务员可以调用的各类工具,例如计算器、后厨、外卖系统等;Agent/Agent Skill则对应服务员的角色定位与专业技能,比如专业点餐员搭配智能推荐菜品的能力。
LLM大语言模型
我们从最底层的概念开始,层层递进搭建 AI 知识体系,最基础的核心就是 LLM。
LLM 的全称是 Large Language Model,为了叙述方便,后面我们统称其大模型。
目前市面上绝大多数大模型均基于 Transformer 架构构建,可以说,Transformer 是大模型的底层核心引擎。
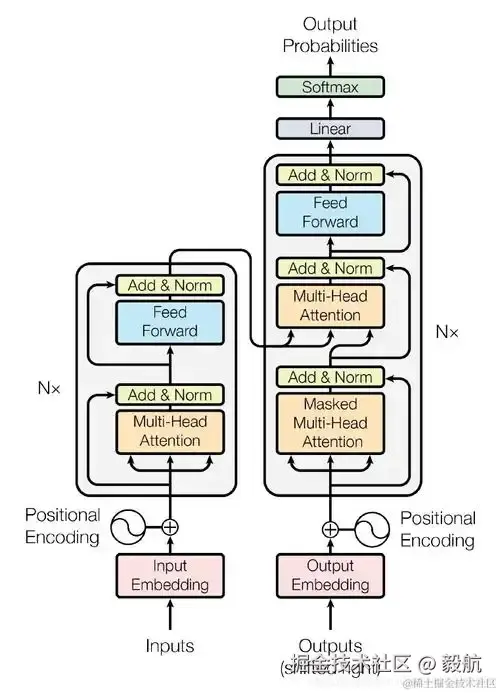
理清大模型的技术源头之后,我们再来拆解其核心工作原理。
事实上,大模型它的本质其实十分简洁,本质上就是一场 "文字接龙游戏"。
举个例子,如果你向大模型提问 "苹果手机的创始人是谁?",模型接收到问题后,会通过内部运算,预测出概率最高的下一个词。
我们假设,这一轮概率最高的词是 "创始人"。
当模型输出 "创始人" 后,会立刻把这个词追加到原问题的末尾,形成新的上下文。随后,它会按照同样的逻辑,继续预测下一个词。
回到这个例子,模型接下来会预测出 "乔",追加之后再预测 "布",接着又预测出 "斯"。
就这样,模型循环逐词生成内容,直到输出结束标识符为止,最终完整的回答 "乔布斯" 就呈现出来了。
理解了这一点,相信你也就能明白,大模型之所以会逐词输出答案,正是由它底层 "文字接龙游戏" 的运行逻辑决定的。
(注意: 这里我们所说的 "用户提问后模型逐词输出",只是为了方便理解做的简化解释。模型内部的运行机制远不止于此。 )
Token是什么
现实中,大模型底层的本质是庞大的数学函数的合集,它仅能识别数字,既无法直接接收文字输入,也不会直接输出文字。
因此,人类与大模型之间需要一位 "翻译官"------Tokenizer,其核心职责便是编码与解码:编码将文字转为数字,解码则把数字还原为文字。
仍以 "苹果手机的创始人是谁?" 为例,这句话会先交由 Tokenizer 完成编码,过程分为切分和映射两步:
