一、基础知识部分
Q:java面向对象三大特性?
A:封装、继承、多态
Q:反射原理以及使用场景
Q:Java中的浅拷贝和深拷贝
- 浅拷贝:只复制对象本身的基本数据类型字段,对于引用类型的字段,只复制内存地址(引用),新旧对象共享同一个子对象
- 深拷贝:不仅复制对象本身,还递归复制所有引用的子对象,新旧对象完全独立,互不影响。
使用场景,对一个List users集合进行拷贝,如果执行浅拷贝后生成新集合 新集合的元素和老的是共用对象引用的,修改新集合某个对象元素的内容,会导致老集合一起被更新
Q: String、StringBuffer、StringBuilder 的区别?
源码分析:csp1999.blog.csdn.net/article/det...
- String:被final关键字修饰不可变,线程安全;每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。
- StringBuilder:字符串对象通过"+"的字符串拼接方式,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象 。线程不安全
- StringBuffer:线程安全,append()、length()等关键方法都被 synchronized 加锁。
Q:String#equals() 和 Object#equals() 有何区别?
String 中的 equals 方法是被重写过的,比较的是 String 字符串的值是否相等。 Object 的 equals 方法是比较的对象的内存地址。
Q: JDK 动态代理和 CGLIB 动态代理有什么区别?
| 对比维度 | JDK动态代理 | CGLIB动态代理 |
|---|---|---|
| 实现原理 | 基于接口,实现目标接口 | 基于继承,生成目标类的子类 |
| 要求 | 目标类必须实现接口 | 目标类无需接口,但不能是final类 |
| 生成方式 | 反射机制生成代理类 | ASM字节码框架生成子类 |
| 性能 | 创建快,调用稍慢(反射) | 创建稍慢,调用较快(直接字节码) |
| 依赖 | JDK内置,无需额外依赖 | 需要引入cglib库 |
| final方法 | 不影响(接口无final方法) | 无法代理final方法 |
scss
┌─────────────────────────────────────
│ 有接口 → 两者都能用,JDK是默认选择
│ 无接口 → 只能用 CGLIB
│ final类 → 两者都不能代理
│ final方法→ CGLIB无法代理,JDK无此问题
└─────────────────────────────────────
JDK代理调用链:
proxy.save() → InvocationHandler.invoke() → Method.invoke()【反射】→ 目标方法
CGLIB调用链:
proxy.save() → MethodInterceptor.intercept() → MethodProxy.invokeSuper()【字节码】→ 目标方法
Q:BIO、NIO 和 AIO 的区别?
TODO
Q:IO多路复用
TODO
二、Java集合部分
Java集合体系
1.ArrayList
1. 数据结构
ArrayList 底层是动态数组,本质上维护了一个 Object\[\] 数组。它支持随机访问,查询快,但插入删除慢。
2. 初始容量
在 JDK 8 中,new ArrayList() 时并不会立刻创建长度为 10 的数组,而是先使用容量为 0 的空数组。第一次添加元素时才扩容到默认容量 10。
如果使用 new ArrayList(int initialCapacity),则初始容量为指定值。
2. 扩容机制
-
当add新元素时,如果当前数组容量不足以容纳新元素,就会触发扩容。即当 size + 1 > elementData.length 时扩容。
-
每次扩容为原容量的 1.5 倍,即:
java
// >>1 右移一位相当于除 2
newCapacity = oldCapacity + (oldCapacity >> 1)- 扩容出触发后,创建一个新的数组,然后把老的数据拷贝过去(Arrays.copyOf())
2.LinkedList
数据结构
LinkedList 基于双向链表实现,插入、删除、更新快,查询慢,不支持随机访问。
LinkedList 底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,不能实现 RandomAccess 接口。
3. HashMap
1. 数据结构
JDK1.7 及之前底层是数组和链表(链表散列)。
JDK1.8 之后底层是数组和链表加红黑树。
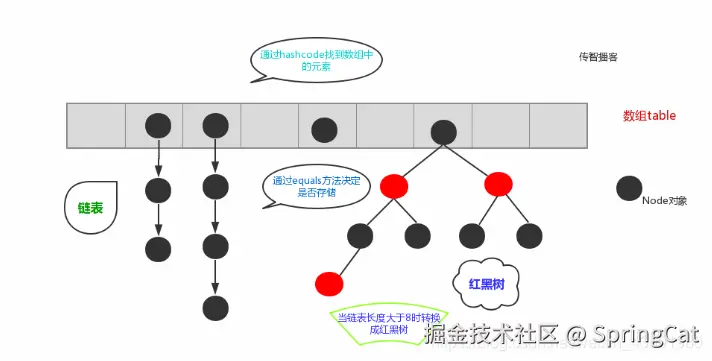
为什么JDK8链表改为尾插法?
- 扩容时保持链表顺序
- 避免头插法并发扩容时遇到死循环问题
2. 初始容量
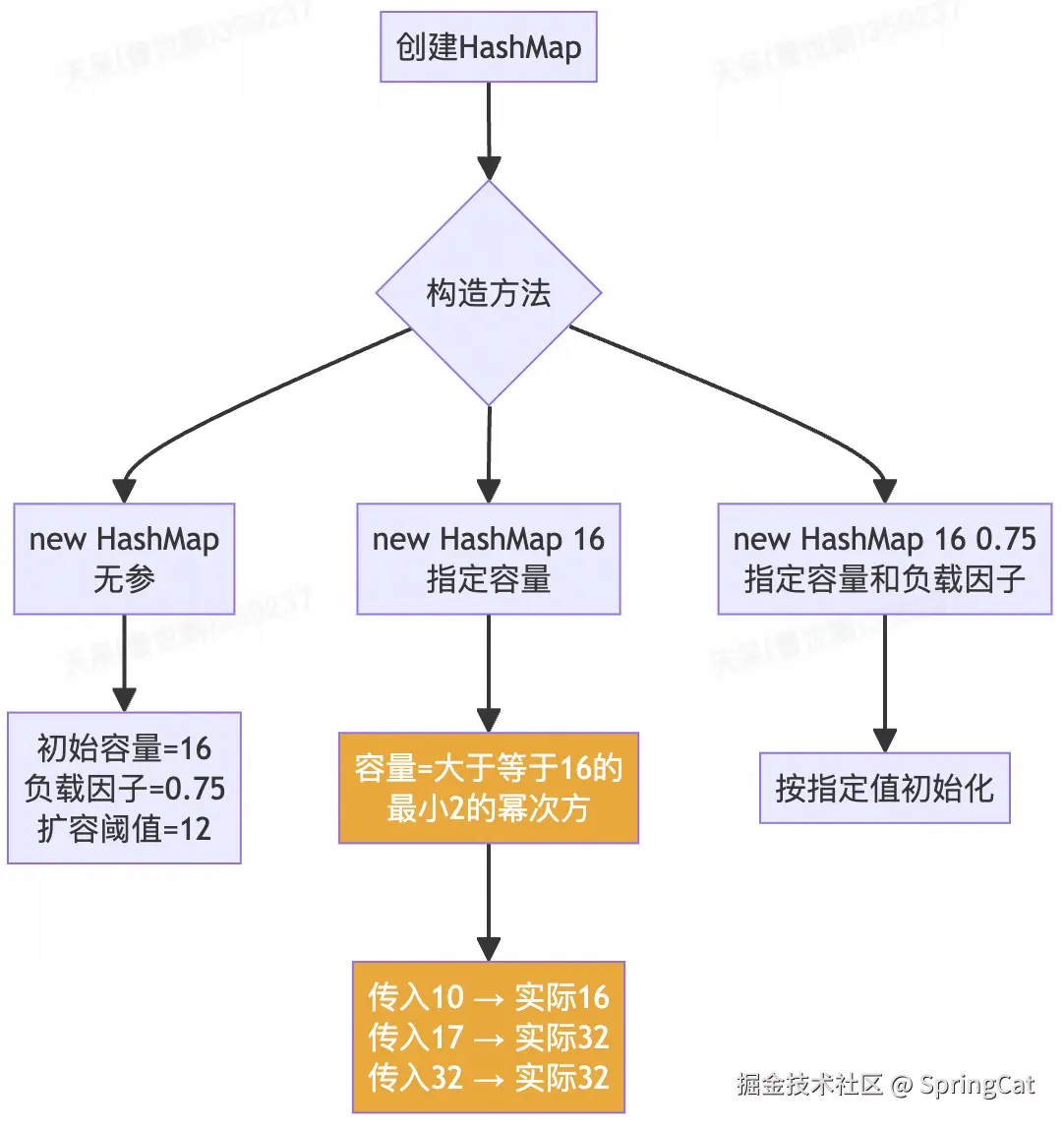
java
// 为什么容量必须是2的幂次方?
