本地大模型部署笔记:Ollama+Qwen2.5+Win11环境配置实录
0、前言
本文旨在记录 Windows 11 本地环境下,利用 Ollama 部署 Qwen2.5 大模型,并实现 API 调用。无需显卡也能跑 "、能够确保"隐私安全"。
可以在在安装和部署中了解与学习以下内容:
Ollama的作用和安装使用;Modelfile的作用和配置;ModelScope的作用;Notebook的作用;- 上述内容怎样结合使用实现部署大模型,部署成功后怎样通过API访问。
1、环境与准备
- Win11:Windows 11 专业版25H2
- CPU:Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz (2.21 GHz)
- 内存:16.0 GB
- 显卡:GTX1050Ti(很鸡肋,笔者在实践过程中,暂时没用到显卡)
- Ollama: 0.17.7
- 大模型 :
- qwen2.5-3b-instruct-q4_k_m
- qwen2.5-7b-instruct-q4_k_m
前置依赖检查
PowerShell(Win11 自带)Git(可选,用于下载)Python(仅用于ModelScope CLI,若只用浏览器下载可不装)
2、核心概念速览
2.1、模型文件名qwen2.5-3b-instruct-q4_k_m.gguf的含义?
文件名通常长这样:qwen2.5-3b-instruct-q4_k_m.gguf。
instruct 表示这是经过指令微调的版本,适合对话;如果是 base 版本,则适合做续写或二次微调,不适合直接对话。
1) q + 数字:代表每个参数用多少 bit 存储。
- 数字越小 = 文件越小 = 速度越快 = 稍微变笨一点。
- 数字越大 = 文件越大 = 速度越慢 = 越聪明。
- 黄金标准 :目前业界公认 4-bit (
q4) 是性价比最高的,智商损失微乎其微,但体积减半。 2)k:代表使用了 K-quants 量化技术(一种更先进的压缩算法,比老式的q4_0更聪明)。 3)m/s/l:代表 Small (小), Medium (中), Large (大)。 q4_k_s:更小一点,稍微笨一点点。q4_k_m:标准版 ,平衡最好(首选)。q4_k_l:更大一点,稍微聪明一点点(但显存占用也高)。
2.2、Modelfile 的基本结构及含义
Dockfile
FROM <model>
SYSTEM <system_prompt>
PARAMETER <name> <value>
TEMPLATE <template>
ADAPTER <path>
PROJECTOR <path>
MESSAGE <role> <content>
LICENSE <text>含义解释:
xml
FROM <model>: 指定基础模型(必选)。
SYSTEM <system_prompt>: 设置系统提示词(定义人设)。
PARAMETER <name> <value>: 设置推理参数(如温度、上下文长度)。
TEMPLATE <template>: 定义对话模板格式。
ADAPTER <path>: 加载 LoRA 适配器文件(用于微调模型)。
PROJECTOR <path>: 加载多模态投影器(用于让模型看懂图片)。
MESSAGE <role> <content>: 预设对话示例(Few-shot prompting)。
LICENSE <text>: 声明模型的许可证信息。一般用到的是:
Dockfile
FROM llama3 # 1. 选基座
SYSTEM "你是个诗人" # 2. 定人设
PARAMETER temperature 0.8 # 3. 调参数2.3、Notebook是什么?
虽然本文主要讲本地部署,但如果本地资源不足(如显存不够),可以使用 ModelScope Notebook 在云端免费体验大模型,无需本地硬件。
ModelScope Notebook是一款云端机器学习开发IDE工具,提供交互式编程环境,为用户提供了开箱可用的限时免费算力额度,实现ModelScope模型开发环境与CPU/GPU等多样化计算资源的无缝连接。
2.4、运行大模型的通俗理解
把运行大模型想象成"搬家"。
- 量化等级(Quantization)= 家具的打包压缩程度
- 推理框架 = 运输工具的选择
