在 AI 大模型竞速的赛道上,当所有玩家都在追求"更快"的时候,陈天桥团队的 MiroMind 却选择了一条截然不同的路------让 AI"慢下来"。
这个看似反直觉的策略,却在最新发布的 MiroThinker-1.7 和 MiroThinker-H1上得到了验证:通过深度推理和严格验证,这两款重型推理智能体在多项基准测试中刷新纪录,超越了 Gemini-3.1-Pro、GPT-5.4-Thinking、Claude-4.6-Opus 等行业顶尖模型。

为什么要让 AI"慢"下来?
在当前的 AI 竞争格局中,"快"似乎成了唯一的标准。秒级响应、实时交互、零延迟体验------这些词汇充斥着各大模型的宣传页面。然而 MiroMind 团队却发现了一个被忽视的关键问题:速度快不等于答案对。
想象一下,你让 AI 预测 15 天后的黄金价格,或者分析一场 F1 比赛的最终排名。这类复杂任务需要模型综合考虑市场趋势、历史数据、实时信息、多重变量等因素,进行深度推理和交叉验证。如果模型只是快速给出一个"看起来合理"的答案,而没有经过严密的逻辑推演,那么这个答案的可信度会大打折扣。
MiroThinker-1.7 的核心理念正是基于这一洞察:在复杂推理任务中,质量比速度更重要。与其让模型快速输出一个不够准确的结果,不如让它多花一两分钟,把每一步推理都做扎实,把每一个结论都验证清楚。
重型推理:不只是延长思考时间
MiroThinker-1.7 被称为"重型推理智能体",但这个"重型"并不仅仅意味着更长的思考时间。
当前业界提升推理能力的主流做法是通过强化学习延长模型的 CoT(Chain of Thought)运算时间。这种方法在数学、编程等领域确实有效,但 MiroMind 团队发现了一个更深层的问题:如果模型每一步决策本身质量不高,即使完成更多轮交互,最终也只是在放大低质量决策的影响。
因此,MiroThinker-1.7 的技术突破聚焦在两个维度:
1. 智能体原生能力的深度强化
MiroThinker-1.7 在训练流程中引入了 **mid-training(中期训练)**阶段。这个阶段使用大规模高质量任务数据,专门训练模型的规划、推理和总结能力,让它建立起更强的 Agent 基础能力------包括目标分解、工具选择、结果理解和答案整合。
在此基础上,再通过 SFT(监督微调)、DPO(偏好优化)、RL(强化学习)进一步将这些能力内化,使模型在面对长时复杂任务时能够保持稳定的推理表现。
2. 以验证为核心的推理架构
单纯提升模型能力还不够,MiroThinker-1.7 引入了验证器机制,分为局部验证和全局验证两个层面。局部验证确保每一步推理的逻辑正确性,全局验证则从整体视角审视推理链条的一致性和完整性。
这种设计带来了一个意外的发现:在引入验证机制后,模型的交互步骤数量反而显著减少了。原因在于验证器充当了过滤器的角色,帮助模型及时筛除没有信息增益的冗余步骤,将算力集中在真正推动问题求解的关键环节上。虽然总步数减少了,但每一步的推理质量更高,整个过程变得更加高效精密。
实战检验:预测黄金价格与 F1 赛事
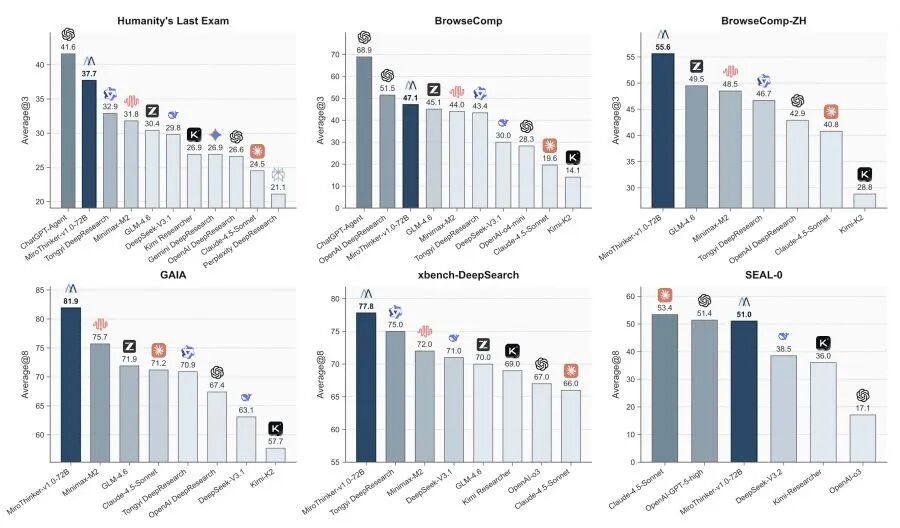
理论再完美,也需要实战来检验。MiroThinker-1.7 在多个真实场景中展现了令人印象深刻的表现。
在金融预测领域,有用户在 2 月 10 日让 MiroThinker 预测 15 天后(2 月 25 日)的黄金价格。模型给出的预测是 5185 美元/盎司,而实际价格为 5181 美元(Fortune 报价)到 5206.40 美元(CME GCG26 收盘价),误差仅为 0.08%,保持在合理范围内。
更有趣的是 F1 上海站的预测案例。在比赛前 2 小时、比赛进行中 1 小时、比赛最后 30 分钟三个时间节点,MiroThinker 分别给出了预测。模型不仅考虑了车队实力、车手状态、历史成绩,还关注到了天气状况、赛道特点、比赛策略等细节因素。随着比赛进程推进,模型不断整合实时信息,调整预测结果,最终在比赛结束前 30 分钟给出的预测与实际结果完全一致。
这种动态调整能力,正是 MiroThinker 深度推理和验证机制的体现:它不是简单地给出一个静态答案,而是能够持续追踪信息变化,在复杂多变的环境中保持推理的准确性。
