
文章目录
-
- 开篇理解:Agent 的记忆系统 {#开篇理解}
-
- [1.1 核心概念:为什么 Agent 需要记忆?](#1.1 核心概念:为什么 Agent 需要记忆?)
- [1.2 记忆系统的三层架构](#1.2 记忆系统的三层架构)
- [1.3 持久化方案对比](#1.3 持久化方案对比)
- [Version 1:多文件快速检索与问答](#Version 1:多文件快速检索与问答)
-
- [2.1 RAG 的三级架构](#2.1 RAG 的三级架构)
- [2.2 Qwen-Agent 中的检索实现](#2.2 Qwen-Agent 中的检索实现)
- [Version 2:海量文件快速索引(ES)](#Version 2:海量文件快速索引(ES))
-
- [3.1 为什么需要 Elasticsearch?](#3.1 为什么需要 Elasticsearch?)
- [3.2 Elasticsearch 基础](#3.2 Elasticsearch 基础)
- [3.3 精细化索引:段落级别检索](#3.3 精细化索引:段落级别检索)
- [3.4 集成到 Qwen-Agent](#3.4 集成到 Qwen-Agent)
- [Version 3:添加向量检索功能](#Version 3:添加向量检索功能)
-
- [4.1 为什么需要向量检索?](#4.1 为什么需要向量检索?)
- [4.2 Qwen3-Embedding 基础](#4.2 Qwen3-Embedding 基础)
- [4.3 文本分块策略](#4.3 文本分块策略)
- [4.4 集成向量检索到 ES](#4.4 集成向量检索到 ES)
- [Version 4:添加外部数据源(AI 搜索 MCP)](#Version 4:添加外部数据源(AI 搜索 MCP))
-
- [5.1 为什么需要外部数据源?](#5.1 为什么需要外部数据源?)
- [5.2 Tavily-MCP 集成](#5.2 Tavily-MCP 集成)
- [5.3 整合本地 RAG 和网络搜索](#5.3 整合本地 RAG 和网络搜索)
- [Version 5:界面美化](#Version 5:界面美化)
-
- [6.1 Gradio 基础](#6.1 Gradio 基础)
- [6.2 构建现代化界面](#6.2 构建现代化界面)
- [6.3 Stream 模式优化](#6.3 Stream 模式优化)
- 实战总结与最佳实践 {#总结}
-
- [7.1 知识点汇总](#7.1 知识点汇总)
- [7.2 完整技术栈](#7.2 完整技术栈)
- [7.3 常见问题诊断](#7.3 常见问题诊断)
- [7.4 最佳实践](#7.4 最佳实践)
- [7.5 进阶方向](#7.5 进阶方向)
- 结语
- 转载声明:
开篇理解:Agent 的记忆系统 {#开篇理解}
1.1 核心概念:为什么 Agent 需要记忆?
想象一下,如果一个人每次对话都从零开始,那会是什么样子?这就是原生 Agent 的困境------它像金鱼一样只有短期记忆。
原生 Agent 的问题:
- ✅ 临时性:对话或上传的文件仅存储在内存列表中,生命周期仅限单次请求
- ❌ 低效性:每次都要重新解析文档,无法处理上亿级别的文档量
- ❌ 无记忆:无法跨会话保留学习到的知识
1.2 记忆系统的三层架构
为了解决这些问题,我们需要构建一个完整的记忆系统:
第一层:短期工作记忆(Short-term Memory)
- 存储位置:内存列表
- 用途:处理当前会话中的临时信息
- 特点:快速访问,但易失
第二层:长期语义记忆(Long-term Semantic Memory)
- 存储位置:文件系统或数据库
- 用途:持久化存储知识,支持跨会话访问
- 特点:持久化,可检索
第三层:高效感知索引(Efficient Perception Index)
- 存储位置:倒排索引&向量索引
- 用途:毫秒级检索海量数据
- 特点:支持复杂的关键词和语义混合检索
1.3 持久化方案对比
| 维度 | File Cache (Qwen Agent 默认) | Elasticsearch |
|---|---|---|
| 存储内容 | 纯文本 | 倒排索引&向量 |
| 启动过程 | 慢(需加载所有缓存到内存) | 快(索引直接存在磁盘) |
| 内存消耗 | 高(1G 文档=1G+ 内存) | 低(仅热点缓存) |
| 检索方式 | 遍历内存列表 | 数据库高效算法(BKD-Tree/倒排) |
| 适用场景 | 小规模文档(<1000 份) | 大规模文档(百万级 +) |
核心差异:缓存 vs 索引
💡 学习提示:选择方案时,先评估你的文档规模。如果是企业级应用(100+ 文档),优先考虑 Elasticsearch;如果是个人项目或原型验证,File Cache 足以。
Version 1:多文件快速检索与问答

2.1 RAG 的三级架构
在 Qwen-Agent 中,RAG(检索增强生成)采用三级架构,每一层建立在前一层的基础上:
级别一:检索(Retrieval)
核心思想:将长上下文分割成短块,只保留最相关的块在 8k 上下文中。
挑战:如何精准定位最相关的块?
解决方案:基于关键词的 BM25 算法
工作流程:
# 步骤1:分离指令与信息
query = "回答时请用2000字详尽阐述,我的问题是,自行车是什么时候发明的?请用英文回复。"
# 模型输出:
# {
# "信息": ["自行车是什么时候发明的"],
# "指令": ["回答时用2000字", "尽量详尽", "用英文回复"]
# }
# 步骤2:提取多语言关键词
# {
# "关键词_英文": ["bicycles", "invented", "when"],
# "关键词_中文": ["自行车", "发明", "时间"]
# }
# 步骤3:BM25检索
# 使用经典的关键词匹配算法找出最相关的文本块Python 代码实现:
import re
from typing import Dict, List
class KeywordExtractor:
"""关键词提取器"""
def separate_instruction_info(self, query: str) -> Dict[str, List[str]]:
"""
步骤1:将用户查询中的指令与非指令信息分开
Args:
query: 用户原始查询
Returns:
包含"信息"和"指令"的字典
"""
# 这是一个简化实现,实际应该使用LLM来完成
# 这里用规则作为示例
instruction_patterns = [
r"请用.*字",
r"尽量.*",
r"用.*回复",
r"详细阐述",
]
instructions = []
info_parts = [query]
for pattern in instruction_patterns:
matches = re.findall(pattern, query)
instructions.extend(matches)
# 从查询中移除指令部分
for match in matches:
info_parts = [part.replace(match, "").strip()
for part in info_parts if part.replace(match, "").strip()]
return {
"信息": info_parts,
"指令": instructions
}
def extract_multilingual_keywords(self, info: List[str]) -> Dict[str, List[str]]:
"""
步骤2:从信息部分推导多语言关键词
Args:
info: 信息部分列表
Returns:
包含中英文关键词的字典
"""
# 简化实现:基于规则提取关键词
# 实际应该使用NLP工具或LLM
keywords_zh = []
keywords_en = []
for item in info:
# 提取中文关键词
zh_words = re.findall(r'[\u4e00-\u9fff]+', item)
keywords_zh.extend(zh_words)
# 提取英文关键词(这里简化处理)
en_words = re.findall(r'[a-zA-Z]+', item)
keywords_en.extend(en_words)
return {
"关键词_中文": keywords_zh,
"关键词_英文": keywords_en
}
# 使用示例
extractor = KeywordExtractor()
query = "回答时请用2000字详尽阐述,我的问题是,自行车是什么时候发明的?请用英文回复。"
result1 = extractor.separate_instruction_info(query)
print("步骤1结果:", result1)
# result2 = extractor.extract_multilingual_keywords(result1["信息"])
# print("步骤2结果:", result2)级别二:分块阅读

问题:直接 RAG 检索常在相关块与关键词重叠不足时失效。
解决方案:暴力策略------让模型评估每个 512 字块的相关性。
工作流程:
# 步骤1:并行评估每个块的相关性
for chunk in chunks:
relevance = model.evaluate_relevance(chunk, query)
if relevance:
extract_sentences(chunk) # 提取相关句子
# 步骤2:用相关句子作为搜索词
new_queries = extract_relevant_sentences()
results = bm25_search(new_queries)
# 步骤3:生成最终答案
answer = generate_answer(results)Python 代码实现:
import concurrent.futures
from typing import List, Tuple
class ChunkReader:
"""分块阅读器 - 级别二"""
def __init__(self, model):
self.model = model
def evaluate_chunk_relevance(self, chunk: str, query: str) -> str:
"""
评估文本块与查询的相关性
Args:
chunk: 文本块(512字)
query: 用户查询
Returns:
相关句子或"无"
"""
# 这里应该调用LLM来评估相关性
# 简化实现:使用简单的关键词匹配
query_keywords = set(query.split())
chunk_words = set(chunk.split())
# 计算关键词重叠度
overlap = len(query_keywords & chunk_words)
if overlap >= 2: # 至少2个关键词匹配
