在社交类业务系统中,用户关注与取关是访问量极高、并发压力大且对数据一致性要求严苛的核心场景,不仅需要应对用户高频点击、恶意刷接口等流量问题,还要解决消息丢失、重复消费、缓存与数据库数据偏差、粉丝关注计数不准等一系列线上常见难题。传统直接发送消息队列的开发模式,极易出现业务入库成功但消息投递失败,最终引发业务数据不一致的隐患。为此我基于实际业务场景,设计并落地了一套限流防护 + 多级缓存 + 本地事务事件表 + Canal 异步转发 的完整高并发社交关系架构,通过前置流量拦截、事务保障事件可靠落地、分层缓存提升查询性能、异步解耦完成后置业务处理,并搭配定时数据校验机制实现数据兜底纠偏,从请求入口到最终数据同步全链路完成优化,在保证系统高性能运行的同时,彻底解决幂等性、消息可靠性、缓存一致性等核心痛点,本文将完整拆解整套架构设计思路、核心代码实现与落地实践经验。
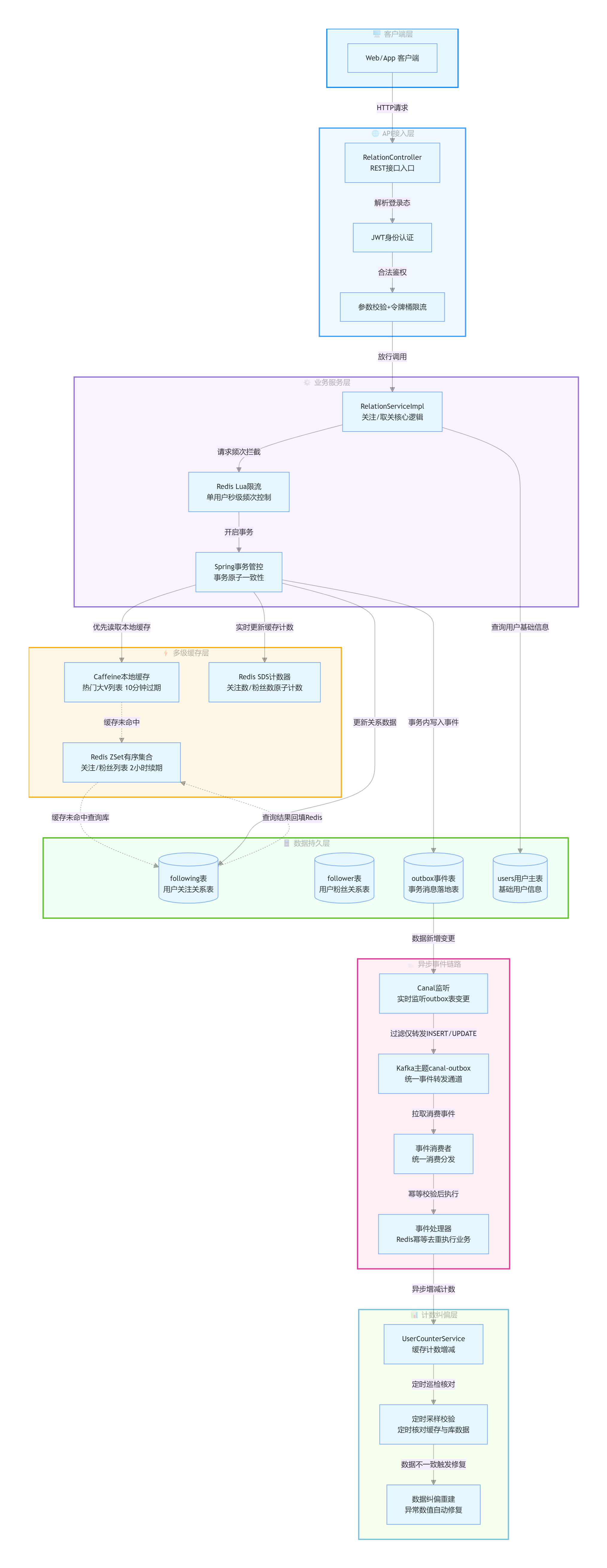
一、整体技术架构总览
分层架构设计:客户端层、API 接入层、业务服务层、多级缓存层、数据持久层、异步事件层、计数纠偏层 核心技术栈梳理:SpringBoot、Redis、Lua 限流、Caffeine 本地缓存、MyBatis、Outbox 事务表、Canal、Kafka
全链路核心流转简述:用户请求→鉴权限流→业务事务→库表写入→事件投递→异步消费→数据更新
二、API 接入层设计:
- 身份安全:JWT 登录鉴权,拦截未登录非法请求(采用双令牌认证,RAS加密算法)
- 基础防护:接口参数统一校验,过滤非法参数
- 流量防护:Redis Lua 令牌桶限流实现,控制单用户关注频次,防恶意刷接口
lua令牌桶设计,限流,防止一个用户指定时间内最多发多少请求
初始桶中有100个令牌,以后每秒生成1个,如果一瞬间有100个请求,消耗完所有令牌,就会拒绝后续的请求同时如果桶满了,后续生成的令牌会直接丢弃
Lua
private static final String TOKEN_BUCKET_LUA = """
local key = KEYS[1]
local capacity = tonumber(ARGV[1])
local rate = tonumber(ARGV[2])
local now = redis.call('TIME')[1]
local last = redis.call('HGET', key, 'last')
local tokens = redis.call('HGET', key, 'tokens')
if not last then last = now; tokens = capacity end
local elapsed = tonumber(now) - tonumber(last)
local add = elapsed * rate
tokens = math.min(capacity, tonumber(tokens) + add)
if tokens < 1 then redis.call('HSET', key, 'last', now); redis.call('HSET', key, 'tokens', tokens); return 0 end
tokens = tokens - 1
redis.call('HSET', key, 'last', now)
redis.call('HSET', key, 'tokens', tokens)
redis.call('PEXPIRE', key, 60000)
return 1
""";三、核心业务服务层设计
- 关注 / 取消关注核心业务逻辑拆分
关注操作:lua令牌桶限流,并将时间写入outbox表
java
@Override
@Transactional
public boolean follow(long fromUserId, long toUserId) {
// Lua 脚本令牌桶限流--同一个用户1s内最多发起多少关注
Long ok = redis.execute(tokenScript, List.of("rl:follow:" + fromUserId), "100", "1");
if (ok == 0L) {
return false;
}
//调用线程安全的随机数生成工具,生成一个超大随机数,作为数据库主键ID
long id = ThreadLocalRandom.current().nextLong(Long.MAX_VALUE);
int inserted = mapper.insertFollowing(id, fromUserId, toUserId, 1);
if (inserted > 0) {
try {
Long outId = ThreadLocalRandom.current().nextLong(Long.MAX_VALUE);
