前言
如果你正在研究具身智能或者VLA(视觉-语言-动作)模型,你会发现一个有趣的现象:几乎所有最新的开源VLA模型都不约而同地放弃了曾经的王者CLIP,转而使用SigLIP作为它们的视觉-语言编码器。OpenVLA用它,Octo用它,小米的Xiaomi-Robotics-0也用它。为什么SigLIP能在短短一年内就取代CLIP的地位?因为它用一个简单到不能再简单的改动------把softmax换成sigmoid------就解决了CLIP几乎所有的痛点:小批量性能差、内存占用高、训练不稳定。今天我们就来深度拆解这篇来自Google DeepMind的神作,看看这个小小的改动到底有多大的魔力。
论文信息
- 标题:Sigmoid Loss for Language Image Pre-Training
- 会议:ICML 2023
- 单位:Google DeepMind, Zürich, Switzerland
- 代码:github.com/google-research/big_vision
- 论文:https://arxiv.org/pdf/2303.15343
一、为什么我们需要SigLIP?
在SigLIP出现之前,所有的视觉-语言预训练模型(比如CLIP、ALIGN、FLIP)都使用同一个损失函数:基于softmax的对比损失。这个损失函数的思想很简单:让匹配的图文对在特征空间中尽可能接近,不匹配的尽可能远离。
但这个看似完美的损失函数有一个致命的缺陷:它需要在整个批次上进行归一化。这就像是老师给全班同学考试排名次,必须看到所有同学的成绩才能给每个人打分。这带来了两个严重的问题:
- 小批量性能灾难:如果班级人数太少(批量小),排名就没有意义,模型学不到好的特征。CLIP需要至少几千的批量才能有不错的性能。
- 内存爆炸:为了计算所有图文对的相似度,需要在内存中保存一个大小为B×B的矩阵(B是批量大小)。当B=32k时,这个矩阵就有10亿个元素,即使是A100也扛不住。
SigLIP的作者们问了一个简单的问题:我们真的需要排名吗?如果我们给每个图文对单独打分,告诉模型"这对是匹配的"或者"这对是不匹配的",会不会更好?
这个问题的答案就是sigmoid损失。它把对比学习从一个"多分类问题"变成了N个独立的"二分类问题"。就像是老师不再给全班排名,而是给每个学生的每道题单独打分,告诉他们"这道题做对了"或者"这道题做错了"。
二、SigLIP的核心思想:从排名到打分
2.1 传统的Softmax对比损失
我们先回顾一下CLIP使用的softmax对比损失:
−12∣B∣∑i=1∣B∣(logetxi⋅yi∑j=1∣B∣etxi⋅yj+logetyi⋅xi∑j=1∣B∣etyi⋅xj)-\frac{1}{2|\mathcal{B}|} \sum_{i=1}^{|\mathcal{B}|}\left(\log \frac{e^{t x_{i} \cdot y_{i}}}{\sum_{j=1}^{|\mathcal{B}|} e^{t x_{i} \cdot y_{j}}}+\log \frac{e^{t y_{i} \cdot x_{i}}}{\sum_{j=1}^{|\mathcal{B}|} e^{t y_{i} \cdot x_{j}}}\right)−2∣B∣1i=1∑∣B∣(log∑j=1∣B∣etxi⋅yjetxi⋅yi+log∑j=1∣B∣etyi⋅xjetyi⋅xi)