# 提取包含关键词的句子
sentences = chunk.split('。')
relevant_sentences = []
for sent in sentences:
sent_words = set(sent.split())
if len(query_keywords & sent_words) > 0:
relevant_sentences.append(sent)
if relevant_sentences:
return '。'.join(relevant_sentences[:3]) # 返回前3个相关句子
return "无"
def parallel_evaluate_chunks(self, chunks: List[str], query: str) -> List[str]:
"""
并行评估所有文本块的相关性
Args:
chunks: 文本块列表
query: 用户查询
Returns:
相关句子列表
"""
relevant_sentences = []
# 使用线程池并行处理
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
# 提交所有评估任务
future_to_chunk = {
executor.submit(self.evaluate_chunk_relevance, chunk, query): chunk
for chunk in chunks
}
# 收集结果
for future in concurrent.futures.as_completed(future_to_chunk):
result = future.result()
if result != "无":
relevant_sentences.append(result)
return relevant_sentences
def search_with_relevant_sentences(self, relevant_sentences: List[str],
bm25_searcher) -> List[dict]:
"""
使用相关句子进行二次检索
Args:
relevant_sentences: 相关句子列表
bm25_searcher: BM25搜索器
Returns:
检索结果
"""
all_results = []
for sentence in relevant_sentences:
# 用相关句子作为查询词
results = bm25_searcher.search(sentence, top_k=3)
all_results.extend(results)
# 去重并按相关性排序
unique_results = self._deduplicate_and_rank(all_results)
return unique_results[:10] # 返回前10个结果
def _deduplicate_and_rank(self, results: List[dict]) -> List[dict]:
"""去重和排序"""
seen = set()
unique = []
for result in results:
content_hash = hash(result['content'])
if content_hash not in seen:
seen.add(content_hash)
unique.append(result)
# 按得分排序
unique.sort(key=lambda x: x['score'], reverse=True)
return unique
# 使用示例
# chunk_reader = ChunkReader(model)
# chunks = load_chunks_from_documents() # 加载文档块
# relevant_sentences = chunk_reader.parallel_evaluate_chunks(chunks, query)
# results = chunk_reader.search_with_relevant_sentences(relevant_sentences, bm25_searcher)级别三:逐步推理
问题:多跳推理问题,需要多次检索才能回答。
解决方案:将级别二的智能体封装为工具,由工具调用智能体调用。
经典示例:
问题: "与第五交响曲创作于同一世纪的交通工具是什么?"
推理过程:
1. Lv3智能体提出子问题1: "贝多芬的第五交响曲是在哪个世纪创作的?"
→ Lv2智能体回答: "19世纪"
2. Lv3智能体提出子问题2: "19世纪期间发明了什么交通工具?"
→ Lv2智能体回答: "自行车于19世纪发明"
3. Lv3智能体整合所有信息,回答原始问题: "自行车"Python 代码实现:
from typing import Dict, Any
class MultiHopReasoner:
"""多跳推理器 - 级别三"""
def __init__(self, level2_agent):
self.level2_agent = level2_agent
self.memory = []
def answer_with_reasoning(self, question: str) -> str:
"""
通过多跳推理回答复杂问题
Args:
question: 用户问题
Returns:
最终答案
"""
max_iterations = 5 # 最多5次推理
iteration = 0
while iteration < max_iterations:
iteration += 1
# 尝试基于当前记忆回答
answer = self._try_answer(question)
if answer:
return answer
# 如果无法回答,提出新的子问题
sub_question = self._generate_sub_question(question)
print(f"推理步骤{iteration}: 提出子问题: {sub_question}")
# 调用Lv2智能体回答子问题
sub_answer = self.level2_agent.query(sub_question)
print(f"推理步骤{iteration}: 子问题答案: {sub_answer}")
# 将子问题和答案添加到记忆
self.memory.append({
"question": sub_question,
"answer": sub_answer
})
return "抱歉,我无法回答这个问题"
def _try_answer(self, question: str) -> str:
"""
尝试基于当前记忆回答问题
Args:
question: 问题
Returns:
答案或None(如果无法回答)
"""
# 这里应该调用LLM来判断是否能回答
# 简化实现:如果记忆中有足够信息,就回答
if not self.memory:
return None
# 构造上下文
context = "\n".join([
f"Q: {item['question']}\nA: {item['answer']}"
for item in self.memory
])
prompt = f"""
基于以下信息,回答问题。如果信息不足,返回"无法回答"。
{context}
问题: {question}
"""
# 这里应该调用LLM
# answer = llm.generate(prompt)
# 简化实现:检查记忆中是否直接包含答案
for item in self.memory:
if question.lower() in item['question'].lower():
return item['answer']
return None
def _generate_sub_question(self, question: str) -> str:
"""
生成子问题
Args:
question: 原始问题
Returns:
子问题
"""
# 这里应该调用LLM来生成子问题
# 简化实现:基于规则
# 示例规则:如果是"与...同一世纪"的问题
if "同一世纪" in question:
# 提取主语
parts = question.split("与")
if len(parts) > 1:
subject = parts[1].split("创作")[0].strip()
return f"{subject}是在哪个世纪创作的?"
return f"请告诉我关于{question}的背景信息"
# 使用示例
# level2_agent = Level2Agent() # 假设已经实现
# reasoner = MultiHopReasoner(level2_agent)
# answer = reasoner.answer_with_reasoning("与第五交响曲创作于同一世纪的交通工具是什么?")2.2 Qwen-Agent 中的检索实现
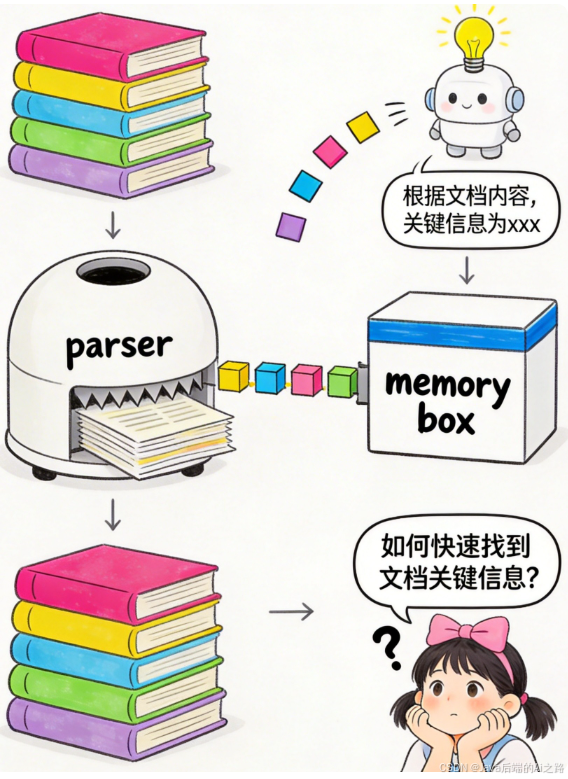
核心文件位置:
- 文档拆分代码:
qwen_agent/tools/simple_doc_parser.py - 检索逻辑代码:
qwen_agent/tools/retrieval.py - 数据存储位置:内存中(临时,单次查询)
工作流程:
# 1. Assistant初始化时传入files参数
assistant = Assistant(files=["doc1.pdf", "doc2.txt"])
# 2. Memory类自动加载两个工具
memory = Memory()
memory.load_tools([
"retrieval", # 负责检索
"doc_parser" # 负责解析和切分
])
# 3. 当用户提问时
user_query = "工伤保险和雇主险有什么区别?"
# 4. retrieval工具调用流程
# -> doc_parser解析文档 -> 切分成512字块 -> 存入内存
# -> retrieval使用BM25算法检索 -> 返回最相关的块Python 代码示例:
from qwen_agent import Assistant
from qwen_agent.agents import Assistant as QwenAssistant
# 示例1:基本的多文件问答
def basic_multi_file_qa():
"""
Version 1: 多文件快速检索与问答
"""
# 初始化Assistant,传入多个文件
assistant = QwenAssistant(
llm={
'model': 'qwen-max',
'api_key': 'your-api-key'
},
files=[
'docs/雇主责任险.txt',
'docs/工伤保险.txt',
'docs/保险条款.txt'
]
)
# 用户提问
query = "工伤保险和雇主险有什么区别?"