// 方便用位运算代替取模:hash % capacity = hash & (capacity-1)
// 位运算效率远高于取模运算!
// tableSizeFor:找到大于等于cap的最小2的幂次方
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
// 传入10 → 返回16
// 传入17 → 返回32
3. 扩容机制
-
HashMap扩容时每次容量变为原来的两倍;新的扩容阈值为新容量*0.75
-
当桶的数量小于64时不会进行树化,只会扩容;
-
当桶的数量大于64且单个桶中元素的数量大于8时,进行树化;
-
当单个桶中元素数量小于6时,进行反树化;
为什么树化阈值是8?
链表长度符合泊松分布长度为8的概率约为 0.00000006(极低)
红黑树查询O(logn) vs 链表O(n),转换有额外内存开销(TreeNode是Node的2倍大小)长度8时收益才大于成本。
为什么退化阈值是6而不是8?
避免频繁在8附近增删导致树与链表反复转换,6和8之间留有缓冲区。
扩容后旧数组迁移过程?
PS:搬移元素,原链表分化成两个链表,低位链表节点存储在原来桶的位置,高位链表搬移到原来桶的位置加旧容量的位置;目的是在扩容数组上,将原来链表上的hash冲突打散。
4. HashMap如何解决Hash冲突?如何定位桶位
java
// 第一步:计算hash(扰动函数)
static final int hash(Object key) {
int h;
// null的hash固定为0,放在桶0
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 为什么要高16位异或低16位?
// hashCode是32位,桶位计算只用低位(hash & n-1)
// 高位信息被浪费,容易产生冲突
// 扰动函数让高位参与运算,降低hash碰撞概率
// 第二步:计算桶位
int index = hash & (n - 1);
// 等价于 hash % n,但位运算更快
// 前提:n必须是2的幂次方!
// 举例:
// n=16,n-1=15=0000 1111
// hash=1010 1100 & 0000 1111 = 0000 1100 = 桶12
5. HashMap中put方法的执行流程?
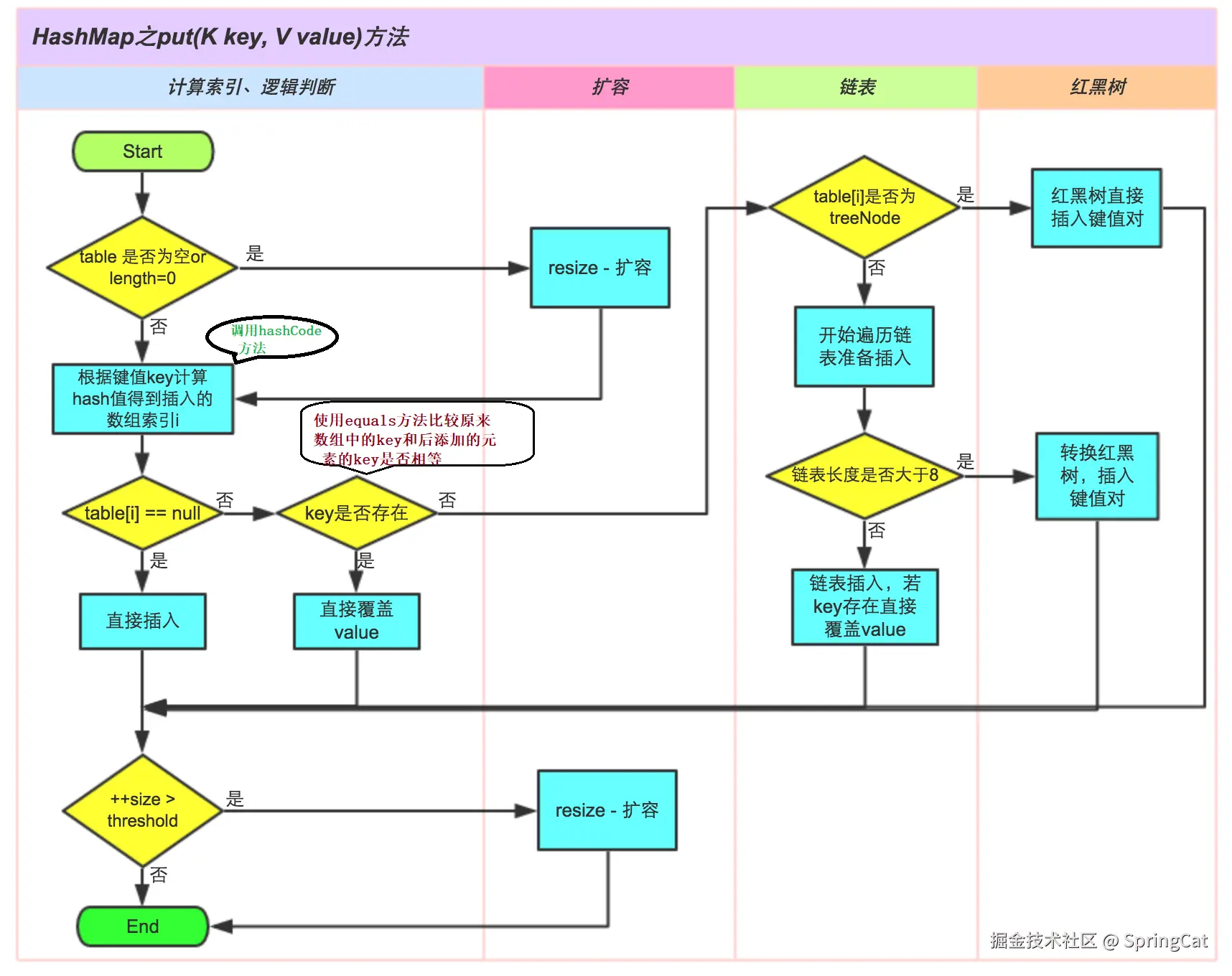
6. HashMap vs Hashtable vs ConcurrentHashMap?
| 对比维度 | HashMap | Hashtable | ConcurrentHashMap |
|---|---|---|---|
| 线程安全 | ❌ 不安全 | ✅ 安全(方法级synchronized) | ✅ 安全(CAS+synchronized) |
| 锁粒度 | 无锁 | 整个对象锁(锁全表) | JDK7:分段锁 / JDK8:锁单个桶 |
| 性能 | 最高 | 最低(全表锁竞争激烈) | 较高(细粒度锁) |
| null Key | ✅ 允许1个 | ❌ 不允许 | ❌ 不允许 |
| null Value | ✅ 允许 | ❌ 不允许 | ❌ 不允许 |
| 底层结构 | 数组+链表+红黑树 | 数组+链表 | 数组+链表+红黑树 |
| 初始容量 | 16 | 11 | 16 |
| 扩容倍数 | 2倍 | 2倍+1 | 2倍 |
| 扩容时机 | 容量*0.75 | 容量*0.75 | 容量*0.75 |
| 链表转红黑树 | ✅ 链表长度≥8 | ❌ 不支持 | ✅ 链表长度≥8 |
PS:HashSet底层就是基于HashMap实现,不需要额外做比较
HashMap和TreeMap的区别?
