在这篇文章中https://blog.csdn.net/2305_79295532/article/details/158928900我们讲过如何使用Serializer,但是我们可以注意到每个字段我们都需要手动定义,并且加上参数。那有没有一种办法可以实现自动定义字段,而且最好是定义模型的时候加了什么字段什么参数,序列化器就能生成类似或者一样的字段呢? 有的兄弟!有的! ------ModelSerializer
阅读本文,必须先去了解什么是Serializer,也可查看我的文章其中有对Serializer详细的讲解
目录
[1.2、 ModelSerializer 对比 Serializer](#1.2、 ModelSerializer 对比 Serializer)
[2.1 定义模型](#2.1 定义模型)
[2.2 定义ModelSerializer](#2.2 定义ModelSerializer)
[问题一:DRF 通过 字段映射表(Field Mapping) + 元数据推断 自动生成序列化器字段。](#问题一:DRF 通过 字段映射表(Field Mapping) + 元数据推断 自动生成序列化器字段。)
[问题二:null 影响数据库存储,blank 影响输入验证;ModelSerializer 分别映射为 allow_null 和 required/allow_blank。](#问题二:null 影响数据库存储,blank 影响输入验证;ModelSerializer 分别映射为 allow_null 和 required/allow_blank。)
3.2、关于2.2、定义ModelSerializer留下的坑
[使用 read_only_fields 和 extra_kwargs](#使用 read_only_fields 和 extra_kwargs)
一、ModelSerializer是什么
1.1、定义
ModelSerializer 是 Django REST Framework(DRF)提供的一个序列化器基类,它能自动根据指定的 Django 模型(Model)推断并生成对应的字段、验证规则以及默认的 .create() 和 .update() 方法,从而将模型实例与 JSON 兼容的原生数据结构(如字典)相互转换,极大减少样板代码,适用于标准的模型 CRUD API 开发。
**简而言之:**1、ModelSerializer根据模型生成对应的字段,2、ModelSerializer实现了create,update方法,用于操作数据库实现数据的增改。
1.2、 ModelSerializer 对比 Serializer
Serializer:完全手动定义字段和逻辑,灵活但重复,适用于任意数据结构。ModelSerializer:自动绑定 Django 模型,自动生成字段、验证、保存逻辑,适用于标准模型 CRUD。
| 维度 | Serializer(普通) |
ModelSerializer |
|---|---|---|
| 继承关系 | rest_framework.serializers.BaseSerializer |
Serializer 的子类 |
| 是否依赖模型 | 不依赖 | 必须指定 Meta.model |
| 字段定义 | 完全手动声明每个字段 | 自动从模型字段推断(类型、max_length、null、blank 等) |
.create() / .update() |
必须自己实现 | 自动生成(调用 Model.objects.create() 和 instance.save()) |
| 验证规则 | 全靠自定义(validate_, validators) |
自动继承模型约束: • unique → 唯一性验证 • blank=False → required=True • null=False → allow_null=False |
