首先,在安装消息队列之前,我们需要知道消息队列是解决什么问题呢?
消息队列本质是解决消息传递的问题,场景都是扩展出来的。
可能你会问,一条消息不能直接传递吗?比如服务A不总是能将消息直接传给服务B吗?为啥还要引入一个消息队列?
有一些时候是不能的,举几个例子:
- 接收方处理不过来的时候,比如接收方每秒只能处理1000条消息,但是你因为搞活动,瞬间1s有10000条,这时候打过去接收方也扛不住啊,通过消息队列可以让接收方按自己的能力来协调,把消息压力摊平,这就是削峰
- 发送一个通知到短信服务,让短信服务发一条短信给客户,这时候如果要等待短信发完,发送方就会慢,不需要关注结果,就可以实现解耦
面对上述问题,没有什么事是引入一个中间层解决不了的;这就是引入消息队列作为中间层,来解决某些场景下消息传递的问题,这就是消息队列的意义;
接下来介绍消息队列的应用场景
- 解耦
比如发送短信场景,假设服务SvrA发送消息给SvrB,SvrB发送短信给客户,很多时候业务是允许SvrA不需要得到SvrB发送完成的回应,只需要消息发送到SvrB就行了,这种情况下,如果还让SvrA等待SvrB的返回,显然会导致性能变低,同时还要去关注SvrB的运行结果。所以,如果业务可以去除这种依赖,那么就能获得性能,可靠性等的提升;
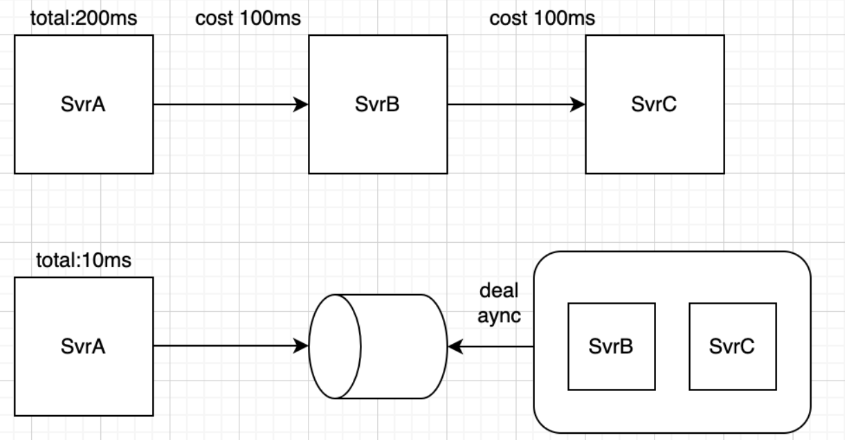
- 异步
如果一个接口,处理时间很长,而且不能通过水平扩容来解决,就需要异步。那么,什么情况下不能通过水平扩容解决呢?