7. HashMap vs TreeMap
| 对比维度 | HashMap | TreeMap |
|---|---|---|
| 底层结构 | 数组+链表+红黑树 | 红黑树 |
| 是否有序 | ❌ 无序 | ✅ 按Key自然排序或自定义排序 |
| 查询性能 | O(1) | O(log n) |
| 插入性能 | O(1) | O(log n) |
| null Key | ✅ 允许1个 | ❌ 不允许 |
| null Value | ✅ 允许 | ✅ 允许 |
| 排序方式 | 不支持 | 自然排序/Comparator自定义 |
| 适用场景 | 大多数键值对存储 | 需要范围查询/排序场景 |
4.CurrentHashMap
1. 数据结构
JDK1.7 的 ConcurrentHashMap 底层采用分段的数组 + 链表实现,固定位16分段,每一段都是一个独立的HashMap结构,可以独立进行扩容。
JDK1.8 的 ConcurrentHashMap 内部的 map 结构和 HashMap 是一致的,都是由:数组 + 链表 + 红黑树构成。
ConcurrentHashMap 和 HashMap 区别就在于支持并发扩容,其内部通过加锁(CAS + synchronized)来保证线程安全。
2. 初始容量
ConcurrentHashMap 默认初始容量是 16。在 JDK 8 中,默认构造不会立刻创建数组,而是在第一次 put 时延迟初始化,最终容量会调整为不小于指定值的 2 的幂。
3. 扩容机制
1.7与1.8版本扩容机制对比
| 对比维度 | JDK7 | JDK8 |
|---|---|---|
| 并发性能 | 低,单线程扩容阻塞写 | 高,多线程协同缩短扩容时间 |
| 扩容范围 | 单个Segment内扩容 | 整个Node数组扩容 |
| 扩容线程数 | 单线程 | 多线程协同并发扩容 |
| 锁机制 | ReentrantLock锁住Segment | CAS+synchronized锁住桶头节点 |
| 锁粒度 | Segment级别(1/16数组) | 单个桶头节点 |
| 其他线程行为 | 其他Segment不受影响,正常读写 | 发现MOVED标记,加入协助扩容 |
| 数据迁移方式 | 链表头插法重建 | 链表尾插法拆分低位链/高位链 |
| 读操作 | 扩容期间正常读旧Segment | 发现ForwardingNode转向新数组读 |
| 并发性能 | 低,单线程扩容阻塞写 | 高,多线程协同缩短扩容时间 |
4. ConcurrentHashMap 为什么 key 和 value 不能为 null?
ConcurrentHashMap 不允许 null key 和 null value。因为在并发环境下,get 返回 null 时无法区分到底是 key 不存在,还是 value 本身为 null,这会导致语义不明确。
5. ConcurrentHashMap 如何保证线程安全?
- JDK1.7版本是通过锁住分段数组的一个分段桶位,不允许其他线程进入,这个分段桶里的扩容和put流程与HashMap一致。分段数组最多有16个桶位,支持16个并发写入。
- JDK1.8以后细化锁粒度,通过CAS+synchronized锁住table数组的一个桶位来保证写入线程安全,通过 volatile 关键字保证内存可见性,读操作直接读主内存最新值,无需加锁。
6. ConcurrentHashMap 的 get() 需要加锁吗?为什么?
不需要加锁! 通过 volatile 关键字保证内存可见性,读操作直接读主内存最新值,无需加锁。
7. ConcurrentHashMap 的 put() 操作流程?
put 流程总共分为 7步:
第一步 校验,key 或 value 为 null 直接抛 NPE
第二步 用 spread() 计算 hash 值
第三步 进入 for 自旋,保证 put 最终一定成功
第四步 table 未初始化则 initTable,用 CAS 保证只有一个线程完成初始化
第五步 定位桶位,分三种情况:
- 空桶 → CAS 写入,成功结束,失败继续自旋
- MOVED → 协助扩容,完成后继续自旋重新 put
- 桶不为空 → synchronized 锁头节点,链表尾插或红黑树插入
第六步 检查链表长度,满足条件则树化或扩容
第七步 addCount 更新 size,超过阈值触发扩容
put核心链路流程图
put时触发协助扩容流程图
8. ConcurrentHashMap 的 size 如何计算?
JDK1.7时锁住每个分段槽位,逐个每个槽位上的size和
JDK1.8时参考LongAdder原子类的计数设计,基于baseCount + cells数组方式实现,二者都被volatile关键词修饰(线程可见性)
具体原理:
举例:
这样设计的目的:是分散线程竞争,低线程竞争情况下优先使用CAS,线程竞争多的情况下,则通过cells数组分散线程竞争。
9. ConcurrentHashMap的sizeCtl 有哪些含义?
java
private transient volatile int sizeCtl;分别对应四种状态:

sizeCtl状态流转流程图:
10. 描述一下ConcurrentHashMap中的hash寻址算法? 节点的 Node.hash 字段一般情况下必须 >=0 这是为什么?
寻址算法:
java
// 1)先取 key 的 hashCode
int h = key.hashCode();
// 2)做 spread 扰动运算, 减少哈希冲突概率
(h ^ (h >>> 16)) & HASH_BITS
// 3)通过 (n - 1) & hash 定位桶下标
int idx = (n - 1) & hash节点hash值对照表:
| hash值 | 常量名 | 节点类型 | 含义 |
|---|---|---|---|
>= 0 |
- | 普通Node | 正常链表节点,spread保证最高位=0 |
-1 |
MOVED |
ForwardingNode | 扩容占位,读写转向新数组 |
-2 |
TREEBIN |
TreeBin | 红黑树根节点包装类 |
-3 |
RESERVED |
ReservationNode | compute()方法占位节点 |
PS:RESERVED,防止并发操作同一个key,用来占位的。
11. ConcurrentHashMap 能完全保证线程安全吗?
ConcurrentHashMap 不能完全保证线程安全。
- ConcurrentHashMap 只保证自己API的原子性
- 业务代码的复合操作需要自己自己加锁控制!
例如:单独用ConcurrentHashMap的get/put这些API是线程安全的,但是在业务代码里如果,做了非原子操作,例如先get下,如果存在元素,然后在put更新下,这种场景下并发处理就可能出现线程不安全
12. ConcurrentHashMap 的并发扩容原理?
ConcurrentHashMap 并发扩容时,会先创建一个容量为table数组 2 倍的新数组nextTable;将 sizeCtl 设置为 -(1+n),表示已经处于并发扩容状态,其他线程执行put时,会根据 sizeCtl 值判断是否需要进来协助扩容。
协助扩容的流程是根据transferIndex,把旧table数组拆分成多个段,每个线程认领一段区间,将旧数组上的数据迁移到数组nextTable。旧数组上每个桶位执行迁移的时候,会标记为ForwardingNode。当每个线程完成自己的迁移任务后,再去执行自己的put逻辑,执行完后推出。
扩容结束后更新sizeCtl为新数组容量*0.75,表示下次扩容阈值。
几个关键变量:
- sizeCtl:作为扩容开关标识
- transferIndex:作为迁移任务分发器,记录还有哪些桶没迁移,哪些区间分给哪个线程
- ForwardingNode:作为桶迁移完成标记 + 访问转发标志,告诉其他线程这个桶已经搬走了,去新表查询
流程图:
13. ConcurrentHashMap 和 HashTable区别?
并发锁粒度不同:
- HashTable 用 synchronized 锁住整张表,同一时刻只允许一个线程操作,性能差。
- ConcurrentHashMap 用 CAS + synchronized 锁单个桶,并发度高于 HashTable
初始容量与扩容倍数不同:
- HashTable 初始11,扩容倍数2n+1
- ConcurrentHashMap 初始16,扩容倍数 2n,容量必须是2的幂次方
数据结构不同:
- HashTable 数组+链表
- ConcurrentHashMap 数组+链表+红黑树
二者都不允许null为key/value
三、JUC部分
1. 线程基础知识
Q: Thread#sleep() 方法和 Object#wait() 方法对比?
共同点:两者都可以暂停线程的执行。
| 对比项 | Thread.sleep() | Object.wait() |
|---|---|---|
| 所属类 | Thread |
Object |
| 是否释放锁 | 否 | 是 |
| 是否必须在同步块中调用 | 否 | 是 |
| 主要用途 | 让当前线程休眠一段时间 | 线程间通信 / 条件等待 |
| 唤醒方式 | 到时间自动恢复 | notify/notifyAll、中断、超时 |
Q:什么是线程死锁?如何避免死锁?如何检测死锁?