String payload = objectMapper.writeValueAsString(new RelationEvent("FollowCreated", fromUserId, toUserId, id));
outboxMapper.insert(outId, "following", id, "FollowCreated", payload);
} catch (Exception ignored) {}
return true;
}
return false;
}取关操作:写入outbox事件
java
/**
* 取消关注操作,并写入 Outbox 事件。
* @param fromUserId 发起取消关注的用户ID
* @param toUserId 被取消关注的用户ID
* @return 是否取消成功
*/
@Override
@Transactional
public boolean unfollow(long fromUserId, long toUserId) {
int updated = mapper.cancelFollowing(fromUserId, toUserId);
if (updated > 0) {
try {
Long outId = ThreadLocalRandom.current().nextLong(Long.MAX_VALUE);
String payload = objectMapper.writeValueAsString(new RelationEvent("FollowCanceled", fromUserId, toUserId, null));
outboxMapper.insert(outId, "following", null, "FollowCanceled", payload);
} catch (Exception ignored) {}
return true;
}
return false;
}- Spring 声明式事务管控:保证关系表与事件表写入原子性
- 分布式幂等设计:Redis 唯一键去重,杜绝 MQ 重复消费导致业务重复执行
查看是否是第一次,防止消息重复执行业务
java
String dk = "dedup:rel:" + evt.type() + ":" + evt.fromUserId() + ":" + evt.toUserId() + ":" + (evt.id() == null ? "0" : String.valueOf(evt.id()));
Boolean first = redis.opsForValue().setIfAbsent(dk, "1", Duration.ofMinutes(10));- 主键 ID 生成方案:高性能随机长整型替代自增主键
四、多级缓存架构:支撑高并发列表查询
- 三级缓存整体设计思路:本地缓存→Redis 缓存→数据库
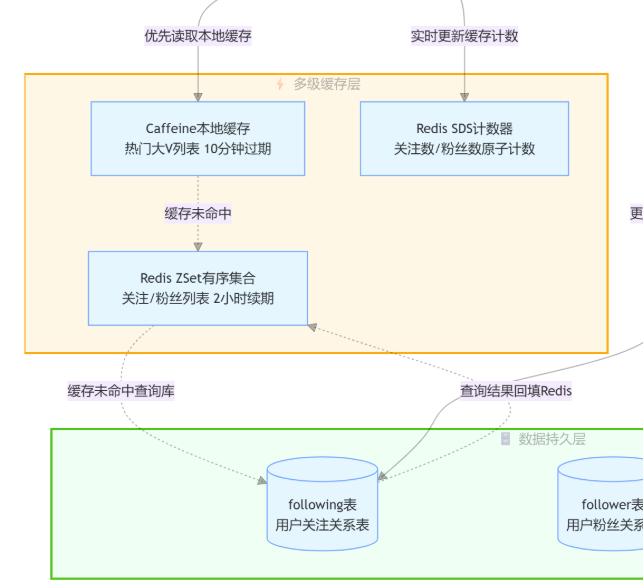
- Caffeine 本地缓存:热门大 V 用户缓存,减轻 Redis 压力。头部大 V 用户的关注 / 粉丝列表会产生超高频率的查询流量 。如果所有请求都直接访问 Redis,甚至穿透到数据库,会造成极大的资源浪费,也容易在热点访问下产生性能瓶颈。因此,我在架构中引入 Caffeine 本地缓存 ,专门对大 V 热点数据进行前置缓存
java
this.flwsTopCache = Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(Duration.ofMinutes(10)).build();
this.fansTopCache = Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(Duration.ofMinutes(10)).build();- Redis ZSet 有序集合:存储关注 / 粉丝列表,按关注时间排序,自动 2 小时续期过期策略
java
public void process(RelationEvent evt) {
String dk = "dedup:rel:" + evt.type() + ":" + evt.fromUserId() + ":" + evt.toUserId() + ":" + (evt.id() == null ? "0" : String.valueOf(evt.id()));
Boolean first = redis.opsForValue().setIfAbsent(dk, "1", Duration.ofMinutes(10));
// 非首次(存在去重键)直接返回,保证消息幂等,防止网络波动,消费者重启,重平衡,重试机制