| 适用数据源 | 任意 Python 对象(字典、聚合数据、非模型数据) | 仅限 Django 模型实例或 QuerySet |
| 典型场景 | 登录、注册、搜索、统计报表、第三方 API 适配 | 用户管理、文章发布、商品 CRUD 等标准模型操作 |
二、使用ModelSerializer
接下来进入本文核心点------如何使用ModelSerializer 完成一个用户注册功能
2.1 定义模型
因为ModelSerializer根据模型生成字段,所以定义模型就是第一步。
定义模型对你来说可能很简单,但是接下来这几个问题如果你都能答出来才算真的过关
1. ModelSerializer根据模型字段会生成对应的字段,那你说说到底怎么对应的,生成了什么字段
**2.**关于 null 和 blank这两个参数 ModelSerializer会怎么处理
这两个问题的答案放在拓展中详细展开,这里我们着重讲如何使用ModelSerializer
python
from django.db import models
from django.core.validators import RegexValidator
# Create your models here.
class User(models.Model):
username = models.CharField('用户名', null=False, blank=False,max_length=50)
password = models.CharField('密码', null=False,blank=False,max_length=15)
mobile = models.CharField('手机号', unique=True, null=False,blank=False,max_length=11,validators=[RegexValidator(r'^1[3-9]\d{9}$', '请输入有效的中国大陆手机号')])
email = models.CharField('邮箱', unique=True, null=False,blank=False,max_length=20)
avatar = models.URLField('头像', blank=True,null=True)
bio = models.TextField('个人简介', default="这个人很帅,什么都没有留下", blank=True, max_length=500)
class Meta:
verbose_name = "用户信息"
verbose_name_plural = "用户信息"
db_table = 'user_profile'2.2 定义ModelSerializer
按照以下三步走
**step1:**定义 Meta类,指定模型及fields列表
**step2:**根据具体业务,可以选择新增自定义字段,亦或者覆盖模型字段,re_password:新增字段 , bio:覆盖模型字段
**step3:**如有自定义字段,需在validate方法中进行剔除
Tips:
- 关于新增字段需在fields中声明
ModelSerializer的fields列表决定了哪些字段会被包含在序列化器中。- 即使在类中声明了
re_password = ...,如果它不在Meta.fields里,DRF 会直接忽略它! - 新增字段如果仅用于数据校验,要定义validate方法进行字段剔除
- 如需覆盖模型字段,需要主动声明
- 对于bio字段,注册时无需用户填写,故设置为只读
关于Meta元类 如何定义的细节以及其他配置项将在 三、ModelSerializer扩展中展开
python
from rest_framework import serializers
from .models import User
class RegisterSerializer(serializers.ModelSerializer):
re_password = serializers.CharField(required=True,write_only=True)
bio = serializers.CharField(read_only=True)
class Meta:
model = User
fields = ['username', 'password', 'mobile', 'email', 'avatar', 'bio', 're_password']
def validate(self, attrs):
# 进行密码校验 两次输入密码需一致 ......
# 数据库无该字段 也不用存 故剔除re_password
attrs.pop('re_password')
return attrs2.3、在视图中使用ModelSerializer保存用户
使用ModelSerializer要严格按照以下步骤
- 实例化序列化器,传入数据
- 调用is_valid方法校验数据
- 只有通过校验才能进行save方法调用,否则报错
- 最后.data进行序列化返回
python
from rest_framework.response import Response
