机器学习18-tensorflow4.1
- CNN局部感受野和权值共享
-
- 一、先搞懂:为什么全连接网络不适合图像?
- [二、局部感受野(Local Receptive Field):只看局部,不看全局](#二、局部感受野(Local Receptive Field):只看局部,不看全局)
-
- [1. 通俗理解](#1. 通俗理解)
- [2. 原理定义](#2. 原理定义)
- [3. 直观示例(MNIST 28×28 图像)](#3. 直观示例(MNIST 28×28 图像))
- [4. 关键特性](#4. 关键特性)
- [三、权值共享(Weight Sharing):一套参数,复用全局](#三、权值共享(Weight Sharing):一套参数,复用全局)
-
- [1. 通俗理解](#1. 通俗理解)
- [2. 原理定义](#2. 原理定义)
- [3. 直观对比(参数数量)](#3. 直观对比(参数数量))
- [4. 核心价值](#4. 核心价值)
- [四、局部感受野 + 权值共享:CNN 的黄金组合](#四、局部感受野 + 权值共享:CNN 的黄金组合)
-
- [1. 组合效果](#1. 组合效果)
- [2. 可视化理解(MNIST 数字「5」)](#2. 可视化理解(MNIST 数字「5」))
- [3. 代码验证(查看 CNN 卷积核权重与感受野)](#3. 代码验证(查看 CNN 卷积核权重与感受野))
- 五、新手常见误区
- 卷积计算
-
- 一、先建立直观认知:卷积到底在做什么?
- [二、手动计算:单通道卷积(最基础,MNIST 场景)](#二、手动计算:单通道卷积(最基础,MNIST 场景))
-
- [步骤 1:定义输入和卷积核](#步骤 1:定义输入和卷积核)
- [步骤 2:滑动卷积核,逐位置计算](#步骤 2:滑动卷积核,逐位置计算)
-
- [位置 1:卷积核覆盖输入的 (0,0)~(2,2) 区域](#位置 1:卷积核覆盖输入的 (0,0)~(2,2) 区域)
- [位置 2:卷积核向右滑动1格,覆盖 (0,1)~(2,3) 区域](#位置 2:卷积核向右滑动1格,覆盖 (0,1)~(2,3) 区域)
- [位置 3:卷积核继续滑动,直到覆盖所有有效区域](#位置 3:卷积核继续滑动,直到覆盖所有有效区域)
- [步骤 3:最终特征图](#步骤 3:最终特征图)
- 三、公式推导:卷积计算的通用规则
-
- [1. 核心公式(单通道)](#1. 核心公式(单通道))
- [2. 输出尺寸计算公式(重中之重)](#2. 输出尺寸计算公式(重中之重))
-
- [实战示例(MNIST 28×28 图像)](#实战示例(MNIST 28×28 图像))
- [3. 多通道卷积(彩色图像场景)](#3. 多通道卷积(彩色图像场景))
- [四、代码验证:用 TensorFlow 复现卷积计算](#四、代码验证:用 TensorFlow 复现卷积计算)
- 五、实战关键注意事项(新手避坑)
-
- [1. Padding 选择](#1. Padding 选择)
- [2. Stride 调整](#2. Stride 调整)
- [3. 多通道 vs 多卷积核](#3. 多通道 vs 多卷积核)
- [4. 卷积的反向传播](#4. 卷积的反向传播)
- 总结(核心关键点)
- 池化操作
-
- 一、先搞懂:为什么需要池化?
- 二、池化的直观理解
- 三、池化的核心类型(实战中99%用这两种)
- 四、手动计算:池化的核心步骤(以最大池化为例)
-
- [步骤 1:定义输入特征图(卷积后的输出)](#步骤 1:定义输入特征图(卷积后的输出))
- [步骤 2:设置池化超参数](#步骤 2:设置池化超参数)
- [步骤 3:滑动池化窗口,逐区域取最大值](#步骤 3:滑动池化窗口,逐区域取最大值)
-
- [区域 1:(0,0)~(1,1)](#区域 1:(0,0)~(1,1))
- [区域 2:(0,2)~(1,3)](#区域 2:(0,2)~(1,3))
- [区域 3:(2,0)~(3,1)](#区域 3:(2,0)~(3,1))
- [区域 4:(2,2)~(3,3)](#区域 4:(2,2)~(3,3))
- [步骤 4:输出池化后的特征图](#步骤 4:输出池化后的特征图)
- 关键:池化输出尺寸计算
- [五、代码验证:用 TensorFlow 实现池化](#五、代码验证:用 TensorFlow 实现池化)
- 六、池化的核心价值(新手必懂)
-
- [1. 降维减参](#1. 降维减参)
- [2. 增强鲁棒性(平移/缩放不变性)](#2. 增强鲁棒性(平移/缩放不变性))
- [3. 保留关键特征](#3. 保留关键特征)
- [4. 防止过拟合](#4. 防止过拟合)
- 七、实战避坑指南
-
- [1. 池化窗口选择](#1. 池化窗口选择)
- [2. Padding 选择](#2. Padding 选择)
- [3. 池化 vs 步长>1的卷积](#3. 池化 vs 步长>1的卷积)
- [4. 全局平均池化(GAP)](#4. 全局平均池化(GAP))
- 总结(核心关键点)
CNN局部感受野和权值共享
提出者与实验:1962年哈佛医学院神经生理学家Hubel和Wiesel通过猫视觉皮层细胞实验提出,该研究后来获得诺贝尔奖
实验发现:当给猫展示静态图像时视觉皮层细胞无反应,但在图像切换瞬间(如幻灯片翻页)会产生显著激活
生物学意义:揭示了视觉系统对动态刺激的敏感性,为理解视觉信息处理机制奠定基础
人工神经网络应用:1984年日本学者Fukushima基于该概念提出神经认知机(neocognitron),成为卷积神经网络的雏形
CNN 的局部感受野(Local Receptive Field) 和权值共享(Weight Sharing) 是其区别于全连接网络的两大核心设计,也是 CNN 能高效处理图像、避免参数爆炸的关键。下面我会用「通俗解释+原理+可视化+代码验证」的方式,帮你彻底理解这两个概念。
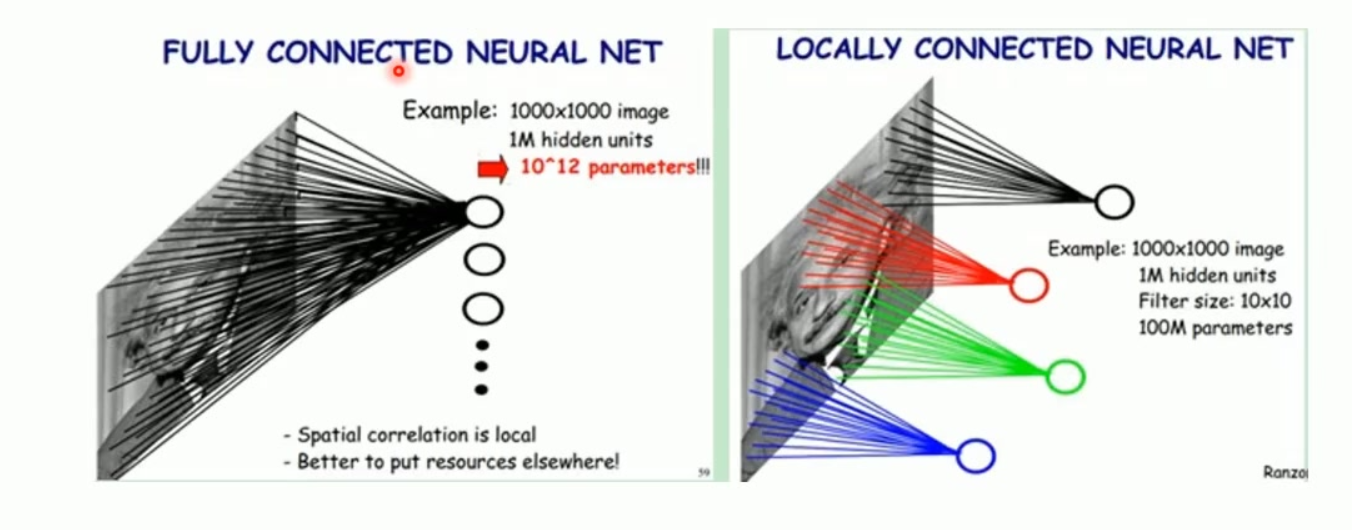
一、先搞懂:为什么全连接网络不适合图像?