if (first == null || !first) {
return;
}
if ("FollowCreated".equals(evt.type())) {
// 异步插入粉丝表
mapper.insertFollower(evt.id(), evt.toUserId(), evt.fromUserId(), 1);
long now = System.currentTimeMillis();
// 更新关注表与粉丝表缓存:ZSet 按时间分数维护最近项,设置短 TTL 减少陈旧数据
redis.opsForZSet().add("uf:flws:" + evt.fromUserId(), String.valueOf(evt.toUserId()), now);
redis.opsForZSet().add("uf:fans:" + evt.toUserId(), String.valueOf(evt.fromUserId()), now);
//使用redis.expire设置缓存过期时间
redis.expire("uf:flws:" + evt.fromUserId(), Duration.ofHours(2));
redis.expire("uf:fans:" + evt.toUserId(), Duration.ofHours(2));
// 更新关注数与粉丝数
userCounterService.incrementFollowings(evt.fromUserId(), 1);
userCounterService.incrementFollowers(evt.toUserId(), 1);
} else if ("FollowCanceled".equals(evt.type())) {
mapper.cancelFollower(evt.toUserId(), evt.fromUserId());
// 更新关注表与粉丝表缓存:移除 ZSet 项并刷新 TTL
redis.opsForZSet().remove("uf:flws:" + evt.fromUserId(), String.valueOf(evt.toUserId()));
redis.opsForZSet().remove("uf:fans:" + evt.toUserId(), String.valueOf(evt.fromUserId()));
redis.expire("uf:flws:" + evt.fromUserId(), Duration.ofHours(2));
redis.expire("uf:fans:" + evt.toUserId(), Duration.ofHours(2));
// 更新关注数与粉丝数
userCounterService.incrementFollowings(evt.fromUserId(), -1);
userCounterService.incrementFollowers(evt.toUserId(), -1);
}
}- Redis SDS 计数器:轻量化存储用户关注数、粉丝数,实现高速原子增减
- 缓存读写逻辑:查询优先走缓存、缓存击穿回源数据库、查询数据自动回填缓存
五、数据持久层设计
- 核心数据表结构设计
- following 关注关系表(逻辑删除设计)
- follower 粉丝关系表
- outbox 事务事件表(核心事务消息载体)
- user 用户基础信息表
- 逻辑删除优势:适配业务取关场景,摒弃物理删除
- Outbox 事务消息核心作用:解决本地事务与 MQ 消息一致性问题
六、异步事件通信核心链路
- 传统直发 MQ 弊端:事务不一致、消息丢失、耦合度高
- Outbox 模式的核心思想是将事件消息与业务数据纳入同一个本地事务,在更新业务数据的同时,向事件表插入一条消息,通过数据库事务原子性保证 "数据入库 + 事件落地" 要么全部成功,要么全部失败。再通过 Canal 监听表变化实现无侵入式消息投递,不依赖分布式事务、不依赖消息中间件可靠性,从架构层面彻底解决消息丢失、数据不一致、业务耦合等难题,实现轻量级、高可靠、可扩展的异步事件通信。
- Canal 监听机制:仅监听 outbox 表 INSERT/UPDATE 变更,过滤无用删除事件
创建Canalkafka桥接器,拉去未处理消息
java
// 创建 Canal 单实例连接器并建立连接
connector = CanalConnectors.newSingleConnector(new InetSocketAddress(host, port), destination, username, password);
