课程结构总览
入门阶段 │ 第 1 章:Spark 是什么 → 第 2 章:环境搭建 → 第 3 章:核心概念 RDD
│
基础阶段 │ 第 4 章:整体架构 → 第 5 章:Spark SQL → 第 6 章:DAG 调度 → 第 7 章:Shuffle
│
进阶阶段 │ 第 8 章:Structured Streaming → 第 9 章:性能调优 → 第 10 章:MLlib
│
精通阶段 │ 第 11 章:Delta Lake → 第 12 章:生产部署 → 第 13 章:Real-Time Mode🟢 入门阶段
第 1 章:Spark 是什么,为什么需要它
1.1 大数据处理的历史困境
在 Spark 出现之前,Hadoop MapReduce 是大数据处理的主流方案,但它有一个致命弱点:每次计算都要把中间结果写到 HDFS 磁盘,导致迭代计算(如机器学习)极其缓慢。
Spark 的核心突破是:把中间数据放在内存里,避免反复的磁盘 I/O。
1.2 Spark 是什么
Apache Spark 是一个统一的、分布式的大数据计算引擎,支持:
- 批处理(Batch Processing)
- 交互式查询(Spark SQL)
- 流处理(Structured Streaming)
- 机器学习(MLlib)
- 图计算(GraphX)
1.3 Spark 生态全景图
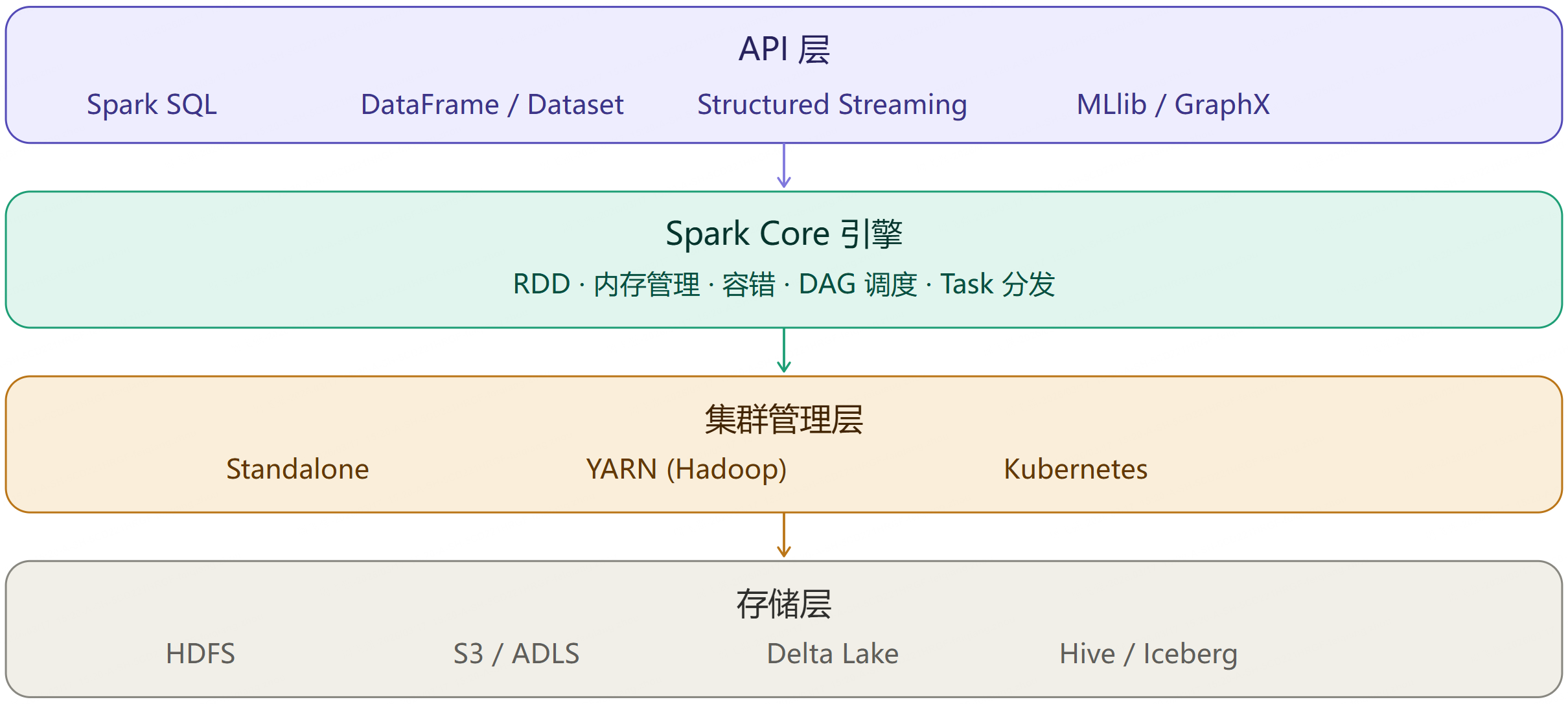
1.4 Spark vs Hadoop MapReduce 对比
| 对比项 | Hadoop MapReduce | Apache Spark |
|---|---|---|
| 计算模型 | 磁盘迭代 | 内存计算 |
| 速度 | 慢(大量磁盘 I/O) | 快 10~100 倍 |
| 编程模型 | Map + Reduce(固定) | 丰富的算子 API |
| 流处理 | 不支持 | Structured Streaming |
| 机器学习 | Mahout(弱) | MLlib(强) |
| 容错方式 | 数据复制 | 血统(Lineage) |
第 2 章:环境搭建
2.1 安装方式选择
对于初学者,推荐按以下顺序尝试:
- 本地模式(Local Mode) --- 最简单,单机运行,适合学习和调试
- Docker --- 一键启动,环境隔离
- Databricks Community Edition --- 免费云端环境,无需安装
2.2 本地模式安装步骤
bash
# 1. 安装 Java 11+
java -version