- ∣B∣|\mathcal{B}|∣B∣:批次大小,也就是一个批次中有多少个图文对
- xix_ixi:第iii张图片经过L2归一化后的特征向量
- yiy_iyi:第iii段文本经过L2归一化后的特征向量
- ttt:可学习的温度参数,用于缩放相似度得分
- xi⋅yjx_i \cdot y_jxi⋅yj:图片iii和文本jjj的点积,也就是它们的相似度
通俗解释 :对于每一张图片iii,我们计算它和批次中所有文本的相似度,然后用softmax把这些相似度变成概率分布。我们希望图片iii和它对应的文本iii的概率尽可能大,和其他文本的概率尽可能小。同样地,对于每一段文本iii,我们也做同样的操作。
这个损失函数有两个问题:
- 不对称:需要计算两次softmax,一次是图片到文本,一次是文本到图片
- 全局依赖:每个样本的损失都依赖于批次中所有其他样本
2.2 革命性的Sigmoid对比损失
SigLIP提出的sigmoid损失简单得令人惊讶:
−1∣B∣∑i=1∣B∣∑j=1∣B∣log11+ezij(−txi⋅yj+b)-\frac{1}{|\mathcal{B}|} \sum_{i=1}^{|\mathcal{B}|} \sum_{j=1}^{|\mathcal{B}|} \log \frac{1}{1+e^{z_{i j}\left(-t x_{i} \cdot y_{j}+b\right)}}−∣B∣1i=1∑∣B∣j=1∑∣B∣log1+ezij(−txi⋅yj+b)1
- zijz_{ij}zij:标签,如果图片iii和文本jjj是匹配的,zij=1z_{ij}=1zij=1;否则zij=−1z_{ij}=-1zij=−1
- bbb:新增的可学习偏置项,用于解决正负样本不平衡问题
- 其他符号和上面相同
通俗解释 :对于每一个图文对(i,j)(i,j)(i,j),我们都把它当作一个独立的二分类问题。如果它们是匹配的,我们希望模型输出的概率接近1;如果不匹配,希望概率接近0。sigmoid函数正好能把任意实数映射到(0,1)之间,适合作为二分类的概率。
你可能会问:这么简单的改动,为什么之前没有人想到?
其实不是没有人想到,而是大家都认为正负样本的严重不平衡会让模型学不到东西。在一个批次大小为B的情况下,只有B个正样本,却有B²-B个负样本。也就是说,负样本的数量是正样本的B倍。当B=32k时,负样本是正样本的32000倍!
但SigLIP的作者们发现,只要加入一个简单的偏置项bbb,并把它初始化为-10,就能完美解决这个不平衡问题。这个偏置项会让模型在训练初期倾向于预测所有对都是负样本,然后再慢慢学习区分正样本。
2.3 伪代码实现
SigLIP的损失函数实现起来非常简单,只有几行代码:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
def siglip_loss(img_emb, txt_emb, t_prime, b):
