目录
[(4)Mix up](#(4)Mix up)
[(6)Augment HSV(Hue, Saturation, Value)](#(6)Augment HSV(Hue, Saturation, Value))
[(2)4.2 平衡不同尺度的损失](#(2)4.2 平衡不同尺度的损失)
1.前言
-
YOLO v5测试数据:
-
-
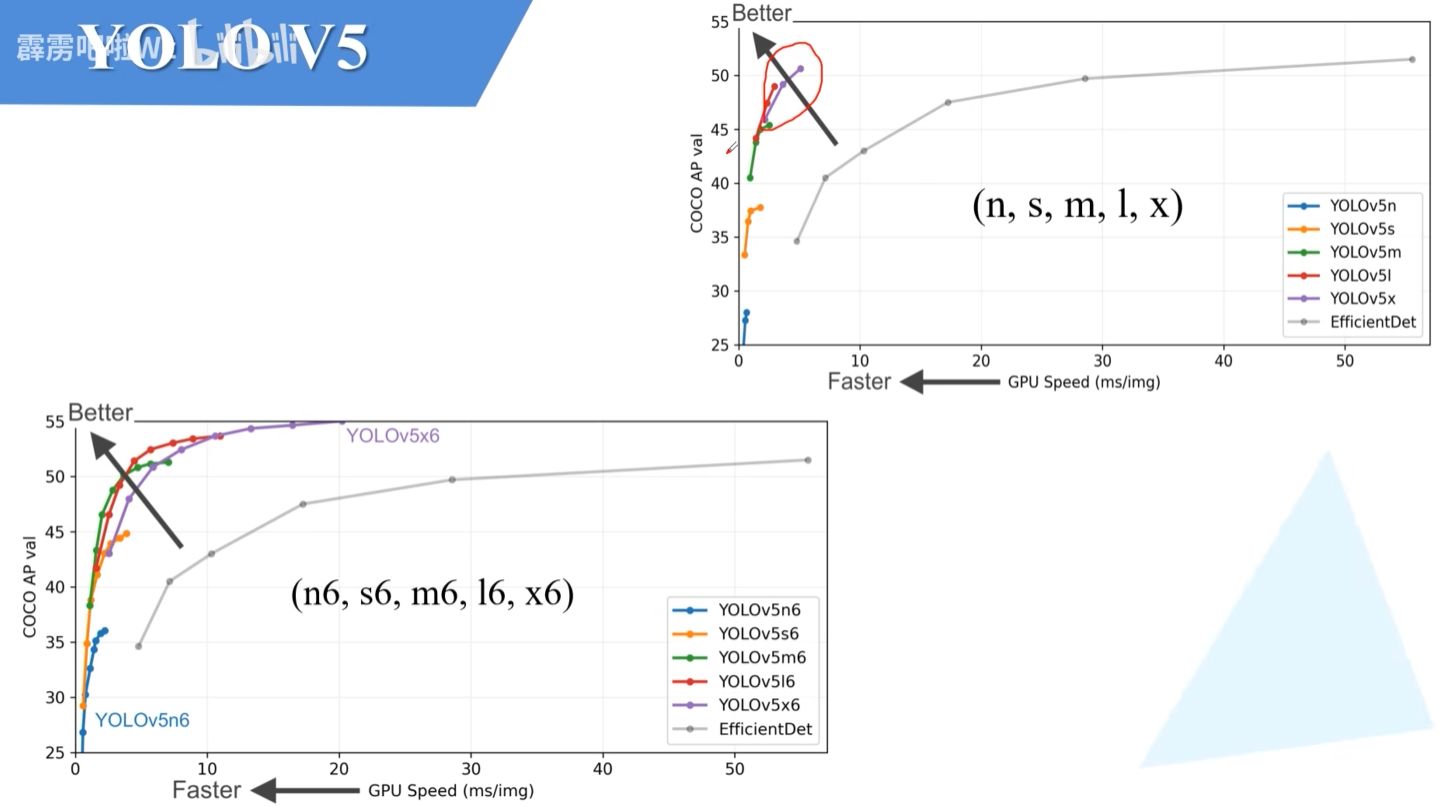
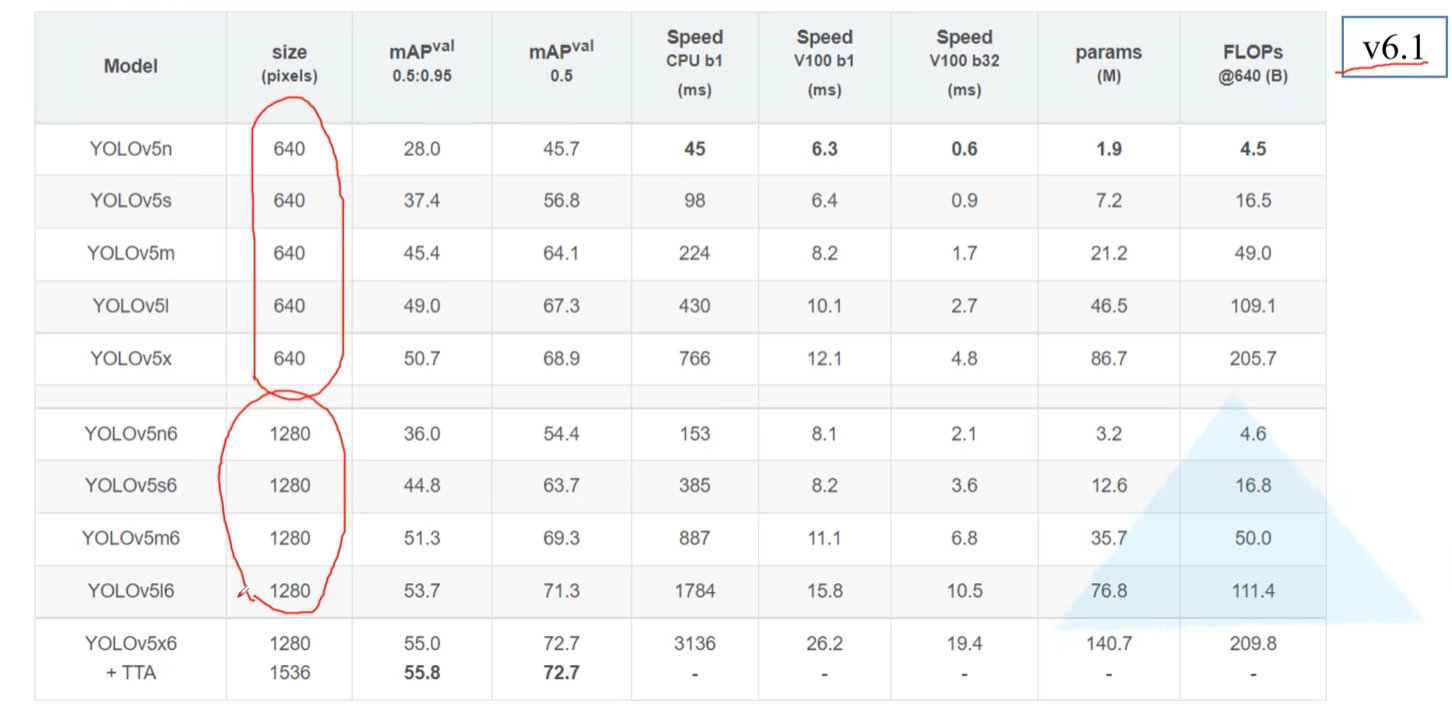
右上角是YOLO v5(n,s,m,l,x)五个模型的测试结果。输出分辨率640×640。和之前一样,下采样率达到32倍,输出特征层有3层。
-
左下角是YOLO v5(n6,s6,m6,l6,x6)五个模型的测试结果,这几个模型的输出分辨率更大一些,一般是1280×1280。下采样率达到64倍,输出特征层有4层。
-
2.网络结构
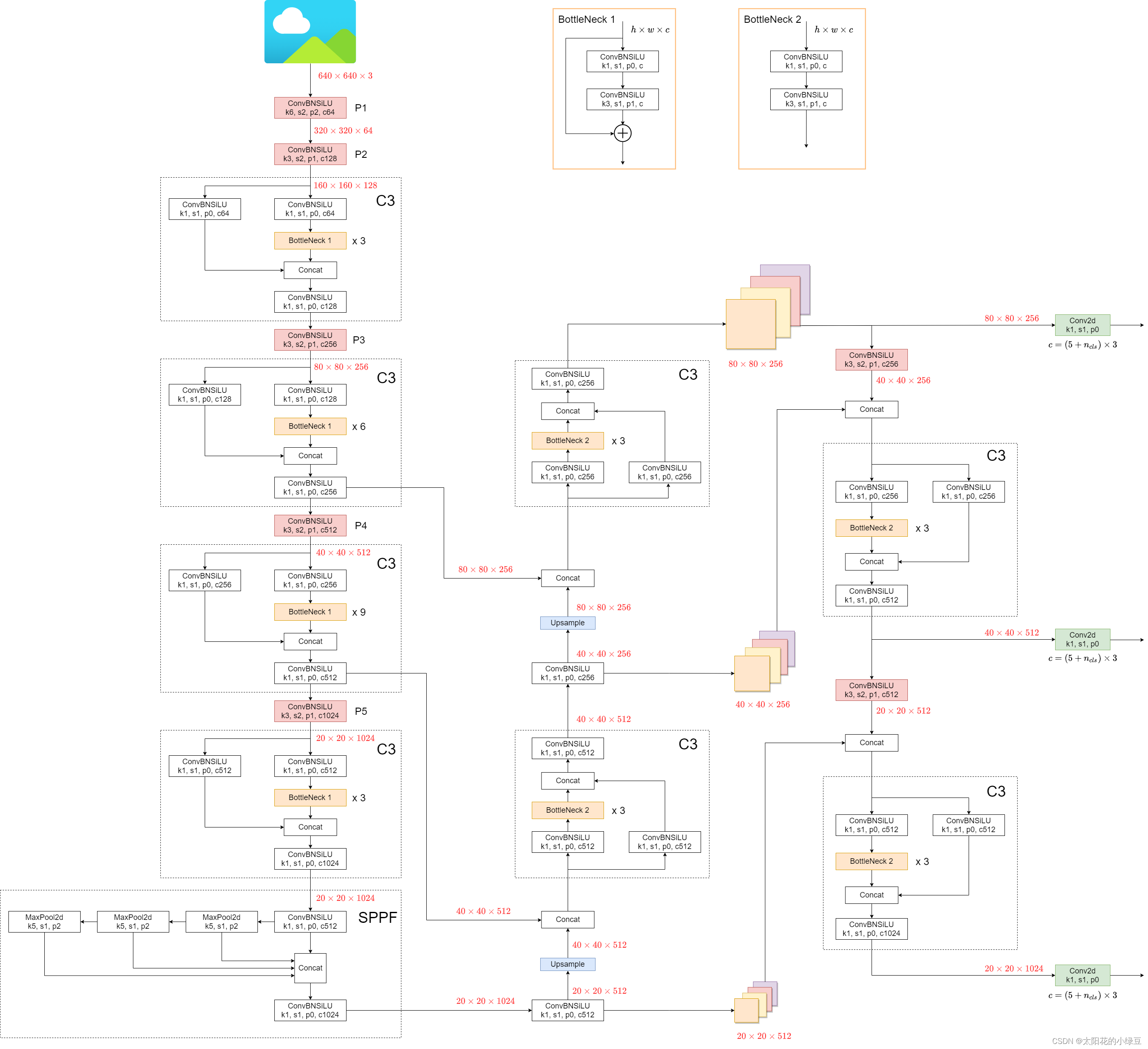
(1)整体结构
关于YOLOv5的网络结构其实网上相关的讲解已经有很多了。网络结构主要由以下几部分组成:
-
Backbone: New CSP-Darknet53
-
Neck: SPPF, New CSP-PAN
-
Head: YOLOv3 Head
-
-
P1,P2,C3是backbone部分,左下角是SPPF,右边是PAN部分。
-
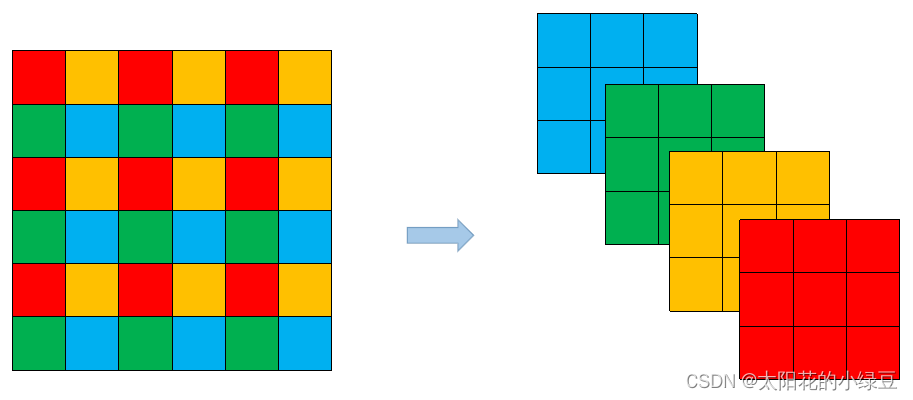
和YOLOv4对比,YOLOv5在Backbone部分没太大变化。但是YOLOv5在v6.0版本后相比之前版本有一个很小的改动,把网络的第一层(原来是Focus模块)换成了一个6x6大小的卷积层。两者在理论上其实等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6x6大小的卷积层比使用Focus模块更加高效。下图是原来的Focus模块,将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map,然后在接上一个3x3大小的卷积层。这和直接使用一个6x6大小的卷积层等效。
-
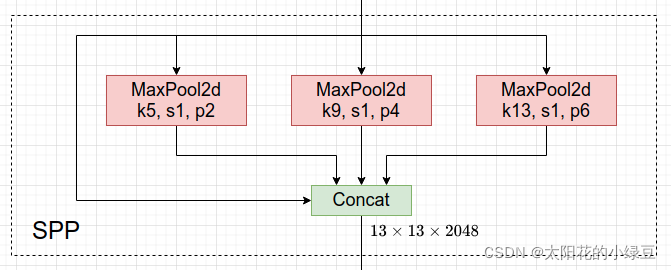
