论文题目:Mono3DVLT: Monocular-Video-Based 3D Visual Language Tracking(Mono3DVLT:基于单眼视频的3D视觉语言跟踪)
会议:CVPR2025
摘要:视觉语言跟踪(VLT)正在成为弥合人机性能差距的一个有前途的范例。对于单个对象,VLT将问题范围扩大到文本驱动的视频理解。然而,这个方向仍然局限于2D空间范围,目前缺乏在单目视频范围内处理3D跟踪的能力。不幸的是,3D跟踪的进步主要依赖于昂贵的传感器输入,例如点云、深度测量、雷达。缺乏语言对应的输出这些温和民主化的传感器在文献中也阻碍了VLT扩展到3D跟踪。为了解决这个问题,我们首次尝试将VLT扩展到基于单目视频的3D跟踪。我们提出了一个全面的框架,介绍了(i)基于单眼视频的3D视觉语言跟踪(Mono3DVLT)任务,(ii)该任务的大规模数据集,称为Mono3DVLT- v2x,以及(iii)该任务的定制神经模型。我们的数据集是精心策划的,利用大型语言模型(大型语言模型),然后进行人工验证,为79,158个针对单个对象跟踪的视频序列组成自然语言描述,提供2D和3D边界框注释。我们的神经模型,称为Mono3DVLT- mt,是Mono3DVLT任务的第一个目标方法。该模型由多模态特征提取器、视觉语言编码器、跟踪解码器和跟踪头组成,为Mono3DVLT-V2X上的任务设置了强大的基线。实验结果表明,该方法在Mono3DVLT-V2X数据集上显著优于现有技术。
数据集和代码可在https://github.com/hongkai-wei/Mono3DVLT中获得。

Mono3DVLT - 突破性的单目视频3D视觉语言跟踪框架
引言:人类如何追踪物体?
想象一下,当你在繁忙的街道上追踪一辆白色汽车时,你会怎么做?你的大脑会综合利用视觉信息(汽车的外观、位置)和语义理解("那辆靠右边的第二辆白色轿车"),然后在3D空间中持续追踪它。这个看似简单的过程,对计算机视觉系统来说却是一个巨大的挑战。
