SELF-SUPERVISED POCKET PRETRAINING VIA PROTEIN FRAGMENT-SURROUNDINGS ALIGNMENT
通过蛋白质片段-环境比对实现自我监督口袋预训练
这个文章提出一个方法叫ProFSA 主要是用来解决 药物研发中,蛋白质和小分子结合数据太少的问题。
主要通过从蛋白质切下一块片段当做假药物,构造了500万组假药物-蛋白质口袋的数据,训练出一个ai模型,去判断口袋能不能放得下药物,或者能不能结合的牢靠。 就类似蛋白质口袋是 "钥匙孔",小分子是 "钥匙",只有形状、材质匹配的钥匙,才能插进钥匙孔并发挥作用。
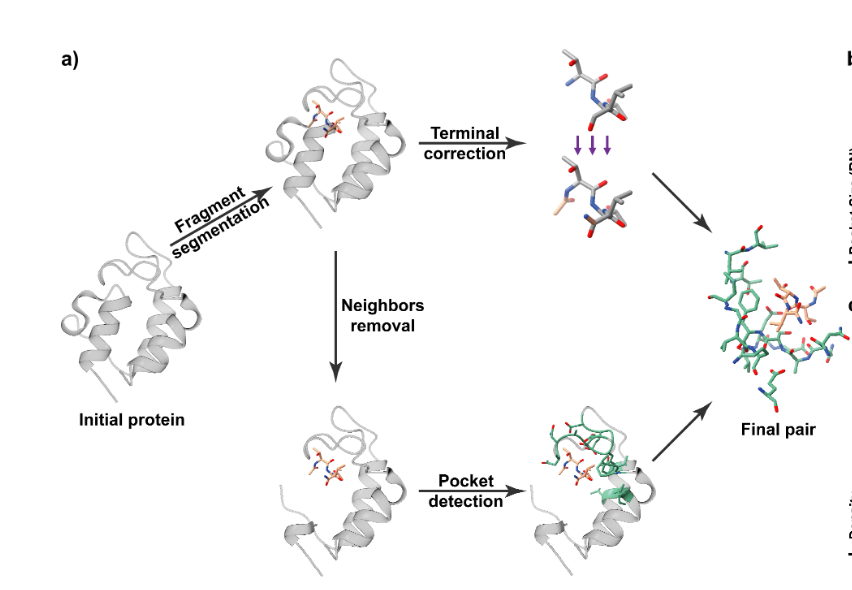
具体细节:
步骤1:从蛋白质上切1-8个氨基酸组成的片段,把这个氨基酸片段当做假小分子(因为有相似的化学结构,同时能与口袋结合)
步骤2:每个假小分子周围,一定会存在凹陷区域,把他叫做假口袋,以片段为中心,找周围 6 埃(原子尺度的距离单位)内的蛋白质残基,这些残基构成的凹陷就是 "假口袋";同时要做一定的修正工。给片段的两端加化学基团,让它更像真实小分子。
步骤3:造出500多万种组合,并且保证与真实数据中的口袋大小结合程度一致。
步骤4:让模型学习正确的配对形式和不正确的配对形式,从而让他找到规律扩展到真实的情况中。
借鉴到酶优化中?
能否在目标酶的结构中也切,然后学习。
或者是在编码的时候考虑3D结构特征,在对某一个节点进行突变的时候,同时考虑到突变以后跟口袋是否还匹配?
