本文用 「春眠不觉」→ 补全「晓」 走通 Transformer 从输入到输出的完整链路。文首流程图用 4 字输入演示各步;后文示例多用整句 「春眠不觉晓」 。示例模型为 uer/gpt2-chinese-cluecorpussmall(GPT-2 结构,层数、维度以 config.json 为准)。
Transformer 整体框架
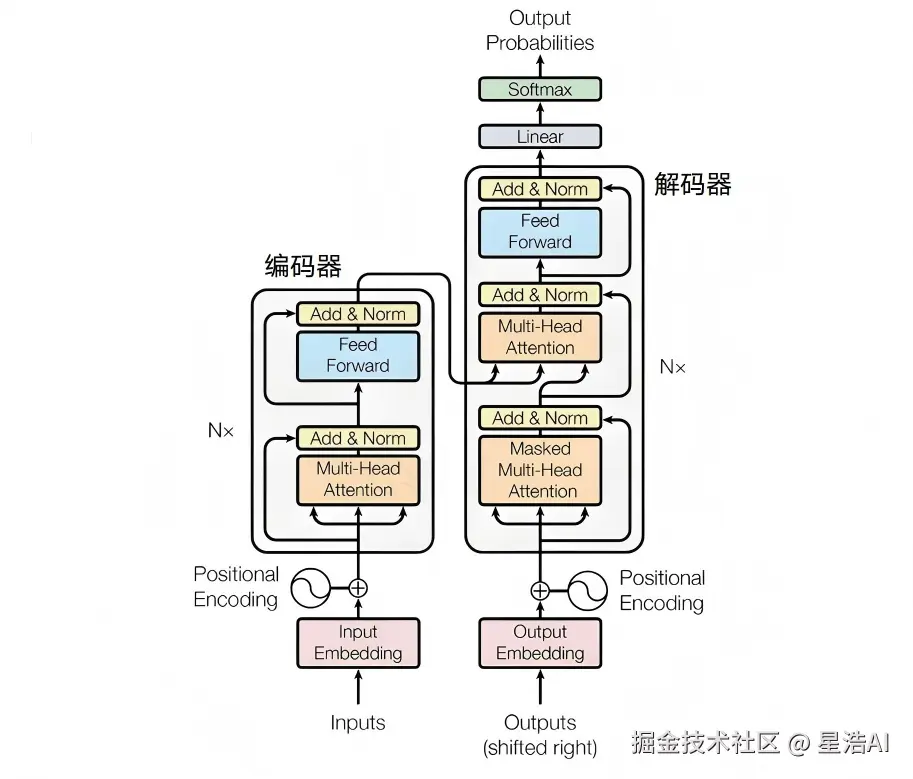
下面用 「春眠不觉」→ 补全「晓」 串起全流程(层数、维度随具体模型而变):
css
输入:"春眠不觉"
│
▼
┌─────────────────────────────────────────┐
│ 1. Tokenize(分词) │
│ ["春", "眠", "不", "觉"] │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 2. 编码(Token → ID) │
│ [102, 235, 301, 189] │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 3. Embedding(如 768 维) │
│ 查表得 [v1, v2, v3, v4] │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 4. 位置编码(Position Embedding) │
│ 与 vi 相加:输入i = vi + pi │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 5. Decoder × N 层(如 12 层,视模型而定) │
│ • Masked Self-Attention │
│ • Feed-Forward Network │
│ • 残差连接 + LayerNorm │
│ (Encoder-Decoder 架构才有 │
│ Cross-Attention,纯 GPT 无此项) │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 6. Linear(输出层 / LM Head) │
│ 隐状态 → 词表大小(如 21128)→ logits │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 7. Softmax │
│ logits → 词表上的概率分布 │
└─────────────────────────────────────────┘
│
▼
概率示意(词表维度,非句中第几位):
[0, 0, ..., 0.92, ..., 0] → 「晓」对应下标概率最高
│
▼
输出 Token:"晓"
最终句子:"春眠不觉晓"后文各节按 1 → 7 的顺序展开说明。
文本转换为Token
把一段文字变成一组 Token ,这一过程叫 词元化(Tokenization) 。
Transformer 处理自然语言的第一步:模型只能对数字做矩阵运算,不能直接处理汉字或英文,因此须先把文本切成离散单元,再映射为整数编号。
分词器做什么?