在讲 CNN 的核心设计前,先对比全连接(FC)的问题,你就能明白 CNN 设计的初衷:
- 以 MNIST 28×28 图像为例,全连接层需要 784 个输入神经元 → 若隐藏层有 1000 个神经元,仅这一层就需要 784×1000 = 78.4 万个参数;
- 全连接层不考虑像素的空间关系(比如数字「8」的上下半圆是关联的,但全连接会把所有像素当成独立特征);
- 参数量爆炸 → 训练慢、易过拟合,且无法利用图像的空间结构。
CNN 正是通过「局部感受野」和「权值共享」解决了这两个问题。
二、局部感受野(Local Receptive Field):只看局部,不看全局
1. 通俗理解
把 CNN 的卷积核想象成你的「眼睛」:看一幅画时,你不会一次性看完整幅画,而是先看局部(比如一个人物的脸、一朵花),再把局部信息拼接成全局。
- 图像的空间特征是局部关联的(比如数字「5」的笔画是连续的局部像素),远处的像素几乎无关联;
- 卷积核只关注「局部区域」的像素,这个区域就是「局部感受野」。
2. 原理定义
- 感受野:卷积层中,一个输出神经元对应的输入图像的区域大小(单位:像素);
- 局部感受野:卷积核的尺寸决定了感受野的大小(比如 3×3 卷积核的感受野就是 3×3 像素)。
3. 直观示例(MNIST 28×28 图像)
| 卷积核尺寸 | 局部感受野 | 作用 |
|---|---|---|
| 3×3 | 3×3 像素 | 提取边缘、纹理等细粒度局部特征(如数字「1」的竖线) |
| 5×5 | 5×5 像素 | 提取稍大的局部特征(如数字「8」的半个圆环) |
| 7×7 | 7×7 像素 | 提取更宏观的局部特征(如数字「0」的完整轮廓) |
4. 关键特性
- 层级递进 :浅层卷积核感受野小(提取细节),深层卷积核感受野大(拼接细节成全局特征);
比如:2层 3×3 卷积的感受野 = 5×5(叠加效应),3层 3×3 卷积的感受野 = 7×7; - 参数减少:3×3 卷积核仅 9 个参数,而全连接层对应 9 个像素需要 N 个参数(N 为输出神经元数);
- 空间保留:卷积输出仍保留「高×宽」的空间结构(全连接会展平为一维,丢失空间信息)。
三、权值共享(Weight Sharing):一套参数,复用全局
1. 通俗理解
把卷积核的权重想象成「印章」:用同一个印章在图像的不同位置盖章,印章本身(权重)不变,只是盖章的位置不同 → 用同一套参数识别图像不同位置的相同特征。
- 比如:数字「1」的竖线可能出现在图像左侧、中间、右侧,用同一套 3×3 卷积核权重,就能识别所有位置的竖线;
- 若不用权值共享,每个位置的局部感受野都需要一套独立权重 → 参数量会暴涨。
2. 原理定义
- 权值共享:同一个卷积核在遍历图像所有位置时,使用完全相同的权重参数;
- 公式验证(单通道卷积):
o u t p u t ( i , j ) = ∑ m = 0 k h − 1 ∑ n = 0 k w − 1 i n p u t ( i + m , j + n ) × w e i g h t ( m , n ) + b i a s output(i,j) = \sum_{m=0}^{k_h-1}\sum_{n=0}^{k_w-1} input(i+m,j+n) \times weight(m,n) + bias output(i,j)=m=0∑kh−1n=0∑kw−1input(i+m,j+n)×weight(m,n)+bias
其中: w e i g h t ( m , n ) weight(m,n) weight(m,n) 是卷积核的固定权重,遍历 ( i , j ) (i,j) (i,j) 时始终不变。
3. 直观对比(参数数量)
以 MNIST 28×28 图像、3×3 卷积核、输出 32 个特征图为例:
- 使用权值共享:每个卷积核 3×3=9 个权重 + 1 个偏置 → 32 个卷积核总参数 = 32×(9+1) = 320 个;
- 不使用权值共享 :每个输出像素对应一套独立权重 → 输出特征图尺寸 26×26 → 总参数 = 32×26×26×9 = 191616 个;
→ 权值共享让参数减少 99.8%!