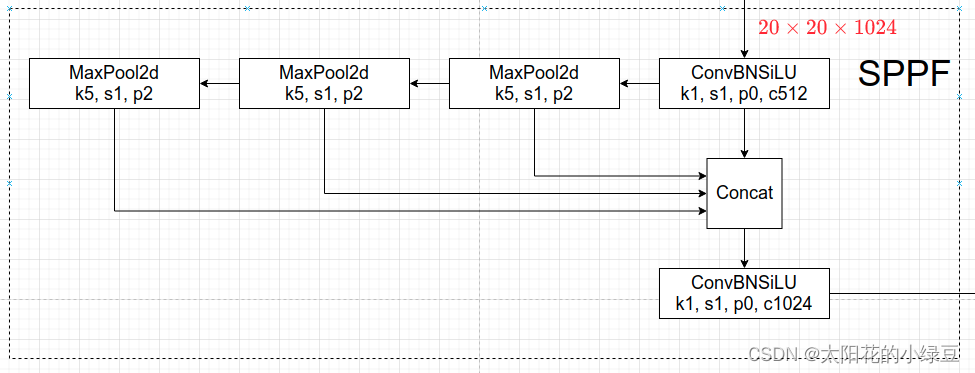
在Neck部分的变化还是相对较大的,首先是将SPP换成成了SPPF,两者的作用是一样的,但后者效率更高 。SPP结构是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。而SPPF结构是将输入串行通过多个5x5大小的MaxPool层,这里需要注意的是串行两个5x5大小的MaxPool层是和一个9x9大小的MaxPool层计算结果是一样的,串行三个5x5大小的MaxPool层是和一个13x13大小的MaxPool层计算结果是一样的。下面是SPP和SPPF的结构示意图。
-
SPP:
-
SPPF:
3.数据增强
(1)拼图
- 将四张图片拼成一张图片
(2)复制粘贴
- 将部分目标随机的粘贴到图片中,前提是数据要有
segments数据才行,即每个目标的实例分割信息。下面是Copy paste原论文中的示意图。 
(3)随机仿射变换(旋转、缩放、平移、切割)
- 但根据配置文件里的超参数发现只使用了Scale和Translation即缩放和平移。
(4)Mix up
