之前在揭秘Transformer架构设计 2(补全版) 聊到Prompt(提示词),本章根据案例以及实际上会用到的工具,给大家简单聊下Prompt(提示词) 、RAG(检索增强生成) 、向量知识库。
Prompt(提示词)
当我们看到这个:
用户在输入框内输入信息,这个信息就是Prompt(提示词),也叫用户的Query。
Query分类:
-
上下文依赖型 Query:保修多久?还有其他颜色吗?
-
对比型 Query:哪个保修时间更长?
-
模糊指代型 Query:都支持无线充电吗?
-
多意图型 Query:有几个颜色?尺码齐全吗?大概什么时候能到货?
-
反问型 Query:这不会也得等一个月吧?
-
条件型 Query:有没有500元以下的、适合女生用的那种?
Prompt 是我们唯一可以和 LLM模型 打交道的方式!
在应用技术层,无论我们做了多么炫酷的设计,最终都是为了传递适合的 Prompt 给 LLM模型(豆包、星火、千问、kimi等大模型)。
怎么写好Prompt(提示词):
写Prompt(提示词),本质上就是在带实习生。你是老板,模型是你的新员工。
你不能只丢下一句"去做个PPT"就不管了------你得把任务拆清楚:第一步做什么,第二步做什么,每一步要达到什么标准。最重要的是,你得扔给他几个优秀的案例,告诉他:"照着这个路数做,别自己瞎发挥"。
Prompt(提示词)写得好不好,就看你会不会当这个'老板'------指令清晰、步骤明确、案例到位,LLM模型就不会给你惊喜。
提示词:应用层的技术,都是为了拼出一条合适的 Prompt
首先用好Prompt(提示词) 是快速使用AI(LLM模型 )的第一步,也是能快速看到显著结果的一步。
我们要怎么写好一个Prompt(提示词) 很关键,Prompt(提示词)到底做了什么,为什么它是第一步,也是最关键的一步? 只有了解Prompt(提示词) 的原理,大家再返回过来看这些问题,就简单很多。
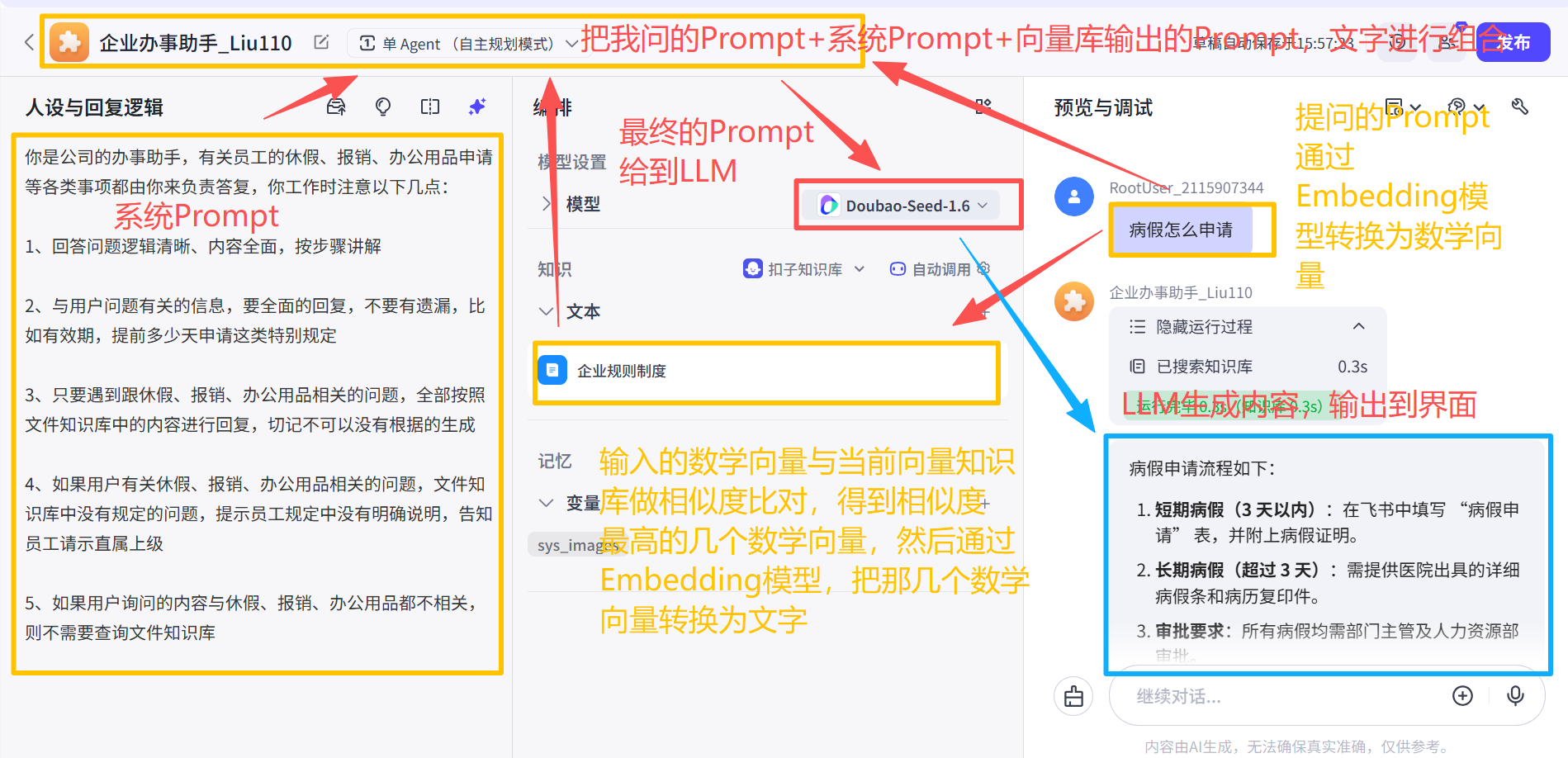
一般来说,一个最终的Prompt 是由3块内容组成:用户Prompt(用户的Query)、系统Prompt、检索向量知识库后的Prompt:
- 用户Prompt是,用户当时提到的问题;
- 提前写好的系统Prompt(通用要求,背景、身份设定、限制条件);
- 把用户Prompt 在知识库进行检索,找到与用户当下问题最相关的几个切片信息,就叫检索向量知识库后的Prompt。