# Assistant自动进行RAG检索并回答
response = assistant.run(query)
print(f"用户问题: {query}")
print(f"助手回答: {response}")
# 示例2:添加GUI界面
import gradio as gr
def create_multi_file_qa_gui():
"""
为Version 1添加图形用户界面
"""
assistant = QwenAssistant(
llm={'model': 'qwen-max', 'api_key': 'your-api-key'},
files=['docs/*.txt'] # 支持通配符
)
def chat(message, history):
"""聊天函数"""
response = assistant.run(message)
return response
# 创建Gradio界面
with gr.Blocks() as demo:
gr.Markdown("## 📚 多文档智能问答系统")
chatbot = gr.Chatbot()
msg = gr.Textbox(label="请输入您的问题")
clear = gr.Button("清空对话")
def user(user_message, history):
return "", history + [[user_message, None]]
def bot(history):
user_message = history[-1][0]
bot_message = chat(user_message, history)
history[-1][1] = bot_message
return history
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(
bot, chatbot, chatbot
)
clear.click(lambda: None, None, chatbot, queue=False)
return demo
# 运行示例
if __name__ == "__main__":
# basic_multi_file_qa()
# GUI版本
# demo = create_multi_file_qa_gui()
# demo.launch()
pass常见问题解答:
❓ **Q1: 为什么默认使用内存存储?**A: 为了快速原型验证。对于 <1000 份文档,内存存储足够且实现简单。
❓ **Q2: BM25 算法的缺点是什么?**A: 无法理解语义相似性。例如搜"自行车",可能搜不到"单车"。
❓ **Q3: 如何调整检索块的大小?**A: 在 rag_cfg 配置中修改 parser_page_size 参数,默认 500 字符。
学习提示:
- ✅ 小规模项目(<100 文档):直接使用 Qwen-Agent 内置的 retrieval
- ✅ 需要快速验证想法:File Cache 模式启动快,代码量少
- ⚠️ 文档数量 >1000:必须升级到 Elasticsearch(见 Version 2)
Version 2:海量文件快速索引(ES)
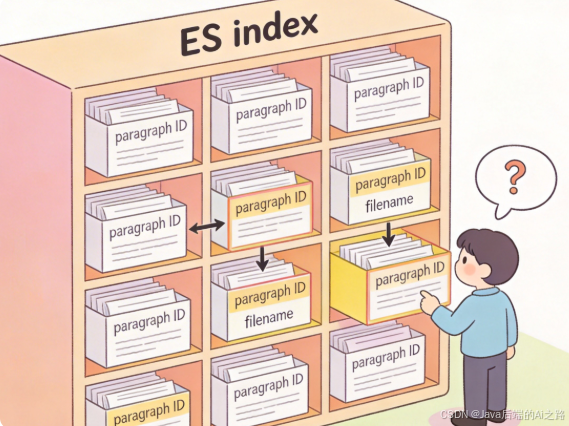
3.1 为什么需要 Elasticsearch?
当文档数量达到百万级时,内存式方案会遇到瓶颈:
- ❌ 启动慢:需要将所有文档加载到内存
- ❌ 内存爆炸:1G 文档需要 1G+ 内存
- ❌ 检索慢:遍历整个内存列表
**Elasticsearch(ES)**是解决方案:
- ✅ 毫秒级检索:使用倒排索引和 BKD-Tree 算法
- ✅ 低内存消耗:数据存在磁盘,仅热点数据在内存
- ✅ 可扩展:支持分布式部署,处理上亿文档
- ✅ 混合检索:支持关键词(BM25)+ 向量检索
3.2 Elasticsearch 基础
核心概念:
- 索引(Index):类似数据库的表
- 文档(Document):类似数据库的行
- 字段(Field):类似数据库的列
- 倒排索引(Inverted Index):从词到文档的映射,实现快速检索
BM25 算法原理:
score = IDF × (TF × (k1 + 1)) / (TF + k1 × (1 - b + b × (field_length / avg_field_length)))
其中:
- TF (Term Frequency):词频,词在文档中出现次数
- IDF (Inverse Document Frequency):逆文档频率,词的稀有度
- k1:调节词频饱和度的参数(默认1.2)
- b:调节字段长度归一化的参数(默认0.75)
- field_length:当前字段长度
- avg_field_length:平均字段长度Python 代码示例:
from elasticsearch import Elasticsearch
import os
class ElasticsearchManager:
"""Elasticsearch管理器"""
def __init__(self, host="localhost", port=9200,
username="elastic", password="your-password"):
"""
初始化ES客户端
Args:
host: ES主机地址
port: ES端口
username: 用户名
password: 密码
"""
self.client = Elasticsearch(
["https://{}:{}".format(host, port)],
basic_auth=(username, password),
verify_certs=False # 生产环境应该使用真实证书
)
self.index_name = "pingan_employer_insurance"
def create_index(self):
"""创建索引"""
# 如果索引已存在,先删除
if self.client.indices.exists(index=self.index_name):
print(f"索引 '{self.index_name}' 已存在,正在删除...")
self.client.indices.delete(index=self.index_name)
# 创建新索引
print(f"正在创建新索引 '{self.index_name}'...")
self.client.indices.create(index=self.index_name)
print(f"索引创建成功!")
def index_document(self, doc_id: int, file_name: str, content: str):
"""
索引单个文档
Args:
doc_id: 文档ID
file_name: 文件名
content: 文档内容
"""
self.client.index(
index=self.index_name,
id=doc_id,
document={
"file_name": file_name,
"content": content
}
)
def index_folder(self, docs_folder: str):
"""
索引整个文件夹的文档
Args:
docs_folder: 文档文件夹路径
"""
print(f"\n正在从 '{docs_folder}' 文件夹读取并索引文档...")
doc_id_counter = 1
# 支持的文件类型
supported_extensions = ['.txt', '.pdf']
for filename in os.listdir(docs_folder):
file_path = os.path.join(docs_folder, filename)
# 检查文件类型
if not any(filename.lower().endswith(ext) for ext in supported_extensions):
print(f" - 跳过不支持的文件: {filename}")
continue
# 提取内容
content = self._extract_content(file_path)
if content.strip():
self.index_document(doc_id_counter, filename, content)
print(f" ✓ 成功索引文档: {filename} (ID: {doc_id_counter})")
doc_id_counter += 1
# 强制刷新索引,确保数据立即可搜
self.client.indices.refresh(index=self.index_name)
print(f"\n索引完成!共索引 {doc_id_counter - 1} 个文档")
def _extract_content(self, file_path: str) -> str:
"""
从文件中提取文本内容
Args:
file_path: 文件路径
Returns:
文件内容
"""
try:
if file_path.lower().endswith('.pdf'):
# PDF文件处理
from PyPDF2 import PdfReader
reader = PdfReader(file_path)
content = ""
for page in reader.pages:
content += page.extract_text() + "\n"
return content
elif file_path.lower().endswith('.txt'):
# TXT文件处理
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
except Exception as e:
print(f" ✗ 读取文件失败: {file_path}, 错误: {e}")
return ""
return ""
def search(self, query: str, size: int = 3) -> list:
"""
执行搜索
Args:
query: 搜索查询
size: 返回结果数量
Returns:
搜索结果列表
"""
print(f"\n正在执行搜索,查询语句: '{query}'")
response = self.client.search(
index=self.index_name,
query={
"match": {
"content": {
"query": query,
"operator": "and" # 使用and操作符,要求所有词都出现
}
}
},
size=size
)
return response['hits']['hits']
def display_search_results(self, hits: list):
"""
显示搜索结果
Args:
hits: 搜索结果
"""
print("\n--- 搜索结果 ---")
if not hits:
print("没有找到匹配的文档。")
return
for i, hit in enumerate(hits):
print(f"\n--- 结果 {i+1} ---")
print(f"来源文件: {hit['_source']['file_name']}")
print(f"相关度得分: {hit['_score']:.2f}")
# 显示内容预览(前200字符)
content_preview = hit['_source']['content'].strip().replace('\n', ' ')
print(f"内容预览: {content_preview[:200]}...")