- 就是将两张图片按照一定的透明度融合在一起,具体有没有用不太清楚,毕竟没有论文,也没有消融实验。代码中只有较大的模型才使用到了MixUp,而且每次只有10%的概率会使用到。
(5)Albumentations
- 主要是做些滤波、直方图均衡化以及改变图片质量等等,代码里写的只有安装albumentations包才会启用,默认不启用。
(6)Augment HSV(Hue, Saturation, Value)
- 随机调整色度,饱和度以及明度

(7)随机水平翻转
4.损失计算
(1)损失
- YOLOv5的损失主要由三个部分组成:
- Classes loss,分类损失,采用的是BCE loss,注意只计算正样本的分类损失。
- Objectness loss,obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的obj损失。
- Location loss,定位损失,采用的是CIoU loss,注意只计算正样本的定位损失。
- λ1,λ2,λ3是平衡系数。
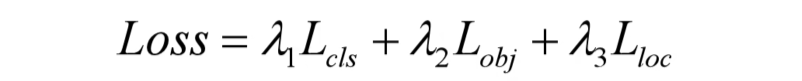
(2)4.2 平衡不同尺度的损失
- 这里是指针对三个预测特征层(P3, P4, P5)上的obj损失采用不同的权重。在源码中,针对预测小目标的预测特征层(P3)采用的权重是4.0,针对预测中等目标的预测特征层(P4)采用的权重是1.0,针对预测大目标的预测特征层(P5)采用的权重是0.4,作者说这是针对COCO数据集设置的超参数。
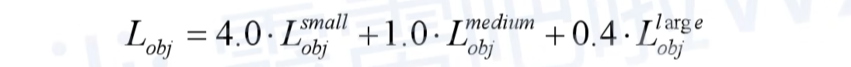
(3)预测框的宽高限制
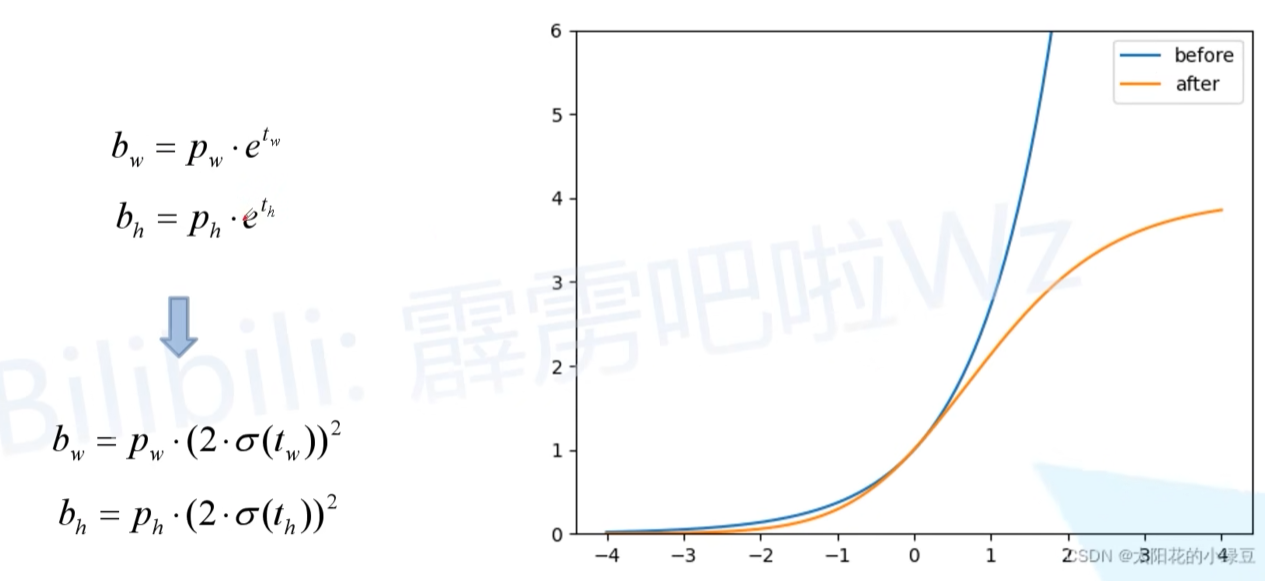
- 我们之前在YOLO v4中针对anchor的公式预测,只针对中心坐标的位置做了限制,但是没有对anchor的宽高做限制,这样可能出现梯度爆炸,训练不稳定等问题。用新公式限制宽高后,下图是修改前和修改后的的变化曲线, 很明显调整后倍率因子被限制在(0,4)之间
(4)正样本匹配
-
YOLO v5 和 v4 的大致流程差不多,主要的区别在于GT Box与Anchor模板的匹配方式。在YOLOv4中是计算IoU,只要IoU大于设定的阈值就算匹配成功。
-
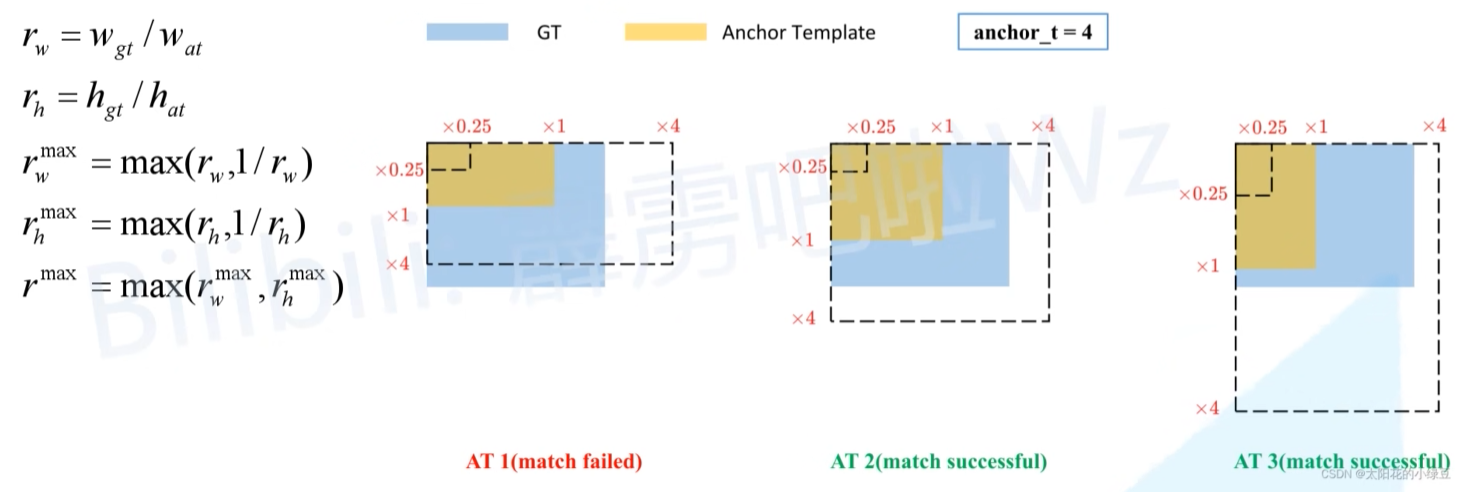