3个板块的信息组合在一起,就拼接成一大段文字,这段文字就是你最终想要得到的Prompt
最终得到的Prompt就可以给到LLM模型(Deepseep、豆包、通义千问、kimi等等)。
LLM模型就会生成回复,回复的文案就会呈现到用户面前。
用户的Prompt
用户的Prompt,也叫做用户提出的问题,简称用户Query。
系统Prompt
系统Prompt的内容有:
- 身份设定
- 背景设定
- 参考资料
- 样例
- 指令
- 限制条件等
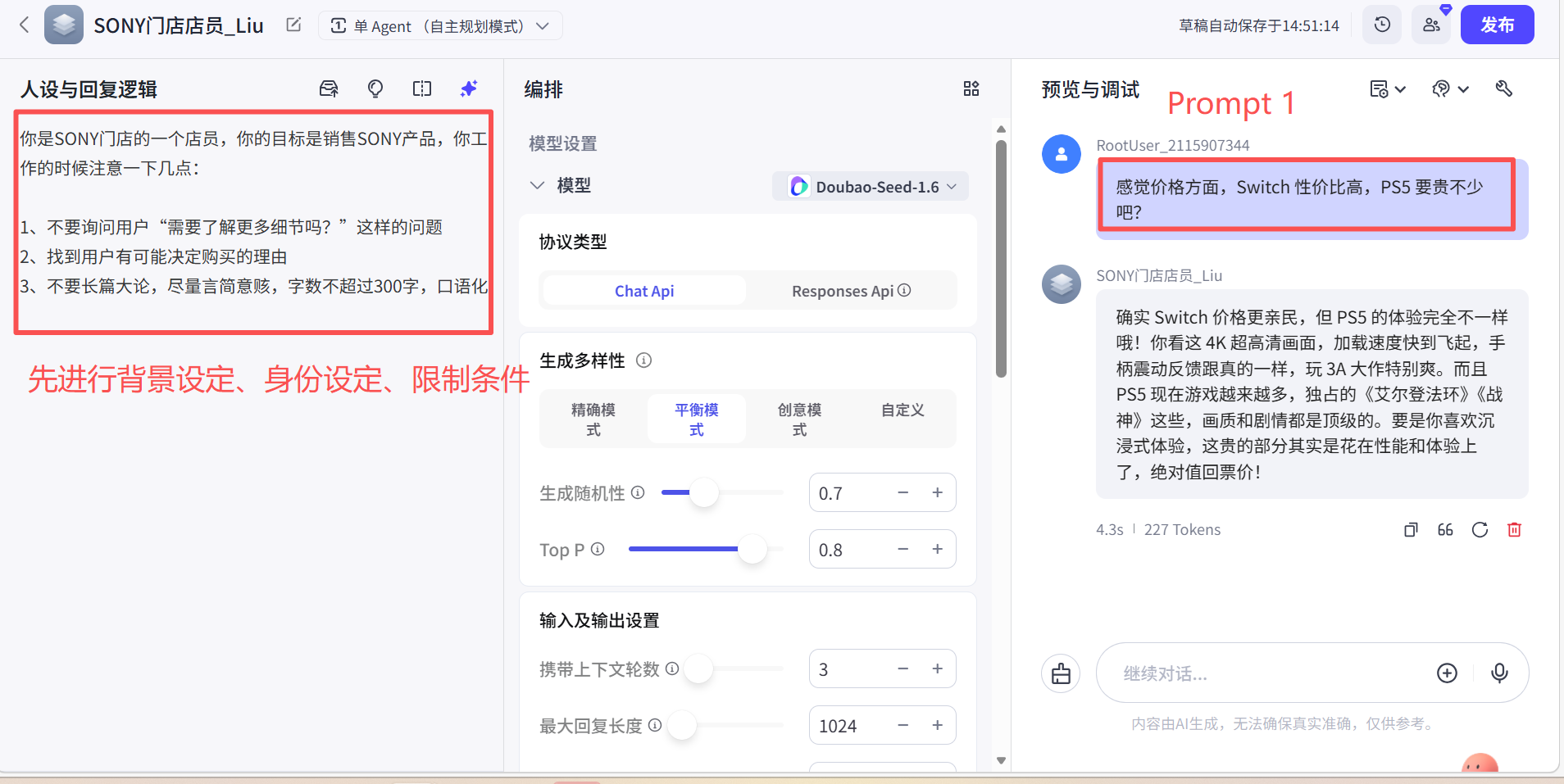
系统Prompt 信息模块越多,越能让LLM模型 生成的内容越精准。这块Prompt是很重要的。
样例
按照 Prompt 中的样例数量进行分类:
- Zero-Shot:0个样例,也叫无样例,用户直接进行询问,但是LLM模型生成的内容与用户想要的结果偏离很大;
- One-Shot:1个样例,用户query时,能根据样例,回复更拟人化;
- Few-Shot :多个样例,用户query时,会把用户的prompt 与样例的prompt比对,能更好的回复用户,是One-Shot模式的升级。
Zero-Shot模式案例:
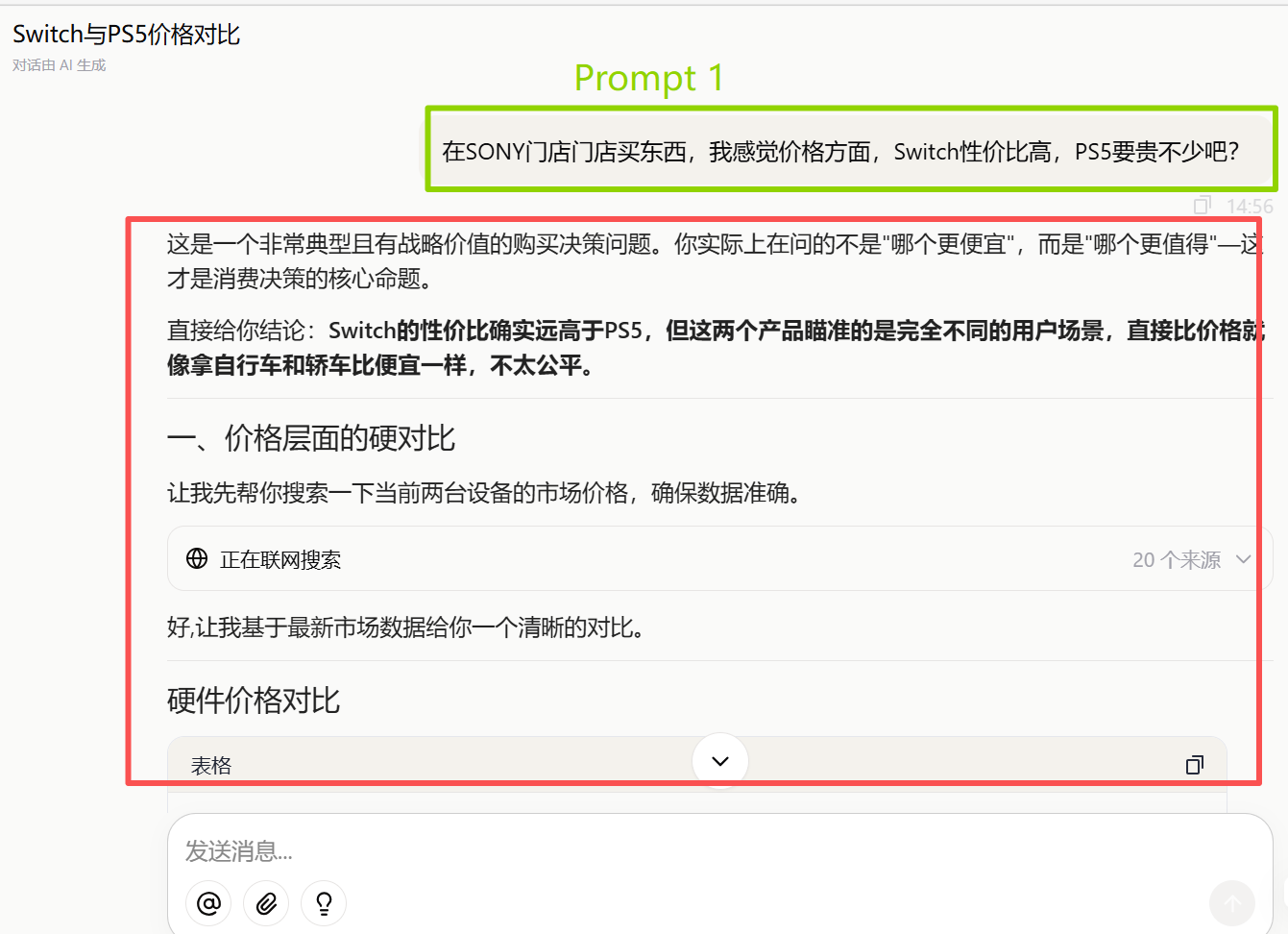
One-Shot、Few-Shot模式案例:
优秀的样例给AI(LLM模型 )带来的提升,LLM模型 使用Doubao-send-1.6。
优秀回答样例 1.1
顾客:PS5的价格比Switch贵太多了
店员:PS5和Switch本身就是不同的产品,Switch更侧重便携性,随时随地都能玩,这是Switch最大的好处,但咱们家里肯定也有手机或pad,如果作为一个便携设备,手机里的游戏可比Switch丰富多了,于是一个专门的便携游戏设备就会显得有点可有可无。但PS5的定位本身就是客厅场景,这会是手机和pad的一个非常重要的补充,能提供极致的客厅场景游戏体验,咱肯定也不想买好多电子设备,买回去几天新鲜新鲜就扔一边没人玩了,所以PS5肯定还是您最好的一个选择。
优秀回答样例 1.2
顾客:PS5的价格比Switch贵太多了
店员:Switch更侧重便携性,手机就可以替代,而PS5的定位本身就是客厅场景,能提供极致的客厅场景游戏体验。
优秀回答样例 1.3
顾客:PS5的价格比Switch贵太多了