"""
SigLIP损失函数的PyTorch实现
Args:
img_emb: 图片特征 [batch_size, embed_dim]
txt_emb: 文本特征 [batch_size, embed_dim]
t_prime: 可学习的温度参数的对数
b: 可学习的偏置参数
Returns:
loss: SigLIP损失值
"""
# 计算温度参数
t = torch.exp(t_prime)
# L2归一化特征
zimg = F.normalize(img_emb, dim=-1)
ztxt = F.normalize(txt_emb, dim=-1)
# 计算所有图文对的相似度
logits = torch.matmul(zimg, ztxt.T) * t + b
# 创建标签:对角线为1,其他为-1
labels = 2 * torch.eye(logits.shape[0], device=logits.device) - 1
# 计算sigmoid损失
loss = -torch.sum(F.logsigmoid(labels * logits)) / logits.shape[0]
return loss就是这么简单!和CLIP的损失函数相比,它不仅更短,而且更对称,只需要计算一次。
三、让百万级批量成为可能的工程魔法
sigmoid损失最大的优势不是它的性能,而是它的内存效率。因为每个图文对的损失都是独立的,我们不需要在内存中保存整个B×B的相似度矩阵。Google的工程师们更进一步,设计了一个精妙的"分块实现",让内存复杂度从O(B²)降到了O(b²),其中b是每个设备的批量大小。
3.1 分块实现原理
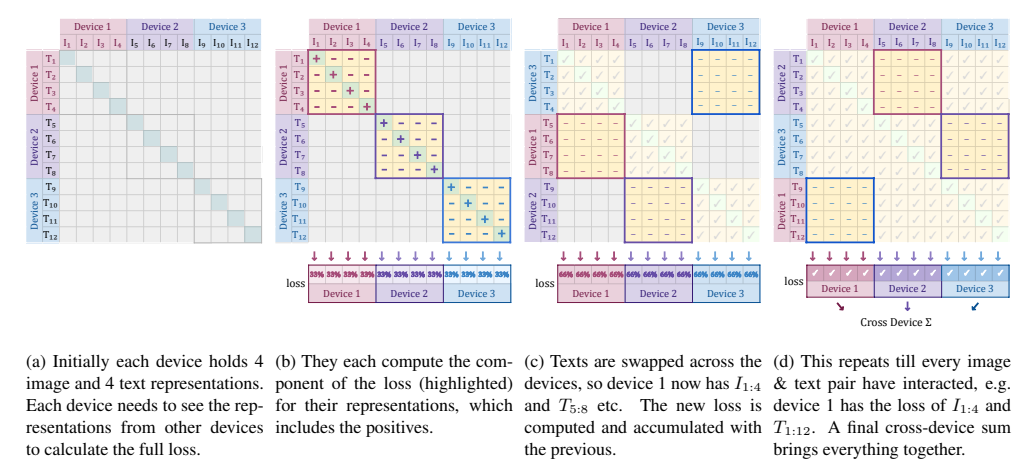
图1:SigLIP的分块损失实现(出处:原文Figure 1)
这个分块实现的思想非常巧妙:
- 初始时,每个设备都有自己的b个图片和b个文本
- 每个设备先计算自己本地的b×b个图文对的损失,这包含了所有的正样本和b-1个负样本
- 然后,设备之间交换文本特征:设备1把自己的文本发给设备2,设备2发给设备3,依此类推
- 每个设备再计算自己的图片和新收到的文本的损失
- 重复这个过程,直到每个设备的图片都和所有设备的文本计算过损失
这样一来,任何时候每个设备的内存中都只需要保存一个b×b的相似度矩阵,而不是B×B的。当有D个设备时,B = D×b,内存占用就变成了原来的1/D²。
举个例子:如果我们有32个设备,每个设备的批量是1024,那么总批量是32768。传统的softmax实现需要保存32768×32768≈10亿个元素的矩阵,而SigLIP的分块实现只需要保存1024×1024≈100万个元素的矩阵,内存占用减少了1000倍!
正是这个分块实现,让SigLIP能够在只有4个TPUv4芯片的情况下训练出批量大小为32k的模型,甚至能够支持高达100万的批量大小。
四、用数据说话:SigLIP到底有多强?
SigLIP的作者们做了非常详尽的实验,从各个角度验证了sigmoid损失的优势。我们来看最关键的几个实验。
4.1 批量大小的影响:32k就足够了!