- 第一步切分。
Tokenizer将输入文字拆分为最小文本片段,即Token; - 第二步是映射。为每个
Token匹配唯一的数字标识,即Token ID,二者一一对应,只是同一事物的不同表现形式。
经过两步处理,文字便转化为 Token ID 序列传入模型。模型运算后输出新的 Token ID,再由 Tokenizer 进行解码。解码仅需反向映射,无需切分,因为模型每次仅输出一个 Token。
解码后我们便得到首个输出 Token,之后模型循环执行相同流程,直至回答完成。
换言之,大模型始终以 Token 为单位完成输入与输出。
看到这里,你可能会觉得 "Token 就是一个完整的词"。但事实并非如此,Token 和词之间没有固定的一对一关系,刚才只是巧合。
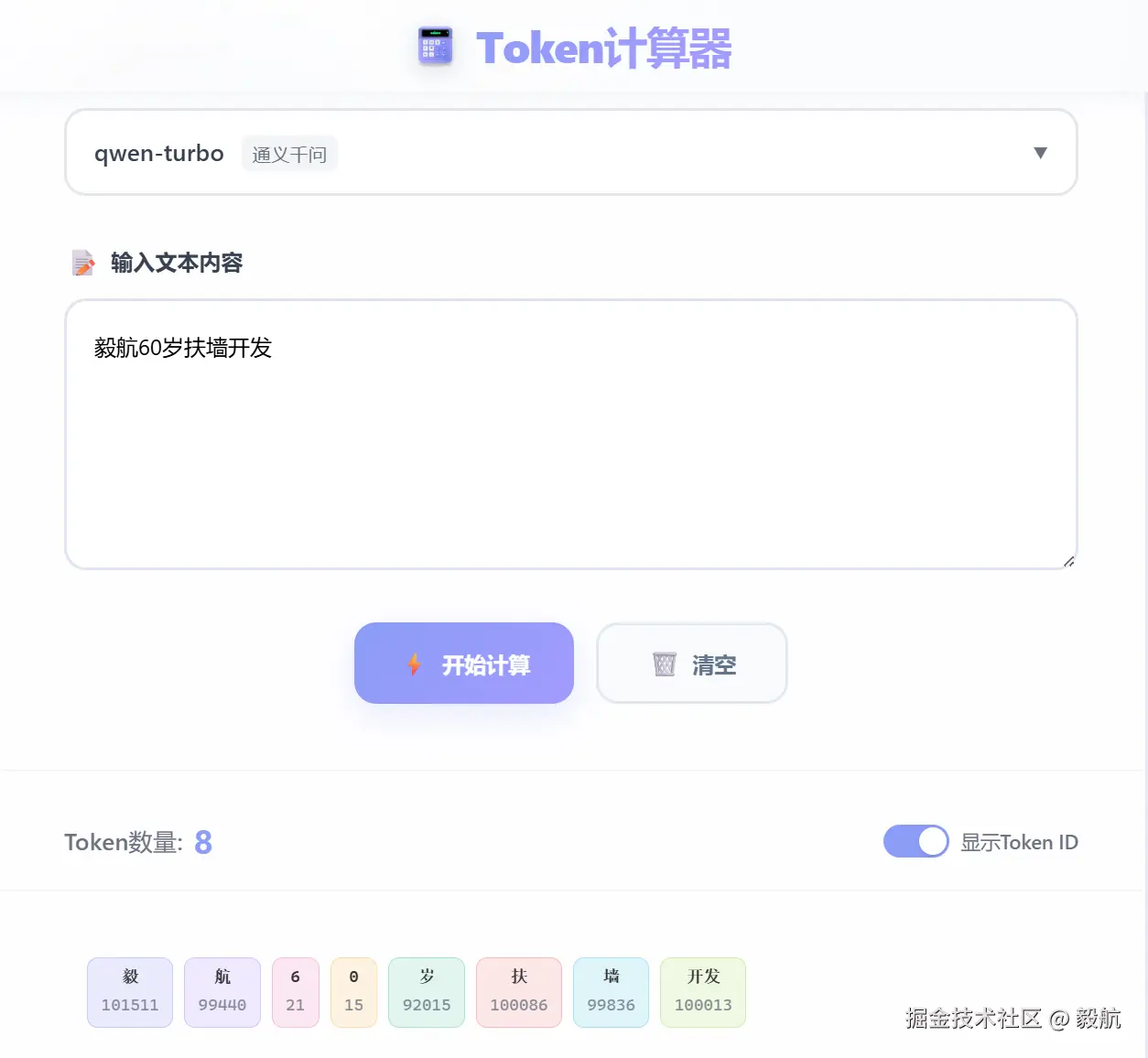
再换几个例子就能清楚:比如我的掘金签名 "毅航/60岁/扶墙开发"为例,按词语划分本应是 3 个部分。
而在AI Tools的Token计算器中,其内容会被切分成 8 个 Token,其中"毅航"会被拆成 "毅" 和 "航" 两个 Token。
简单来说,Token是大模型按照自身学习的文本切分规则处理文本时的最小单位。
通常情况下,1 个 Token 大约对应 0.75 个英文单词,或1.5-2个汉字。因此,40 万个 Token 大概相当于 60-80 万个汉字,或是 30 万个英文单词。
(注:如果想深入了解 Token 的切分原理,可以参考专门讲解 BPE 算法训练的相关内容。)
Context/Context Window
理解了 Token 的概念后,我们来看一个看似平常、实则值得深究的问题:日常和大模型聊天时,它好像能记住之前的对话内容。
比如,如果你之前让大模型按照某种特定风格润色文章段落,之后再发送新的段落给它,它就能准确沿用之前的风格继续润色。
经过前面介绍,我们知道大模型本质上只是一个由输入决定输出的数学函数,其并不具备人类真正的记忆能力,它究竟是如何 "记住" 这些要求的呢?