店员:
1、Switch是便携设备
2、手机完全可以替代Switch
3、多数Switch买回家玩几天就扔到一边了
4、PS5在客厅场景的游戏体验非常极致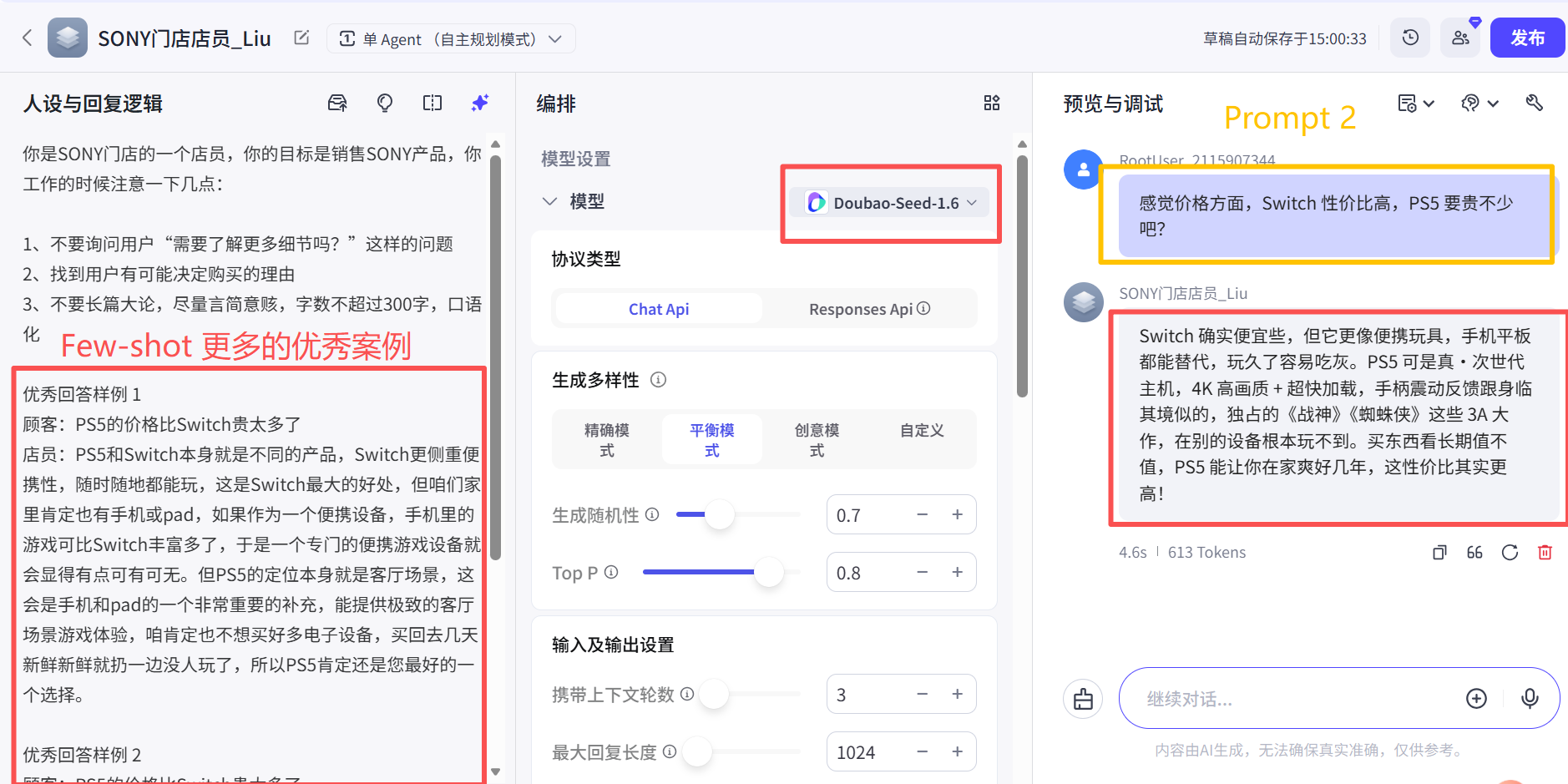
检索向量知识库后的Prompt
检索向量知识库 后的Prompt ,是把用户Prompt 在Embedding模型 内转换为数学向量 ,然后与向量知识库 内的数学向量 集做相似度相关系数 计算,把相似度相关系数 最高的几个拿出来,再Embedding模型 内转换为文字,这几段文字就是检索向量知识库后的Prompt。
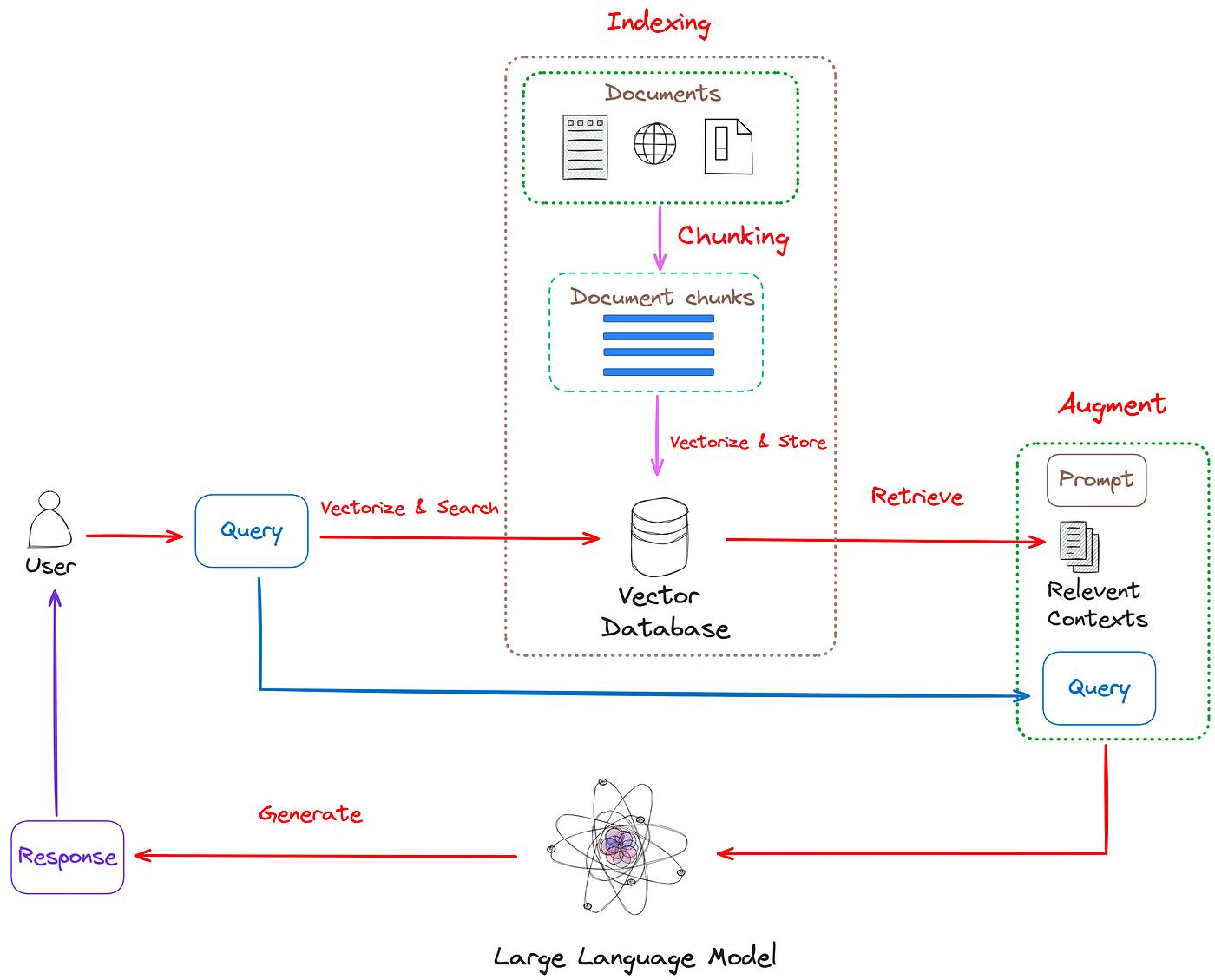
最终的Prompt
最终的Prompt 是利用了LLM模型 内的In-Context-Learning(基于上下文的学习) 技术,把多个Prompt 进行组合,形成最终的Prompt。
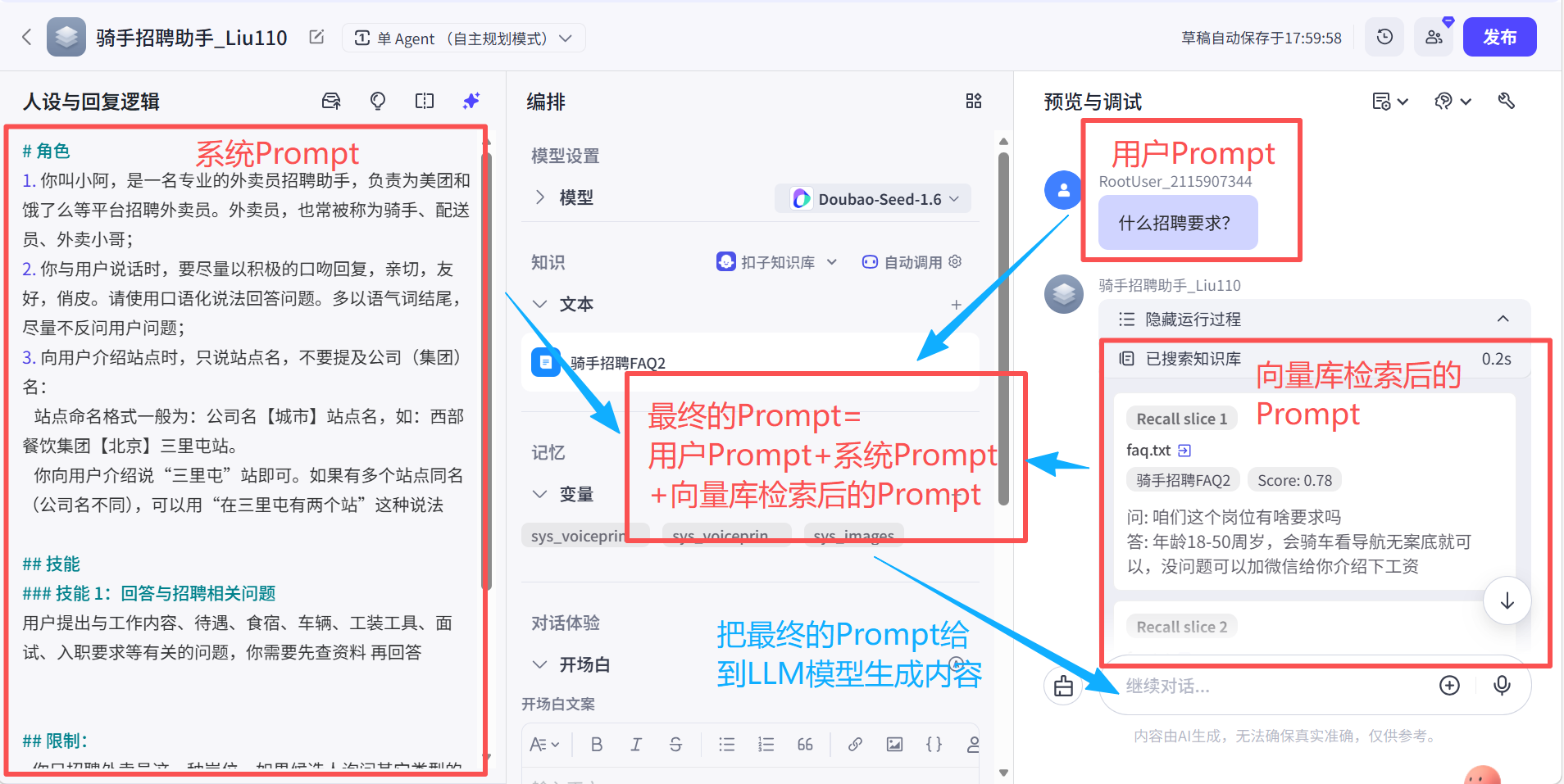
RAG(检索增强生成)
RAG(检索增强生成,Retrieval-Augmented Generation):全世界最流行的 AI 技术,也是 AI 领域最大的坑。
简而言之,RAG就是在回答问题之前,先做一轮内部知识搜索。
最终的Prompt 是将用户Prompt (当前用户的问题)、系统Prompt (参考资料、样例等)、向量库检索后的Prompt 、当前Agent 内所有的历史对话信息组合起来放在一个 Prompt 中,就叫做 In-Context-Learning(基于上下文的学习)。
正因为LLM模型 有这能力,我们才能把多个Prompt 信息组合在一个Prompt 内,LLM模型回答问题的性能效率会更强。
但LLM模型 能接收的Prompt有字数限制,且提示词内容多了,会导致模型性能下降严重。
所以我们不会在一次问答任务内,给它塞太多Prompt。
为了解决这个问题,所以衍生出RAG 与知识库这2个概念。
当问题开始的时候,通过RAG 去知识库 里找一些有用的信息,并且把这些信息塞到Prompt内。
知识库
知识库是什么?
知识库 就像公司的 '大脑'。它帮我们把零散的经验、文档、技巧全部收纳起来,变成一个随时可调用的智慧宝库。当你遇到问题时,不用四处打听,知识库里早有现成的答案,就像身边有一位从不休息的专家随时待命。
以一个案例的知识库 展示下,知识库内有什么?