今天,我要为大家介绍一篇发表在CVPR 2025上的突破性论文:Mono3DVLT: Monocular-Video-Based 3D Visual Language Tracking。这项工作首次实现了仅使用单目视频和自然语言描述的3D目标跟踪,让机器更接近人类的跟踪方式。
现有方法的局限性
问题1:2D视觉语言跟踪的维度困境
当前的视觉语言跟踪(VLT)技术虽然能够结合图像和文本信息,但仅限于2D空间。这就像让一个只能看平面图的人去导航三维世界------信息是不完整的。
问题2:3D跟踪的"传感器依赖症"
传统3D目标跟踪严重依赖:
- LiDAR点云:昂贵且计算密集
- 深度相机:受环境光照影响
- 雷达传感器:空间分辨率有限
这些方案与人类仅凭双眼就能进行3D跟踪的能力相去甚远,而且成本高昂,限制了大规模应用。
问题3:研究空白
没有针对性的数据集和基准方法,使得研究者无法系统地探索这个方向。
Mono3DVLT的创新解决方案

创新1:全新的任务定义
论文首次定义了Mono3DVLT任务:
使用单目RGB视频和自然语言描述,在3D空间中追踪单个目标物体
这个任务设定更符合人类的感知方式,仅需:
- ✅ 普通RGB摄像头
- ✅ 自然语言描述
- ❌ 不需要LiDAR
- ❌ 不需要深度传感器
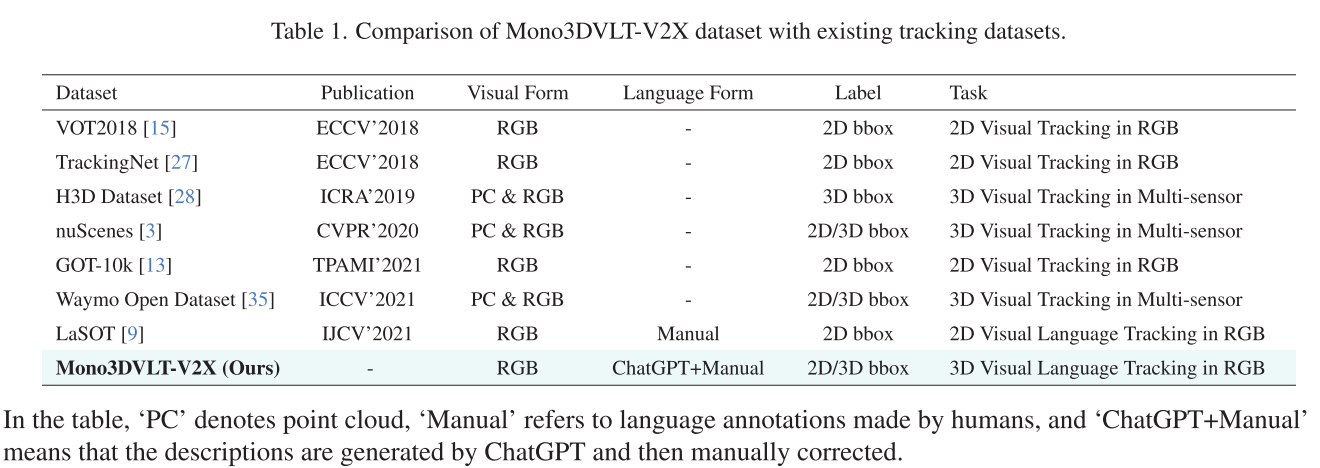
创新2:大规模数据集 Mono3DVLT-V2X
数据集规模
- 79,158个视频序列,每个都配有精心设计的语言描述
- 平均每个描述176个单词,提供丰富的语义信息
- 同时提供2D和3D边界框标注
创新的数据生成流水线
论文设计了一个三阶段的数据生成方法:
阶段1:属性提取
从原始数据中提取两类属性:
- 静态属性:颜色、状态、长度、宽度、高度、类型
- 动态属性:截断、遮挡、旋转、距离、网格位置、序号、方向、空间关系
阶段2:ChatGPT生成描述
使用精心设计的提示模板,将提取的属性填入,让ChatGPT生成自然流畅的描述。例如:
"一辆明显的白色汽车,高1.5米,长4.1米,宽2.2米,从起始位置距离38.9米,方位角110度处移动,位于画面右中区域,是该区域的第二辆车。最初,车辆未被截断,面向左侧..."
