少样本提示是⼀种通过向 LLM 提供少量具体示例或样本,来教会它如何执行某项特定任务的技术。提高模型性能的最有效方法之⼀是给出⼀个【模型示例】指导大模型你想做什么、怎么做。也就是给出example,通过输入和预期输出(label)来增强模型的可预估性
通过给出一些少样本示例,让模型的回答更准确,可信!
实现少样本提示的第⼀步也是最重要的⼀步是提出⼀个好的示例数据集。
python
examples = [
{"input": "2 🦜 2", "output": "4"},
{"input": "2 🦜 3", "output": "5"},
]然后我们提供聊天提示词模版
python
example_prompt = ChatPromptTemplate(
[
("human", "{input}"),
("ai", "{output}")
]
)接下来我们需要将示例集实例化成聊天模型可以读懂的聊天消息,然后供模型去调用
对于 LangChain 就需要创建⼀个FewShotChatMessagePromptTemplate 对象来实例化示例集。
是⼀个提示词模板,专门用来将示例集实例化为聊天消息
python
# 通过FewShotChatMessagePromptTemplate专门用来将示例集实例化为聊天消息
fewshot_chat_mes_prompt_tem = FewShotChatMessagePromptTemplate(
examples=examples, # 样本实例
example_prompt=example_prompt, # ChatPromptTemplate,⽤于格式化单个⽰例
)
print(fewshot_chat_mes_prompt_tem.invoke({}).to_messages())
# 结果
# [HumanMessage(content='2 🦜 2', additional_kwargs={}, response_metadata={}),
# AIMessage(content='4', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]),
# HumanMessage(content='2 🦜 3', additional_kwargs={}, response_metadata={}),
# AIMessage(content='5', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[])]下面我们就可以定义链让LLM去调用了。
这里需要再区分一下,提示词模版,是为了方便我们的,让我们更好维护和管理,复用性更高,少样本提示模版是有利于LLM的,为了让模型的准确性更好,针对的角色是不同的。
所以,少样本提示能干嘛?
1.可以推理引导,让LLM回答的让我们值得可信。
之前说LLM的回答可能是不够专业,不一定可信。但是我们可以通过少样本提示,推理引导,让其准确。
举个例子:
比如我们给出的示例集:
这是我们希望LLM的思考过程
python
# 创建⽰例集
examples = [
{
"question": "李⽩和杜甫,谁更⻓寿?",
"answer": """
是否需要后续问题:是的。
后续问题:李⽩享年多少岁?
中间答案:李⽩享年61岁。
后续问题:杜甫享年多少岁?
中间答案:杜甫享年58岁。
所以最终答案是:李⽩"""
},
{
"question": "腾讯的创始⼈什么时候出⽣?",
"answer": """
是否需要后续问题:是的。
后续问题:腾讯的创始⼈是谁?
中间答案:腾讯由⻢化腾创⽴。
后续问题:⻢化腾什么时候出⽣?
中间答案:⻢化腾出⽣于1971年10⽉29⽇。
所以最终答案是:1971年10⽉29⽇
""",
},
{
"question": "孙中⼭的外祖⽗是谁?",
"answer": """
是否需要后续问题:是的。
后续问题:孙中⼭的⺟亲是谁?
中间答案:孙中⼭的⺟亲是杨太夫⼈。
后续问题:杨太夫⼈的⽗亲是谁?