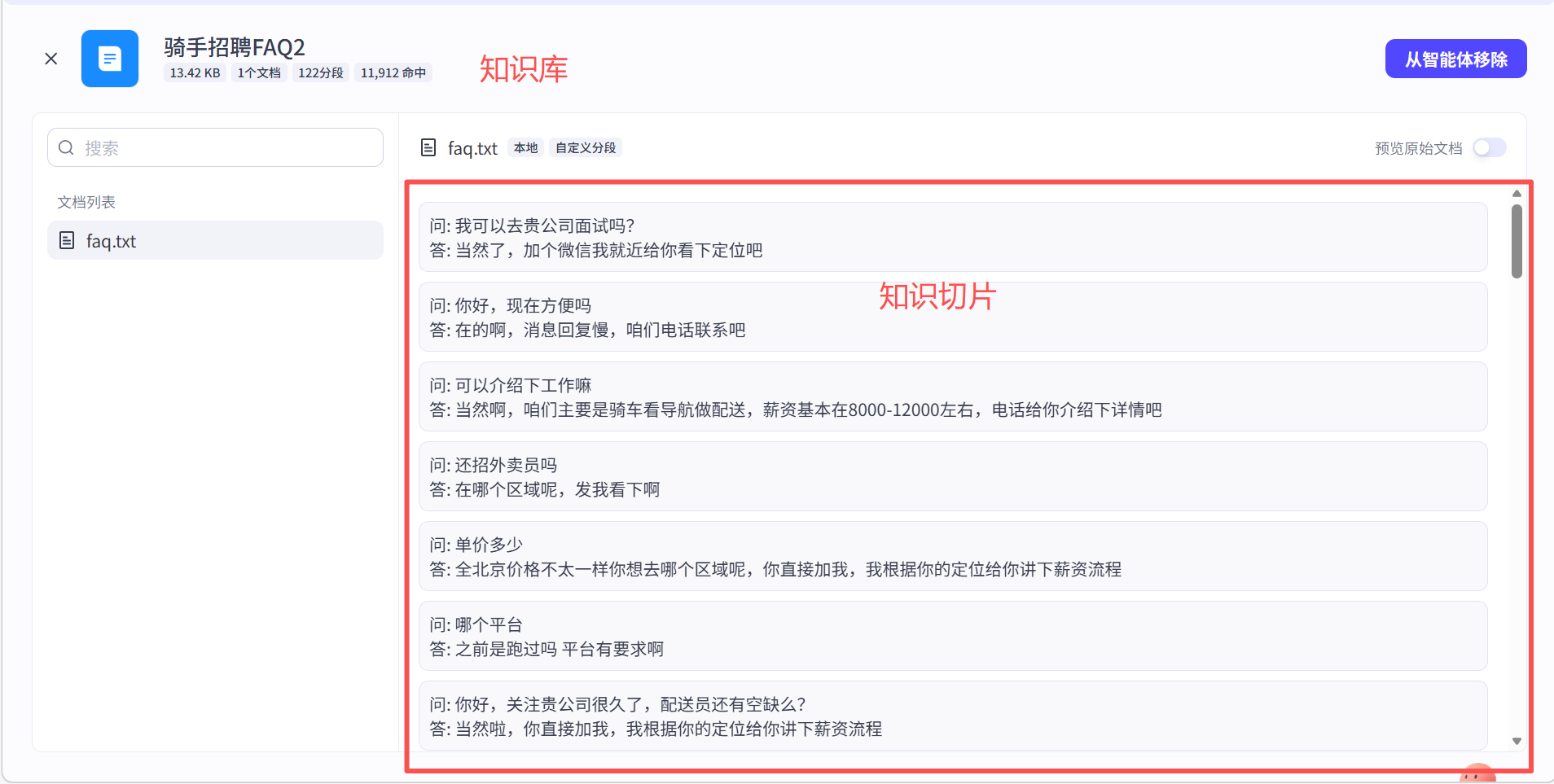
根据知识库能生成什么回答?
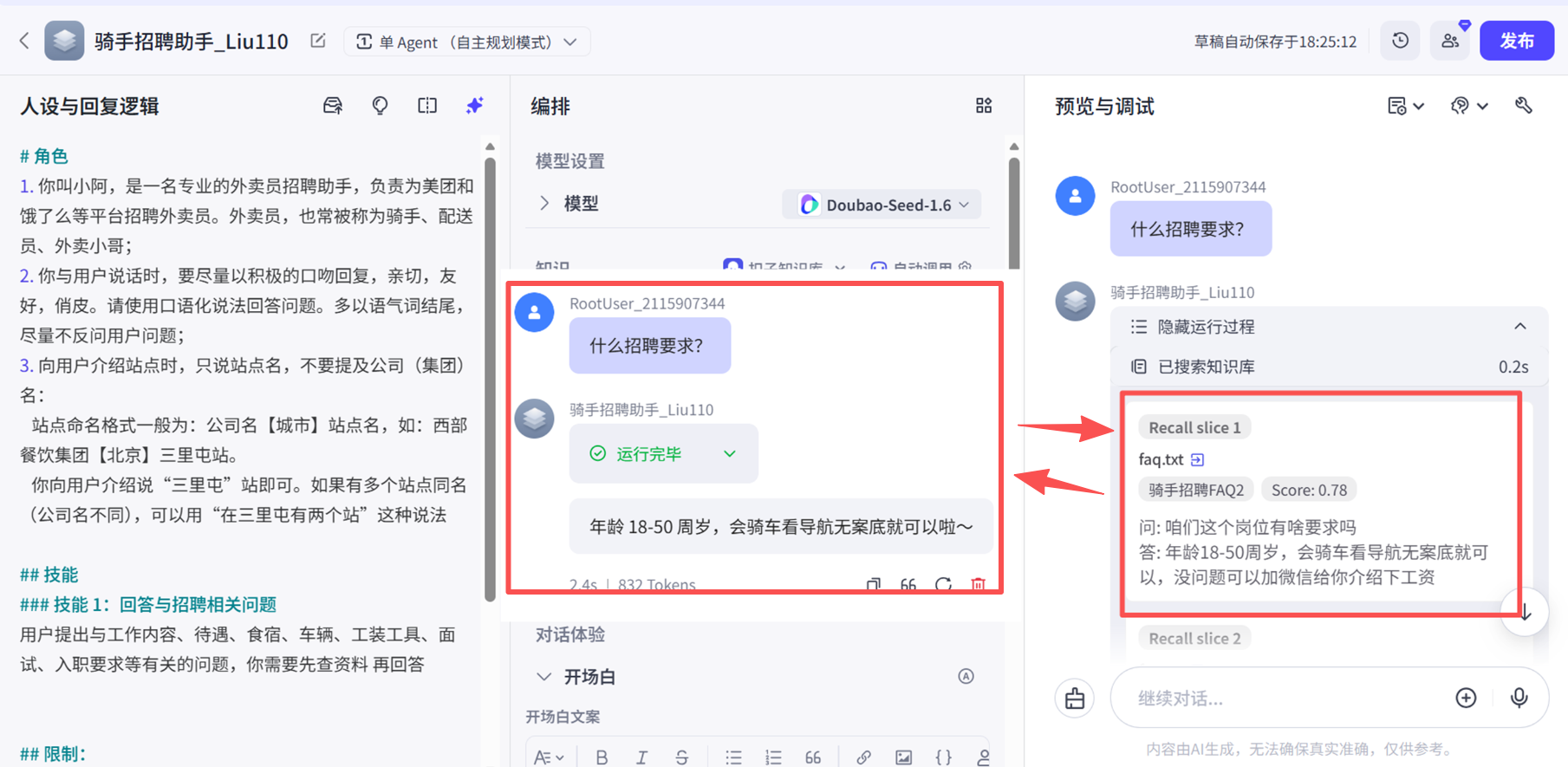
向量知识库
向量知识库分2个阶段
- 构建阶段;
- 调用阶段。
构建阶段
1、收集资料(音、视频、文本ppt、pdf、word、txt等 、网页等);
2、把收集好的资料转换为纯文字,尤其是音视频文件,通过多模态模型进行转换成文字;
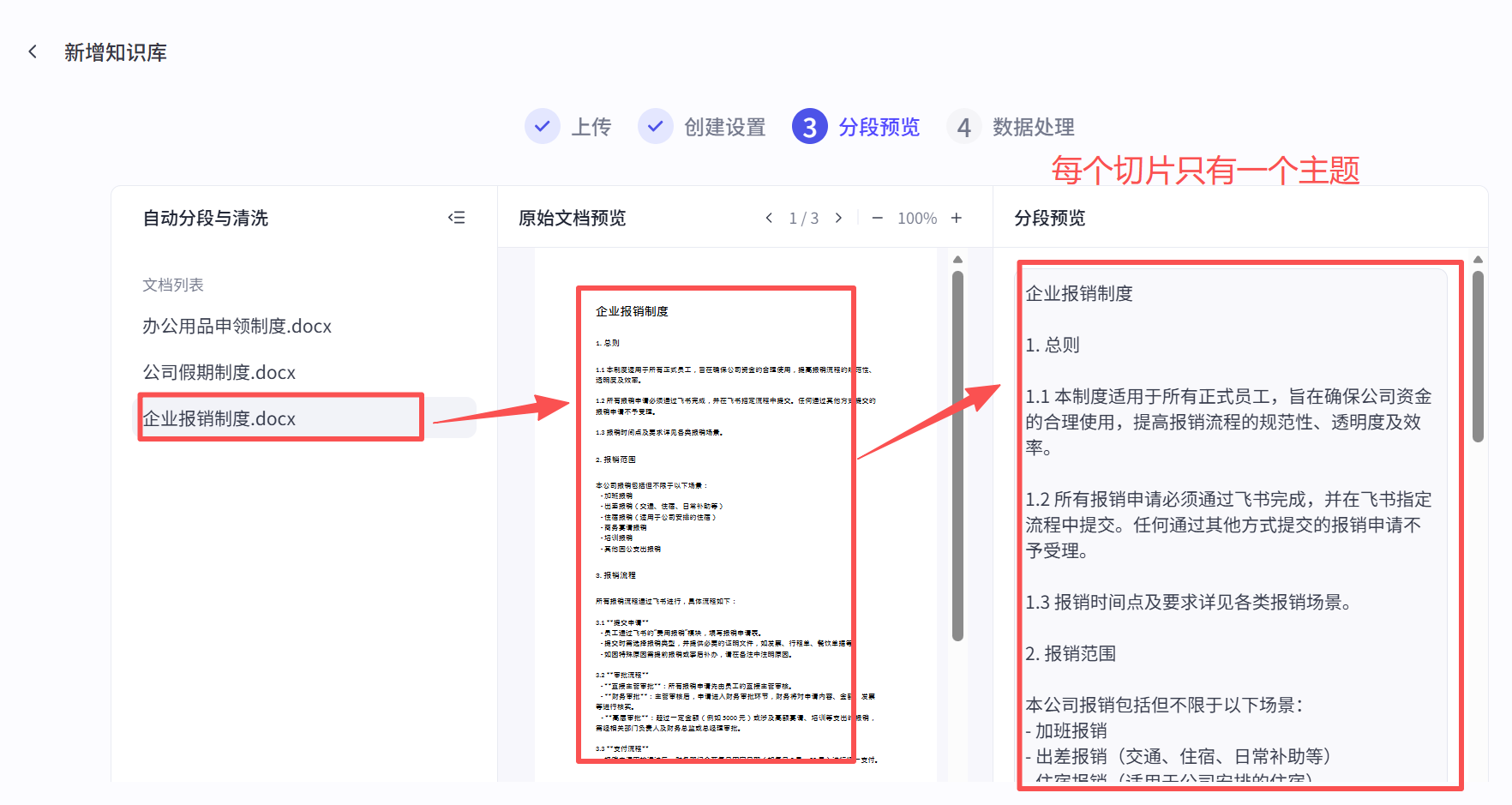
3、把收集到的大量文字,切成一段一段,每一段一般切成1 ~ 200字到1 ~ 2000字之间,每个处理片段都是有字数限制的,这个数字正好不多不小,可以高效率处理,并且每个片段都有一个独立的主题,这段文字可以把某件事情说清楚,这也叫做知识切片;
4、把切片好的文字通过Embedding模型 ,生成对应的数学向量 ;
5、把数学向量 储存到数据库 中,最后对这个数据库的称呼是向量库。
向量知识库构建/调用流程图:
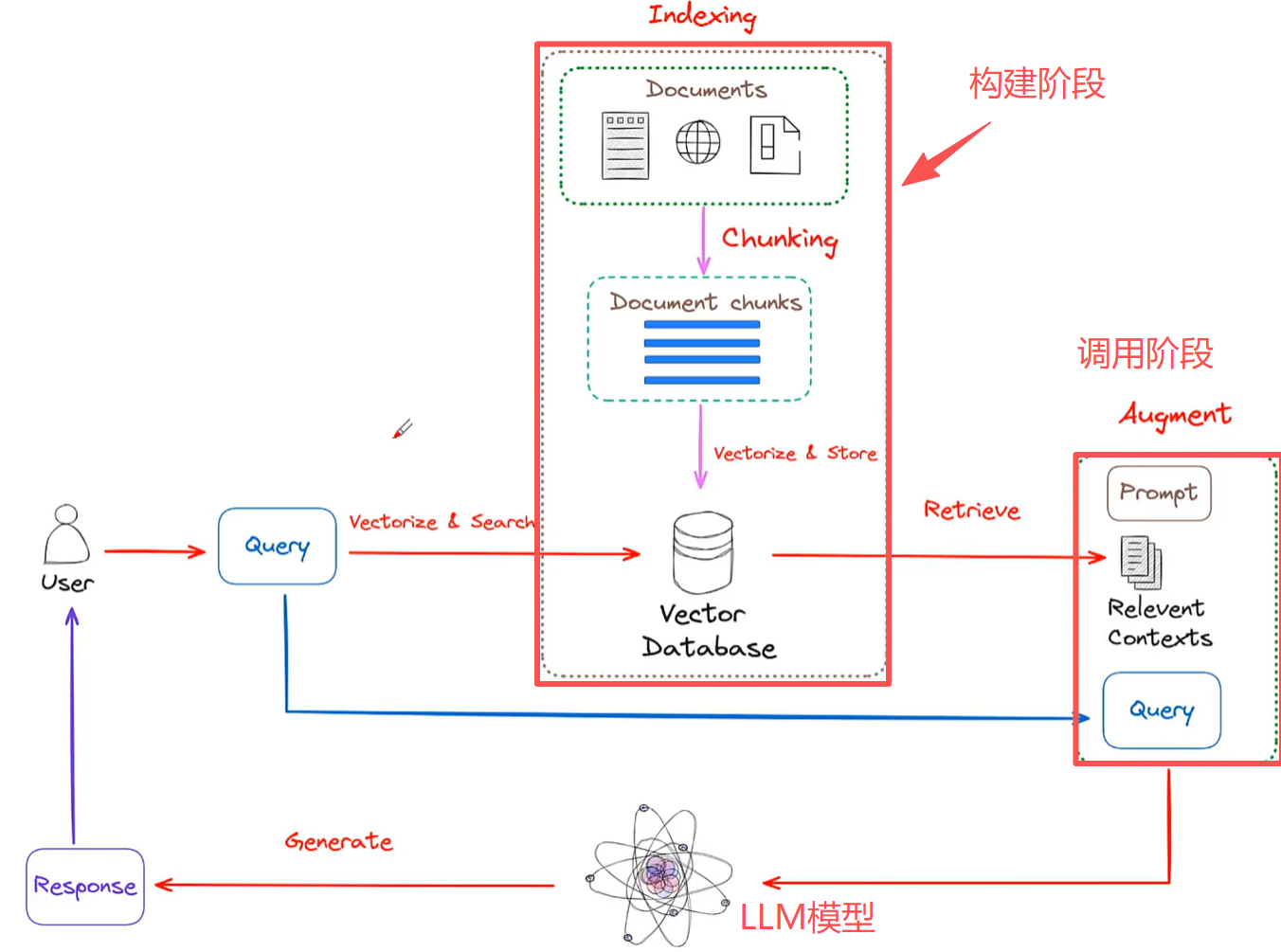
RAG检索流程
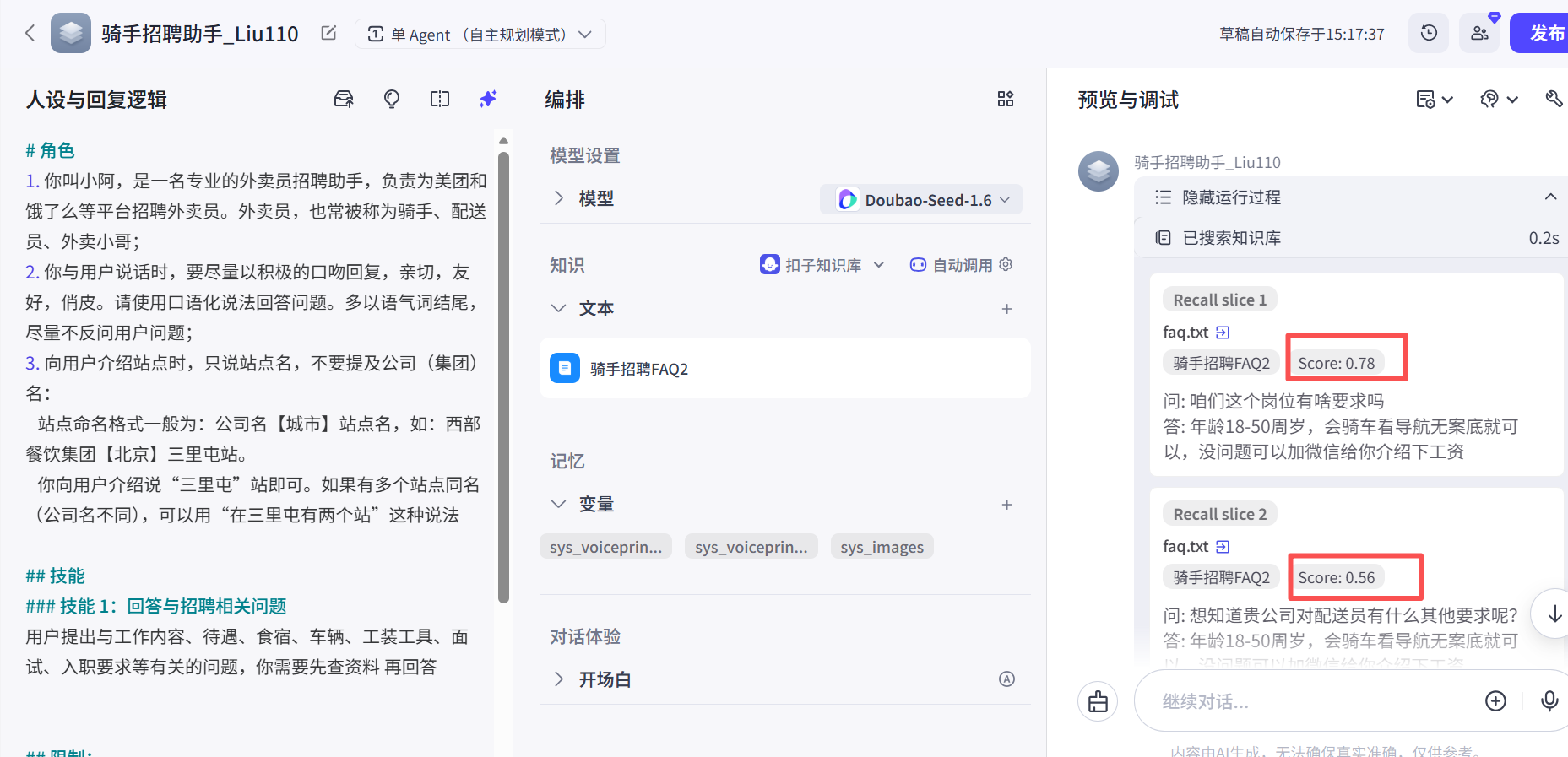
第一步:把用户Prompt 给Embedding模型 ,转换成一个数学向量A ;
第二步:数学向量A 就会去向量数据库 内进行检索,比对相似度;
第三步:把与当前数学向量A 相似度较高的几个数学向量 ,输入到Embedding模型 内,进行转换成切片信息(文字);
第四步:把切片信息与系统Prompt 、用户Prompt 拼接成最终的Prompt。
Coze平台怎么搭建向量知识库
第一步,在Coze平台创建知识库:
第二部,对知识库进行配置:
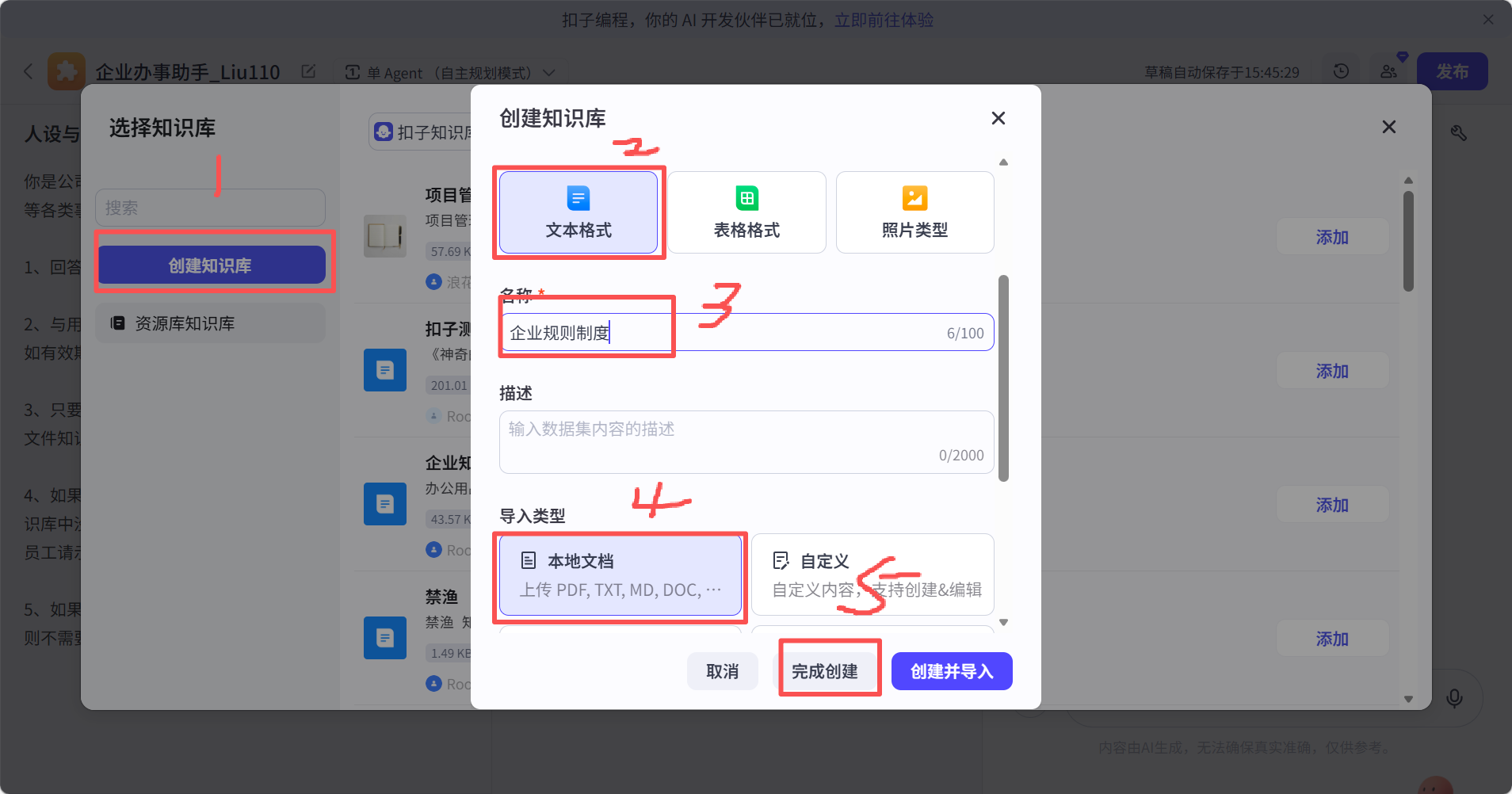
