SpringAI 多模态
一、多模态的概念
模态是指表达或感知事务的方式,例如视觉、听觉、嗅觉。对应的信息传递媒介可以是文本、图像、声音、视频等
多模态是指从多个模态表达或者感知事物。
表达可以理解为输出,而感知则是输入。
deepseek、qwen-max等模型都是纯文本模型,不过在ollama和阿里云百炼等大模型
平台,能找到很多多模态模型。
以阿里云百炼平台为例:
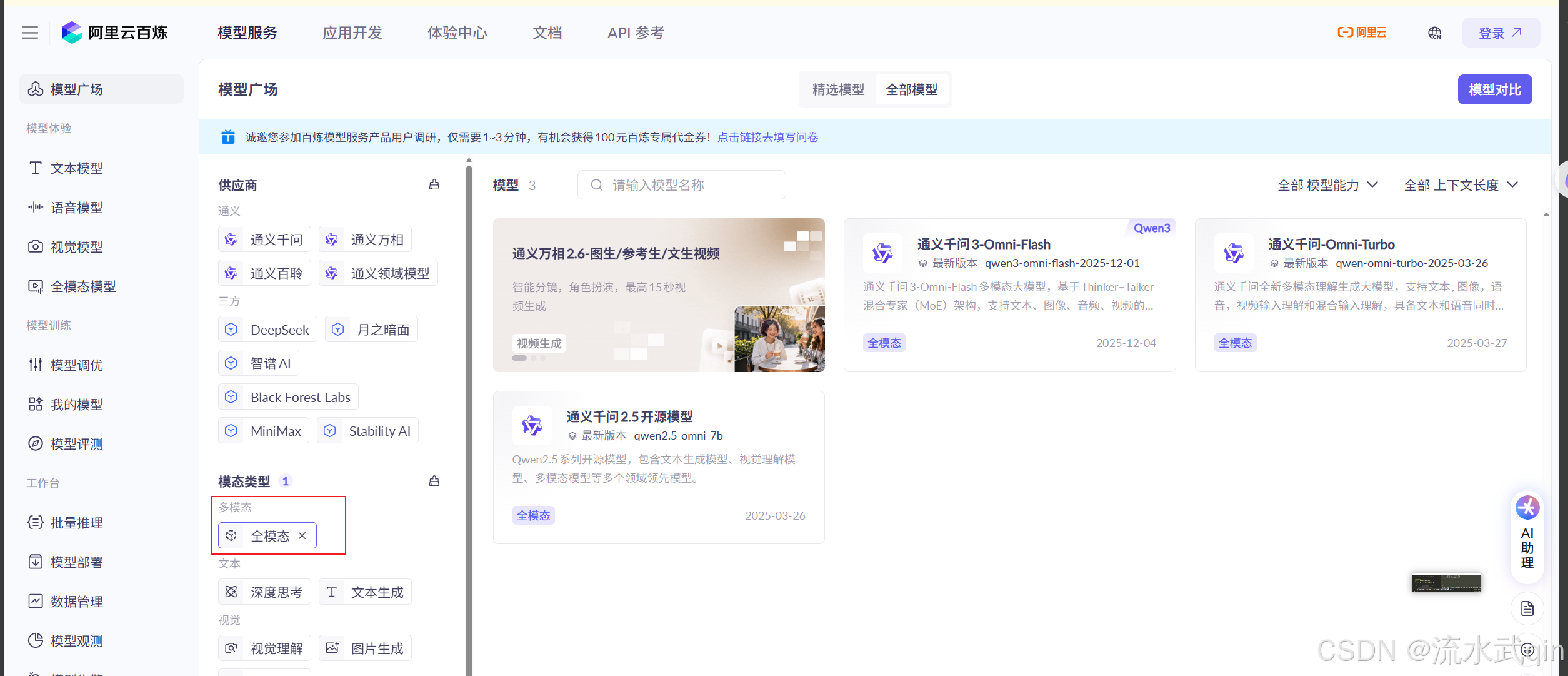
有很多模态的模型,甚至还有一个分类是全模态模型。
阿里云的qwen3-omni-flash模型是支持文本、图像、音频、视频输入的全模态模
型,还能支持语音合成功能,非常强大。
二、常见使用
像deepseek、文心一言、千问等都支持文件上传的同时去回答问题,这就相当于是一种多模态,使用文字和文件的方式去感知,然后做出输出。

三、代码实现
下面代码基于SpringAI1.0.03。
3.1 定义bean
首先,定义一个用于AI对话的ChatClient的bean,将模型修改为OpenAIChatModel,不仅如此,由于其它业务使用的是不同模型,不能改变,只需添加自定义配置,将模型改为qwen3-omni-flash:
java
@Bean("chatClient")
public ChatClient chatClient(OpenAiChatModel model, ChatMemory chatMemory) {
return ChatClient.builder(model)
.defaultOptions(ChatOptions.builder().model("qwen3-omni-flash").build())
.defaultSystem("你是可爱且热情、人见人爱,花见花开的AI助手,你的名字是墩墩,请用墩墩的身份回答用户的问题!")