中间答案:杨太夫⼈的⽗亲是杨胜辉。
所以最终答案是:杨胜辉
""",
},
{
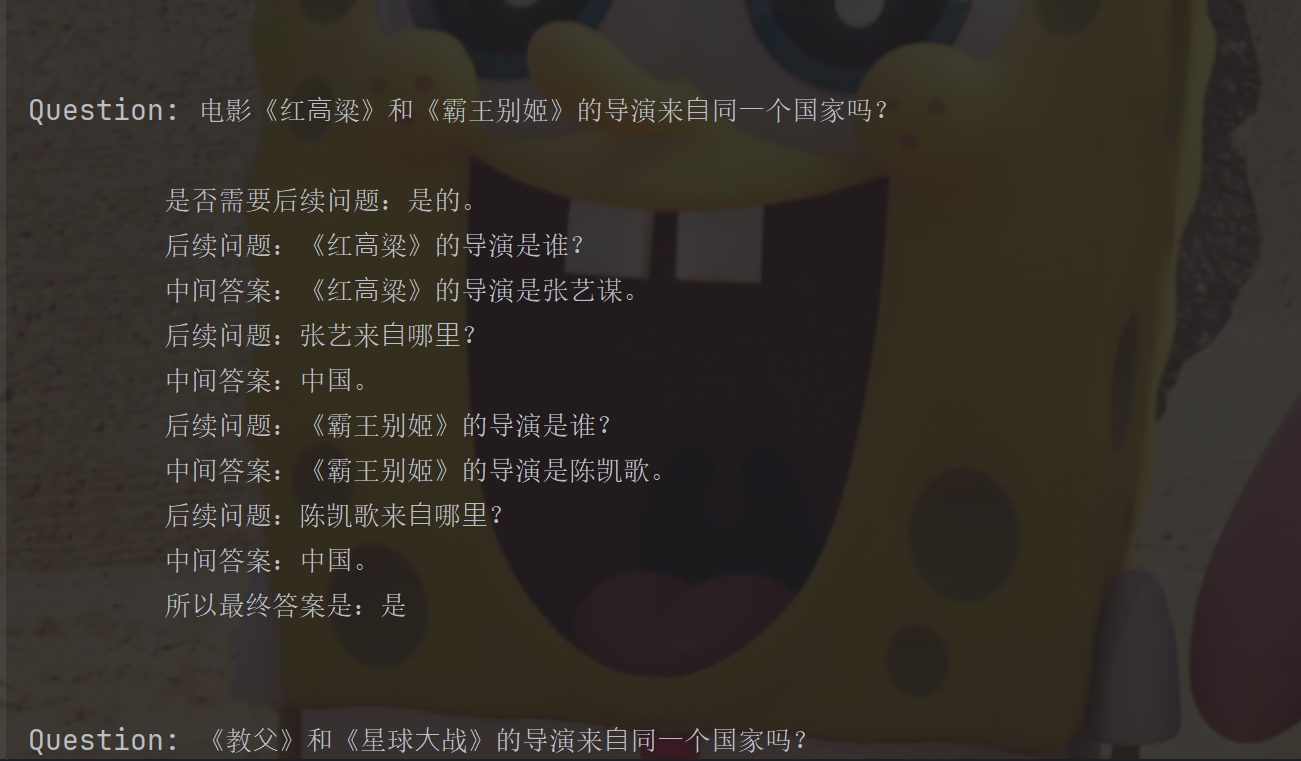
"question": "电影《红⾼粱》和《霸王别姬》的导演来⾃同⼀个国家吗?",
"answer": """
是否需要后续问题:是的。
后续问题:《红⾼粱》的导演是谁?
中间答案:《红⾼粱》的导演是张艺谋。
后续问题:张艺来⾃哪⾥?
中间答案:中国。
后续问题:《霸王别姬》的导演是谁?
中间答案:《霸王别姬》的导演是陈凯歌。
后续问题:陈凯歌来⾃哪⾥?
中间答案:中国。
所以最终答案是:是
""",
},
]接下来我们需要格式化完整的样本提示。此时可以创建⼀个 FewShotPromptTemplate 对象来初始化少样本提示模板。
python
example_prompt = PromptTemplate.from_template("Question: {question}\n{answer}")
examples = [...]