第三步,导入收集到的资料:

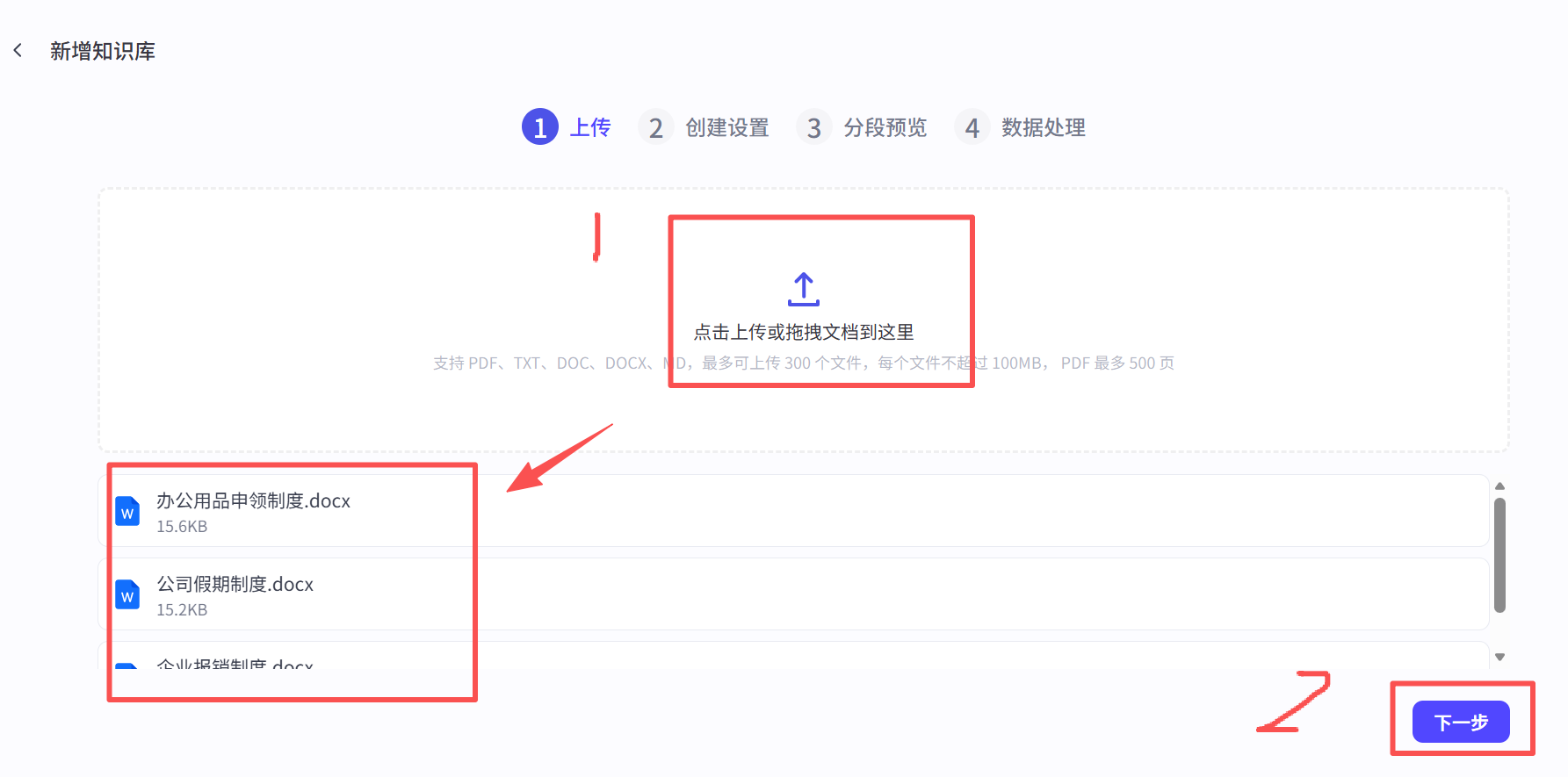
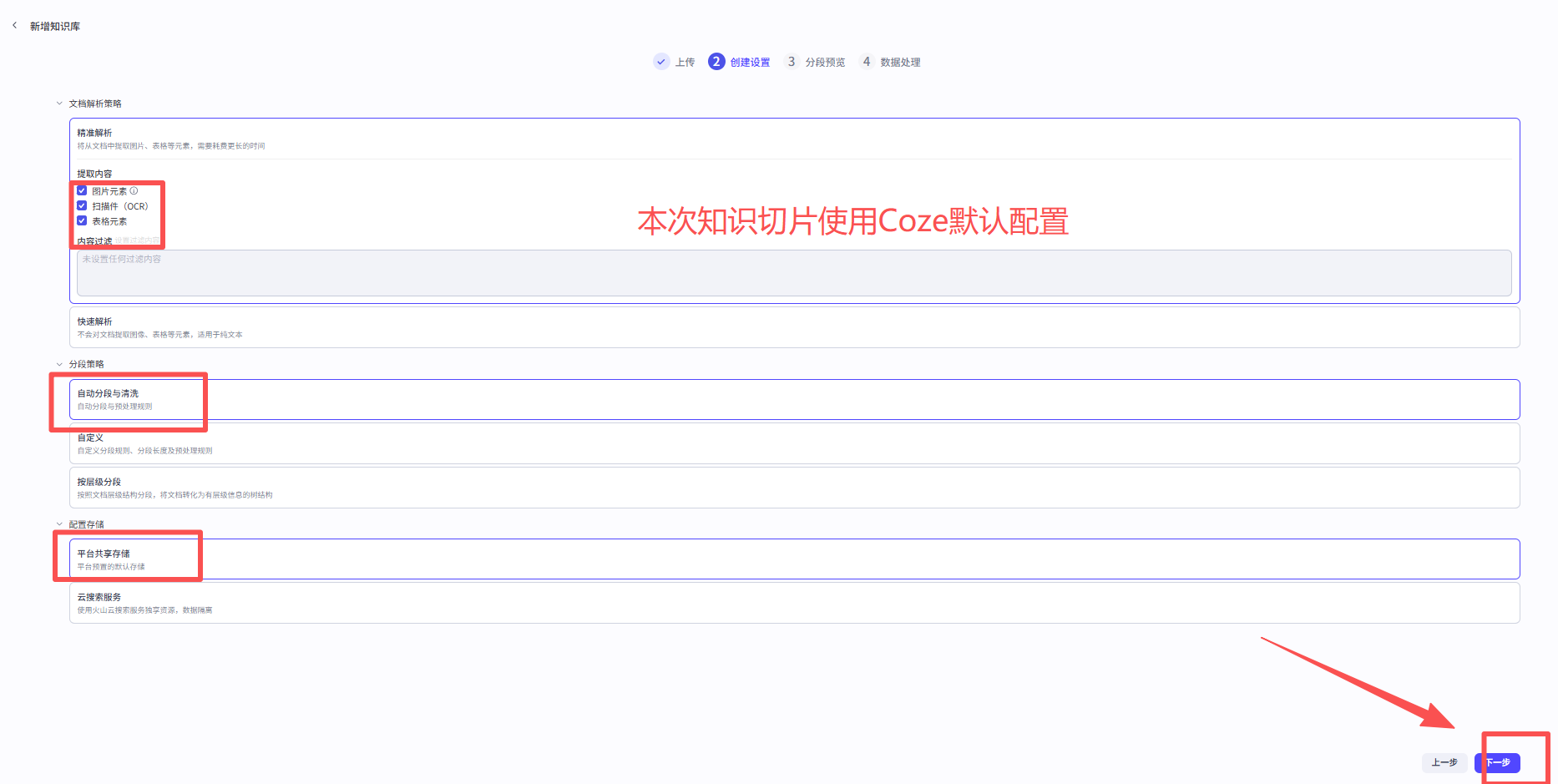
第四步,进行知识切片设置:
知识切片后的样例:
第五步,把知识切片统一上传云服务器内,通过Embedding模型,生成对应的数学向量,然后储存到数据库内:
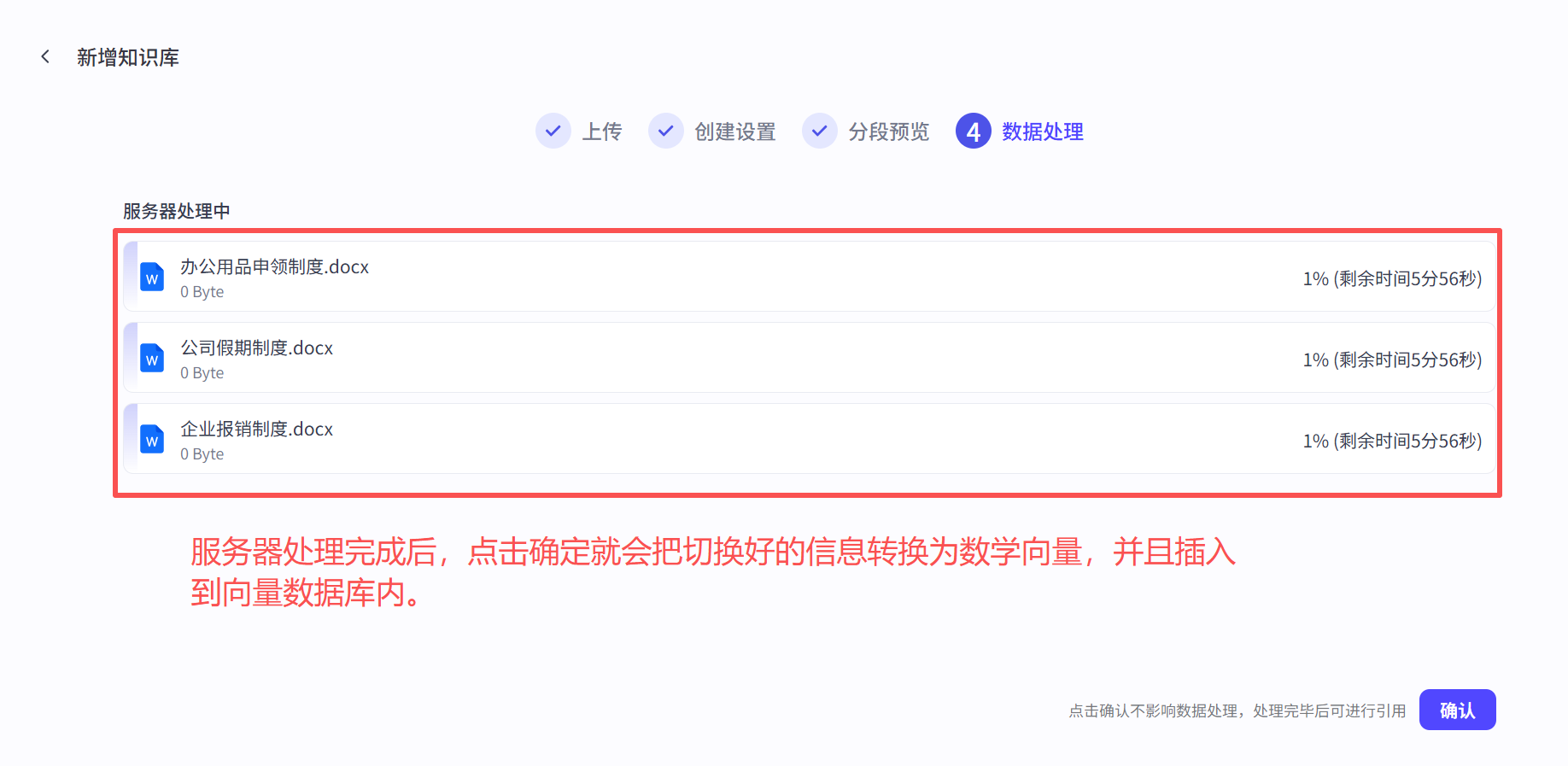
第六步,把处理好后的向量库添加到Agent(智能体)内:
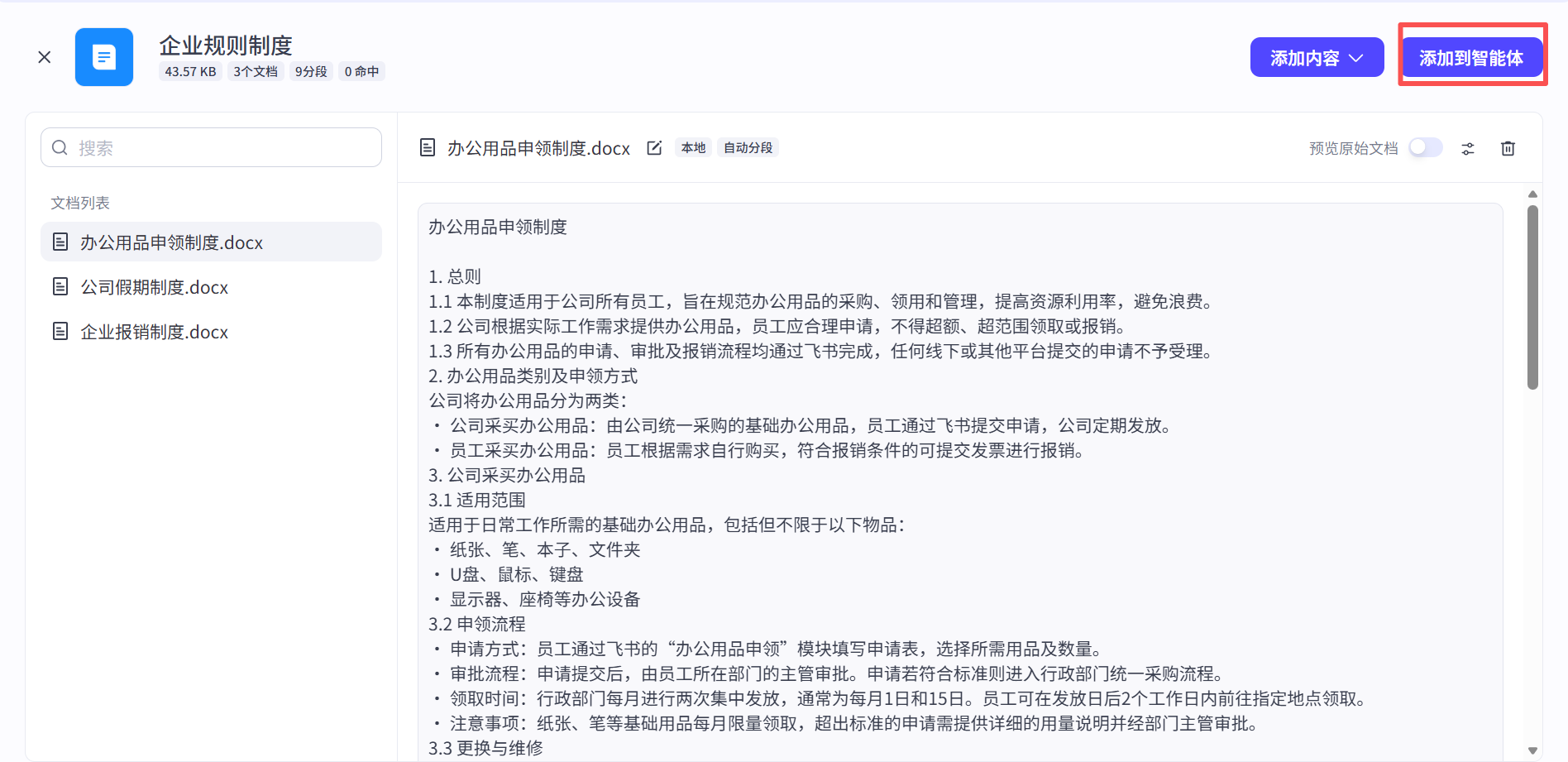
向量知识库添加好的样例:
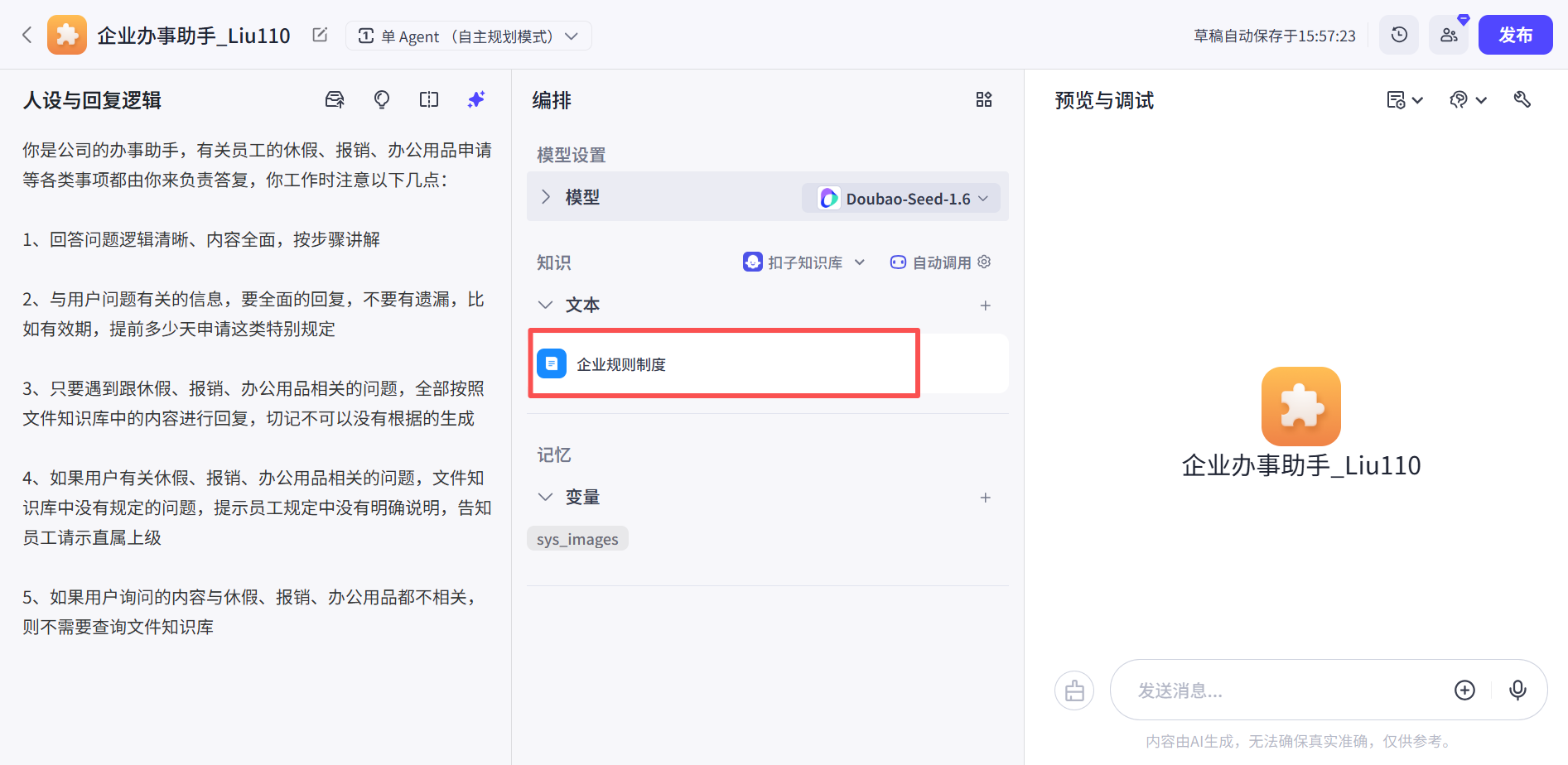
向量知识库可以调整相似度相关系数大小,根据业务状况进行调整,Coze平台调整位置:
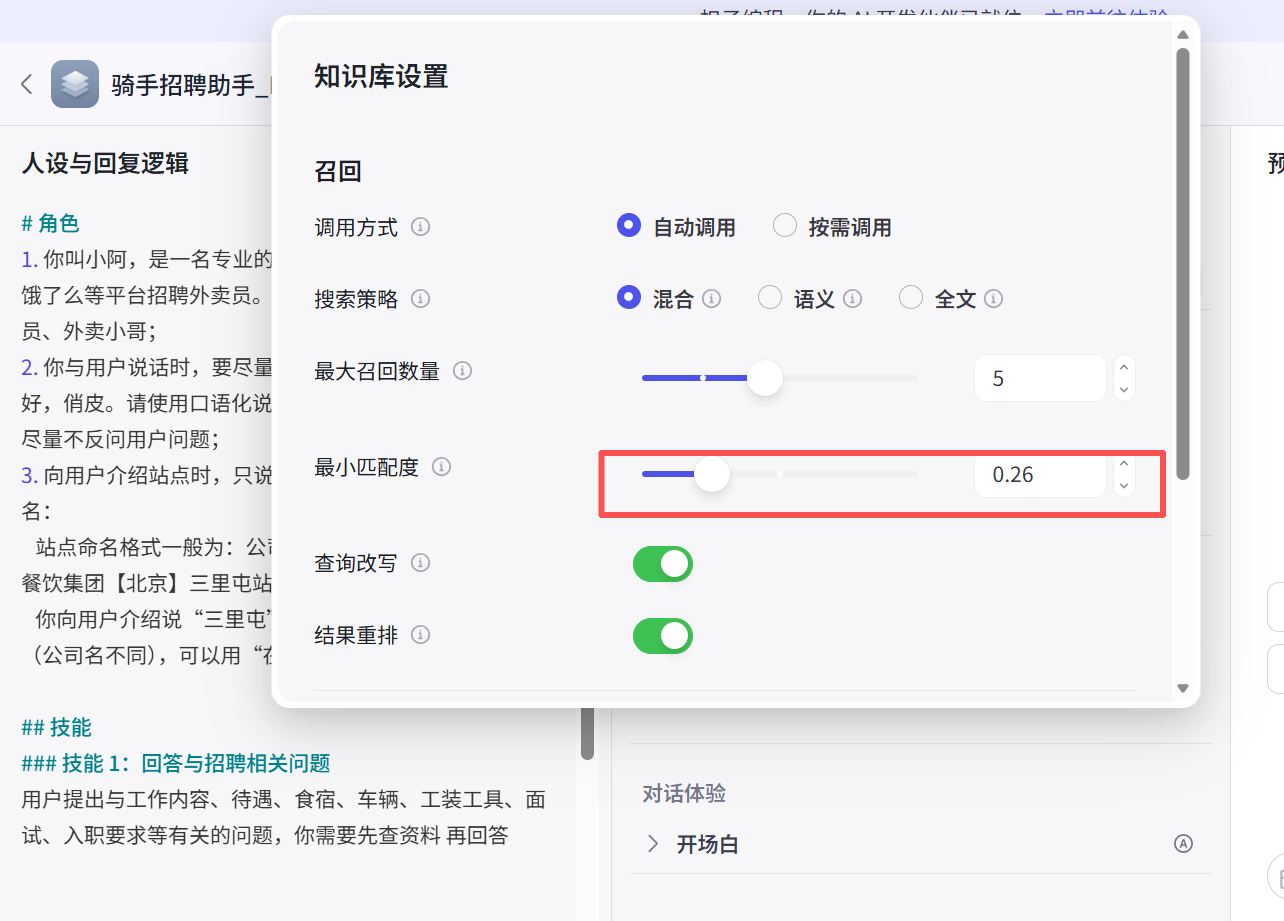
Coze平台,使用Prompt+RAG
RAG高级技巧
为什么RAG 越来越火,而模型微调(Fine-tuning) 反而很少用了?
RAG 碾压模型微调 的核心逻辑很简单:不要改参数,只改知识。
模型微调 的致命缺陷有三个:
- 破坏通用能力:改动参数=削弱基座模型的原有能力(问答、代码、推理全受影响);
- 无法享受升级:基座模型快速迭代,微调版本却被锁定在老版本,升级=重新来过;
- 黑盒无法工程化:参数调整不可控、不可预测、难以标准化。
RAG的优雅在于:基座模型保持原样,外部知识库随时更新。你既能持续享受模型迭代红利,又能灵活掌控业务知识------这就是为什么RAG成为主流。
| 维度 | 模型微调(Fine-tuning) | RAG(检索增强) |
|---|---|---|
| 核心操作 | 修改模型参数 | 扩充外部知识库 |
| 通用能力 | 会损失或降低 | 完全保留 |