- 上下文长度(Context Length)= 这次要搬多少东西(记忆量)
3、实战部署:安装与运行
3.1、安装 Ollama
Ollama是一个开源的、专为本地运行大型语言模型(LLM)设计的工具平台,就像是"大模型的Docker"。
Ollama官网: ollama.com/

官网下载后安装:
bash
# 查看版本号
ollama -v
ollama version is 0.17.73.2、方式一:一键拉取(官方推荐),Ollama界面/命令行拉取
开了梯子依然慢。通过
Ollama拉去的镜像不用创建下面的Modelfile。
bash
# 下载并运行模型
ollama run qwen2.5:3b
3.3、方式二:自定义导入 (进阶),下载gguf文件自行配置
1)从ModelScope下载gguf文件
通过modelscope来进行浏览器下载模型,用Qwen2.5-3B-Instruct-GGUF演示(实际上我部署的就是这个)。
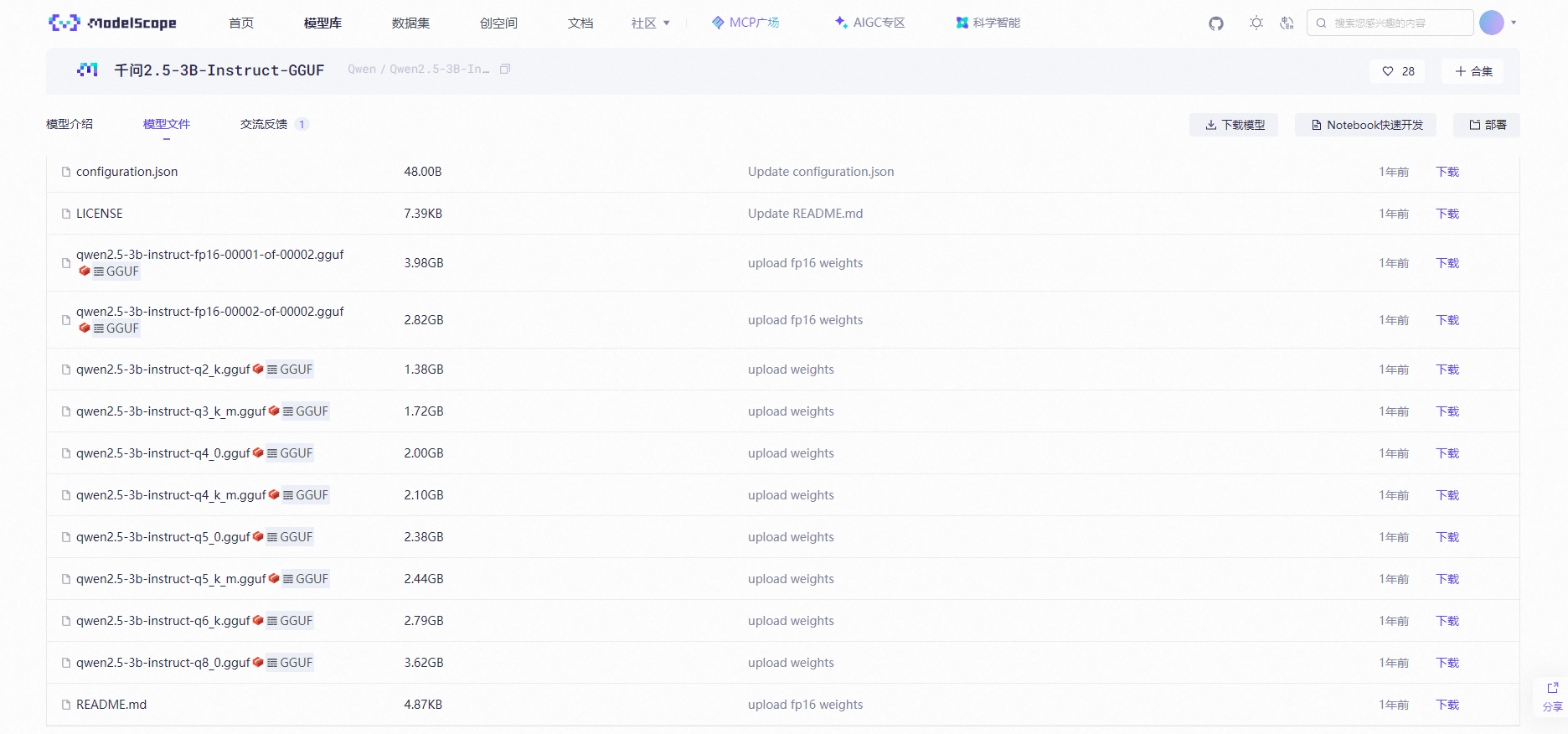
进入模型文件页,找到类似 qwen2.5-3b-instruct-q4_k_m.gguf 的文件,下载该文件。
2)编写Modelfile文件
Modelfile是Ollama用来实现大模型推理的自定义参数文件,类似于Dockerfile。如果你只是简单对话,Ollama 官方库里的默认模板通常已经适配好了 Qwen 系列,手动指定 TEMPLATE 仅在需要特殊对话格式或微调时才必要。具体可以见文末【4.3、Modelfile 的基本结构及含义】
新建文件,命名为Modelfile,内容如下:
python
FROM "G:\AI\Modelfiles\qwen2.5-3b\qwen2.5-3b-instruct-q4_k_m.gguf"
TEMPLATE """{{- if .Messages }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 }}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ .Content }}<|im_end|>
{{ else if eq .Role "system" }}<|im_start|>system
{{ .Content }}<|im_end|>
{{ end }}
{{- if $last }}<|im_start|>assistant
{{ end }}
{{- end }}
{{- else }}
{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ end }}"""
PARAMETER stop <|im_end|>
PARAMETER stop <|im_start|>
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER top_k 20
PARAMETER repeat_penalty 1.05
LICENSE """https://huggingface.co/Qwen/Qwen2.5-3B-Instruct/blob/main/LICENSE"""最简单版(自问自答几乎没法用)
text
FROM "F:\\Downloads\qwen2.5-3b-instruct-q4_k_m.gguf"3)创建模型
打开Powershell,找到刚才的Modelfile文件的路径,执行以下命令:
bash
# 把 GGUF 文件打包成 Ollama 模型
ollama create qwen2.5:3b -f Modelfile
# 或者用绝对路径
ollama create qwen2.5:3b -f G:\AI\Modelfiles\qwen2.5-3b\Modelfile
4)运行模型
Ollama 默认会自动检测并使用GPU 。Ollama 为了优化资源,默认会在 5 分钟 无活动后卸载模型;当再次发起请求时,如果模型已卸载,Ollama 会重新加载该模型到显存/内存中,然后处理请求。这会导致首次请求有额外的延迟(加载时间)。
arduino
ollama run qwen2.5:3b
查看大模型状态:
SIZE: 占用内存大小PROCESSOR:100% CPU: 表示模型完全在中央处理器 上运行,没有使用显卡(GPU)加速。我的显卡的显存只有4GB。CONTEXT:上下文窗口大小。当前会话保留的"记忆"长度(Token 数量)。这个数字越大,占用的内存也越大。UNTIL(自动卸载倒计时):表示如果接下来没有任何人使用该模型,Ollama 将在 2 分钟后 自动把它从内存中卸载,以释放资源。

5)示例:Qwen2.5-7B的配置
文件名:qwen2.5-7b-instruct-q4_k_m.gguf
ModelFile
FROM ./qwen2.5-7b-instruct-q4_k_m.gguf
TEMPLATE """{{- if .System }}
<|im_start|>system
{{ .System }}<|im_end|>
{{- end }}
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
PARAMETER stop <|im_end|>
PARAMETER stop <|im_start|>
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER top_k 20
SYSTEM "你是一个有帮助的AI助手。"4、通过API访问大模型
4.1、启动服务
bash
# 运行命令查看端口
ollama serve
# 返回信息:Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.默认 Ollama 只接受本机连接,拒绝局域网 IP(192.168.x.x),需要让 Ollama 暴露在网络上,Windows环境下按照下图配置即可。
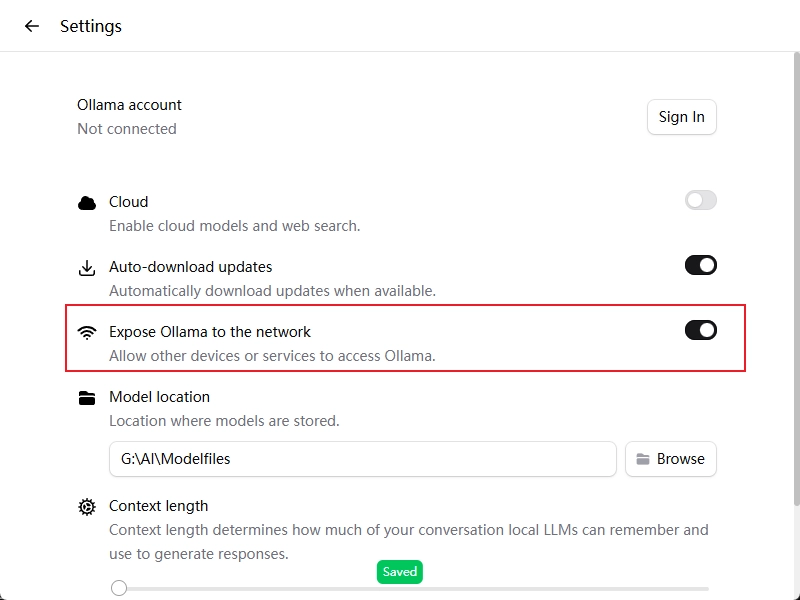
4.2、Powershell中测试接口
bash
# Windows Powershell
curl http://192.168.2.111:11434/api/generate -d "{\"model\": \"qwen2.5:3b\", \"prompt\": \"hello\"}"
curl http://192.168.31.87:11434/api/tags4.3、后台方式运行技巧
powershell
Start-Process ollama -ArgumentList "run","qwen2.5:3b" -WindowStyle Hidden5、常用命令速查表
Ollama相关文档: docs.ollama.com/quickstart
bash
# 查看帮助
ollama -h
# 查看本地已下载的模型
ollama list
# 下载并运行模型
ollama run qwen2.5:3b
# ollama run <模型名> <提示词>,单次问答
ollama run qwen2.5:3b "你好,请介绍一下你自己"
# 删除模型
ollama rm <模型名>
# 启动后台服务
ollama serve
# 查看模型详情
ollama show <模型名>
# 查看正在运行的模型
ollama ps
ollama stop qwen2.5:3b6、附录与参考资料
6.1、文档资料链接
1)Ollama:
- 官网: ollama.com/
- 文档: docs.ollama.com/quickstart 2)魔搭
ModelScope: - 官网: modelscope.cn/
- 文档: www.modelscope.cn/docs 3) Python: 3.11.9
- www.python.org/downloads/r...
6.2、ModelScope Pip 安装详解
powershell
# 安装python
python -V
Python 3.11.9
# 安装魔搭
pip install modelscope
# 下载完整模型库
modelscope download --model Qwen/Qwen2.5-3B-Instruct-GGUF
# 下载单个文件到指定本地文件夹(以下载README.md到当前路径下"dir"目录为例)
modelscope download --model Qwen/Qwen2.5-3B-Instruct-GGUF README.md --local_dir ./dir