4. 核心价值
- 参数量暴减:避免过拟合,加快训练速度;
- 平移不变性:识别图像中「位置不同但特征相同」的内容(比如不同位置的数字「5」);
- 泛化能力提升:模型不依赖特征的绝对位置,更适应真实场景的图像变形。
四、局部感受野 + 权值共享:CNN 的黄金组合
1. 组合效果
| 设计 | 单独作用 | 组合作用 |
|---|---|---|
| 局部感受野 | 聚焦局部特征,保留空间结构 | 以极少的参数,高效提取图像的局部特征,并通过权值共享复用参数识别全局相同特征 |
| 权值共享 | 复用参数,减少计算量 | 让局部特征提取能力覆盖整个图像,同时避免参数爆炸 |
2. 可视化理解(MNIST 数字「5」)
输入图像:28×28 数字「5」
3×3 卷积核(局部感受野)
权值共享
遍历图像所有位置,提取所有位置的竖线/横线特征
输出特征图:保留「5」的局部特征空间结构
多层卷积叠加,感受野扩大,拼接成全局特征
最终识别数字「5」
3. 代码验证(查看 CNN 卷积核权重与感受野)
python
import tensorflow as tf
import matplotlib.pyplot as plt
# 构建简单CNN(MNIST)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1), name='conv1'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
# 查看卷积层权重(权值共享的体现)
conv1_weights = model.get_layer('conv1').get_weights()[0]
print(f"卷积核权重形状:{conv1_weights.shape}") # (3, 3, 1, 32) → 3×3 核,1输入通道,32输出通道
print(f"单个卷积核权重数量:{3*3} = 9 个(权值共享)")
# 可视化前8个卷积核的权重(权值共享的直观展示)
plt.figure(figsize=(12, 8))
for i in range(8):
kernel = conv1_weights[:, :, 0, i] # 取第i个卷积核的权重
plt.subplot(2, 4, i+1)
plt.imshow(kernel, cmap='gray')
plt.title(f"Conv Kernel {i+1}")
plt.axis('off')
plt.suptitle('卷积核权重(权值共享:同一核复用全局)')
plt.show()
# 计算感受野(浅层→深层)
def calculate_receptive_field(layer_configs):
"""计算各层感受野大小"""
rf = 1 # 初始感受野(输入像素)
stride = 1
for layer in layer_configs:
if layer['type'] == 'conv' or layer['type'] == 'pool':
rf = rf + (layer['kernel_size'] - 1) * stride
stride *= layer['stride']
return rf
# 示例:2层卷积的感受野
layer_configs = [
{'type': 'conv', 'kernel_size': 3, 'stride': 1},
{'type': 'pool', 'kernel_size': 2, 'stride': 2},
{'type': 'conv', 'kernel_size': 3, 'stride': 1}
]
rf = calculate_receptive_field(layer_configs)
print(f"\n3层后的感受野大小:{rf}×{rf} 像素") # 输出 7×7 像素(叠加效应)代码输出说明
- 卷积核权重形状为
(3,3,1,32)→ 32 个卷积核,每个核仅 9 个权重(权值共享的直接体现); - 感受野计算结果:多层卷积叠加后,感受野从 3×3 扩大到 7×7 → 深层能捕捉更大的局部特征。
五、新手常见误区
- 感受野越大越好?
否!浅层需要小感受野(提取细节),深层需要大感受野(拼接全局),3×3 是最优平衡(多个 3×3 卷积叠加 ≈ 大卷积核,但参数更少); - 权值共享适用于所有场景?
否!若图像不同区域的特征差异极大(如医学图像的局部病变),可使用「分组卷积」或「空洞卷积」调整权值共享策略; - 感受野 = 卷积核尺寸?
否!感受野是「输出神经元对应的输入区域」,多层卷积后感受野会叠加扩大(比如 2 层 3×3 卷积的感受野 = 5×5)。
总结
- 局部感受野:CNN 只关注图像的局部区域(卷积核尺寸),利用图像的局部关联性,保留空间结构,减少无效计算;