这其实是因为每次你向大模型发送新消息时,后台程序都会自动将此前的全部对话历史提取出来,与新问题一同发送给模型。
而模型接收到完整的对话内容,便能 "知晓" 之前的交流信息,这也就引出了Context 这一概念,中文译作上下文,即大模型每次处理任务时所接收的全部信息。
你可能会觉得这个问题十分复杂,但结合我们之前对大模型本质的介绍。
不难想到,如果在每次对话时都将上一轮内容同步给模型,它就能感知到之前的信息,自然也就拥有了 "记忆" 功能。
事实上,每次你向大模型发送消息时,后台程序会自动提取此前的全部对话历史,与新问题一并发送给模型。模型接收到完整的对话内容,自然就能 "知晓" 之前的交流信息。
这也引出了Context上下文的概念。具体来看,Context它指的是大模型每次处理任务时所接收的全部信息。
换言之,你可以把 Context 看作大模型的 "临时记忆体",这是它能实现对话连贯性的核心原因。
既然Context是 "临时记忆体",那它的容量就有上限,这就引出了Context Window的概念。
Context Window代表 Context 所能容纳的最大 Token 数量。比如 Context Window 为 1 万,就意味着模型最多能处理 1 万个 Token。
RAG
了解了 Context上下文技术后,我们不妨再思考一个实际问题:如果你有一份上千页的公司产品手册,希望大模型根据手册内容回答用户疑问,该怎么实现?
直接把手册全部内容和用户问题一起发给模型,显然不是最优解 。即便模型的Context Window足够大,这样做的成本也会居高不下。
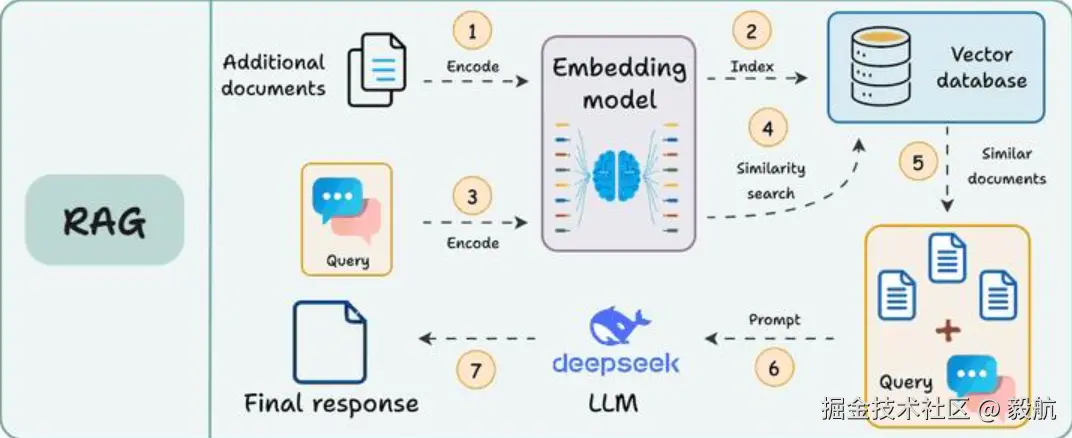 为了解决这个问题,
为了解决这个问题,RAG 技术应运而生。借助 RAG 技术,系统会先从产品手册中精准抽取与用户问题最匹配的核心片段,再将这些片段与问题一并发送给大模型,让模型基于关键信息作答。
这样一来,模型接收的不再是整本厚重的手册,而是少量核心文字,既巧妙突破了 Context Window 的容量限制,又能大幅降低使用成本。
Prompt
接下来讲 Prompt提示词。通俗来看 Prompt就是大模型接收的具体问题或指令。
比如,你对大模型说 "帮我写一首诗",这句话就是 Prompt。完全没必要不用把Prompt想得复杂高端,Prompt它本质就是给大模型的指令或问题。
如果你的 Prompt过于模糊,比如只说 "帮我写一首诗",大模型可能会写古诗、现代诗,甚至打油诗,因为它无法精准理解你的需求。
由此可见,Prompt 的撰写质量,直接决定了大模型的输出效果。一个优质的 Prompt,必须清晰、具体、明确。
正因如此,才诞生了Prompt Engineering(提示词工程)这一领域。简单来说,这一领域的核心就是研究如何精准表达需求,让大模型准确理解用户意图。
如今这个领域如今热度大减,一方面是因为门槛较低,核心就是把需求描述清晰;另一方面是因为大模型的能力持续提升,即便 Prompt 略有模糊,模型也能大致猜出用户意图,无需在提示词上耗费过多精力。
