一、技术方案核心机制解析
1.1 神经纹理压缩:革命性显存节省与传输效率提升
神经纹理压缩(NTC)技术通过引入AI算法,从根本上改变了纹理数据的处理范式,实现了对传统块截断编码(BC)方法的革命性替代。其核心机制在于将纹理视为一个多维张量进行处理,能够同时压缩多个通道和Mipmaps。这种基于深度学习的压缩方法,通过训练神经网络学习纹理数据的统计特性,有效去除冗余信息,从而在编码阶段实现极高的压缩率。以英伟达的RTX NTC技术为例,它能够将纹理内存占用最高降低96% ,在具体测试中,可将纹理从32.00 MB压缩至1.52 MB,磁盘占用和PCI-E传输开销均得到显著优化。这意味着,在相同的显存容量下,游戏能够支持比当前GPU原生处理能力高出四倍分辨率 的纹理(例如从1024x1024提升至4096x4096),使纹理规模扩大16倍。这一特性使得游戏制作端能够对高分辨率材质进行高效率压缩,显著减小分发文件体积,为存储与网络传输带来巨大便利。尽管该技术深度依赖现代GPU中的张量核心进行加速,但其广泛的硬件兼容性(已验证支持GTX 10系列、AMD RX 6000系列及英特尔Arc A系列显卡)为其在下一代游戏主机平台的部署奠定了坚实基础。
1.2 AI超分辨率重建:轻量化模型实现高效细节还原
在主机端,NTC方案通过轻量化的AI推理模型实时解压并重建纹理细节,以还原接近原生分辨率的视觉质量。其重建机制并非简单解压,而是依赖一个集成在渲染管线中的神经网络解码器。该解码器将压缩后的数据(即神经网络的权重和一个小型特征张量)作为输入,在着色器中直接运行,实时生成未过滤的纹理数据。为了满足游戏渲染对高质量纹理采样的要求,该技术建议与随机纹理过滤(STF)等技术结合使用,以在着色器中实现高质量的纹理过滤输出。在重建质量方面,该技术的峰值信噪比(PSNR)通常在40到50 dB之间 ,表明即使在极高的压缩率下,仍能保持较高的图像保真度,这对于追求视觉沉浸感的游戏主机应用至关重要。为了实现实时性,该技术充分利用硬件加速能力,例如通过协同向量扩展(Cooperative Matrix extensions)为Vulkan和DirectX 12 API提供2-4倍的推理吞吐量提升,从而确保在每秒数十至上百帧的渲染频率下稳定运行。这种"按需解压"的特性------即仅推理渲染特定视角所需的单个纹素------进一步降低了实时渲染的算力开销。
1.3 端到端流程:从制作压缩到实时渲染的协同机制