# 使用示例
def example_es_usage():
"""Elasticsearch使用示例"""
# 1. 初始化ES管理器
es_manager = ElasticsearchManager(
username="elastic",
password="your-password" # 替换为你的ES密码
)
# 2. 创建索引
es_manager.create_index()
# 3. 索引文档
es_manager.index_folder("docs/")
# 4. 执行搜索
search_query = "工伤保险和雇主险有什么区别?"
results = es_manager.search(search_query, size=3)
# 5. 显示结果
es_manager.display_search_results(results)
# 运行示例
if __name__ == "__main__":
# example_es_usage()
pass3.3 精细化索引:段落级别检索
问题:以文档为单位检索太粗粒度,用户可能只需要某个段落。
解决方案:将文档切分成段落,每个段落作为一个独立的 ES 文档。
Python 代码实现:
import re
from typing import List
class ParagraphIndexer:
"""段落级别索引器"""
def __init__(self, es_manager: ElasticsearchManager):
self.es_manager = es_manager
def split_text_into_paragraphs(self, text: str) -> List[str]:
"""
将文本切分成段落
Args:
text: 原始文本
Returns:
段落列表
"""
# 按照换行符切分
paragraphs = text.split('\n')
# 过滤空段落
paragraphs = [p.strip() for p in paragraphs if p.strip()]
# 合并过短的段落(小于50字符)
merged_paragraphs = []
current_para = ""
for para in paragraphs:
if len(current_para) + len(para) < 50:
current_para += " " + para
else:
if current_para:
merged_paragraphs.append(current_para.strip())
current_para = para
if current_para:
merged_paragraphs.append(current_para.strip())
return merged_paragraphs
def index_document_by_paragraphs(self, file_path: str):
"""
按段落索引文档
Args:
file_path: 文件路径
"""
# 提取文件内容
content = self.es_manager._extract_content(file_path)
if not content.strip():
print(f" ✗ 文件内容为空: {file_path}")
return
# 切分成段落
paragraphs = self.split_text_into_paragraphs(content)
filename = os.path.basename(file_path)
# 索引每个段落
for i, paragraph in enumerate(paragraphs):
doc_id = f"{filename}_{i}" # 使用 文件名_段落号 作为ID
self.es_manager.client.index(
index=self.es_manager.index_name,
id=doc_id,
document={
"file_name": filename,
"paragraph_index": i,
"content": paragraph
}
)
print(f" ✓ 成功索引文档: {filename} (共{len(paragraphs)}个段落)")
def index_folder_by_paragraphs(self, docs_folder: str):
"""
按段落索引整个文件夹
Args:
docs_folder: 文件夹路径
"""
print(f"\n正在按段落索引 '{docs_folder}' 文件夹...")
for filename in os.listdir(docs_folder):
file_path = os.path.join(docs_folder, filename)
if os.path.isfile(file_path):
self.index_document_by_paragraphs(file_path)
# 刷新索引
self.es_manager.client.indices.refresh(index=self.es_manager.index_name)
# 使用示例
def example_paragraph_indexing():
"""段落索引示例"""
es_manager = ElasticsearchManager(
username="elastic",
password="your-password"
)
para_indexer = ParagraphIndexer(es_manager)
para_indexer.index_folder_by_paragraphs("docs/")
# 搜索测试
results = es_manager.search("雇主责任险的赔偿范围", size=5)
es_manager.display_search_results(results)
if __name__ == "__main__":
# example_paragraph_indexing()
pass3.4 集成到 Qwen-Agent
核心改动:
- 创建
es_retrieval.py替代原有的retrieval.py - 修改
memory.py,添加 ES 选项 - 创建
elasticsearch_searcher.py管理 ES 连接
Python 代码实现:
# qwen_agent/tools/es_retrieval.py
from qwen_agent.tools.base import BaseTool
from typing import Dict, Any
class ESRetrieval(BaseTool):
"""基于Elasticsearch的检索工具"""
def __init__(self, es_client, index_name):
self.es_client = es_client
self.index_name = index_name
self.max_ref_token = 4000 # 最大引用token数
def call(self, query: str, **kwargs) -> Dict[str, Any]:
"""
执行检索
Args:
query: 查询语句
**kwargs: 其他参数
Returns:
检索结果
"""
# 执行ES搜索
response = self.es_client.search(
index=self.index_name,
query={
"match": {
"content": {
"query": query,
"operator": "and"
}
}
},
size=10
)
hits = response['hits']['hits']
# 提取内容并控制token数量
contents = []
total_tokens = 0
for hit in hits:
content = hit['_source']['content']
# 估算token数量(简化:1 token ≈ 1.5中文字符)
tokens = len(content) / 1.5
if total_tokens + tokens > self.max_ref_token:
break
contents.append(content)
total_tokens += tokens
return {
"query": query,
"results": contents,
"num_results": len(contents)
}
# qwen_agent/memory/memory.py (修改部分)
class Memory:
"""记忆系统 - 支持ES"""
def __init__(self, llm, rag_cfg=None, use_es=False,
es_config=None):
self.llm = llm
self.rag_cfg = rag_cfg or {}
self.use_es = use_es
# 初始化工具
if use_es and es_config:
# 使用ES检索
from elasticsearch import Elasticsearch
self.es_client = Elasticsearch(
hosts=[es_config['host']],
basic_auth=(es_config['username'], es_config['password']),
verify_certs=False
)
self.function_map = {
'retrieval': ESRetrieval(
self.es_client,
es_config['index_name']
),
'doc_parser': DocParser(self.rag_cfg)
}
else:
# 使用默认的内存检索
from qwen_agent.tools.retrieval import Retrieval
self.function_map = {
'retrieval': Retrieval(self.rag_cfg),
'doc_parser': DocParser(self.rag_cfg)
}
def _run(self, query, files=None, **kwargs):
"""运行记忆系统"""
if self.use_es:
# 使用ES检索
result = self.function_map['retrieval'].call(query)
else:
# 使用默认检索
result = self.function_map['retrieval'].call(query, files=files)
return result
# 使用示例:创建支持ES的Agent
def create_es_agent():
"""创建使用Elasticsearch的Agent"""
from qwen_agent import Assistant
# ES配置
es_config = {
'host': 'https://localhost:9200',
'username': 'elastic',
'password': 'your-password',
'index_name': 'pingan_employer_insurance'
}
# 创建Assistant,启用ES
assistant = Assistant(
llm={
'model': 'qwen-max',
'api_key': 'your-api-key'
},
use_es=True, # 启用ES
es_config=es_config
)
# 现在可以使用ES进行快速检索了
response = assistant.run("工伤保险和雇主险的区别?")
print(response)
if __name__ == "__main__":
# create_es_agent()
pass常见问题解答:
❓ **Q1: 如何重置 ES 密码?**A: 运行命令 bin/elasticsearch-reset-password -u elastic
❓ **Q2: ES 可以处理多少文档?**A: 单个索引上限为 21 亿文档,上亿级别也能处理,性能取决于硬件。
❓ **Q3: BM25 得分如何解读?**A: 得分综合考虑了词频(TF)、词的稀有度(IDF)和字段长度。得分越高越相关。
学习提示:
- ✅ 企业级应用(100+ 文档):强烈推荐使用 ES
- ✅ 需要毫秒级响应:ES 是唯一选择
- ⚠️ 小规模项目:File Cache 可能更简单,不需要额外部署 ES
Version 3:添加向量检索功能
4.1 为什么需要向量检索?
BM25 的局限:只能匹配字面,无法理解语义。
- 搜"自行车",找不到"单车"
- 搜"工伤",找不到"职业病"
向量检索的优势:
- ✅ 语义理解:将文字转化为高维向量,相似的概念在向量空间中距离更近
- ✅ 跨语言检索:中文、英文等不同语言的相同概念会被映射到相近的向量
- ✅ 长文本处理:Qwen3-Embedding 支持 32K 上下文
4.2 Qwen3-Embedding 基础
核心能力:
- 多语言支持:119 种语言,MTEB 榜单第一
- 长文本处理:32K 上下文
- 灵活维度:32-4096 维可调
使用示例:
import os
from openai import OpenAI
class EmbeddingGenerator:
"""嵌入向量生成器"""
def __init__(self, api_key=None):
"""
初始化嵌入生成器
Args:
api_key: DashScope API Key
"""
self.client = OpenAI(
api_key=api_key or os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
self.model = "text-embedding-v4" # Qwen3-Embedding
def generate_embedding(self, text: str, dimensions: int = 1024) -> list:
"""
生成文本的嵌入向量
Args:
text: 输入文本
dimensions: 向量维度(默认1024)
Returns:
嵌入向量(list of floats)
"""
completion = self.client.embeddings.create(
model=self.model,
input=text,
dimensions=dimensions,
encoding_format="float"
)
return completion.data[0].embedding
def generate_batch_embeddings(self, texts: list,
dimensions: int = 1024) -> list:
"""
批量生成嵌入向量
Args:
texts: 文本列表
dimensions: 向量维度
Returns:
嵌入向量列表
"""
embeddings = []
for text in texts:
embedding = self.generate_embedding(text, dimensions)
embeddings.append(embedding)
return embeddings
# 使用示例
def example_embedding():
"""嵌入向量使用示例"""
generator = EmbeddingGenerator()
# 示例文本
text = "衣服的质量杠杠的,很漂亮,不枉我等了这么久啊,喜欢,以后还来这里买"
# 生成嵌入向量
embedding = generator.generate_embedding(text, dimensions=1024)
print(f"向量维度: {len(embedding)}")
print(f"前10个维度: {embedding[:10]}")
# 验证语义相似性
text1 = "工伤保险"
text2 = "职业病保险"
text3 = "汽车保险"
emb1 = generator.generate_embedding(text1)
emb2 = generator.generate_embedding(text2)
emb3 = generator.generate_embedding(text3)
# 计算余弦相似度
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
sim12 = cosine_similarity(emb1, emb2)
sim13 = cosine_similarity(emb1, emb3)
print(f"\n'{text1}' 和 '{text2}' 的相似度: {sim12:.4f}")
print(f"'{text1}' 和 '{text3}' 的相似度: {sim13:.4f}")
print(f"\n可以看到,工伤保险和职业病保险的相似度更高!")