Deep contrastive learning enables genome-wide virtual screening
深度对比学习支持全基因组虚拟筛选
核心是解决 "全基因组规模虚拟筛选太慢" 的痛点 ------ 提出基于深度对比学习的框架,将蛋白质口袋和小分子编码到同一特征空间,实现 "搜索引擎式" 快速匹配。
数据准备:从ProFSA中的伪配对+一点真实的配对
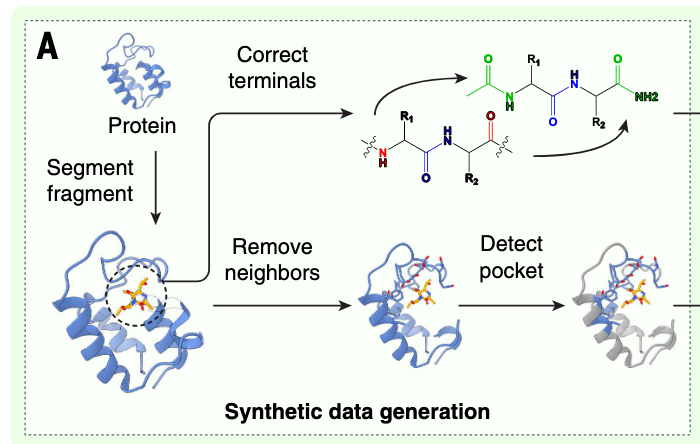
模型训练:预训练选择冻结分子编码器,训练口袋编码器(这里用到对比学习),微调时同时更新分子和口袋编码器对比损失。
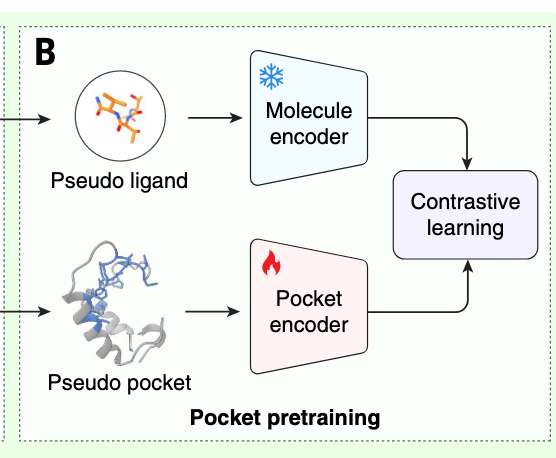
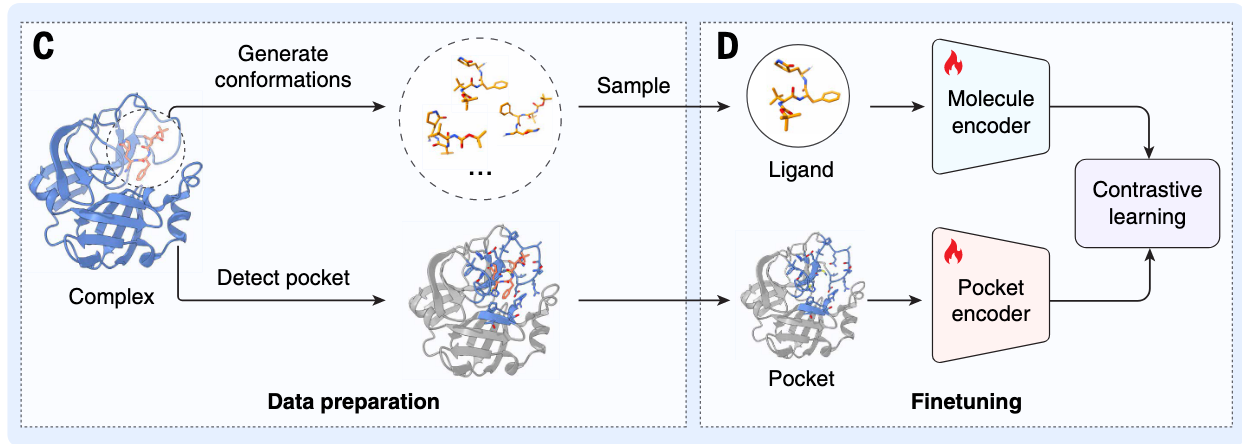
虚拟筛选:首先将口袋和化合物转成特征向量,去计算余弦相似度,最后用湿实验验证。
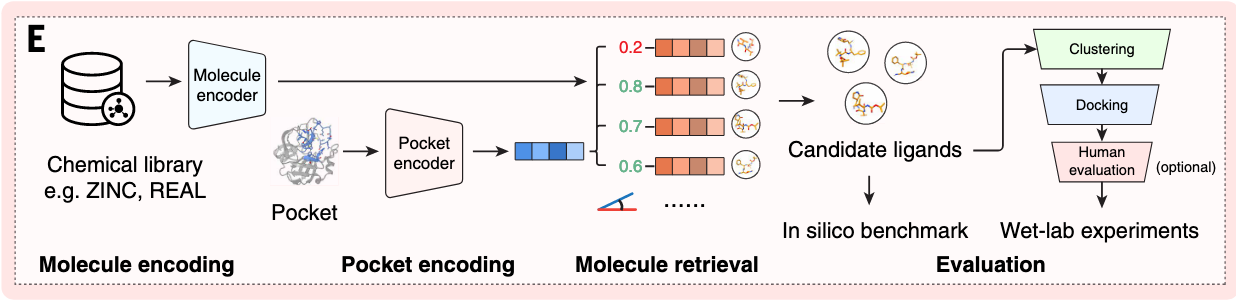
主要点:他把筛选变成检索大大加快速度,先把所有化合物提前编码,筛选的时候只需要目标口袋的信息,再用相似度排序。
与之前ProFSA论文相似点:都解决 "蛋白 - 小分子结合数据稀缺" 的问题(ProFSA 缺口袋表征数据,DrugCLIP 缺虚拟筛选数据)
元学习器
酶分种类做学习器 再汇总做泛化能力
进行一个不同的分类
前3位EC号进行分类 坝是蛋白质序列,结果是酶和活性的值
主动学习+加口袋特征,酶催化底物+产物信息