这是论文中最重要的一个发现:无论是sigmoid损失还是softmax损失,性能都会在批量大小达到32k时饱和,再增大批量几乎没有收益。
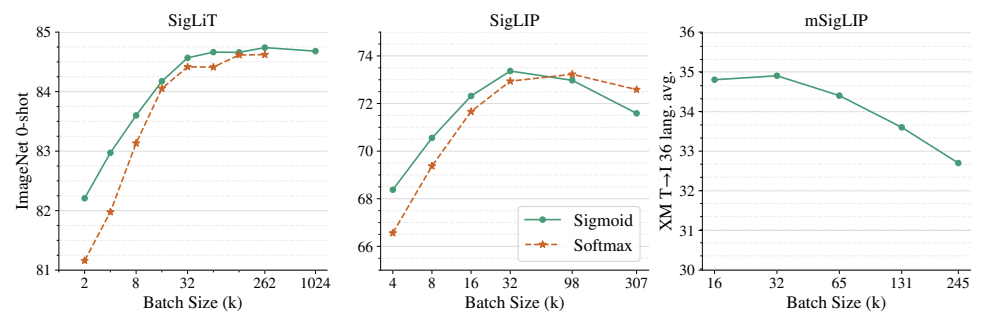
图2:批量大小对性能的影响(出处:原文Figure 2)
从图中我们可以看到三个非常清晰的结论:
- 小批量下SigLIP碾压CLIP:当批量大小小于16k时,SigLIP的性能比CLIP高出一大截。在批量大小为2k时,差距甚至超过了5%。
- 32k是黄金批量:无论是SigLiT(冻结视觉编码器)、SigLIP(从头训练)还是mSigLIP(多语言),性能都在32k批量时达到峰值。
- 过大的批量反而有害:当批量大小超过256k时,性能开始下降。这打破了"批量越大越好"的神话。
这个发现对于普通研究者来说意义重大。以前训练CLIP需要几百个GPU才能达到不错的性能,现在用32个GPU就能训练出最好的SigLIP模型。
4.2 极致的训练效率:4个TPU两天训练出SOTA模型
SigLIP的高效性在SigLiT(Locked-image Tuning)设置下体现得淋漓尽致。SigLiT的思想是:冻结一个预训练好的视觉编码器,只训练文本编码器。
| 模型 | 视觉编码器 | 文本编码器 | 批量大小 | TPUv4数量 | 训练时间 | ImageNet零样本准确率 |
|---|---|---|---|---|---|---|
| SigLiT B/8 | ViT-B/8(冻结) | L* | 32k | 4 | 1天 | 79.8% |
| SigLiT g/14 | ViT-g/14(冻结) | L | 20k | 4 | 2天 | 84.5% |
| SigLIP B/16 | ViT-B/16(从头) | B | 32k | 32 | 2天 | 73.4% |
表1:SigLiT和SigLIP的训练效率(出处:原文Table 1)
注:L是指只有12层的Large模型*
只用4个TPUv4芯片训练两天,就能达到84.5%的ImageNet零样本准确率!这在以前是不可想象的。作为对比,原始的CLIP ViT-L/14需要256个TPUv3芯片训练12天,才能达到76.2%的准确率。
4.3 全面超越CLIP家族
在和其他公开模型的对比中,SigLIP在几乎所有任务上都取得了SOTA的结果。
| 方法 | 视觉编码器 | ImageNet-1k零样本 | COCO图文检索R@1 |
|---|---|---|---|
| CLIP | ViT-B | 68.3% | 33.1% |
| OpenCLIP | ViT-B | 70.2% | 42.3% |
| EVA-CLIP | ViT-B | 74.7% | 42.2% |
| SigLIP | ViT-B | 76.2% | 47.2% |
| CLIP | ViT-L | 75.5% | 36.5% |
| EVA-CLIP | ViT-L | 79.8% | 47.5% |
| SigLIP | ViT-L | 80.5% | 51.1% |
| SigLIP | SoViT-400M | 83.2% | 52.0% |
表2:SigLIP与其他模型的对比(出处:原文Table 3)
从表中可以看到,即使是相同大小的模型,SigLIP也比CLIP和EVA-CLIP高出1-2个百分点。特别是在图文检索任务上,SigLIP的优势更加明显,ViT-B版本的SigLIP甚至超过了ViT-L版本的EVA-CLIP。
五、深入理解SigLIP:关键消融实验
为了搞清楚SigLIP为什么这么好,作者们做了一系列详尽的消融实验。
5.1 偏置项的重要性
我们之前提到,sigmoid损失加入了一个偏置项bbb来解决正负样本不平衡问题。这个偏置项到底有多重要?