但在YOLOv5中,作者先去计算每个GT Box与对应的Anchor模板的高宽比例 rw,rh,
-
然后统计这些比例和它们倒数之间的最大值 ,得到 rmaxw,rmaxh,
-
最后统计rmaxw,rmaxh 之间的最大值,得到rmax,
-
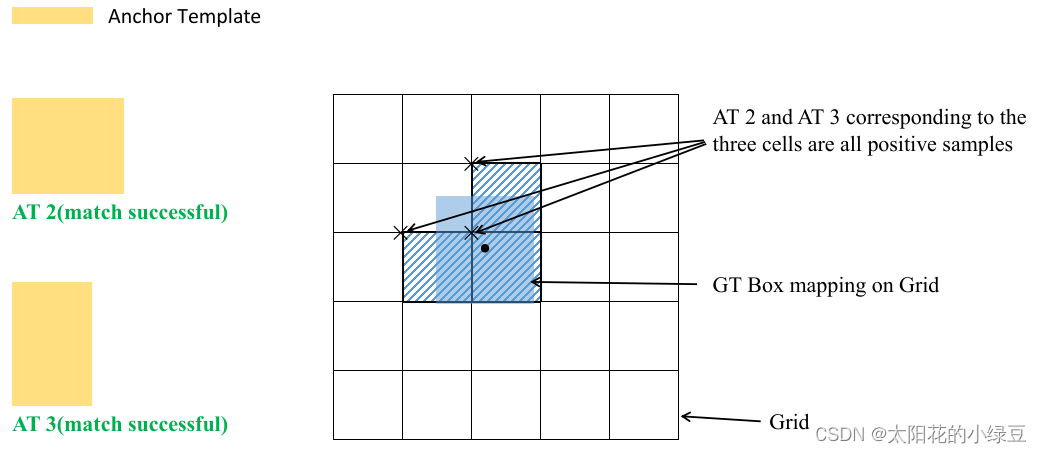
如果rmax小于阈值anchor_t (在源码中默认设置为4.0),即GT Box和对应的Anchor Template的高、宽比例相差不算太大,则将GT Box分配给该Anchor Template模板。按下图的例子来理解:就是GT在黑色虚线框内的就算匹配成功,AT2 和 AT3 都匹配成功。
-
-
剩下的步骤和YOLOv4中一致:
-
将GT投影到对应预测特征层上,根据GT的中心点定位到对应Cell,注意图中有三个对应的Cell。因为网络预测中心点的偏移范围已经调整到了(-0.5, 1.5),所以按理说只要Grid Cell左上角点距离GT中心点在(−0.5,1.5)范围内它们对应的Anchor都能回归到GT的位置处。这样会让正样本的数量得到大量的扩充。
-