- 权值共享:同一卷积核的权重在图像所有位置复用,大幅减少参数量,实现「平移不变性」;
- 核心价值:两者结合让 CNN 以极少的参数高效处理图像,既保留空间特征,又避免过拟合,是 CNN 超越全连接网络的关键。
这两个设计也是 CNN 能在图像识别、目标检测等任务中脱颖而出的根本原因,理解它们就能抓住 CNN 的核心逻辑。
卷积计算
卷积(Convolution)是 CNN 的核心运算,理解它的计算过程是掌握 CNN 的关键。下面我会从「直观理解→手动计算→公式推导→代码验证→实战注意事项」一步步拆解,用 MNIST 28×28 图像的实际例子,让你彻底搞懂卷积的计算逻辑。
一、先建立直观认知:卷积到底在做什么?
卷积的本质是用一个「卷积核(Kernel/Filter)」在输入图像上「滑动」,逐位置做「元素相乘后求和」 ,最终输出特征图(Feature Map)。
卷积核与特征图
基本概念:卷积核(又称滤波器或卷积窗口)是一个用于特征提取的矩阵,常见尺寸有3×3、5×5、7×7等
特征图生成:通过卷积核在图像上滑动计算得到的输出矩阵称为特征图(feature map),其每个元素是局部区域与卷积核的加权和
可以把这个过程类比成:
- 输入图像 = 一张布满数字的格子纸;
- 卷积核 = 一个小尺子(比如 3×3),尺子上标了权重数字;
- 卷积计算 = 把尺子贴在格子纸的某个位置,对应位置数字相乘后求和 → 得到一个结果;
- 滑动尺子 = 逐行逐列移动尺子,重复上述计算 → 所有结果组成新的格子纸(特征图)。
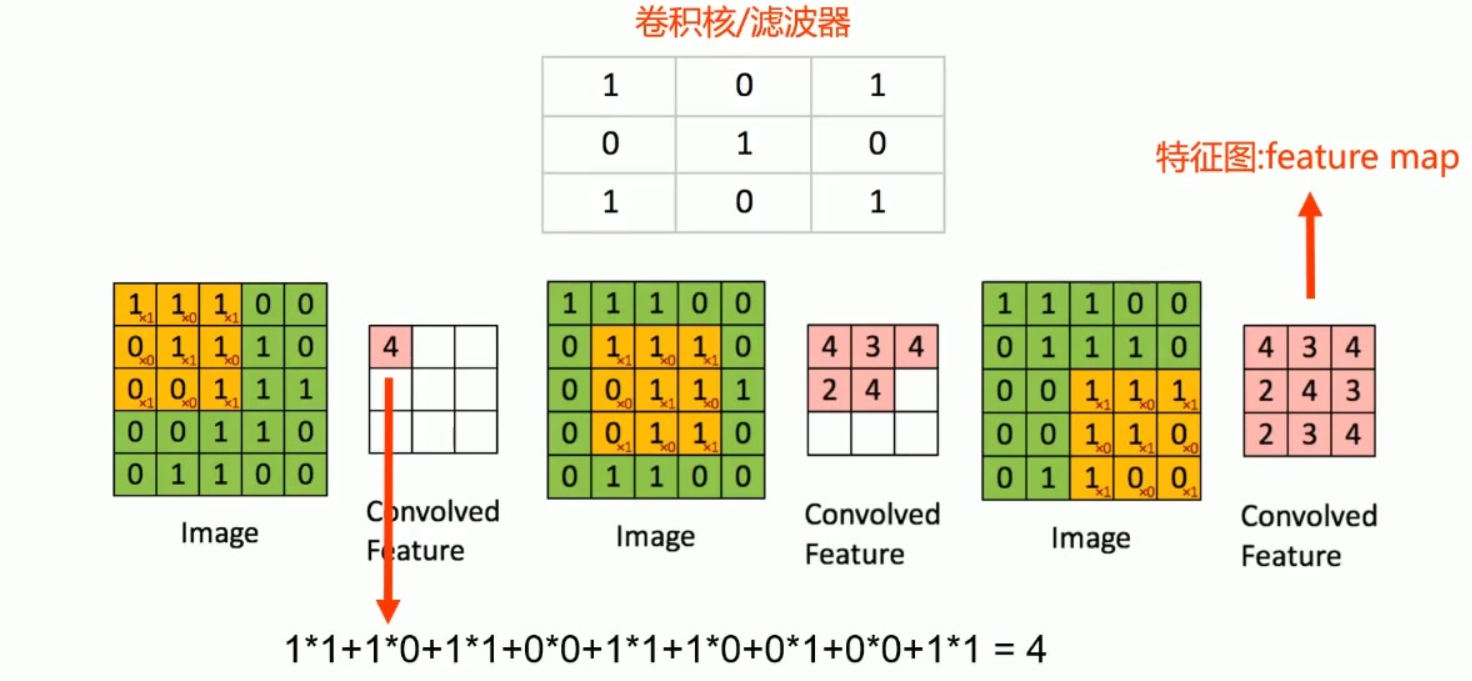
计算规则:对应位置元素相乘后求和,例如
1 ∗ 1 + 1 ∗ 0 + 1 ∗ 1 + 0 ∗ 0 + 1 ∗ 1 + 1 ∗ 0 + 0 ∗ 1 + 0 ∗ 0 + 1 ∗ 1 = 4 1^{ * }1 + 1^{ * }0 + 1^{ * }1 + 0^{ * }0 + 1^{ * }1 + 1^{ * }0 + 0^{ * }1 + 0^{ * }0 + 1^{ * }1 = 4 1∗1+1∗0+1∗1+0∗0+1∗1+1∗0+0∗1+0∗0+1∗1=4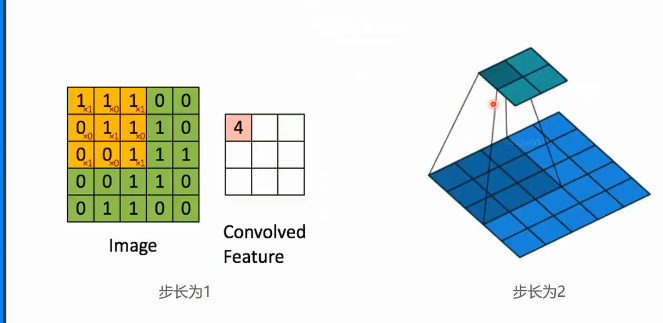
滑动方式:从左上角开始,先向右移动(步长决定移动距离),到达边界后向下移动一行,重复该过程直至覆盖整个图像
步长定义:卷积核每次移动的像素距离
影响规律:
步长=1:每次移动1格,特征图尺寸较大(如输入5×5→输出3×3)
步长=2:每次移动2格,特征图尺寸减半(如输入5×5→输出2×2)
步长越大,特征图尺寸越小
滤波器与特征提取
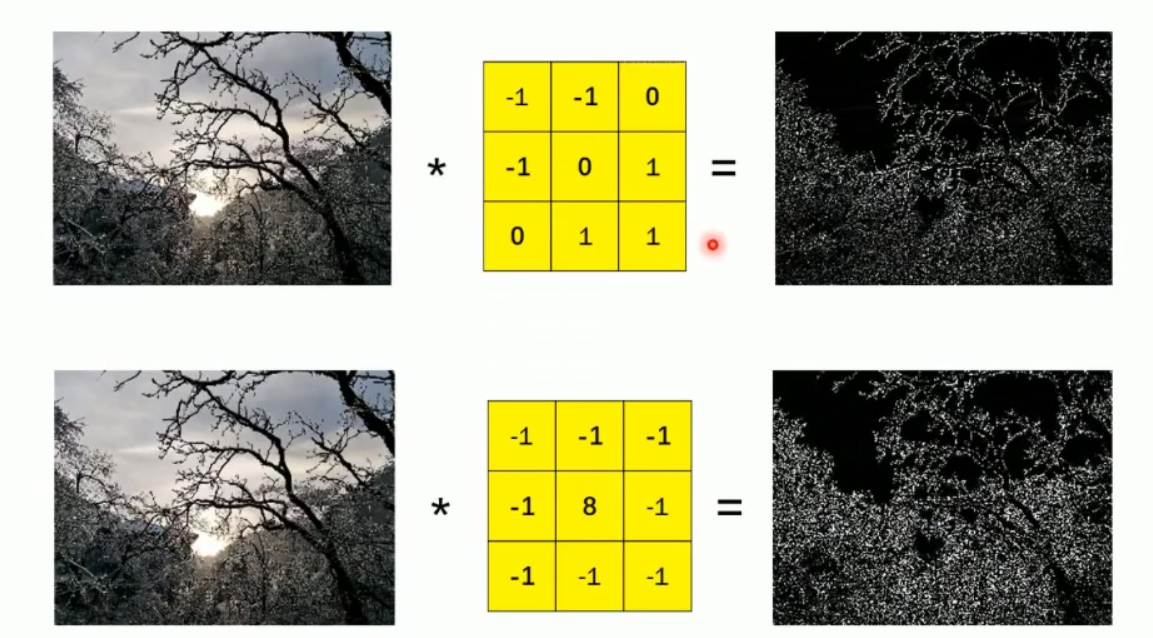
功能本质:卷积核作为滤波器可提取不同图像特征
实例说明:
使用-1 -1 0; -1 0 1滤波器得到特定特征图
使用-1 -1 -1; -1 8 -1滤波器得到边缘更突出的结果
核心原理:不同权值组合能捕获亮度变化、边缘等不同视觉特征
卷积核的设计与训练
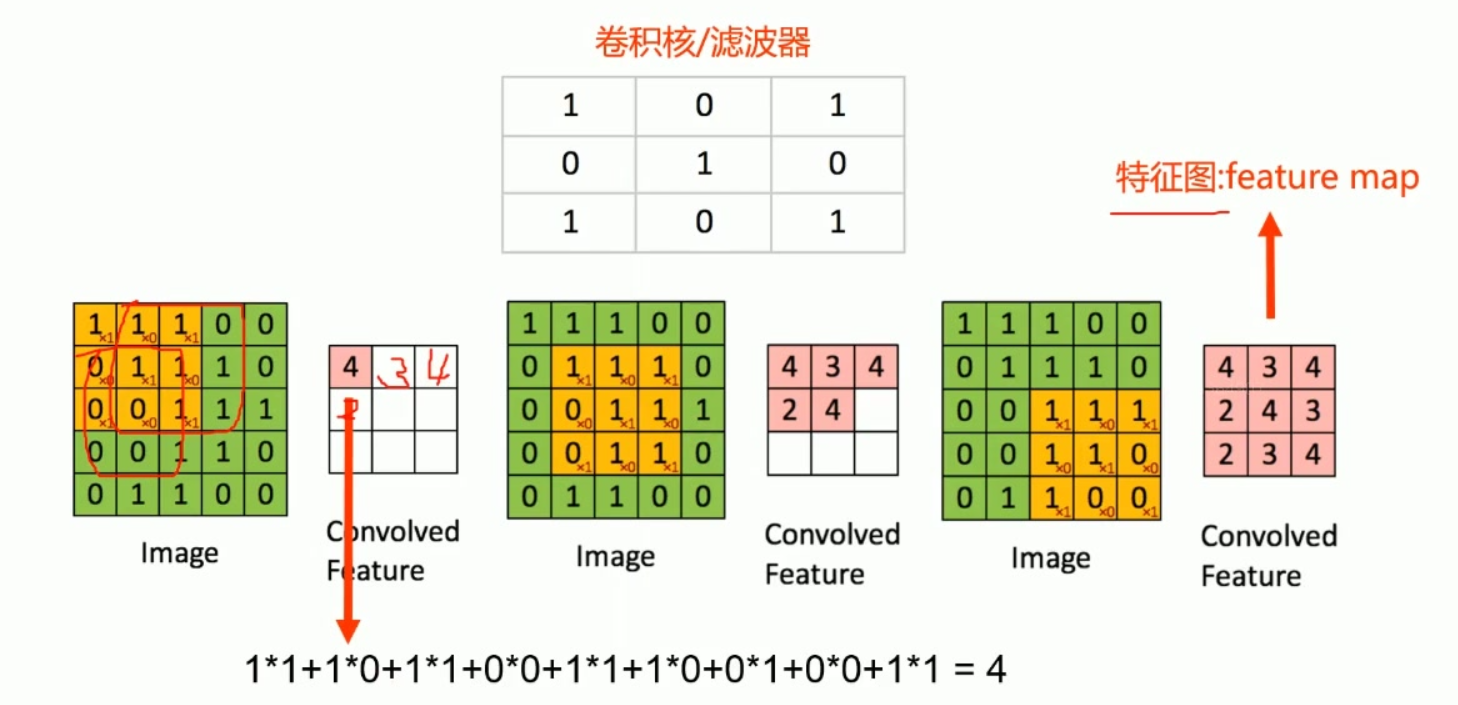
参数本质:卷积核元素即网络权重参数(w0到w8)
训练方法:
初始化为随机值
通过反向传播算法自动优化
最终获得具有特征提取能力的滤波器
优势:无需人工设计,模型自动学习最优特征提取方式
多个卷积核的使用
必要性:单个卷积核只能提取特定特征,多个卷积核可捕获更丰富的特征组合
实现方式:
同一卷积层包含多个不同卷积核
每个核生成独立的特征图
最终将所有特征图堆叠形成多维特征表示
典型应用:深层CNN中常使用64/128/256个卷积核同时工作
二、手动计算:单通道卷积(最基础,MNIST 场景)
MNIST 图像是单通道灰度图(28×28×1),先以简化的 5×5 输入、3×3 卷积核为例,手动计算卷积过程,步骤清晰无冗余。
步骤 1:定义输入和卷积核
-
输入(Input) :5×5 单通道矩阵(模拟 MNIST 图像的局部区域):
python[ [1, 0, 1, 0, 1], [0, 1, 0, 1, 0], [1, 0, 1, 0, 1], [0, 1, 0, 1, 0], [1, 0, 1, 0, 1] ] -
卷积核(Kernel) :3×3 单通道权重矩阵(提取「边缘」特征):
python[ [1, 0, -1], [1, 0, -1], [1, 0, -1] ] -
超参数:步长(Stride)=1(每次滑动1个像素),填充(Padding)=0(无填充,边缘不补0)。
步骤 2:滑动卷积核,逐位置计算
位置 1:卷积核覆盖输入的 (0,0)~(2,2) 区域
python
输入区域 卷积核 元素相乘 求和
1 0 1 1 0 -1 1×1 + 0×0 + 1×(-1) = 0
0 1 0 1 0 -1 0×1 + 1×0 + 0×(-1) = 0