# 2. 下载 Spark(以 3.5.x 为例)
wget https://downloads.apache.org/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz
tar -xzf spark-3.5.0-bin-hadoop3.tgz
# 3. 配置环境变量
export SPARK_HOME=/path/to/spark-3.5.0-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin
# 4. 启动 PySpark 交互式 Shell
pyspark --master local[*]2.3 第一个 Spark 程序
python
from pyspark.sql import SparkSession
# 创建 SparkSession(入口)
spark = SparkSession.builder \
.appName("HelloSpark") \
.master("local[*]") \
.getOrCreate()
# 读取数据
df = spark.read.csv("data.csv", header=True, inferSchema=True)
# 转换与查询
result = df.filter(df["age"] > 18).groupBy("city").count()
# 展示结果
result.show()
# 关闭
spark.stop()2.4 Spark 模式对比

第 3 章:核心概念 --- RDD、DataFrame、Dataset
3.1 三个核心数据抽象
Spark 有三种数据表示方式,理解它们的关系是入门的关键:

3.2 RDD 的两类算子
RDD 操作分为两类,这是理解 Spark 懒执行的关键:
- Transformation(转换) :
map、filter、groupByKey、join等,返回新 RDD,不立即执行,只记录操作 - Action(动作) :
collect、count、save、show等,触发实际计算
python
# Transformation(懒执行,不触发计算)
rdd2 = rdd.filter(lambda x: x > 0) # 记录操作
rdd3 = rdd2.map(lambda x: x * 2) # 继续记录
# Action(触发计算,DAG 开始执行)
result = rdd3.collect() # 此刻才真正运行3.3 RDD 的两种依赖关系
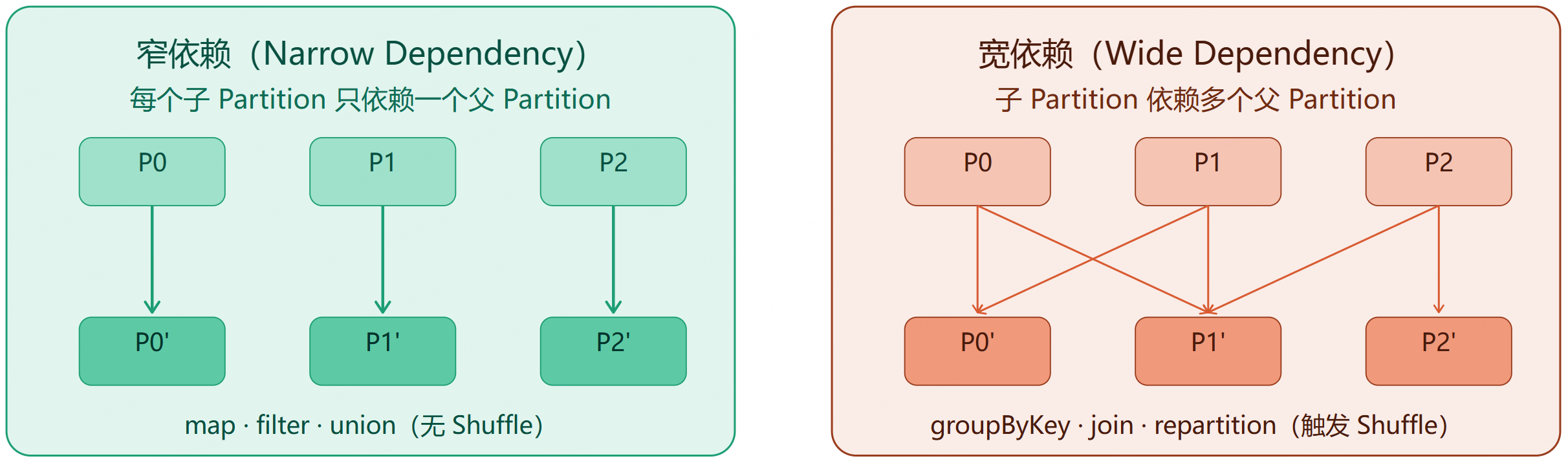
🟣 基础阶段