阶段3:人工验证
由5人团队共同验证,确保描述能够唯一识别目标对象。
创新3:Mono3DVLT-MT神经网络架构
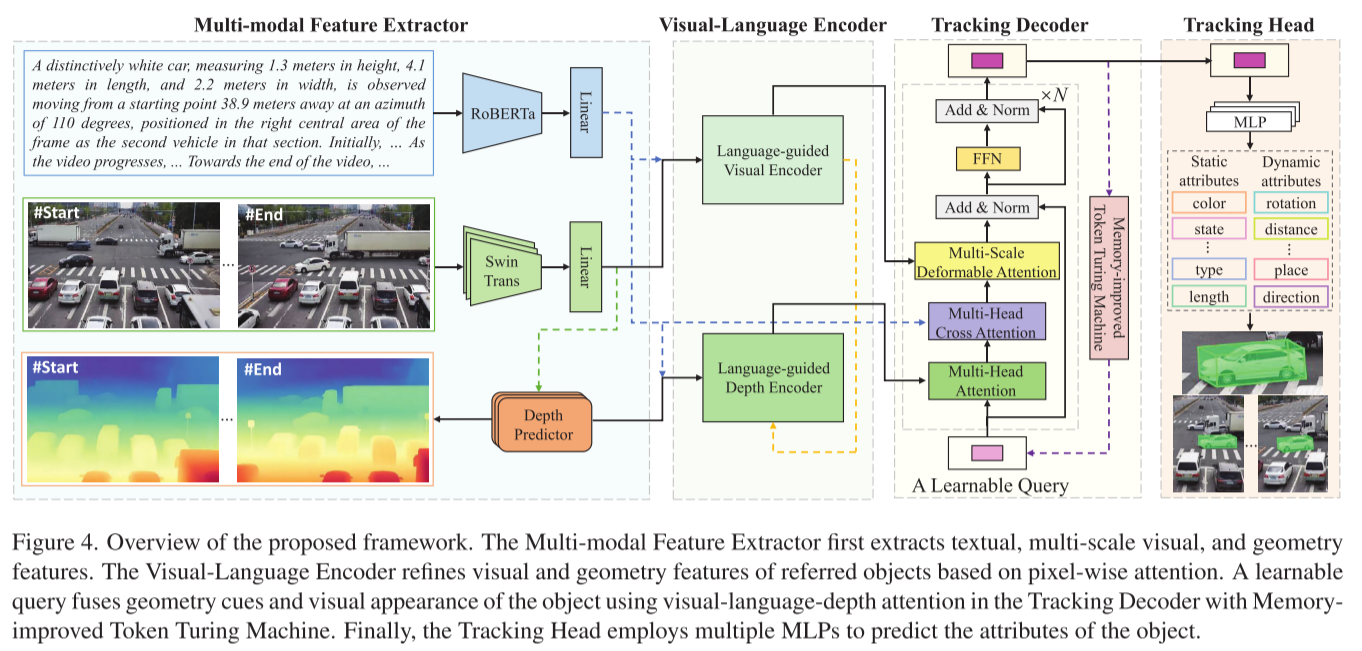
模块1:多模态特征提取器
这个模块负责从不同模态提取特征:
- RoBERTa → 提取语言token特征 (f_l)
- Swin Transformer → 提取4个层级的多尺度视觉特征 (f_v)
- 轻量级深度预测器 → 提取几何特征 (f_d)
模块2:视觉-语言跟踪编码器
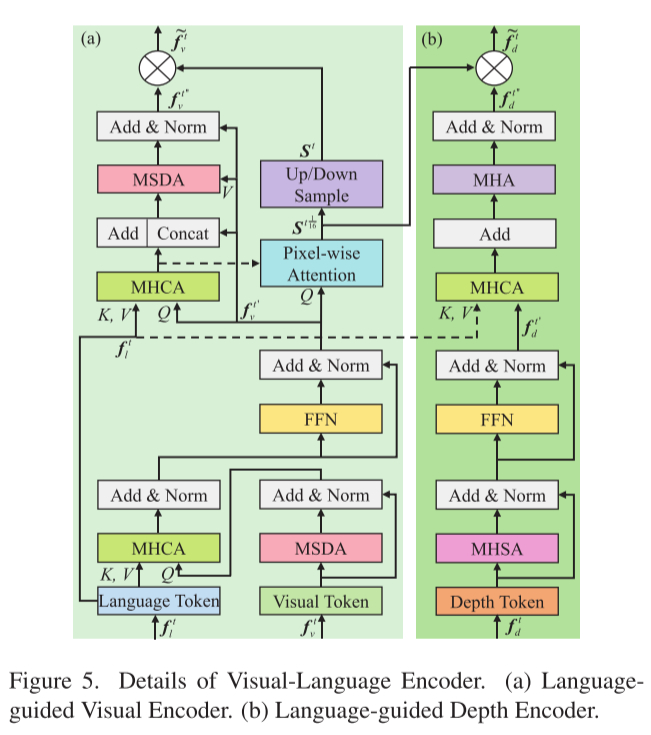
这是论文的核心创新之一,包含两个关键编码器:
语言引导的视觉编码器
- 使用**多尺度可变形注意力(MSDA)**替代传统自注意力,降低计算复杂度
- 通过**多头交叉注意力(MHCA)**融合语言线索
- 计算像素级注意力分数,突出与文本描述相关的视觉区域
语言引导的深度编码器
- 使用深度token作为查询
- 使用语言token作为键和值
- 融合几何和语义信息
像素级注意力机制:
通过高斯函数建模语义相似性:
S = α · exp(-(1 - similarity)² / 2σ²)这个机制确保模型关注与语言描述最相关的图像区域。
模块3:记忆增强跟踪解码器
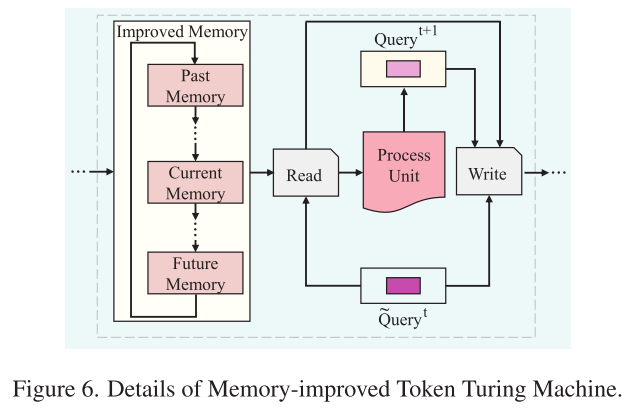
使用改进的Token Turing Machine(TTM):
- 三种记忆状态:过去(M_{t-1})、当前(M_t)、未来(M_{t+1})
- 读取操作:从多个时间步的记忆中提取信息
- 处理操作:使用Transformer更新query
- 写入操作:将更新后的信息写回记忆
这种机制让模型能够:
- ✅ 保持历史跟踪信息
- ✅ 实现时序一致性
- ✅ 提高长时间跟踪的鲁棒性
模块4:跟踪头
使用多个MLP分别预测:
- 目标类别(3层MLP + Focal Loss)
- 2D边界框(l, r, t, b坐标)
- 3D中心坐标(x3D, y3D)
- 3D尺寸(h3D, w3D, l3D)