1 0 1 1 0 -1 1×1 + 0×0 + 1×(-1) = 0
总和 = 0+0+0 = 0位置 2:卷积核向右滑动1格,覆盖 (0,1)~(2,3) 区域
输入区域 卷积核 元素相乘 求和
0 1 0 1 0 -1 0×1 + 1×0 + 0×(-1) = 0
1 0 1 1 0 -1 1×1 + 0×0 + 1×(-1) = 0
0 1 0 1 0 -1 0×1 + 1×0 + 0×(-1) = 0
总和 = 0+0+0 = 0位置 3:卷积核继续滑动,直到覆盖所有有效区域
最终,5×5 输入 + 3×3 卷积核 + Stride=1 + Padding=0 → 输出特征图尺寸为 3×3 (计算方式: ( 5 − 3 ) / 1 + 1 = 3 (5-3)/1 + 1 = 3 (5−3)/1+1=3)。
步骤 3:最终特征图
[
[0, 0, 6],
[0, 0, 6],
[0, 0, 6]
](注:最后一列计算结果为6,因为输入最后一列是 1/0/1/0/1,与卷积核相乘求和后得到6,体现「边缘特征」的提取效果)。
三、公式推导:卷积计算的通用规则
1. 核心公式(单通道)
对于输入 X X X(尺寸 H × W H×W H×W)、卷积核 K K K(尺寸 k h × k w k_h×k_w kh×kw)、步长 s s s、填充 p p p,输出特征图 Y Y Y 的每个元素计算为:
Y ( i , j ) = ∑ m = 0 k h − 1 ∑ n = 0 k w − 1 X ( i × s + m − p , j × s + n − p ) × K ( m , n ) + b Y(i,j) = \sum_{m=0}^{k_h-1}\sum_{n=0}^{k_w-1} X(i×s+m-p, j×s+n-p) × K(m,n) + b Y(i,j)=m=0∑kh−1n=0∑kw−1X(i×s+m−p,j×s+n−p)×K(m,n)+b
- i , j i,j i,j:输出特征图的坐标;
- m , n m,n m,n:卷积核的坐标;
- b b b:偏置项(可选,通常每个卷积核对应1个偏置);
- 填充 p p p:为了保持输入输出尺寸一致,常在输入边缘补0(比如 Padding=1 时,5×5 输入补0后变为7×7)。
2. 输出尺寸计算公式(重中之重)
输出高度 = H − k h + 2 × p s + 1 \text{输出高度} = \frac{H - k_h + 2×p}{s} + 1 输出高度=sH−kh+2×p+1
输出宽度 = W − k w + 2 × p s + 1 \text{输出宽度} = \frac{W - k_w + 2×p}{s} + 1 输出宽度=sW−kw+2×p+1
实战示例(MNIST 28×28 图像)
- 输入:28×28×1;
- 卷积核:3×3×1,Stride=1,Padding=1;
- 输出尺寸: ( 28 − 3 + 2 × 1 ) / 1 + 1 = 28 (28-3+2×1)/1 +1 = 28 (28−3+2×1)/1+1=28 → 输出 28×28×C(C 为卷积核数量)。
3. 多通道卷积(彩色图像场景)
若输入是 RGB 彩色图(3通道,如 28×28×3),卷积核需与输入通道数一致(3×3×3),计算逻辑:
- 每个通道的输入与卷积核对应通道做「元素相乘求和」;
- 所有通道的结果相加 → 得到一个值;
- 加上偏置 → 输出特征图的一个像素。
注:若有 N 个卷积核,输出通道数就是 N(比如 32 个卷积核 → 输出 28×28×32)。
四、代码验证:用 TensorFlow 复现卷积计算
用代码验证上述手动计算的结果,同时展示 MNIST 实际场景的卷积计算:
python
import tensorflow as tf
import numpy as np
# ===================== 1. 验证手动计算的单通道卷积 =====================
# 定义5×5输入(单通道)
input_data = np.array([
[1, 0, 1, 0, 1],
[0, 1, 0, 1, 0],
[1, 0, 1, 0, 1],
[0, 1, 0, 1, 0],
[1, 0, 1, 0, 1]
], dtype=np.float32).reshape(1, 5, 5, 1) # 形状:(批次, 高, 宽, 通道)
# 定义3×3卷积核(单通道)
kernel = np.array([
[1, 0, -1],
[1, 0, -1],
[1, 0, -1]
], dtype=np.float32).reshape(3, 3, 1, 1) # 形状:(核高, 核宽, 输入通道, 输出通道)
# 执行卷积运算(Stride=1,Padding=0)
conv_result = tf.nn.conv2d(