死锁场景:两个或多个线程互相持有对方需要的锁,都在等待对方释放,导致所有线程永久阻塞,程序无法继续执行!
代码案例:
java
public class DeadLockDemo {
private static final Object lockA = new Object();
private static final Object lockB = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
synchronized (lockA) {
System.out.println("线程1拿到 lockA");
try { Thread.sleep(100); } catch (InterruptedException e) {}
synchronized (lockB) {
System.out.println("线程1拿到 lockB");
}
}
});
Thread t2 = new Thread(() -> {
synchronized (lockB) {
System.out.println("线程2拿到 lockB");
try { Thread.sleep(100); } catch (InterruptedException e) {}
synchronized (lockA) {
System.out.println("线程2拿到 lockA");
}
}
});
t1.start();
t2.start();
}
}如何避免:
- 尽量不要嵌套加锁
- ReentrantLock#tryLock() 抢锁超时放弃
如何检测和排查死锁?
- jstack工具
bash
jstack <pid>
如果有死锁,通常会直接看到类似:能看到哪些线程死锁了,持有那些锁
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor ...
which is held by "Thread-2"
"Thread-2":
waiting to lock monitor ...
which is held by "Thread-1"
根据下面的标识去看持有什么锁
locked <0x000000...>
根据下面的标识去看当前线程在等待那些锁
waiting to lock <0x000000...>
根据下面的命令可以看出当前死锁卡在那行代码:
at com.xxx.OrderService.doXxxx(OrderService.java:123)Q:什么是乐观锁、悲观锁?有哪些例子
- 悲观锁:先加锁,然后再判断是否有线程冲突,例如 synchronized、ReentrantLock
- 乐观锁:先提交执行,如果有冲突在加锁。例如 CAS、版本号控制
Q:什么是CAS?如何解决ABA问题?
Java中的CAS在Unsafe类中有实现。
CAS操作包含三个操作数------------内存位置(V)、期望值(A)和新值(B)。
如果内存位置的值与期望值匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不作任何操作。
参考:blog.csdn.net/weixin_4359...
2. Unsafe相关
Q:Unsafe有哪些功能?
| 分类 | 核心方法 | 典型应用 |
|---|---|---|
| 堆外内存 | allocateMemory / freeMemory |
Netty、DirectByteBuffer |
| CAS操作 | compareAndSwapInt / compareAndSwapObject |
AtomicXxx、AQS |
| 线程调度 | park / unpark |
LockSupport |
| 对象操作 | allocateInstance / objectFieldOffset |
反序列化框架 |
| 类操作 | defineClass / defineAnonymousClass |
Lambda、动态代理 |
| 数组操作 | arrayBaseOffset / arrayIndexScale |
AtomicIntegerArray |
| 内存屏障 | loadFence / storeFence / fullFence |
Disruptor、volidate |
| 系统信息 | addressSize / pageSize |
内存对齐 |
堆外内存使用场景?
在 I/O 通信过程中,会存在堆内内存到堆外内存的数据拷贝操作,对于需要频繁进行内存间数据拷贝且生命周期较短的暂存数据,都建议存储到堆外内存。例如Netty就是这样做的。
内存屏障是什么?有什么作用?
内存屏障是一种 CPU 指令,用来解决多线程下的可见性和有序性问题。 它通过禁止指令重排序、强制写操作刷回主内存、强制读操作从主内存加载,来保证多线程间数据的正确性。在 Java 中 volatile 关键字底层就是通过插入内存屏障来实现的。
-
解决指令重排问题对多线程场景下的影响
-
Unsafe涉及的内存屏障方法如下:
内存屏障如何解决指令重排问题:
Unsafe的CAS操作?
CAS(Compare And Swap)比较并交换,是一种无锁原子操作。 如果内存中的值等于期望值,则将其更新为新值,否则不做任何操作,整个过程是原子的。
Unsafe的线程调度操作有哪些?
核心方法:
3. volatile关键词
volatile 两大作用
-
保证可见性
- 写:修改volatile变量 → 立即刷新到主内存
- 读:读取volatile变量 → 从主内存重新加载
-
禁止指令重排序(通过内存屏障实现)
- 写屏障:写操作前后插入屏障,保证之前操作不会重排到写之后
- 读屏障:读操作前后插入屏障,保证之后操作不会重排到读之前
注意:volatile不保证原子性!
java
volatile int count = 0;
count++; // 非原子!读-改-写三步,volatile救不了!4. synchronized关键字
synchronized 是 Java 内置的互斥同步锁,基于 JVM 层面实现,保证同一时刻只有一个线程执行同步代码块,解决多线程原子性、可见性、有序性问题!
1. synchronized锁的是什么?
- 修饰成员方法时,锁的是对象实例
java
public synchronized void my_method() {}- 修饰静态方法时,锁的是类Class
java
public static synchronized void my_method() {}2. synchronized锁信息存放在哪里?
synchronized 锁信息存储在对象头的 Mark Word 中!JVM 在字节码层面会通过 Monitor(对象监视器): monitorenter、monitorexit 2个字节码命令实现同步代码块;
css
synchronized 锁信息存储在对象头的 Mark Word 中!
对象在内存中的结构:
┌─────────────────────────────────┐
│ 对象头 Header │
│ ┌───────────────────────────┐ │
│ │ Mark Word(8字节) │ │ ← 存锁状态/hashCode/GC年龄
│ │ Klass Pointer(4/8字节) │ │ ← 指向Class对象
│ └───────────────────────────┘ │
├─────────────────────────────────┤
│ 实例数据 Fields │
├─────────────────────────────────┤
│ 对齐填充 Padding │
└─────────────────────────────────┘
Mark Word 在不同锁状态下的内容:
锁信息中包含了,持有锁线程ID、锁状态、锁冲入次数、自选情况等等。
┌──────────────┬────────────────────────────────┬──────┐
│ 锁状态 │ Mark Word内容 │标志位│
├──────────────┼────────────────────────────────┼──────┤
│ 无锁 │ hashCode│GC年龄│偏向位=0 │ 01 │
│ 偏向锁 │ 线程ID │epoch│GC年龄│偏向位=1 │ 01 │
│ 轻量级锁 │ 指向栈帧中Lock Record的指针 │ 00 │
│ 重量级锁 │ 指向Monitor对象的指针 │ 10 │
│ GC标记 │ │ 11 │
└──────────────┴────────────────────────────────┴──────┘3. synchronized 锁升级的过程?
JDK1.6后引入锁升级过程。
5. ReentrantLock锁
ReentrantLock 底层基于 AQS(AbstractQueuedSynchronizer) 实现,AQS 通过一个 volatile int state 表示同步状态,通过 CAS 修改 state,并维护一个 CLH 变体的双向等待队列来管理获取锁失败的线程。
ReentrantLock和synchronized关键词的区别?
| 对比项 | synchronized | ReentrantLock |
|---|---|---|
| 类型 | Java 关键字 | JDK 锁类 |
| 实现层面 | JVM | JDK(AQS) |
| 加锁/释放 | 自动 | 手动 |
| 是否可重入 | 是 | 是 |
| 是否支持公平锁 | 否 | 是 |
| 是否支持可中断 | 否 | 是 |
| 是否支持超时获取锁 | 否 | 是 |
| 条件队列 | wait/notify,单一隐式队列 | Condition,支持多个条件队列 |
| 性能 | JDK6 后优化很好 | 高灵活性场景更有优势 |
6. AQS相关
AQS(AbstractQueuedSynchronizer) 是 Java 并发包的核心基础框架,Doug Lea 大神设计,提供了一套基于 FIFO 等待队列的同步器实现框架,ReentrantLock、Semaphore、CountDownLatch 等都基于它实现!