# 运行示例
if __name__ == "__main__":
# example_embedding()
pass4.3 文本分块策略
问题:Qwen3-Embedding 最大支持 8192 tokens,长文档需要分块。
解决方案:
- 固定大小分块:每块固定字数(如 512 字)
- 语义分块:按段落、句子边界切分
- 重叠分块:块之间保留部分重叠,保持上下文连续性
Python 代码实现:
import re
from typing import List, Tuple
class TextChunker:
"""文本分块器"""
def __init__(self, chunk_size: int = 512, overlap: int = 50):
"""
初始化分块器
Args:
chunk_size: 块大小(字符数)
overlap: 重叠字符数
"""
self.chunk_size = chunk_size
self.overlap = overlap
def chunk_text(self, text: str) -> List[Tuple[int, str]]:
"""
将文本切分成块
Args:
text: 原始文本
Returns:
块列表,每个元素为 (块索引, 块内容)
"""
chunks = []
start = 0
chunk_index = 0
while start < len(text):
# 计算块的结束位置
end = min(start + self.chunk_size, len(text))
# 尽量在句子边界切分
if end < len(text):
# 查找最近的句号、问号、感叹号
for delimiter in ['。', '?', '!', '.', '?', '!', '\n']:
last_delimiter = text.rfind(delimiter, start, end)
if last_delimiter > start + self.chunk_size // 2:
end = last_delimiter + 1
break
# 提取块
chunk = text[start:end].strip()
if chunk:
chunks.append((chunk_index, chunk))
chunk_index += 1
# 移动到下一个块(考虑重叠)
start = end - self.overlap
return chunks
def chunk_text_by_paragraph(self, text: str) -> List[Tuple[int, str]]:
"""
按段落切分文本
Args:
text: 原始文本
Returns:
段落块列表
"""
paragraphs = text.split('\n')
chunks = []
for i, para in enumerate(paragraphs):
para = para.strip()
if para:
chunks.append((i, para))
return chunks
def chunk_text_with_context(self, text: str) -> List[Tuple[int, str, str]]:
"""
带上下文的分块
Args:
text: 原始文本
Returns:
块列表,每个元素为 (块索引, 块内容, 上下文)
"""
chunks = self.chunk_text(text)
chunks_with_context = []
for i, (chunk_idx, chunk) in enumerate(chunks):
# 提取前后各100字符作为上下文
start = max(0, i - 1)
end = min(len(chunks), i + 2)
context_chunks = [chunks[j][1] for j in range(start, end)]
context = "\n...\n".join(context_chunks)
chunks_with_context.append((chunk_idx, chunk, context))
return chunks_with_context
# 使用示例
def example_chunking():
"""分块示例"""
# 示例长文本
long_text = """
雇主责任险是指被保险人所雇佣的员工在受雇过程中从事与保险单所载明的与被保险人业务有关的工作而遭受意外或患与业务有关的国家规定的职业性疾病,所致伤、残或死亡,被保险人根据法律或雇用合同,须负担医药费用及经济赔偿责任,包括应支出的诉讼费用,由保险人在规定的赔偿限额内负责赔偿的一种保险。
工伤保险是指国家和社会为在生产、工作中遭受事故伤害和患职业性疾病的劳动者及亲属提供医疗救治、生活保障、经济补偿、医疗和职业康复等物质帮助的一种社会保障制度。
两者的主要区别在于:雇主责任险是商业保险,由企业自愿购买;工伤保险是社会保险,强制企业必须为员工购买。
""" * 10 # 重复10次模拟长文本
# 创建分块器
chunker = TextChunker(chunk_size=200, overlap=20)
# 普通分块
print("=== 普通分块 ===")
chunks = chunker.chunk_text(long_text)
for idx, chunk in chunks[:3]: # 显示前3块
print(f"\n块 {idx} (长度: {len(chunk)}):")
print(chunk[:100] + "...")
# 按段落分块
print("\n=== 按段落分块 ===")
para_chunks = chunker.chunk_text_by_paragraph(long_text)
for idx, chunk in para_chunks[:3]:
print(f"\n段落 {idx} (长度: {len(chunk)}):")
print(chunk[:100] + "...")
if __name__ == "__main__":
# example_chunking()
pass4.4 集成向量检索到 ES
核心思路:
- 使用 Qwen3-Embedding 为每个文本块生成向量
- 将向量存储到 ES 的 dense_vector 字段
- 查询时也生成查询向量,使用 k-NN 算法搜索
Python 代码实现:
from elasticsearch import Elasticsearch
from typing import List, Dict
import numpy as np
class VectorSearcher:
"""向量搜索器"""
def __init__(self, es_client, index_name, embedding_generator):
"""
初始化向量搜索器
Args:
es_client: ES客户端
index_name: 索引名称
embedding_generator: 嵌入生成器
"""
self.es_client = es_client
self.index_name = index_name
self.embedding_generator = embedding_generator
self.vector_dimension = 1024 # 与embedding模型一致
def create_vector_index(self):
"""创建支持向量检索的索引"""
# 删除旧索引
if self.es_client.indices.exists(index=self.index_name):
self.es_client.indices.delete(index=self.index_name)
# 创建索引,定义mapping
index_mapping = {
"mappings": {
"properties": {
"file_name": {"type": "keyword"},
"chunk_index": {"type": "integer"},
"content": {"type": "text"},
"content_vector": {
"type": "dense_vector",
"dims": self.vector_dimension,
"index": True,
"similarity": "cosine" # 使用余弦相似度
}
}
}
}
self.es_client.indices.create(
index=self.index_name,
body=index_mapping
)
print(f"向量索引 '{self.index_name}' 创建成功!")
def index_document_with_vectors(self, file_path: str):
"""
索引文档,包含向量
Args:
file_path: 文件路径
"""
# 读取文件内容
content = self._extract_content(file_path)
if not content.strip():
return
# 分块
chunker = TextChunker(chunk_size=512, overlap=50)
chunks = chunker.chunk_text(content)
filename = os.path.basename(file_path)
# 为每个块生成向量并索引
for chunk_idx, chunk_text in chunks:
# 生成嵌入向量
vector = self.embedding_generator.generate_embedding(
chunk_text,
dimensions=self.vector_dimension
)
# 索引到ES
doc_id = f"{filename}_{chunk_idx}"
self.es_client.index(
index=self.index_name,
id=doc_id,
document={
"file_name": filename,
"chunk_index": chunk_idx,
"content": chunk_text,
"content_vector": vector
}
)
print(f"✓ 成功索引文档: {filename} (共{len(chunks)}个向量块)")
def vector_search(self, query: str, top_k: int = 5) -> List[Dict]:
"""
执行向量搜索
Args:
query: 查询文本
top_k: 返回结果数量
Returns:
搜索结果列表
"""
# 生成查询向量
query_vector = self.embedding_generator.generate_embedding(
query,
dimensions=self.vector_dimension
)
# 执行k-NN搜索
response = self.es_client.search(
index=self.index_name,
body={
"knn": {
"field": "content_vector",
"query_vector": query_vector,
"k": top_k,
"num_candidates": 100
}
}
)
return response['hits']['hits']
def hybrid_search(self, query: str, top_k: int = 5) -> List[Dict]:
"""
混合检索(BM25 + 向量)
Args:
query: 查询文本
top_k: 返回结果数量
Returns:
搜索结果列表
"""
# 生成查询向量
query_vector = self.embedding_generator.generate_embedding(
query,
dimensions=self.vector_dimension
)
# 混合检索
response = self.es_client.search(
index=self.index_name,
body={
"query": {
"bool": {
"should": [
# BM25检索
{
"match": {
"content": {
"query": query,
"boost": 1.0
}
}
},
# 向量检索
{
"knn": {
"field": "content_vector",
"query_vector": query_vector,
"k": top_k,
"boost": 1.0
}
}
]
}
}
}
)
return response['hits']['hits']
def _extract_content(self, file_path: str) -> str:
"""提取文件内容"""
if file_path.lower().endswith('.pdf'):
from PyPDF2 import PdfReader
reader = PdfReader(file_path)
content = ""
for page in reader.pages:
content += page.extract_text() + "\n"
return content
elif file_path.lower().endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
return ""
# 使用示例
def example_vector_search():
"""向量搜索示例"""
# 初始化
es_client = Elasticsearch(
["https://localhost:9200"],
basic_auth=("elastic", "your-password"),
verify_certs=False
)
embedding_generator = EmbeddingGenerator()
vector_searcher = VectorSearcher(
es_client,
"insurance_vector_index",
embedding_generator
)
# 创建索引
vector_searcher.create_vector_index()
# 索引文档
docs_folder = "docs/"
for filename in os.listdir(docs_folder):
file_path = os.path.join(docs_folder, filename)
vector_searcher.index_document_with_vectors(file_path)
# 刷新索引
es_client.indices.refresh(index="insurance_vector_index")
# 向量搜索
query = "企业需要为员工购买哪些保险?"