input=input_data,
filters=kernel,
strides=[1, 1, 1, 1], # 批次/高/宽/通道 步长,通常批次和通道为1
padding='VALID' # VALID=无填充,SAME=填充至输入输出尺寸一致
)
# 打印结果(与手动计算对比)
print("手动计算的特征图:")
print(np.array([[0,0,6],[0,0,6],[0,0,6]]))
print("\nTensorFlow 卷积结果:")
print(conv_result.numpy().squeeze()) # squeeze() 去掉维度为1的轴
# ===================== 2. MNIST 实际场景的卷积计算 =====================
# 加载MNIST数据
(x_train, _), (_, _) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_train = x_train[0:1][..., tf.newaxis] # 取第一个样本,形状:(1,28,28,1)
# 定义MNIST的卷积层(32个3×3卷积核,Padding=1,Stride=1)
conv_layer = tf.keras.layers.Conv2D(
filters=32, # 卷积核数量=输出通道数
kernel_size=(3, 3),
strides=(1, 1),
padding='SAME', # 填充至输出尺寸=输入尺寸
activation='relu'
)
# 执行卷积
conv_output = conv_layer(x_train)
print(f"\nMNIST 卷积输入尺寸:{x_train.shape}") # (1,28,28,1)
print(f"MNIST 卷积输出尺寸:{conv_output.shape}") # (1,28,28,32) → 28×28不变,通道数=32
# 查看卷积核参数
kernel_params = conv_layer.get_weights()[0]
bias_params = conv_layer.get_weights()[1]
print(f"卷积核参数形状:{kernel_params.shape}") # (3,3,1,32) → 3×3核,1输入通道,32输出通道
print(f"偏置参数形状:{bias_params.shape}") # (32,) → 每个卷积核1个偏置代码输出说明
- 手动计算的卷积结果与 TensorFlow 输出完全一致,验证了计算逻辑的正确性;
- MNIST 场景中,
padding='SAME'保证卷积后尺寸仍为 28×28,32 个卷积核输出 32 通道特征图; - 卷积核参数形状为
(3,3,1,32),对应 32 个 3×3 单通道卷积核(权值共享的体现)。
五、实战关键注意事项(新手避坑)
1. Padding 选择
VALID:无填充,输出尺寸缩小(如 28×28 → 26×26),适合需要降维的场景;SAME:填充0至输出尺寸=输入尺寸,适合需要保留空间信息的场景(MNIST 常用)。
2. Stride 调整
- Stride=1:默认值,滑动1像素,输出尺寸最大;
- Stride>1:滑动多像素,输出尺寸缩小(如 Stride=2 时,28×28 → 14×14),替代池化层实现降维。
3. 多通道 vs 多卷积核
- 输入通道数:必须与卷积核的「输入通道数」一致(如 RGB 图3通道 → 卷积核3通道);
- 卷积核数量:决定输出通道数(如 32 个卷积核 → 输出32通道),数量越多,提取的特征越丰富。
4. 卷积的反向传播
- 训练时,梯度会通过卷积的反向运算更新卷积核权重;
- 核心逻辑:损失函数对输出特征图的梯度 → 反向计算对卷积核权重和输入的梯度 → 梯度下降更新权重。
总结(核心关键点)
- 卷积计算本质:卷积核滑动 + 逐位置元素相乘求和 + 可选偏置;
- 核心公式 :输出尺寸 = ( 输入尺寸 − 核尺寸 + 2 × 填充 ) / 步长 + 1 (输入尺寸 - 核尺寸 + 2×填充)/步长 + 1 (输入尺寸−核尺寸+2×填充)/步长+1;
- 实战规则 :
- 单通道(MNIST):卷积核通道数=1,输出通道数=卷积核数量;
SAME填充保留尺寸,VALID填充缩小尺寸;- Stride>1 可实现降维,减少后续计算量。
理解卷积计算后,你就能明白 CNN 如何通过「局部感受野+权值共享+卷积运算」高效提取图像特征,这也是 CNN 超越全连接网络的核心原因。
图解(https://www.bilibili.com/video/BV1x44y1P7s2?t=1.6)
池化操作
一、先搞懂:为什么需要池化?