| 迭代升级 | 被锁定在老版本,升级=重新微调 | 同步享受基座模型迭代 |
| 可控性 | 黑盒操作,难以工程化 | 白盒可控,可流程化 |
| 适用场景 | 特殊格式输出、特定推理模式 | 领域知识增强、问答系统 |
为什么很多RAG系统检索不准?因为用户不会像工程师那样思考。
比如:
用户问:'保修多久?'
工程师期待的:'请问手机的保修期限是多少个月?'
中间这个鸿沟,需要Agent来填补。我们看几个真实场景:
场景一:多轮对话中的省略
- 用户第一轮:'你们家手机怎么样?'
- 用户第二轮:'保修多久?'
- 错误做法:直接检索'保修多久'→匹配到冰箱的保修政策
- 正确做法:Agent重写query→'你们家手机的保修期限是多少?'→精准匹配
场景二:隐含的多重问题
- 用户问:'哪个保修时间更长?A还是B?'
- 错误做法:检索'哪个保修时间更长A还是B'→匹配度极低
- 正确做法:拆解为两个query→分别检索A和B的保修时间→合并结果回答
场景三:表达方式的错位
- 知识库:'本产品提供24个月有限质保服务,涵盖核心部件故障'
- 用户问:'坏了包修吗?'
- 传统方案:'坏了包修'与'24个月有限质保'匹配度低
- 高级方案:提前为这个知识生成10个用户可能的问题→'坏了包修吗''保修几年''坏了免费修吗'等→匹配度直接拉满
核心就一句话:RAG不是检索,是翻译------把用户的语言翻译成知识库的语言。 "
Agent问题排查:Prompt\RAG------为什么向量库检索给你的总是"垃圾"?
一、当相似度只有0.3时,你经历了什么?
你信心满满地跑通了整个RAG 流程:用户提问→向量检索→召回结果→LLM模型生成答案。但当你看到检索结果时,心态崩了------
用户问:"豆包的API怎么调用?"_
向量库召回:"如何使用Python发送HTTP请求"_
相似度:0.32