对应上文流程图的 第 1、2 步 (Tokenize → 编码),由 Tokenizer(分词器) 完成:
| 人类 | 模型 | |
|---|---|---|
| 输入 | 「春眠不觉晓」 | 同一句经词元化后 |
| 实际使用 | 直接理解语义 | [101, 2345, 6789, ...] 这样的 Token ID 序列 |
送进模型的是 ID 序列,不是原始字符串。分词器主要做两件事:
- 切分:把字符串拆成 Token 列表;
- 编码:把每个 Token 换成词表(Vocabulary)里的整数 ID。
训练与推理须用同一套词元化规则;换模型通常也要换对应的分词器,否则 ID 与词义会对不上。
三种词元化粒度:字、词与子词
模型里的 Token 是词元化后交给大模型的最小单元,按切分方式,常见有三类:
| 粒度 | 做法 | 优点 | 缺点 |
|---|---|---|---|
| 字/字符级 | 每个汉字、字母单独成 Token | 词表小,罕见词也能表示 | 序列很长,语义片段被拆碎 |
| 词级 | 按词典切分为完整词语 | 符合直觉 | 词表巨大,未登录词(OOV)难处理 |
| 子词级(Subword) | BPE、WordPiece、SentencePiece 等 | 词表可控,能兼顾常见词与生僻词 | 规则稍复杂,需专门学习 |
当前主流大模型(GPT、BERT、LLaMA 等)几乎都采用子词分词:常见词整段保留,生僻词拆成更小的片段。
从句子到 ID 序列
以句子 「春眠不觉晓」 为例(实际切分结果因模型而异):
css
原文: 春眠不觉晓
Token: [春, 眠, 不, 觉, 晓] ← 词元化后的字符串片段
Token ID: [2345, 1890, 45, 67, 891] ← 词表中的整数编号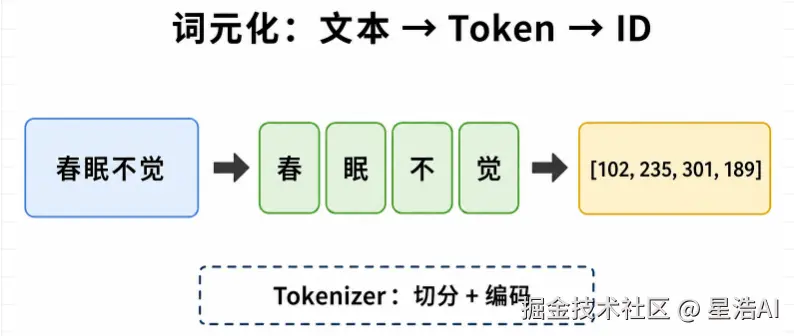
模型后续接收的是 Token ID 序列 ,而不是原始字符串。解码时再用分词器的 decode 把 ID 还原成文字。
特殊 Token