该技术方案构建了一个从内容制作到终端渲染的完整、协同的端到端流程。在游戏制作端,开发流程始于将PBR材质的多达16个纹理通道(典型为9-10个)输入至NTC编码器,该编码器通过训练好的AI模型将原始高分辨率纹理数据压缩为一个高度优化的NTC纹理集,并生成对应的神经网络解码器权重。经过此过程,纹理的磁盘存储体积得到极大缩减。在分发与加载阶段,显著减小的游戏包体便于存储和网络传输;当游戏运行时,仅需将压缩后的NTC纹理集(而非庞大的原始纹理)加载至主机显存,实现了显存占用的根本性降低。在主机实时渲染环节,关键的数据流与控制逻辑在于:图形管线在需要采样纹理时,调用内置的轻量化神经网络解码器。该解码器读取显存中的压缩数据,实时推理并重建出高细节的纹理值,直接供着色器使用。这种机制形成了一种高效的协同:制作端负责"高质量压缩",主机端负责"智能实时重建",两者通过统一的神经网络模型权重相连接,从而在降低存储、传输和显存负担的同时,致力于还原甚至增强最终的画面表现力。
二、多维性能平衡点实证评估
2.1 压缩率与重建质量的博弈关系
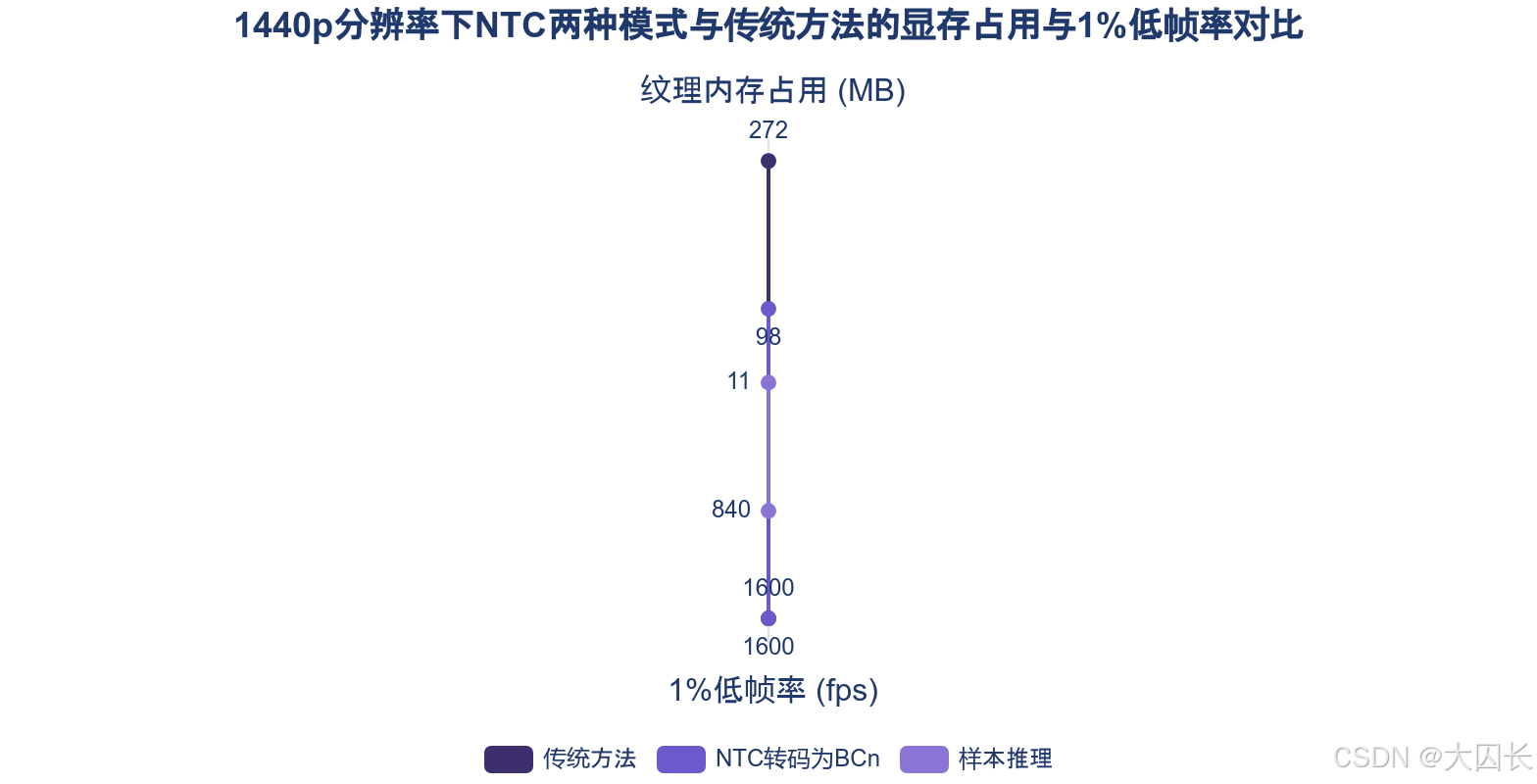
神经纹理压缩(NTC)技术通过AI算法实现了革命性的压缩效率 ,其"样本推理"模式在1440p分辨率下,能将纹理内存从272MB压缩至11.37MB ,降幅高达95.8% 。这种极致的压缩率直接解决了游戏分发文件体积庞大的痛点,为高分辨率材质的广泛部署扫清了存储与传输障碍。然而,高压缩率与重建画质之间存在着固有的权衡关系。在启用DLSS(一种AI超分辨率技术)的场景下,NTC的"转码为BCn"模式在保持极高压缩率(将纹理内存从272MB降至98MB)的同时,其平均帧率下降可忽略不计,且1%低帧率表现甚至优于传统压缩方法。这表明,在AI超分辨率重建的辅助下,NTC能够在高压缩率与高质量视觉还原之间找到有效的平衡点,其输出的画面质量(以峰值信噪比PSNR衡量)可达到40-50 dB的专业水准。
相比之下,纯粹的"样本推理"模式虽然压缩率登峰造极,但在相同测试环境下,其平均帧率从约1600fps降至1500fps,1%低帧率也下降至约840fps,性能损耗更为明显。这揭示了质量损失的临界点:当压缩强度达到极致时,实时推理重建的计算负担会加剧,可能对渲染流畅度构成挑战。因此,在实际应用中,开发者需根据目标平台算力和画质要求,在"高压缩率+高重建开销"与"适度压缩率+低重建开销"两种模式间进行策略性选择。AMD的神经纹理块压缩(NTBC)技术同样致力于此,其目标是在减少70%游戏存储空间的同时,确保视觉质量优于传统方法,且不影响运行时效率,这进一步印证了行业通过智能算法优化压缩率-质量博弈关系的共同方向。
2.2 实时性保障与显存优化的技术实现
在游戏主机环境下,确保纹理实时解压与重建的延迟可控至关重要。NTC技术的实时性表现高度依赖于运行模式与渲染设置。数据显示,在4K分辨率并开启DLSS后,无论是"转码为BCn"还是"样本推理"模式,其平均帧率均可维持在约1100fps的高水平,1%最低帧率也稳定在500fps左右,证明了在AI超分辨率管线中,NTC能够实现稳定的实时性能。更重要的是,显存占用的大幅降低直接缓解了带宽压力 ,为维持高帧率提供了基础。NTC通过将纹理视为多维张量并利用张量核心进行处理,最高可节省96%的显存占用,这使得GPU能够处理比当前原生能力高出四倍分辨率的纹理。