results = vector_searcher.vector_search(query, top_k=3)
print(f"\n=== 向量搜索结果: {query} ===")
for i, hit in enumerate(results):
print(f"\n结果 {i+1}:")
print(f" 文件: {hit['_source']['file_name']}")
print(f" 得分: {hit['_score']:.4f}")
print(f" 内容: {hit['_source']['content'][:100]}...")
# 混合检索
print(f"\n=== 混合检索结果: {query} ===")
hybrid_results = vector_searcher.hybrid_search(query, top_k=3)
for i, hit in enumerate(hybrid_results):
print(f"\n结果 {i+1}:")
print(f" 文件: {hit['_source']['file_name']}")
print(f" 得分: {hit['_score']:.4f}")
print(f" 内容: {hit['_source']['content'][:100]}...")
if __name__ == "__main__":
# example_vector_search()
pass常见问题解答:
❓ **Q1: 向量维度如何选择?**A: 1024 维是平衡性能和精度的好选择。维度越高越精确,但计算和存储成本也越高。
❓ **Q2: BM25 和向量检索如何选择?**A: 推荐混合检索。BM25 擅长精确匹配,向量检索擅长语义理解,两者结合效果最佳。
❓ **Q3: 长文档如何处理?**A: 使用 TextChunker 分块,每块 512 字左右,块之间保留 50 字重叠以保持上下文。
学习提示:
- ✅ 需要语义理解:必须使用向量检索
- ✅ 跨语言检索:向量检索是唯一解决方案
- ✅ 最佳实践:BM25 + 向量混合检索
Version 4:添加外部数据源(AI 搜索 MCP)
5.1 为什么需要外部数据源?
RAG 的局限:知识库是静态的,无法获取最新信息。
AI 搜索 MCP 的优势:
- ✅ 实时信息:访问互联网获取最新资讯
- ✅ 知识广度:不受限于本地知识库
- ✅ 智能整合:MCP(Model Context Protocol)自动整合多源信息
5.2 Tavily-MCP 集成
Tavily 是一个专门为 AI 优化的搜索 API,特点是:
- 返回结构化的搜索结果
- 自动去重和排序
- 支持深度搜索
Python 代码实现:
from tavily import TavilyClient
from typing import List, Dict
class WebSearcher:
"""网络搜索器 - 使用Tavily MCP"""
def __init__(self, api_key: str):
"""
初始化搜索器
Args:
api_key: Tavily API Key
"""
self.client = TavilyClient(api_key=api_key)
def search(self, query: str, max_results: int = 10,
search_depth: str = "advanced") -> List[Dict]:
"""
执行网络搜索
Args:
query: 搜索查询
max_results: 最大结果数
search_depth: 搜索深度 ("basic" 或 "advanced")
Returns:
搜索结果列表
"""
print(f"正在搜索: {query}")
response = self.client.search(
query=query,
max_results=max_results,
search_depth=search_depth,
include_answer=True, # 包含AI生成的答案摘要
include_raw_content=False,
include_images=False
)
return response
def extract_search_results(self, response: Dict) -> Dict:
"""
提取搜索结果
Args:
response: Tavily API响应
Returns:
提取的结果字典
"""
results = {
"answer": response.get("answer", ""),
"query": response.get("query", ""),
"sources": []
}
for item in response.get("results", []):
source = {
"title": item.get("title", ""),
"url": item.get("url", ""),
"content": item.get("content", ""),
"score": item.get("score", 0)
}
results["sources"].append(source)
return results
def format_results_for_llm(self, results: Dict) -> str:
"""
将搜索结果格式化为LLM可理解的文本
Args:
results: 搜索结果
Returns:
格式化后的文本
"""
formatted = f"搜索查询: {results['query']}\n\n"
if results['answer']:
formatted += f"AI摘要: {results['answer']}\n\n"
formatted += "搜索来源:\n"
for i, source in enumerate(results['sources'], 1):
formatted += f"\n{i}. {source['title']}\n"
formatted += f" URL: {source['url']}\n"
formatted += f" 内容: {source['content'][:300]}...\n"
formatted += f" 相关度: {source['score']:.2f}\n"
return formatted
# 使用示例
def example_web_search():
"""网络搜索示例"""
# 初始化搜索器
searcher = WebSearcher(api_key="your-tavily-api-key")
# 执行搜索
query = "最新的AI搜索技术发展趋势"
response = searcher.search(query, max_results=5)
# 提取结果
results = searcher.extract_search_results(response)
# 格式化结果
formatted_results = searcher.format_results_for_llm(results)
print(formatted_results)
if __name__ == "__main__":
# example_web_search()
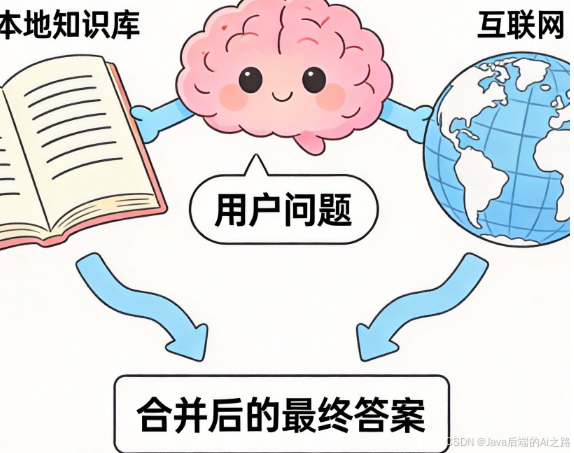
pass5.3 整合本地 RAG 和网络搜索
核心思路:
- 用户提问时,先在本地 RAG 检索
- 如果本地结果不充分,再进行网络搜索
- 将两路结果整合,提供给 LLM 生成答案
Python 代码实现:
from typing import Optional
class HybridQASystem:
"""混合问答系统:本地RAG + 网络搜索"""
def __init__(self, rag_retriever, web_searcher, llm):
"""
初始化混合问答系统
Args:
rag_retriever: RAG检索器
web_searcher: 网络搜索器
llm: 大语言模型
"""
self.rag_retriever = rag_retriever
self.web_searcher = web_searcher
self.llm = llm
def answer(self, query: str, use_web: bool = True) -> str:
"""
回答用户问题
Args:
query: 用户问题
use_web: 是否使用网络搜索
Returns:
答案
"""
print(f"\n=== 用户问题: {query} ===")
# 步骤1: 本地RAG检索
rag_results = self.rag_retriever.search(query, top_k=3)
print(f"本地检索到 {len(rag_results)} 条结果")
# 步骤2: 评估本地结果是否充分
if self._is_rag_sufficient(rag_results, query):
# 本地结果足够,直接回答
answer = self._generate_answer(query, rag_results, web_results=None)
return answer
# 步骤3: 本地结果不足,进行网络搜索
if use_web:
print("本地结果不足,启动网络搜索...")