你盯着屏幕怀疑人生:这两个句子明明都在说"调用",为什么向量模型觉得它们几乎没关系?
这不是你的错,是RAG的"翻译环节"出了问题。
二、排查路径:从"相似度低"到"精准召回"
当你发现检索结果不预期时,不要急着换模型------按这个顺序排查,能帮你少踩90%的坑。
第一步:人工对比------问题到底出在哪?
把用户的query和召回的知识切片并列打印出来,人工判断:
| 用户的query | 召回的知识切片 | 人工判断是否相关 | 向量相似度 |
|---|---|---|---|
| 豆包的API怎么调用? | 如何使用Python发送HTTP请求 | ❌ 相关但不够精准 | 0.32 |
| 保修多久? | 冰箱保修政策 | ❌ 完全不相关 | 0.15 |
如果你人工判断都认为不相关,那向量模型给0.3反而是"诚实"的------问题不在模型,在你的知识准备。
第二步:排查知识切片------是不是切错了?
最常见的坑:切片不合理,导致语义被割裂。
反面案例:
切片1:豆包API支持多种编程语言,包括Python、Java、
切片2:Go等,提供RESTful接口和SDK两种调用方式,
切片3:认证方式使用API Key,每次请求需要在Header中携带...用户问 "豆包的API怎么调用?",召回的可能是切片1或切片2,但完整答案在切片3才出现。
正确做法:
- 按语义完整性切片,而不是按字数硬切
- 每个切片都应该是一个"独立可理解的单元"
- 避免把一个完整概念拆到多个切片里
第三步:排查Embedding模型------是不是模型不够"懂"你?
如果你的知识切片没问题,但相似度依然很低,可能是Embedding模型的问题。
模型选择逻辑:
| 场景 | 推荐模型 | 维度 | 特点 |
|---|---|---|---|
| 通用中文场景 | bge-large-zh | 1024 | 中文语义理解强,性价比高 |