为了实现实时性保障与显存优化的协同,动态资源分配策略是关键。当关闭DLSS并启用TAA抗锯齿时,"样本推理"模式在1440p下的1%低帧率可从840fps跃升至1300fps左右。这表明,渲染管线的其他环节(如抗锯齿)的计算负载变化,会显著影响NTC模型推理的可用资源与最终延迟。因此,主机系统需要具备动态调度能力,根据帧时间预算,智能分配GPU的流处理器与张量核心资源,在纹理重建、光照计算、后期处理等任务间取得平衡,确保整体渲染流水线的高效与稳定。
2.3 功耗控制与渲染效能的协同策略
神经纹理压缩与重建方案对功耗的影响呈现多面性。一方面,显著降低的显存占用直接减少了对显存带宽的需求,而显存访问是GPU功耗的主要来源之一,因此该技术能够从系统层面间接实现功耗优化。另一方面,运行轻量化AI模型进行实时解压需要调用GPU的张量核心或相关计算单元,这会引入额外的计算功耗。技术的整体能效比取决于"显存功耗节省"与"计算功耗增加"之间的净值。
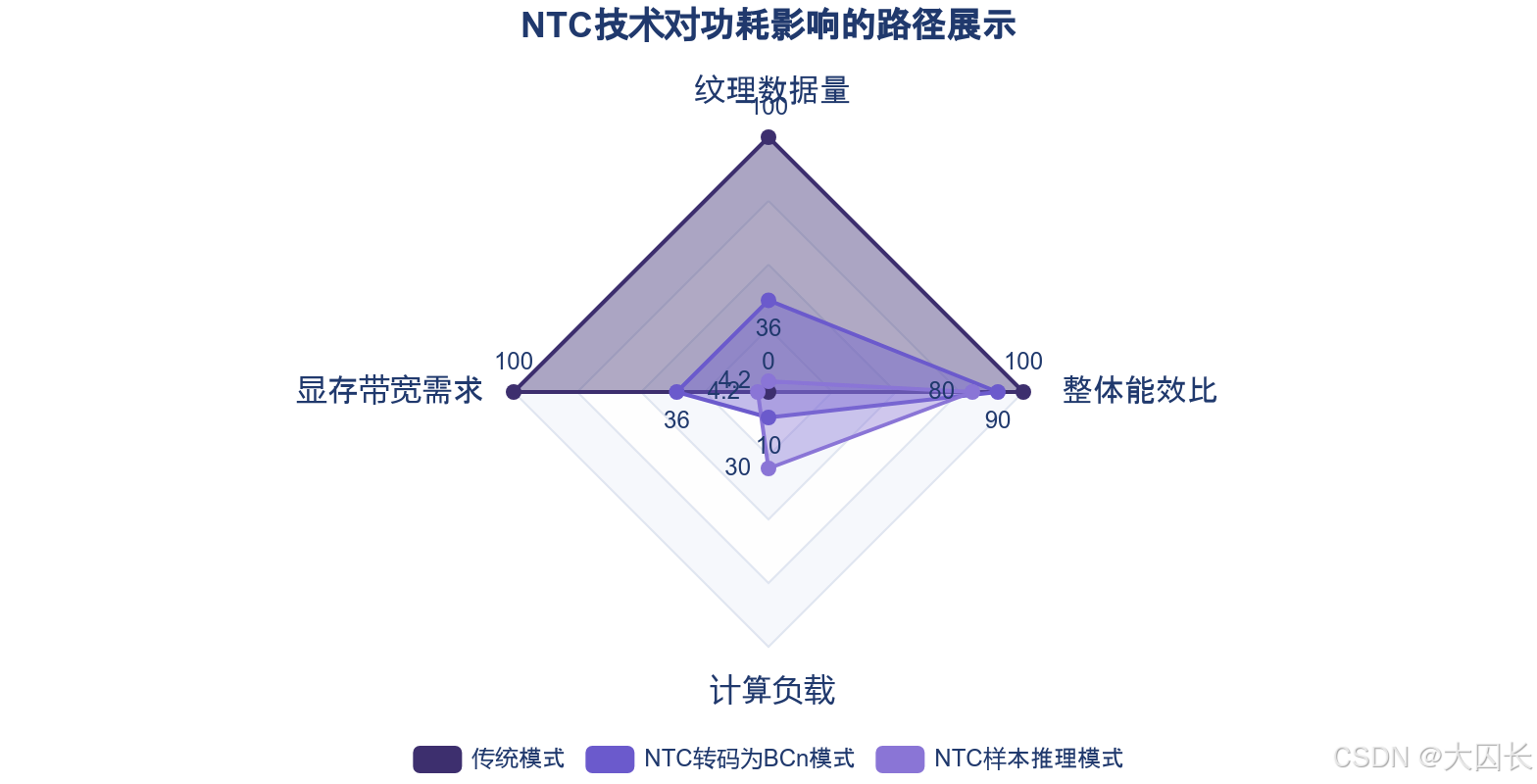
实证数据揭示了其提升渲染效能的边界。在4K分辨率且关闭DLSS、启用TAA时,"NTC转码为BCn"模式的平均帧率可提升至约1700fps,"样本推理"模式也达到1500fps。这验证了在特定渲染配置下,NTC通过极致优化显存使用,所释放出的带宽和缓存资源能够有效提升传统渲染管线的执行效率 ,实现了对GPU原生算力的替代与增强。其核心价值在于,它使得中端硬件设备能够通过"高效压缩+智能重建"的路径,呈现出接近需要高端硬件才能支持的高分辨率材质细节,从而在有限的功耗预算内最大化画面表现力。AMD NTBC技术同样强调在大幅减小游戏体积的同时,承诺不影响运行时执行效率,这体现了业界对于该技术路径在能效比上达成积极共识的期待。
三、游戏工作流集成可行性路径
3.1 开发端适配:引擎支持与工具链改造需求
将神经纹理压缩(NTC)与AI重建技术集成至游戏开发工作流,首先面临的是主流游戏引擎的适配挑战。该技术需要与图形API及渲染管线深度协同,其在不同抗锯齿模式(如DLSS或TAA)下对帧率表现有显著影响,这增加了引擎集成的复杂性。目前,NTC技术仍处于beta测试阶段,尚未明确获得游戏引擎的原生支持,这意味着开发团队需要进行底层技术改造以对接其压缩与解压接口。