第 4 章:Spark 整体架构
4.1 核心角色
Spark 集群由以下角色组成:
- Driver:运行用户代码的主程序,负责创建 SparkContext、构建 DAG、提交 Job
- Cluster Manager:负责整个集群的资源分配(YARN/K8s/Standalone)
- Worker:集群中的工作节点,上面运行 Executor 进程
- Executor:Worker 节点上的 JVM 进程,负责执行 Task,存储 RDD 缓存
- Task:Executor 内的线程,处理一个 Partition 的数据
4.2 Spark 集群架构图
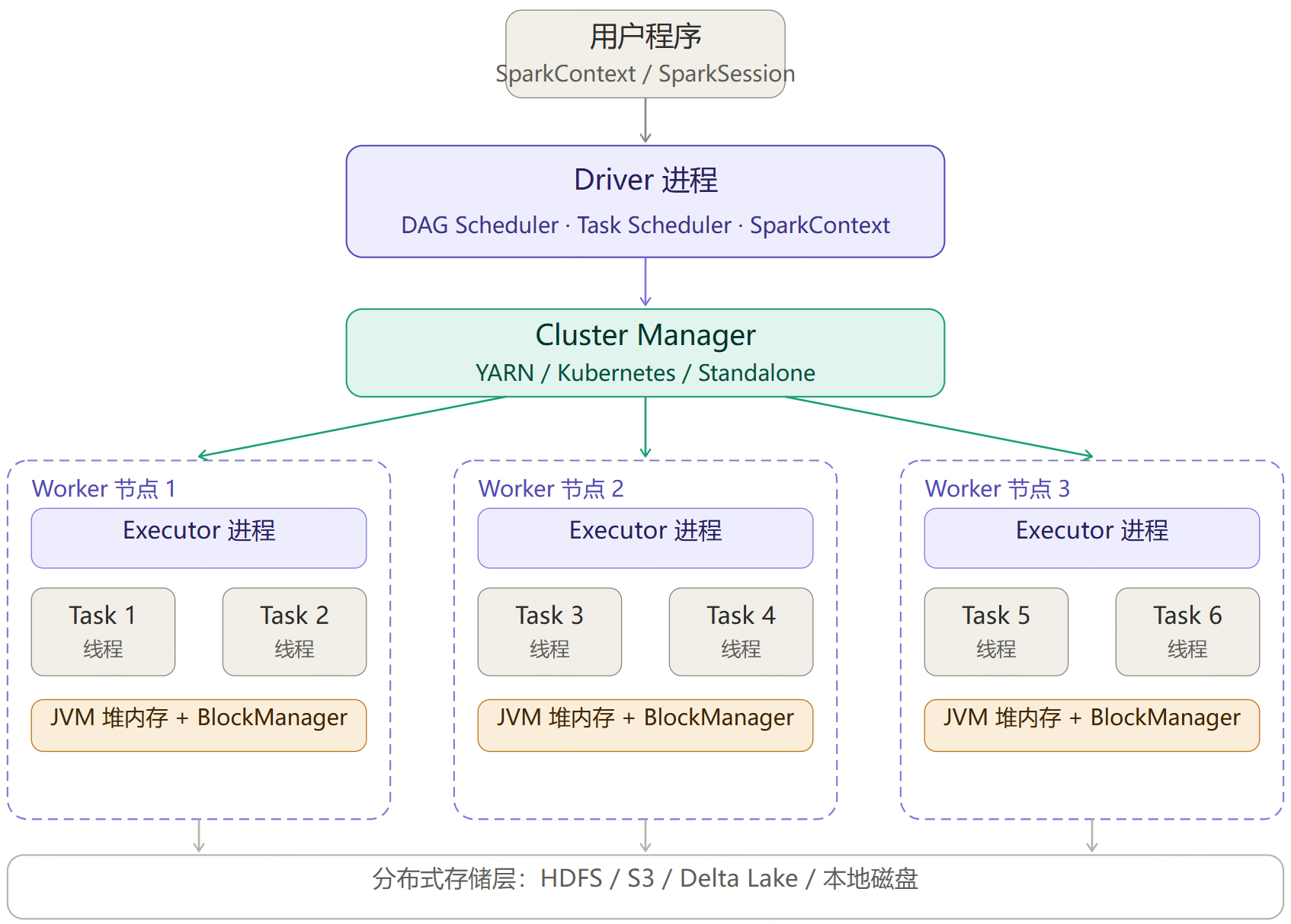
第 5 章:Spark SQL 与 DataFrame 编程
5.1 DataFrame 常用操作
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, count, when
spark = SparkSession.builder.appName("SQL Demo").getOrCreate()
# 读取数据
df = spark.read.parquet("s3://bucket/sales/")
# 选择列
df.select("name", "amount", "city")
# 过滤
df.filter(col("amount") > 1000)
# 分组聚合
df.groupBy("city").agg(
avg("amount").alias("avg_amount"),
count("*").alias("total_orders")
)
# 排序
df.orderBy(col("avg_amount").desc())
# 使用 SQL
df.createOrReplaceTempView("sales")
spark.sql("""
SELECT city, AVG(amount) as avg_amount
FROM sales
WHERE amount > 1000
GROUP BY city
ORDER BY avg_amount DESC
""").show()5.2 Catalyst 查询优化器
Spark SQL 的核心优化器 Catalyst 将 SQL / DataFrame 操作转换为高效的物理执行计划:

第 6 章:DAG 与 Job / Stage / Task 调度
6.1 执行单元层级
在 Spark 中,一次程序运行包含三个层级的执行单元:
- Job :一次 Action 触发一个 Job(如