词表里除了普通字词,还预留了一些控制用的符号,例如:
| 符号(示例) | 常见含义 |
|---|---|
[CLS] |
BERT 等用于分类/句首聚合(GPT 生成模型通常不用) |
[SEP] |
句子分隔(多用于 BERT 双句输入) |
| `` | 补齐到同一长度(批处理时) |
[MASK] |
掩码语言模型训练时遮盖的位置 |
<endoftext> |
GPT 类模型生成结束 |
用 Hugging Face 亲手试一次
用 AutoTokenizer 加载与模型配套的分词器:
python
from transformers import AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "春眠不觉晓"
# 编码:文本 → Token ID
encoded = tokenizer(text)
print("Token ID:", encoded["input_ids"])
# 看每个 ID 对应什么片段(便于理解子词切分)
tokens = tokenizer.tokenize(text)
print("Token 片段:", tokens)
# 解码:Token ID → 文本
decoded = tokenizer.decode(encoded["input_ids"])
print("还原文本:", decoded)典型输出形态(具体数字以本机为准;GPT-2 中文多为按字切分,一般不含 BERT 的 CLS/SEP):
less
Token 片段: ['春', '眠', '不', '觉', '晓']
Token ID: [2345, 1890, 45, 67, 891]要点小结:
- Tokenizer 与模型成对使用 :
from_pretrained同一模型名,会下载vocab.txt、tokenizer_config.json等(见下一篇文章模型目录说明)。 - 词表大小(如 21128)决定 Embedding 矩阵行数,即模型最多认识多少个不同 Token。
Token转换为向量