- 方向角(θ)
- 深度(d_reg)
损失函数综合了2D、3D和深度图损失:
L_overall = L_2D + L_3D + L_dmap实验结果:全面领先
定量结果分析
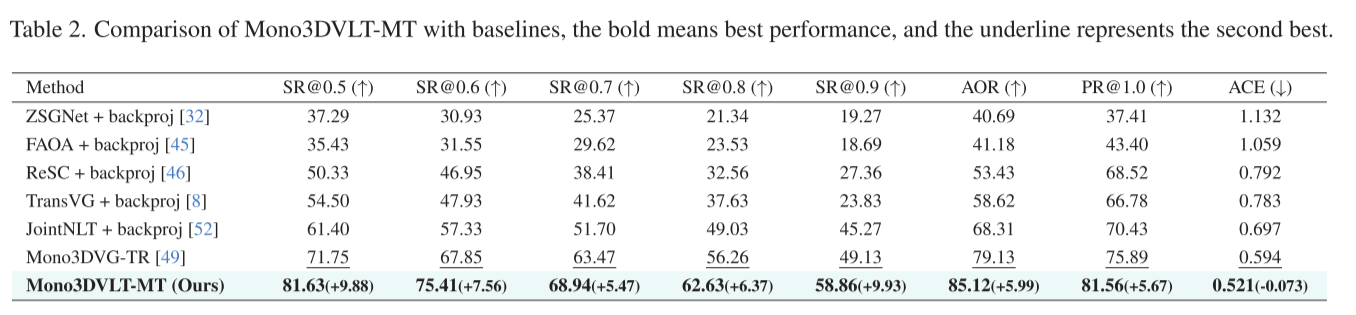
与最佳基线方法Mono3DVG-TR相比,Mono3DVLT-MT取得了全面提升:
核心指标提升
- SR@0.5: 81.63% (↑9.88%) - 在IoU阈值0.5下的成功率
- SR@0.9: 58.86% (↑9.93%) - 在严格阈值下仍保持大幅领先
- AOR: 85.12% (↑5.99%) - 平均重叠率,衡量整体跟踪质量
- PR@1.0: 81.56% (↑5.67%) - 精确率
- ACE: 0.521像素 (↓0.073) - 平均中心误差极低
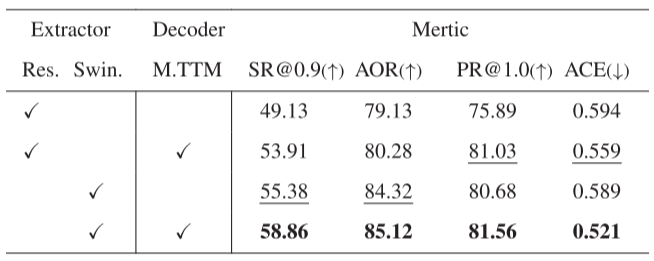
消融实验:验证设计有效性
论文进行了详细的消融实验,验证每个组件的贡献:
1. 特征提取器对比
- ResNet50 → Swin Transformer: SR@0.9从49.13%提升到53.91%
- 结论:Swin Transformer的分层结构和预训练更适合这个任务
2. 记忆增强解码器
- 无记忆 → 有记忆(TTM): SR@0.9从53.91%提升到58.86%
- 结论:历史信息对于连续跟踪至关重要
定性结果:可视化对比

论文提供的可视化结果显示:
- TransVG + backproj: 中心位置偏差大,依赖2D投影导致误差累积
- Mono3DVG: 中心预测改善,但仍存在尺寸和方向误差
- Mono3DVLT-MT: 3D边界框与真实值高度吻合,IoU分数最高
技术亮点与创新总结
🎯 核心优势
-
无需昂贵传感器
- 仅需普通RGB相机
- 显著降低部署成本
- 更容易大规模应用
-
充分利用语言信息
- 像素级注意力机制
- 语言引导的特征学习
- 多模态深度融合
-
时序信息建模
- Memory-improved TTM机制
- 跨帧信息传递