2. AQS锁的是什么?
AQS 本身不锁任何东西,它只是一个框架!它提供两个核心能力:
-
通过 CAS 原子管理 state 变量
-
通过 CLH 队列管理等待线程的 park/unpark
AQS 锁的本质:
不同子类实现中,state的含义不同:
3. AQS的主要组成部分,核心结构,AQS 核心变量有哪些?
AQS主要由三部分组成:
- state 同步状态
- CLH先进先出双向队列(包含头head和尾tail),线程从尾部入队,通过CAS方式修改tail
- Condition条件队列
java
/**
AQS
├── state:资源状态
├── Sync Queue:同步队列
│ ├── head
│ ├── tail
│ └── Node
│ ├── waitStatus
│ ├── prev
│ ├── next
│ ├── thread
│ └── nextWaiter
├── CAS:修改 state / 入队
└── park/unpark:阻塞与唤醒
*/
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
// 同步状态
private volatile int state;
// 同步队列头节点
private transient volatile Node head;
// 同步队列尾节点
private transient volatile Node tail;
static final class Node {
// 等待状态
volatile int waitStatus;
// 前驱节点
volatile Node prev;
// 后继节点
volatile Node next;
// 当前线程
volatile Thread thread;
// 条件队列 / 模式标记
Node nextWaiter;
}
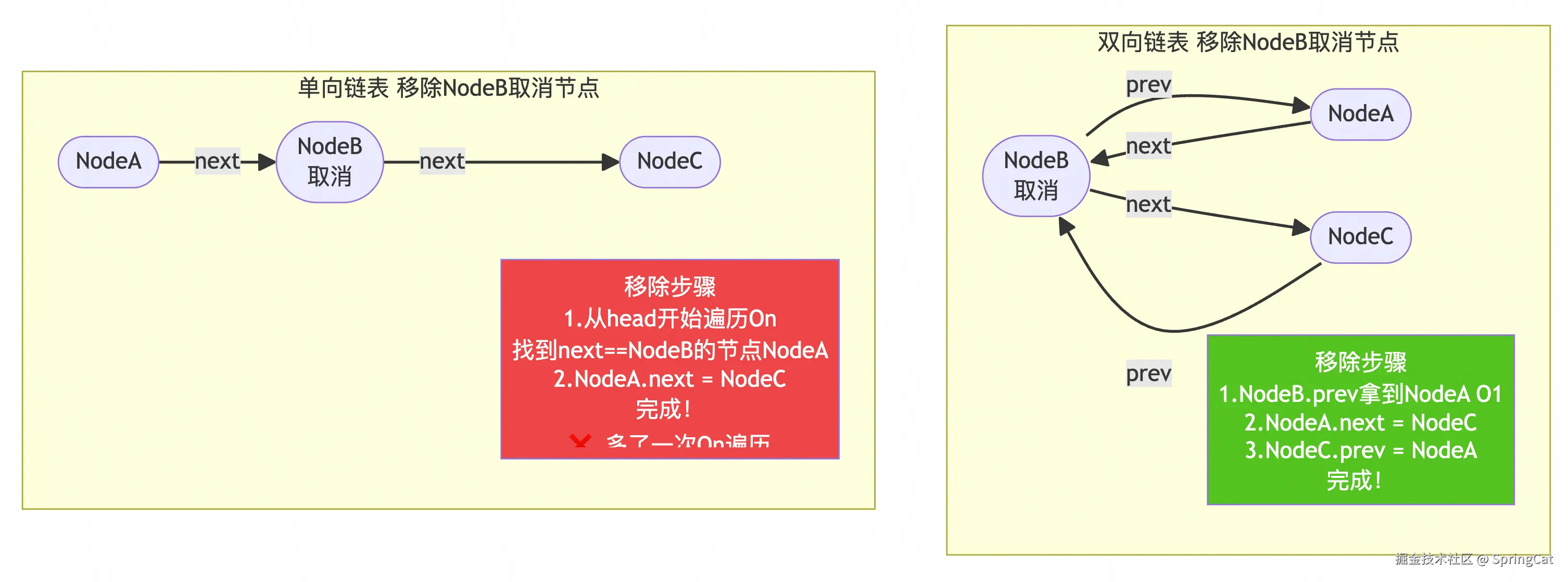
}4. CLH 等待队列是什么?有哪些作用?为什么是双向链表而不是单向链表?
CLH 队列是 AQS 中用来管理获取锁失败的等待线程的双向链表队列,线程获取锁失败后封装成 Node 入队并 park 挂起,锁释放后 unpark 唤醒队头线程重新竞争!用双向链表是因为取消节点、唤醒后继、从尾往前遍历这些操作都需要访问前驱节点,单向链表做不到!
CLH队列结构:
CHL队列的作用:
- 作用一:管理等待线程,保证有序,线程等待超时或被中断,需要从队列移除
- 作用二:实现公平性,队列中挂起的线程按照先来后到等待被唤醒
为什么用双向链表?
双向链表的话,当某个待被唤醒的节点线程是取消或者中断状态,需要从链表中移除,只需要移动前后指针即可。如果是单向链表的话需要遍历一次,拿到前或者后节点然后移动指针
如下图所示:
5.AQS 中 Node 的 waitStatus 有哪些值,分别表示什么?
waitStatus 共有 5个值:0(初始)、-1 SIGNAL、-2 CONDITION、-3 PROPAGATE、1 CANCELLED,记住规律:大于0就是取消,小于0都是有效状态!
arduino
static final class Node {
static final int CANCELLED = 1; // 已取消
static final int SIGNAL = -1; // 后继需要唤醒
static final int CONDITION = -2; // 条件队列等待
static final int PROPAGATE = -3; // 共享模式传播
// 0 // 初始状态
volatile int waitStatus;
}图示如下:
6.Condition 条件队列的作用是什么?Condition 如何精确唤醒线程?Condition 原理?wait和notify、park和unpark?以及 Condition 和 CLH 两个队列的关系?
Condition 是什么?作用是什么?
Condition 的核心作用是线程间通信,解决 Object.wait/notify 只有一个等待集合、无法精确唤醒指定类型线程的问题!一个 Lock 可以创建多个 Condition,每个对应独立等待队列,实现精确唤醒!
Condition 是通过两个单向链表实现:
java
// ConditionObject 是 AQS 的内部类
public class ConditionObject implements Condition {
// 条件队列头节点
private transient Node firstWaiter;
// 条件队列尾节点
private transient Node lastWaiter;
// 核心方法
void await(); // 释放锁,进入条件队列等待
void signal(); // 唤醒条件队列头节点
void signalAll(); // 唤醒条件队列所有节点
void awaitUninterruptibly(); // 不响应中断的等待
boolean await(long time, TimeUnit unit); // 超时等待
}Condition 和 CLH 两个队列的关系?
CLH队列是用来解决锁竞争问题的,所有线程都在抢同一把锁!但实际业务中,线程等待的原因不同,需要在不同条件满足时唤醒不同类型的线程,CLH队列做不到这个!Condition就是为了解决按条件精确唤醒的问题!
CLH 是等锁,Condition 是等条件,两种等待原因完全不同,所以需要两个队列分别管理!
Condition 是如何精确唤醒某个线程的?
每个 Condition 对象内部有一个独立的条件等待队列,不同 Condition 的队列完全隔离互不干扰!
流程与代码案例:
await():线程调用哪个 Condition 的 await(),就进哪个 Condition 的队列,同时释放锁 park 挂起。
signal():只操作当前 Condition 自己队列的 firstWaiter,把它转移到 CLH 同步队列,然后 unpark 唤醒。
java
public class BoundedBuffer {
private final ReentrantLock lock = new ReentrantLock();
// 两个独立条件队列
private final Condition notFull = lock.newCondition(); // 生产者等待队列
private final Condition notEmpty = lock.newCondition(); // 消费者等待队列
private final Queue<Integer> queue = new LinkedList<>();
private final int capacity = 5;
// ===== 生产者 =====
public void produce(int item) throws InterruptedException {
lock.lock();
try {
// 队列满了,生产者去 notFull 队列等待
while (queue.size() == capacity) {
System.out.println(Thread.currentThread().getName()
+ " 队列满了,生产者等待...");
notFull.await(); // ← 进入 notFull 条件队列💤
}
queue.offer(item);
System.out.println(Thread.currentThread().getName()
+ " 生产:" + item + " 队列大小:" + queue.size());
// 生产了一个,通知消费者可以消费了
notEmpty.signal(); // ← 只唤醒 notEmpty 队列的消费者!