df.count()) - Stage:Job 按宽依赖(Shuffle)边界切分为多个 Stage,Stage 内部是流水线执行
- Task:一个 Stage 内,每个 Partition 对应一个 Task,Task 是最小执行单元
6.2 DAG 调度流程
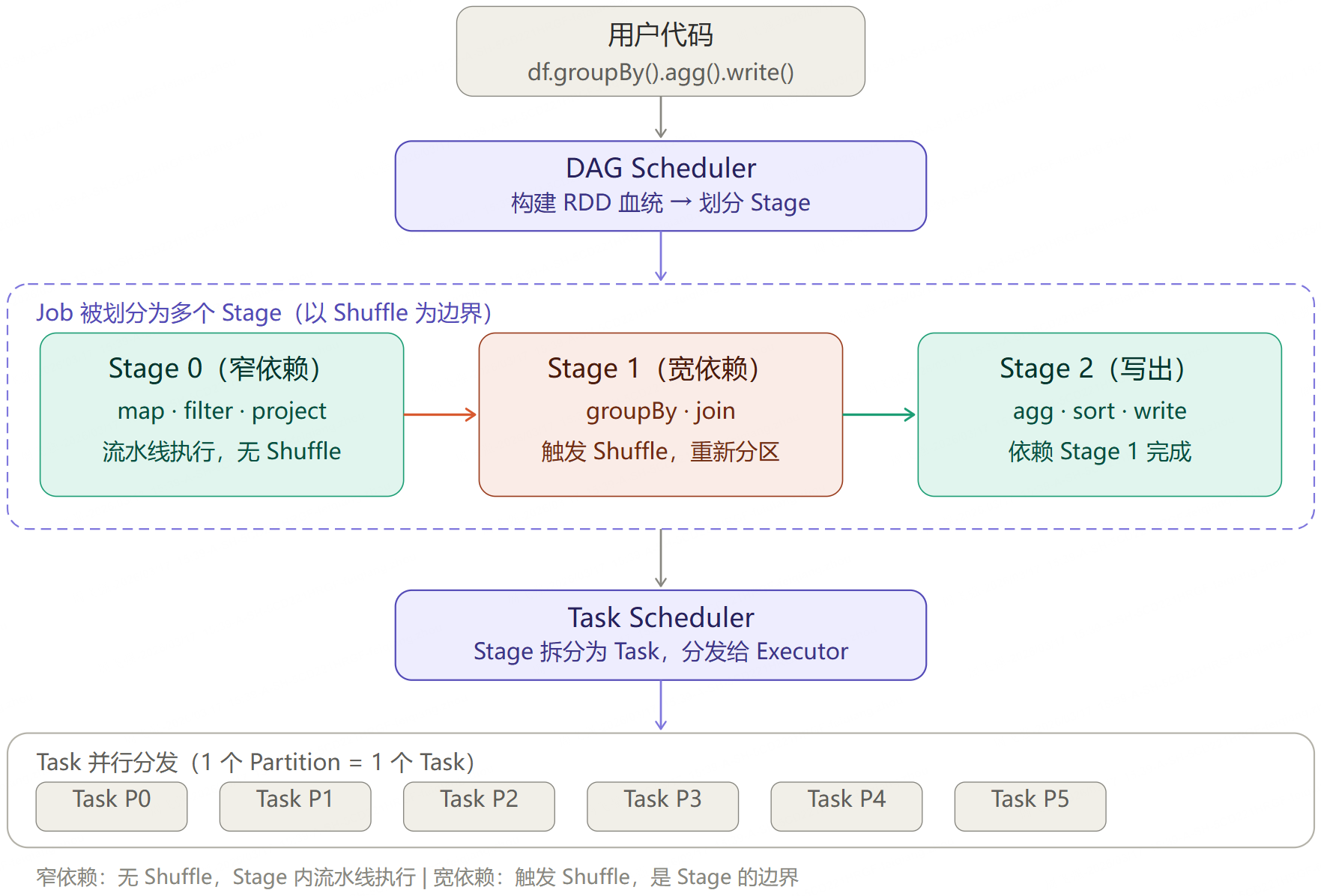
第 7 章:Shuffle 机制详解
7.1 什么是 Shuffle
Shuffle 是 Spark 中最昂贵的操作。当数据需要跨节点重新分区(如 groupBy、join),就必须通过网络传输数据,这个过程称为 Shuffle。
7.2 Shuffle 写出与读取流程
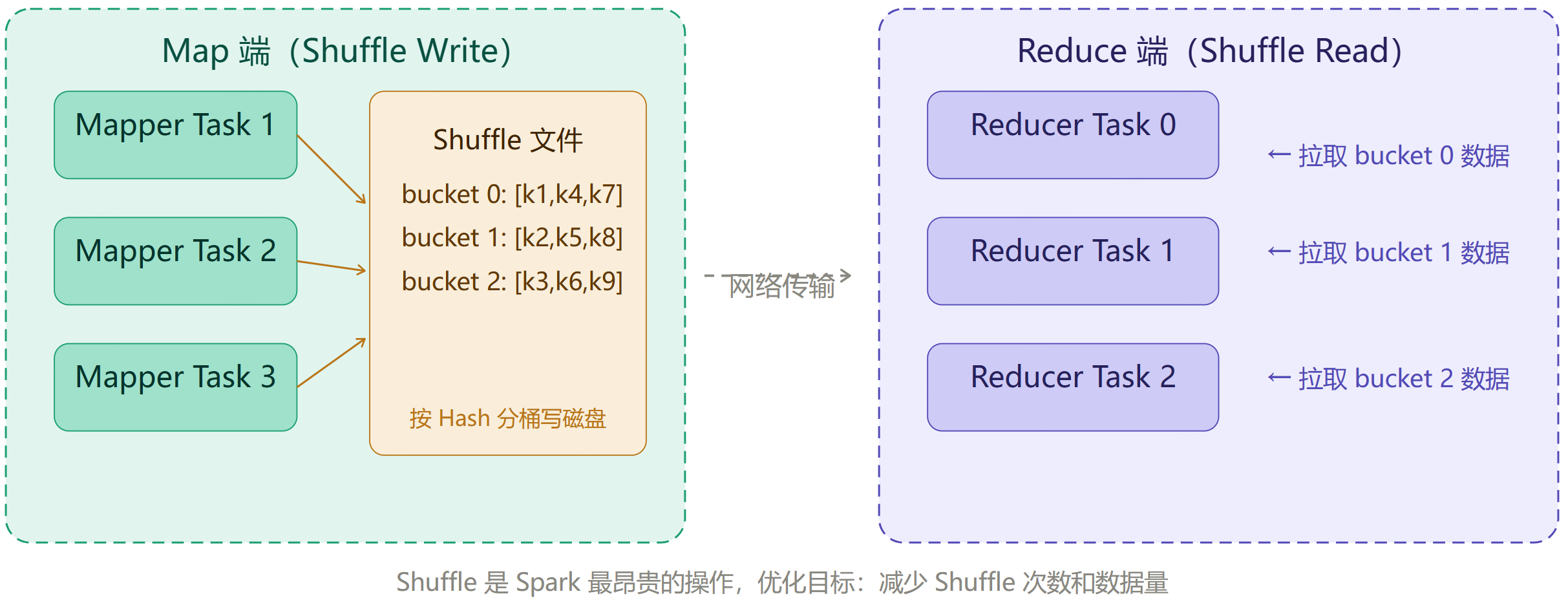
7.3 减少 Shuffle 的常用技巧
- 使用
reduceByKey代替groupByKey(前者在 Map 端做预聚合) - 开启 AQE(Adaptive Query Execution)自动合并小 Partition
- 使用 Broadcast Join 避免大表 Shuffle
🟠 进阶阶段
第 8 章:Structured Streaming 流处理
8.1 核心思想:将流视为无界表
Structured Streaming 的革命性思想:把实时数据流看做一张不断追加行的无界表,用和批处理完全相同的 SQL / DataFrame API 来写流处理代码。
8.2 执行模型全览
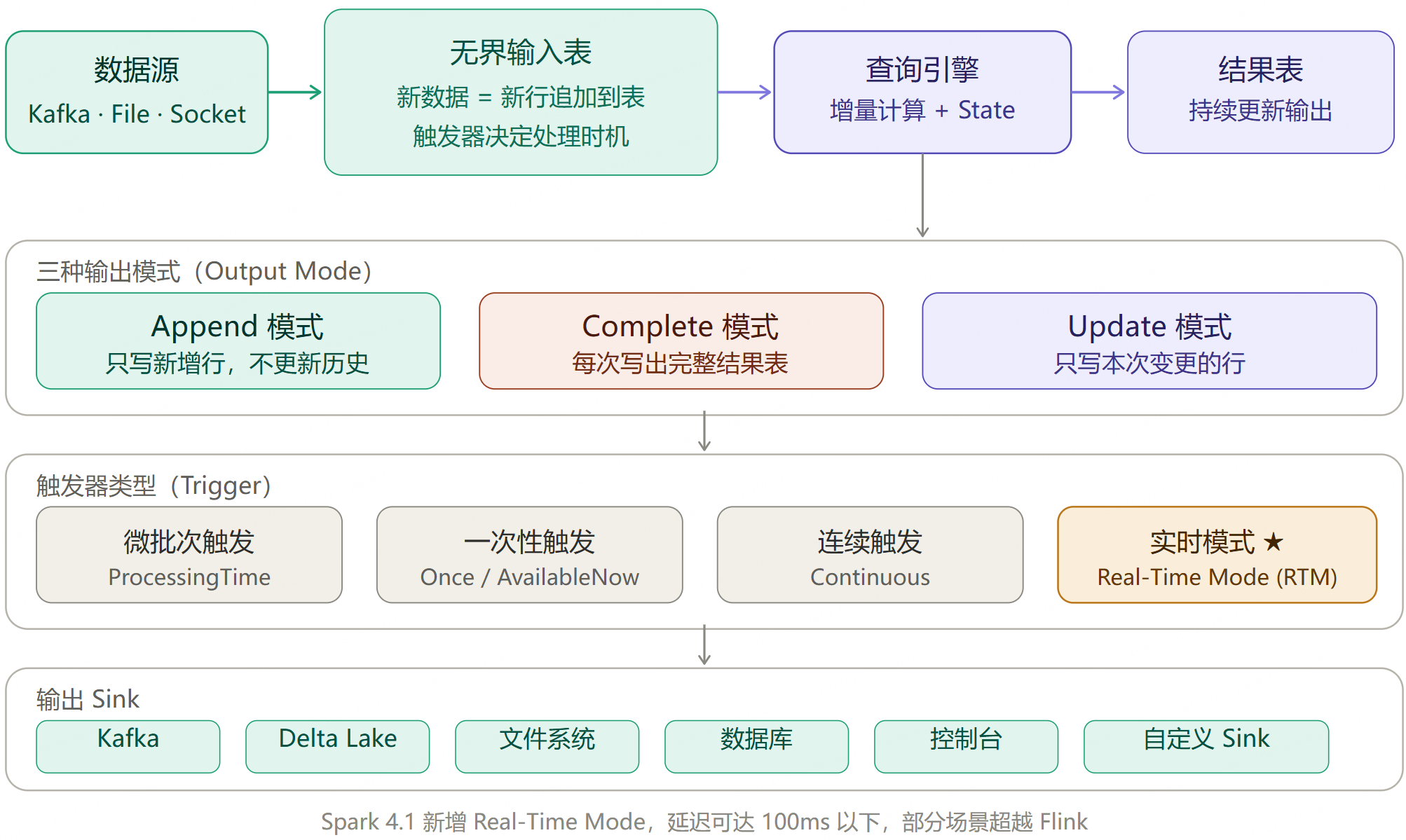
8.3 一个完整的流处理示例
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import window, count
spark = SparkSession.builder.appName("StreamDemo").getOrCreate()
# 读取 Kafka 流
df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "orders") \
.load()
# 解析 JSON 数据
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StringType, DoubleType
schema = StructType().add("city", StringType()).add("amount", DoubleType())