Embedding(嵌入) 把每个 Token ID 映射为一条 hidden_size 维向量(如 768 维)。实现上是查表:矩阵 [词表大小, hidden_size],每个 ID 取一行;n 个 Token 得到 [n, hidden_size]。
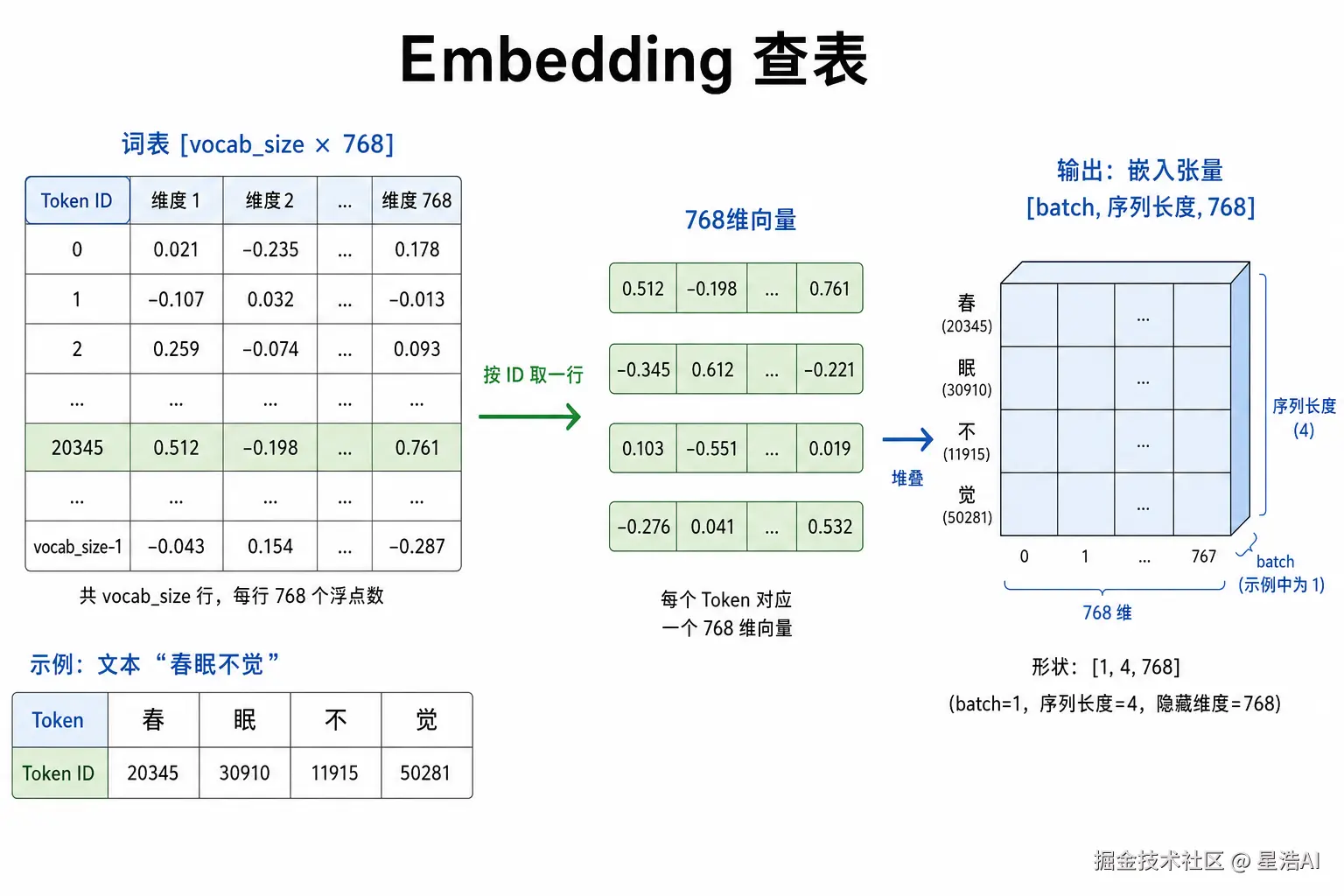
用代码看形状
python
import torch
from transformers import AutoModel, AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
text = "春眠不觉晓"
inputs = tokenizer(text, return_tensors="pt")
input_ids = inputs["input_ids"]
print("Token ID 张量:", input_ids.shape)
# 取出模型的词嵌入层
embed_layer = model.get_input_embeddings()
token_vectors = embed_layer(input_ids)
print("Token 向量张量:", token_vectors.shape)
print("hidden_size:", model.config.hidden_size)若 hidden_size 为 768、分词后序列长度为 5,则 token_vectors.shape 多为 torch.Size([1, 5, 768]):
| 维度 | 含义 |
|---|---|
第 1 维 1 |
batch,一次 1 条句子 |
第 2 维 5 |
序列中 5 个 Token |
第 3 维 768 |
每个 Token 一条 768 维向量 |
要点小结:
- Embedding 把离散 ID 变成连续向量,是第一个可学习的语义表示层。
- 走完整 Transformer 后,同一词在不同上下文里向量还会被后续层改写;本节是刚查表时的初始向量。
向量中加入位置信息
