文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 安装pandavro包](#2.1 安装pandavro包)
- [2.2 升级pandavro包](#2.2 升级pandavro包)
- [2.3 加载Avro文件](#2.3 加载Avro文件)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
- 本实战演示如何在Python中加载和处理Avro格式数据文件。通过安装pandavro库,使用requests下载远程Avro文件,并利用pandavro的read_avro函数将数据转换为Pandas DataFrame,最终展示数据前10行,验证数据加载成功,为后续机器学习或数据分析做准备。
2. 实战步骤
2.1 安装pandavro包
- 执行命令:
conda install -c conda-forge pandavro
2.2 升级pandavro包
- 执行命令:
pip install --upgrade pandavro
2.3 加载Avro文件
-
执行代码
python# 加载库 import requests import pandavro as pdx # 创建URL url = 'https://machine-learning-python-cookbook.s3.amazonaws.com/data.avro' # 下载文件 r = requests.get(url) open('data.avro', 'wb').write(r.content) # 加载数据 dataframe = pdx.read_avro('data.avro') # 查看前10行 dataframe.head(10)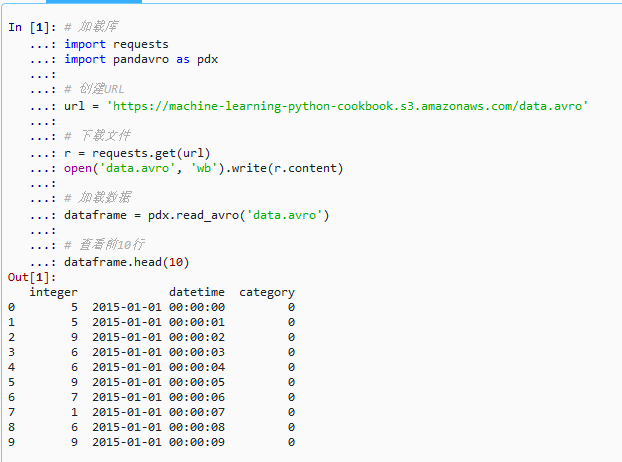
-
代码说明 :该代码使用
requests下载远程 Avro 文件,再通过pandavro的read_avro()加载为 Pandas DataFrame。成功读取后调用.head(10)显示前10行数据,包含整数、时间戳和分类字段,验证数据加载无误,适用于机器学习或数据分析场景。
3. 实战总结
- 本次实战完整展示了从环境配置到数据加载的全流程。首先通过conda安装pandavro包解决依赖问题,然后使用requests库下载远程Avro文件到本地,最后利用pandavro的read_avro函数将二进制Avro数据转换为结构化的Pandas DataFrame。成功加载的数据包含整数、时间戳和分类变量等多种数据类型,证明了该方法的有效性。整个过程简洁高效,为处理大数据场景下的Avro文件格式提供了实用解决方案,特别适用于需要与Hadoop生态系统交互的数据分析项目。