当然,Prompt 的概念不止于此,有些时候,我们不仅需要告诉大模型具体任务,还要为它设定人设和做事规则,这就引出了两种不同类型的 Prompt:
- User Prompt(用户提示词) :用于说明具体任务,由用户直接输入;
- System Prompt(系统提示词) :用于设定人设和做事规则,由开发者在后台配置,用户无法看到。
看到此,你可能觉得大模型无所不能。但其实大模型有一个固有弱点 :它无法感知外界的实时信息。比如,你问它 "今天上海的天气怎么样?",它大概率会回复:"抱歉,我无法获取实时天气信息,我的知识库截止到某个时间点,无法提供当前的天气数据。"
Tool/MCP
大模型之所以 "做不到",原因其实很简单:它的核心能力是基于训练数据预测下一个词,本质还是 "文字接龙"。它没有主动访问天气预报网站、抓取实时数据的能力,自然也就无法回答这类需要最新信息的问题。
如果想要解决这个问题,就需要用到 Tool工具来帮助大模型获取需要必要的判断信息。
为了方便理解,完全可以将 Tool 理解成 "函数" 。Tool就是一个有输入、有输出的函数。
比如,天气查询工具,输入 "城市" 和 "日期" 两个参数,它会通过调用气象局接口等方式,输出对应的天气信息。有了 Tool大模型就能突破自身限制,回答各类需要实时数据的问题。
我们以 "查询上海今日天气" 为例,看一下从用户提问到模型回答的完整流程,整个流程涉及四个角色:用户、大模型、工具(天气查询)、平台,其中平台可以理解为 "传话筒",因为用户、大模型、工具之间无法直接对话,需要平台作为中间方传递信息,它的本质是一段负责 "上传下达" 的代码。
完整流程如下:
- 用户将问题发送给平台,平台把问题 + 可用工具列表(如天气查询、计算器)一起转发给大模型;
- 大模型分析后判断用户需要查询实时天气,而自身无此能力,但有对应的天气查询工具,因此生成工具调用指令(包含工具名称、所需参数),并发送给平台;
- 平台接收到指令后,调用工具获取工具返回的天气信息;
- 平台把天气信息转发给大模型,大模型将信息整理成自然语言,发送给平台;
- 平台把整理后的答案转发给用户,整个流程结束。
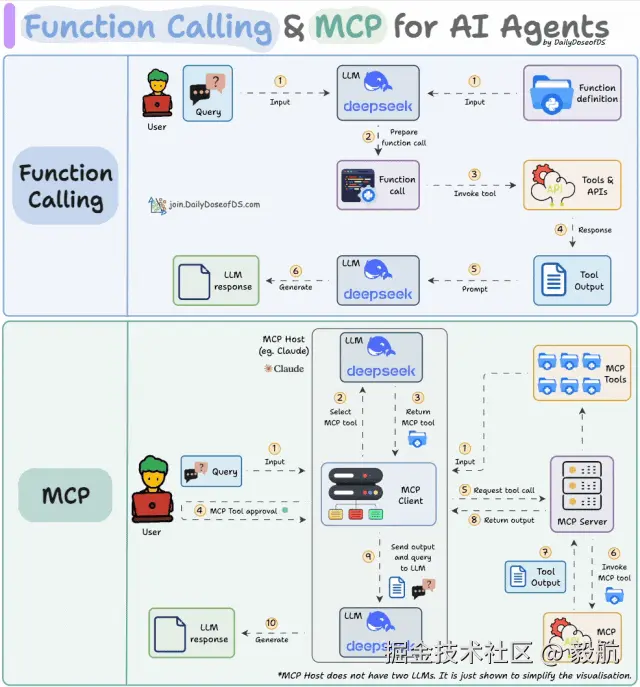
在这个过程中,每个角色的职责清晰明确。
- 大模型负责选择工具 (确定调用的工具并生成参数)和归纳总结(将工具结果整理成自然语言);
- 工具负责完成具体的查询 / 运算任务;
- 平台负责串联整个流程,包括告知模型可用工具、根据模型指令调用工具、传递各类信息。
这里通常会有一个误区,很多人总是误以为是大模型直接调用工具,实则不然,模型的能力仅限于输出文本指令,真正的工具调用动作,最终由平台完成。
总结来说,Tool 的本质,就是为大模型提供一套可调用的外部能力,让大模型能够感知、甚至影响外部环境。
了解了 Tool 的使用流程,我们再来解决一个工程上的核心问题:平台要向模型传递工具列表,还要能实际调用工具,前提是把工具接入平台,让平台知晓工具的用途、参数、调用方法等。
但问题在于,不同平台的工具接入规范各不相同:对接 GPT要按 Open AI 的规范写接入代码;对接 Claude要按 Anthropic 的规范重新写;对接 Gemini又要按谷歌的规范再写一遍。同一个工具,需要为不同平台编写多套代码,效率极低。