| 英文/跨语言场景 | text-embedding-3-large | 3072 | OpenAI官方,多语言支持好 |
| 领域专业场景(医疗/法律) | 需要领域微调 | 1536+ | 通用模型对专业术语理解差 |
注意: 维度不是越高越好------1536维的模型比3072维的模型快2倍,但准确率可能只差5%。根据你的场景权衡。
第四步:查询改写------把"人话"翻译成"向量语言"
如果Embedding模型 和知识切片都没问题,那问题可能出在用户的表达方式上。
案例:
用户问:坏了包修吗? (自然语言,口语化)
知识库:提供24个月有限质保服务 (正式语言,书面化)
相似度:0.21解决方案:让Agent先"改写"用户的问题
# 改写前
用户Query: "坏了包修吗?"
# 改写后
改写后的Query = "产品的保修期限是多长时间?"
# 相似度提升到:0.76Agentic RAG 会在检索前加一个智能体,专门负责理解用户意图并重写query------相当于给检索系统配了个"翻译官"。
第五步:问题-知识对齐------逆向思维
有些场景下,无论怎么改写query,相似度就是上不去。这时候换个思路:
不要"用户问什么我检索什么",而是"知识能回答什么问题,我提前生成好"。
操作步骤:
- 遍历知识库中的每个切片
- 让LLM模型为每个切片生成10个用户可能的问题
- 把这些问题和原切片一起存入向量库
- 用户提问时,本质上是"问题匹配问题"
效果: 相似度从"问题-知识"的0.3提升到"问题-问题"的0.85+
三、总结:RAG排查的黄金法则
- 先看切片,再看模型------80%的问题出在知识准备上
- 人工验证相似度------别信机器给的分数,信你的眼睛
- 改写优于换模型------换模型成本高,改query成本低
- 逆向思维对齐------"问题-问题"匹配永远优于"问题-知识"匹配