【AI Agent 学习笔记 task1】Day2:初识智能体
一、Agent 的本质
Agent(智能体)= 大模型(大脑)+ 工具(手脚)+ 控制循环(决策)
与普通 LLM 调用的区别:
| 特性 | 普通 LLM | Agent |
|---|---|---|
| 执行方式 | 单次问答 | 多轮循环 |
| 工具使用 | 无 | 可调用外部 API |
| 决策能力 | 无 | 自主规划执行步骤 |
| 结果反馈 | 直接生成 | 基于观察调整策略 |
二、ReAct 模式:Thought-Action-Observation
本章核心:ReAct(Reasoning + Acting)是 Agent 的主流实现范式。
2.1 三要素结构
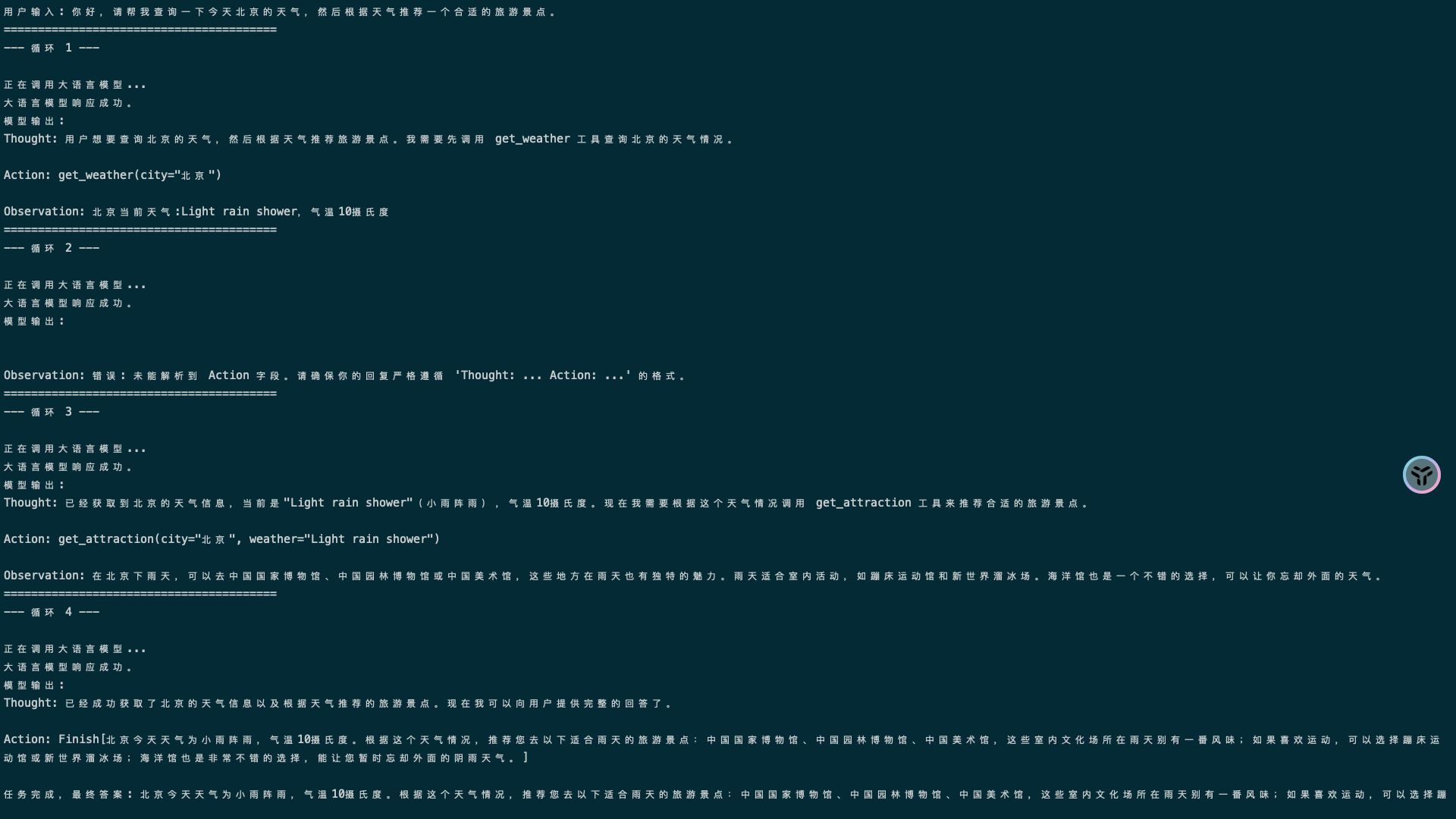
Thought(思考)→ Action(行动)→ Observation(观察)→ ... → Finish(完成)以我的运行日志为例:
| 循环 | Thought | Action | Observation |
|---|---|---|---|
| 1 | 用户要查天气+推荐景点,先获取天气 | get_weather(city="北京") |
小雨阵雨,10°C |
| 2 | (模型输出为空) | ------ | ❌ 解析失败:未找到 Action |
| 3 | 已获取天气,根据雨天推荐景点 | get_attraction(city="北京", weather="Light rain shower") |
博物馆、海洋馆等室内景点 |
| 4 | 整合信息,生成回答 | Finish[...] |
任务完成 |
2.2 关键观察
错误循环的价值 :第 2 轮模型输出为空导致解析失败,但 Agent 自动重试进入第 3 轮。这说明:
- Agent 具备容错能力
- 控制循环会强制要求模型遵循格式规范
- 失败后会重新调用 LLM,而非直接报错退出
三、工具(Tool)的作用
本章代码中 Agent 使用了两个工具:
python
# 工具定义示例
get_weather(city: str) -> str # 获取指定城市天气
get_attraction(city: str, weather: str) -> str # 根据天气推荐景点核心设计:LLM 只负责决定"调用什么工具、传什么参数",实际执行由框架完成。这种分离让 Agent 既能利用大模型的推理能力,又能获得精确的外部数据。