- 提高长时间跟踪稳定性
-
端到端可训练
- 统一的优化目标
- 联合2D和3D监督
- 简化训练流程
🔬 技术创新
创新1:像素级视觉-语言对齐 通过高斯函数建模语义相似性,精确定位与文本描述相关的图像区域。
创新2:多尺度可变形注意力 降低传统自注意力的计算复杂度,同时保持多尺度特征融合能力。
创新3:三态记忆机制 通过维护过去、现在、未来三种状态的记忆,实现更强的时序建模能力。
应用前景与影响
🚗 自动驾驶
- 低成本3D目标跟踪
- 语义理解辅助决策
- 适合量产车型部署
🤖 机器人导航
- 自然语言交互
- 3D场景理解
- 人机协作任务
📹 智能监控
- 基于描述的目标搜索
- 3D轨迹分析
- 异常行为检测
🎮 AR/VR应用
- 自然语言控制
- 虚实融合定位
- 沉浸式交互
局限性与未来方向
当前局限
-
单目深度估计的固有不确定性
- 远距离目标深度精度下降
- 纹理缺失区域估计困难
-
计算复杂度
- 多尺度特征处理
- 记忆机制开销
-
语言描述依赖
- 需要详细的文本描述
- 描述质量影响性能
未来研究方向
方向1:轻量化设计
- 模型压缩与加速
- 移动端部署优化
- 实时性能提升
方向2:弱监督学习
- 减少对详细标注的依赖
- 自监督预训练
- 半监督学习方法
方向3:多目标扩展
- 从单目标到多目标跟踪
- 目标间关系建模
- 场景级理解
方向4:跨域泛化
- 从驾驶场景到通用场景
- 域自适应技术
- 零样本/少样本学习
结语
Mono3DVLT这项工作首次实现了基于单目视频的3D视觉语言跟踪,在以下三个方面做出了重要贡献:
- 任务定义:提出了一个新颖且实用的研究问题
- 数据集构建:提供了大规模、高质量的基准数据集
- 方法创新:设计了有效的端到端解决方案
这项工作缩小了机器与人类感知能力的差距,让AI系统能够像人类一样,仅依靠视觉和语言线索就能在3D空间中准确跟踪目标。随着技术的进一步发展和优化,这种方法有望在自动驾驶、机器人、智能监控等众多领域得到广泛应用。
相信这项工作将开启单目视频3D目标跟踪的新方向,启发更多研究者探索视觉、语言和3D几何的深度融合。