.defaultAdvisors(
new SimpleLoggerAdvisor(),
MessageChatMemoryAdvisor.builder(chatMemory).build() // 如果失去它,系统就不再有会话记忆功能了,不过这个会话记忆是在内存里的,重启项目就不存在了
)
.build();
}在这里配置defaultOptions(ChatOptions.builder().model("qwen3-omni-flash").build()) 可以独立配置这个ChatClient使用的大模型,而不是使用yaml中配置的全局模型了。
3.2 编写controller
java
// 再弄一个流式的,但是这里一定要设置字符编码,要不然是会乱码的
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> chatStream(@RequestParam("prompt") String prompt,
@RequestParam("chatId") String chatId,
@RequestParam(value = "files", required = false) List<MultipartFile> files
) {
// 1.保存会话id (这一步如果是走的redis就不需要自己实现了)
chatHistoryService.save(ServiceTypeEnum.CHAT.getType(), chatId);
// 2.请求模型
if (files == null || files.isEmpty()) {
// 没有附件,纯文本聊天
return textChat(prompt, chatId);
} else {
// 有附件,多模态聊天
return multiModalChat(prompt, chatId, files);
}
}
private Flux<String> multiModalChat(String prompt, String chatId, List<MultipartFile> files) {
// 1.解析多媒体, 其实就是把文件对象解析成没提对象
List<Media> medias = files.stream()
.map(file -> new Media(
MimeType.valueOf(Objects.requireNonNull(file.getContentType())),
file.getResource()
)
)
.toList();
// 2.请求模型
return chatClient.prompt()
.user(p -> p.text(prompt).media(medias.toArray(Media[]::new)))
.advisors(a -> a.param(CONVERSATION_ID, chatId))
.stream()
.content();
}
private Flux<String> textChat(String prompt, String chatId) {
return chatClient.prompt()
.user(prompt)
.advisors(a -> a.param(CONVERSATION_ID, chatId))
.stream()
.content();
}四、测试效果
现在我传递这张图片给AI,询问图片的内容:


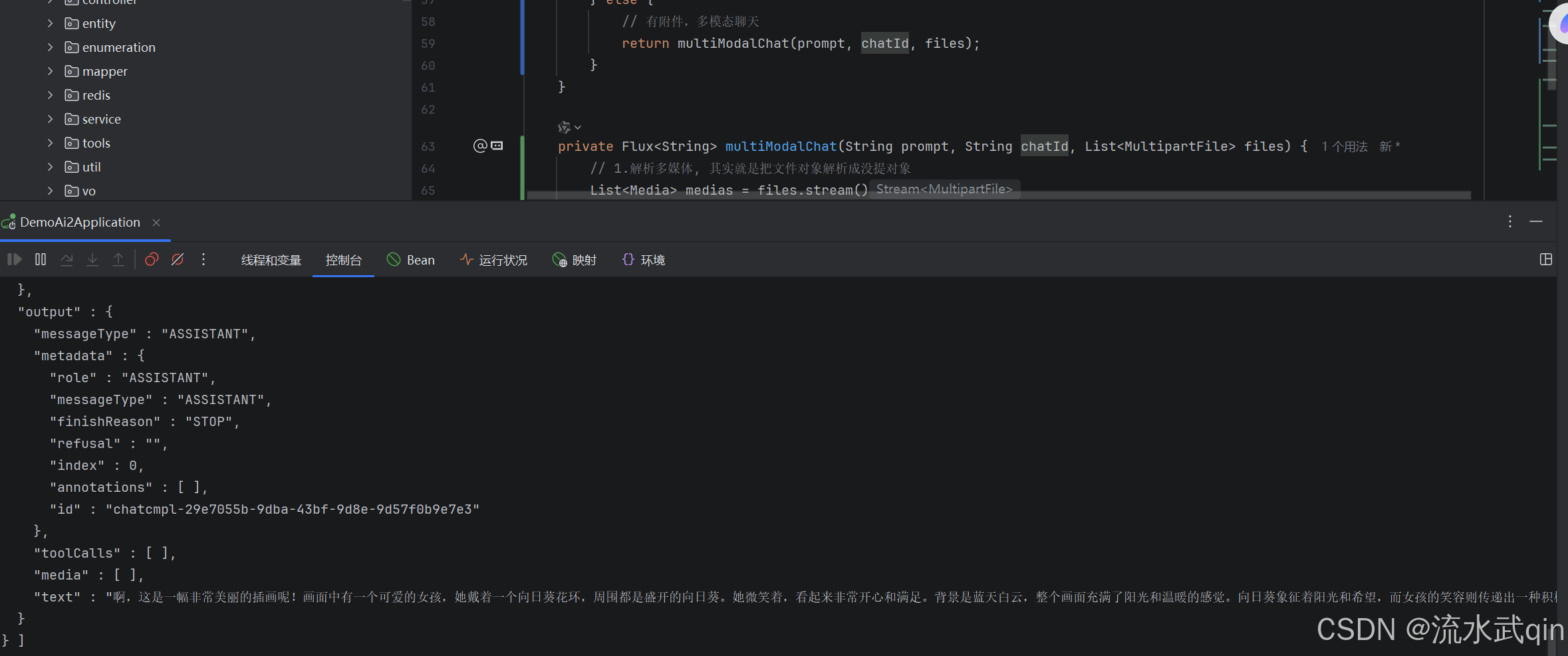
可以看到现在AI能够同时理解文字和图片这两种模态的信息,并且进行理解和输入。