from rest_framework import status
from .models import User
# Create your views here.
class RegisterAPIView(APIView):
def post(self,request):
# 传入数据
serializer = RegisterSerializer(data=request.data,context={'request':request})
# 校验数据
serializer.is_valid(raise_exception=True)
# 保存数据
serializer.save()
return Response(serializer.data,status=status.HTTP_201_CREATED)2.4、Apipost完成接口测试
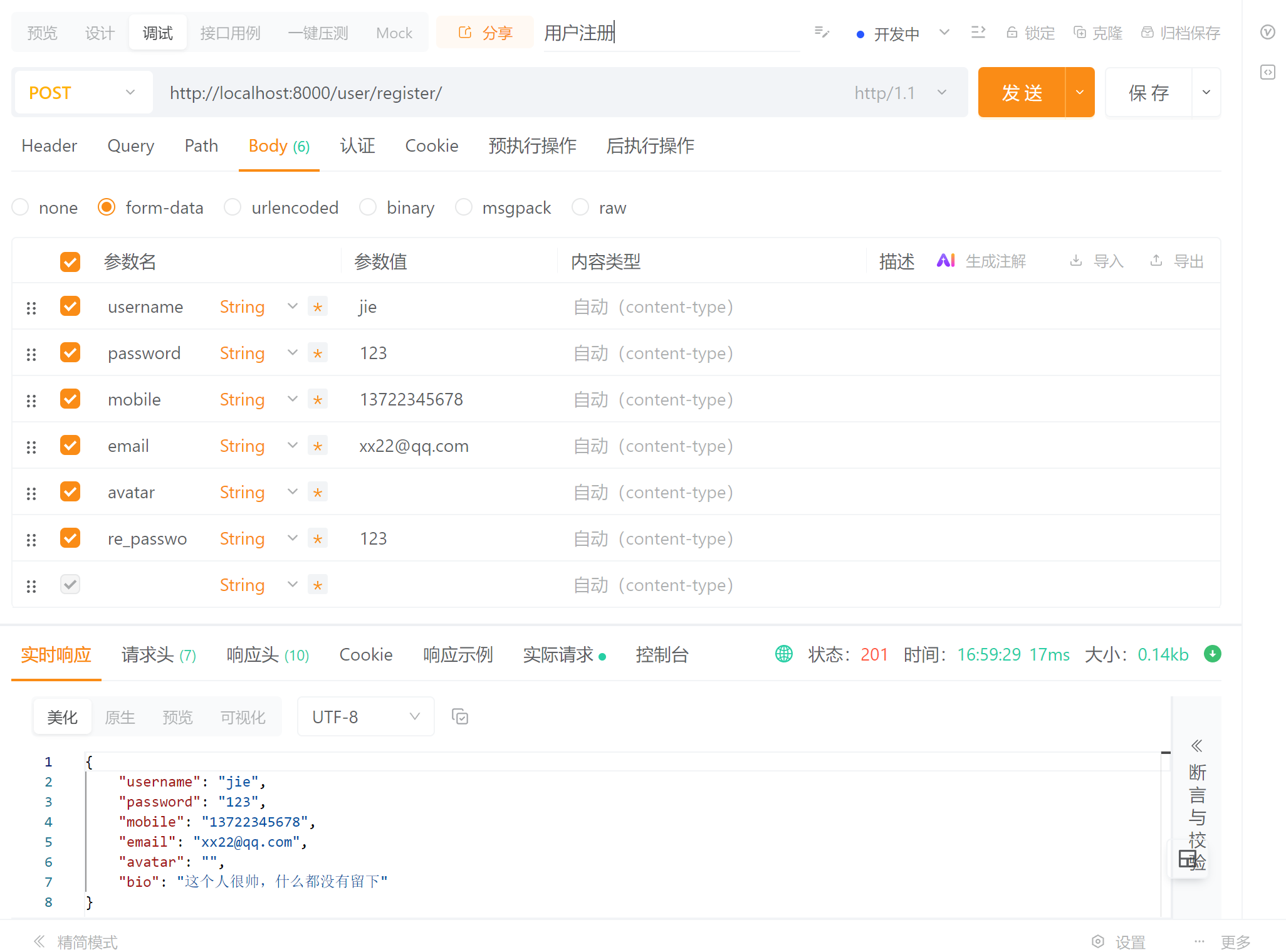
三、ModelSerializer拓展
3.1、关于2.1、定义模型留下的坑
1. ModelSerializer根据模型字段会生成对应的字段,那你说说到底怎么对应的,生成了什么字段
**2.**关于 null 和 blank这两个参数 ModelSerializer会怎么处理
问题一:DRF 通过 字段映射表(Field Mapping) + 元数据推断 自动生成序列化器字段。
在ModelSerializer源码中有一个 serializer_field_mapping 的字典,它定义了字段映射关系。可以点进源码查看其位于ModelSerializer类的最上面。
下面是我整理的表格,关于字段及字段选项的推断关系
通过查阅这个表格,能够完全明白模型定义的字段及约束会怎么生成到序列化器中
推断字段类型
| Django 模型字段 | DRF 自动生成的 Serializer 字段 | 关键参数推断 |
|---|---|---|
CharField / TextField |
CharField |
max_length, allow_blank= not field.blank |
EmailField |
EmailField |
同上 |
URLField |
URLField |
同上 |
IntegerField |
IntegerField |
min_value, max_value(如有 validators) |
FloatField |
FloatField |
--- |
DecimalField |
DecimalField |
必须有 max_digits, decimal_places |
BooleanField |
BooleanField |
--- |
DateField |
DateField |
auto_now/auto_now_add → read_only=True |
DateTimeField |
DateTimeField |
同上 |
ForeignKey / OneToOneField |
PrimaryKeyRelatedField |
queryset=model_field.related_model.objects.all() |
ManyToManyField |
PrimaryKeyRelatedField(many=True) |
同上 |
FileField / ImageField |
FileField / ImageField |
--- |
UUIDField |
UUIDField |
--- |
推断字段选项(来自模型约束)
| 模型字段属性 | → Serializer 字段选项 |
|---|---|
blank=False |
required=True, allow_blank=False(文本类) |
blank=True |
required=False, allow_blank=True |
null=False |
allow_null=False |
null=True |
allow_null=True |
unique=True |
添加 UniqueValidator |
choices |
自动加 ChoiceField 验证 |
default |
不自动设为 serializer 默认值(需手动处理) |
问题二:null 影响数据库存储,blank 影响输入验证;ModelSerializer 分别映射为 allow_null 和 required/allow_blank。
- null 指的是 数据库中对应的这个字段能不能存 null值
- blank指的是 前端传数据时对应的这个字段可以不传
一个是数据库保存数据,一个是前端传数据到后端。
重点区别:
- 文本字段有 空字符串 "" 概念 → 所以需要
allow_blank来限制不能传空字符串 - 非文本字段没有空字符串 → 只能是
null或有效值 → 所以只看required和allow_null
处理规则总结:
| 模型字段类型 | (模型中)blank=False→ |
blank=True→ |
null=False→ |
null=True→ |
|---|---|---|---|---|