orders = df.select(from_json(col("value").cast("string"), schema).alias("data")).select("data.*")
# 每 1 分钟统计各城市订单金额
result = orders \
.withWatermark("timestamp", "10 minutes") \
.groupBy(window("timestamp", "1 minute"), "city") \
.agg(count("*").alias("order_count"))
# 写出到 Kafka(Update 模式)
query = result.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("topic", "order_stats") \
.outputMode("update") \
.start()
query.awaitTermination()第 9 章:性能调优
9.1 性能调优全景图
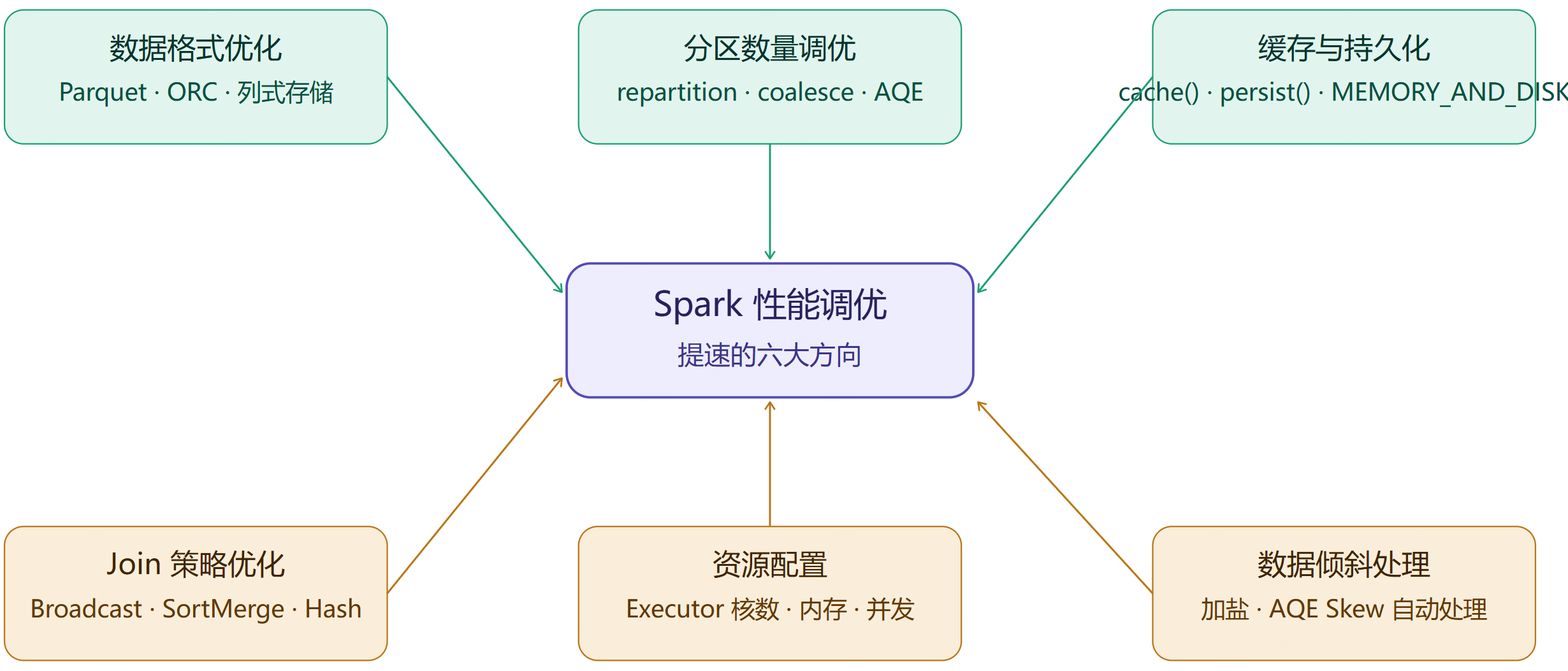
9.2 关键配置参数
python
spark = SparkSession.builder \
.config("spark.executor.memory", "8g") \
.config("spark.executor.cores", "4") \
.config("spark.sql.shuffle.partitions", "200") # 默认 200,按数据量调整
.config("spark.sql.adaptive.enabled", "true") # 开启 AQE
.config("spark.sql.adaptive.skewJoin.enabled", "true") # AQE 自动处理倾斜
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
# Broadcast Join(小表 < 10MB 自动广播)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 10 * 1024 * 1024)
# 手动指定 Broadcast
from pyspark.sql.functions import broadcast
result = large_df.join(broadcast(small_df), "id")第 10 章:MLlib 机器学习
10.1 MLlib Pipeline
Spark MLlib 使用 Pipeline 将数据预处理和模型训练串联:
python