} finally {
lock.unlock();
}
}
// ===== 消费者 =====
public void consume() throws InterruptedException {
lock.lock();
try {
// 队列空了,消费者去 notEmpty 队列等待
while (queue.isEmpty()) {
System.out.println(Thread.currentThread().getName()
+ " 队列空了,消费者等待...");
notEmpty.await(); // ← 进入 notEmpty 条件队列💤
}
int item = queue.poll();
System.out.println(Thread.currentThread().getName()
+ " 消费:" + item + " 队列大小:" + queue.size());
// 消费了一个,通知生产者可以生产了
notFull.signal(); // ← 只唤醒 notFull 队列的生产者!
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
BoundedBuffer buffer = new BoundedBuffer();
// 3个生产者
for (int i = 0; i < 3; i++) {
int item = i;
new Thread(() -> {
for (int j = 0; j < 5; j++) {
try {
buffer.produce(item * 10 + j);
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}, "生产者-" + i).start();
}
// 3个消费者
for (int i = 0; i < 3; i++) {
new Thread(() -> {
for (int j = 0; j < 5; j++) {
try {
buffer.consume();
Thread.sleep(150);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}, "消费者-" + i).start();
}
}
}输出结果:
erlang
输出结果:
生产者-0 生产:0 队列大小:1
生产者-1 生产:10 队列大小:2
生产者-2 生产:20 队列大小:3
消费者-0 消费:0 队列大小:2
消费者-1 消费:10 队列大小:1
生产者-0 生产:1 队列大小:2
...
生产者-0 队列满了,生产者等待... ← 进notFull队列
消费者-0 消费:xx 队列大小:4 ← 消费后signal通知生产者
生产者-0 生产:xx 队列大小:5 ← 生产者被精确唤醒!不会唤醒消费者!流程图:
本质上是用业务代码控制线程去哪个队列:生产者调 notFull.await() 进生产者队列,消费者调 notEmpty.await() 进消费者队列,signal 时各取各的,天然精确!
7.AQS 获取锁失败后线程怎么处理?
获取锁失败后,线程被封装成 Node 节点 CAS 加入 CLH 队列尾部,然后进入自旋:如果前驱是 head 则再次 tryAcquire 尝试抢锁;抢不到则检查前驱的 waitStatus,如果前驱是 SIGNAL=-1 说明前驱释放锁时会唤醒自己,就放心调用 LockSupport.park 挂起;如果前驱已取消(CANCELLED=1)则跳过找有效前驱;如果前驱是 0 则 CAS 设为 SIGNAL 再重新判断。线程挂起后等待前驱节点释放锁时 unpark 唤醒,醒来后重新自旋竞争锁!
具体流程如下:
8.AQS加锁和释放锁的流程?
加锁流程
释放锁流程
9.AQS如何实现可重入锁?如何实现公平锁?
AQS实现可重入锁
AQS实现公平锁
所有等待被唤醒的线程在CLH队列中按照先来后到顺序依次被唤醒,而不需要每次重新竞争抢锁。
10.AQS独占模式和共享模式区别?
独占模式:同一时刻只有一个线程能持有锁,其他线程全部等待,如 ReentrantLock!
共享模式:同一时刻允许多个线程同时持有,如 Semaphore、CountDownLatch!核心区别在于 state 的语义和锁释放后是否传播唤醒后续节点!
7. TreadLocal
ThreadLocal是一个全局对象 ,ThreadLocal是线程范围内变量共享的解决方案。
1. ThreadLocal 数据结构,ThreadLocal、Thread、ThreadLocalMap之间的关系?
一个Thread里面,有一份自己的threadLocalMap,他的key是某个ThreadLocal对象实例的弱引用,value是ThreadLocal对象中包含的数据(强引用)
TreadLocal自己没有table数组,而是用的Thread里的threadLocalMap中的table数组。
数据结构图解
ThreadLocal 为什么线程安全?
ThreadLocal中存放的数据是使用Thread下的threadlocalMap作为容器的,即线程独享。
ThreadLocalMap 的 key 和 value 分别是什么?
key是某个ThreadLocal对象实例的弱引用,value是ThreadLocal对象中包含的数据(强引用)。
例如UserContext内定义了一个TreadLocal对象
UserInfo user = UserContext.get();
即向Thread获取TreadLocalMap,key为UserInfo内TreadLocal实例弱引用,value为UserInfo
图解关系:
2. 初始容量,扩容机制
Tread中的TreadLocalMap初始table数组容量为16,必须为2的n次幂。扩容阈值为容量的2/3。扩容后新table数组大小为旧数组的2倍。
3. set、get核心流程
set流程
get流程
ThreadLocalMap 如何解决 hash 冲突?
Thread下的TreadLocalMap虽然是一个Map结构,但是实际上遇到hash冲突时不会形成链表,而是线形探测转移到另一个桶去,如果还是冲突就继续探测。
线形探测算法:
java
i = (i + 1) & (len - 1)Q:如果线形探测到table数组末尾或者边界,怎么办?
A:自动回到数组头部,形成环形;
Q:如果探测了整个数组还没找到空桶位怎么办?
A:不可能出现这个情况,因为数组始终是不满状态,容量占用到临界阈值就自动扩容了,所以始终会有充裕,不会出现数组全满情况。
4. key 为什么设计成弱引用?
为什么key要为弱引用?
线程方法执行结束,可以使ThreadLocal的key引用在GC时被主动回收,不需要像强引用那样要主动清除key引用。当key变为null的时候,下次set/get时,会通过TreadLocal自己的清理逻辑将value也回收。
弱引用能完全解决内存泄漏吗?为什么?
不能。例如线程池场景、静态变量修饰等。参考下面问题的解释。
5. ThreadLocal 为什么会内存泄漏?如何正确避免内存泄漏?
什情况下会出现内存泄露?
- 1.线程池中使用TreadLocal,在线程任务完结的时候没有主动remove销毁。线程池回收这个线程实例,但是线程对象本身不会被销毁,所以TreadLocalMap中存放的数据也不会被回收,无效占用内存。
- 2.key 变 null 后 value 无法回收。
原理:key变为null后,弱引用被GC回收,无法通过get/set定位到数组桶位上的Entry(无法通过寻址算法定位桶位),但是这个ThreadLocal中存放的value对象还被Entry强引用着无法回收,无效占用内存。
解决办法:
- 等待下次set/get时TreadLocal自己的探测清理,但是不能保证一定可以清理
- 等待线程被回收
- 在线程方法中finally中提前调用remove。
- TheadLocal对象被静态变量修饰,key永远不会被GC回收,例如在UserContext中使用。
如何避免内存泄露?
- 1.TreadLocal存储信息用完后,在线程任务完结的时候主动remove销毁。例如登陆用户会话信息,在请求执行完结后再拦截器postProcessor中销毁。
- 2.避免使用线程池中的线程对象去使用TreadLocal,防止线程执行完后被线程池回收但线程并未销毁。
- 3.headLocal对象被静态变量修饰,key永远不会被GC回收,例如在UserContext中使用。
什么情况下key会变成null?
示例代码:
java
public class OrderService {
public void processOrder(Order order) {
// ⚠️ 局部变量!不是static!
ThreadLocal<Order> orderTL = new ThreadLocal<>();
orderTL.set(order);
doSomething();
// ❌ 忘记 remove()
// 方法结束,orderTL 局部变量销毁
// 强引用断开!
} // ← 方法结束,orderTL 出栈,强引用消失
}流程图解:
6. 父子线程能共享 ThreadLocal 吗?