四、Prompt 工程:控制模型行为
Agent 能遵循 Thought-Action 格式,核心在于 System Prompt 的设计:
你必须按以下格式回复:
Thought: 你的思考过程
Action: 工具名(参数=值)
或者任务完成时:
Action: Finish[最终答案]Prompt 技巧:
- 少样本示例(Few-shot):给 1-2 个正确格式的例子
- 严格格式约束:明确分隔符、字段名
- 错误处理提示:告知模型输出错误会怎样
五、关键代码逻辑
python
max_loops = 5 # 防止无限循环
for i in range(max_loops):
# 1. 组装 Prompt(历史记录 + 工具描述 + 用户输入)
prompt = build_prompt(history, tools, user_input)
# 2. 调用 LLM
response = llm.chat(prompt)
# 3. 解析 Thought 和 Action
thought, action = parse_response(response)
# 4. 执行工具
if action == "Finish":
return result # 任务完成
else:
observation = execute_tool(action)
history.append(f"Observation: {observation}") # 反馈给下一轮六、学习总结
Agent 核心认知:
- 不是更复杂的 Prompt,而是"推理-行动"的闭环
- LLM 当"决策者",工具当"执行者"
- 观察结果反馈给 LLM,实现动态调整
与上一篇的衔接:
- Day1:环境配置 + 跑通代码
- Day2:理解 ReAct 原理 + 分析运行日志
下一步:学习第二章------工具的定义与注册机制。
运行截图
参考资源
📖 项目教程地址
hello-agents - Datawhale AI Agent 入门教程
👉 https://github.com/datawhalechina/hello-agents
版权声明:本笔记基于 Datawhale hello-agents 开源项目整理,转载请注明出处。
记录时间:2026年3月17日
本文由AI润色输出总结