web_response = self.web_searcher.search(query, max_results=3)
web_results = self.web_searcher.extract_search_results(web_response)
print(f"网络搜索到 {len(web_results['sources'])} 条结果")
else:
web_results = None
# 步骤4: 整合两路结果,生成答案
answer = self._generate_answer(query, rag_results, web_results)
return answer
def _is_rag_sufficient(self, rag_results: list, query: str) -> bool:
"""
评估RAG结果是否充分
Args:
rag_results: RAG检索结果
query: 查询
Returns:
是否充分
"""
# 简化判断:如果有3个结果且得分较高,认为足够
if len(rag_results) < 3:
return False
# 检查得分(假设得分>=0.7为高分)
avg_score = sum(r['_score'] for r in rag_results) / len(rag_results)
if avg_score >= 0.7:
return True
return False
def _generate_answer(self, query: str, rag_results: list,
web_results: Optional[dict] = None) -> str:
"""
基于检索结果生成答案
Args:
query: 查询
rag_results: RAG结果
web_results: 网络搜索结果
Returns:
生成的答案
"""
# 构造上下文
context = f"问题: {query}\n\n"
# 添加RAG结果
if rag_results:
context += "本地知识库:\n"
for i, result in enumerate(rag_results, 1):
content = result['_source']['content']
context += f"\n{i}. {content[:500]}...\n"
# 添加网络搜索结果
if web_results:
context += "\n\n网络搜索:\n"
if web_results['answer']:
context += f"AI摘要: {web_results['answer']}\n"
for i, source in enumerate(web_results['sources'][:3], 1):
context += f"\n{i}. {source['title']}\n"
context += f" {source['content'][:300]}...\n"
# 调用LLM生成答案
prompt = f"""
基于以下信息,回答用户问题。请用简洁、准确的语言回答,并注明信息来源。
{context}
请回答:
"""
# 这里应该调用LLM
# answer = self.llm.generate(prompt)
# 简化实现
answer = f"基于本地知识库和网络搜索,关于'{query}'的回答:\n\n"
answer += "(这里应该是LLM生成的答案)\n\n"
if rag_results:
answer += f"参考来源: {rag_results[0]['_source']['file_name']}"
if web_results and web_results['sources']:
answer += f"\n网络来源: {web_results['sources'][0]['title']}"
return answer
# 使用示例:创建完整的混合问答Agent
def create_hybrid_agent():
"""创建混合问答Agent"""
# 1. 初始化ES检索器
from qwen_agent.tools.es_retrieval import ESRetrieval
from elasticsearch import Elasticsearch
es_client = Elasticsearch(
["https://localhost:9200"],
basic_auth=("elastic", "your-password"),
verify_certs=False
)
rag_retriever = ESRetrieval(
es_client,
"pingan_employer_insurance"
)
# 2. 初始化网络搜索器
web_searcher = WebSearcher(api_key="your-tavily-api-key")
# 3. 初始化LLM
llm = {
'model': 'qwen-max',
'api_key': 'your-api-key'
}
# 4. 创建混合问答系统
hybrid_system = HybridQASystem(rag_retriever, web_searcher, llm)
# 5. 测试
queries = [
"工伤保险和雇主险有什么区别?", # 本地可回答
"2024年最新的AI搜索技术是什么?", # 需要网络搜索
"施工保主要适用于哪些场景?" # 本地可回答
]
for query in queries:
answer = hybrid_system.answer(query, use_web=True)
print("\n" + "="*50)
print(answer)
print("="*50)
if __name__ == "__main__":
# create_hybrid_agent()
pass常见问题解答:
❓ **Q1: 什么时候需要网络搜索?**A: 当问题涉及最新信息、或者本地知识库中没有相关内容时。
❓ **Q2: 如何平衡本地检索和网络搜索?**A: 先评估本地结果的质量,如果得分高就不搜索网络;如果得分低再搜索网络。
❓ **Q3: Tavily 和 Google Search API 有什么区别?**A: Tavily 专为 AI 优化,返回结构化结果;Google Search API 更适合传统应用。
学习提示:
- ✅ 需要实时信息:必须集成网络搜索
- ✅ 知识库更新慢:网络搜索作为补充
- ⚠️ 成本考虑:网络搜索需要 API 费用,谨慎使用
Version 5:界面美化

6.1 Gradio 基础
Gradio 是快速搭建 AI 应用界面的 Python 库,特点:
- ✅ 极简开发:几行代码创建 Web 界面
- ✅ 多模态支持:文本、图像、音频、视频
- ✅ 一键分享:生成公开链接
- ✅ 高度可定制:Blocks API 支持自定义布局
6.2 构建现代化界面
界面设计要点:
- 左侧导航栏:应用 Logo、功能菜单
- 主内容区:聊天窗口、搜索框
- 底部工具栏:收藏、历史、设置
Python 代码实现:
import gradio as gr
from typing import List, Tuple
import os
class ModernChatInterface:
"""现代化聊天界面"""
def __init__(self, qa_system, logo_path="logo.png"):
"""
初始化界面
Args:
qa_system: 问答系统
logo_path: Logo文件路径
"""
self.qa_system = qa_system
self.logo_path = logo_path
self.chat_history = []
def create_interface(self):
"""创建Gradio界面"""
# 自定义CSS样式
custom_css = """
.logo-container {
text-align: center;
padding: 20px;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
border-radius: 10px;
margin-bottom: 20px;
}
.logo-image {
max-width: 80px;
border-radius: 50%;
border: 3px solid white;
}
.nav-button {
width: 100%;
text-align: left;
padding: 12px 16px;
margin: 8px 0;
border-radius: 8px;
transition: all 0.3s;
border: none;
background: #f0f0f0;
color: #333;
}
.nav-button:hover {
background: #667eea;
color: white;
transform: translateX(5px);
}
.chat-container {
height: 500px;
overflow-y: auto;
padding: 20px;
border-radius: 10px;
border: 2px solid #e0e0e0;
}
.message-user {
background: #667eea;
color: white;
padding: 12px 16px;
border-radius: 18px 18px 4px 18px;
margin: 8px 0;
max-width: 70%;
margin-left: auto;
}
.message-bot {
background: #f0f0f0;
color: #333;
padding: 12px 16px;
border-radius: 18px 18px 18px 4px;
margin: 8px 0;
max-width: 70%;
}
"""
with gr.Blocks(css=custom_css, title="AI智能问答系统") as demo:
# 顶部标题栏
gr.Markdown("# 🤖 AI智能问答系统")
gr.Markdown("基于RAG + ES + 向量检索 + 网络搜索的混合架构")
# 使用Row布局:左侧导航,右侧主内容
with gr.Row():
# 左侧导航栏
with gr.Column(scale=1):
# Logo展示
if os.path.exists(self.logo_path):
gr.Image(
value=self.logo_path,
label="",
show_label=False,
elem_classes=["logo-container"]
)
else:
gr.Markdown(
f'<div class="logo-container">'
f'<h3 style="color: white; margin: 0;">AI问答系统</h3>'
f'</div>'
)
# 导航按钮
with gr.Group():
gr.Button("💬 智能问答", elem_classes=["nav-button"])
gr.Button("📚 知识库管理", elem_classes=["nav-button"])
gr.Button("⭐ 收藏夹", elem_classes=["nav-button"])
gr.Button("📜 历史记录", elem_classes=["nav-button"])
gr.Button("⚙️ 设置", elem_classes=["nav-button"])
# 统计信息
gr.Markdown("### 📊 系统统计")
stats_text = gr.Textbox(
value="知识库文档: 0\n已索引段落: 0\n总提问次数: 0",
lines=3,
interactive=False,
show_label=False
)
# 右侧主内容区
with gr.Column(scale=3):
# 标签页
with gr.Tabs():
# 智能问答标签
with gr.Tab("💬 智能问答"):
# 聊天窗口
chatbot = gr.Chatbot(
label="对话记录",
elem_classes=["chat-container"]
)
# 输入区域
with gr.Row():
user_input = gr.Textbox(
label="",
placeholder="请输入您的问题...",
scale=4,
lines=2
)
submit_btn = gr.Button(
"发送",
variant="primary",
scale=1
)
# 选项
with gr.Row():
use_web = gr.Checkbox(
label="启用网络搜索",
value=True
)
clear_btn = gr.Button("清空对话")
# 知识库管理标签
with gr.Tab("📚 知识库管理"):
gr.Markdown("### 上传文档到知识库")
file_upload = gr.File(
label="选择文件",
file_count="multiple"
)
index_btn = gr.Button(
"开始索引",
variant="primary"
)
index_status = gr.Textbox(
label="索引状态",
interactive=False
)
# 其他标签
with gr.Tab("⭐ 收藏夹"):
gr.Markdown("### 🚧 功能开发中\n敬请期待...")
with gr.Tab("📜 历史记录"):
gr.Markdown("### 🚧 功能开发中\n敬请期待...")