Embedding 只按 Token ID 查表,同一字在不同位置查到的向量相同------还须知道顺序 。例如「狗 咬人」与「人咬狗」,词一样,顺序不同,意思相反。
怎么做:位置向量与 Token 向量相加
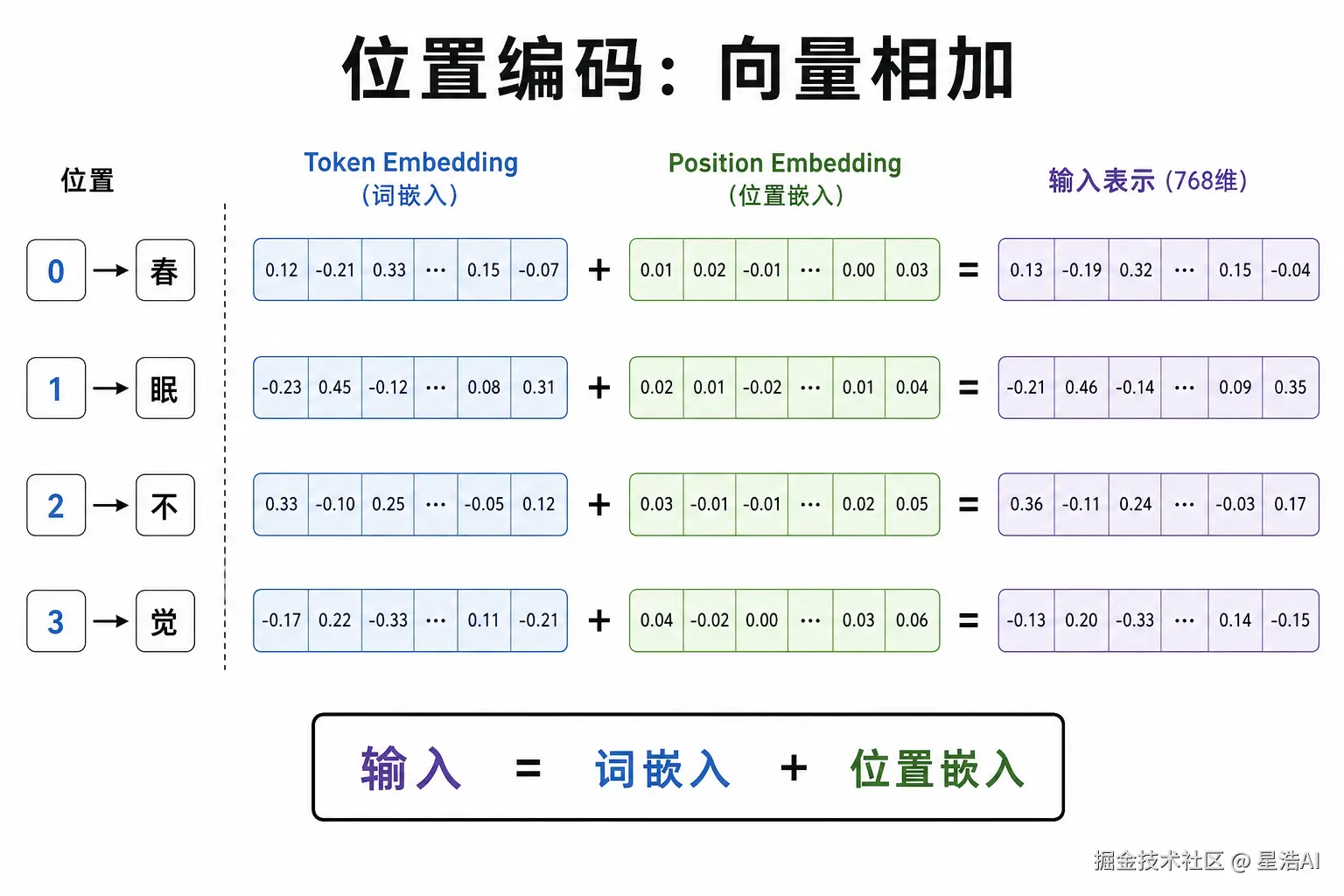
css
输入表示 = Token Embedding + Position Embedding| 方式 | 说明 |
|---|---|
| 正弦位置编码 | 原始论文用 sin/cos 生成,不增加可训练参数 |
| 可学习位置编码 | GPT-2、BERT:每个位置一行可训练向量 |
相加后,同一 Token 在不同位置上的输入向量不同,后续自注意力才能区分先后。
用代码看一眼(GPT-2)
GPT-2 使用可学习位置编码,内部大致是「词嵌入 + 位置嵌入」:
python
from transformers import AutoModel, AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
inputs = tokenizer("春眠不觉晓", return_tensors="pt")
# 模型 forward 时会自动把 wte(词嵌入)与 wpe(位置嵌入)相加
outputs = model(**inputs)
print(outputs.last_hidden_state.shape) # [1, 序列长度, hidden_size]要点小结:
- Embedding 管「是什么词」,位置编码管「在第几位」。
- 没有位置信息,模型无法稳定区分语序。
深度理解语义
「春」在「春眠不觉晓」和「春色满园」里含义不同------须结合整句其它词 更新每个位置的表示。核心是 自注意力(Self-Attention) :每个 Token 按相关程度汇总句中信息。
Decoder 生成时还用 掩码自注意力(Masked Self-Attention) :当前位置不能看见后面的词,避免「偷看答案」。