文本类 (CharField, TextField) |
(序列化器中) required=True allow_blank=False |
required=False allow_blank=True |
allow_null=False |
allow_null=True |
非文本类 (IntegerField, DateTimeField, ForeignKey) |
(序列化器中) required=True |
required=False |
allow_null=False |
allow_null=True |
3.2、关于2.2、定义ModelSerializer留下的坑
关于Meta元类 如何定义的细节以及其他配置项
在2.2中 我们粗略的讲了下使用Meta元类 指定模型及需要生成的字段。除了这两个外,Meta元类还可以指定很多参数
以下是 ModelSerializer.Meta的常用配置项
这里看着有很多,但实际开发时,经常使用的还是头两个,有时为了节省代码,可能使用**read_only_fields,extra_kwargs。所以将重心放在这四个上面即可。以后遇到了对应场景再去学习了解也不迟**
| 属性 | 类型 | 说明 | 示例 |
|---|---|---|---|
model |
Model 类 |
指定关联的 Django 模型(仅 ModelSerializer 及其子类需要) |
model = User |
fields |
list[str] 或 '__all__' |
指定要序列化的字段名列表。 • '__all__' 表示包含所有模型字段 • 可包含自定义字段(需在类中声明) |
fields = ['id', 'username', 'email'] |
exclude |
list[str] |
排除某些字段(不能与 fields 同时使用) |
exclude = ['password', 'is_staff'] |
read_only_fields |
list[str] |
指定只读字段(反序列化时忽略,仅用于输出) | read_only_fields = ['created_at', 'id'] |
extra_kwargs |
dict |
为字段提供额外参数(如 write_only, required, min_length 等),适用于模型字段 |
extra_kwargs = { 'password': {'write_only': True},'email': {'required': True, 'min_length': 5}} |
validators |
list[callable] |
添加跨字段对象级验证器(作用于整个 validated_data) |
|
depth |
int |
自动展开外键/关系字段的嵌套层级(仅用于读取/序列化,不用于写入) |
使用 read_only_fields 和 extra_kwargs
还是以该代码为例,我们来讲清楚注意事项
- extra_kwargs是方便开发者,不用为了新增字段配置而去重新定义字段。前提是该字段是模型中已定义
- read_only_fields 用于设置fields列表中那些字段只读,也是为了简化开发。对字段无要求。
| 配置 | 能否用于非模型字段? | 建议使用场景 |
|---|---|---|
read_only_fields |
✅ 可以 | 任何你想设为只读的字段(无论来源) |
extra_kwargs |
❌ 不可以 | 仅用于模型字段的快捷配置(避免显式重写字段) |
python
from rest_framework import serializers
from .models import User
class RegisterSerializer(serializers.ModelSerializer):
re_password = serializers.CharField(required=True,write_only=True)
# bio = serializers.CharField(read_only=True) #下方配置了read_only_fields 故取消注释
class Meta:
model = User
fields = ['username', 'password', 'mobile', 'email', 'avatar', 'bio', 're_password']
# 配置了这个 那么上面的bio就可以注释掉
read_only_fields = ['bio']
# 只能作用于model中定义的字段
extra_kwargs = {
'password': {'write_only':True}, # password 是模型字段 有效
're_password': {'write_only':True, 'required':True} # re_password 不是模型中的字段 无效
}
def validate(self, attrs):
# 进行密码校验 两次输入密码需一致 ......
# 数据库无该字段 也不用存 故剔除re_password
attrs.pop('re_password')
return attrs