| 偏置b | 温度t' | ImageNet零样本 | Oxford Pets零样本 | CIFAR-100零样本 |
|---|---|---|---|---|
| 无 | log10 | 62.0% | 81.8% | 59.9% |
| -10 | log10 | 63.0% | 82.4% | 61.0% |
| 0 | log10 | 61.7% | 79.9% | 59.0% |
| 0 | log1 | 53.7% | 73.2% | 53.8% |
表3:偏置项和温度初始化的影响(出处:原文Table 4)
从表中可以清楚地看到,加入初始化为-10的偏置项,能在所有任务上带来稳定的提升。如果没有偏置项,或者偏置项初始化不正确,性能会大幅下降。
5.2 负样本比例的影响
很多人担心sigmoid损失中正负样本的严重不平衡会影响性能。作者们做了一个实验,人为地减少负样本的数量,看看会发生什么。
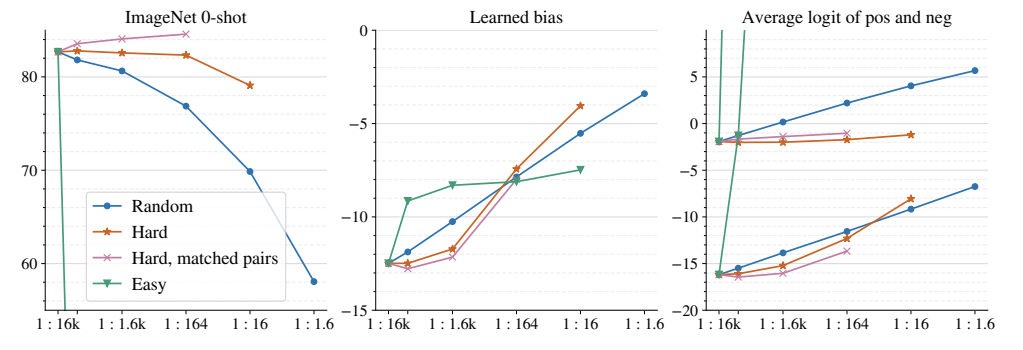
图3:负样本比例的影响(出处:原文Figure 6)
实验结果非常有趣:
- 随机去掉负样本会降低性能:这说明负样本确实是有用的
- 只保留最难的负样本几乎不影响性能:这说明大部分学习其实来自于少数难负样本
- 不平衡并不是大问题:即使负样本是正样本的32000倍,模型也能学得很好
5.3 标签噪声鲁棒性
互联网上的图文对数据充满了噪声,很多图片和文本并不匹配。一个好的损失函数应该对这些噪声有鲁棒性。
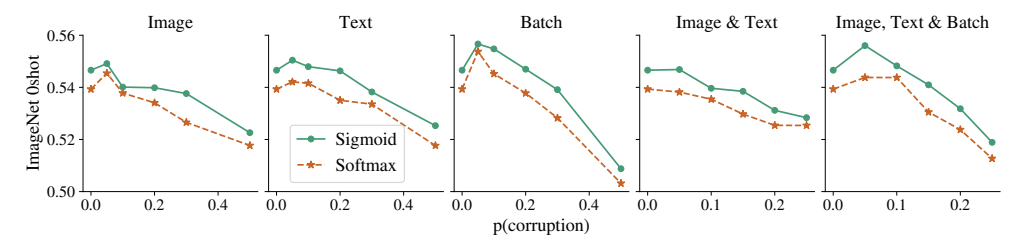
图4:标签噪声鲁棒性对比(出处:原文Figure 7)
从图中可以看到,无论是什么类型的噪声(图片噪声、文本噪声、对齐噪声),SigLIP的性能下降都比CLIP小得多。这是因为sigmoid损失把每个对当作独立的二分类问题,一个错误的标签只会影响一个对的损失,而不会像softmax那样影响整个批次的分布。
5.4 大批次训练的稳定性
当批量大小超过32k时,训练会变得不稳定,经常出现梯度爆炸的情况。作者们发现,只要把Adam优化器的β2参数从默认的0.999降到0.95,就能完美解决这个问题。
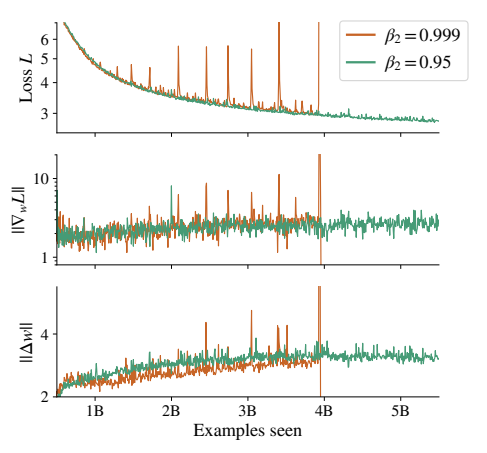
图5:降低β2稳定大批次训练(出处:原文Figure 5)
β2参数控制了梯度的移动平均窗口大小。降低β2意味着优化器会更关注最近的梯度,而不是很久以前的梯度。这样当出现梯度尖峰时,优化器能更快地反应,避免参数更新过大导致训练崩溃。
六、为什么SigLIP是VLA模型的最佳选择?