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler, StandardScaler, StringIndexer
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.evaluation import BinaryClassificationEvaluator
# 1. 特征工程
indexer = StringIndexer(inputCol="city", outputCol="city_idx")
assembler = VectorAssembler(inputCols=["age","amount","city_idx"], outputCol="features")
scaler = StandardScaler(inputCol="features", outputCol="scaled_features")
# 2. 模型
rf = RandomForestClassifier(featuresCol="scaled_features", labelCol="label", numTrees=100)
# 3. Pipeline 串联
pipeline = Pipeline(stages=[indexer, assembler, scaler, rf])
# 4. 训练
train_df, test_df = df.randomSplit([0.8, 0.2])
model = pipeline.fit(train_df)
# 5. 预测 & 评估
predictions = model.transform(test_df)
evaluator = BinaryClassificationEvaluator(labelCol="label")
print(f"AUC: {evaluator.evaluate(predictions):.4f}")🟡 精通阶段
第 11 章:Delta Lake 与 Lakehouse 架构
11.1 Delta Lake 解决什么问题
传统数据湖(S3 / HDFS 上的 Parquet 文件)存在三大痛点:数据不一致(写了一半宕机)、无法更新删除(Upsert)、读取慢(大量小文件)。
Delta Lake 在 Parquet 上加了一个事务日志(Transaction Log),解决了以上所有问题。
11.2 Delta Lake 架构图
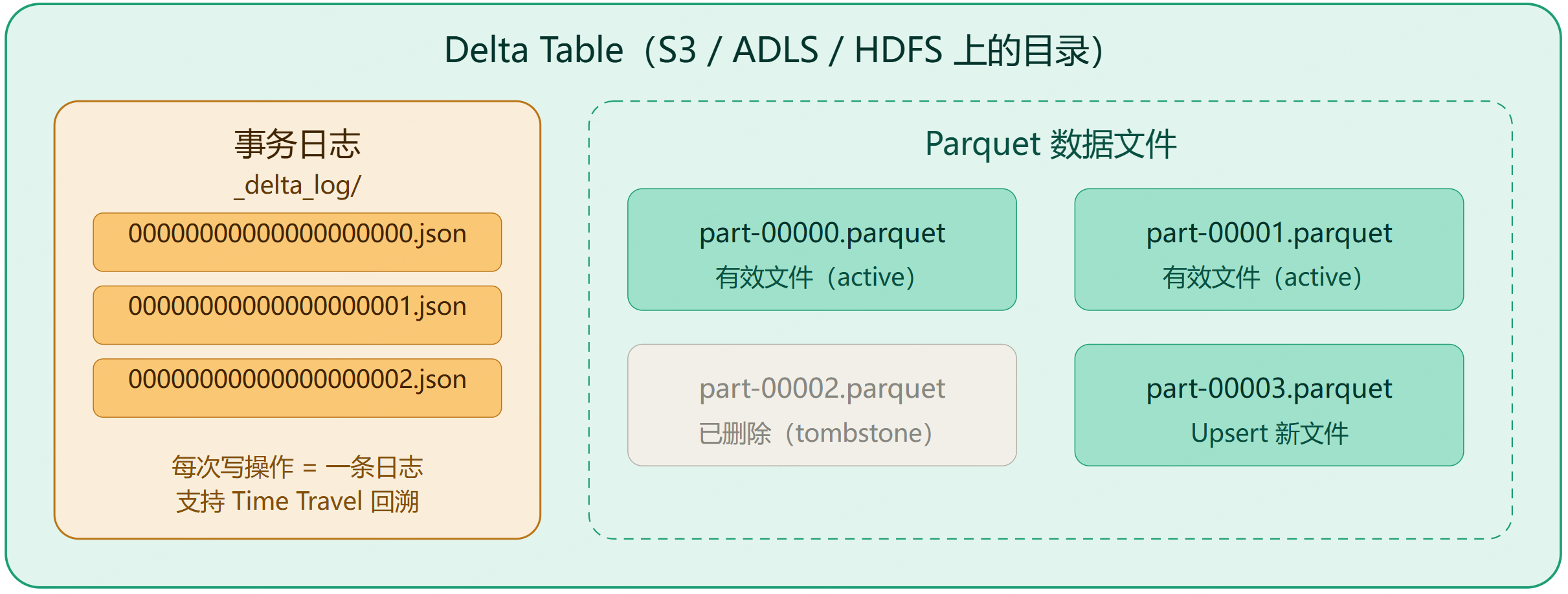
11.3 Delta Lake 核心能力
python