有很多,比如视频处理,涉及到视频下载,那受限于网络带宽等因素,扩容无用;比如区块链这种共识场景,只有单机才能出块,扩容也没有用;还有更常见的,比如一个业务流程,过了10多个微服务,单个也许不长,加起来就很难接受。
以上的情况下,用户很难通过同步接口长时间等待结果,那就应该做成异步,先扔进消息队列,后续再进行消费,和解耦一样可以收获更高的性能,以及获得更好的可靠性。
异步和解耦最大的区别在于,解耦是业务上本身就不需要依赖,异步是可能还是需要关注结果,但是不一定干等,可以回头再找。
- 消息分发
假设一个核心服务A,是用来发布某种信号的,发布之后,需要通知到下游服务B、C,这种模式在只有B、C两兄弟的时候,没啥问题。但随着业务需要,可能会有D、E、F等更多的打工人出现,这时候A服务就需要更改代码,将消息也传递给这些新加入的兄弟,每次增加打工人,就需要更改一次代码。
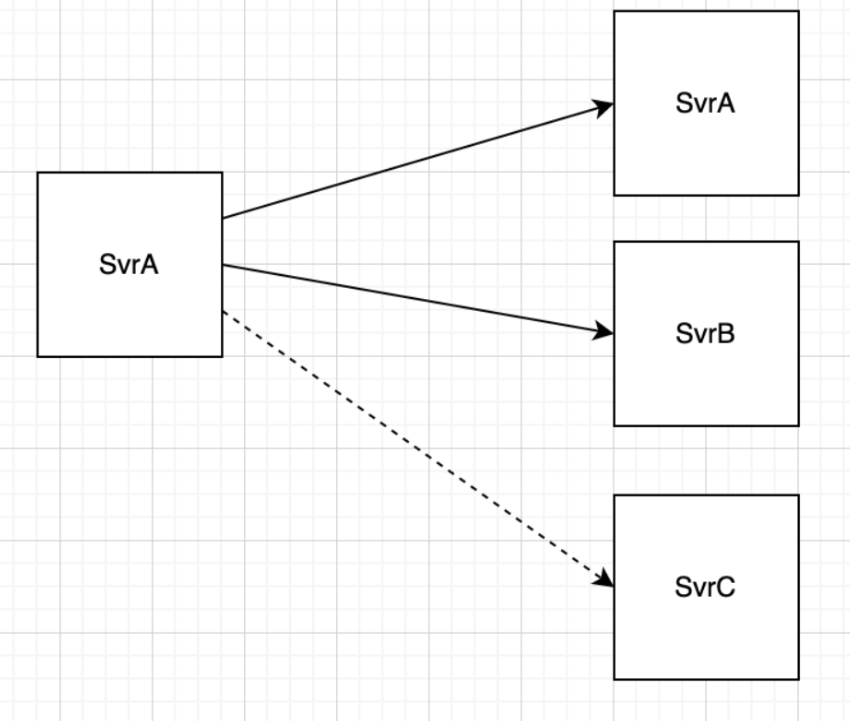
而引入消息队列,就可以解决这个问题,实现代码复用,业务解耦,拥有高扩展性
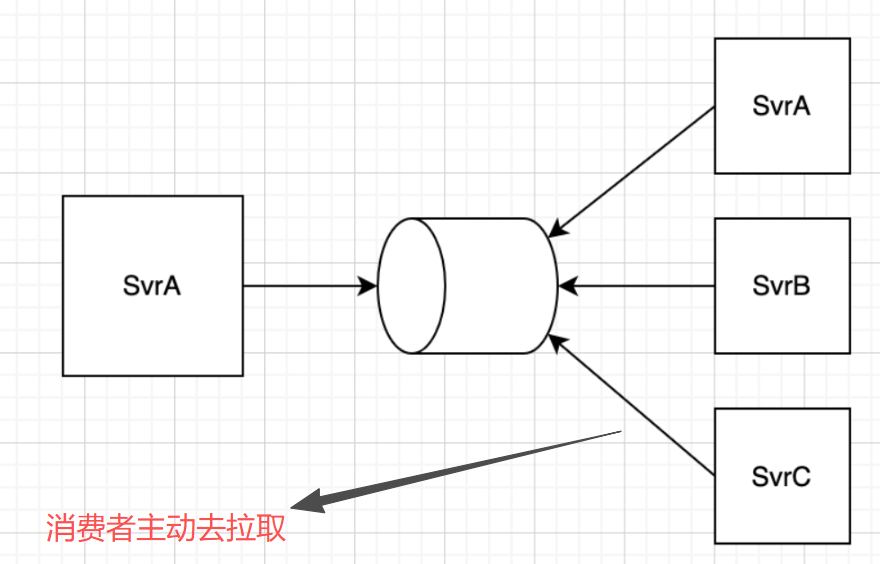
- 削峰
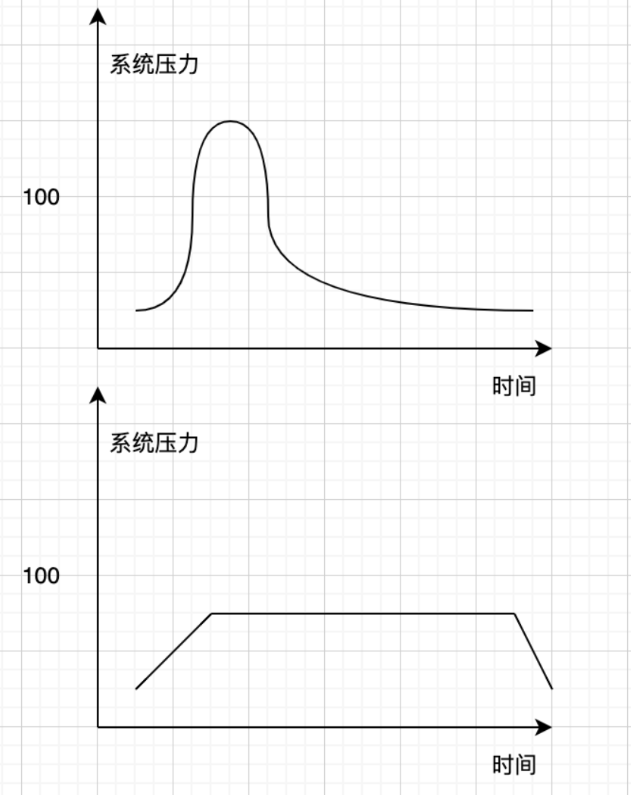
每天要被人打48拳,1小时之内打完48拳可能人就挺不过去了,但是分散到24小时,1小时两拳,就能存活,这就是削峰。
我们经常遇到的秒杀场景就需要削峰的能力,一般而言就是将扣减库存操作均匀化处理,以防止瞬时流量打崩MySQL,如下所示(上面的图是削峰前,下面的图是削峰后):
最后就是进入了kafka的安装,本文主要是在wsl2中通过docker来拉取安装
-
打开wsl2终端,进入我的用户主目录:
bashcd ~ -
创建一个专门放 Kafka 的文件夹
bashmkdir kafka-dev -
创建配置文件 (
docker-compose.yml)bashnano docker-compose.ymlbashservices: kafka: image: apache/kafka:latest container_name: kafka ports: - "9092:9092" environment: # KRaft 模式配置,不需要 Zookeeper KAFKA_NODE_ID: 1 KAFKA_PROCESS_ROLES: 'broker,controller' KAFKA_LISTENERS: 