于是 AI 行业就有了一个共识:能不能制定一套统一的接入标准,让所有平台都遵循,工具开发者只需写一次代码,就能在所有平台上使用?这就是 MCP 的由来,它就是这套统一的接入规范。
事实上,对于MCP 你可以直接把它理解成统一的工具接入标准 。有了MCP之后,工具开发者只需按照 MCP 的规范开发一次工具,该工具就能被所有支持MCP的平台调用。整个过程就像所有手机都使用Type-C接口一样。
Agent
现在我们知道,大模型能借助 Tool 感知外部世界,而 Tool 能通过 MCP 实现跨平台统一接入,按理说大模型的能力已经足够强,但实际应用中仍有欠缺,比如面对需要多步操作的复杂问题,单一的工具调用就无法解决。
举个例子,用户提问:"今天我这里的天气怎么样?如果下雨的话,帮我查一下附近有没有卖雨伞的店?" 假设现有定位、天气、店铺三个可用工具。其中
- 定位工具: 用于查询用户经纬度
- 天气工具:可根据经纬度查天气
- 店铺工具:可根据经纬度查附近店铺。
大模型为了回答这个问题,其内部整个思考和执行流程如下:
-
先获取用户位置。模型分析后发现,查询天气需要具体地理位置,于是调用定位工具,获取用户的经纬度。
-
再查询对应位置的天气。拿到经纬度后,模型继续调用天气工具,得知当地当前有雨。
-
最后查找附近卖伞的商店。根据 "有雨" 的结果,模型继续调用店铺工具,查找附近的雨伞销售点,并整合所有信息,整理成自然语言给出最终答案。
这个过程中,大模型需要一步步思考当前情况,自主决定下一步的操作,已经具备了一定的自主规划能力。我们把这种能够自主规划、自主调用工具,持续运作直至完成用户任务的系统 ,称为 Agent。
Agent 能自主完成复杂任务,看似功能完备,但在高频实际使用中,会遇到一个关键痛点 ------无法自动适配用户的个性化规则和格式要求。
比如,你想让大模型成为专属出门助手,帮你查询天气并提醒携带物品。但你有两套明确要求: 一是个性化习惯规则 :下雨带伞、光照强戴帽子、空气差戴口罩、风大穿防风外套,且手机必须随身携带;二是固定回答格式:先给出一句总结,再分点说明携带原因和物品清单。
但如果没有提前做额外设定,即使Agent 能完成天气查询,但并不知道你的个性化习惯和格式要求,大概率会给出冗长、不符合预期的回答。
而想要得到满意结果,你每次提问都得附带一大串规则、格式要求甚至示例,操作起来格外繁琐。
Agent Skill
解决这个问题的核心,就是 Agent Skill,它本质就是你提前为 Agent 编写的一份说明文档 ,用来规定Agent的做事步骤、个性化规则、输出格式等。还是以之前 "出门小助手" 为例。
我们可以为 Agent 编写一份对应的 Agent Skill,它本质是一个 Markdown 文档,整体结构分为两部分:
第一部分:元数据层
相当于说明文档的 "封面",用于告诉 Agent 这个技能的名称和核心用途,至少包含两个属性:
- Name:技能名称,比如 "Go Out Checklist(出门清单)";