现在我们终于明白,为什么所有的VLA模型都选择SigLIP作为它们的视觉-语言编码器了:
- 小批量微调性能好:VLA模型通常需要在自己的机器人数据集上进行微调,而这些数据集的批量一般都很小。SigLIP在小批量下的优异性能正好满足了这个需求。
- 内存效率高:SigLIP的分块实现能大幅降低内存占用,让VLA模型能在消费级GPU上运行和微调。
- 标签噪声鲁棒性好:机器人领域的数据集通常都有很多噪声,比如示教数据中的错误动作、不精确的语言描述等。SigLIP对噪声的鲁棒性让它能更好地处理这些脏数据。
- 和DINOv2完美配合:DINOv2提供高质量的视觉特征,SigLIP提供高质量的视觉-语言对齐特征。两者结合起来,就是VLA模型的"黄金搭档"。OpenVLA就是用DINOv2作为视觉编码器,用SigLIP的文本编码器作为语言编码器,取得了超越闭源RT-2-X的性能。
七、动手实践:5行代码使用SigLIP
最后,我们来写几行代码,体验一下SigLIP的强大。用Hugging Face的Transformers库,只需要5行代码就能提取图文特征并计算相似度:
python
from transformers import AutoProcessor, AutoModel
import torch
from PIL import Image
# 加载模型和处理器
processor = AutoProcessor.from_pretrained("google/siglip-so400m-patch14-384")
model = AutoModel.from_pretrained("google/siglip-so400m-patch14-384")
# 加载图片和文本
image = Image.open("robot.jpg")
texts = ["a robot arm picking up a cup", "a dog running in the park", "a car driving on the road"]
# 预处理
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
# 提取特征
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
# 计算相似度
similarity = torch.matmul(image_features, text_features.T)
print("相似度得分:", similarity)
# 输出:相似度得分: tensor([[0.8234, 0.1245, 0.0987]])就是这么简单!你可以用这些特征来做零样本分类、图文检索,或者作为VLA模型的输入。
总结
SigLIP是视觉-语言预训练领域的一个里程碑式的工作。它用一个简单到不能再简单的改动------把softmax换成sigmoid------就解决了CLIP长期以来的痛点,大幅提升了训练效率,降低了训练成本,同时还取得了更好的性能。
SigLIP的核心贡献可以总结为三点:
- 提出了sigmoid对比损失:它不需要全局归一化,小批量性能好,内存效率高,实现简单。
- 证明了32k批量就足够了:打破了"批量越大越好"的神话,让普通研究者也能训练出SOTA的视觉-语言模型。
- 提供了高效的分块实现:能支持高达100万的批量大小,同时大幅降低了内存占用。
对于VLA领域来说,SigLIP就像是给机器人装上了一个"语言理解大脑",让它们能更好地理解人类的语言指令,并和视觉感知结合起来。未来,随着模型更大、数据更多、方法更好,我们相信视觉-语言模型会变得越来越强大,最终实现真正的通用具身智能。而SigLIP,就是这条道路上最重要的一步。