'PLAINTEXT://:9092,CONTROLLER://:9093' KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://localhost:9092' KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER' KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT' KAFKA_CONTROLLER_QUORUM_VOTERS: '1@localhost:9093' KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 volumes: - kafka_data:/var/lib/kafka/data kafka-ui: image: provectuslabs/kafka-ui:latest container_name: kafka-ui ports: - "8080:8080" environment: KAFKA_CLUSTERS_0_NAME: local-cluster KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092 depends_on: - kafka volumes: kafka_data:按下
Ctrl + O(保存),然后按Enter确认文件名。按下Ctrl + X(退出编辑器)。 -
一键启动
bashdocker compose up -d-d的意思是"后台运行",这样你关掉终端窗口 Kafka 也不会挂掉。 -
验证安装结果
bashdocker ps因为安装了 Kafka UI, 所以不用敲复杂的 Linux 命令,直接用你刚才安装的 Kafka UI (可视化界面)来操作:http://localhost:8080
9092 是 Kafka 搬运工的端口(给代码、数据用的)。
8080 是 Kafka-UI 监控器的端口(给人看网页用的)。
如果后期今天还要写代码,直接关掉 WSL 终端窗口即可,不用管它。Kafka 会在后台静默运行,随时待命。
但如果今天不写代码了,准备看电影或关机,建议手动停止它,释放内存给 Windows:
bash
cd ~/kafka-dev
docker compose stop之后如果你重启了 Windows:
-
确保 Docker Desktop 已经启动。
-
打开 WSL 终端,进入目录
-
再次输入:
docker compose up -d。 它会秒级启动,并且你之前创建的 Topic 和数据都会通过我们配置的volumes自动找回来。
进入kafka的命令:
bash
docker exec -it kafka bash