# 少样本提示
fewshot_prompt_template = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt, # PromptTemplate,⽤于格式化单个⽰例
suffix="Question: {input}", # 放在⽰例之后的提⽰模板字符串。
input_variables=["input"] # 变量的名称列表,这些变量的值需要作为提⽰词的输入
)
print(fewshot_prompt_template.invoke({
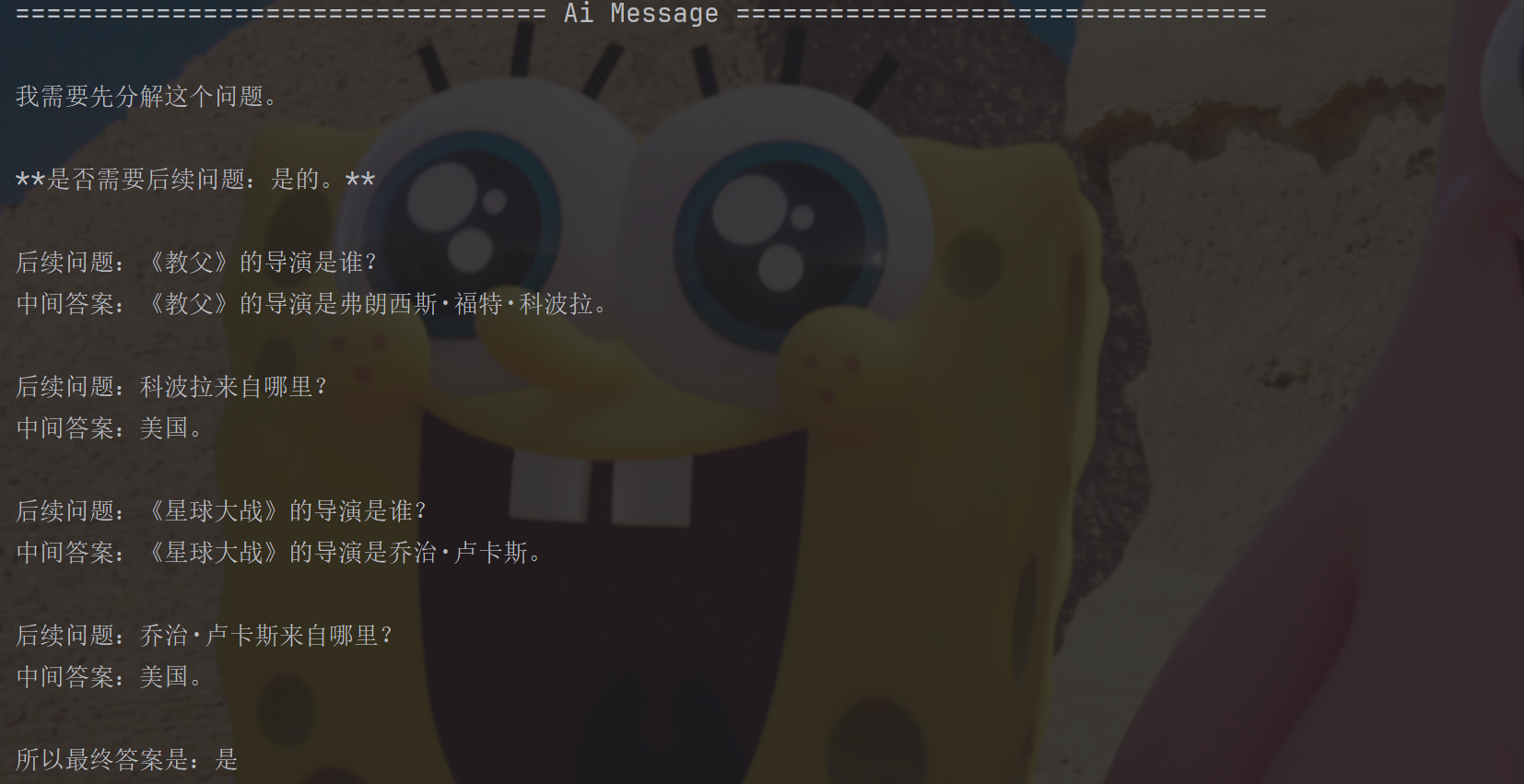
"input": "《教⽗》和《星球⼤战》的导演来⾃同⼀个国家吗?"