ThreadLocal 不能,因为Tread的threadLocalMap是当前线程使用,不考虑父线程。
如果需要子父线程使用,可以用 InheritableThreadLocal
7. ThreadLocalMap过期 key 的清理流程?
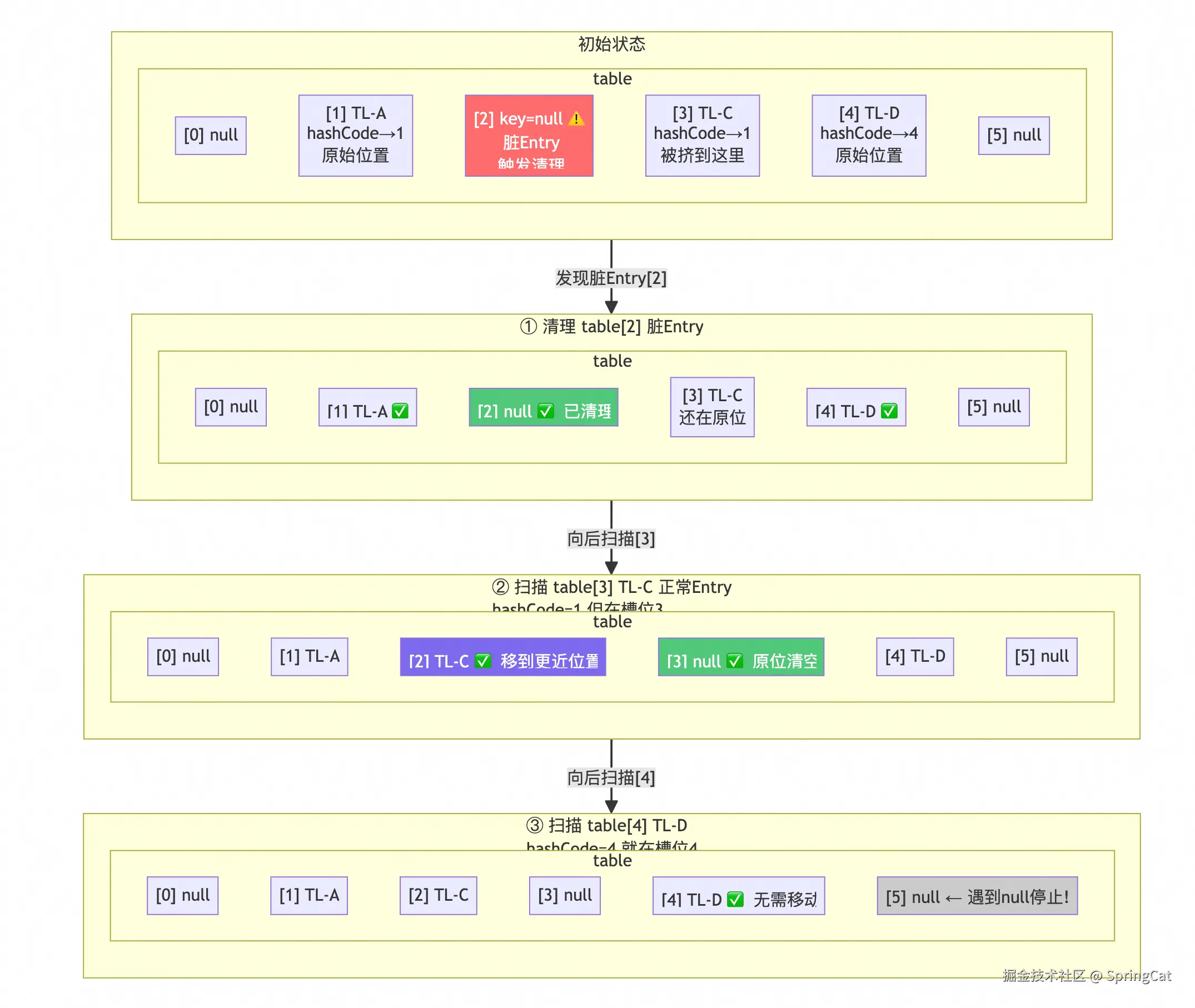
什么是探测清理
触发时机:发现某个脏Entry后,从这个位置出发向后线性扫描。
清理动作:遇到 key=null 的脏Entry 清理。遇到正常Entry 重新哈希。
停止时机:遇到 null 空槽停止。
完整流程图解
启发式清理
触发时机:新写入一个Entry后,开始log₂(n) 次抽样
清理动作:遇到 key=null 的脏Entry 清理。遇到正常Entry 重新哈希。
停止时机:抽样结束
8. 线程池
TODO
四、JVM部分
1.运行时数据区
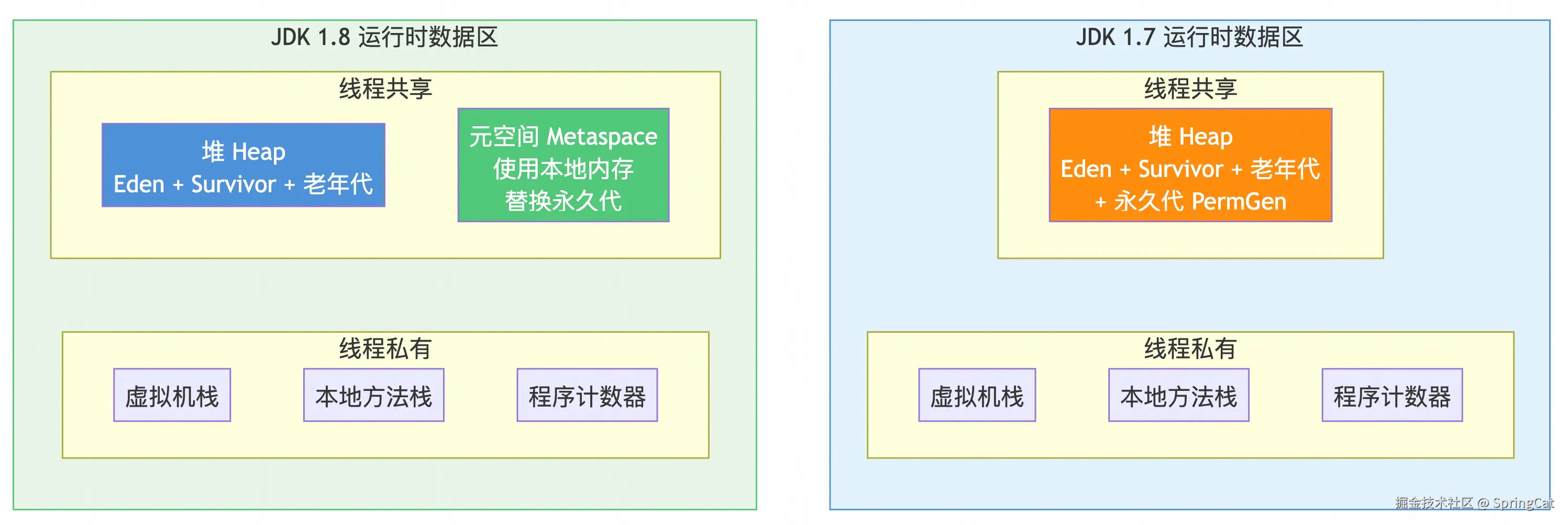
1.7和1.8版本差异
组成部分:
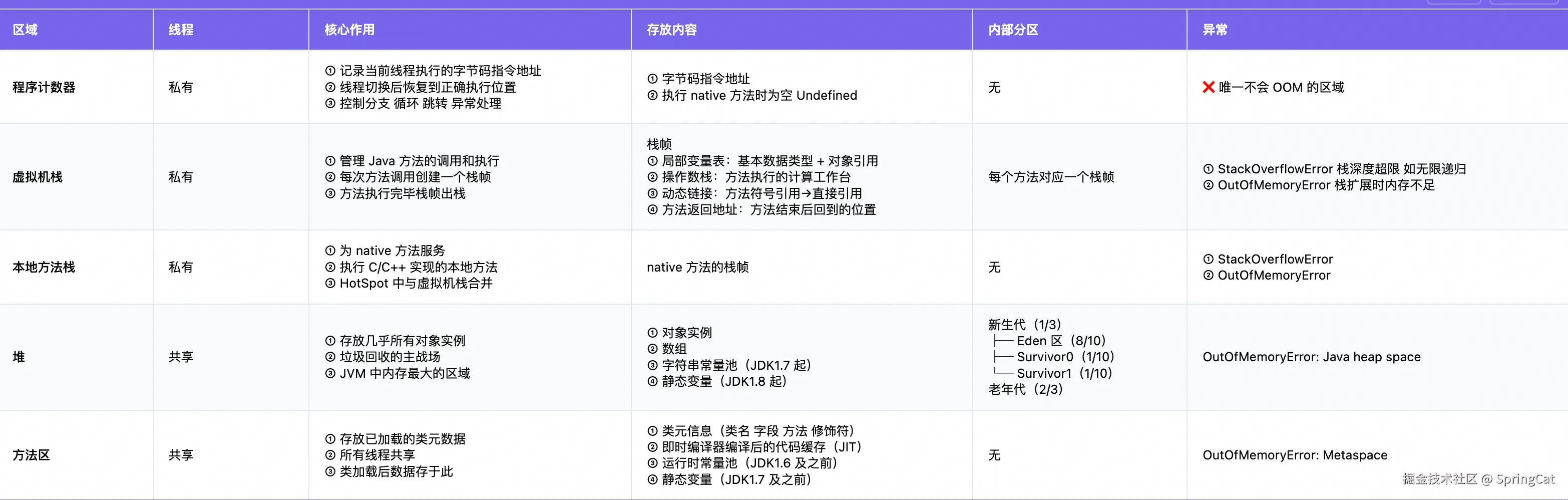
JVM 运行时数据区分为线程私有 和线程共享两部分。
线程私有(生命周期与线程相同)包含三个区域:
- 程序计数器:记录当前线程执行的字节码指令地址,是唯一不会发生 OOM 的区域
- 虚拟机栈:每个方法调用对应一个栈帧,存放局部变量表、操作数栈、动态链接、方法返回地址
- 本地方法栈:为 native 方法服务,HotSpot 虚拟机将其与虚拟机栈合并为一个
线程共享包含两个区域:
- 堆:存放几乎所有对象实例和数组,分为新生代(Eden + 两个 Survivor)和老年代
- 方法区:存放类元信息、即时编译代码缓存、常量池、静态变量
JDK 1.7 vs 1.8 差异
两个版本最核心的差异在于方法区的实现方式不同:
- JDK 1.7 用永久代 实现方法区,永久代位于堆内存中,受
-XX:MaxPermSize限制,默认大小较小,存放类元信息、运行时常量池、静态变量,容易触发OutOfMemoryError: PermGen space - JDK 1.8 废除永久代,改用元空间 实现方法区,元空间位于本地内存(堆外),默认没有大小上限,受本地内存限制,只存放类元信息和即时编译代码,触发的是
OutOfMemoryError: Metaspace
同时伴随这个变化,常量池和静态变量的存放位置也发生了迁移:字符串常量池在 JDK 1.7 就已经从永久代移入堆中,静态变量在 JDK 1.8 随 Class 对象一起移入堆中。
之所以做这个改变,主要原因是永久代大小难以评估、GC 回收效率低,使用本地内存的元空间可以动态扩展,大幅降低了 OOM 的风险。
每个区域存放什么内容
直接内存的作用是?
TODO
字符串常量池的作用?
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
ini
// 1.在字符串常量池中查询字符串对象 "ab",如果没有则创建"ab"并放入字符串常量池
// 2.将字符串对象 "ab" 的引用赋值给 aa
String aa = "ab";
// 直接返回字符串常量池中字符串对象 "ab",赋值给引用 bb
String bb = "ab";
System.out.println(aa==bb); // true2.JMM内存模型
JMM(Java Memory Model)是 Java 的并发内存访问模型,定义了线程工作内存与主内存之间的交互规则,用来屏蔽不同硬件和编译器的内存访问差异
在 JMM 里,每个线程都有自己独立的 工作内存 (也常叫本地内存),线程之间的工作内存彼此不可直接访问;而 主内存 中存放共享变量,是所有线程共享的。
如下图所示:
- Java程序运行时,每开辟一个线程都会分配一个固定大小的线程栈区域
- JVM命令参数控制线程栈内存大小:
-Xss1m,默认是512k或1M - 新开线程执行时,会将当线程执行代码所需要用到相关变量,从主内存中拷贝到工作内存中,作为变量副本。