from delta.tables import DeltaTable
# ACID 写入
df.write.format("delta").mode("overwrite").save("/delta/orders")
# Upsert(Merge Into)
delta_table = DeltaTable.forPath(spark, "/delta/orders")
delta_table.alias("target").merge(
updates_df.alias("source"),
"target.order_id = source.order_id"
).whenMatchedUpdateAll() \
.whenNotMatchedInsertAll() \
.execute()
# Time Travel(数据回溯)
df_v0 = spark.read.format("delta").option("versionAsOf", 0).load("/delta/orders")
df_yesterday = spark.read.format("delta").option("timestampAsOf", "2024-01-01").load("/delta/orders")
# Schema Evolution(自动演化)
df.write.format("delta").option("mergeSchema", "true").mode("append").save("/delta/orders")第 12 章:生产部署与运维
12.1 提交作业到集群
bash
# 提交到 YARN 集群
spark-submit \
--master yarn \
--deploy-mode cluster \
--executor-memory 8g \
--executor-cores 4 \
--num-executors 20 \
--conf spark.sql.adaptive.enabled=true \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
my_spark_job.py
# 提交到 Kubernetes
spark-submit \
--master k8s://https://<k8s-master>:6443 \
--deploy-mode cluster \
--conf spark.kubernetes.container.image=spark:3.5.0 \
my_spark_job.py12.2 监控与排障
- Spark UI (默认