}).to_string())我们这里为啥不用聊天提示词模版了,一般聊天提示词模版是用于聊天对话的,当然也可以用,不过这种文本,直接使用PromptTemplate即可
最后定义链,调用模型
python
chain = fewshot_prompt_template | model
chain.invoke({
"input": "《教⽗》和《星球⼤战》的导演来⾃同⼀个国家吗?" # input传给少样本提示输入
}).pretty_print()最终AI的回复,是我们想要的推理工程
使用占位符来提供少样本提示
2.使用示例数据增强 LangChain 信息提取能力
还记得我们之前用格式化器让模型提取到输出具有我们特定的schema格式。那LLM能保证一定提取的准确嘛?
python
import os
from typing import List, Optional
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
# 2.使用示例数据增强 LangChain 信息提取能力
# 定义结构化输出
class Person(BaseModel):
"""⼀个⼈的信息。"""
name: Optional[str] = Field(default=None, description="这个⼈的名字")
hair_color: Optional[str] = Field(default=None, description="如果知道这个⼈头发的颜⾊")
skin_color: Optional[str] = Field(default=None, description="如果知道这个⼈的肤⾊")
height_in_meters: Optional[str] = Field(default=None, description="以⽶为单位的⾼度")
class Data(BaseModel):
"""提取关于⼈的数据。"""
people: List[Person]
model = ChatOpenAI(model="deepseek-chat",
api_key=os.environ.get("DEEPSEEK_API_KEY"),
openai_api_base="https://api.deepseek.com/v1")
model_with_struct = model.with_structured_output(schema=Data, method="function_calling")
messages = [
SystemMessage("你是一个文本提取大师,提取相关属性,如果属性不存在,返回null"),
HumanMessage("篮球场上,⾝⾼两⽶的中锋王伟默契地将球传给⼀⽶七的后卫挚友李明,完成⼀记绝杀")
]
print(model_with_struct.invoke(messages))好像也可以

不过使用少样本提示+结构化返回来进一步增强 LangChain 信息提取能力,有种锦上添花的作用
下面,我们如果增加少样本提示,先构造提示词模版:
python
# 定义提示词模版
chat_prompt_tem = ChatPromptTemplate([
("system", "你是一个文本提取大师,提取相关属性,如果属性不存在,返回null"), # 系统提示词
MessagesPlaceholder("msg"), # 用于传递示例消息的,先占位置
("user", "{input}"),
])
chain = chat_prompt_tem | model_with_struct
chain.invoke({
"msg": examples_msg,
"input": "篮球场上,⾝⾼两⽶的中锋王伟默契地将球传给⼀⽶七的后卫挚友李明,完成⼀记绝杀"
})可是这个examples_msg怎么确定呢?,我们就需要构造LLM可理解的消息列表了,如何构建呢?
遍历每个示例对:文本、期望输出
• 根据 是否有⼈员信息生成自然语言响应: "检测到⼈" or "未检测到⼈"
• 使用 tool_example_to_messages 转换格式,将每个示例转换为模型可理解的消息格式
python
# 将示例->消息
# 遍历⽰例对,将每个⽰例构造成聊天消息
examples_msg = []
for txt, tool_call in examples:
# 根据提取结果⽣成AI响应⽂本
if tool_call.people:
ai_response = "检测到人"
else:
ai_response = "未检测到人"
# 将⽰例转换为模型可理解的消息格式
examples_msg.extend(tool_example_to_messages(
input=txt, # 示例的输入
tool_calls=[tool_call], # 工具 Data(people=[])的标准参考
ai_response=ai_response,
))最后我们得到的消息列表结果:
消息已经被我们构造成功!可以看到,⼀个示例经过转换构建出了4条消息: HumanMessage 、AiMessage(tool) 、 ToolMessage 、 AiMessage
python
print(examples_msg)
# [HumanMessage(content='海洋是⼴阔⽽蓝⾊的。它有两万多英尺深。', additional_kwargs={}, response_metadata={}),
# AIMessage(content='', additional_kwargs={'tool_calls': [{'id': '4735bb36-8f7c-44fa-b724-4d0b036326a9', 'type': 'function', 'function': {'name': 'Data', 'arguments': '{"people":[]}'}}]}, response_metadata={}, tool_calls=[{'name': 'Data', 'args': {'people': []}, 'id': '4735bb36-8f7c-44fa-b724-4d0b036326a9', 'type': 'tool_call'}], invalid_tool_calls=[]),
# ToolMessage(content='You have correctly called this tool.', tool_call_id='4735bb36-8f7c-44fa-b724-4d0b036326a9'),