- 线程执行过程中,更新或读取变量副本都是在工作内存执行的,并不会立刻将配置刷新回主内存。
JMM三大特性:可见性、原子性、有序性
3.java类加载过程?
4.对象创建过程?
5.垃圾回收机制
6.JVM核心参数
五、数据库部分
1. 分库分表相关
Q:为什么要分库分表?
分库分表,即把原来存放在一个数据库的一张大表里的数据,拆分到多个数据库、多个表中去,降低单表数据量过大查询效率降低。(数据量太大单库单表扛不住了)
常用分表拆分方式:
- 按照用户ID取模分表
- 按照时间范围分表
- 按业务类型分表
json
例如按 user_id % 4 分表:
user_id % 4 = 0 放 user_order_0
user_id % 4 = 1 放 user_order_1
...
user_order_0
user_order_1
user_order_2
user_order_3常用分库方式:
- 按照用户ID取模分库
- 按照单元区域分库
- 按业务类型分库
分库分表带来的问题?
- 分页查询成本增加
- 分布式事务问题
- 扩容和数据迁移困难
分库分表场景下,如何做分页查询?
- 场景1: 单分片分页,根据用户ID取模或者按天分表,命中单个分片表,等同于单库单表分页
- 场景2: 跨分片分页,查询数据量小,每个分片取少量数据(例如按照查询条件取每个分片前10条),应用层业务逻辑聚合。
- 场景3: 跨分片分页,查询数据量大,使用游标分页。
排序字段唯一:
sql
order by create_time desc, id desc每次查询,基于上一页最后一条数据的排序字段值(如 create_time 或 id)作为游标进行查询
sql
-- 假设上一页最后一条数据的 create_time 是 '2023-10-01 12:00:00',id 是 1005
SELECT * FROM order_table
WHERE create_time > '2023-10-01 12:00:00'
OR (create_time = '2023-10-01 12:00:00' AND id > 1005)
ORDER BY create_time, id
LIMIT 10;在每个分片,从游标位置开始往后查询,不需要每个分片下全表查询。
应用场景:Feed 流、消息列表、无限滚动加载。
- 场景4: 跨分片分页,任意跳转某一页,使用二次查询法
第一次查询:查各分片 count
shard_0:80 条
shard_1:120 条
shard_2:50 条第二步:根据页码推算目标区间
假设:
第 3 页 每页 20 条
那么目标区间就是:
全局第 41 ~ 60 条
第三步:根据各分片数量,算目标区间落在哪些分片
如果全局顺序等于分片顺序拼接,例如:
shard_0 -> shard_1 -> shard_2
那么全局位置区间就是:
shard_0:第 1 ~ 80 条
shard_1:第 81 ~ 200 条
shard_2:第 201 ~ 250 条第 41~60 条显然就在 shard_0。
如果命中多个分片,需要在每个分片上过滤到业务数据,应用层聚合
2. 索引实效场景
- 条件中有 or,且 or 两边不能同时命中索引:使用 OR 连接条件时,只要其中一个条件没有索引,整个查询就会失效,导致全表扫描。
- 对索引列做函数、运算、类型转换
- 联合索引不满足最左前缀原则:比如索引是 (a,b,c),但查询条件直接写 b=1 and c=2,由于跳过了最左列 a,通常无法有效使用这个联合索引。
- 使用 !=、<>、not in、not like 等负向条件
- like 以 % 开头
sql
案例:
索引:name
失效 SQL:WHERE name LIKE '%张%' 或 WHERE name LIKE '%张'
原因:B+ 树是从左向右构建的,前缀未知无法定位起点,只能全表扫描。六、中间件部分
1. Redis相关
2. RPC相关
TODO
3. MQ相关
TODO
4. Netty与网络IO
TODO
七、Spring部分
Q:Spring AOP中的动态代理如何实现?
八、AI部分
TODO
九、场景题
TODO