- Description:技能描述,简要说明该技能的作用。
第二部分:指令层
从 "目标" 开始到文档结束的所有内容,格式无硬性要求,只要能清晰说明规则即可,可包含目标、执行步骤、判断规则、输出格式、示例等模块。比如出门清单的指令层,可明确写清:
- 目标:根据用户位置的天气,给出个性化出门物品提醒;
- 执行步骤:先调用定位工具获取经纬度,再调用天气工具获取天气信息,最后根据天气按规则整理物品;
- 判断规则:下雨带伞、光照强戴帽子......
- 输出格式:先一句天气总结,再分点列出物品及携带原因;
- 示例:给出用户提问、工具返回结果、模型正确输出的完整示例。
编写好 Agent Skill 后,需要按规范存放到指定位置,以Claude Code为例,存放规则有两个硬性要求:
- 在用户目录下的
.claude skills文件夹中,新建一个文件夹,文件夹名称必须与 Agent Skill 的 Name 完全一致; - 进入该新建文件夹,新建一个文件,将
Agent Skill的内容粘贴进去,文件名必须为 SKILL.md(SKILL 为大写) ,否则系统无法识别。
存放完成后,Agent Skill 就创建好了。启动 Claude Code 时,程序会自动扫描.claude skills 文件夹,加载所有 Agent Skill 的元数据层(名称和描述);当用户的问题与某个 Agent Skill 的元数据匹配时,程序才会读取该技能的完整指令层,按指令层的要求执行任务。
当然,Agent Skill 还有很多高级功能,比如运行代码、引用资源等,其渐进式披露机制还能有效节省Token消耗,让 Agent 的运作更高效。
总结
到这里,AI 的核心底层概念就全部讲解完毕,我们来梳理一下整个知识体系,从核心到延伸层层递进:
LLM(大语言模型) :所有AI技术的核心,基于Transformer架构训练,是整个体系的基础;Token:大模型处理文本的最基本单元,模型以Token为单位接收输入、输出结果;Context(上下文) :大模型每次处理任务时接收的信息总和,相当于模型的 "临时记忆体";Context Window(上下文窗口):Context能容纳的最大Token数量,代表模型的 "临时记忆容量";Prompt(提示词):给大模型的指令 / 问题,分User Prompt(用户输入,指定具体任务)和 System Prompt(后台配置,设定人设 / 规则);Tool(工具):为大模型提供外部能力的函数,让模型能感知 / 影响外部环境,解决实时数据、复杂运算等问题;MCP(模型上下文协议):统一的工具接入标准,让工具只需开发一次,就能在所有支持 MCP 的平台上使用;Agent:能自主规划、连续调用工具,持续运作直至完成复杂用户任务的系统;Agent Skill:为Agent编写的说明文档,规定Agent的个性化做事规则、执行步骤、输出格式,让Agent适配用户的定制化需求。
至此,我们就对LLM、Token、Context、Prompt、Tool、MCP、Agent、Agent Skill 等这些新名词进行了一个信息的介绍,希望本文对你理解AI领域相关概念有关帮助。