# AIMessage(content='未检测到人', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]),
# HumanMessage(content='⼩强从中国远⾏到美国。', additional_kwargs={}, response_metadata={}),
# AIMessage(content='', additional_kwargs={'tool_calls': [{'id': '54b38770-f090-4e7e-8404-0e2e3c7e5c01', 'type': 'function', 'function': {'name': 'Data', 'arguments': '{"people":[{"name":"⼩强","hair_color":null,"skin_color":null,"height_in_meters":null}]}'}}]}, response_metadata={}, tool_calls=[{'name': 'Data', 'args': {'people': [{'name': '⼩强', 'hair_color': None, 'skin_color': None, 'height_in_meters': None}]}, 'id': '54b38770-f090-4e7e-8404-0e2e3c7e5c01', 'type': 'tool_call'}], invalid_tool_calls=[]),
# ToolMessage(content='You have correctly called this tool.', tool_call_id='54b38770-f090-4e7e-8404-0e2e3c7e5c01'),
# AIMessage(content='检测到人', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[])]实例化提示词:
测试一下:
python
for msg in chat_prompt_tem.invoke({
"msg": examples_msg,
"input": "篮球场上,⾝⾼两⽶的中锋王伟默契地将球传给⼀⽶七的后卫挚友李明,完成⼀记绝杀"
}).to_messages():
msg.pretty_print()我们最后给LLM的消息
python
================================ System Message ================================
你是一个文本提取大师,提取相关属性,如果属性不存在,返回null
================================ Human Message =================================
海洋是⼴阔⽽蓝⾊的。它有两万多英尺深。
================================== Ai Message ==================================
Tool Calls:
Data (04af4b86-4104-48c9-8a50-167135a6dd4b)
Call ID: 04af4b86-4104-48c9-8a50-167135a6dd4b
Args:
people: []
================================= Tool Message =================================
You have correctly called this tool.
================================== Ai Message ==================================
未检测到人
================================ Human Message =================================
⼩强从中国远⾏到美国。
================================== Ai Message ==================================
Tool Calls:
Data (1e7dccf2-50e8-416d-ba31-3c2a7b85d01a)
Call ID: 1e7dccf2-50e8-416d-ba31-3c2a7b85d01a
Args:
people: [{'name': '⼩强', 'hair_color': None, 'skin_color': None, 'height_in_meters': None}]
================================= Tool Message =================================
You have correctly called this tool.
================================== Ai Message ==================================
检测到人
================================ Human Message =================================
篮球场上,⾝⾼两⽶的中锋王伟默契地将球传给⼀⽶七的后卫挚友李明,完成⼀记绝杀最后,调用一下chain:
python
# 带有Pydantic对象的链
chain = chat_prompt_tem | model_with_struct
print(chain.invoke({
"msg": examples_msg,
"input": "篮球场上,⾝⾼两⽶的中锋王伟默契地将球传给⼀⽶七的后卫挚友李明,完成⼀记绝杀"
}))
# 普通模型+少量样本示例的链
chain = chat_prompt_tem | model
chain.invoke({
"msg": examples_msg,
"input": "篮球场上,⾝⾼两⽶的中锋王伟默契地将球传给⼀⽶七的后卫挚友李明,完成⼀记绝杀"
}).pretty_print()
最后总结一下:
我们通过Pydantic定义输出模式、少样本学习引导模型行为、提示词模板动态组装上下文,以及链式调用简化流程。最终实现从非结构化文本中精准提取结构化数据。