在工具链层面,微软已通过DirectX Compute Graph Compiler提供了关键的简化路径。该编译器允许GPU以原生性能执行完整的机器学习模型图,从而极大地简化了开发者将AI模型集成到游戏引擎的流程 ,为开发端工具链的改造提供了官方支持框架。这降低了开发团队自行构建AI推理管线的技术门槛,使得将NTC的压缩与重建模型嵌入游戏资产处理流程成为可能。此外,NTC技术能够将显存占用降低最高96%,允许处理更高分辨率的纹理,这一特性可直接减少开发过程中对显存容量的依赖,使美术与程序人员无需过度担忧玩家硬件限制,从而加快图形效果的测试与迭代速度,从工具效率层面提升了开发流程的可行性。
3.2 主机端部署:硬件兼容性与系统层优化空间
在主机端部署实时AI推理模型,硬件兼容性是首要考量。NTC技术的最低硬件要求虽为RTX 20系列显卡,但已在包括AMD Radeon RX 6000系列在内的多品牌显卡上通过验证,表明其具备跨品牌硬件兼容性基础 ,这为在PS5(基于AMD RDNA 2架构)和Xbox Series X上实现类似技术提供了可能性。然而,要实现完整的端到端优化,还需满足更高级别的系统层要求。例如,为支持相关的光线追踪优化,微软DXR 2.0要求硬件支持着色器模型6.10及透明度微图(OMM),这构成了下一代主机硬件兼容性的一个关键门槛。
在系统层优化方面,微软已在DirectX API中集成了神经纹理压缩技术,通过着色器模型6.9的'协作向量'特性实现,并已融入Agility SDK 1.619。这一系统级的集成,为在主机操作系统驱动层实现AI推理加速提供了标准化路径。英伟达的Blackwell架构已率先支持该特性,而AMD也计划在后续架构中引入,预示着未来主机GPU将具备更原生的AI纹理处理能力,为降低推理延迟和功耗提供了硬件加速空间。
3.3 跨平台协同:分发标准与用户透明化体验设计
实现跨PS5、Xbox Series X等多平台的协同,需要构建统一的纹理压缩与分发标准。微软在DirectX生态中的举措为此指明了方向,其将神经纹理压缩技术集成至Agility SDK,并推出**'高级着色器分发'(ASD)技术**,允许开发者通过App Identity和Stats API声明应用身份并监控预编译着色器数据库命中率。这套机制使得针对不同主机硬件优化的预编译着色器(可能包含AI重建模型)能够被高效分发与管理,为实现跨平台统一标准下的差异化优化提供了技术基础。

在用户体验设计上,核心目标是实现"无感知"的画质增强。ASD技术通过监控和优化着色器命中率,旨在提升运行时性能的稳定性,这直接关系到用户能否获得流畅、无卡顿的视觉体验。整个技术流程------从开发端的高效压缩,到根据主机硬件自动分配合适的AI重建模型,再到最终渲染出高质量画面------应对玩家完全透明。用户仅感知到游戏安装包体积显著减小、加载速度可能加快,以及最终呈现的画面细节超越其硬件常规水平,而无需进行任何复杂设置,从而实现技术升级与用户体验平滑衔接的最终目标。