卷积层输出的特征图仍保留了大量空间信息(比如 28×28×32),直接送入全连接层会导致:
- 参数量过大(28×28×32 = 25088 个特征 → 全连接层1000神经元需要 25088×1000 = 2500万+ 参数);
- 特征图中的微小位置变化(如数字「5」的笔画偏移1像素)会影响模型判断;
- 计算效率低,训练慢、易过拟合。
池化的核心目标:在保留关键特征的前提下,压缩特征图的尺寸,同时增强模型对特征位置变化的鲁棒性。
二、池化的直观理解
把池化想象成「拍照放大后再缩小」:
- 你拍了一张高清照片(卷积后的特征图),里面有很多细节;
- 缩小照片(池化)后,细节减少,但核心内容(比如数字的轮廓)依然清晰;
- 即使照片里的主体稍微偏移(比如数字位置偏1像素),缩小后依然能识别 → 这就是「平移不变性」。
池化的本质:对特征图的局部区域做「聚合统计」(取最大值/平均值),用一个值代表该区域的整体特征 。
常用方式:卷积层后通常会接池化层,主要有三种方式:
最大池化(max-pooling)
平均池化(mean-pooling)
随机池化(stochastic pooling)
窗口参数:最常用的是2×2窗口,步长为2的配置
操作特点:与卷积类似具有滑动窗口机制,但计算方式不同
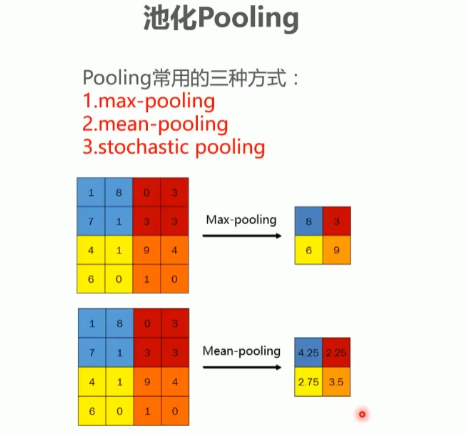
最大池化和平均池化计算示例
最大池化过程:
对2×2窗口取最大值
示例:窗口8,3;4,1→取最大值8
步长2滑动得到新特征图8,3;6,9
平均池化过程:
对2×2窗口取平均值
示例:窗口8,3;4,1→计算平均值(8+3+4+1)/4=4
步长2滑动得到新特征图4,2.25;2.75,3.5
输出名称:池化结果仍称为特征图(feature map)
池化操作的理解与作用
核心功能:
特征压缩:将16×16特征图降采样为4×4
特征选择:保留最显著特征(如最大池化保留最大值)
设计目的:
控制参数增长:防止卷积层输出特征数量爆炸
计算效率:减少后续计算量
特征提取逻辑:数值越大通常代表特征越重要,池化可看作二次特征筛选
池化操作的平移不变性
概念解释:
对目标位置变化不敏感(如数字"2"在图像左/中/右位置)
输出特征保持相似性
实际效果:
缓解位置敏感性,但非完全消除
提升分类器对空间变化的鲁棒性
应用场景:特别适合手写数字识别等需要位置不变性的任务
padding操作
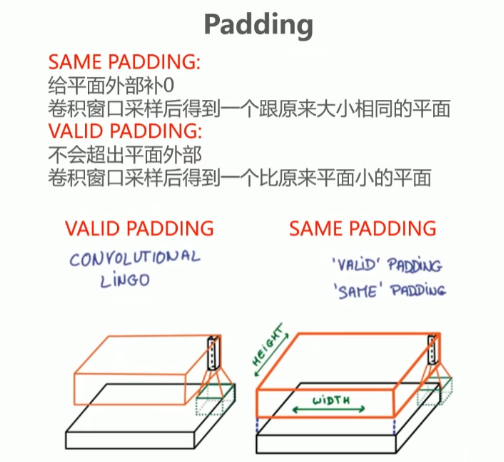
实现方式:在图像外围补零(zero-padding)
输出特性:
保持输入输出尺寸相同
补零圈数根据卷积核大小动态计算
适用场景:需要保持特征图尺寸不变的网络结构
VALID PADDING操作详解
核心原则:不进行任何边界填充
输出特性:
输出尺寸必然小于输入
尺寸缩减量取决于卷积核大小
计算特点:仅在完整覆盖输入区域时进行计算
例子

SAME演示:
蓝色原始图像→红色特征图尺寸不变
通过外围补零实现
VALID演示:
蓝色原始图像→绿色特征图尺寸缩小
无外围扩展
例题2:28×28平面卷积/池化操作
操作参数:
输入:28×28平面
窗口:2×2,步长2
结果分析:
SAME/VALID输出均为14×14
原因:28能被2整除,无需补零
例题3:2×3平面卷积/池化操作
操作参数:
输入:2×3平面
窗口:2×2,步长2
结果对比:
SAME PADDING:输出1×2(自动补零)
VALID PADDING:输出1×1(舍弃不完整区域)
关键结论:步长>1时SAME可能补零,VALID必然缩小输出
总结:
池化(Pooling)是 CNN 中仅次于卷积的核心操作,也叫「下采样(Downsampling)」,核心作用是降维、减少参数、增强鲁棒性。下面我会从「直观理解→核心类型→手动计算→代码验证→实战价值」一步步拆解,结合 MNIST 场景讲透池化的本质和用法。
三、池化的核心类型(实战中99%用这两种)
1. 最大池化(Max Pooling):保留显著特征(最常用)
定义
对特征图的局部区域(池化窗口)取最大值,代表该区域的核心特征(比如边缘、纹理的最强响应)。
适用场景
- 图像分类(MNIST、ImageNet):保留关键特征,抑制噪声;
- 目标检测:保留物体的轮廓和关键纹理。
2. 平均池化(Average Pooling):保留整体特征
定义
对特征图的局部区域取平均值,代表该区域的整体强度。
适用场景
- 语义分割:需要保留区域的整体信息;
- 模型最后一层:替代全连接层(Global Average Pooling)。
3. 其他类型(极少用)
- 求和池化:局部区域求和,效果接近平均池化;
- 自适应池化:自动调整池化窗口尺寸,输出固定尺寸(如不管输入多大,输出7×7)。
四、手动计算:池化的核心步骤(以最大池化为例)
以 MNIST 卷积后的 4×4 特征图、2×2 池化窗口、步长=2、无填充为例,手动计算最大池化过程:
步骤 1:定义输入特征图(卷积后的输出)
python
[
[1, 3, 2, 4],
[5, 7, 6, 8],
[9, 11, 10, 12],
[13, 15, 14, 16]
]步骤 2:设置池化超参数
- 池化窗口(Kernel Size):2×2;
- 步长(Stride):2(窗口每次滑动2像素);
- 填充(Padding):0(无填充)。
步骤 3:滑动池化窗口,逐区域取最大值
区域 1:(0,0)~(1,1)
python
[1,3]
[5,7] → 最大值=7区域 2:(0,2)~(1,3)
python
[2,4]
[6,8] → 最大值=8区域 3:(2,0)~(3,1)
python
[9,11]
[13,15] → 最大值=15区域 4:(2,2)~(3,3)
python
[10,12]
[14,16] → 最大值=16步骤 4:输出池化后的特征图
python
[
[7, 8],
[15, 16]
]关键:池化输出尺寸计算
和卷积的尺寸计算公式完全一致 :
输出尺寸 = 输入尺寸 − 池化窗口尺寸 + 2 × 填充 步长 + 1 \text{输出尺寸} = \frac{\text{输入尺寸} - \text{池化窗口尺寸} + 2×\text{填充}}{\text{步长}} + 1 输出尺寸=步长输入尺寸−池化窗口尺寸+2×填充+1
示例中: ( 4 − 2 ) / 2 + 1 = 2 (4-2)/2 +1 = 2 (4−2)/2+1=2 → 输出 2×2 特征图(输入4×4 → 降维50%)。
五、代码验证:用 TensorFlow 实现池化
结合 MNIST 场景,验证最大池化/平均池化的计算逻辑,以及池化在 CNN 中的实际应用:
python
import tensorflow as tf
import numpy as np