自注意力 :以 「春」 为例(见下图),按 Q / K / V 三步融合全句------
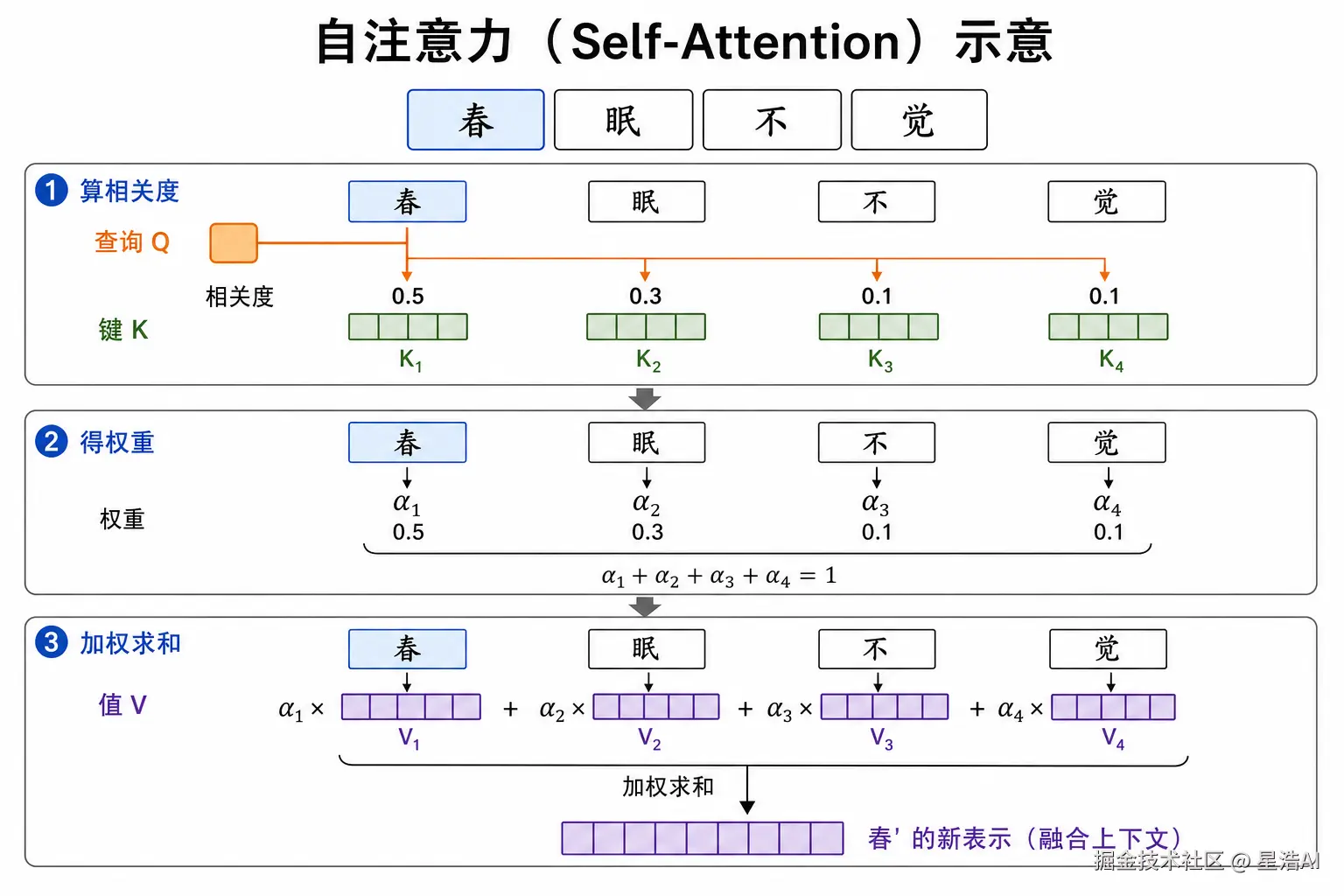
- 算相关度 :「春」的 Q 与每个词的 K 比对;
- 得权重:Softmax 归一,权重和为 1;
- 加权求和 :对 V 加权,得到 春'。
| 符号 | 含义(通俗理解) |
|---|---|
| Q | 当前词「想找什么」 |
| K | 每个词「能提供什么匹配信息」 |
| V | 每个词「实际贡献的语义内容」 |
句中每个词都会走一遍(也会看自己),因此叫「自」注意力。
一层 Block 与多层堆叠 :把 多头注意力(MHA) 与 前馈网络(FFN) 组成一层 Transformer Block (各带一次 Add & Norm),再 叠 N 层 ------对应文首第 5 步与整体架构图(1-1.png)里 Decoder 的 Nx。
多头 是同一层内多路并行,多层 是同一种 Block 重复很多遍(二者含义不同)。叠完后得到 last_hidden_state ,供下文映射到词表。本文为 仅 Decoder 的 GPT;理解类常用 Encoder(如 BERT),翻译等用 Encoder-Decoder。
python
outputs = model(**inputs)
hidden = outputs.last_hidden_state # [1, 序列长度, hidden_size]生成"下一个字"的权重分布
对应文首流程图 第 6 步 。最后一层每个位置是一条 hidden_size 维向量,经 Linear(LM Head) 映射到整个词表 ,得到每个候选 Token 的 logits(未归一化的得分)。
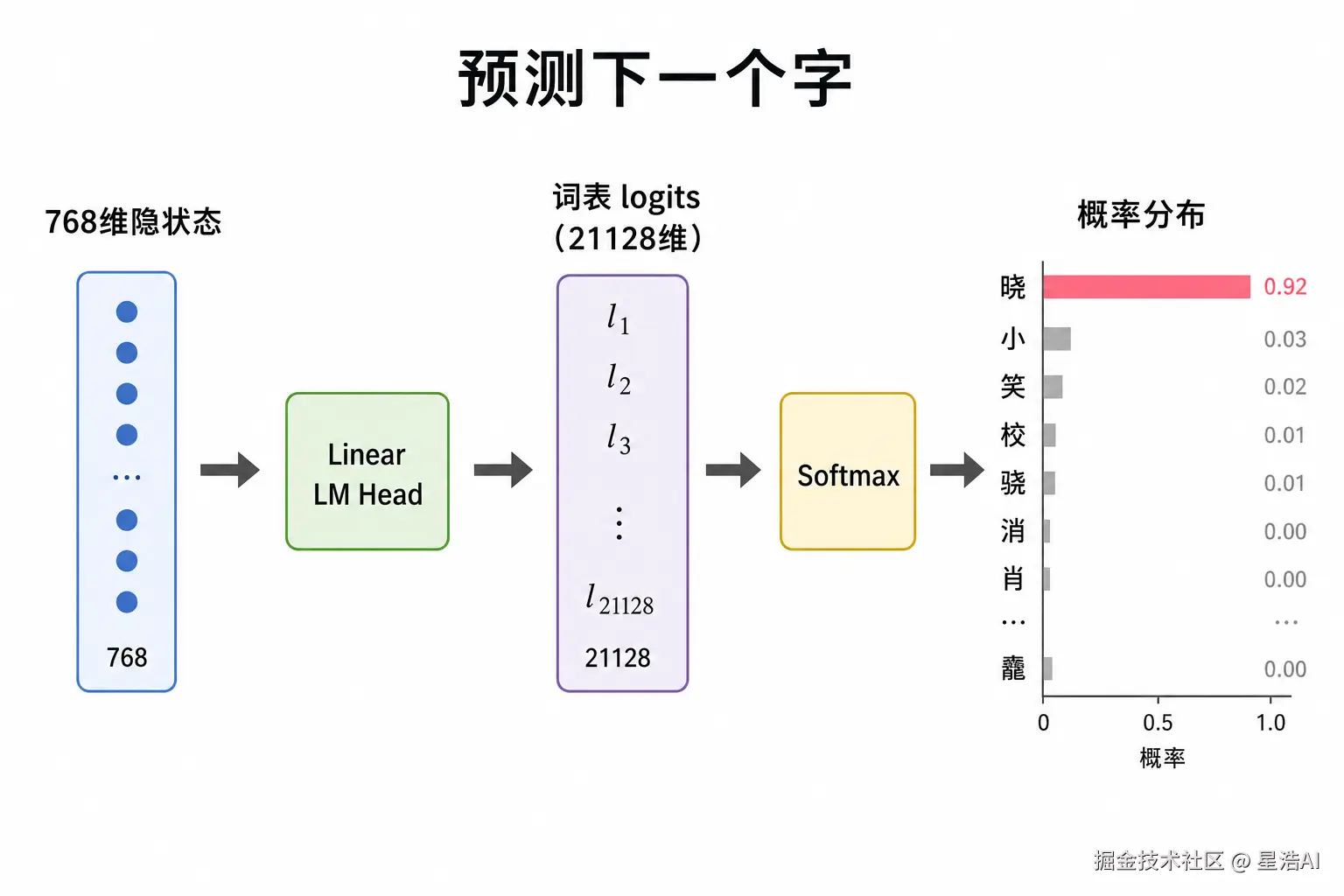
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