四、风险研判与未来演进方向
4.1 实时重建质量波动与性能瓶颈风险
该方案在实时渲染中的稳定性面临挑战。神经纹理压缩(NTC)的"样本推理"模式虽能实现高达95.8%的压缩率 ,但在1440p分辨率下,其1%低帧率会显著下降至约840fps ,表明AI推理引入的延迟可能构成影响流畅性的潜在性能瓶颈。同时,其画质增强效果高度依赖开发者对参数的精细调校,若调校不当,可能产生动态模糊或细节失真。在4K高分辨率场景下,NTC技术虽能维持约1100fps的平均帧率,但关闭DLSS时帧率波动明显,显示出其对AI超分辨率上采样技术的依赖风险,一旦协同失效,重建质量与实时性均可能受损。
4.2 硬件生态分化与开发适配障碍
技术的跨平台普及面临硬件与开发双重壁垒。一方面,尽管NTC技术已兼容多品牌显卡,但其最佳性能表现依赖于新一代GPU的专用硬件单元(如RTX 50系列的Tensor Core),这可能加剧设备分化,限制技术在低配或旧款主机平台上的普及 。另一方面,当前主流游戏引擎(如Unity、Unreal)尚未完全适配此类AI神经渲染新技术,开发者需掌握AI模型训练与参数调控能力,面临较高的学习门槛与工具链重构成本。技术本质上是开发者艺术意图的延伸工具,其成功落地高度依赖开发者对神经渲染参数的掌握能力,这构成了广泛的接受度障碍。
4.3 渐进式技术演进路线规划
为应对上述风险,建议采取分阶段、标准先行的推进策略。**短期(1-2年)**应聚焦于生态培育,依托英伟达开源RTX Remix平台和神经纹理压缩SDK等工具链,降低开发者集成门槛,并通过提升40%推理效率的工具优化开发体验。同时,推动微软将NTC更深层次集成至DirectX API与Agility SDK,为未来主机GPU原生AI纹理处理能力奠定软件基础。**中期(3-5年)**的目标是实现跨平台标准化,由主要平台商牵头,制定统一的神经纹理压缩与分发标准,并推动游戏引擎原生支持,使AI渲染成为下一代游戏开发的基础设施。长期则需与硬件迭代同步,等待如Rubin架构GPU等下一代硬件在2027-2028年后逐步普及,从根本上解决算力与能效约束。
4.4 未来技术迭代方向预判
展望未来,技术本身将向更高效、更智能的方向演进。核心方向之一是优化网络结构与推理速度 ,通过设计更高效的轻量化模型,在保证逼真度的同时进一步降低实时渲染延迟,解决当前存在的性能波动问题。其次,自监督学习与跨域泛化能力将成为重点,旨在减少对海量标注数据的依赖,并使模型能在不同游戏场景、光照条件下均保持出色的重建质量与稳定性,提升技术的实用性与鲁棒性。最终,技术将与硬件进步深度融合,推动实现完全"无感知"的极致体验,使中端硬件也能流畅呈现超高细节的渲染效果,彻底改变游戏画质与硬件配置之间的传统关系。