NVIDIA在2026年提出的Alpamayo-R1(AR1)视觉-语言-动作模型,旨在提升自动驾驶在复杂场景中的安全性和泛化能力。该模型突破传统模仿学习,引入因果推理机制(Chain of Causation),通过结构化因果标注、模块化架构(Cosmos-Reason推理核心+扩散轨迹解码器)和高效视觉压缩技术,实现99ms低延迟响应。采用三阶段训练策略,最终在规划精度(提升12%)、安全性(冲突率降低35%)和推理质量(提升45%)方面表现优异,并已成功应用于实车测试。
Ref:https://arxiv.org/pdf/2511.00088
这份由 NVIDIA 在 2026 年初发布的论文介绍了一种名为 Alpamayo-R1 (AR1) 的视觉-语言-动作模型(VLA) 。该模型的核心目标是解决自动驾驶在长尾场景(即少见且复杂的危险情况)中表现脆弱的问题,通过赋予 AI "因果推理"能力来提升驾驶的安全性和泛化性 。
以下是对该研究的系统性讲解:
1. 核心突破:从"模仿"到"理解"
传统的端到端(E2E)自动驾驶模型主要依靠模仿学习,它们虽然擅长处理常规路况,但在安全关键的长尾场景中,由于缺乏对因果关系的理解,往往表现得像个"只会背书不会思考"的学生 。
Alpamayo-R1 引入了类似 OpenAI o1 或 DeepSeek-R1 的推理范式,让汽车在做出驾驶动作前,先生成一段逻辑严密的因果链(Chain of Causation, CoC) 。
2. 三大技术创新
该系统通过以下三个支柱构建而成:
-
因果链(CoC)数据集 : * 解决痛点:现有数据集的推理往往很模糊(例如"请小心"),或者包含不可见的未来信息(因果混淆) 。
- 创新点 :AR1 使用了一种结构化的因果标注框架,强制模型必须基于当前观察到的历史证据 来推导出具体的驾驶决策(如"为了避开右侧路障,向左小幅转向并减速") 。
-
模块化 VLA 架构:
-
大脑 (Cosmos-Reason):基于专门为物理 AI 设计的 Cosmos-Reason 多模态大模型,具备物理常识和具身推理能力 。
-
手脚 (扩散轨迹解码器):为了保证实时性,AR1 没有像普通 LLM 那样用文本输出路径点,而是采用基于**流匹配(Flow Matching)**的扩散模型,生成符合动力学约束的连续轨迹 。
-
视觉压缩 :通过 Triplane 或 Flex 等高效视觉编码技术,将多摄像头视频压缩高达 20 倍,从而在强大的 RTX 6000 平台上实现 99ms 的超低延迟,满足实时驾驶需求 。
-
-
多阶段训练策略:
-
第一步:动作注入:让模型学会预测车辆控制参数 。
-
第二步:诱导推理(SFT):在 CoC 数据集上进行监督微调,教模型"开口说话"解释理由 。
-
第三步:强化学习(RL)对齐:这是提升逻辑质量的关键。通过教师模型反馈(LRM)和因果一致性奖励,确保模型**"说的和做的一致"**,并惩罚不安全或不合逻辑的推理 。
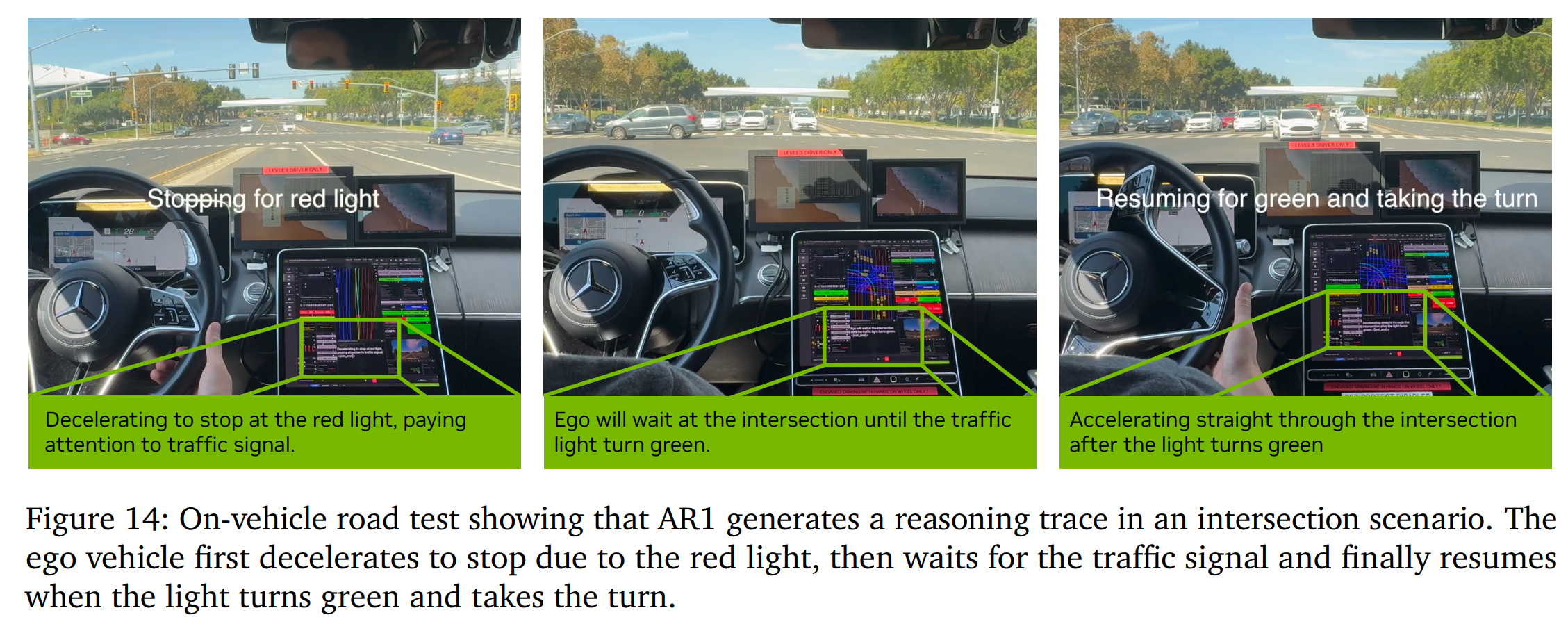
3. 性能表现与实战验证
-
规划精度提升 :在具有挑战性的案例中,AR1 的规划准确度比纯轨迹模型提升了 12% 。
-
安全性增强 :在闭环仿真中,车辆的近距离冲突率(Close Encounter Rate)降低了 35% 。
-
推理质量 :经过 RL 后训练,推理逻辑的质量提升了 45% ,言行一致性提升了 37% 。
-
实车路测:AR1 已成功部署在测试车上,能够自主应对复杂的城市道路场景(如红绿灯识别、无保护转弯、绕行建筑区) 。