精准 Scaling:把算力用在刀刃上
MiroThinker 系列的另一个亮点是精准 Scaling策略。
在 AI 行业,"Scaling Law"(规模法则)几乎成了信仰:更大的模型、更多的数据、更强的算力,就能带来更好的性能。但 MiroMind 团队提出了一个不同的视角:算力不应该无差别地堆砌,而应该精准投放到真正需要的地方。
MiroThinker-1.7 系列包含三个版本:旗舰级的 MiroThinker-H1、开源的 MiroThinker-1.7(235B)、以及小尺寸的 MiroThinker-1.7-mini(30B)。这种差异化的产品矩阵,让开发者可以根据具体任务的复杂度和对响应速度的要求,选择最合适的模型版本。
对于需要极致准确性的科研、金融、法律等专业领域任务,可以使用 MiroThinker-H1,让模型充分发挥深度推理能力;对于复杂度适中的任务,MiroThinker-1.7 能够在性能和效率之间取得最优平衡;而对于资源受限或对响应速度有要求的场景,MiroThinker-1.7-mini 则提供了轻量化的解决方案。
这种"因任务而异"的设计理念,体现了 MiroMind 对算力使用效率的深刻思考:不是所有任务都需要最大的模型,关键是找到任务复杂度与模型能力的最佳匹配点。
慢交互的哲学:深度优先于速度
从 V1.5 到 V1.7,MiroThinker 系列一直坚持"慢交互"的理念。这种坚持在快节奏的 AI 竞争中显得格外特立独行,但也正是这种差异化定位,让 MiroThinker 找到了自己的生态位。
"慢"不是目的,而是手段。MiroThinker 追求的不是慢本身,而是在行动前暂停、验证、权衡,确保在复杂场景下推得深、推得对。这种看似不讨巧的选择,反而成就了 MiroThinker 在深度推理任务中的独特优势。
在算力约束与复杂任务的博弈中,MiroThinker 没有盲目堆砌算力,而是像一位深谙最优路径的理科生,精打细算地将每一份算力落在该去的地方。结果证明,只要踏实做好有效交互,"慢"不等同于落后,反而是助力 LLM 走向真实物理世界的更扎实路径。
团队升级:三位世界级科学家加盟
技术突破的背后,是团队实力的支撑。MiroMind 从诞生之初就由时任盛大副总裁、现任 MiroMind COO 邴立东博士在新加坡牵头组建团队,一路护航 MiroThinker 从 V1.5 走到 V1.7。
而在最近,三位世界级顶尖 AI 科学家------杜少雷、安波和杨凯峪------同时加入 MiroMind。他们都是模型推理领域的资深专家,长期致力于开发前沿大模型的推理决策能力。这支梦之队的组建,标志着 MiroMind 在技术深度和产品化能力上都进入了新的阶段。
有技术、有人才、有资金、有理念------四角齐全的 MiroMind,虽然入场大模型赛道的时间相对较晚,但每一步都稳扎稳打。从 V1.5 的初露锋芒到 V1.7 的全面突破,MiroThinker 用实力证明:在 AI 的长跑中,后来者居上从来不是神话。
写在最后
在这个人人追求"快"的时代,MiroThinker 选择了"慢"。但这个"慢"不是迟钝,而是深思熟虑;不是落后,而是精准高效。
当其他模型在秒级响应中给出似是而非的答案时,MiroThinker 愿意多花一两分钟,把每一步推理都做扎实,把每一个结论都验证清楚。这种对质量的执着追求,或许正是 AI 从"看起来很聪明"走向"真正可信赖"的必经之路。
MiroThinker-1.7 的发布,不仅是一次技术升级,更是一次理念的宣示:在复杂推理任务中,我们需要的不是更快的 AI,而是更可靠的 AI。
社区地址
OpenCSG社区:https://opencsg.com/models/AIWizards/MiroThinker-1.7
hf社区:https://huggingface.co/miromind-ai/MiroThinker-1.7
关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论, 由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。