log.info("Canal connecting to {}:{} dest={} user={} filter={}", host, port, destination, username, filter);
connector.connect();
// 订阅过滤表达式,仅拉取关心的表(如 outbox)
connector.subscribe(filter);
// 回滚到上次确认位点,保证一致性处理
connector.rollback();
log.info("Canal connected and subscribed: host={} port={} dest={} filter={} batchSize={} intervalMs={}ms", host, port, destination, filter, batchSize, intervalMs);
while (running) {
// 拉取一批未确认消息(不自动 ack)
Message message = connector.getWithoutAck(batchSize);- Canal 数据组装转发:解析库表变更数据,封装统一 JSON 格式推送 Kafka
java
try {
//把kafka消息转换成多行数据表
List<JsonNode> rows = OutboxMessageUtil.extractRows(objectMapper, message);
if (rows.isEmpty()) {
ack.acknowledge();
return;
}
for (JsonNode row : rows) {
JsonNode payloadNode = row.get("payload");
if (payloadNode == null) {
continue;
}
//将json转换成要读的字符串
RelationEvent evt = objectMapper.readValue(payloadNode.asText(), RelationEvent.class);
processor.process(evt);
}
ack.acknowledge();
} catch (Exception ignored) {}
}- Kafka 消费者消费流程:事件接收→幂等二次校验→执行后置业务
写入Redis,写入follower表
- 消费后置业务:更新缓存列表、维护用户计数、同步上下游业务数据
七、用户计数精准保障体系
- 实时计数更新:业务侧 + 消费侧双端维护计数
- 定时采样校验机制:定时核对缓存计数与数据库真实关系数量
- 自动数据纠偏修复:解决缓存失效、消息丢失导致计数错乱问题
八、业务核心问题解决方案
-
解决用户频繁重复点击关注 采用Redis Lua 令牌桶接口限流 做前置流量拦截,搭配Redis 唯一维度键实现分布式幂等双重防护,从请求入口与业务执行两层杜绝重复关注操作,避免无效请求冲击业务逻辑。
-
解决关注与取关场景缓存数据不一致用户执行关注、取消关注操作时,实时刷新对应 Redis ZSet 有序集合缓存过期时间,依托自动续期策略保障热数据有效留存,同时同步增删缓存内关系数据,彻底抹平缓存与业务状态偏差。
-
解决异步业务消息丢失、投递不可靠问题 摒弃直连 MQ 易出现的事务不一致问题,基于Outbox 本地事务事件表实现事务内事件落地,再通过 Canal 监听事件表变更结合 Kafka 完成异步转发,构建零丢失、高可靠的事件推送链路。
-
解决粉丝、关注列表深分页查询卡顿优先使用 Redis ZSet 有序集合实现分页查询,依托集合天然排序特性适配按时间倒序业务需求,仅缓存未命中、深分页场景下才回源数据库查询,大幅优化分页查询响应速度。
-
解决高并发流量下数据库访问压力过大 搭建Caffeine 本地热点缓存 + Redis 分布式缓存 + MySQL 数据库三级缓存架构,由上至下层层拦截用户查询流量,绝大部分热点请求直接走缓存响应,极大降低数据库查询与写入压力。
九、架构优势总结
-
高可用依托 Spring 事务保障业务数据写入原子性,结合 Outbox+Canal 构建可靠事件链路,既保证库表数据不会出现错乱偏差,又能实现业务事件百分百不丢失,整体业务流转稳定可靠。
高性能搭建本地缓存 + Redis 分布式缓存 + 数据库三级缓存体系,依靠多级缓存完成流量削峰与热点数据承载,日常绝大多数查询请求直接命中缓存响应,极少流量穿透至数据库,接口响应速度与系统吞吐能力大幅提升。
高扩展采用事件驱动架构实现业务完全解耦,核心关注取关逻辑与下游计数、数据同步等后置业务彻底隔离,后续新增业务消费场景,仅需新增消费者即可接入,无需改动核心业务代码,业务拓展灵活便捷。
易维护整体采用分层清晰的模块化架构,各层级职责明确,线上问题可快速定位溯源;同时内置定时采样校验与自动纠偏机制,具备数据自愈修复能力,大幅降低后期运维与故障排查成本。