# ===================== 1. 验证手动计算的最大池化 =====================
# 定义4×4输入特征图(单通道,模拟卷积输出)
input_data = np.array([
[1, 3, 2, 4],
[5, 7, 6, 8],
[9, 11, 10, 12],
[13, 15, 14, 16]
], dtype=np.float32).reshape(1, 4, 4, 1) # 形状:(批次, 高, 宽, 通道)
# 执行最大池化(2×2窗口,步长2,无填充)
max_pool = tf.keras.layers.MaxPooling2D(
pool_size=(2, 2),
strides=(2, 2),
padding='VALID'
)(input_data)
# 执行平均池化(对比效果)
avg_pool = tf.keras.layers.AveragePooling2D(
pool_size=(2, 2),
strides=(2, 2),
padding='VALID'
)(input_data)
# 打印结果
print("手动计算的最大池化结果:")
print(np.array([[7,8],[15,16]]))
print("\nTensorFlow 最大池化结果:")
print(max_pool.numpy().squeeze())
print("\nTensorFlow 平均池化结果:")
print(avg_pool.numpy().squeeze()) # 平均池化结果:[[4,5],[12,13]]
# ===================== 2. MNIST 实战:池化在CNN中的应用 =====================
# 加载MNIST数据
(x_train, _), (_, _) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_train = x_train[0:1][..., tf.newaxis] # 形状:(1,28,28,1)
# 构建包含卷积+池化的CNN
model = tf.keras.Sequential([
# 卷积层:32个3×3核,SAME填充,输出28×28×32
tf.keras.layers.Conv2D(32, (3,3), padding='SAME', activation='relu', input_shape=(28,28,1)),
# 最大池化:2×2窗口,步长2,输出14×14×32(降维50%)
tf.keras.layers.MaxPooling2D((2,2), strides=2, padding='SAME'),
# 第二层卷积:64个3×3核,输出14×14×64
tf.keras.layers.Conv2D(64, (3,3), padding='SAME', activation='relu'),
# 第二层池化:输出7×7×64
tf.keras.layers.MaxPooling2D((2,2), strides=2, padding='SAME'),
# 展平:7×7×64 = 3136 维
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
# 打印各层输出尺寸
model.build(input_shape=(None, 28, 28, 1))
for layer in model.layers:
print(f"\n{layer.name} 输出尺寸:{layer.output_shape}")
# 输出说明:
# Conv2D: (None, 28, 28, 32)
# MaxPooling2D: (None, 14, 14, 32)
# Conv2D_1: (None, 14, 14, 64)
# MaxPooling2D_1: (None, 7, 7, 64)
# Flatten: (None, 3136)
# Dense: (None, 10)代码输出说明
- 手动计算的最大池化结果与 TensorFlow 完全一致,验证了计算逻辑;
- 平均池化结果更「平滑」,但最大池化能突出关键特征(实战中 MNIST 用最大池化准确率更高);
- MNIST 场景中,两次池化将特征图从 28×28 压缩到 7×7,参数量从 28×28×32=25088 降至 7×7×64=3136,大幅减少后续计算量。
六、池化的核心价值(新手必懂)
1. 降维减参
- 池化是 CNN 中最主要的降维手段(步长2的2×2池化直接将特征图面积缩小75%);
- 减少全连接层的参数量,避免过拟合,加快训练速度。
2. 增强鲁棒性(平移/缩放不变性)
- 平移不变性:特征在局部区域内的微小偏移(如数字「5」的笔画偏1像素),池化后仍能提取相同特征;
- 缩放不变性:池化后特征图缩小,模型对输入图像的缩放变化更不敏感。
3. 保留关键特征
- 最大池化:保留局部区域的「最强响应」(如边缘、纹理的关键像素);
- 平均池化:保留局部区域的「整体强度」(如背景的平均亮度)。
4. 防止过拟合
- 降维减少了模型的参数数量,降低了模型的复杂度;
- 池化相当于对特征做「抽象」,避免模型过度关注细节噪声。
七、实战避坑指南
1. 池化窗口选择
- 优先用 2×2 窗口(最平衡:降维效果好,且不丢失关键特征);
- 避免用 3×3 以上窗口(易丢失过多特征,MNIST 中 3×3 池化会导致准确率下降)。
2. Padding 选择
VALID:无填充,降维更明显(常用);SAME:填充0至输出尺寸=输入尺寸/步长(如 28×28 → 14×14),保留边缘特征。
3. 池化 vs 步长>1的卷积
- 两者都能降维,但池化无参数(纯统计操作),卷积有参数(可学习特征);
- 实战中:先用卷积提取特征,再用池化降维(最优组合)。
4. 全局平均池化(GAP)
- 替代全连接层的高级用法:将最后一层特征图(如 7×7×64)做全局平均池化 → 输出 64 维向量(每个通道取平均值);
- 优点:无参数,避免过拟合,增强可解释性(MNIST 中可替代 Flatten+Dense)。
总结(核心关键点)
- 池化本质:对特征图局部区域做聚合统计(最大/平均),实现降维;
- 核心公式:输出尺寸 = (输入尺寸 - 池化窗口 + 2×填充)/步长 + 1;
- 实战价值 :
- 降维减参,加快训练,防止过拟合;
- 增强平移/缩放不变性,提升模型鲁棒性;
- 最大池化优先用于图像分类(如 MNIST),平均池化用于语义分割/全局特征提取。
池化和卷积是 CNN 的「黄金搭档」:卷积提取特征,池化压缩特征,两者结合让 CNN 既能高效提取图像特征,又能控制模型复杂度,是 MNIST 等图像分类任务的核心设计。