# 事件绑定
submit_btn.click(
fn=self.chat,
inputs=[user_input, chatbot, use_web],
outputs=[user_input, chatbot]
)
user_input.submit(
fn=self.chat,
inputs=[user_input, chatbot, use_web],
outputs=[user_input, chatbot]
)
clear_btn.click(
fn=lambda: ([], []),
outputs=[chatbot]
)
index_btn.click(
fn=self.index_files,
inputs=[file_upload],
outputs=[index_status]
)
return demo
def chat(self, message: str, history: List[Tuple[str, str]],
use_web: bool) -> Tuple[str, List[Tuple[str, str]]]:
"""
聊天函数
Args:
message: 用户消息
history: 历史记录
use_web: 是否使用网络搜索
Returns:
(空消息, 更新后的历史记录)
"""
# 添加用户消息到历史
history.append([message, None])
try:
# 调用问答系统
response = self.qa_system.answer(message, use_web=use_web)
# 更新历史记录
history[-1][1] = response
# 保存到历史
self.chat_history.append({
"user": message,
"bot": response,
"use_web": use_web
})
except Exception as e:
error_msg = f"抱歉,回答问题时出错了: {str(e)}"
history[-1][1] = error_msg
return "", history
def index_files(self, files: list) -> str:
"""
索引上传的文件
Args:
files: 上传的文件列表
Returns:
索引状态
"""
if not files:
return "请先选择文件!"
try:
indexed_count = 0
for file in files:
# 这里应该调用索引逻辑
# self.qa_system.index_document(file.name)
indexed_count += 1
return f"✓ 成功索引 {indexed_count} 个文件!"
except Exception as e:
return f"✗ 索引失败: {str(e)}"
# 使用示例
def create_full_app():
"""创建完整的应用"""
# 1. 创建问答系统
qa_system = HybridQASystem(
rag_retriever=None, # 替换为实际的检索器
web_searcher=None, # 替换为实际的搜索器
llm=None # 替换为实际的LLM
)
# 2. 创建界面
interface = ModernChatInterface(qa_system)
demo = interface.create_interface()
# 3. 启动应用
demo.launch(
server_name="0.0.0.0",
server_port=7860,
share=False,
show_error=True
)
if __name__ == "__main__":
# create_full_app()
pass6.3 Stream 模式优化
问题:一次性显示答案,用户体验不佳。
解决方案:使用 Gradio 的 stream 模式,逐字显示答案。
Python 代码实现:
from typing import Iterator
class StreamingChatInterface:
"""流式聊天界面"""
def __init__(self, qa_system):
self.qa_system = qa_system
def chat_stream(self, message: str, history: List[Tuple[str, str]],
use_web: bool) -> Iterator[Tuple[List[Tuple[str, str]], str]]:
"""
流式聊天
Args:
message: 用户消息
history: 历史记录
use_web: 是否使用网络搜索
Yields:
(更新后的历史记录, 当前答案片段)
"""
# 添加用户消息
history.append([message, ""])
try:
# 生成答案(这里应该是流式生成)
# 简化实现:模拟流式输出
response = self.qa_system.answer(message, use_web=use_web)
# 逐字输出
current_answer = ""
for char in response:
current_answer += char
history[-1][1] = current_answer
yield history, ""
# 最终输出
yield history, current_answer
except Exception as e:
error_msg = f"抱歉,回答问题时出错了: {str(e)}"
history[-1][1] = error_msg
yield history, error_msg
def create_streaming_interface(self):
"""创建流式界面"""
with gr.Blocks(title="AI智能问答系统") as demo:
gr.Markdown("# 🤖 AI智能问答系统 (流式版)")
chatbot = gr.Chatbot(label="对话记录")
with gr.Row():
msg = gr.Textbox(
label="",
placeholder="请输入您的问题...",
scale=4
)
send = gr.Button("发送", variant="primary", scale=1)
use_web = gr.Checkbox(label="启用网络搜索", value=True)
clear = gr.Button("清空对话")
# 流式聊天
msg.submit(
fn=self.chat_stream,
inputs=[msg, chatbot, use_web],
outputs=[chatbot, msg]
)
send.click(
fn=self.chat_stream,
inputs=[msg, chatbot, use_web],
outputs=[chatbot, msg]
)
clear.click(
lambda: ([], ""),
outputs=[chatbot, msg]
)
return demo
# 使用示例
def create_streaming_app():
"""创建流式应用"""
qa_system = HybridQASystem(None, None, None)
interface = StreamingChatInterface(qa_system)
demo = interface.create_streaming_interface()
demo.launch()
if __name__ == "__main__":
# create_streaming_app()
pass常见问题解答:
❓ **Q1: Gradio 和 Streamlit 有什么区别?**A: Gradio 更适合 AI 模型演示,Streamlit 更适合数据可视化应用。
❓ **Q2: 如何自定义界面样式?**A: 使用 Gradio 的 css 参数,传入自定义 CSS 代码。
❓ **Q3: 如何实现用户认证?**A: Gradio 支持 basic_auth 和 OAuth 认证,详见官方文档。
学习提示:
- ✅ 快速原型:Gradio 是最佳选择
- ✅ AI 演示:Gradio 的原生支持非常友好
- ⚠️ 生产环境:考虑使用 Flask 或 FastAPI
实战总结与最佳实践 {#总结}
7.1 知识点汇总
记忆能力升级路径:
Level 1: File Cache (内存缓存)
↓ 优点:简单快速
↓ 缺点:临时的,低效
Level 2: Elasticsearch (持久化索引)
↓ 优点:毫秒级检索,可扩展
↓ 缺点:需要额外部署
Level 3: Vector Search (语义理解)
↓ 优点:理解语义,跨语言
↓ 缺点:计算成本高搜索能力对比:
| 检索方式 | 精度 | 速度 | 成本 | 适用场景 |
|---|---|---|---|---|
| BM25 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ | 精确关键词匹配 |
| 向量检索 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | 语义理解,跨语言 |
| 混合检索 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 综合场景(推荐) |
7.2 完整技术栈
推荐的完整架构:
用户界面层
↓ Gradio (快速演示)
↓ Streamlit (数据可视化)
业务逻辑层
↓ Qwen-Agent (智能体框架)
↓ 自定义RAG Pipeline
数据存储层
↓ Elasticsearch (关键词索引)
↓ 向量数据库 (语义索引)
数据来源层
↓ 本地文档 (PDF, TXT)
↓ 网络搜索 (Tavily MCP)
↓ 外部API (可选)7.3 常见问题诊断
问题 1: 检索速度慢
- 检查 ES 配置,是否使用了正确的索引
- 检查文档分块大小,建议 500-800 字
- 考虑增加 ES 的内存和 CPU 资源
问题 2: 检索不准确
- 调整 BM25 参数(k1, b)
- 增加向量检索权重
- 检查文档质量,确保内容清晰
问题 3: 内存占用高
- 切换到 Elasticsearch
- 减少检索的文档数量
- 优化分块策略
7.4 最佳实践
✅ DO (应该做):
- 从小规模开始,验证想法后再扩展
- 使用混合检索(BM25 + 向量)
- 添加日志和监控,方便调试
- 定期更新知识库,保持信息新鲜度
- 设计友好的用户界面,提升体验
❌ DON'T (不应该做):
- 不要一开始就上大规模,先跑通 MVP
- 不要只依赖一种检索方式,混合效果更好
- 不要忽略错误处理,要有容错机制
- 不要硬编码配置,使用配置文件
- 不要忽视用户体验,界面同样重要
7.5 进阶方向
方向 1:多模态检索
- 支持图片、视频检索
- 使用 CLIP 等视觉模型
方向 2:个性化推荐
- 基于用户历史推荐相关内容
- 使用协同过滤或深度学习
方向 3:实时更新
- 监控数据源变化
- 自动更新索引
方向 4:知识图谱
- 构建实体关系图谱
- 支持复杂推理查询
方向 5:分布式部署
- ES 集群部署
- 负载均衡和高可用
结语
恭喜你!通过本教程,你已经掌握了构建 Agent 搜索、感知与记忆能力的完整技术栈:
✅ Version 1 :多文件快速检索与问答✅ Version 2 :海量文件快速索引(ES)✅ Version 3 :添加向量检索功能✅ Version 4 :添加外部数据源(AI 搜索 MCP)✅ Version 5:界面美化
关键收获:
- 理解了 Agent 记忆系统的三层架构
- 掌握了 BM25 和向量检索的原理和实现
- 学会了混合检索的最佳实践
- 构建了完整的 AI 搜索应用
下一步行动:
- 选择一个感兴趣的领域(如法律、医疗、金融)
- 收集相关文档,构建知识库
- 按照本教程的 5 个版本逐步实现
- 优化用户体验,发布你的 AI 搜索应用
记住:
从金鱼记忆到博学大脑,核心在于:持久化、索引化、语义化。
转载声明:
本文为原创文章,如需转载,请联系作者获得授权,并注明出处。