http://driver-host:4040):查看 Jobs / Stages / Tasks / SQL 执行计划 - History Server:查看已完成作业的历史日志
- 常见问题排查:OOM → 增加 Executor 内存或减少 Partition 大小;数据倾斜 → 开启 AQE 或加盐;GC 频繁 → 开启堆外内存
12.3 生产架构推荐
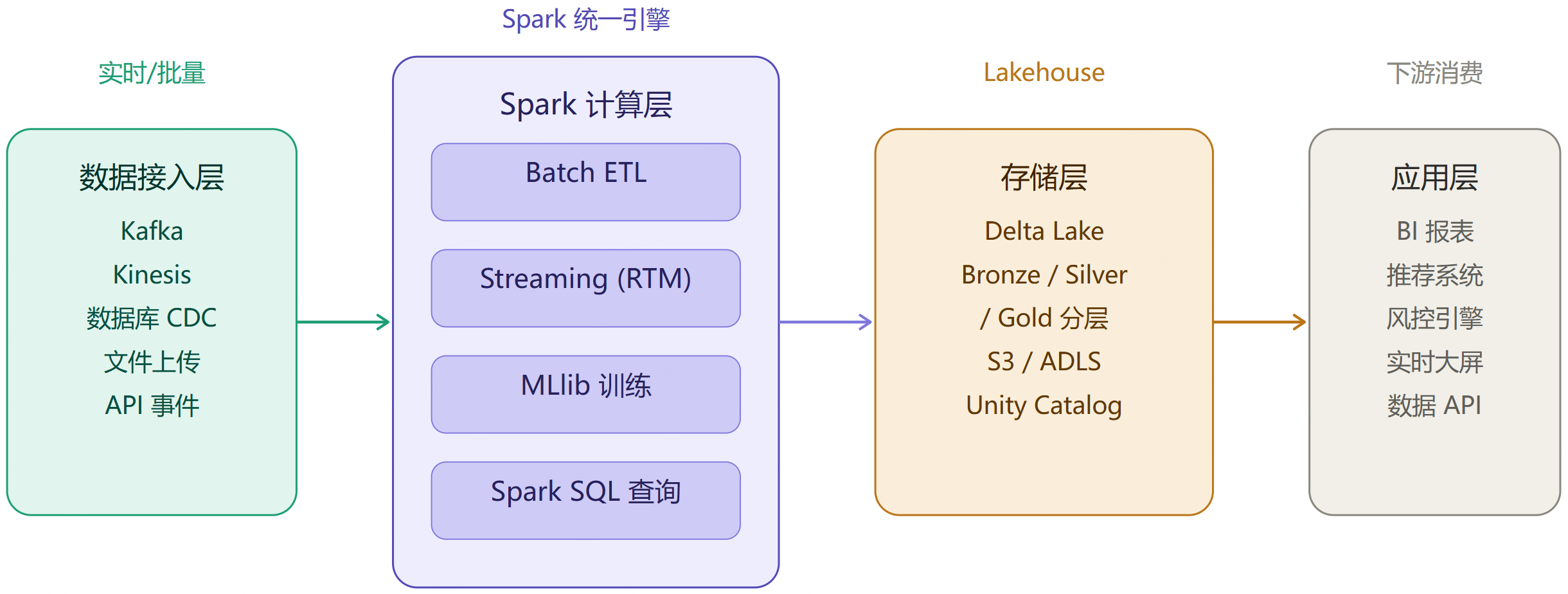
第 13 章:Spark Real-Time Mode --- 毫秒级实时计算
13.1 为什么需要 RTM
Spark 4.1 引入 Real-Time Mode,通过三大技术创新实现毫秒级延迟:
- 长周期 Epoch + 连续数据流(Checkpoint 开销被摊薄)
- Stage 并发执行(Reducer 无需等待 Mapper 全部完成)
- 非阻塞算子(数据流过即处理,无需等待)
13.2 如何开启 RTM
python
# 方式一:通过 Trigger 配置
query = df.writeStream \
.trigger(processingTime="0 seconds") # 或使用 Trigger.Continuous
.format("delta") \
.start()
# 方式二:Databricks 平台开启 RTM
spark.conf.set("spark.databricks.streaming.realtime.enabled", "true")13.3 RTM 适用场景
| 场景 | 延迟要求 | 推荐方案 |
|---|---|---|
| 实时特征工程 | 100ms 级 | Spark RTM |
| 交易欺诈检测 | 100ms 级 | Spark RTM |
| 旅行实时定价 | 100ms 级 | Spark RTM |
| 高频交易风控 | < 10ms | Apache Flink |
| 批量 ETL 管道 | 秒级 | Spark 微批次 |
附录:学习资源推荐
| 资源 | 说明 |
|---|---|
| Apache Spark 官方文档 | 最权威的参考资料 |
| Databricks Learning | 免费在线课程 |
| 《Learning Spark》(第二版) | O'Reilly 出版,官方推荐书籍 |
| 《Spark: The Definitive Guide》 | 深度原理讲解 |
| Databricks Community Edition | 免费云端练习环境 |
本指南基于 Apache Spark 3.5 / 4.1,持续更新中。