inputs = tokenizer("春眠不觉", return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # [1, 序列长度, vocab_size]
print("logits 形状:", logits.shape)
print("词表大小:", model.config.vocab_size)
# 通常取最后一个位置的 logits,用于预测「下一个字」
next_logits = logits[0, -1, :]将权重分布转换成概率分布
对应文首 第 7 步 。对 logits 做 Softmax ,得到和为 1 的概率 ;再 取概率最大 (贪心)或按概率采样,得到下一个 Token。
以补全 「晓」 为例:词表中「晓」对应位置概率最高,即输出该 Token;再拼回输入,继续预测,直到遇到结束符------这叫 自回归生成。
python
import torch
probs = torch.softmax(next_logits, dim=-1)
pred_id = torch.argmax(probs).item()
print("预测 Token ID:", pred_id)
print("预测片段:", tokenizer.decode([pred_id]))也可用 model.generate 自动完成多轮预测(见 下一篇文章)。
要点回顾
| 步骤 | 做什么 | 本文对应 |
|---|---|---|
| 1--2 | 词元化 → Token ID | Tokenizer |
| 3 | ID → 向量 | Embedding |
| 4 | 加位置信息 | Position Embedding |
| 5 | N 层 Decoder 理解上下文 | 自注意力 + Block × N |
| 6 | 映射到词表得分 | LM Head → logits |
| 7 | 得分 → 概率 → 下一个字 | Softmax + 采样/贪心 |
「春眠不觉」 经上述链路,模型在词表上给 「晓」 较高概率,补全为 「春眠不觉晓」。下一章节中用 Hugging Face 完整跑通加载、生成与本地部署。